Dalam artikel ini saya akan berbicara tentang bagaimana proyek tempat saya bekerja berubah dari monolit besar menjadi seperangkat layanan mikro.
Proyek ini memulai sejarahnya sejak lama, pada awal tahun 2000. Versi pertama ditulis dalam Visual Basic 6. Seiring waktu, menjadi jelas bahwa pengembangan bahasa ini di masa depan akan sulit untuk didukung, karena IDE dan bahasa itu sendiri kurang berkembang. Pada akhir 2000-an, diputuskan untuk beralih ke C # yang lebih menjanjikan. Versi baru ditulis secara paralel dengan penyempurnaan dari yang lama, secara bertahap semakin banyak kode di .NET. Backend di C # awalnya berfokus pada arsitektur layanan, namun, selama pengembangan, perpustakaan bersama dengan logika digunakan, dan layanan diluncurkan dalam satu proses tunggal. Ternyata aplikasi tersebut, yang kami sebut "service monolith".
Salah satu dari sedikit kelebihan bundel ini adalah kemampuan layanan untuk saling memanggil melalui API eksternal. Ada prasyarat yang jelas untuk transisi ke layanan yang lebih benar, dan di masa depan, arsitektur layanan mikro.
Kami memulai pekerjaan dekomposisi kami sekitar tahun 2015. Kami belum mencapai kondisi ideal - ada bagian dari proyek besar yang sulit disebut monolit, tetapi mereka juga tidak terlihat seperti layanan mikro. Namun, kemajuannya sangat besar.
Saya akan berbicara tentang dia di artikel tersebut.
Isi
Arsitektur dan masalah solusi yang ada
Awalnya, arsitekturnya tampak sebagai berikut: UI adalah aplikasi terpisah, bagian monolitik ditulis dalam Visual Basic 6, aplikasi dalam .NET adalah seperangkat layanan terkait yang bekerja dengan database yang cukup besar.
Kekurangan dari solusi sebelumnyaSatu titik kegagalanKami memiliki satu titik kegagalan: aplikasi .NET berjalan dalam satu proses. Jika ada modul yang rusak, seluruh aplikasi gagal, dan Anda harus memulai ulang. Karena kami mengotomatisasi sejumlah besar proses untuk pengguna yang berbeda, karena kegagalan pada salah satu dari mereka, beberapa tidak dapat bekerja selama beberapa waktu. Dan dengan kesalahan perangkat lunak, redundansi juga tidak membantu.
Susunan perbaikanKelemahan ini agak bersifat organisasi. Aplikasi kami memiliki banyak pelanggan, dan mereka semua ingin menyelesaikannya sesegera mungkin. Sebelumnya, tidak mungkin melakukan hal ini secara paralel, dan semua pelanggan mengantri. Proses ini menyebabkan efek negatif pada bisnis, karena mereka perlu membuktikan bahwa tugas mereka berharga. Dan tim pengembangan menghabiskan waktu mengatur lineup ini. Ini membutuhkan banyak waktu dan usaha, dan produk sebagai hasilnya tidak dapat berubah secepat dari dia.
Penggunaan sumber daya yang tidak pantasSaat menempatkan layanan dalam satu proses, kami selalu sepenuhnya menyalin konfigurasi dari server ke server. Kami ingin menempatkan layanan yang paling banyak dimuat secara terpisah agar tidak menyia-nyiakan sumber daya dan mendapatkan manajemen skema penempatan yang lebih fleksibel.
Sulit untuk memperkenalkan teknologi modernMasalah yang umum bagi semua pengembang: ada keinginan untuk memperkenalkan teknologi modern ke dalam proyek, tetapi tidak ada kemungkinan. Dengan solusi monolitik besar, setiap pembaruan perpustakaan saat ini, belum lagi transisi ke yang baru, berubah menjadi tugas yang agak sepele. Butuh waktu lama untuk membuktikan kepada pemimpin tim bahwa itu akan membawa lebih banyak bonus daripada menghabiskan waktu.
Kesulitan mengeluarkan perubahanIni adalah masalah paling serius - kami mengeluarkan rilis setiap dua bulan.
Setiap rilis berubah menjadi bencana nyata bagi bank, terlepas dari pengujian dan upaya pengembang. Bisnis mengerti bahwa pada awal minggu beberapa fungsi tidak akan berfungsi untuknya. Dan para pengembang mengerti bahwa mereka sedang menunggu satu minggu insiden serius.
Setiap orang memiliki keinginan untuk mengubah situasi.
Harapan Layanan Mikro
Pengiriman komponen berdasarkan ketersediaan. Pengiriman komponen begitu tersedia karena dekomposisi solusi dan pemisahan berbagai proses.
Tim makanan kecil. Ini penting karena tim besar yang mengerjakan monolit lama sulit dikelola. Tim seperti itu dipaksa bekerja sesuai dengan proses yang ketat, tetapi saya menginginkan lebih banyak kreativitas dan kemandirian. Hanya tim kecil yang mampu membelinya.
Isolasi layanan dalam proses terpisah. Idealnya, saya ingin mengisolasi dalam wadah, tetapi sejumlah besar layanan yang ditulis dalam .NET Framework hanya berjalan di bawah Windows. Sekarang ada layanan di .NET Core, tetapi sejauh ini mereka sedikit.
Fleksibilitas Penempatan. Saya ingin menggabungkan layanan yang kami butuhkan, dan bukan sebagai kekuatan kode.
Penggunaan teknologi baru. Ini menarik bagi setiap programmer.
Masalah transisi
Tentu saja, jika itu sederhana untuk memecah monolith menjadi layanan microser, Anda tidak perlu membicarakannya di konferensi dan menulis artikel. Dalam proses ini, ada banyak jebakan, saya akan menggambarkan yang utama yang mengganggu kita.
Masalah pertama adalah tipikal kebanyakan monolit: koherensi logika bisnis. Ketika kami menulis monolith, kami ingin menggunakan kembali kelas kami agar tidak menulis kode tambahan. Dan ketika beralih ke layanan microser, ini menjadi masalah: semua kode terhubung cukup erat, dan sulit untuk memisahkan layanan.
Pada saat awal pekerjaan, repositori memiliki lebih dari 500 proyek dan lebih dari 700 ribu baris kode. Ini adalah solusi yang cukup besar dan
masalah kedua . Itu tidak mungkin untuk hanya mengambil dan membaginya menjadi layanan microser.
Masalah ketiga adalah kurangnya infrastruktur yang diperlukan. Bahkan, kami terlibat dalam menyalin kode sumber secara manual ke server.
Cara beralih dari monolith ke layanan microser
Alokasi Layanan MikroPertama, kami segera memutuskan untuk diri kami sendiri bahwa pemisahan layanan-layanan mikro adalah proses berulang. Kami selalu diminta untuk melakukan pengembangan tugas bisnis secara paralel. Bagaimana kita akan melakukan ini secara teknis sudah menjadi masalah kita. Oleh karena itu, kami sedang mempersiapkan proses berulang. Ini tidak akan bekerja secara berbeda jika Anda memiliki aplikasi besar, dan tidak siap untuk ditulis ulang dari awal.
