Kursus lengkap dalam bahasa Rusia dapat ditemukan di tautan ini .
Kursus bahasa Inggris asli tersedia di tautan ini .

Kuliah baru dijadwalkan setiap 2-3 hari.
Isi
- Wawancara dengan Sebastian Trun
- Pendahuluan
- Dataset Anjing dan Kucing
- Gambar berbagai ukuran
- Gambar berwarna. Bagian 1
- Gambar berwarna. Bagian 2
- Operasi konvolusi pada gambar berwarna
- Pengoperasian subsampling dengan nilai maksimum dalam gambar berwarna
- CoLab: kucing dan anjing
- Softmax dan sigmoid
- Periksa
- Ekstensi gambar
- Pengecualian
- CoLab: anjing dan kucing. Pengulangan
- Teknik lain untuk mencegah pelatihan ulang
- Latihan: klasifikasi gambar warna
- Ringkasan
Softmax dan Sigmoid
Dalam CoLab terakhir kami, kami menggunakan arsitektur jaringan saraf convolutional berikut:
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
Harap dicatat bahwa lapisan terakhir kami (classifier kami) terdiri dari lapisan yang sepenuhnya terhubung dengan dua neuron output dan softmax aktivasi softmax :
tf.keras.layers.Dense(2, activation='softmax')
Pendekatan populer lainnya untuk memecahkan masalah klasifikasi biner adalah penggunaan classifier, yang terdiri dari lapisan yang terhubung penuh dengan 1 output neuron dan sigmoid aktivasi sigmoid :
tf.keras.layers.Dense(1, activation='sigmoid')
Kedua opsi ini akan bekerja dengan baik dalam masalah klasifikasi biner. Namun, apa yang harus Anda ingat jika Anda memutuskan untuk menggunakan sigmoid aktivasi sigmoid di classifier Anda, Anda juga perlu mengubah fungsi loss di model.compile() dari sparse_categorical_crossentropy ke binary_crossentropy seperti pada contoh di bawah ini:
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Validasi
Di kelas sebelumnya, kami mempelajari keakuratan jaringan saraf convolutional kami menggunakan metrik accuracy pada dataset uji. Ketika kami mengembangkan jaringan saraf convolutional untuk mengklasifikasikan gambar dari set data FASHION MNIST, kami memperoleh akurasi 97% pada set data pelatihan dan hanya 92% akurasi pada set data uji. Semua ini terjadi karena model kami dilatih ulang. Dengan kata lain, jaringan saraf convolutional kami mulai mengingat set data pelatihan. Namun, kami dapat belajar tentang pelatihan ulang hanya setelah kami melatih dan menguji model pada data yang tersedia dengan membandingkan akurasi set data pelatihan dan set data uji.
Untuk menghindari masalah ini, kami sering menggunakan kumpulan data untuk validasi:
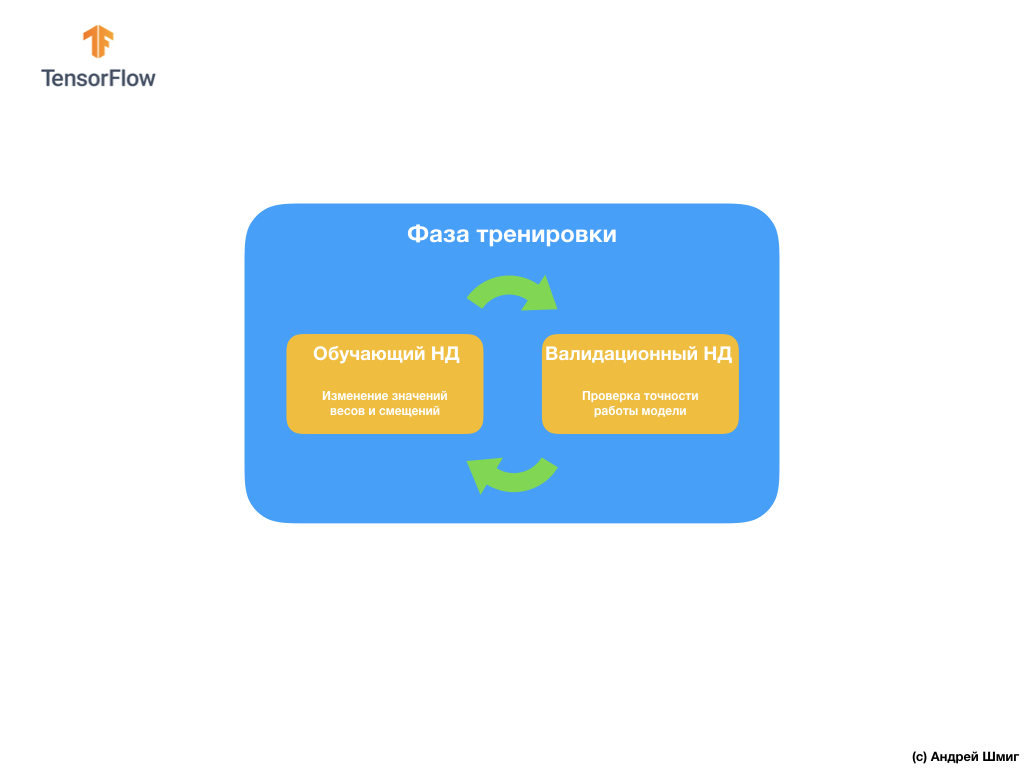
Selama pelatihan, jaringan saraf convolutional kami "melihat" hanya set data pelatihan dan membuat keputusan tentang bagaimana mengubah nilai-nilai parameter internal - bobot dan perpindahan. Setelah setiap iterasi pelatihan, kami memeriksa keadaan model dengan menghitung nilai fungsi kerugian pada set data pelatihan dan pada set data validasi. Perlu dicatat dan memberikan perhatian khusus pada fakta bahwa data dari set validasi tidak digunakan di mana pun oleh model untuk menyesuaikan nilai parameter internal. Memeriksa keakuratan model pada set data validasi hanya memberi tahu kami seberapa baik model kami bekerja pada set data yang sama. Dengan demikian, hasil model pada set data validasi memberi tahu kami seberapa baik model kami telah belajar untuk menggeneralisasi data yang diperoleh dan menerapkan generalisasi ini ke set data baru.
