Setiap sistem pemantauan menghadapi tiga jenis masalah kinerja.
Pertama, sistem pemantauan yang baik harus sangat cepat menerima, memproses, dan mencatat data yang datang dari luar. Akun pergi ke mikrodetik. Begitu saja, ini mungkin tampak tidak jelas, tetapi ketika sistem menjadi cukup besar, semua fraksi detik ini disimpulkan, berubah menjadi penundaan yang jelas terlihat.

Tugas kedua adalah menyediakan akses mudah ke array besar metrik yang sebelumnya dikumpulkan (dengan kata lain, ke data historis). Data historis digunakan dalam berbagai konteks. Misalnya, laporan dan grafik dihasilkan darinya, pemeriksaan agregat dibuat atasnya, pemicu bergantung padanya. Jika ada keterlambatan dalam mengakses histori, maka ini segera mempengaruhi kecepatan keseluruhan sistem secara keseluruhan.
Ketiga, data historis membutuhkan banyak ruang. Bahkan konfigurasi pemantauan yang relatif sederhana sangat cepat memperoleh sejarah yang solid. Tetapi hampir tidak ada orang yang ingin menyimpan sejarah memuat prosesor yang berusia lima tahun, sehingga sistem pemantauan tidak hanya dapat merekam dengan baik, tetapi juga menghapus riwayat dengan baik (dalam Zabbix proses ini disebut "housekeeping"). Menghapus data lama tidak harus seefisien mengumpulkan dan menganalisis data baru, tetapi operasi penghapusan yang berat menggunakan sumber daya DBMS yang berharga dan dapat memperlambat operasi yang lebih kritis.
Dua masalah pertama diselesaikan dengan caching. Zabbix mendukung beberapa cache khusus untuk mempercepat operasi baca dan tulis data. Mekanisme DBMS sendiri tidak cocok di sini, karena bahkan algoritma caching tujuan umum yang paling canggih tidak akan tahu struktur data mana yang membutuhkan akses instan pada titik waktu tertentu.
Pemantauan dan Data Rangkaian Waktu
Semuanya baik-baik saja selama data ada di memori server Zabbix. Tetapi memori tidak terbatas dan pada titik tertentu data perlu ditulis (atau dibaca) ke database. Dan jika kinerja database secara serius di belakang kecepatan pengumpulan metrik, maka bahkan algoritma caching khusus yang paling canggih tidak akan membantu untuk waktu yang lama.
Masalah ketiga juga datang ke kinerja database. Untuk mengatasinya, Anda harus memilih strategi penghapusan yang andal yang tidak akan mengganggu operasi basis data lainnya. Secara default, Zabbix menghapus data historis dalam kumpulan beberapa ribu catatan per jam. Anda dapat mengonfigurasi periode pembersihan yang lebih lama atau ukuran paket yang lebih besar jika kecepatan pengumpulan data dan tempat dalam basis data memungkinkannya. Tetapi dengan jumlah metrik yang sangat besar dan / atau frekuensi pengumpulan yang tinggi, pengaturan tata graha yang tepat bisa menjadi tugas yang menakutkan, karena jadwal penghapusan data mungkin tidak mengikuti laju perekaman yang baru.
Meringkas, sistem pemantauan memecahkan masalah kinerja dalam tiga arah - mengumpulkan data baru dan menulisnya ke database menggunakan query SQL INSERT, mengakses data menggunakan query SELECT, dan menghapus data menggunakan DELETE. Mari kita lihat bagaimana query SQL khas dieksekusi:
- DBMS menganalisis kueri dan memeriksanya untuk kesalahan sintaksis. Jika permintaan secara sintaksis benar, maka mesin membangun pohon sintaks untuk diproses lebih lanjut.
- Perencana permintaan menganalisis pohon sintaks dan menghitung berbagai cara (jalur) untuk mengeksekusi permintaan.
- Penjadwal menghitung cara termurah. Dalam prosesnya, ini memperhitungkan banyak hal - seberapa besar tabelnya, apakah perlu mengurutkan hasilnya, apakah ada indeks yang berlaku untuk kueri, dll.