Metode apa yang kami gunakan untuk mengisolasi layanan mikro?
Cara pertama adalah dengan mem-porting modul yang ada sebagai layanan. Dalam hal ini, kami beruntung: sudah ada layanan formal yang bekerja pada protokol WCF. Mereka diposting di majelis terpisah. Kami memindahkannya secara terpisah, menambahkan peluncur kecil ke setiap unit. Itu ditulis menggunakan perpustakaan Topshelf indah, yang memungkinkan Anda untuk menjalankan aplikasi baik sebagai layanan maupun sebagai konsol. Ini nyaman untuk debugging, karena tidak ada proyek tambahan yang diperlukan dalam solusi.
Layanan terhubung sesuai dengan logika bisnis, karena mereka menggunakan rakitan umum dan bekerja dengan database umum. Sulit untuk memanggil mereka layanan mikro dalam bentuk murni mereka. Namun demikian, kami dapat mengeluarkan layanan ini secara terpisah, dalam proses yang berbeda. Ini sudah memungkinkan untuk mengurangi pengaruh mereka satu sama lain, mengurangi masalah dengan pengembangan paralel dan satu titik kegagalan.
Membangun dengan host hanya satu baris kode di kelas Program. Kami menyembunyikan Topshelf di kelas pembantu.
namespace RBA.Services.Accounts.Host { internal class Program { private static void Main(string[] args) { HostRunner<Accounts>.Run("RBA.Services.Accounts.Host"); } } }
Cara kedua untuk mengisolasi layanan mikro: buat mereka untuk memecahkan masalah baru. Jika monolit tidak tumbuh pada saat yang sama, ini sudah sangat baik, yang berarti bahwa kita bergerak ke arah yang benar. Untuk mengatasi masalah baru, kami mencoba melakukan layanan terpisah. Jika ada peluang seperti itu, maka kami menciptakan lebih banyak layanan "kanonik" yang sepenuhnya mengendalikan model data mereka, sebuah basis data terpisah.
Kami, seperti banyak orang, mulai dengan layanan otentikasi dan otorisasi. Mereka sempurna untuk ini. Mereka independen, sebagai suatu peraturan, mereka memiliki model data yang terpisah. Mereka sendiri tidak berinteraksi dengan monolith, hanya dia berpaling kepada mereka untuk menyelesaikan beberapa masalah. Pada layanan ini, Anda dapat memulai transisi ke arsitektur baru, men-debug infrastruktur pada mereka, mencoba beberapa pendekatan yang berkaitan dengan perpustakaan jaringan, dll. Di organisasi kami, tidak ada tim yang tidak dapat membuat layanan otentikasi.
Cara ketiga untuk mengisolasi layanan microser yang kami gunakan sedikit spesifik untuk kami. Ini mengeluarkan logika bisnis dari lapisan UI. Kami memiliki aplikasi UI desktop utama, seperti backend, ditulis dalam C #. Pengembang secara berkala melakukan kesalahan dan dilakukan pada bagian UI dari logika yang seharusnya ada di backend dan digunakan kembali.
Jika Anda melihat contoh nyata dari kode bagian UI, Anda dapat melihat bahwa sebagian besar solusi ini berisi logika bisnis nyata, yang berguna dalam proses lain, tidak hanya untuk membangun formulir UI.
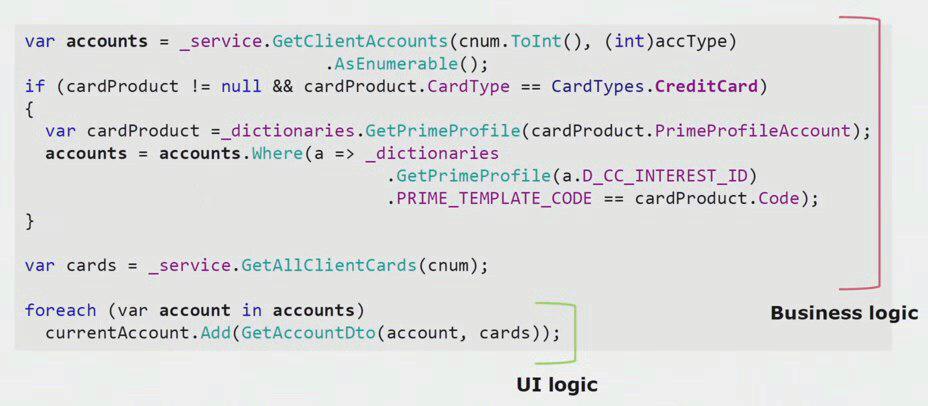
Logika UI sebenarnya hanya ada beberapa baris terakhir. Kami memindahkannya ke server sehingga kami dapat menggunakannya kembali, sehingga mengurangi UI dan mencapai arsitektur yang benar.
Cara keempat, yang paling penting untuk mengisolasi layanan mikro , yang memungkinkan Anda mengurangi monolit, adalah menghapus layanan yang ada dengan pemrosesan. Ketika kami mengeluarkan modul yang sudah ada, hasilnya tidak selalu menyenangkan bagi pengembang, dan proses bisnis sejak saat fungsi itu dibuat bisa menjadi usang. Berkat refactoring, kami dapat mendukung proses bisnis baru karena persyaratan bisnis terus berubah. Kami dapat meningkatkan kode sumber, menghapus cacat yang diketahui, membuat model data yang lebih baik. Ada banyak keuntungan.
Departemen layanan pemrosesan terkait erat dengan konsep konteks terbatas. Ini adalah konsep dari desain berorientasi subjek. Ini berarti bagian model domain di mana semua istilah dari satu bahasa didefinisikan secara unik. Pertimbangkan konteks asuransi dan tagihan sebagai contoh. Kami memiliki aplikasi monolitik, dan perlu untuk bekerja dengan akun di asuransi. Kami mengharapkan pengembang untuk menemukan kelas "Akun" yang ada di majelis lain, membuat tautan ke sana dari kelas "Asuransi", dan kami akan mendapatkan kode kerja. Prinsip KERING akan dihormati, tugas melalui penggunaan kode yang ada akan dilakukan lebih cepat.
Akibatnya, ternyata konteks akun dan asuransi terhubung. Ketika persyaratan baru muncul, koneksi ini akan mengganggu pengembangan, meningkatkan kompleksitas logika bisnis yang sudah kompleks. Untuk mengatasi masalah ini, Anda perlu menemukan batasan antara konteks dalam kode dan menghapus pelanggarannya. Misalnya, dalam konteks asuransi, sangat mungkin bahwa nomor rekening 20 digit dari Bank Sentral dan tanggal pembukaan rekening akan cukup.