Idenya adalah karena kita tidak menggunakan set data validasi saat melatih model, maka pengujian model pada set validasi akan memungkinkan kita untuk memahami apakah model dilatih ulang atau tidak.
Mari kita lihat sebuah contoh.
Dalam CoLab, yang kami lakukan beberapa poin di atas, kami melatih jaringan saraf kami untuk 15 iterasi.
Epoch 15/15 10/10 [===] - loss: 1.0124 - acc: 0.7170 20/20 [===] - loss: 0.0528 - acc: 0.9900 - val_loss: 1.0124 - val_acc: 0.7070
Jika kita melihat keakuratan prediksi pada set data pelatihan dan validasi pada iterasi pelatihan kelima belas, kita dapat melihat bahwa kita telah mencapai akurasi tinggi pada set data pelatihan dan indikator yang sangat rendah pada set data validasi - 0.9900 dibandingkan 0.7070 .
Ini adalah tanda pelatihan ulang yang jelas. Jaringan saraf mengingat set data pelatihan, oleh karena itu ia bekerja dengan akurasi luar biasa pada input data dari itu. Namun, segera setelah memeriksa akurasi pada dataset validasi yang modelnya tidak “lihat”, hasilnya berkurang secara signifikan.
Salah satu cara untuk menghindari pelatihan ulang adalah dengan hati-hati mempelajari grafik nilai-nilai fungsi kerugian pada set data pelatihan dan validasi di seluruh semua iterasi pelatihan:
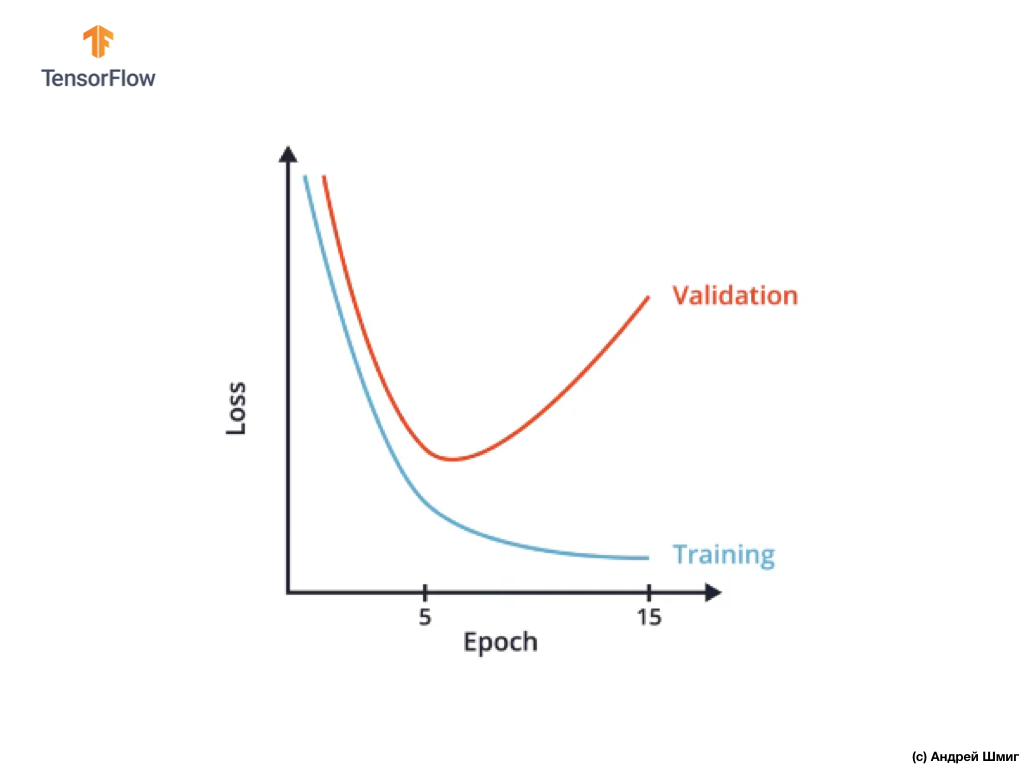
Dalam CoLab, kami membangun grafik yang sama dan mendapatkan sesuatu yang mirip dengan grafik di atas dari ketergantungan fungsi kerugian pada iterasi pelatihan.
Anda mungkin memperhatikan bahwa setelah iterasi pelatihan tertentu, nilai fungsi kerugian dalam set data validasi mulai meningkat, sementara nilai fungsi kerugian dalam set data pelatihan terus menurun.
Pada akhir iterasi 15 pelatihan, kami melihat bahwa nilai fungsi kerugian pada set data validasi sangat tinggi, dan nilai fungsi kerugian pada set data pelatihan sangat kecil. Sebenarnya, ini adalah indikator pelatihan jaringan saraf.
Dengan melihat grafik dengan cermat, Anda dapat memahami bahwa secara harfiah setelah beberapa iterasi pelatihan, jaringan saraf kami mulai hanya menyimpan data pelatihan, yang berarti bahwa kemampuan model untuk menggeneralisasi berkurang, yang mengarah pada penurunan akurasi pada set data validasi.