- Ketika jalur optimal ditemukan, mesin menjalankan kueri dengan mengakses blok data yang diinginkan (menggunakan indeks atau pemindaian berurutan), menerapkan kriteria pemilahan dan pemfilteran, mengumpulkan hasilnya dan mengembalikannya ke klien.
- Untuk memasukkan, memodifikasi, dan menghapus kueri, mesin juga harus memperbarui indeks untuk tabel terkait. Untuk tabel besar, operasi ini mungkin memakan waktu lebih lama daripada bekerja dengan data itu sendiri.
- Kemungkinan besar, DBMS juga akan memperbarui statistik internal penggunaan data untuk panggilan selanjutnya ke penjadwal permintaan.
Secara umum, ada banyak pekerjaan. Sebagian besar DBMS menyediakan banyak pengaturan untuk optimasi kueri, tetapi biasanya berfokus pada beberapa alur kerja rata-rata di mana memasukkan dan menghapus catatan terjadi pada frekuensi yang sama dengan perubahan.
Namun, seperti yang disebutkan di atas, untuk sistem pemantauan, operasi yang paling umum adalah penambahan dan penghapusan periodik dalam mode batch. Mengubah data yang ditambahkan sebelumnya hampir tidak pernah terjadi, dan mengakses data melibatkan penggunaan fungsi agregat. Selain itu, biasanya nilai metrik yang ditambahkan dipesan berdasarkan waktu. Data seperti itu biasa disebut sebagai
deret waktu :
Rangkaian waktu adalah serangkaian titik data yang diindeks (atau terdaftar atau grafiti) dalam urutan sementara.
Dari sudut pandang basis data, seri waktu memiliki properti berikut:
- Rangkaian waktu dapat ditemukan pada disk sebagai urutan blok waktu yang dipesan.
- Tabel seri waktu dapat diindeks menggunakan kolom waktu.
- Sebagian besar query SQL SELECT akan menggunakan klausa WHERE, GROUP BY, atau ORDER BY pada kolom yang menunjukkan waktu.
- Biasanya, data deret waktu memiliki "tanggal kedaluwarsa" setelah itu dapat dihapus.
Jelas, database SQL tradisional tidak cocok untuk menyimpan data seperti itu, karena optimasi tujuan umum tidak memperhitungkan kualitas-kualitas ini. Oleh karena itu, dalam beberapa tahun terakhir, beberapa DBMS baru dan berorientasi waktu telah muncul, seperti, misalnya, InfluxDB. Tetapi semua DBMS populer untuk time series memiliki satu kelemahan signifikan - kurangnya dukungan SQL penuh. Selain itu, kebanyakan dari mereka bahkan bukan CRUD (Buat, Baca, Perbarui, Hapus).
Bisakah Zabbix menggunakan DBMS ini dengan cara apa pun? Salah satu pendekatan yang mungkin adalah mentransfer data historis untuk penyimpanan ke database eksternal yang dikhususkan dalam seri waktu. Mengingat bahwa arsitektur Zabbix mendukung backend eksternal untuk menyimpan data historis (misalnya, dukungan Elasticsearch diimplementasikan dalam Zabbix), sekilas opsi ini terlihat sangat masuk akal. Tetapi jika kami mendukung satu atau beberapa DBMS untuk deret waktu sebagai server eksternal, maka pengguna harus memperhitungkan poin-poin berikut:
- Sistem lain yang perlu dieksplorasi, dikonfigurasi dan dipelihara. Tempat lain untuk melacak pengaturan, ruang disk, kebijakan penyimpanan, kinerja, dll.
- Mengurangi toleransi kesalahan sistem pemantauan, seperti tautan baru muncul di rantai komponen terkait.
Untuk beberapa pengguna, manfaat penyimpanan khusus untuk data historis mungkin lebih penting daripada ketidaknyamanan karena harus khawatir tentang sistem lain. Tetapi bagi banyak orang, ini adalah komplikasi yang tidak perlu. Perlu juga diingat bahwa karena sebagian besar solusi khusus ini memiliki API mereka sendiri, kompleksitas lapisan universal untuk bekerja dengan basis data Zabbix akan meningkat secara nyata. Dan kami, idealnya, lebih memilih untuk membuat fungsi-fungsi baru, daripada melawan API lain.
