Selama 3 tahun terakhir, lebih dari seribu insiden berbagai tingkat epik terjadi di Contour. Alasannya berbeda: misalnya, 36% disebabkan oleh rilis berkualitas buruk, dan 14% - karena pemeliharaan besi di pusat data. Dari mana statistik berasal? Setelah setiap kejadian, sebuah laporan ditulis - post mortem. Mereka ditulis oleh insinyur tugas yang menanggapi pemberitahuan kecelakaan dan merupakan orang pertama yang memahami penyebabnya. Post-mortem dianalisis, diidentifikasi dan dihilangkan penyebab insiden, sehingga di masa depan insiden tersebut tidak terjadi. Tapi itu tidak selalu terjadi.
Alexey Kirpichnikov (
BeeVee ) telah pemrograman di Yandex sejak 2008. Kemacetan lalu lintas, bekerja pada proyek-proyek khusus olahraga, adalah pemimpin tim dari backend Yandex.Taxi. Sejak 2014, ia telah terlibat dalam DevOps dan infrastruktur di
Kontur - ia telah mengembangkan alat yang membuat hidup lebih mudah bagi pengembang dari tim produk. Gagasan untuk menulis dan menganalisis topik post-mortem muncul lima tahun yang lalu, dan selama ini topik post-mortem ditumbuhi templat, glosarium, memo, screenshot, dan analitik. Tapi ini bukan yang paling sulit -
lebih sulit untuk mengatasi inersia, ketakutan dan kesalahpahaman tentang makna laporan insiden di antara para insinyur . Apa yang akhirnya terjadi dan apa manfaat yang tidak dapat diperbaiki dari "analisis sofa" dapat dilakukan dalam menguraikan laporan Alexey.
 Harap dicatat - di bawah kaki meja panjang yang berbeda ada buku "Metrik", "Tes" dan "Menyebarkan".
Harap dicatat - di bawah kaki meja panjang yang berbeda ada buku "Metrik", "Tes" dan "Menyebarkan".Di Kontur, setelah merekrut, mereka memberikan satu set suvenir: pena, cangkir, buku catatan. Saya datang ke SKB Kontur ke tim infrastruktur baru 5 tahun yang lalu, ketika perusahaan berusia 25 tahun.

Kontur masa itu, dan sekarang juga, adalah perusahaan produk di mana beberapa lusin produk mengembangkan jumlah tim yang sama, tidak tergantung satu sama lain dalam hal pemilihan teknologi dan peralatan.
Pada saat itu, saya pertama kali membaca “Project '' Phoenix ''” dan terinspirasi oleh ide-ide baru yang dikembangkan oleh DevOps-practices. Saya mulai menuliskan ide-ide saya untuk perbaikan di buku catatan, dan sekarang ini adalah artefak dengan noda kopi dan catatan sejarah.
- " Pemantauan! Mari kita letakkan Grafana, kumpulkan metrik, dan buat grafik. Kami akan lebih memahami apa yang terjadi dalam produksi. " Untuk 2014, ini adalah ide baru yang cukup segar dan praktik DevOps yang solid. ”
- " Menabrak otomatis!" Berapa banyak file zip yang dapat diunggah ke folder bersama, unzip di server dan jalankan exe di penjadwal tugas di Windows? "Mari kita perkenalkan sistem penyebaran industri dan rilis rilis melalui itu, CI!"
- “ Post-mortem ! Jika ada semacam kecelakaan dalam produksi, mari kita semua mencari tahu apa itu, menemukan alasannya, menulis laporan, dan mengubah pengembangan, pengujian, proses CI kami sehingga tidak ada insiden seperti itu di masa depan ”
Selama 5 tahun kami telah melangkah maju di semua bidang ini. Kami memiliki sistem peringatan
Moira kami sendiri, sistem orkestrasi aplikasi dan banyak alat. Tetapi dari semua hal di atas,
menulis laporan insiden ternyata merupakan praktik rekayasa yang paling sulit untuk diterapkan . Insinyur menyukai semua jenis alat - kencangkan semacam sistem hosting atau CI, skrip sesuatu, otomatisasi, dan mereka tidak suka menulis laporan, meskipun praktik ini sangat bermanfaat.
Saya akan memberi tahu Anda bagaimana kami menerapkan sistem post-mortem dan manfaat apa yang kami dapatkan. Mungkin menyapu kami akan membantu untuk pergi dengan cara ini lebih cepat dan mengisi lebih sedikit kerucut. Sebelum mulai berbicara tentang bedah mayat, kita akan memahami definisi tersebut.
Apa itu insiden?
Yang mana dari insiden ini?
- Contoh No. 1. Pada platform blog dengan sejuta pengguna, sebagai akibat dari beberapa jenis kesalahan, semua entri dari satu pengguna hilang.
- Contoh No. 2. Layanan untuk karyawan kantor berfungsi pada hari kerja dari 9 hingga 6, dan di saat lain tidak ada pengguna di dalamnya. Layanan tidak tersedia pada malam Sabtu hingga Minggu selama dua jam berturut-turut, tidak ada yang memperhatikan.