Seperti yang mungkin sudah Anda pahami, kumpulan data validasi memungkinkan kami untuk menentukan jumlah iterasi pelatihan yang perlu dilakukan agar jaringan saraf convolutional kami akurat dan, pada saat yang sama, tidak berlatih ulang.
Pendekatan semacam itu bisa sangat berguna jika kita memiliki pilihan beberapa arsitektur jaringan saraf convolutional:

Misalnya, jika Anda memutuskan jumlah lapisan dalam jaringan saraf convolutional, Anda dapat membuat beberapa arsitektur jaringan saraf dan kemudian membandingkan keakuratannya menggunakan kumpulan data untuk validasi.
Arsitektur jaringan saraf, yang memungkinkan Anda untuk mencapai nilai minimum dari fungsi kerugian dan akan menjadi yang terbaik untuk menyelesaikan tugas Anda.
Pertanyaan selanjutnya yang mungkin Anda miliki adalah mengapa membuat dataset validasi jika kita sudah memiliki dataset uji? Bisakah kita menggunakan set data uji untuk validasi?
Masalahnya adalah bahwa meskipun fakta bahwa kami tidak menggunakan dataset validasi dalam proses pelatihan model, kami menggunakan hasil bekerja pada dataset uji untuk meningkatkan akurasi model, yang berarti bahwa dataset uji mempengaruhi bobot dan bias dalam saraf. jaringan.
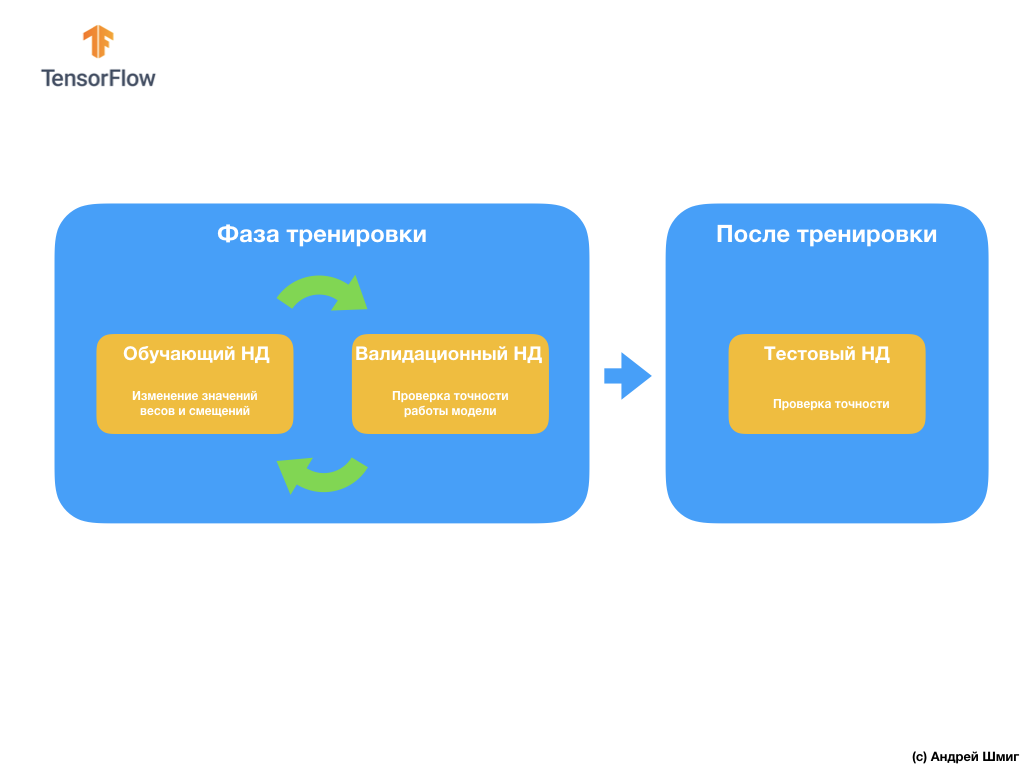
Karena alasan inilah kami memerlukan dataset validasi yang belum pernah dilihat oleh model kami untuk memverifikasi kinerjanya secara akurat.
Kami baru saja mengetahui bagaimana dataset yang divalidasi dapat membantu kami menghindari pelatihan ulang. Pada bagian berikut, kita akan berbicara tentang ekstensi data (yang disebut augmentasi) dan pemutusan (yang disebut putus) neuron - dua teknik populer yang juga dapat membantu kita menghindari pelatihan ulang.
Ekstensi Gambar (augmentasi)
Dalam melatih jaringan saraf untuk menentukan objek dari kelas tertentu, kami ingin jaringan saraf kami menemukan objek-objek ini, terlepas dari lokasi dan ukurannya dalam gambar.
Sebagai contoh, misalkan kita ingin melatih jaringan saraf kita untuk mengenali anjing dalam gambar:

Dengan demikian, kami ingin jaringan saraf kami untuk menentukan keberadaan seekor anjing dalam gambar, terlepas dari seberapa besar anjing itu dan di bagian mana dari gambar itu, apakah bagian dari anjing itu terlihat atau seluruh anjing. Kami ingin memastikan bahwa jaringan saraf kami dapat memproses semua opsi ini selama pelatihan.
Jika Anda cukup beruntung dan Anda memiliki satu set data pelatihan yang besar, maka kita dapat mengatakan dengan yakin bahwa Anda beruntung dan jaringan saraf Anda tidak mungkin untuk berlatih kembali. Namun, apa yang terjadi cukup sering, kami harus bekerja dengan rangkaian gambar yang terbatas (data pelatihan), yang, pada gilirannya, akan memimpin jaringan saraf convolutional kami dengan probabilitas tinggi untuk pelatihan ulang dan mengurangi kemampuannya untuk menggeneralisasi dan menghasilkan hasil yang diinginkan pada data yang tidak "melihat" sebelumnya.