Muncul pertanyaan - apakah ada cara untuk mengambil keuntungan dari DBMS untuk deret waktu, tetapi tanpa kehilangan fleksibilitas dan kelebihan SQL? Secara alami, jawaban universal tidak ada, tetapi satu solusi spesifik sangat dekat dengan jawaban -
TimescaleDB .
Apa itu TimescaleDB?
TimescaleDB (TSDB) adalah ekstensi PostgreSQL yang mengoptimalkan pekerjaan dengan deret waktu dalam database PostgreSQL (PG) biasa. Meskipun, seperti yang disebutkan di atas, tidak ada kekurangan solusi time series yang dapat diskalakan dengan baik di pasar, fitur unik TimescaleDB adalah kemampuannya untuk bekerja dengan baik dengan deret waktu tanpa mengorbankan kompatibilitas dan manfaat dari database relasional CRUD tradisional. Dalam praktiknya, ini berarti kita mendapatkan yang terbaik dari kedua dunia. Basis data tahu tabel mana yang harus dianggap sebagai deret waktu (dan menerapkan semua optimasi yang diperlukan), tetapi Anda bisa bekerja dengannya dengan cara yang sama seperti dengan tabel biasa. Selain itu, aplikasi tidak diperlukan untuk mengetahui bahwa data dikontrol oleh TSDB!
Untuk menandai tabel sebagai tabel seri waktu (dalam TSDB ini disebut hipertensi), cukup panggil prosedur create_ hypertable () TSDB. Di bawah tenda, TSDB membagi tabel ini menjadi apa yang disebut fragmen (istilah bahasa Inggris adalah chunk) sesuai dengan kondisi yang ditentukan. Fragmen dapat direpresentasikan sebagai bagian tabel yang dikontrol secara otomatis. Setiap fragmen memiliki rentang waktu yang sesuai. Untuk setiap fragmen, TSDB juga menetapkan indeks khusus sehingga bekerja dengan satu rentang data tidak memengaruhi akses ke yang lain.
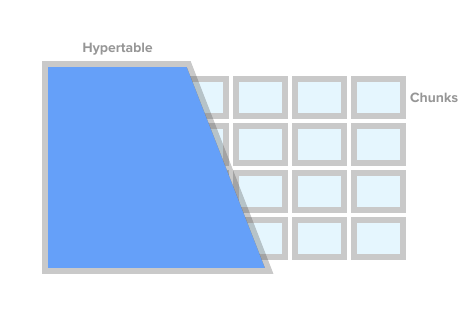 Gambar Hipertable dari timescaledb.com
Gambar Hipertable dari timescaledb.comSaat aplikasi menambahkan nilai baru untuk deret waktu, ekstensi mengarahkan nilai ini ke fragmen yang diinginkan. Jika rentang waktu nilai baru tidak ditentukan, maka TSDB akan membuat fragmen baru, menetapkan rentang yang diinginkan dan memasukkan nilai di sana. Jika aplikasi meminta data dari hipertensi, maka sebelum menjalankan permintaan, ekstensi memeriksa fragmen mana yang terkait dengan permintaan ini.
Tapi itu belum semuanya. TSDB melengkapi ekosistem PostgreSQL yang tangguh dan teruji waktu dengan sejumlah perubahan kinerja dan skalabilitas. Ini termasuk penambahan cepat dari catatan baru, permintaan waktu cepat dan penghapusan batch yang hampir gratis.
Seperti disebutkan sebelumnya, untuk mengontrol ukuran basis data dan mematuhi kebijakan penyimpanan (mis. Jangan menyimpan data lebih lama dari yang diperlukan), solusi pemantauan yang baik harus secara efektif menghapus sejumlah besar data historis. Dengan TSDB, kita dapat menghapus cerita yang diinginkan hanya dengan menghapus fragmen tertentu dari hipertensi. Dalam hal ini, aplikasi tidak perlu melacak fragmen dengan nama atau tautan lain, TSDB akan menghapus semua fragmen yang diperlukan sesuai dengan kondisi waktu yang ditentukan.
