Nama saya Stas Kirillov, saya adalah pengembang terkemuka di grup platform-ML di Yandex. Kami sedang mengembangkan alat pembelajaran mesin, mendukung dan mengembangkan infrastruktur untuk mereka. Di bawah ini adalah pembicaraan terakhir saya tentang cara kerja perpustakaan CatBoost. Dalam laporan itu, saya berbicara tentang titik masuk dan fitur kode bagi mereka yang ingin memahaminya atau menjadi kontributor kami.
- CatBoost hidup di GitHub di bawah lisensi Apache 2.0, yaitu terbuka dan gratis untuk semua orang. Proyek ini aktif berkembang, sekarang repositori kami memiliki lebih dari empat ribu bintang. CatBoost ditulis dalam C ++, itu adalah perpustakaan untuk meningkatkan gradien pada pohon keputusan. Ini mendukung beberapa jenis pohon, termasuk yang disebut pohon "simetris", yang digunakan di perpustakaan secara default.
Apa untungnya pohon-pohon kita yang terlupakan? Mereka dengan cepat belajar, dengan cepat menerapkan dan membantu belajar menjadi lebih tahan terhadap perubahan parameter dalam hal perubahan kualitas akhir model, yang sangat mengurangi kebutuhan untuk pemilihan parameter. Perpustakaan kami adalah tentang membuatnya nyaman untuk digunakan dalam produksi, belajar dengan cepat dan mendapatkan kualitas yang baik segera.

Gradient boosting adalah suatu algoritma di mana kita membangun alat prediksi sederhana yang meningkatkan fungsi tujuan kita. Artinya, alih-alih segera membangun model yang kompleks, kami membangun banyak model kecil secara bergantian.

Bagaimana proses pembelajaran di CatBoost? Saya akan memberi tahu Anda cara kerjanya dalam hal kode. Pertama, kami mem-parsing parameter pelatihan yang dilewati pengguna, memvalidasinya, dan kemudian melihat apakah kami perlu memuat data. Karena data sudah dapat dimuat - misalnya, dalam Python atau R. Selanjutnya, kami memuat data dan membangun kisi dari perbatasan untuk menghitung fitur numerik. Ini diperlukan untuk membuat belajar cepat.
Fitur kategorikal yang kami proses sedikit berbeda. Kami mengategorikan fitur di awal, dan kemudian memberi nomor baru dari nol hingga jumlah nilai unik dari fitur kategorikal agar dapat dengan cepat membaca kombinasi fitur kategorikal.
Kemudian kami meluncurkan loop pelatihan secara langsung - siklus utama pembelajaran mesin kami, tempat kami membangun pohon secara iteratif. Setelah siklus ini, model diekspor.
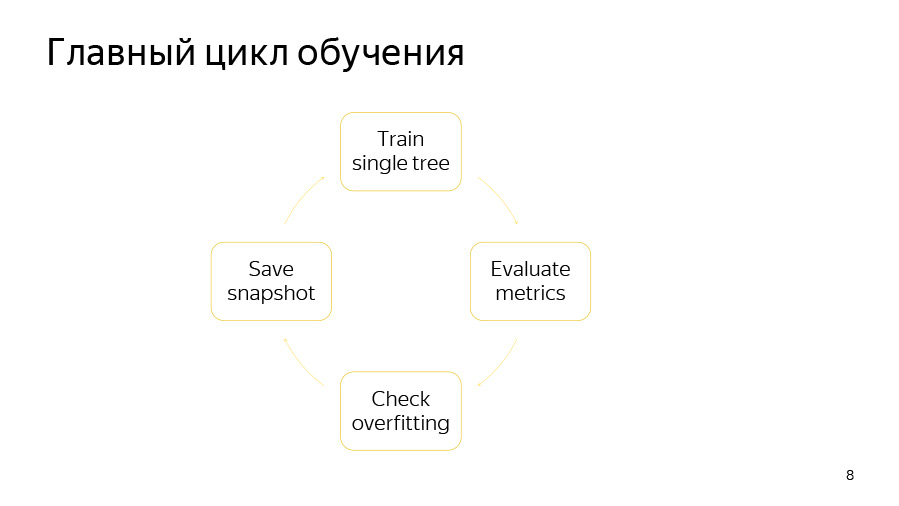
Siklus pelatihan itu sendiri terdiri dari empat poin. Pertama, kami mencoba membangun satu pohon. Kemudian kita melihat peningkatan atau penurunan kualitas apa yang dihasilkannya. Kemudian kami memeriksa untuk melihat apakah detektor pelatihan kami telah bekerja. Maka kita, jika waktunya tepat, simpan snapshot.