Untuk memisahkan konteks terbatas ini satu sama lain dan memulai proses ekstraksi layanan mikro dari solusi monolitik, kami menggunakan pendekatan seperti membuat API eksternal dalam aplikasi. Jika kita tahu bahwa beberapa modul harus menjadi layanan mikro, entah bagaimana berubah dalam proses, maka kami segera membuat panggilan ke logika, yang termasuk dalam konteks terbatas lain, melalui panggilan eksternal. Misalnya melalui REST atau WCF.
Kami memutuskan sendiri bahwa kami tidak akan menghindari kode yang akan memerlukan transaksi terdistribusi. Dalam kasus kami, ternyata cukup mudah untuk mematuhi aturan ini. Kami masih belum menemukan situasi seperti itu ketika transaksi yang didistribusikan sangat dibutuhkan - konsistensi akhir antara modul cukup.
Pertimbangkan contoh spesifik. Kami memiliki konsep orkestra - konveyor, yang memproses esensi dari "aplikasi". Dia bergantian menciptakan pelanggan, akun, dan kartu bank. Jika klien dan akun berhasil dibuat, dan pembuatan kartu gagal, aplikasi tidak masuk ke status "berhasil" dan tetap dalam status "kartu tidak dibuat". Di masa depan, aktivitas latar belakang akan mengambilnya dan mengakhirinya. Sistem ini dalam keadaan tidak konsisten untuk beberapa waktu, tetapi ini, secara keseluruhan, cocok untuk kita.
Namun, jika suatu situasi muncul ketika akan diperlukan untuk secara konsisten menyimpan bagian dari data, kami kemungkinan besar akan memperbesar layanan untuk memproses ini dalam satu proses.
Mari kita perhatikan contoh alokasi layanan-mikro. Bagaimana bisa relatif aman dibawa ke produksi? Dalam contoh ini, kami memiliki bagian terpisah dari sistem - modul layanan gaji, salah satu bagian dari kode yang ingin kami buat layanan-mikro.
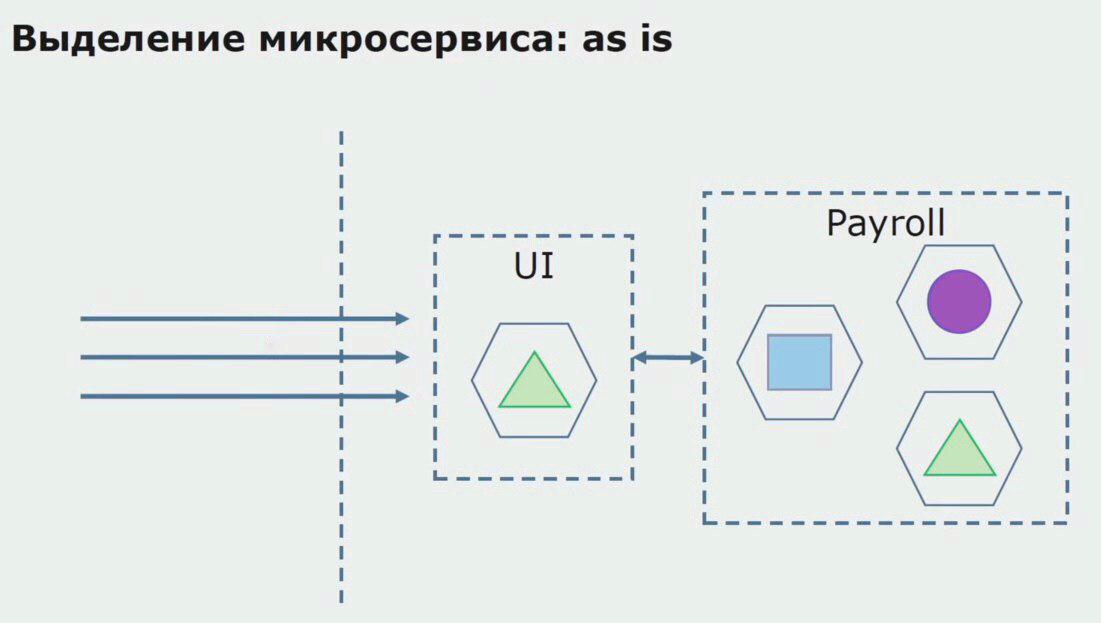
Pertama-tama, kami membuat microservice dengan menulis ulang kode. Kami meningkatkan beberapa poin yang tidak sesuai dengan kami. Kami menyadari persyaratan bisnis baru dari pelanggan. Kami menambah bundel antara UI dan backend Gateway API, yang akan menyediakan penerusan panggilan.
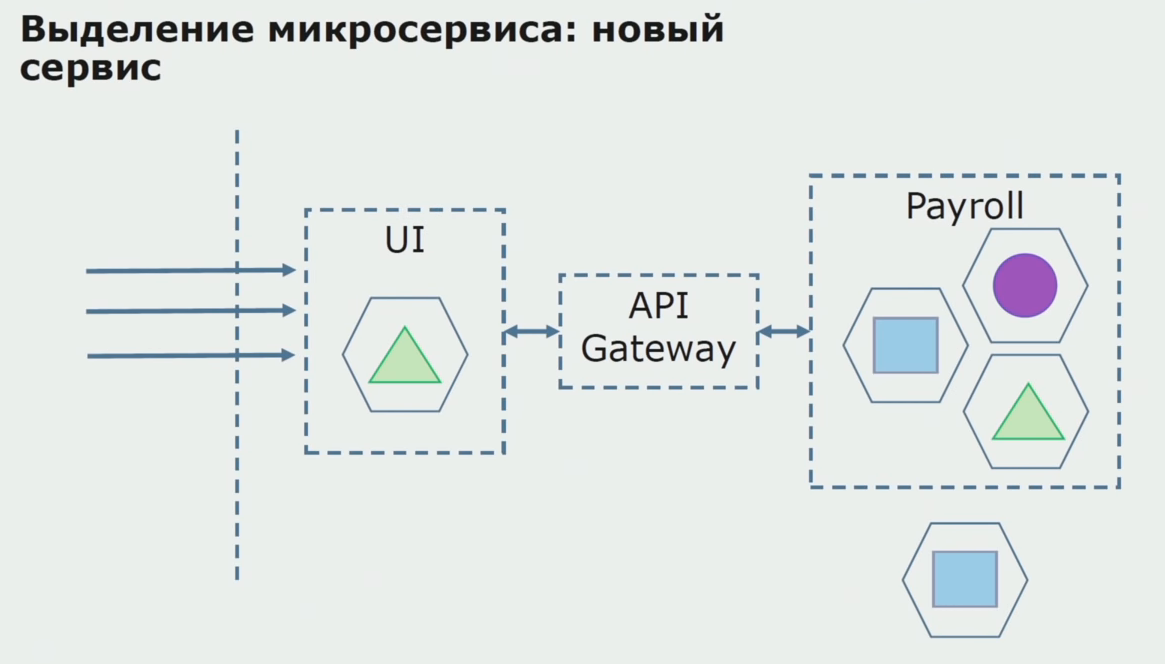
Selanjutnya, kami melepaskan konfigurasi ini ke dalam operasi, tetapi dalam keadaan pilot. Sebagian besar pengguna kami masih bekerja dengan proses bisnis lama. Untuk pengguna baru, kami sedang mengembangkan versi baru aplikasi monolitik yang proses ini tidak lagi mengandung. Bahkan, kami memiliki banyak layanan monolith dan microser yang bekerja dalam bentuk pilot.