- Contoh No. 3. Grafana dengan metrik produksi turun 15 menit. Dalam produksi, tidak ada yang rusak, tetapi grafiknya tidak tersedia.
Untuk memahami apa dari kepalsuan ini, kita beralih ke pengalaman para guru - Google, Atlassian, PagerDuty. Gurus tahu cara menyiapkan shift, insinyur yang bertugas, dan bagaimana menulis laporan untuk memahaminya. Panduan online mereka memiliki definisi insiden.
Definisi dari PagerDuty.
Suatu insiden adalah gangguan layanan yang tidak direncanakan atau degradasi layanan yang mempengaruhi ketersediaan layanan kepada pengguna. Insiden serius adalah insiden apa pun yang membutuhkan respons terkoordinasi dari beberapa tim.
Kedengarannya logis, tetapi definisinya tidak jelas. Dalam praktiknya, sedikit membantu untuk memahami apa yang merupakan insiden dan apa yang tidak.
Buku
Rekayasa Keandalan Situs Google memiliki kriteria yang jelas:
- Pengguna memperhatikan penurunan layanan.
- Semua data hilang.
- Butuh intervensi dari insinyur tugas, misalnya, untuk memutar kembali rilis secara manual.
- Memecahkan masalah butuh waktu terlalu lama. Jika masalah diselesaikan dalam 2 jam, dan kemudian satu minggu dihabiskan untuk itu - ini adalah insiden yang membutuhkan penyelidikan.
- Pemantauan tidak berhasil. Misalnya, Anda belajar tentang masalah dari pengguna.
Contour tidak memiliki definisi yang diterbitkan tentang fakap, tetapi kami telah merumuskan kriteria kami sendiri untuk menentukan apa yang merupakan insiden.
Pengguna eksternal atau internal telah memperhatikan penurunan layanan . Contoh No. 3 dengan Grafana, yang terbentang, adalah insiden yang jelas. Produksi tidak putus dan pengguna eksternal tidak memperhatikan ini, tetapi meskipun demikian, bagi Contour itu adalah fakap, karena alat internal tidak berfungsi.
Keberuntungan Dalam contoh No. 2, layanan untuk pekerja kantor berbaring selama 2 jam pada malam hari - untungnya jatuh pada malam hari. Waktu berikutnya, itu mungkin sial, dan karena itu kejadian malam juga memerlukan pengadilan, seolah-olah itu terjadi pada siang hari.
Insiden itu menyangkut beberapa tim . Kami mengambil definisi ini dari PagerDuty. Mengurai insiden adalah alasan bagus bagi beberapa tim untuk bekerja bersama. Budaya “Di pihak kami, peluru itu terbang keluar, tetapi ada sesuatu yang pecah untuk Anda - itu kesalahan Anda” dihilangkan dengan analisis bersama.
Setidaknya satu insinyur menganggap ini sebagai insiden . Definisi yang paling kabur, tetapi juga yang paling penting. Aturan sederhana: jika insinyur percaya bahwa itu layak untuk dilaporkan, maka itu layak untuk dilaporkan. Jika itu membuat Anda takut bahwa para insinyur akan mulai menulis laporan untuk siapa saja dan menyebut hal kecil sebagai kecelakaan, ini tidak benar.
Insinyur adalah orang-orang yang masuk akal, percayai mereka.Dengan definisi dan berbagai jenis kerusakan beres. Mari beralih ke cara memanfaatkan insiden.
Apa gunanya fakap?
Instruksi sederhana yang akan saya berikan lebih lanjut, bisa Anda terapkan sendiri, bahkan tanpa melalui artikel sampai akhir. Tapi tetap baca sampai akhir.
Instruksi klasik
Temukan pelakunya terlebih dahulu. Kemudian lakukan pekerjaan "pendidikan" dengan para insinyur.
- Minta lebih berhati-hati lain kali.
- Jika tidak membantu, kirim ke kursus pelatihan ulang. Mungkin mereka akan belajar untuk lebih berhati-hati di sana.
- Jika ini tidak membantu, singkirkan pelaku dari bekerja dengan bagian-bagian penting dari sistem. Berhenti membiarkan pengembang berproduksi jika mereka mengacaukannya.
- Jika tidak ada yang membantu, tembak yang buruk dan pekerjakan yang kompeten.
Jika instruksinya mengganggu Anda, ini adalah kabar baik.
Pendekatan ini dianggap tradisional untuk perusahaan klasik yang berorientasi vertikal dengan bos yang memarahi semua orang dan dapat memecatnya. Salah satu dasar gerakan DevOps dan ideologi DevOps adalah keberangkatan dari organisasi yang terintegrasi secara vertikal ke organisasi horizontal, dengan kepercayaan yang lebih besar pada karyawan.
Saya akan menggambarkan pergeseran paradigma ini dengan
instruksi dari John Alspaw, salah satu pemimpin gerakan DevOps, yang sebelumnya bekerja untuk CTO di Etsy. Instruksi ini diambil dari artikel kanonik 2013-nya, Blameless Post Mortem dan Budaya Adil.
