Selama sesi pelatihan (Mei-Juni dan Desember-Januari), pengguna meminta kami untuk memeriksa pinjaman hingga 500 dokumen setiap menit. Dokumen datang dalam berbagai format file, kompleksitas bekerja dengan masing-masing berbeda. Untuk memeriksa dokumen peminjaman, pertama-tama kita perlu mengekstraksi teksnya dari file, dan pada saat yang sama berurusan dengan pemformatan. Tugasnya adalah menerapkan ekstraksi setengah ribu teks berkualitas tinggi dengan format per menit, sementara jarang terjadi (atau lebih baik tidak jatuh sama sekali), mengonsumsi sedikit sumber daya dan tidak membayar setengah anggaran galaksi untuk pengembangan dan pengoperasian gagasan akhir.
Ya, ya, tentu saja, kami tahu bahwa dari tiga hal - cepat, murah dan efisien - Anda harus memilih dua. Tetapi hal yang paling buruk adalah bahwa dalam kasus kami, kami tidak dapat menghapus apa pun. Pertanyaannya adalah seberapa baik kita melakukannya ...

Sumber Gambar: Wikipedia
Kita sering diberi tahu bahwa nasib orang tergantung pada kualitas pekerjaan kita. Karena itu, Anda harus mendidik dalam diri Anda perfeksionis. Tentu saja, kami terus meningkatkan kualitas sistem (dalam semua aspek), karena penulis yang tidak bermoral menemukan cara baru untuk menyelesaikannya. Dan saya berharap bahwa hari itu sudah dekat ketika kompleksitas penipuan, di satu sisi, dan perasaan kepuasan dari pekerjaan yang dilakukan dengan baik, di sisi lain, akan mendorong sebagian besar siswa untuk meninggalkan keinginan mereka untuk bercanda. Pada saat yang sama, kami memahami bahwa harga kesalahan dapat menjadi kemungkinan penderitaan orang-orang tidak bersalah jika kami tiba-tiba memalsukannya.
Kenapa saya? Jika kita perfeksionis, kita akan berpikir untuk menulis serangkaian artikel tentang karya sistem Anti-Plagiarisme . Kami akan dengan susah payah merumuskan rencana publikasi untuk menyatakan segala sesuatu dengan cara yang paling logis dan diharapkan untuk pembaca:
- Pertama, kami akan berbicara tentang bagaimana Sistem kami disusun ( publikasi kelima tentang Habré), dan akan menjelaskan tiga tahap utama pemrosesan dokumen ketika diperiksa untuk meminjam:
- Ekstrak teks dokumen (Anda ada di sini!);
- Cari pinjaman (potongan sudah ada di beberapa artikel kami );
- Membuat laporan tentang dokumen (dalam rencana).
- Selanjutnya, kami akan mulai mencurahkan pembaca ke perangkat mekanisme bantu yang menarik, seperti pencarian pinjaman yang dapat ditransfer ( artikel pertama ), definisi parafrase ( keempat ) dan klasifikasi tematik ( kedua ).
- Dan akhirnya, kami sampai di mesin pencari - indeks herpes zoster ( artikel ketujuh ).
Pembaca yang penuh perhatian harus memperhatikan bahwa kita masih tidak menderita perfeksionisme yang berlebihan, jadi inilah saatnya untuk beralih ke tahap pertama - mengekstraksi teks dan memformat dokumen. Inilah yang akan kita lakukan hari ini, tentang cara berpikir tentang kefanaan makhluk hidup dan tentang cahaya di ujung terowongan, tentang tidak adanya sesuatu yang ideal dan tentang mengejar keunggulan, tentang memiliki rencana dan mengikutinya dan tentang kompromi yang selalu mendorong kita untuk hidup.