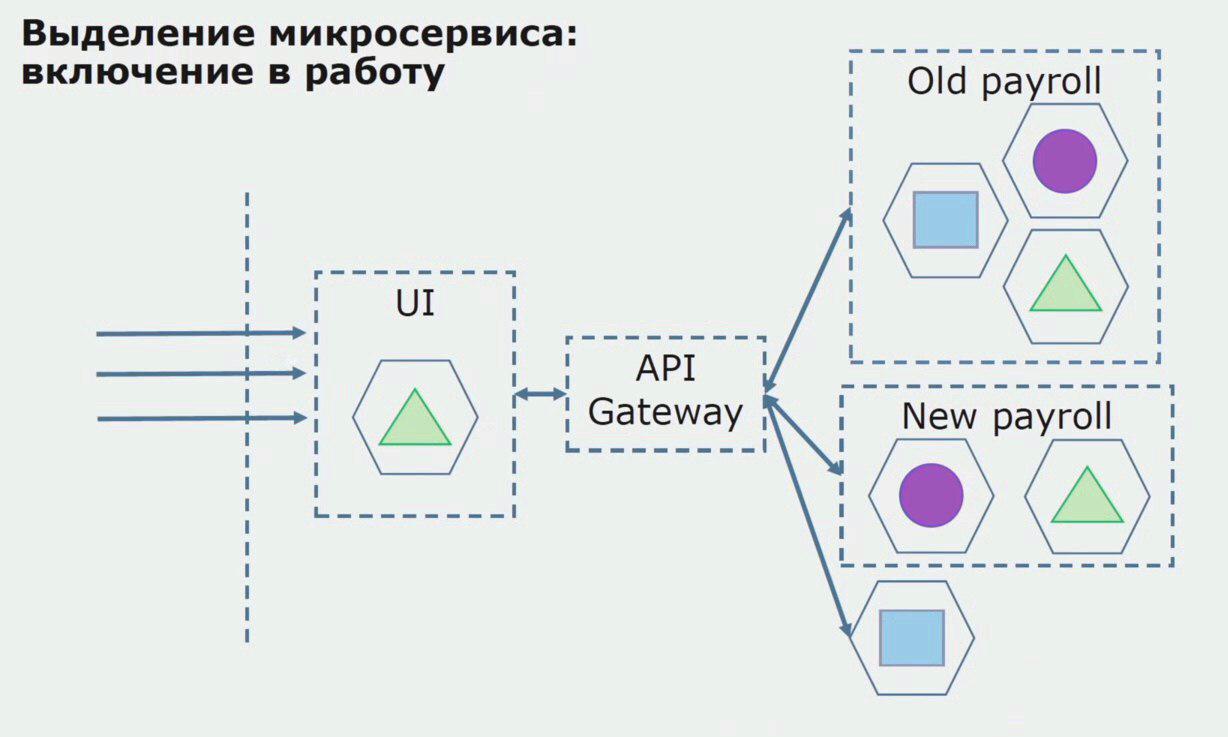
Dengan pilot yang sukses, kami memahami bahwa konfigurasi baru benar-benar operasional, kami dapat menghapus monolit lama dari persamaan dan meninggalkan konfigurasi baru di tempat solusi lama.
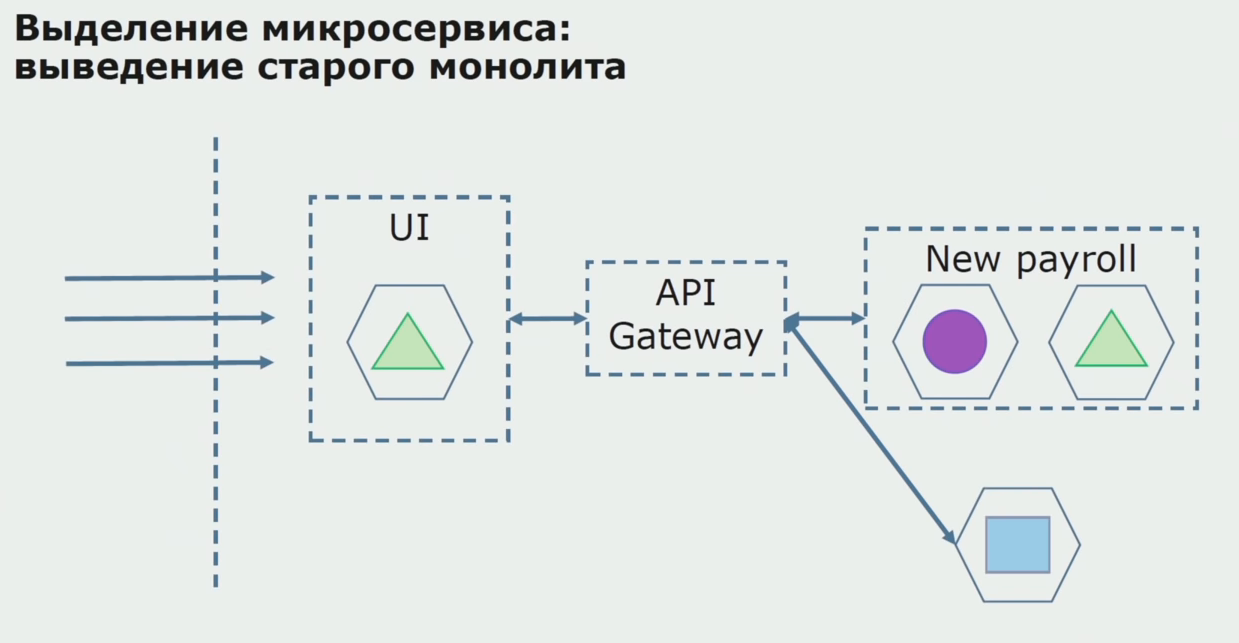
Secara total, kami menggunakan hampir semua metode yang ada untuk memisahkan kode sumber monolit. Semuanya memungkinkan kita untuk mengurangi ukuran bagian aplikasi dan mentransfernya ke perpustakaan baru, membuat kode sumber yang lebih baik.
Bekerja dengan DB
Basis data dapat dibagi lebih buruk daripada kode sumber, karena mengandung tidak hanya skema saat ini, tetapi juga akumulasi data historis.