Masalah ini dapat diselesaikan dengan menggunakan teknik yang disebut "ekstensi" (augmentasi gambar). Perluasan gambar (data) bekerja dengan membuat (menghasilkan) gambar baru untuk pelatihan dengan menerapkan transformasi sewenang-wenang dari set gambar asli dari set pelatihan.
Misalnya, kita dapat mengambil salah satu gambar sumber dari set data pelatihan kami dan menerapkan beberapa transformasi sewenang-wenang terhadapnya - balikkan dengan derajat X, mirror secara horizontal dan buat peningkatan yang sewenang-wenang.

Dengan menambahkan gambar yang dihasilkan ke set data pelatihan kami, kami yakin bahwa jaringan saraf kami akan "melihat" sejumlah contoh berbeda untuk pelatihan. Sebagai hasil dari tindakan tersebut, jaringan saraf convolutional kami akan lebih menggeneralisasi dan bekerja pada data yang belum terlihat dan kami akan dapat menghindari pelatihan ulang.
Pada bagian selanjutnya, kita akan belajar apa itu dropout (shutdown) - teknik lain untuk mencegah overfitting model.
Pengecualian (putus)
Pada bagian ini, kita akan belajar teknik baru - dropout, yang juga akan membantu kita menghindari pelatihan model yang berlebihan. Seperti yang sudah kita ketahui dari bagian awal, jaringan saraf mengoptimalkan parameter internal (bobot dan perpindahan) untuk meminimalkan fungsi kerugian.
Salah satu masalah yang dapat dihadapi saat melatih jaringan saraf adalah nilai-nilai besar di satu bagian dari jaringan saraf dan nilai-nilai kecil di bagian lain dari jaringan saraf.

Akibatnya, ternyata neuron dengan bobot lebih tinggi memainkan peran yang lebih besar dalam proses pembelajaran, sedangkan neuron dengan bobot lebih rendah berhenti menjadi signifikan dan semakin sedikit dapat berubah. Salah satu cara untuk menghindarinya adalah dengan menggunakan dropout neuron secara sewenang-wenang.
Shutdown (dropout) - proses shutdown selektif neuron dalam proses pembelajaran.
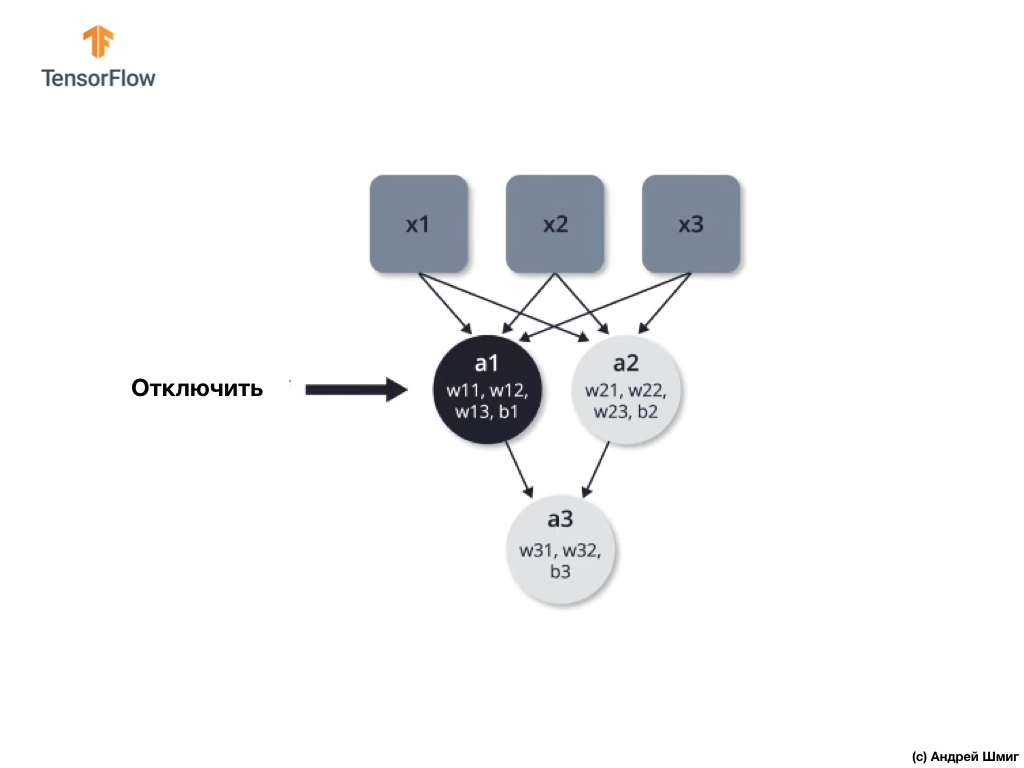
Pematian selektif dari beberapa neuron dalam proses pembelajaran memungkinkan Anda untuk secara aktif melibatkan neuron lain dalam pembelajaran. Selama pelatihan iterasi, kami sewenang-wenang menonaktifkan beberapa neuron.