Pada mulanya adalah kata
Pada awalnya, kami mengekstrak dari dokumen hanya yang paling diperlukan untuk memeriksa mereka untuk meminjam - teks dari dokumen itu sendiri. Format utama didukung - docx, doc, txt, pdf, rtf, html. Kemudian ppt, pptx, odt, epub, fb2, djvu yang kurang umum ditambahkan, namun, perlu untuk menolak bekerja dengan sebagian besar dari mereka di masa depan . Masing-masing diproses dengan caranya sendiri - di suatu tempat di perpustakaan yang terpisah, di suatu tempat di parser sendiri. Rata-rata, ekstraksi teks berlangsung sekitar ratusan milidetik. Tampaknya kesulitan utama dan hampir-satunya dalam mengekstraksi teks adalah "parsing" dari format itu sendiri, yang terutama berlaku untuk format pdf dan doc biner (dan sifat kepemilikan yang terakhir membuat bekerja dengan itu bahkan lebih bermasalah). Namun, sudah pada tahap ini, ketika keinginan kita terbatas hanya untuk mengekstraksi teks, menjadi jelas bahwa cara membaca format yang kita butuhkan membawa sejumlah fitur yang tidak menyenangkan. Yang paling penting dari mereka:
- Pengecualian bahkan ketika memproses beberapa dokumen yang valid, belum lagi pemrosesan dokumen "rusak" yang salah. Yang menciptakan lebih banyak masalah adalah bahwa kode asli bisa jatuh, dan menangani situasi seperti itu dalam kode .net sulit;
- Konsumsi memori yang tidak cukup tinggi, yang dapat melukai baik proses tetangga maupun yang saat ini memproses dokumen "masalah" (kehabisan memori dalam kode yang dikelola atau tidak dikelola);
- Terlalu lama pemrosesan dokumen, yang diperburuk oleh kurangnya mekanisme pembatalan untuk sebagian besar perpustakaan, dan kadang-kadang oleh kompleksitas (baca: hampir mustahil) untuk membatalkan panggilan kode yang tidak dikelola dari yang dikelola;
- "Ekstraksi teks dari dokumen." Membuat teks dokumen pdf (dan format ini adalah kunci bagi kami), yang parsingnya sudah dilakukan, bertentangan dengan harapan, adalah tugas yang tidak sepele. Faktanya adalah bahwa format pdf pada awalnya dikembangkan terutama untuk presentasi elektronik dari bahan cetak. Teks dalam pdf adalah sekumpulan blok teks yang terletak di halaman-halaman dokumen. Selain itu, blok dapat berupa paragraf teks atau karakter tunggal. Tugas mengembalikan teks dalam bentuk aslinya dari kumpulan blok ini terletak pada pustaka (kode / program) yang membaca dokumen. Ya, formatnya, dimulai dengan versi tertentu, menyediakan kemampuan untuk menentukan urutan blok, tetapi, sayangnya, dokumen dengan urutan blok teks yang ditandai jarang terjadi. Oleh karena itu, perpustakaan membaca teks pdf berisi sejumlah heuristik (yah, standarnya di sini: pembelajaran mesin,
bigdata, blockchain , ...) yang memungkinkan Anda untuk mengembalikan teks dalam bentuk yang benar dengan satu derajat atau lebih, dan, seperti yang diharapkan, hasil yang diperoleh berbeda dari perpustakaan ke perpustakaan .

Sumber Gambar Bawah: Artikel
Sumber Gambar Top: Hmm ...
Perlu lebih banyak data!
Jika, untuk menganalisis dokumen untuk dipinjam, latar belakang teks dari dokumen itu cukup bagi kami, maka penerapan sejumlah fitur baru tidak mungkin atau sangat sulit tanpa mengekstraksi data tambahan dari dokumen. Hari ini, selain latar belakang teks, kami juga mengekstrak pemformatan dokumen dan membuat gambar halaman. Kami menggunakan yang terakhir untuk pengenalan teks optik ( OCR ), serta untuk mengidentifikasi beberapa jenis bypass.
Memformat dokumen mencakup pengaturan geometris semua kata dan karakter pada halaman, serta ukuran font semua karakter. Informasi ini memungkinkan kami untuk:
- Menampilkan laporan verifikasi dokumen dengan indah, menarik pinjaman yang terdeteksi secara langsung pada dokumen asli;

- Untuk menentukan blok dokumen (halaman judul, daftar pustaka ) dengan lebih akurat dan mengambil metadata-nya (penulis, jabatan, tahun dan tempat kerja, dll);
- Mendeteksi upaya bypass sistem.