TimescaleDB dan PostgreSQL Partitioning
Sekilas, mungkin terlihat bahwa TSDB adalah pembungkus yang bagus di sekitar partisi standar tabel PG (
partisi deklaratif , seperti yang secara resmi disebut dalam PG10). Memang, untuk menyimpan data historis, Anda dapat menggunakan PG10 partisi standar. Tetapi jika Anda melihat lebih dekat, fragmen dari TSDB dan bagian PG10 jauh dari konsep yang identik.
Untuk mulai dengan, menyiapkan partisi di PG membutuhkan pemahaman yang lebih dalam tentang detail, yang harus dilakukan oleh aplikasi itu sendiri atau DBMS dengan cara yang baik. Pertama, Anda perlu merencanakan hierarki bagian Anda dan memutuskan apakah akan menggunakan partisi bersarang. Kedua, Anda harus membuat skema penamaan bagian dan mentransfernya ke skrip untuk membuat skema. Kemungkinan besar, skema penamaan akan mencakup tanggal dan / atau waktu, dan nama-nama tersebut perlu diotomatisasi entah bagaimana.
Selanjutnya, Anda perlu memikirkan cara menghapus data kadaluarsa. Di TSDB, Anda cukup memanggil perintah drop_chunks (), yang menentukan fragmen yang akan dihapus untuk jangka waktu tertentu. Di PG10, jika Anda perlu menghapus rentang nilai tertentu dari bagian PG standar, Anda harus menghitung sendiri daftar nama bagian untuk rentang ini. Jika skema partisi yang dipilih melibatkan bagian bersarang, ini semakin memperumit penghapusan.
Masalah lain yang perlu diatasi adalah apa yang harus dilakukan dengan data yang melampaui rentang waktu saat ini. Misalnya, data mungkin berasal dari masa depan yang bagian-bagiannya belum dibuat. Atau dari masa lalu untuk bagian yang sudah dihapus. Secara default di PG10, menambahkan catatan seperti itu tidak akan berfungsi dan kami hanya akan kehilangan data. Di PG11, Anda dapat menentukan bagian default untuk data tersebut, tetapi ini hanya sementara menutupi masalah, dan tidak menyelesaikannya.
Tentu saja, semua masalah di atas dapat diselesaikan dengan satu atau lain cara. Anda dapat menggantung pangkalan dengan pemicu, cron-jab dan taburi secara bebas dengan skrip. Itu akan jelek, tapi fungsional. Tidak ada keraguan bahwa bagian PG lebih baik daripada tabel monolitik raksasa, tetapi apa yang pasti tidak diselesaikan melalui skrip dan pemicu adalah peningkatan deret waktu yang tidak dimiliki PG.
Yaitu Dibandingkan dengan bagian PG, hipertensi TSDB dibedakan dengan baik tidak hanya dengan menyelamatkan saraf administrator DB, tetapi juga dengan mengoptimalkan akses ke data dan menambahkan yang baru. Misalnya, fragmen di TSDB selalu berupa array satu dimensi. Ini menyederhanakan manajemen fragmen dan mempercepat insert dan seleksi. Untuk menambahkan data baru, TSDB menggunakan algoritma peruteannya sendiri dalam fragmen yang diinginkan, yang, tidak seperti PG standar, tidak segera membuka semua bagian. Dengan sejumlah besar bagian, perbedaan kinerja dapat sangat bervariasi. Rincian teknis tentang perbedaan antara partisi standar di PG dan TSDB dapat ditemukan di
artikel ini .
Zabbix dan TimescaleDB
Dari semua opsi, TimescaleDB tampaknya menjadi pilihan teraman untuk Zabbix dan penggunanya:
- TSDB dirancang sebagai ekstensi PostgreSQL, dan bukan sebagai sistem mandiri. Oleh karena itu, tidak memerlukan perangkat keras tambahan, mesin virtual, atau perubahan infrastruktur lainnya. Pengguna dapat terus menggunakan alat yang mereka pilih untuk PostgreSQL.
- TSDB memungkinkan Anda untuk menyimpan hampir semua kode untuk bekerja dengan database di Zabbix tidak berubah.
- TSDB secara signifikan meningkatkan kinerja syncer sejarah dan pembantu rumah tangga.
