(bagian pertama di sini: https://habr.com/en/post/456446/ )
Ceph
Pendahuluan
Karena jaringan adalah salah satu elemen kunci Ceph, dan ini sedikit spesifik di perusahaan kami, pertama-tama kami akan memberi tahu Anda sedikit tentangnya.
Akan ada lebih sedikit deskripsi tentang Ceph sendiri, terutama infrastruktur jaringan. Hanya server Ceph dan beberapa fitur server virtualisasi Proxmox yang akan dijelaskan.
Jadi: Topologi jaringan itu sendiri dibangun sebagai Leaf-Spine. Arsitektur three-tier klasik adalah jaringan di mana ada Core (router inti), Agregasi (router agregasi) dan terhubung langsung dengan klien Access (router akses):
Skema tiga tingkat
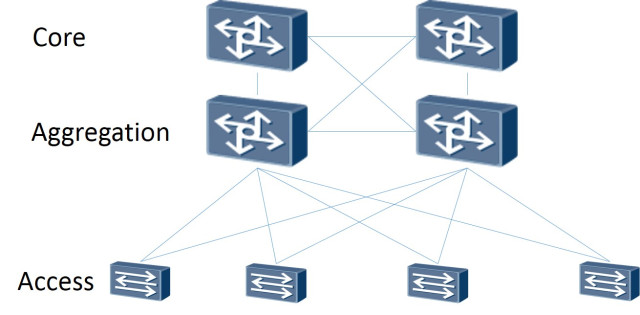
Topologi Leaf-Spine terdiri dari dua level: Spine (kira-kira berbicara router utama) dan Leaf (cabang).
Skema dua tingkat

Semua perutean internal dan eksternal dibangun di atas BGP. Sistem utama yang berkaitan dengan kontrol akses, pengumuman, dan lainnya adalah XCloud.
Server untuk reservasi saluran (dan juga untuk perluasannya) terhubung ke dua switch L3 (sebagian besar server terhubung ke switch Leaf, tetapi beberapa server dengan beban jaringan yang meningkat terhubung langsung ke Spine switch), dan melalui BGP mengumumkan alamat unicast mereka, serta alamat broadcast mana pun untuk layanan ini jika beberapa server melayani lalu lintas layanan dan penyeimbangan ECMP sudah cukup untuk mereka. Fitur terpisah dari skema ini, yang memungkinkan kami untuk menghemat alamat, tetapi juga mengharuskan para insinyur untuk berkenalan dengan dunia IPv6, adalah penggunaan standar tanpa nomor BGP berdasarkan RFC 5549. Selama beberapa waktu, Quagga digunakan untuk server di BGP untuk skema ini untuk server dan secara berkala ada masalah dengan hilangnya pesta dan konektivitas. Tetapi setelah beralih ke FRRouting (yang kontributor aktifnya adalah vendor peralatan jaringan kami: Cumulus dan XCloudNetworks), kami tidak melihat masalah seperti itu lagi.
Untuk kenyamanan, kami menyebut seluruh skema umum ini sebagai "pabrik."
Cari cara
Opsi konfigurasi jaringan cluster:
1) Jaringan kedua pada BGP
2) Jaringan kedua pada dua sakelar bertumpuk terpisah dengan LACP
3) Jaringan kedua pada dua sakelar terisolasi terpisah dengan OSPF
Tes
Tes dilakukan dalam dua jenis:
a) jaringan menggunakan utilitas iperf, qperf, nuttcp
b) tes internal Ceph ceph-gobench, rados bench, dibuat rbd dan diuji menggunakan dd di satu atau beberapa thread, menggunakan fio
Semua tes dilakukan pada mesin uji dengan disk SAS. Angka-angka dalam kinerja rbd tidak terlihat terlalu banyak, mereka hanya digunakan untuk perbandingan. Tertarik pada perubahan tergantung pada jenis koneksi.
Opsi pertama
Kartu jaringan terhubung ke pabrik, BGP yang dikonfigurasi.