Untuk menyatukan pemrosesan dokumen dan satu set data yang diekstraksi, kami mengonversi dokumen dari semua format yang didukung oleh kami ke pdf. Dengan demikian, prosedur untuk mengekstraksi data dokumen dilakukan dalam dua tahap:
- Konversi dokumen ke pdf;
- Ekstrak data dari pdf.
Konversikan ke pdf. Pemilihan perpustakaan
Karena tidak mudah mengambil dan mengonversi dokumen menjadi pdf, kami memutuskan untuk tidak menemukan kembali roda dan menjelajahi solusi yang sudah jadi, memilih yang paling cocok untuk kami. Itu kembali pada tahun 2017.
Kriteria untuk memilih kandidat:
- Library di .net, idealnya .net core dan cross-platform
Spoiler!Akibatnya, pada saat itu, cita-cita itu tidak mungkin tercapai
- Dukungan untuk format yang diperlukan - doc, docx, rtf, odf, ppt, pptx
- Stabilitas
- Performa
- Kualitas dukungan teknis
- Harga masalah
Kami menganalisis solusi yang tersedia, memilih di antaranya 6 yang paling cocok untuk tugas kami:
MS Word Interop, Neevia Document Converter Pro dan DynamicPdf membutuhkan instalasi MS Office pada produksi, yang akhirnya dapat mengikat kita ke Windows tanpa dapat ditarik kembali. Karenanya, kami tidak lagi mempertimbangkan opsi ini.
Dengan demikian, kami memiliki tiga kandidat utama yang tersisa, dan hanya satu dari mereka yang sepenuhnya mendukung semua format yang kami butuhkan. Nah, saatnya untuk melihat apa yang mampu mereka lakukan.
Untuk menguji perpustakaan, kami membentuk sampel 120 ribu dokumen pengguna nyata, rasio format yang kira-kira sesuai dengan apa yang kami lihat setiap hari pada produksi.
Jadi babak pertama. Mari kita lihat proporsi dokumen yang dapat berhasil dikonversi menjadi pdf library yang sedang dipertimbangkan. Berhasil, dalam kasus kami, bukan untuk melempar pengecualian, memenuhi batas waktu 3 menit dan mengembalikan teks yang tidak kosong.
Syncfusion segera menonjol, yang tidak hanya berhasil memproses jumlah dokumen terkecil, tetapi juga membuang seluruh proses pada beberapa dokumen (menghasilkan pengecualian seperti OutOfMemoryException atau pengecualian dari kode asli yang tidak tertangkap tanpa menari dengan rebana).
GroupDocs gagal memproses sekitar 5,5 kali lebih banyak dokumen daripada DevExpress (semuanya dapat dilihat pada plat di atas). Ini terlepas dari kenyataan bahwa lisensi pengembang tunggal dari GroupDocs sekitar 9 kali lebih mahal daripada lisensi pengembang tunggal dari DevExpress. Omong-omong, begitulah.