Basis data kami, seperti banyak yang lainnya, memiliki kelemahan penting lainnya - ukurannya yang besar. Basis data ini dirancang sesuai dengan logika bisnis monolit yang rumit, dan tautan telah terakumulasi di antara tabel dari berbagai konteks terbatas.
Dalam kasus kami, untuk menyelesaikan semua masalah (database besar, banyak hubungan, kadang-kadang perbatasan tidak dapat dipahami antara tabel), masalah muncul di banyak proyek besar: menggunakan templat database bersama. Data diambil dari tabel melalui tampilan, melalui replikasi, dan dikirim ke sistem lain di mana replikasi ini diperlukan. Akibatnya, kami tidak dapat mengeluarkan tabel dalam skema terpisah, karena mereka digunakan secara aktif.
Pemisahan membantu kita untuk memecah menjadi konteks terbatas dalam kode. Ini biasanya memberi kita ide yang cukup bagus tentang bagaimana kita memecah data di tingkat basis data. Kami memahami tabel mana yang terkait dengan satu konteks terbatas dan yang terkait dengan yang lain.
Kami menerapkan dua cara global untuk mempartisi basis data: mempartisi tabel yang ada dan mempartisi dengan pemrosesan.
Pemisahan tabel yang ada adalah metode yang baik untuk digunakan jika struktur data berkualitas tinggi, memenuhi persyaratan bisnis dan cocok untuk semua orang. Dalam hal ini, kita bisa memilih tabel yang ada dalam skema terpisah.
Departemen pemrosesan diperlukan ketika model bisnis telah banyak berubah dan tabel tidak lagi sepenuhnya memuaskan kita.
Pisahkan tabel yang ada. Kita perlu menentukan apa yang akan kita pisahkan. Tanpa pengetahuan ini, tidak akan ada yang muncul darinya, dan di sini pemisahan konteks terbatas dalam kode akan membantu kita. Sebagai aturan, jika dimungkinkan untuk memahami batas-batas konteks dalam kode sumber, menjadi jelas tabel mana yang harus dimasukkan dalam daftar untuk pemisahan.
Bayangkan kita memiliki solusi di mana dua modul monolith berinteraksi dengan satu basis data. Kita perlu memastikan bahwa hanya satu modul yang berinteraksi dengan bagian dari tabel yang terpisah, dan yang lainnya mulai berinteraksi dengannya melalui API. Sebagai permulaan, cukup hanya entri yang dibuat melalui API. Ini adalah kondisi yang diperlukan agar kita dapat berbicara tentang independensi layanan-layanan mikro. Link membaca dapat tetap ada sampai ada masalah besar.

Sebagai langkah selanjutnya, kita sudah dapat memilih bagian kode yang bekerja dengan tabel yang dapat dilepas dengan atau tanpa memproses ke dalam layanan mikro terpisah dan menjalankannya dalam proses terpisah, wadah. Ini akan menjadi layanan terpisah dengan komunikasi dengan database monolith dan tabel-tabel yang tidak terkait langsung dengannya. Monolith masih berinteraksi dengan bagian yang bisa dilepas untuk membaca.

Nanti kita akan menghapus koneksi ini, yaitu, membaca data aplikasi monolitik dari tabel yang terpisah juga akan ditransfer ke API.
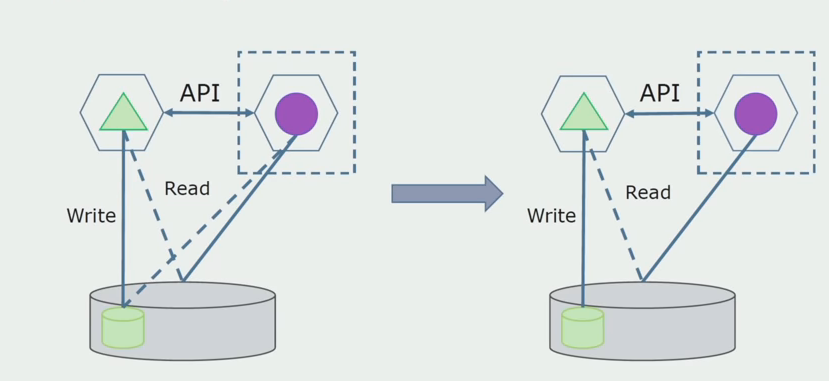
Selanjutnya, kami memilih dari database umum tabel yang hanya berfungsi dengan layanan microservice baru. Kita dapat menempatkan tabel dalam skema terpisah atau bahkan dalam database fisik terpisah. Ada koneksi untuk membaca antara microservice dan database monolith, tetapi tidak ada yang perlu dikhawatirkan, dalam konfigurasi ini dapat hidup untuk waktu yang lama.
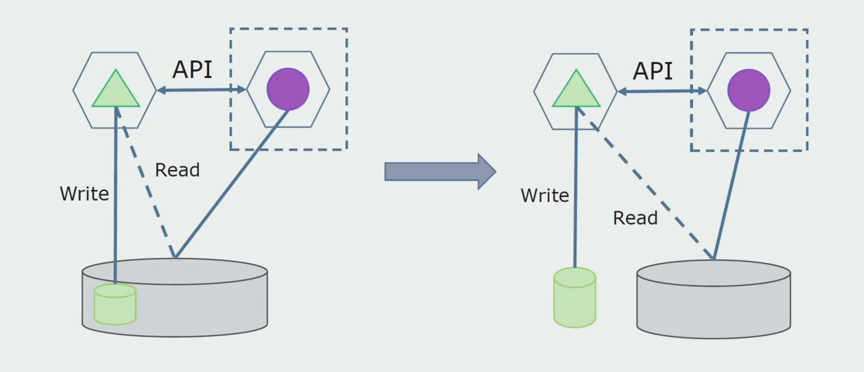
Langkah terakhir adalah sepenuhnya menghapus semua koneksi. Dalam hal ini, kami mungkin perlu memigrasikan data dari basis data utama. Terkadang kami ingin menggunakan kembali dalam beberapa database beberapa data atau direktori yang direplikasi dari sistem eksternal. Kami secara berkala bertemu ini.