Menggunakan skema ini untuk jaringan internal tidak dianggap sebagai pilihan terbaik:
Pertama, kelebihan jumlah elemen perantara dalam bentuk sakelar yang memberikan latensi tambahan (ini adalah alasan utama).
Kedua, pada awalnya, untuk melemparkan statika melalui s3, mereka menggunakan alamat broadcast yang dibangkitkan pada beberapa mesin dengan radosgateway. Ini menghasilkan fakta bahwa lalu lintas dari mesin front-end ke RGW tidak didistribusikan secara merata, tetapi melewati rute terpendek - yaitu, front-end Nginx selalu beralih ke node yang sama dengan RGW yang terhubung ke daun yang dibagikan dengannya (ini, tentu saja, adalah bukan argumen utama - kami hanya menolak selanjutnya dari alamatcast untuk mengembalikan statis). Tetapi untuk kemurnian percobaan, mereka memutuskan untuk melakukan tes pada skema tersebut untuk mendapatkan data untuk perbandingan.
Kami takut menjalankan tes untuk seluruh bandwidth, karena pabrik digunakan oleh server prod, dan jika kami memblokir tautan antara leaf dan spine, ini akan merugikan sebagian penjualan.
Sebenarnya, ini adalah alasan lain untuk menolak skema semacam itu.
Tes Iperf dengan batas BW 3Gbps dari aliran 1, 10 dan 100 digunakan untuk perbandingan dengan skema lain.
Tes menunjukkan hasil sebagai berikut:
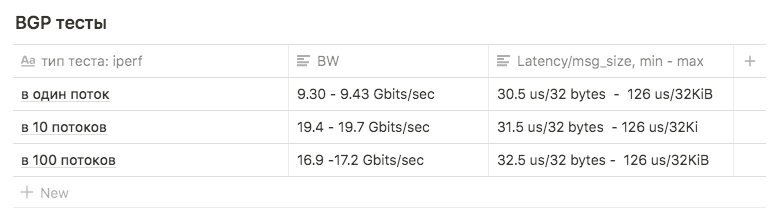
dalam 1 aliran, sekitar 9,30 - 9,43 Gbits / detik (dalam hal ini, jumlah transmisi ulang tumbuh dengan kuat, menjadi 39148 ). Angka tersebut ternyata mendekati maksimal satu antarmuka menunjukkan bahwa salah satu dari keduanya digunakan. Jumlah pengiriman ulang adalah sekitar 500-600.
10 stream dari 9,63 Gbits / detik per antarmuka, sementara jumlah pengiriman ulang tumbuh rata-rata 17045.
di 100 utas, hasilnya lebih buruk daripada di 10 , sementara jumlah pengiriman kembali lebih sedikit: nilai rata-rata adalah 3354
Opsi kedua
Lacp
Ada dua switch Juniper EX4500. Mereka mengumpulkannya di stack, menghubungkan server dengan tautan pertama ke satu switch, switch kedua ke switch kedua.
Pengaturan ikatan awal adalah sebagai berikut:
root@ceph01-test:~# cat /etc/network/interfaces auto ens3f0 iface ens3f0 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f0 rx 8192 post-up /sbin/ethtool -G ens3f0 tx 8192 post-up /sbin/ethtool -L ens3f0 combined 32 post-up /sbin/ip link set ens3f0 txqueuelen 10000 mtu 9000 auto ens3f1 iface ens3f1 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f1 rx 8192 post-up /sbin/ethtool -G ens3f1 tx 8192 post-up /sbin/ethtool -L ens3f1 combined 32 post-up /sbin/ip link set ens3f1 txqueuelen 10000 mtu 9000 auto bond0 iface bond0 inet static address 10.10.10.1 netmask 255.255.255.0 slaves none bond_mode 802.3ad bond_miimon 100 bond_downdelay 200 bond_xmit_hash_policy 3 #(layer3+4 ) mtu 9000
Tes iperf dan qperf menunjukkan Bw hingga 16Gbits / detik. Kami memutuskan untuk membandingkan berbagai jenis mod:
rr, balance-xor dan 802.3ad. Kami juga membandingkan berbagai jenis hashing layer2 + 3 dan layer3 + 4 (berharap mendapatkan keuntungan pada komputasi hash).