- Ambang entri rendah - Konsep dasar TSDB sederhana dan mudah.
- Instalasi dan konfigurasi yang mudah baik untuk ekstensi itu sendiri maupun Zabbix akan sangat membantu pengguna sistem kecil dan menengah.
Mari kita lihat apa yang perlu dilakukan untuk memulai TSDB dengan Zabbix yang baru diinstal. Setelah menginstal Zabbix dan menjalankan skrip pembuatan database PostgreSQL, Anda perlu mengunduh dan menginstal TSDB pada platform yang diinginkan. Lihat instruksi instalasi di
sini . Setelah menginstal ekstensi, Anda harus mengaktifkannya untuk basis Zabbix, dan kemudian jalankan skrip timecaledb.sql yang datang dengan Zabbix. Ini terletak baik di database / postgresql / timecaledb.sql jika instalasi berasal dari sumber, atau di /usr/share/zabbix/database/timecaledb.sql.gz jika instalasi berasal dari paket. Itu saja! Sekarang Anda dapat memulai server Zabbix dan itu akan bekerja dengan TSDB.
Skrip timescaledb.sql sepele. Yang dia lakukan adalah mengonversi tabel historis Zabbix biasa ke hipertensi TSDB dan mengubah pengaturan default - menetapkan parameter Override periode histori item dan Override periode tren item. Sekarang (versi 4.2) tabel Zabbix berikut berfungsi di bawah kendali TSDB - history, history_uint, history_str, history_log, history_text, tren dan tren_uint. Script yang sama dapat digunakan untuk memigrasi tabel ini (perhatikan bahwa parameter migrate_data disetel ke true). Harus diingat bahwa migrasi data adalah proses yang sangat panjang dan dapat memakan waktu beberapa jam.
Parameter chunk_time_interval => 86400 mungkin juga memerlukan perubahan sebelum menjalankan timecaledb.sql. Chunk_time_interval adalah interval yang membatasi waktu nilai jatuh ke dalam fragmen ini. Misalnya, jika Anda menetapkan interval chunk_time_interval menjadi 3 jam, maka data sepanjang hari akan didistribusikan di antara 8 fragmen, dengan fragmen pertama No. 1 mencakup 3 jam pertama (0: 00-2: 59), fragmen kedua No. 2 - 3 jam kedua ( 3: 00-5: 59), dll. Fragmen terakhir No. 8 akan berisi nilai dengan waktu 21: 00-23: 59. 86400 detik (1 hari) adalah nilai standar rata-rata, tetapi pengguna sistem yang dimuat mungkin ingin menguranginya.
Untuk memperkirakan kebutuhan memori secara kasar, penting untuk memahami berapa banyak ruang yang rata-rata dapat mengambil satu bagian. Prinsip umum adalah bahwa sistem harus memiliki memori yang cukup untuk mengatur setidaknya satu fragmen dari setiap hipertensi. Pada saat yang sama, tentu saja, jumlah ukuran fragmen tidak hanya harus sesuai dengan memori dengan margin, tetapi juga lebih kecil dari nilai parameter shared_buffers dari postgresql.conf. Informasi lebih lanjut tentang topik ini dapat ditemukan di dokumentasi TimescaleDB.
Misalnya, jika Anda memiliki sistem yang mengumpulkan metrik integer utama dan Anda memutuskan untuk membagi tabel history_uint menjadi fragmen 2 jam, dan membagi tabel yang tersisa menjadi fragmen satu hari, maka Anda perlu mengubah baris ini di timecaledb.sql:
SELECT create_hypertable('history_uint', 'clock', chunk_time_interval => 7200, migrate_data => true);
Setelah sejumlah data historis terakumulasi, Anda dapat memeriksa ukuran fragmen untuk tabel history_uint dengan memanggil chunk_relation_size ():
zabbix=> SELECT chunk_table,total_bytes FROM chunk_relation_size('history_uint'); chunk_table | total_bytes -----------------------------------------+------------- _timescaledb_internal._hyper_2_6_chunk | 13287424 _timescaledb_internal._hyper_2_7_chunk | 13172736 _timescaledb_internal._hyper_2_8_chunk | 13344768 _timescaledb_internal._hyper_2_9_chunk | 13434880 _timescaledb_internal._hyper_2_10_chunk | 13230080 _timescaledb_internal._hyper_2_11_chunk | 13189120
Panggilan ini dapat diulang untuk menemukan ukuran fragmen untuk semua hipertensi. Jika, misalnya, ditemukan bahwa ukuran fragmen history_uint adalah 13MB, fragmen untuk tabel sejarah lainnya, katakanlah 20MB dan untuk tabel tren 10MB, maka total kebutuhan memori adalah 13 + 4 x 20 + 2 x 10 = 113MB. Kami juga harus meninggalkan ruang dari shared_buffers untuk menyimpan data lain, katakanlah 20%. Maka nilai shared_buffers harus disetel ke 113MB / 0.8 = ~ 140MB.