Belajar satu pohon adalah siklus melalui tingkat pohon. Pada awalnya, kami memilih permutasi data secara acak jika kami menggunakan penguat pesanan atau memiliki fitur kategorikal. Kemudian kami menghitung penghitung pada permutasi ini. Kemudian kami mencoba dengan rakus untuk mengambil bagian yang bagus di pohon ini. Maksud kami adalah beberapa kondisi biner: fitur numerik ini-dan-itu lebih besar dari nilai ini-atau-itu, atau penghitung ini-dan-demikian oleh fitur kategorikal lebih besar daripada nilai ini-dan-itu.
Bagaimana siklus tingkat pohon serakah diatur? Pada awalnya, bootstrap sudah selesai - kami mengulangi atau sampel objek, setelah itu hanya objek yang dipilih yang akan digunakan untuk membangun pohon. Bootstrap juga dapat dihitung ulang sebelum memilih setiap pemisahan jika opsi pengambilan sampel di setiap tingkat diaktifkan.
Kemudian kami menggabungkan turunan ke dalam histogram, seperti yang kami lakukan untuk setiap kandidat. Dengan menggunakan histogram, kami mencoba mengevaluasi perubahan dalam fungsi tujuan yang akan terjadi jika kami memilih kandidat yang terbagi ini.
Kami memilih kandidat dengan kecepatan terbaik dan menambahkannya ke pohon. Kemudian kami menghitung statistik menggunakan pohon yang dipilih ini pada permutasi yang tersisa, memperbarui nilai dalam daun pada permutasi ini, menghitung nilai dalam daun untuk model, dan melanjutkan ke iterasi berikutnya dari loop.

Sangat sulit untuk memilih satu tempat di mana pelatihan berlangsung, jadi pada slide ini - Anda dapat menggunakannya sebagai titik masuk - file utama yang kami gunakan untuk pelatihan terdaftar. Ini adalah greedy_tensor_search, di mana kita menjalankan prosedur untuk pemilihan serakah yang serakah. Ini adalah train.cpp, di mana kami memiliki pabrik pelatihan CPU utama. Ini adalah aprox_calcer, di mana fungsi memperbarui nilai di daun terletak. Dan juga score_calcer - fungsi untuk mengevaluasi beberapa kandidat.
Bagian yang sama pentingnya adalah catboost.pyx dan core.py. Ini adalah kode pembungkus python, kemungkinan besar banyak dari Anda akan menanamkan beberapa jenis barang ke dalam pembungkus python. Pembungkus python kami ditulis dalam Cython, Cython diterjemahkan dalam C ++, jadi kode ini harus cepat.
R-wrapper kami terletak di folder paket-R. Mungkin seseorang harus menambahkan atau memperbaiki beberapa opsi, untuk opsi kita memiliki pustaka yang terpisah - catboost / libs / options.
Kami datang dari Arcadia ke GitHub, jadi kami memiliki banyak artefak menarik yang akan Anda temui.


Mari kita mulai dengan struktur repositori. Kami memiliki folder util di mana primitif dasar adalah: vektor, peta, sistem file, bekerja dengan string, stream.
Kami memiliki perpustakaan tempat pustaka bersama yang digunakan oleh Yandex berada - banyak, bukan hanya CatBoost.
Folder CatBoost dan contrib adalah kode perpustakaan pihak ketiga yang kami tautkan.
Sekarang mari kita bicara tentang primitif C ++ yang akan Anda temui. Yang pertama adalah pointer cerdas. Di Yandex, kami telah menggunakan THolder sejak std :: unique_ptr, dan MakeHolder digunakan sebagai ganti std :: make_unique.

Kami memiliki SharedPtr kami sendiri. Selain itu, ada dalam dua bentuk, SimpleSharedPtr dan AtomicSharedPtr, yang berbeda dalam jenis penghitung. Dalam satu kasus, itu adalah atom, yang berarti seolah-olah beberapa aliran dapat memiliki objek. Jadi itu akan aman dari sudut pandang transfer antar aliran.
Kelas terpisah, IntrusivePtr, memungkinkan Anda memiliki objek yang diwarisi dari kelas TRefCounted, yaitu kelas yang memiliki penghitung referensi bawaan. Ini untuk mengalokasikan objek-objek tersebut pada satu waktu, tanpa tambahan mengalokasikan blok kontrol dengan penghitung.
Kami juga memiliki sistem kami sendiri untuk input dan output. IInputStream dan IOutputStream adalah antarmuka untuk input dan output. Mereka memiliki metode yang bermanfaat, seperti ReadTo, ReadLine, ReadAll, secara umum, semua yang dapat diharapkan dari InputStreams. Dan kami memiliki implementasi stream ini untuk bekerja dengan konsol: Cin, Cout, Cerr dan Endl secara terpisah, yang mirip dengan std :: endl, yaitu, ia menyiram stream.