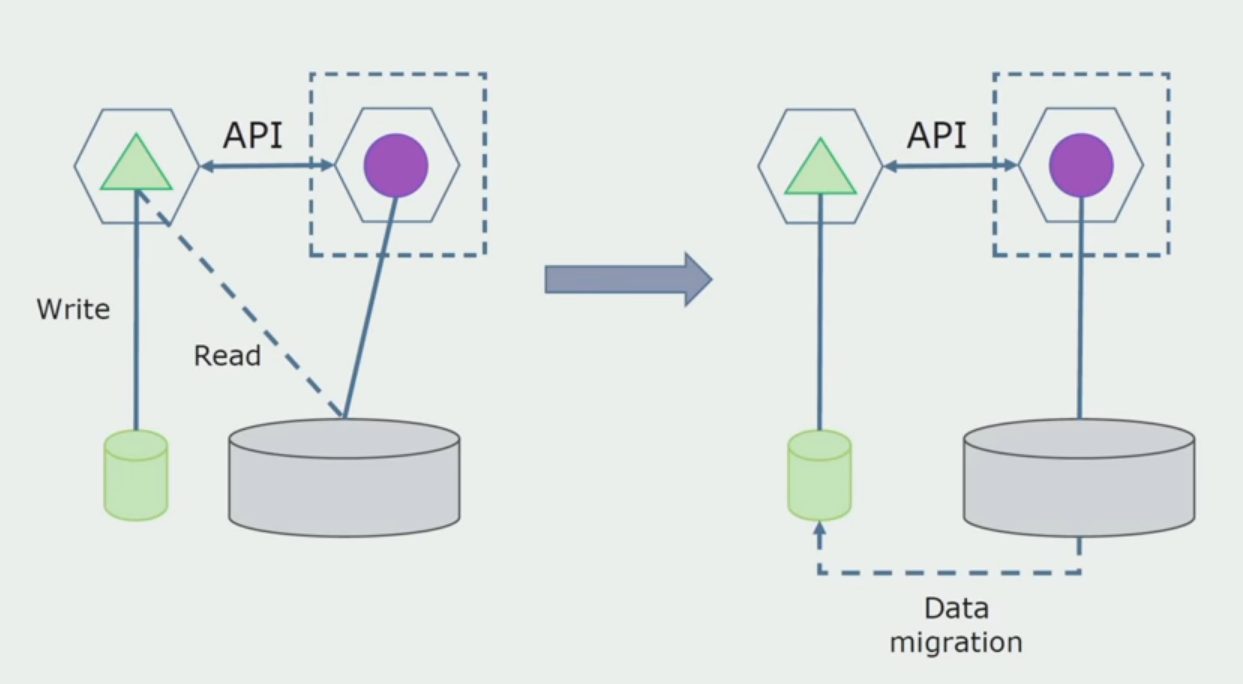 Departemen pengolahan.
Departemen pengolahan. Metode ini sangat mirip dengan yang pertama, hanya berjalan dalam urutan terbalik. Kami segera memiliki database baru dan layanan microser baru yang berinteraksi dengan monolith melalui API. Tetapi pada saat yang sama, masih ada satu set tabel database yang ingin kita hapus di masa depan. Kami tidak lagi membutuhkannya, dalam model baru kami menggantinya.
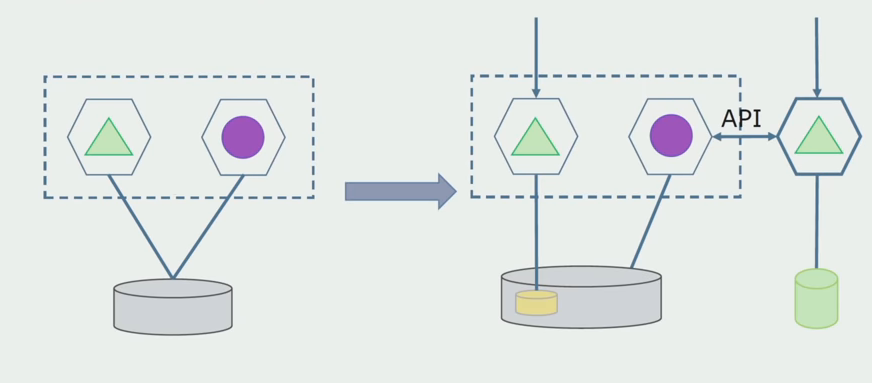
Agar skema ini berfungsi, kemungkinan besar kita akan membutuhkan masa transisi.
Ada dua pendekatan yang mungkin.
Pertama : kami menduplikasi semua data dalam database baru dan lama. Dalam hal ini, kami memiliki redundansi data, mungkin ada masalah dengan sinkronisasi. Tetapi kemudian kita dapat mengambil dua pelanggan yang berbeda. Satu akan bekerja dengan versi baru, yang lain dengan yang lama.
Kedua : kami berbagi data sesuai dengan beberapa karakteristik bisnis. Misalnya, dalam sistem kami ada 5 produk yang disimpan dalam database lama. Keenam sebagai bagian dari tugas bisnis baru, kami memasukkan basis data baru. Tetapi kami membutuhkan Gateway API, yang menyinkronkan data ini dan menunjukkan kepada klien ke mana dan apa yang harus diambil.
Kedua pendekatan itu berfungsi, pilih sesuai situasi.
Setelah kami memastikan bahwa semuanya berfungsi, bagian dari monolith yang berfungsi dengan struktur basis data lama dapat dinonaktifkan.
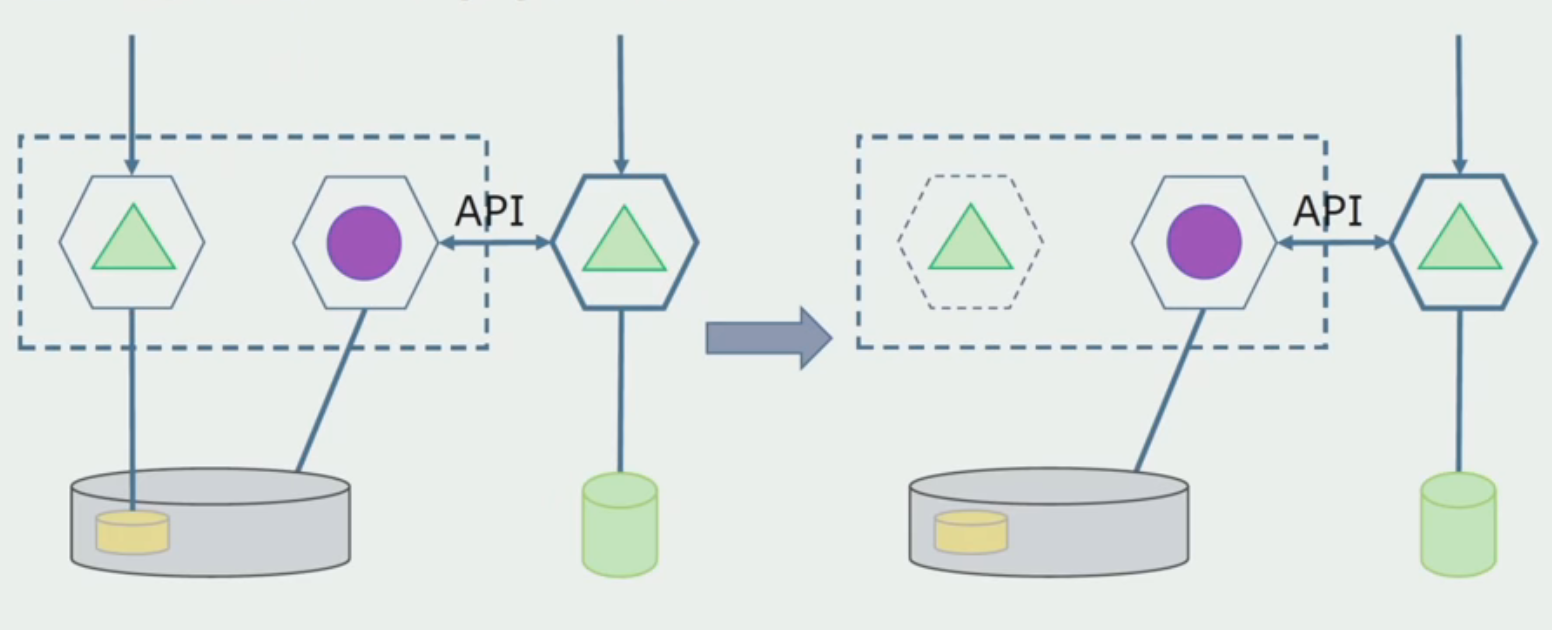
Langkah terakhir adalah menghapus struktur data lama.