Mari kita lihat sebuah contoh. Bayangkan bahwa pada iterasi pelatihan pertama, kami mematikan dua neuron yang disorot dalam warna hitam:
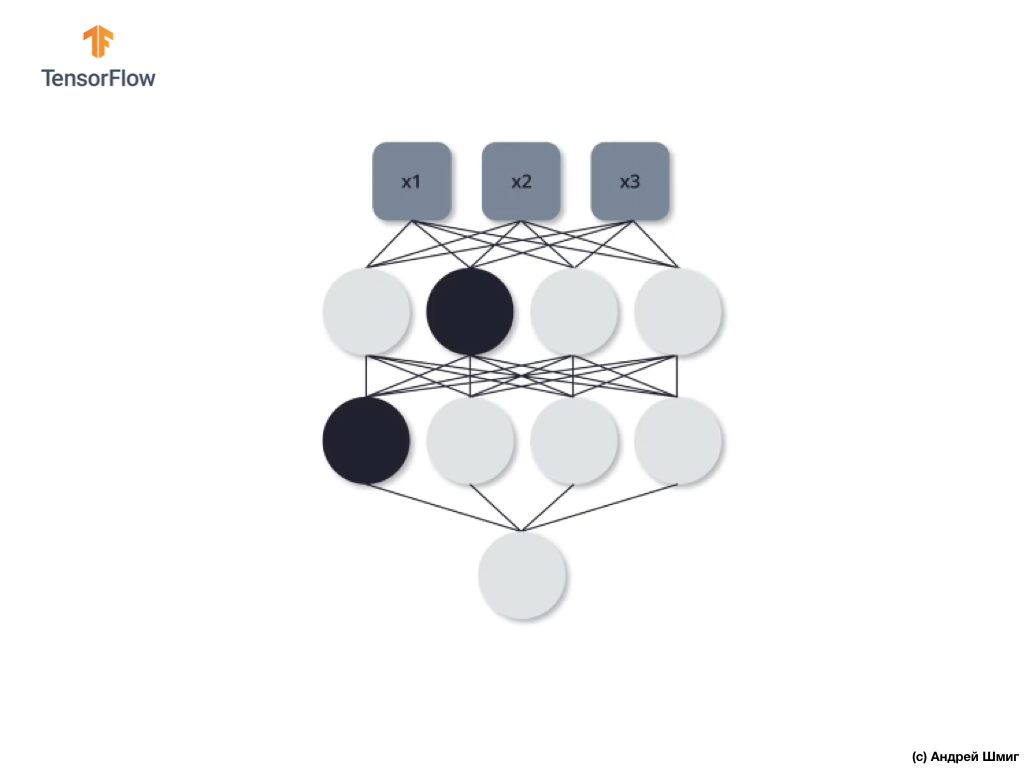
Proses propagasi langsung dan propagasi balik terjadi tanpa menggunakan dua neuron yang terisolasi.
Pada iterasi pelatihan kedua, kami memutuskan untuk tidak menggunakan tiga neuron berikut - matikan:

Seperti dalam kasus sebelumnya, dalam proses propagasi langsung dan balik, kami tidak menggunakan ketiga neuron ini. Terakhir, iterasi pelatihan ketiga, kami memutuskan untuk tidak menggunakan dua neuron ini:
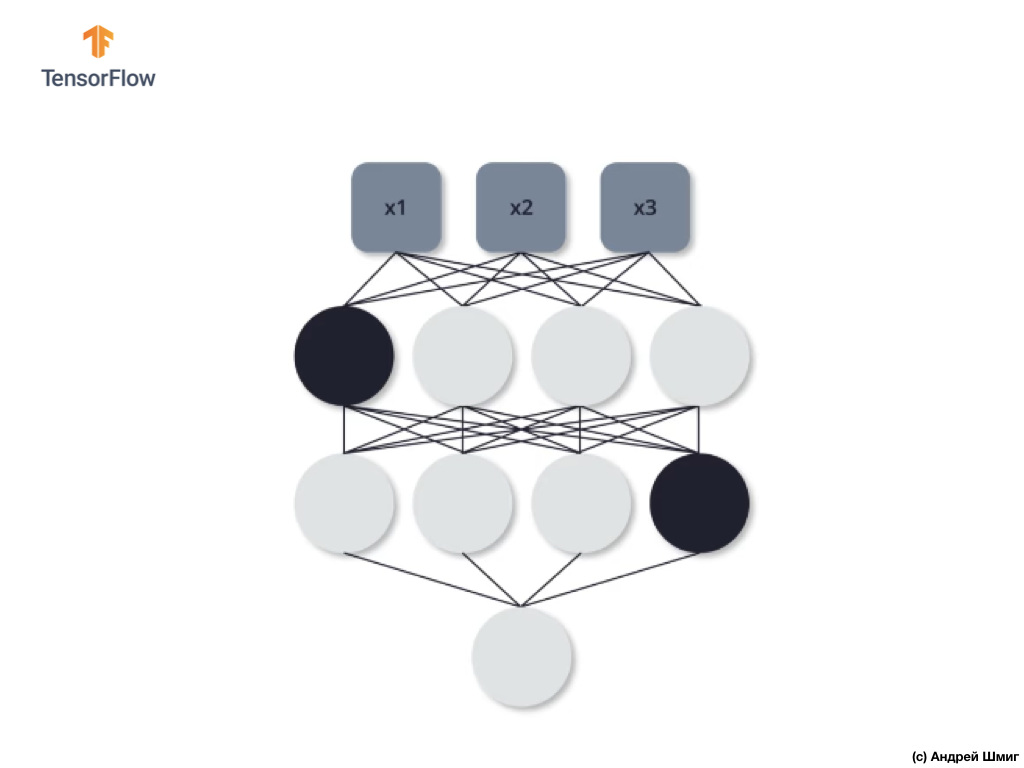
Dan dalam hal ini, kami tidak menggunakan neuron yang terputus dalam proses propagasi langsung dan terbalik. Dan sebagainya.