Tes serius kedua adalah waktu konversi, 120 ribu dokumen yang sama:
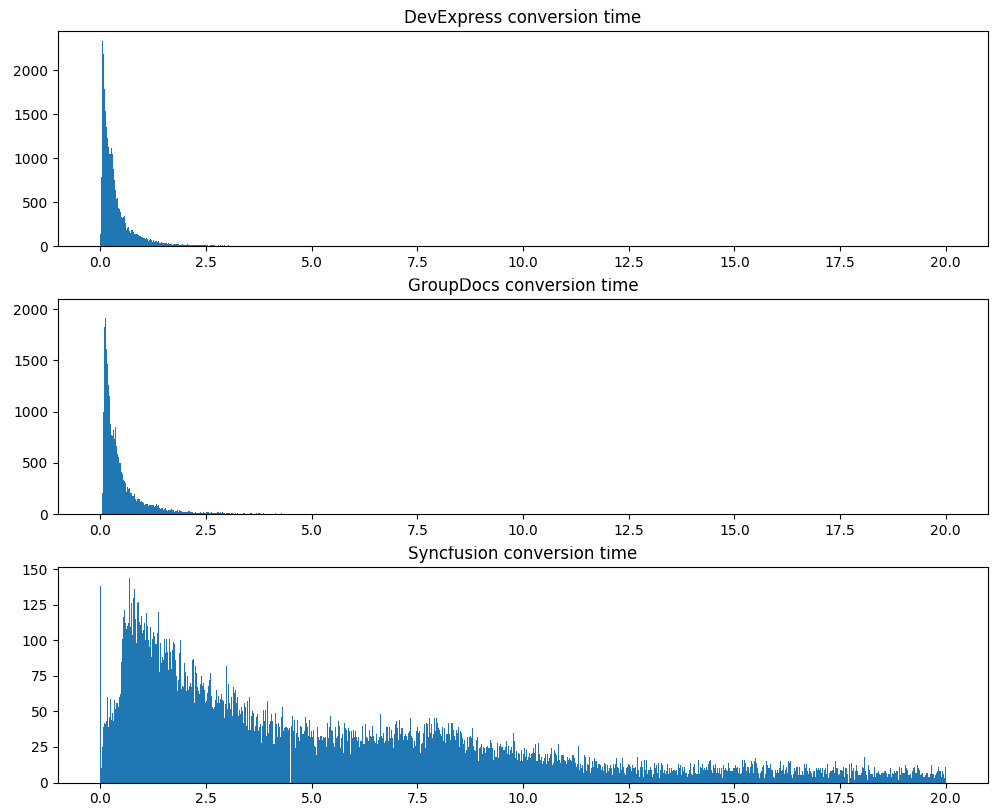
Perhatikan bahwa DevExpress tidak hanya memproses dokumen lebih cepat secara rata-rata, tetapi juga menunjukkan waktu pemrosesan yang jauh lebih stabil.
Tetapi stabilitas dan kecepatan pemrosesan tidak berarti apa-apa jika outputnya pdf buruk. Mungkin DevExpress melewatkan setengah teks? Kami periksa. Jadi, dengan 120 ribu dokumen yang sama, kali ini kami akan menghitung volume total teks yang diekstraksi dan rata-rata pangsa kata-kata kamus (semakin banyak kata yang diekstraksi adalah kamus, semakin sedikit sampah / teks yang diekstraksi dengan tidak benar):
Sebagian, anggapan itu benar. Ternyata, GroupDocs, tidak seperti DevExpress, dapat bekerja dengan catatan kaki. DevExpress hanya melewatkannya saat mengonversi dokumen ke pdf. Omong-omong, ya, teks dari pdf'ok yang diterima dalam semua kasus diekstraksi menggunakan DevExpress'a.
Jadi, kami mempelajari kecepatan dan stabilitas perpustakaan yang bersangkutan, sekarang kami dengan hati-hati mengevaluasi kualitas konversi dokumen pdf. Untuk melakukan ini, kami akan menganalisis tidak hanya volume teks yang akan diekstraksi dan proporsi kata-kata kamus di dalamnya, tetapi kami akan membandingkan teks yang diekstraksi dari pdf yang diterima dengan teks pdf yang diperoleh menggunakan MS Word. Kami menerima hasil konversi dokumen menggunakan MS Word sebagai pdf referensi . Sekitar 4.500 pasang " dokumen, referensi pdf'ka " disiapkan untuk tes ini.
Untuk setiap pasangan “ referensi pdf, hasil konversi ”, kami menghitung kesamaan dalam panjang teks yang diekstraksi dan dalam frekuensi kata-kata yang diekstraksi. Secara alami, metrik ini diperoleh hanya dalam kasus-kasus ketika konversi berhasil. Karena itu, kami tidak mempertimbangkan hasil Syncfusion di sini. DevExpress dan GroupDocs menunjukkan kinerja yang kira-kira sama. Di sisi DevExpress, ada persentase konversi yang sukses secara signifikan lebih tinggi, di sisi GD, pekerjaan yang benar dengan catatan kaki.
Mengingat hasilnya, pilihannya jelas. Hingga hari ini, kami menggunakan solusi dari DevExpress dan akan segera berencana untuk meningkatkan ke versi ke-19.