Kami juga membandingkan hasil untuk nilai sysctl yang berbeda dari variabel net.ipv4.fib_multipath_hash_policy, (well, kami bermain sedikit dengan net.ipv4.tcp_congestion_control , meskipun tidak ada hubungannya dengan ikatan . Ada artikel ValdikSS yang bagus tentang variabel ini).
Tetapi dalam semua tes, itu tidak berhasil untuk mengatasi ambang 18Gbits / detik (angka ini dicapai dengan menggunakan balance-xor dan 802.3ad , tidak ada banyak perbedaan antara hasil tes) dan nilai ini dicapai "dalam lompatan" oleh semburan.
Opsi ketiga
OSPF
Untuk mengkonfigurasi opsi ini, LACP telah dihapus dari sakelar (penumpukan ditinggalkan, tetapi hanya digunakan untuk manajemen). Pada setiap switch, kami mengumpulkan vlan terpisah untuk sekelompok port (dengan pandangan ke masa depan bahwa server QA dan PROD akan terjebak dalam switch yang sama).
Mengkonfigurasi dua jaringan pribadi datar untuk setiap vlan (satu antarmuka per sakelar). Di atas semua alamat ini adalah pengumuman alamat lain dari jaringan pribadi ketiga, yang merupakan jaringan cluster untuk CEPH.
Karena jaringan publik (melalui mana kami menggunakan SSH) bekerja pada BGP, kami menggunakan frr untuk mengkonfigurasi OSPF, yang sudah ada di sistem.
10.10.10.0/24 dan 20.20.20.0/24 - dua jaringan datar pada sakelar
172.16.1.0/24 - jaringan untuk pengumuman
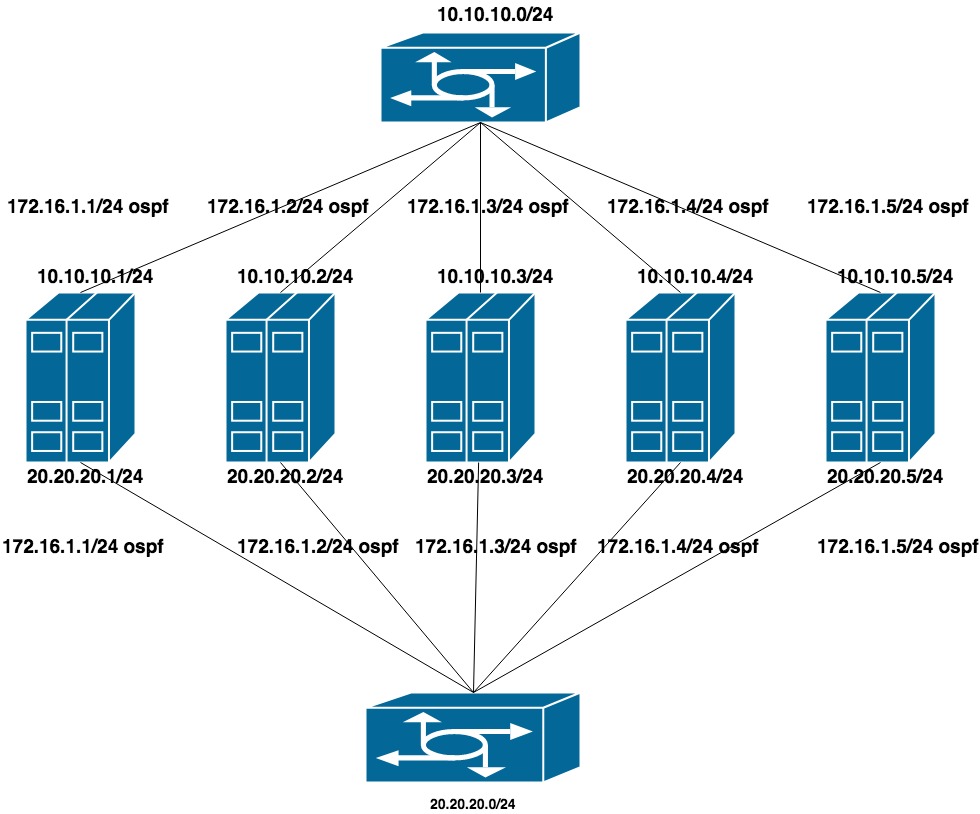
Pengaturan mesin:
antarmuka ens1f0 ens1f1 melihat jaringan pribadi
antarmuka ens4f0 ens4f1 melihat jaringan publik
Konfigurasi jaringan pada mesin terlihat seperti ini:
oot@ceph01-test:~# cat /etc/network/interfaces # This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback auto ens1f0 iface ens1f0 inet static post-up /sbin/ethtool -G ens1f0 rx 8192 post-up /sbin/ethtool -G ens1f0 tx 8192 post-up /sbin/ethtool -L ens1f0 combined 32 post-up /sbin/ip link set ens1f0 txqueuelen 10000 mtu 9000 address 10.10.10.1/24 auto ens1f1 iface ens1f1 inet static post-up /sbin/ethtool -G ens1f1 rx 8192 post-up /sbin/ethtool -G ens1f1 tx 8192 post-up /sbin/ethtool -L ens1f1 combined 32 post-up /sbin/ip link set ens1f1 txqueuelen 10000 mtu 9000 address 20.20.20.1/24 auto ens4f0 iface ens4f0 inet manual post-up /sbin/ethtool -G ens4f0 rx 8192 post-up /sbin/ethtool -G ens4f0 tx 8192 post-up /sbin/ethtool -L ens4f0 combined 32 post-up /sbin/ip link set ens4f0 