Untuk penyetelan TSDB yang lebih baik, utilitas timescaledb-tune baru-baru ini muncul. Ini menganalisis postgresql.conf, menghubungkannya dengan konfigurasi sistem (memori dan prosesor), dan kemudian memberikan rekomendasi tentang pengaturan parameter memori, parameter untuk pemrosesan paralel, WAL. Utilitas mengubah file postgresql.conf, tetapi Anda dapat menjalankannya dengan parameter -dry-run dan memeriksa perubahan yang diajukan.
Kami akan memikirkan parameter Zabbix Override periode histori item dan Override periode tren item (tersedia di Administrasi -> Umum -> Housekeeping). Mereka diperlukan untuk menghapus data historis sebagai seluruh fragmen hipertensi TSDB, bukan catatan.
Faktanya adalah bahwa Zabbix memungkinkan Anda untuk mengatur periode pembersihan untuk setiap elemen data (metrik) secara individual. Namun, fleksibilitas ini dicapai dengan memindai daftar elemen dan menghitung periode individu dalam setiap iterasi rumah tangga. Jika sistem memiliki periode pembersihan masing-masing elemen, maka sistem jelas tidak dapat memiliki satu titik cut-off untuk semua metrik bersama-sama dan Zabbix tidak akan dapat memberikan perintah yang benar untuk menghapus fragmen yang diperlukan. Dengan demikian, dengan mematikan Timpa riwayat untuk metrik, Zabbix akan kehilangan kemampuan untuk menghapus riwayat dengan cepat dengan memanggil prosedur drop_chunks () untuk tabel history_ *, dan, dengan demikian, mematikan tren Timpa akan kehilangan fungsi yang sama untuk tabel tren_ *.
Dengan kata lain, untuk memanfaatkan sepenuhnya sistem tata graha baru, Anda harus menjadikan kedua opsi tersebut mendunia. Dalam hal ini, proses pembersihan tidak akan membaca pengaturan item data sama sekali.
Performa dengan TimescaleDB
Sudah waktunya untuk memeriksa apakah semua hal di atas benar-benar berfungsi dalam praktik. Testbed kami adalah Zabbix 4.2rc1 dengan PostgreSQL 10.7 dan TimescaleDB 1.2.1 untuk Debian 9. Mesin uji ini adalah Intel Xeon 10-core dengan RAM 16 GB dan ruang penyimpanan 60 GB pada SSD. Dengan standar saat ini, ini adalah konfigurasi yang sangat sederhana, tetapi tujuan kami adalah untuk mengetahui seberapa efektif TSDB dalam kehidupan nyata. Dalam konfigurasi dengan anggaran tak terbatas, Anda cukup memasukkan 128-256 GB RAM dan memasukkan sebagian besar (jika tidak semua) database ke dalam memori.
Konfigurasi pengujian kami terdiri dari 32 agen Zabbix aktif yang mentransfer data langsung ke Server Zabbix. Setiap agen melayani 10.000 item. Cache historis Zabbix diatur ke 256MB, dan shared_buffers PG diatur ke 2GB. Konfigurasi ini menyediakan beban yang cukup pada basis data, tetapi pada saat yang sama tidak membuat beban besar pada proses server Zabbix. Untuk mengurangi jumlah komponen yang bergerak antara sumber data dan database, kami tidak menggunakan Zabbix Proxy.