Dengan melatih jaringan saraf kita dengan cara ini kita dapat menghindari pelatihan ulang. Kita dapat mengatakan bahwa jaringan saraf kita menjadi lebih stabil, karena dengan pendekatan ini, ia tidak dapat bergantung sepenuhnya pada semua neuron untuk menyelesaikan masalah. Dengan demikian, neuron lain mulai mengambil bagian yang lebih aktif dalam pembentukan nilai output yang dibutuhkan dan juga mulai mengatasi tugas tersebut.
Dalam praktiknya, pendekatan ini membutuhkan indikasi kemungkinan menghilangkan setiap neuron pada setiap iterasi pelatihan. Harap dicatat bahwa menunjukkan kemungkinan kita menemukan diri kita dalam situasi di mana beberapa neuron akan lebih sering terputus daripada yang lain, dan beberapa mungkin tidak terputus sama sekali. Namun, ini bukan masalah, karena proses ini dilakukan berkali-kali dan rata-rata setiap neuron dengan probabilitas yang sama dapat terputus.
Sekarang mari kita terapkan pengetahuan teoretis yang diperoleh dalam praktik dan sempurnakan klasifikasi gambar kucing dan anjing kita.
CoLab: anjing dan kucing. Pengulangan
CoLab dalam bahasa Inggris tersedia di tautan ini .
CoLab dalam bahasa Rusia tersedia di tautan ini .
Kucing VS Anjing: klasifikasi gambar dengan ekstensi
Dalam tutorial ini, kita akan membahas cara mengategorikan gambar kucing dan anjing. Kami akan mengembangkan penggolong gambar menggunakan model tf.keras.Sequential , dan menggunakan tf.keras.Sequential untuk memuat data.
Gagasan yang akan dibahas di bagian ini:
Kami akan mendapatkan pengalaman praktis dalam mengembangkan classifier dan mengembangkan pemahaman intuitif konsep-konsep berikut:
- Membangun model aliran data ( jalur input data ) menggunakan kelas
tf.keras.preprocessing.image.ImageDataGenerator (Bagaimana cara efisien bekerja dengan data pada disk yang berinteraksi dengan model?) - Pelatihan ulang - apa itu dan bagaimana menentukannya?
- Augmentasi data dan metode putus sekolah adalah teknik utama dalam memerangi pelatihan ulang dalam tugas pengenalan pola yang akan kami terapkan dalam proses pelatihan model kami.
Kami akan mengikuti pendekatan dasar dalam mengembangkan model pembelajaran mesin:
- Jelajahi dan pahami data
- Konfigurasikan aliran input
- Membangun model
- Model kereta
- Model uji
- Perbaiki Model / Proses Ulangi
Sebelum kita mulai ...
Sebelum memulai kode di editor, kami sarankan Anda mengatur ulang semua pengaturan di Runtime -> Reset semua di menu atas. Tindakan semacam itu akan membantu menghindari masalah dengan kekurangan memori, jika Anda bekerja secara paralel atau bekerja dengan beberapa editor.
Paket impor
Mari kita mulai dengan mengimpor paket yang Anda butuhkan:
os - baca file dan struktur direktori;numpy - untuk beberapa operasi matriks di luar TensorFlow;matplotlib.pyplot - merencanakan dan menampilkan gambar dari dataset uji dan validasi.
from __future__ import absolute_import, division, print_function, unicode_literals import os import matplotlib.pyplot as plt import numpy as np
Impor TensorFlow :
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
Pemuatan data
Kami memulai pengembangan classifier kami dengan memuat dataset. Kumpulan data yang kami gunakan adalah versi yang disaring dari kumpulan data Anjing vs Kucing dari layanan Kaggle (pada akhirnya, kumpulan data ini disediakan oleh Microsoft Research).
Di masa lalu, CoLab dan saya menggunakan dataset dari modul TensorFlow Dataset itu sendiri, yang sangat nyaman untuk bekerja dan pengujian. Namun, dalam CoLab ini, kita akan menggunakan kelas tf.keras.preprocessing.image.ImageDataGenerator untuk membaca data dari disk. Oleh karena itu, pertama-tama kita perlu mengunduh kumpulan data Anjing VS Kucing dan unzip.
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip' zip_dir = tf.keras.utils.get_file('cats_and_dogs_filterted.zip', origin=_URL, extract=True)
Kumpulan data yang kami unduh memiliki struktur berikut:
cats_and_dogs_filtered |__ train |______ cats: [cat.0.jpg, cat.1.jpg, cat.2.jpg ...] |______ dogs: [dog.0.jpg, dog.1.jpg, dog.2.jpg ...] |__ validation |______ cats: [cat.2000.jpg, cat.2001.jpg, cat.2002.jpg ...] |______ dogs: [dog.2000.jpg, dog.2001.jpg, dog.2002.jpg ...]
Untuk mendapatkan daftar lengkap direktur, Anda dapat menggunakan perintah berikut:
zip_dir_base = os.path.dirname(zip_dir) !find $zip_dir_base -type d -print
Output (saat mulai dari CoLab):
/root/.keras/datasets /root/.keras/datasets/cats_and_dogs_filtered /root/.keras/datasets/cats_and_dogs_filtered/train /root/.keras/datasets/cats_and_dogs_filtered/train/dogs /root/.keras/datasets/cats_and_dogs_filtered/train/cats /root/.keras/datasets/cats_and_dogs_filtered/validation /root/.keras/datasets/cats_and_dogs_filtered/validation/dogs /root/.keras/datasets/cats_and_dogs_filtered/validation/cats
Sekarang tetapkan jalur yang benar ke direktori dengan set data untuk pelatihan dan validasi ke variabel:
base_dir = os.path.join(os.path.dirname(zip_dir), 'cats_and_dogs_filtered') train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') train_cats_dir = os.path.join(train_dir, 'cats') train_dogs_dir = os.path.join(train_dir, 'dogs') validation_cats_dir = os.path.join(validation_dir, 'cats') validation_dogs_dir = os.path.join(validation_dir, 'dogs')
Memahami data dan strukturnya
Mari kita lihat berapa banyak gambar kucing dan anjing yang kita miliki dalam kumpulan data pengujian dan validasi (direktori).