txqueuelen 10000 mtu 9000 auto ens4f1 iface ens4f1 inet manual post-up /sbin/ethtool -G ens4f1 rx 8192 post-up /sbin/ethtool -G ens4f1 tx 8192 post-up /sbin/ethtool -L ens4f1 combined 32 post-up /sbin/ip link set ens4f1 txqueuelen 10000 mtu 9000 # loopback-: auto lo:0 iface lo:0 inet static address 55.66.77.88/32 dns-nameservers 55.66.77.88 auto lo:1 iface lo:1 inet static address 172.16.1.1/32
Konfigurasi frr terlihat seperti ini:
root@ceph01-test:~# cat /etc/frr/frr.conf frr version 6.0 frr defaults traditional hostname ceph01-prod log file /var/log/frr/bgpd.log log timestamp precision 6 no ipv6 forwarding service integrated-vtysh-config username cumulus nopassword ! interface ens4f0 ipv6 nd ra-interval 10 ! interface ens4f1 ipv6 nd ra-interval 10 ! router bgp 65500 bgp router-id 55.66.77.88 # , timers bgp 10 30 neighbor ens4f0 interface remote-as 65001 neighbor ens4f0 bfd neighbor ens4f1 interface remote-as 65001 neighbor ens4f1 bfd ! address-family ipv4 unicast redistribute connected route-map redis-default exit-address-family ! router ospf ospf router-id 172.16.0.1 redistribute connected route-map ceph-loopbacks network 10.10.10.0/24 area 0.0.0.0 network 20.20.20.0/24 area 0.0.0.0 ! ip prefix-list ceph-loopbacks seq 10 permit 172.16.1.0/24 ge 32 ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32 ! route-map ceph-loopbacks permit 10 match ip address prefix-list ceph-loopbacks ! route-map redis-default permit 10 match ip address prefix-list default-out ! line vty !
Pada pengaturan ini, jaringan menguji iperf, qperf, dll. menunjukkan pemanfaatan maksimum kedua saluran pada 19,8 Gbit / detik, sementara latensi turun menjadi 20 us
Bgp router-id field : Digunakan untuk mengidentifikasi node saat memproses informasi rute dan membangun rute. Jika tidak ditentukan dalam konfigurasi, salah satu alamat IP host dipilih. Produsen perangkat keras dan perangkat lunak yang berbeda mungkin memiliki algoritma yang berbeda, dalam kasus kami FRR menggunakan alamat IP loopback terbesar. Ini menyebabkan dua masalah:
1) Jika kami mencoba untuk menutup alamat lain (misalnya, pribadi dari jaringan 172.16.0.0) lebih dari yang sekarang, maka ini menyebabkan perubahan id router dan, karenanya, untuk menginstal ulang sesi saat ini. Ini berarti istirahat pendek dan hilangnya konektivitas jaringan.