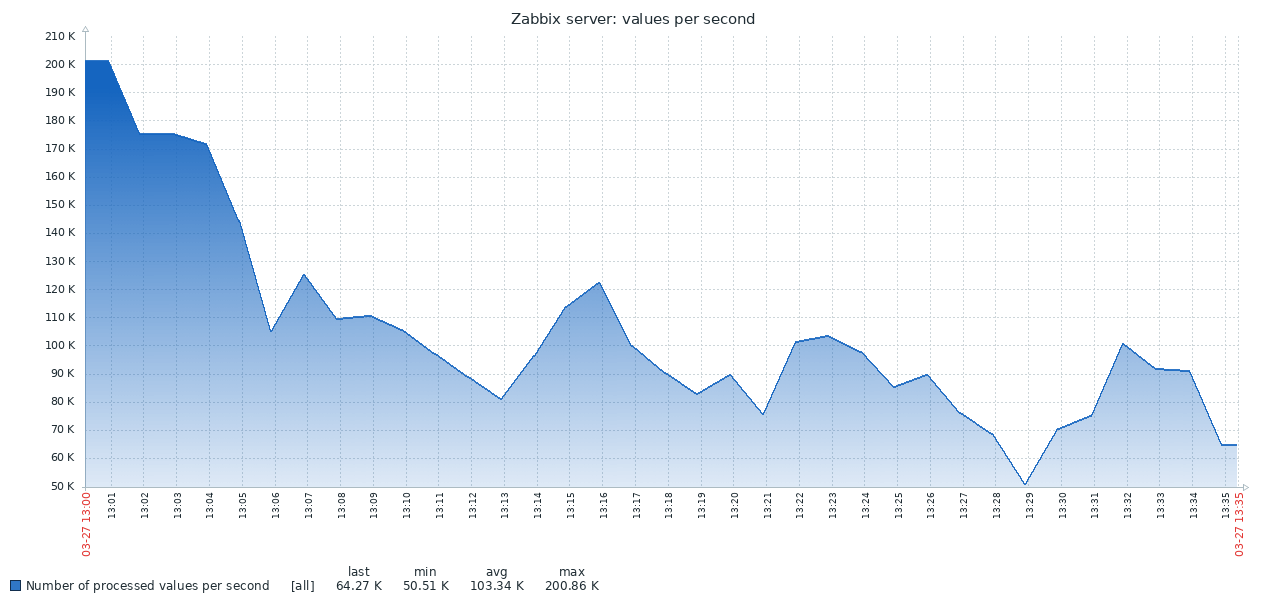
Ini adalah hasil pertama yang diperoleh dari sistem PG standar:
Hasil TSDB sangat berbeda:

Grafik di bawah ini menggabungkan kedua hasil. Pekerjaan dimulai dengan nilai NVPS yang cukup tinggi di 170-200K, karena Diperlukan waktu untuk mengisi cache riwayat sebelum sinkronisasi dengan basis data dimulai.
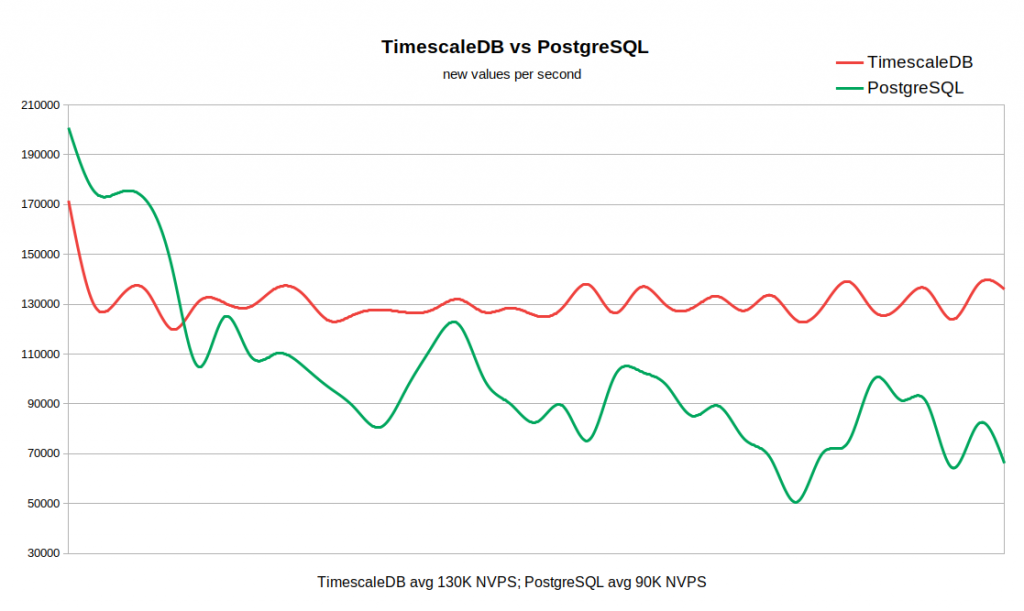
Ketika tabel histori kosong, kecepatan tulis di TSDB sebanding dengan kecepatan tulis di PG, dan bahkan dengan margin kecil dari yang terakhir. Begitu jumlah catatan dalam sejarah mencapai 50-60 juta, throughput PG turun menjadi 110K NVPS, tetapi, yang lebih tidak menyenangkan, itu terus berubah secara terbalik dengan jumlah catatan yang terakumulasi dalam tabel sejarah. Pada saat yang sama, TSDB mempertahankan kecepatan stabil 130K NVPS selama pengujian dari 0 hingga 300 juta catatan.
Secara total, dalam contoh kami, perbedaan dalam kinerja rata-rata cukup signifikan (130K versus 90K tanpa memperhitungkan puncak awal). Terlihat juga bahwa laju penyisipan dalam standar PG bervariasi pada rentang yang luas. Jadi, jika alur kerja membutuhkan penyimpanan puluhan atau ratusan juta catatan dalam sejarah, tetapi tidak ada sumber daya untuk strategi caching yang sangat agresif, maka TSDB adalah kandidat kuat untuk mengganti PG standar.
Keuntungan TSDB sudah jelas untuk sistem yang relatif sederhana ini, tetapi kemungkinan besar perbedaannya akan menjadi lebih nyata pada array besar data historis. Di sisi lain, tes ini sama sekali bukan generalisasi dari semua skenario yang mungkin bekerja dengan Zabbix. Secara alami, ada