Kami juga memiliki implementasi antarmuka kami sendiri untuk file: TInputFile, TOutputFile. Ini adalah buffered read. Mereka menerapkan membaca buffered dan menulis buffered ke file, sehingga Anda dapat menggunakannya.
Util / system / fs.h memiliki metode NFs :: Exists dan NFs :: Copy, jika Anda tiba-tiba perlu menyalin sesuatu atau memeriksa apakah ada file yang benar-benar ada.

Kami memiliki wadah sendiri. Mereka pindah ke menggunakan std :: vector beberapa waktu yang lalu, yaitu, mereka hanya mewarisi dari std :: vector, std :: set dan std :: map, tetapi kami juga memiliki THashMap dan THashSet kami sendiri, yang sebagian memiliki antarmuka yang kompatibel dengan unordered_map dan unordered_set. Tetapi untuk beberapa tugas ternyata lebih cepat, jadi kami masih menggunakannya.

Referensi array analog dengan std :: span dari C ++. Benar, dia muncul bersama kami bukan pada tahun kedua puluh, tetapi jauh lebih awal. Kami secara aktif menggunakannya untuk mentransfer referensi ke array, seolah-olah dialokasikan pada buffer besar, sehingga tidak mengalokasikan buffer sementara setiap waktu. Misalkan, untuk menghitung turunan atau beberapa perkiraan, kita dapat mengalokasikan memori pada beberapa buffer besar yang dialokasikan sebelumnya dan hanya meneruskan TArrayRef ke fungsi penghitungan. Sangat nyaman, dan kami sering menggunakannya.

Arcadia menggunakan serangkaian kelasnya sendiri untuk bekerja dengan string. Ini, pertama, TStingBuf - analog dari str :: string_view dari C ++ 17.
TString sama sekali tidak std :: sting, ini adalah string CopyOnWrite, jadi Anda harus bekerja dengannya dengan sangat hati-hati. Selain itu, TUtf16String adalah TString yang sama, hanya tipe dasarnya bukan char, tetapi 16-bit wchar.
Dan kami memiliki alat untuk mengkonversi dari string ke string. Ini adalah ToString, yang merupakan analog dari std :: to_string dan FromString dipasangkan dengan TryFromString, yang memungkinkan Anda untuk mengubah string menjadi tipe yang Anda butuhkan.

Kami memiliki struktur pengecualian kami sendiri, pengecualian dasar di perpustakaan arcade adalah yexception, yang diwarisi dari std :: exception. Kami memiliki makro ythrow yang menambahkan informasi tentang tempat pengecualian dilontarkan di yexception, itu hanya pembungkus yang nyaman.
Ada analog std :: current_exception - CurrentExceptionMessage, fungsi ini melempar pengecualian saat ini sebagai string.
Ada makro untuk menegaskan dan memverifikasi - ini adalah Y_ASSERT dan Y_VERIFY.

Dan kami memiliki serialisasi internal kami sendiri, ini adalah biner dan tidak dimaksudkan untuk mentransfer data di antara berbagai revisi. Sebaliknya, serialisasi ini diperlukan untuk mentransfer data antara dua binari dari revisi yang sama, misalnya, dalam pembelajaran terdistribusi.
Kebetulan kami memiliki dua versi serialisasi di CatBoost. Opsi pertama bekerja melalui metode antarmuka Save and Load, yang bersambung ke aliran. Opsi lain digunakan dalam pelatihan terdistribusi kami, ini menggunakan perpustakaan BinSaver internal yang agak lama, nyaman untuk membuat serial objek polimorfik yang harus didaftarkan di pabrik khusus. Ini diperlukan untuk pelatihan yang didistribusikan, yang sepertinya tidak akan kita bicarakan di sini.

Kami juga memiliki analog boost_optional atau std :: opsional - TMaybe kami sendiri. Analogue of std :: varian - TVariant. Anda harus menggunakannya.