2) Jika kami mencoba untuk menggantungkan alamat broadcast yang dibagikan oleh beberapa mesin dan itu dipilih sebagai id router , dua node dengan id router yang sama muncul di jaringan .
Bagian 2
Setelah menguji untuk QA, kami mulai meningkatkan tempur Ceph.
JARINGAN
Pindah dari satu jaringan ke dua
Parameter jaringan cluster adalah salah satu yang tidak dapat diubah dengan cepat dengan menetapkan OSD melalui ceph tell osd. * Injectargs. Mengubahnya di konfigurasi dan me-restart seluruh cluster adalah solusi yang dapat ditoleransi, tapi saya benar-benar tidak ingin memiliki bahkan downtime kecil. Juga tidak mungkin untuk memulai kembali satu OSD dengan parameter jaringan baru - pada titik tertentu kita akan memiliki dua setengah kluster - OSD lama pada jaringan lama, yang baru pada yang baru. Untungnya, parameter jaringan cluster (dan juga public_network, by the way) adalah daftar, yaitu, Anda dapat menentukan beberapa nilai. Kami memutuskan untuk pindah secara bertahap - pertama-tama tambahkan jaringan baru ke konfigurasi, kemudian hapus yang lama. Ceph menelusuri daftar jaringan secara berurutan - OSD mulai bekerja lebih dulu dengan jaringan yang terdaftar terlebih dahulu.
Kesulitannya adalah bahwa jaringan pertama bekerja melalui bgp dan terhubung ke satu switch, dan yang kedua - ke ospf dan terhubung ke yang lain yang secara fisik tidak terhubung ke yang pertama. Pada saat transisi, perlu untuk sementara waktu mengakses jaringan antara dua jaringan. Keunikan mendirikan pabrik kami adalah bahwa ACL tidak dapat dikonfigurasi pada jaringan jika tidak ada dalam daftar yang diiklankan (dalam hal ini adalah "eksternal" dan ACL untuk itu hanya dapat dibuat secara eksternal. Itu dibuat pada spanyol, tetapi tidak tiba pada daun).
Solusinya adalah penopang, rumit, tetapi berhasil: untuk mengiklankan jaringan internal melalui bgp, bersamaan dengan ospf.
Urutan transisi adalah sebagai berikut:
1) Mengkonfigurasi jaringan cluster untuk ceph pada dua jaringan: melalui bgp dan melalui ospf
Dalam konfigurasi, tidak perlu mengubah apa pun, garis
ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32
itu tidak membatasi kita di alamat yang diumumkan, alamat untuk jaringan internal itu sendiri dinaikkan pada antarmuka loopback, itu sudah cukup untuk mengkonfigurasi penerimaan pengumuman alamat ini di router.
2) Tambahkan jaringan baru ke konfigurasi ceph.conf
cluster network = 172.16.1.0/24, 55.66.77.88/27
dan mulai restart OSD satu per satu sampai semua orang beralih ke jaringan 172.16.1.0/24.
root@ceph01-prod:~#ceph osd set noout # - OSD # . , # , OSD 30 . root@ceph01-prod:~#for i in $(ps ax | grep osd | grep -v grep| awk '{ print $10}'); \ root@ceph01-prod:~# do systemctl restart ceph-osd@$i; sleep 30; done
3) Kemudian kami menghapus jaringan berlebih dari konfigurasi
cluster network = 172.16.1.0/24
dan ulangi prosedurnya.
Itu saja, kami dengan lancar pindah ke jaringan baru.
Referensi:
https://shalaginov.com/2016/03/26/network-topology-leaf-spine/
https://www.xcloudnetworks.com/case-studies/innova-case-study/
https://github.com/rumanzo/ceph-gobench