banyak faktor yang mempengaruhi hasil, seperti konfigurasi perangkat keras, pengaturan sistem operasi, pengaturan server Zabbix, dan beban tambahan dari layanan lain yang berjalan di latar belakang. Artinya, jarak tempuh Anda mungkin berbeda-beda.
Kesimpulan
TimescaleDB adalah teknologi yang sangat menjanjikan. Ini telah berhasil dioperasikan di lingkungan produksi yang serius. TSDB bekerja dengan baik dengan Zabbix dan menawarkan keuntungan signifikan dibandingkan database PostgreSQL standar.
Apakah TSDB memiliki kekurangan atau alasan untuk menunda menggunakannya? Dari sudut pandang teknis, kami tidak melihat adanya argumen yang menentang. Tetapi harus diingat bahwa teknologi ini masih baru, dengan siklus rilis yang tidak stabil dan strategi yang tidak jelas untuk pengembangan fungsionalitas. Khususnya, versi baru dengan perubahan signifikan dirilis setiap bulan atau dua. Beberapa fungsi dapat dihapus, seperti, misalnya, terjadi dengan chunking adaptif. Secara terpisah, sebagai faktor ketidakpastian lainnya, ada baiknya menyebutkan kebijakan lisensi. Ini sangat membingungkan karena ada tiga tingkatan perizinan. Kernel TSDB dibuat di bawah lisensi Apache, beberapa fungsi dirilis di bawah Lisensi Timescale mereka sendiri, tetapi ada juga versi tertutup dari Enterprise.
Jika Anda menggunakan Zabbix dengan PostgreSQL, maka tidak ada alasan setidaknya untuk tidak mencoba TimescaleDB. Mungkin hal ini akan mengejutkan Anda :) Perlu diingat bahwa dukungan untuk TimescaleDB di Zabbix masih bersifat eksperimental - untuk sementara, sementara kami mengumpulkan ulasan pengguna dan mendapatkan pengalaman.