Kesimpulannya, kita dapat mengatakan bahwa kita memiliki masalah dengan database: sulit untuk bekerja dengannya dibandingkan dengan kode sumber, lebih sulit untuk dipisahkan, tetapi ini dapat dan harus dilakukan. Kami menemukan beberapa cara yang memungkinkan ini dilakukan dengan cukup aman, namun lebih mudah untuk membuat kesalahan dengan data daripada dengan kode sumber.
Bekerja dengan kode sumber
Di sinilah diagram kode sumber terlihat ketika kami mulai menganalisis proyek monolitik.

Secara kondisional dapat dibagi menjadi tiga lapisan. Ini adalah lapisan modul, plugin, layanan, dan aktivitas individual yang diluncurkan. Bahkan, ini adalah titik masuk dalam solusi monolitik. Mereka semua terikat erat dengan lapisan Common. Itu logika bisnis yang dibagi antara layanan, dan banyak koneksi. Setiap layanan dan plugin menggunakan hingga 10 atau lebih rakitan umum, tergantung pada ukuran dan hati nurani para pengembang.
Kami beruntung, kami memiliki perpustakaan infrastruktur yang dapat digunakan secara terpisah.
Kadang-kadang situasi muncul ketika beberapa objek umum tidak benar-benar milik lapisan ini, tetapi perpustakaan infrastruktur. Ini diputuskan dengan mengganti nama.
Paling prihatin dengan konteks terbatas. Dulu bahwa 3-4 konteks dicampur bersama dalam satu perakitan umum dan digunakan satu sama lain dalam fungsi bisnis yang sama. Itu perlu untuk memahami di mana ini dapat dibagi dan pada batas apa, dan apa yang harus dilakukan selanjutnya dengan memetakan pemisahan ini ke dalam kumpulan kode sumber.
Kami telah merumuskan beberapa aturan untuk proses pemisahan kode.
Pertama : kami tidak lagi ingin berbagi logika bisnis antara layanan, aktivitas, dan plugin. Mereka ingin membuat logika bisnis independen dalam kerangka kerja layanan mikro. Di sisi lain, layanan microser, dalam kasus ideal, dianggap sebagai layanan yang ada sepenuhnya secara independen. Saya percaya bahwa pendekatan ini agak boros, dan sulit untuk mencapainya, karena, misalnya, layanan di C # dalam hal apapun akan dihubungkan oleh perpustakaan standar. Sistem kami ditulis dalam C #, teknologi lain belum digunakan. Oleh karena itu, kami memutuskan bahwa kami dapat menggunakan majelis teknis umum. Yang utama adalah mereka tidak memiliki fragmen logika bisnis. Jika Anda memiliki pembungkus yang nyaman untuk ORM yang Anda gunakan, maka menyalinnya dari layanan ke layanan sangat mahal.
Tim kami adalah penggemar desain berorientasi subjek, sehingga "arsitektur bawang" sangat cocok untuk kami. Dasar dalam layanan kami bukan lapisan akses data, tetapi perakitan dengan logika domain, yang hanya berisi logika bisnis dan tanpa koneksi infrastruktur. Pada saat yang sama, kami dapat memodifikasi perakitan domain secara independen untuk menyelesaikan masalah yang terkait dengan kerangka kerja.
Pada tahap ini, kami bertemu dengan masalah serius pertama. Layanan ini seharusnya merujuk pada satu perakitan domain, kami ingin membuat logika independen, dan di sini prinsip KERING sangat mengganggu kami. Untuk menghindari duplikasi, pengembang ingin menggunakan kembali kelas dari majelis tetangga, dan sebagai hasilnya, domain mulai berkomunikasi satu sama lain lagi. Kami menganalisis hasilnya dan memutuskan bahwa mungkin masalahnya juga terletak pada area perangkat penyimpanan kode sumber. Kami memiliki repositori besar tempat semua kode sumber diletakkan. Solusi untuk seluruh proyek sangat sulit untuk dirakit pada mesin lokal. Oleh karena itu, solusi kecil yang terpisah dibuat untuk bagian-bagian proyek, dan tidak ada yang melarang menambahkan perakitan umum atau domain untuk mereka dan menggunakannya kembali. Satu-satunya alat yang tidak memungkinkan kami melakukan ini adalah kode ulasan. Tapi terkadang dia juga jatuh.
Kemudian kami mulai beralih ke model dengan repositori terpisah. Logika bisnis telah berhenti mengalir dari layanan ke layanan, domain telah benar-benar menjadi mandiri. Konteks terbatas didukung lebih jelas. Bagaimana kami menggunakan kembali perpustakaan infrastruktur? Kami mengalokasikannya ke repositori terpisah, lalu menempatkannya di paket Nuget yang kami masukkan ke Artifactory. Dengan perubahan apa pun, perakitan dan publikasi terjadi secara otomatis.
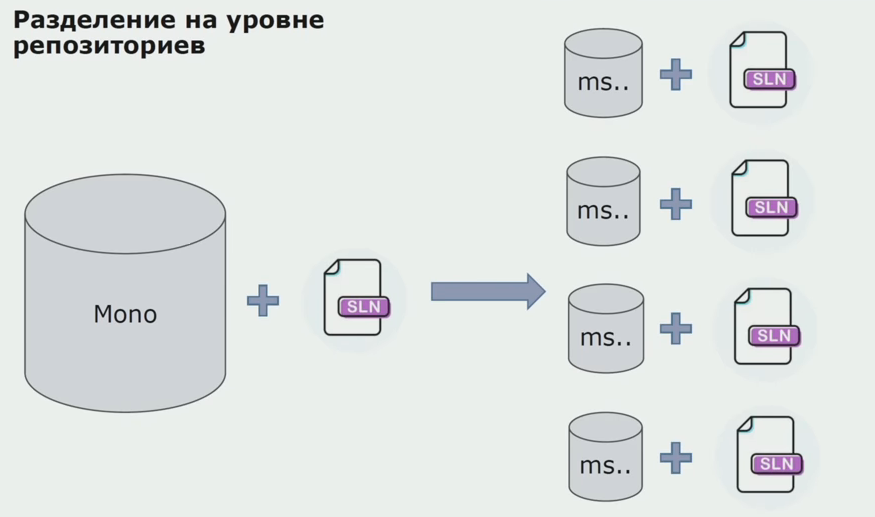
Layanan kami mulai merujuk pada paket infrastruktur internal dengan cara yang sama dengan yang eksternal. Kami mengunduh perpustakaan eksternal dari Nuget. Untuk bekerja dengan Artifactory, tempat kami meletakkan paket-paket ini, kami menggunakan dua manajer paket. Di repositori kecil, kami juga menggunakan Nuget. Dalam repositori dengan beberapa layanan, kami menggunakan Paket, yang menyediakan lebih banyak konsistensi versi antar modul.