Ada konvensi tertentu yang di dalam kode CatBoost kita melempar TCatBoostException alih-alih yexception. Ini adalah yexception yang sama, hanya jejak stack yang selalu ditambahkan ketika dilemparkan.
Dan kami juga menggunakan makro CB_ENSURE untuk memeriksa beberapa hal dan membuang pengecualian jika tidak dieksekusi. Misalnya, kita sering menggunakan ini untuk opsi parsing atau parsing parameter yang diterima pengguna.

Sebelum Anda mulai, kami sarankan agar Anda membiasakan diri dengan gaya kode, terdiri dari dua bagian. Yang pertama adalah gaya kode arcade umum, yang terletak langsung di akar repositori di file CPP_STYLE_GUIDE.md. Juga di akar repositori adalah panduan terpisah untuk tim kami: catboost_command_style_guide_extension.md.
Kami mencoba memformat kode Python menggunakan PEP8. Itu tidak selalu berhasil, karena untuk kode Cython, linter tidak bekerja untuk kita, dan kadang-kadang ada sesuatu dengan PEP8.

Apa saja fitur dari perakitan kami? Perakitan Arcadia pada awalnya ditujukan untuk mengumpulkan aplikasi yang paling kedap udara, yaitu, bahwa akan ada minimum ketergantungan eksternal karena tautan statis. Ini memungkinkan Anda untuk menggunakan biner yang sama di berbagai versi Linux tanpa kompilasi ulang, yang cukup nyaman. Sasaran perakitan dijelaskan dalam file ya.make. Contoh ya.make dapat dilihat pada slide berikutnya.

Jika Anda tiba-tiba ingin menambahkan semacam perpustakaan, program, atau sesuatu yang lain, Anda bisa, pertama, lihat saja file tetangga di file ya.make, dan kedua, gunakan contoh ini. Di sini kami telah membuat daftar elemen terpenting ya.make. Di awal file, kami mengatakan bahwa kami ingin mendeklarasikan pustaka, lalu kami mendaftar unit kompilasi yang ingin kami taruh di pustaka ini. Di sini dapat berupa file cpp, dan, misalnya, file pyx yang akan memulai secara otomatis Cython, dan kemudian kompilator. Ketergantungan perpustakaan didaftar melalui makro PEERDIR. Itu hanya menulis path ke folder dengan perpustakaan atau dengan artefak lain di dalamnya, relatif terhadap akar repositori.
Ada hal yang berguna, GENERATE_ENUM_SERIALIZATION, diperlukan untuk menghasilkan metode ToString, FromString untuk kelas enum dan enum yang dijelaskan dalam beberapa file header yang Anda sampaikan ke makro ini.

Sekarang tentang hal yang paling penting - cara menyusun dan menjalankan beberapa jenis tes. Akar dari repositori adalah skrip ya, yang mengunduh toolkit dan alat yang diperlukan, dan memiliki perintah ya make - make subcommand - yang memungkinkan Anda untuk membangun rilis -r dengan switch -r, dan versi debug dengan kunci -d. Artefak di dalamnya diteruskan dan dipisahkan oleh spasi.
Untuk membangun Python, saya langsung menunjukkan bendera di sini yang mungkin berguna. Kita berbicara tentang membangun dengan sistem Python, dalam hal ini dengan Python 3. Jika Anda tiba-tiba menginstal CUDA Toolkit di laptop atau mesin pengembangan Anda, maka untuk perakitan yang lebih cepat, kami sarankan Anda menentukan –d have_cuda no flag. CUDA dibangun untuk beberapa waktu, terutama pada sistem 4-core.

Ya ide harus sudah berfungsi. Ini adalah alat yang akan menghasilkan solusi clion atau qt untuk Anda. Dan bagi mereka yang datang dengan Windows, kami memiliki solusi Microsoft Visual Studio, yang terletak di folder msvs.
Pendengar:
- Apakah Anda memiliki semua tes melalui pembungkus Python?
Stas:
- Tidak, kami secara terpisah memiliki tes yang terletak di folder pytest. Ini adalah tes antarmuka CLI kami, yaitu, aplikasi kami. Benar, mereka bekerja melalui pytest, yaitu, ini adalah fungsi Python di mana kami membuat panggilan pemeriksaan subproses dan memverifikasi bahwa program tidak macet dan bekerja dengan benar dengan beberapa parameter.
Pendengar:
- Bagaimana dengan tes unit dalam C ++?
Stas:
- Kami juga memiliki unit test di C ++. Mereka biasanya berbaring di folder lib di subfolder ut. Dan mereka ditulis seperti itu - unit test atau unit test. Ada beberapa contoh. Ada makro khusus untuk mendeklarasikan kelas tes unit, dan register terpisah untuk fungsi tes unit.
Pendengar:
- Untuk memverifikasi bahwa tidak ada yang rusak, apakah lebih baik meluncurkan keduanya dan yang lainnya?
Stas:
- Ya. Satu-satunya hal adalah, tes open source kami hanya hijau di Linux. Karena itu, jika Anda mengkompilasi, misalnya, di bawah Mac, jika ada lima tes gagal, maka tidak ada yang perlu dikhawatirkan. Karena implementasi yang berbeda dari peserta pada platform yang berbeda atau perbedaan kecil lainnya, hasilnya bisa sangat berbeda.

