Menggunakan nginx untuk menyeimbangkan lalu lintas HTTP di tingkat L7, dimungkinkan untuk mengirim permintaan klien ke server aplikasi berikutnya jika target tidak mengembalikan respons positif. Sebuah uji mekanisme verifikasi pasif kondisi kesehatan server aplikasi menunjukkan ambiguitas dokumentasi dan spesifisitas algoritma untuk mengecualikan server dari kumpulan server produksi.
Ringkasan menyeimbangkan lalu lintas HTTP
Ada berbagai cara untuk menyeimbangkan lalu lintas HTTP. Pada level model OSI,
ada teknologi penyeimbang di level jaringan, transportasi dan aplikasi.
Kombinasi dapat digunakan tergantung pada ukuran aplikasi.
Teknologi penyeimbangan lalu lintas memberikan efek positif dalam aplikasi dan pemeliharaannya. Ini beberapa di antaranya. Penskalaan horisontal aplikasi, di mana
beban didistribusikan di antara beberapa node . Rencana dekomisioning server aplikasi dengan menghapus aliran permintaan klien darinya. Implementasi strategi pengujian A / B untuk fungsionalitas aplikasi yang berubah. Meningkatkan toleransi kesalahan aplikasi dengan
mengirimkan permintaan ke server aplikasi yang berfungsi dengan baik .
Fungsi terakhir diimplementasikan dalam dua mode. Dalam mode pasif, penyeimbang dalam lalu lintas klien mengevaluasi respons server aplikasi target dan mengeluarkannya dari kumpulan server produksi dalam kondisi tertentu. Dalam mode aktif, penyeimbang secara berkala mengirim permintaan ke server aplikasi di URI yang ditentukan secara spesifik, dan untuk tanda-tanda respons tertentu memutuskan untuk mengeluarkannya dari kumpulan server produksi. Selanjutnya, penyeimbang, dalam kondisi tertentu, mengembalikan server aplikasi ke kumpulan server produksi.
Verifikasi pasif dari server aplikasi dan pengecualiannya dari kumpulan server produksi
Mari kita lihat lebih dekat pada pemeriksaan server aplikasi pasif dalam edisi freeware nginx / 1.17.0. Server aplikasi dipilih pada gilirannya oleh algoritma Round Robin, bobotnya sama.
Diagram tiga langkah menunjukkan bagian waktu dimulai dengan mengirim permintaan klien ke server aplikasi No. 2. Indikator yang cerah mencirikan permintaan / tanggapan antara klien dan penyeimbang. Indikator gelap - permintaan / tanggapan antara nginx dan server aplikasi.