num_cats_tr = len(os.listdir(train_cats_dir)) num_dogs_tr = len(os.listdir(train_dogs_dir)) num_cats_val = len(os.listdir(validation_cats_dir)) num_dogs_val = len(os.listdir(validation_dogs_dir)) total_train = num_cats_tr + num_dogs_tr total_val = num_cats_val + num_dogs_val
print(' : ', num_cats_tr) print(' : ', num_dogs_tr) print(' : ', num_cats_val) print(' : ', num_dogs_val) print('--') print(' : ', total_train) print(' : ', total_val)
Kesimpulan:
: 1000 : 1000 : 500 : 500 -- : 2000 : 1000
Pengaturan parameter model
Untuk kenyamanan, kami akan menempatkan pemasangan variabel yang kami butuhkan untuk pemrosesan data lebih lanjut dan pelatihan model dalam pengumuman terpisah:
BATCH_SIZE = 100
Ekstensi data
Pelatihan ulang biasanya terjadi ketika ada beberapa contoh pelatihan dalam dataset kami. Salah satu cara untuk menghilangkan kekurangan data adalah mengembangkannya ke jumlah instance yang tepat dan variabilitas yang tepat. Ekstensi data adalah proses menghasilkan data dari instance yang ada dengan menerapkan berbagai transformasi pada set data asli. Tujuan dari metode ini adalah untuk menambah jumlah instance input unik yang model tidak akan pernah melihat lagi, yang, pada gilirannya, akan memungkinkan model untuk lebih menggeneralisasi data input dan menunjukkan akurasi yang lebih besar pada set data validasi.
Menggunakan tf.keras kita dapat mengimplementasikan transformasi acak tersebut dan menghasilkan gambar baru melalui kelas ImageDataGenerator . Ini akan cukup bagi kita untuk lulus dalam bentuk parameter berbagai transformasi yang ingin kita terapkan pada gambar, dan kelas itu sendiri akan mengurus sisanya selama pelatihan model.
Pertama, mari kita menulis fungsi yang akan menampilkan gambar yang diperoleh sebagai hasil dari transformasi acak. Kemudian kita akan memeriksa secara lebih rinci transformasi yang digunakan dalam proses perluasan set data asli.
def plotImages(images_arr): fig, axes = plt.subplots(1, 5, figsize=(20,20)) axes = axes.flatten() for img, ax in zip(images_arr, axes): ax.imshow(img) plt.tight_layout() plt.show()
Balikkan gambar secara horizontal
Kita dapat mulai dengan konversi sederhana - membalik gambar horizontal. Mari kita lihat bagaimana transformasi ini akan terlihat diterapkan pada gambar sumber kami. horizontal_flip=True ImageDataGenerator .
image_gen = ImageDataGenerator(rescale=1./255, horizontal_flip=True) train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE))
:
Found 2000 images belonging to 2 classes.
. ( ) .
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
(2 5 ):
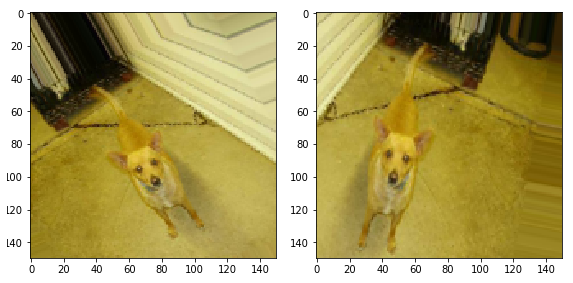
. 45.
image_gen = ImageDataGenerator(rescale=1./255, rotation_range=45) train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE))
:
Found 2000 images belonging to 2 classes.
— 5 . ( ) .
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
(2 5):

— 50%.
image_gen = ImageDataGenerator(rescale=1./255, zoom_range=0.5) train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE))
:
Found 2000 images belonging to 2 classes.
, — 5 . ( ) .
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
(2 5 ):

, , , ImageDataGenerator .
— , 45 , , , .
image_gen_train = ImageDataGenerator( rescale=1./255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest' ) train_data_gen = image_gen_train.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE), class_mode='binary')
:
Found 2000 images belonging to 2 classes.
, .
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
(2 5):

, , , . , , .
image_gen_val = ImageDataGenerator(rescale=1./255) val_data_gen = image_gen_val.flow_from_directory(batch_size=BATCH_SIZE, directory=validation_dir, target_size=(IMG_SHAPE, IMG_SHAPE), class_mode='binary')
4 .
0.5. , 50% 0. .
512 relu . — — softmax .
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(IMG_SHAPE, IMG_SHAPE, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Dropout(0.5), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
adam . sparse_categorical_crossentropy . , accuracy metrics :
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
summary :
model.summary()
:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ dropout (Dropout) (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 2) 1026 ================================================================= Total params: 3,453,634 Trainable params: 3,453,634 Non-trainable params: 0 _________________________________________________________________
!