Ada pdf, ekstrak teks dengan format
Jadi, kita bisa mengonversi dokumen menjadi pdf. Sekarang kita memiliki tugas lain: menggunakan DevExpress untuk mengekstrak teks, mengetahui setiap kata semua informasi yang kita butuhkan. Yaitu:
- Di halaman mana kata itu;
- Lokasi kata pada halaman (membingkai persegi panjang);
- Ukuran font kata (karakter kata).
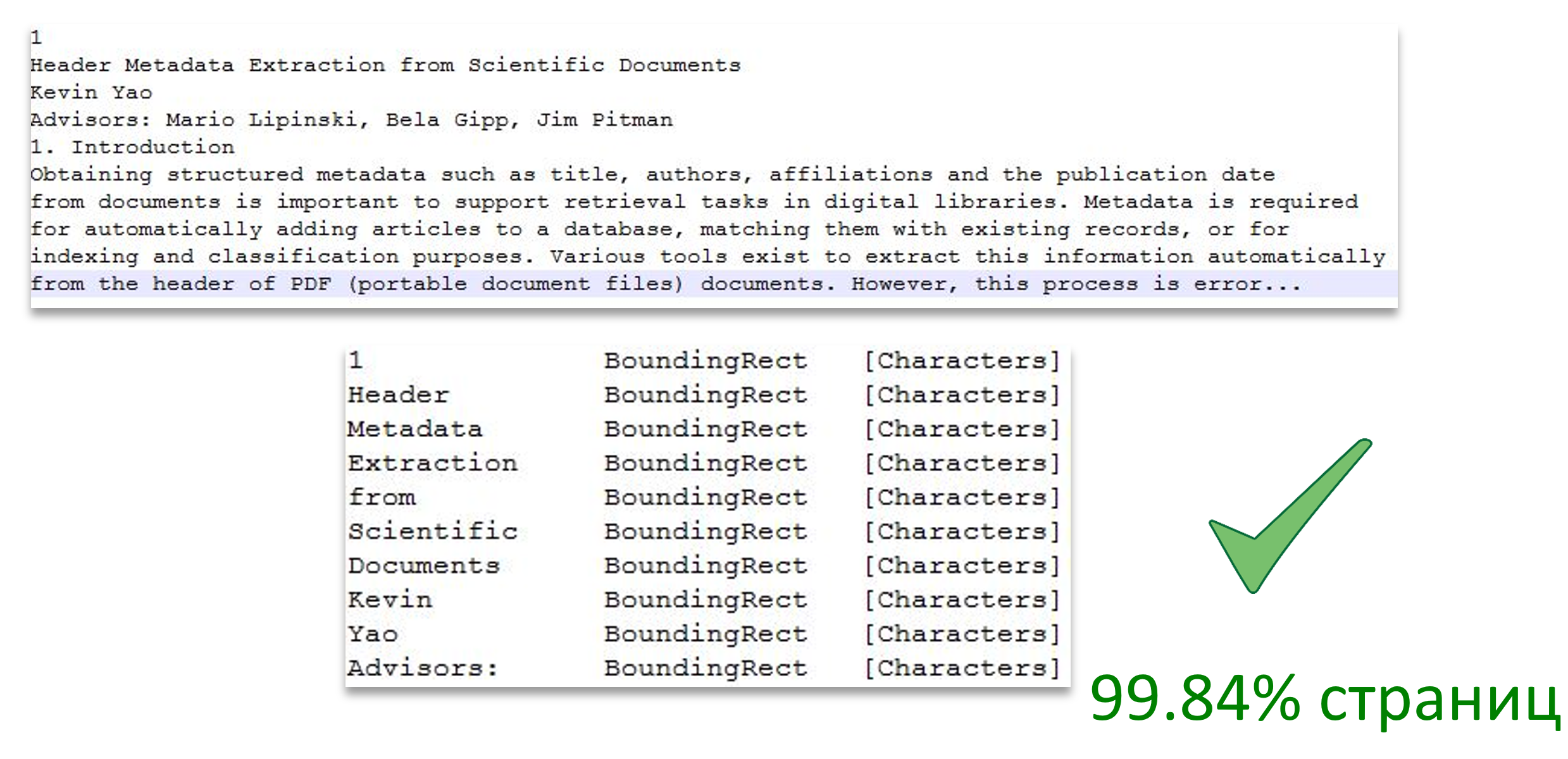
Gambar menunjukkan pengelompokan teks menjadi halaman, dan juga menunjukkan korespondensi kata teks ke area halaman.