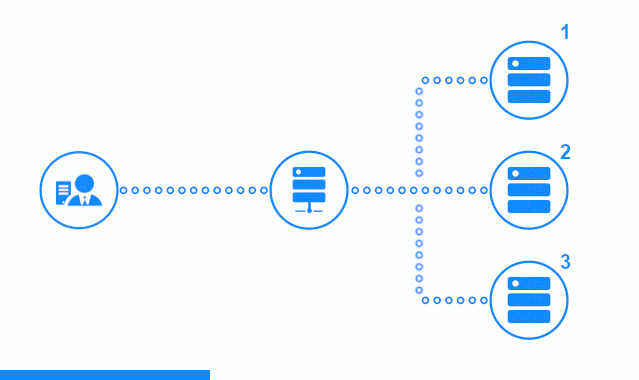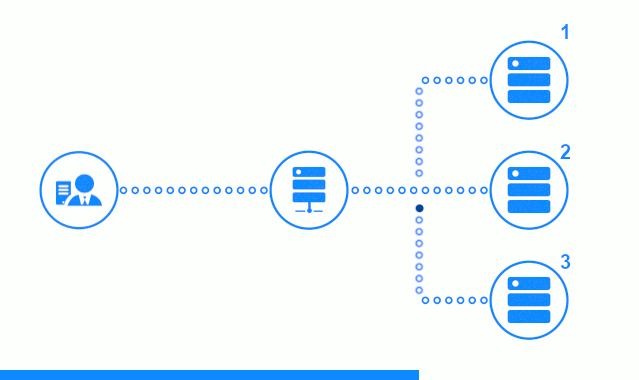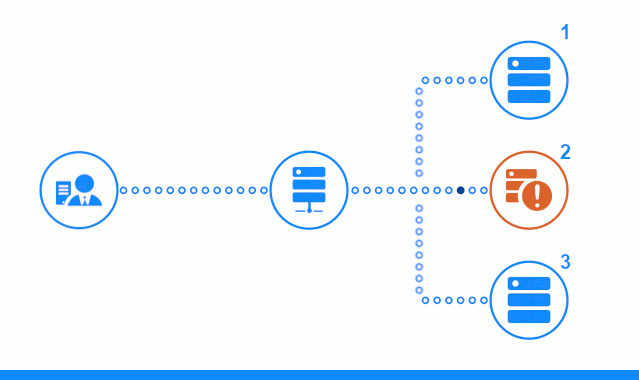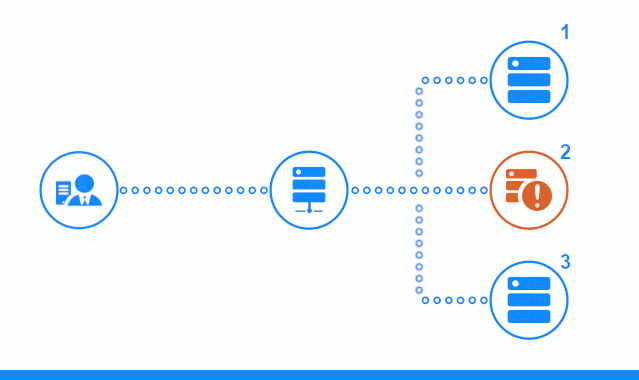
Langkah ketiga diagram menunjukkan bagaimana penyeimbang mengalihkan permintaan klien ke server aplikasi berikutnya, jika server target memberikan respons kesalahan atau tidak menjawab sama sekali.
Daftar kesalahan HTTP dan TCP di mana server menggunakan server berikut ini ditentukan dalam direktif
proxy_next_upstream .
Secara default, nginx hanya mengalihkan
permintaan dengan metode HTTP idempoten ke server aplikasi berikutnya.
Apa yang didapat klien? Di satu sisi, kemampuan untuk mengarahkan permintaan ke server aplikasi berikutnya meningkatkan kemungkinan memberikan respons yang memuaskan kepada klien ketika server target gagal. Di sisi lain, jelas bahwa panggilan berurutan pertama ke server target, dan kemudian ke berikutnya meningkatkan waktu respons total kepada klien.
Pada akhirnya,
respons server aplikasi dikembalikan ke klien
, tempat proxy_next_upstream_tries upaya yang diijinkan berakhir .
Saat menggunakan fungsi pengalihan ke server yang berfungsi berikutnya, Anda perlu juga menyelaraskan batas waktu pada server penyeimbang dan aplikasi. Batas atas waktu untuk permintaan "perjalanan" antara server aplikasi dan penyeimbang adalah batas waktu klien, atau waktu tunggu yang ditentukan oleh bisnis. Saat menghitung batas waktu, juga perlu memperhitungkan margin untuk peristiwa jaringan (keterlambatan / kerugian selama pengiriman paket). Jika klien setiap kali mengakhiri sesi dengan timeout sementara penyeimbang mendapatkan jawaban yang dijamin, niat baik untuk membuat aplikasi yang dapat diandalkan akan sia-sia.

Pemeriksaan kesehatan pasif dari server aplikasi dikendalikan oleh arahan, misalnya, dengan opsi berikut untuk nilainya:
upstream backend { server app01:80 weight=1 max_fails=5 fail_timeout=100s; server app02:80 weight=1 max_fails=5 fail_timeout=100s; } server { location / { proxy_pass http://backend; proxy_next_upstream timeout http_500; proxy_next_upstream_tries 1; ... } ... }
Pada 2 Juli
2019 , dokumentasi
menetapkan bahwa parameter
max_fails menetapkan jumlah upaya yang gagal untuk bekerja dengan server yang harus terjadi dalam waktu yang ditentukan oleh parameter
fail_timeout .