( ImageDataGenerator ) fit_generator fit :
EPOCHS = 100 history = model.fit_generator( train_data_gen, steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))), epochs=EPOCHS, validation_data=val_data_gen, validation_steps=int(np.ceil(total_val / float(BATCH_SIZE))) )
:
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8,8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.savefig('./foo.png') plt.show()
:
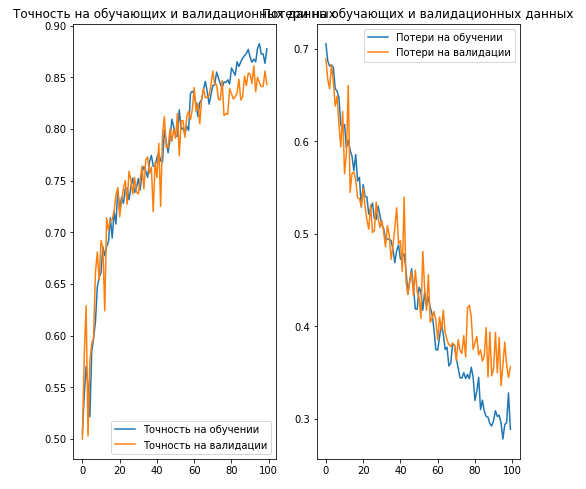
, :
- : ( ).
- (.. augmentation) : .
- / (.. dropout) : ( , ).
, . .
:
CoLab .
CoLab .
. CoLab . CoLab . CoLab , .
CoLab. CoLab , , .
!
# tf.keras
CoLab . tf.keras.Sequential , ImageDataGenerator .
. os , numpy python- numpy- , , matplotlib.pyplot .
from __future__ import absolute_import, division, print_function, unicode_literals import os import numpy as np import glob import shutil import matplotlib.pyplot as plt
TODO: TensorFlow Keras-
TensorFlow tf Keras- , . , ImageDataGenerator - Keras .
— . .
.
_URL = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz" zip_file = tf.keras.utils.get_file(origin=_URL, fname="flower_photos.tgz", extract=True) base_dir = os.path.join(os.path.dirname(zip_file), 'flower_photos')
, , 5 :
:
classes = ['', '', '', '', '']
, , :
flower_photos |__ diasy |__ dandelion |__ roses |__ sunflowers |__ tulips
. . , .
2 train val 5 - ( ). , 80% , 20% . :
flower_photos |__ diasy |__ dandelion |__ roses |__ sunflowers |__ tulips |__ train |______ daisy: [1.jpg, 2.jpg, 3.jpg ....] |______ dandelion: [1.jpg, 2.jpg, 3.jpg ....] |______ roses: [1.jpg, 2.jpg, 3.jpg ....] |______ sunflowers: [1.jpg, 2.jpg, 3.jpg ....] |______ tulips: [1.jpg, 2.jpg, 3.jpg ....] |__ val |______ daisy: [507.jpg, 508.jpg, 509.jpg ....] |______ dandelion: [719.jpg, 720.jpg, 721.jpg ....] |______ roses: [514.jpg, 515.jpg, 516.jpg ....] |______ sunflowers: [560.jpg, 561.jpg, 562.jpg .....] |______ tulips: [640.jpg, 641.jpg, 642.jpg ....]
, , . .
for cl in classes: img_path = os.path.join(base_dir, cl) images = glob.glob(img_path + '/*.jpg') print("{}: {} ".format(cl, len(images))) train, val = images[:round(len(images)*0.8)], images[round(len(images)*0.8):] for t in train: if not os.path.exists(os.path.join(base_dir, 'train', cl)): os.makedirs(os.path.join(base_dir, 'train', cl)) shutil.move(t, os.path.join(base_dir, 'train', cl)) for v in val: if not os.path.exists(os.path.join(base_dir, 'val', cl)): os.makedirs(os.path.join(base_dir, 'val', cl)) shutil.move(v, os.path.join(base_dir, 'val', cl))
:
train_dir = os.path.join(base_dir, 'train') val_dir = os.path.join(base_dir, 'val')
, , , . — (.. augmentation) . . , , — , . .
tf.keras , — ImageDataGenerator . .
. — () batch_size , IMG_SHAPE .
TODO:
100 batch_size 150 IMG_SHAPE :
batch_size = IMG_SHAPE =
TODO:
ImageDataGenerator , , . .flow_from_directory . , , , .
image_gen = train_data_gen =
5 :
def plotImages(images_arr): fig, axes = plt.subplots(1, 5, figsize=(20,20)) axes = axes.flatten() for img, ax in zip(images_arr, axes): ax.imshow(img) plt.tight_layout() plt.show() augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
TODO:
, ImageDataGenerator 45 . .flow_from_directory . , , , .
image_gen = train_data_gen =
5 :
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
TODO:
, ImageDataGenerator 50%. .flow_from_directory . , , , .
image_gen = train_data_gen =
5 :
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
TODO:
, ImageDataGenerator :
flow_from_directory . , , , .
image_gen_train = train_data_gen =
5 :
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
TODO:
. , , ImageDataGenerator , . flow_from_directory . , , . .
image_gen_val = val_data_gen =
TODO:
, 3 — . 16 , — 32 , — 64 . 33. 22.
Flatten , 512 . 5 , softmax . relu . , , 20%.
model =
TODO:
, adam sparse_categorical_crossentropy . , compile(...) .
TODO:
, fit_generator fit , . fit_generator ImageDataGenerator . 80 , fit_generator -.
epochs = history =
TODO: /
, :
acc = val_acc = loss = val_loss = epochs_range =
TODO:
( + ) 512 . . . , , .. , ImageDataGenerator — . , .
?
.
RGB- :
- : , ( );
- : 3D-;
- RGB- : 3 : , ;
- : (). , (). — .
- : . , .
- : . , .
:
. , . .
… call-to-action — , share :)
YouTube
Telegram
VKontakte