Sumber Gambar: Ekstraksi Metadata Header dari Dokumen Ilmiah
Tampaknya semuanya harus sederhana. Kami melihat apa yang disediakan oleh API DevExpress kepada kami:
- Kami memiliki metode yang mengembalikan teks seluruh dokumen. String polos;
- Kami memiliki kemampuan untuk mengulang sesuai dokumen. Untuk setiap kata yang bisa kita dapatkan:
- Teks kata;
- Halaman tempat kata itu berada;
- Persegi panjang framing kata;
- Informasi tentang karakter individu kata (arti karakter membingkai persegi panjang, ukuran font, ...).
Oke, sepertinya semuanya ada di sana. Hanya di sini cara mendapatkan data yang diperlukan untuk setiap kata dalam teks dokumen yang dikembalikan oleh DevExpress? Kami tidak benar-benar ingin mengumpulkan teks dokumen dari kata-kata sendiri, karena, misalnya, kami tidak memiliki informasi di mana hanya ada ruang antara kata-kata dan di mana umpan baris. Kita harus datang dengan heuristik berdasarkan lokasi kata-kata ... Teksnya - ini dia, sebelum kita, sudah berkumpul.

Sumber Gambar: Eureka!
Solusi yang jelas adalah mencocokkan kata-kata dengan teks dokumen. Kami melihat - memang, dalam teks dokumen kata-kata disusun dalam urutan yang sama di mana iterator mengembalikannya sesuai dengan dokumen.
Kami dengan cepat mengimplementasikan algoritme sederhana untuk mencocokkan kata-kata dengan teks dokumen, menambahkan pemeriksaan bahwa semuanya cocok dengan benar, mulai ...
Memang, semuanya berfungsi dengan benar di sebagian besar halaman, tetapi, sayangnya, tidak di semua halaman.

Sumber Gambar Top: Apakah Anda yakin?
Pada bagian dokumen kita melihat bahwa kata-kata dalam teks tidak dalam urutan di mana mereka pergi ketika iterating atas kata-kata dokumen. Selain itu, dapat dilihat bahwa braket kuadrat pembuka dalam teks dalam daftar kata direpresentasikan sebagai braket penutup dan dalam “kata” lain. Tampilan fragmen teks yang benar ini dapat dilihat dengan membuka dokumen dalam MS Word. Lebih menarik lagi, jika Anda tidak mengonversi dokumen menjadi pdf, tetapi langsung mengekstrak teks dari dokumen, maka kami mendapatkan versi ketiga dari fragmen teks yang tidak cocok dengan urutan yang benar atau dua pesanan lain yang diterima dari perpustakaan. Dalam fragmen ini, seperti dalam sebagian besar sisanya, di mana masalah serupa muncul, intinya adalah karakter "RTL" yang tidak terlihat, yang mengubah urutan karakter / kata yang berdekatan.
Di sini perlu diingat bahwa kita menyebut kualitas dukungan teknis penting ketika memilih perpustakaan. Seperti yang telah ditunjukkan oleh praktik, dalam aspek ini, interaksi dengan DevExpress cukup efektif. Masalah dengan dokumen yang dikirimkan dengan cepat diperbaiki setelah kami membuat tiket yang sesuai. Sejumlah masalah lain yang terkait dengan pengecualian / konsumsi memori tinggi / pemrosesan dokumen yang lama juga diperbaiki.
Namun, sementara DevExpress tidak menyediakan cara langsung untuk mendapatkan teks dengan informasi yang diperlukan untuk setiap kata, kami terus membandingkan terkadang tidak ada bandingannya. Jika kami tidak dapat membuat kecocokan yang tepat antara kata dan teks, kami menggunakan sejumlah heuristik yang memungkinkan permutasi kata yang kecil. Jika tidak ada yang membantu, dokumen tetap tanpa format. Jarang, tetapi ini terjadi.
Sampai jumpa :)