Sebagai contoh, kami akan mengambil tugas. Saya ingin menunjukkan beberapa contoh. Kami memiliki file dengan tugas - open_problems.md. Mari kita selesaikan masalah №4 dari open_problems.md. Diformulasikan sebagai berikut: jika pengguna menetapkan tingkat pembelajaran ke nol, maka kita harus turun dari TCatBoostException. Anda perlu menambahkan validasi opsi.
Pertama, kita perlu membuat cabang, mengkloning fork kita, asal clone, asal pop, menjalankan asal di fork kita dan kemudian membuat cabang dan mulai bekerja di dalamnya.
Bagaimana cara kerja parsing opsi? Seperti yang saya katakan, kami memiliki folder catboost / libs / options penting di mana parsing semua opsi disimpan.

Kami memiliki semua opsi yang tersimpan di bungkus TOption, yang memungkinkan kami untuk memahami apakah opsi tersebut telah ditimpa oleh pengguna. Jika tidak, ia menyimpan beberapa nilai default sendiri. Secara umum, CatBoost mem-parsing semua opsi dalam bentuk kamus JSON besar, yang selama parsing berubah menjadi kamus bersarang dan struktur bersarang.

Kami entah bagaimana menemukan - misalnya, dengan mencari dengan grep atau membaca kode - bahwa kami memiliki tingkat pembelajaran di TBoostingOptions. Mari kita coba menulis kode yang hanya menambahkan CB_ENSURE bahwa tingkat pembelajaran kami lebih dari std :: numeric_limits :: epsilon, bahwa pengguna telah memasukkan sesuatu yang lebih atau kurang masuk akal.

Di sini kami hanya menggunakan makro CB_ENSURE, menulis beberapa kode dan sekarang kami ingin menambahkan tes.

Dalam hal ini, kami menambahkan tes pada Antarmuka Baris Perintah. Di folder pytest, kami memiliki skrip test.py, di mana sudah ada beberapa contoh tes dan Anda bisa memilih satu yang terlihat seperti tugas Anda, salin dan ubah parameternya sehingga mulai turun atau tidak turun, tergantung pada parameter yang Anda lewati. Dalam hal ini, kami hanya mengambil dan membuat kumpulan dua garis sederhana. (Kami memanggil kumpulan dataset dalam Yandex. Ini adalah kekhasan kami.) Dan kemudian kami memeriksa bahwa biner kami benar-benar turun jika kami melewati tingkat pembelajaran 0,0.

Kami juga menambahkan tes ke paket python, yang terletak di atBoost / python-package / ut / medium. Kami juga memiliki tes besar, besar yang terkait dengan tes untuk membangun paket roda python.

Selanjutnya kami memiliki kunci untuk ya make - -t dan -A. -t menjalankan tes, -A memaksa semua tes untuk menjalankan terlepas dari apakah mereka memiliki tag besar atau sedang.
Di sini, untuk kecantikan, saya juga menggunakan tes bernama filter. Ini diatur menggunakan opsi -F dan nama tes yang ditentukan nanti, yang mungkin bintang char liar. Dalam kasus ini, saya menggunakan test.py::test_zero_learning_rate*, karena, dengan melihat tes paket python kami, Anda akan melihat: hampir semua fungsi menggunakan fixture jenis tugas. Ini sesuai dengan kode, pengujian paket python kami terlihat sama untuk pembelajaran CPU dan GPU dan dapat digunakan untuk pengujian pelatih GPU dan CPU.

Kemudian komit perubahan kami dan dorong ke repositori bercabang kami. Kami menerbitkan permintaan kolam renang. Dia sudah bergabung, semuanya baik-baik saja.