Parameter
fail_timeout menetapkan waktu di mana jumlah upaya gagal yang ditentukan untuk bekerja dengan server harus terjadi agar server dianggap tidak tersedia; dan waktu selama server dianggap tidak tersedia.
Dalam contoh yang diberikan, bagian dari file konfigurasi, penyeimbang dikonfigurasi untuk menangkap 5 panggilan gagal dalam 100 detik.
Mengembalikan server aplikasi ke kumpulan server produksi
Sebagai berikut dari dokumentasi, penyeimbang setelah
fail_timeout tidak dapat menganggap server tidak beroperasi. Namun, sayangnya, dokumentasi tidak secara eksplisit menetapkan bagaimana kinerja server dievaluasi.
Tanpa eksperimen, seseorang hanya dapat mengasumsikan bahwa mekanisme untuk memeriksa keadaan mirip dengan yang dijelaskan sebelumnya.
Harapan dan Realita
Dalam konfigurasi yang disajikan, perilaku berikut diharapkan dari penyeimbang:
- Sampai penyeimbang mengecualikan server aplikasi No. 2 dari kumpulan server produksi, permintaan klien akan dikirim ke sana.
- Permintaan yang dikembalikan dengan kesalahan 500 dari server aplikasi No. 2 akan diteruskan ke server aplikasi berikutnya, dan klien akan menerima respons positif.
- Segera setelah penyeimbang menerima 5 tanggapan dengan kode 500 dalam 100 detik, ia akan mengecualikan server aplikasi No. 2 dari kumpulan server produksi. Semua permintaan setelah jendela 100 detik akan segera dikirim ke server aplikasi yang tersisa tanpa waktu tambahan.
- Setelah 100 detik, entah bagaimana, penyeimbang harus mengevaluasi kinerja server aplikasi dan mengembalikannya ke kumpulan server produksi.
Setelah melakukan tes dalam bentuk barang, menurut majalah penyeimbang, ditetapkan bahwa pernyataan No. 3 tidak berfungsi. Penyeimbang mengecualikan server idle segera setelah kondisi pada parameter
max_fails terpenuhi . Dengan demikian, server yang gagal dikecualikan dari layanan tanpa menunggu berlalu 100 detik. Parameter
fail_timeout hanya memainkan peran batas atas waktu akumulasi kesalahan.
Sebagai bagian dari pernyataan No. 4, ternyata nginx memeriksa fungsionalitas aplikasi yang sebelumnya dikecualikan dari pemeliharaan server hanya dengan satu permintaan. Dan jika server masih merespons dengan kesalahan, maka pemeriksaan berikutnya akan
gagal setelah
fail_timeout .
Apa yang hilang
- Algoritme yang diimplementasikan dalam nginx / 1.17.0 mungkin bukan cara yang paling adil untuk memeriksa kinerja server sebelum mengembalikannya ke kumpulan server produksi. Paling tidak, sesuai dengan dokumentasi saat ini, tidak 1 permintaan diharapkan, tetapi jumlah yang ditentukan dalam max_fails .
- Algoritma pemeriksaan keadaan tidak memperhitungkan kecepatan permintaan. Semakin besar, semakin kuat spektrum dengan upaya yang gagal bergeser ke kiri, dan server aplikasi keluar dari kumpulan server yang bekerja terlalu cepat. Saya kira ini dapat mempengaruhi aplikasi yang memungkinkan mereka untuk menghasilkan kesalahan "kekurangan waktu". Misalnya, saat mengumpulkan sampah.

Saya ingin bertanya kepada Anda apakah ada manfaat praktis dari algoritma pemeriksaan kesehatan server, yang mengukur kecepatan upaya yang gagal?