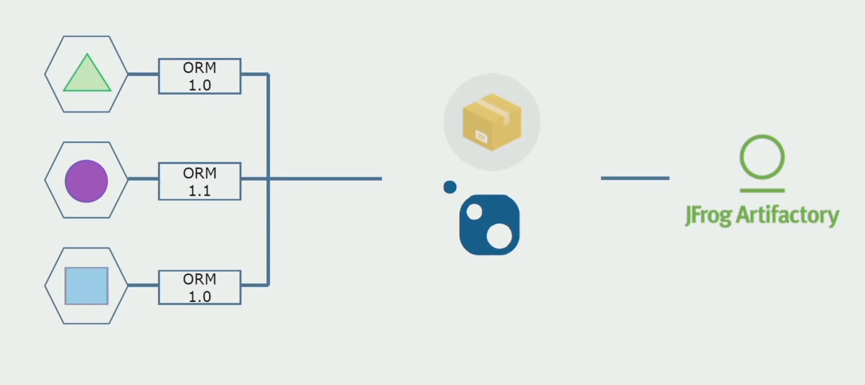
Dengan demikian, bekerja pada kode sumber, sedikit mengubah arsitektur dan berbagi repositori, kami membuat layanan kami lebih mandiri.
Masalah infrastruktur
Sebagian besar kerugian untuk beralih ke layanan-layanan mikro terkait dengan infrastruktur. Anda akan membutuhkan penyebaran otomatis, Anda akan memerlukan perpustakaan baru untuk infrastruktur.
Instalasi manual di lingkunganAwalnya, kami menginstal solusi pada lingkungan secara manual. Untuk mengotomatiskan proses ini, kami membuat pipa CI / CD. Kami memilih proses pengiriman berkelanjutan, karena penyebaran berkelanjutan bagi kami belum dapat diterima dari sudut pandang proses bisnis. Oleh karena itu, pengiriman ke operasi dilakukan oleh tombol, dan untuk pengujian - secara otomatis.
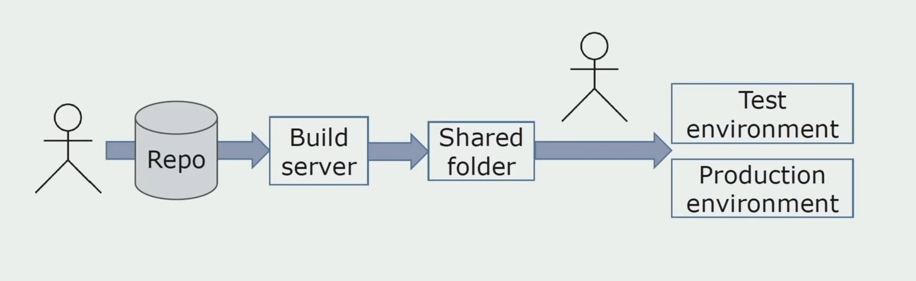
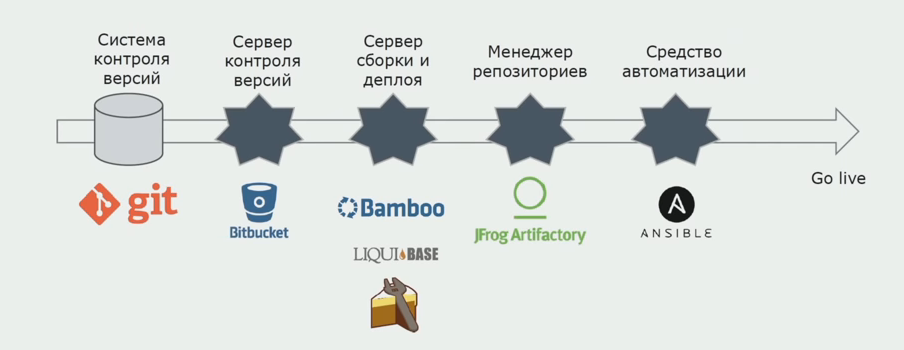
Kami menggunakan Atlassian, Bitbucket untuk menyimpan kode sumber, dan Bamboo untuk perakitan. Kami suka menulis skrip perakitan dalam Cake karena C # yang sama. Paket yang sudah jadi datang ke Artifactory, dan Ansible secara otomatis sampai ke server pengujian, setelah itu mereka dapat segera diuji.
Logging terpisah
Pada suatu waktu, salah satu ide dari monolith adalah ketentuan penebangan bersama. Kami juga perlu memahami apa yang harus dilakukan dengan log individual yang ada di disk. Log ditulis kepada kami dalam file teks. Kami memutuskan untuk menggunakan tumpukan ELK standar. Kami tidak menulis langsung ke ELK melalui penyedia, tetapi memutuskan bahwa kami akan menyelesaikan log teks dan menuliskan ID jejak di dalamnya sebagai pengidentifikasi, menambahkan nama layanan sehingga log ini kemudian dapat diuraikan.

Menggunakan Filebeat, kami mendapat kesempatan untuk mengumpulkan log dari server, lalu mengonversinya, menggunakan Kibana untuk membuat permintaan di UI dan menonton bagaimana panggilan antar layanan. ID jejak sangat membantu dalam hal ini.
Menguji dan men-debug layanan terkait
Awalnya, kami tidak sepenuhnya memahami cara men-debug layanan yang dikembangkan. Semuanya sederhana dengan monolith, kami menjalankannya di mesin lokal. Pada awalnya, mereka mencoba melakukan hal yang sama dengan layanan microser, tetapi kadang-kadang untuk sepenuhnya meluncurkan satu layanan microser, Anda perlu memulai beberapa yang lain, yang tidak nyaman. , , , . , prod. , , . , , .
, production- . , .
Specflow. NUnit Ansible. , . - . , , Jira.
, . JMeter, — InfluxDB, — Grafana.
?
-, «». , production-, -. 1,5 , , .
. , , . .
. , .
, . , . Scrum-. , .
- . , , , . .
- . , , . , , , Scrum.
- — . . . legacy, , .
: . . , , , , , , , — , . . , , .
PS ( ) – .
.