Tanyakan kepada para insinyur:
- peristiwa apa yang mereka amati;
- kapan dan tindakan apa yang diambil;
- hasil apa yang diharapkan dari tindakan ini;
- apa asumsi yang berasal;
- sebagaimana dipahami oleh urutan kejadian yang terjadi.
Para insinyur perlu ditanyai tanpa ancaman hukuman.
Ini adalah hal utama dalam rekomendasi John.
Ancaman hukuman: pelatihan ulang, penghapusan produksi atau pemecatan, memotivasi orang untuk berbohong. Dan kebenaran itu penting bagi kita. Laporan insiden - ini adalah tautan umpan balik yang sangat hilang dalam proses pengembangan dan penempatan fitur dalam produksi.
Dalam paradigma lama, para pengembang berkembang, melemparkan kerajinan itu ke pagar para insinyur operasi, dan mereka entah bagaimana mencoba membuatnya bekerja. Mereka terganggu oleh pembaruan apa pun, karena dapat merusak segalanya, dan para insinyur memulai semuanya dengan kesulitan seperti itu.
Proses umpan balik membantu mengubah proses, infrastruktur, alat dan pendekatan pengembangan sehingga ada lebih sedikit crash dalam produksi.
Ini akan meyakinkan para pemimpin tim dan manajer pengembangan tentang manfaat post-mortem. Tetapi yang menarik adalah sulit untuk membuat insinyur melakukan apa yang mereka pikir tidak ada gunanya dan tidak berguna. Kami memiliki budaya rekayasa di perusahaan kami, dan saya tidak bisa datang begitu saja, melambaikan keputusan CEO dan menuntut agar semua orang menulis post-mortem. Saya perlu meyakinkan para insinyur ini.
Bagaimana cara "menjual" gagasan insinyur post-mortem ke insinyur? Untuk menyiasati keberatan, untuk menunjukkan mengapa post-mortem itu keren, untuk menunjukkan manfaat dari laporan, bahwa ini bukan hanya berhenti berlangganan, jika hanya bos di belakang.
Keberatan No. 1: Sekali
Ini adalah masalah pertama insinyur yang membongkar fakap - perang akan berakhir, maka kita akan bicara! Ketika fakap terjadi, saya ingin memperbaikinya dengan cepat, tetapi saya tidak ingin menulis laporan yang panjang dan membosankan.
Untuk mengatasi masalah, ada hack kehidupan, bagaimana menulis sesuatu dengan benar saat kecelakaan. Ia dipopulerkan oleh Artemy Lebedev:
“Ada cara sederhana mengatur waktu - metode“ jip progresif ”. Setiap saat, proyek apa pun sudah 100% siap, meskipun mungkin 4% lebih maju. Tergantung pada waktu yang tersedia, proyek dapat dikerjakan hingga satu piksel, atau dapat dibiarkan pada tahap sketsa konseptual. "
Saya akan mengilustrasikan metode jeepeg progresif menggunakan gambar. Di Internet yang lambat, gambar tidak langsung diunduh, tetapi secara bertahap.

Selama kebakaran, Anda tidak perlu menulis laporan yang keren dan panjang. Cukup bagi Anda di sudut kiri atas. Cukup menandai hal-hal yang sulit dipulihkan dari ingatan. Jangan mencoba menulis teks sastra yang koheren pada saat semuanya rusak saat diproduksi.
Lakukan tindakan sederhana - tuliskan kronologi peristiwa.
Garis waktu
Timeline kemudian sangat sulit untuk dipulihkan, jika tidak segera direkam. Contoh rekaman dari mayat nyata di sirkuit.
15.01.18 17:25 YEKT PrefixSearch 50 . , .
Ini adalah pengamatan singkat dan sederhana. Menurut kronologi ini, nanti mudah untuk mengembalikan urutan kejadian dan menemukan penyebab gangguan. Tetapi jika Anda tidak merekam apa pun secara langsung selama kebakaran, akan sulit atau tidak mungkin untuk mengembalikan acara nanti.
Tangkapan layar
Suatu hal yang praktis, terutama ketika bekerja dengan situs web atau aplikasi desktop. Situasi ini terkadang sulit dijelaskan dengan kata-kata, dan tangkapan layar hanya satu klik tombol pintas.
Keberatan pertama berhasil. Merekam informasi minimal, laporan kecil selama insiden tidak sulit dan tidak memakan waktu yang berharga. Ketika semuanya selesai, itu harus diselesaikan dan dieksekusi dalam dokumen yang dimengerti dan koheren.
Keberatan No. 2: Kemalasan
Anda tidak tidur selama dua hari dan memperbaiki kecelakaan serius, secara fatal tertinggal dalam semua tugas yang akan Anda selesaikan minggu ini. Tapi ternyata ada hal lain yang perlu dilakukan, tetapi apinya sudah padam! Pada saat ini, kemalasan yang tak terbayangkan menyusul.
Untuk benar-benar mengalahkan masalah tidak akan berhasil. Tetapi Anda dapat memfasilitasi pekerjaan Anda terlebih dahulu.
Pola
Ini yang pertama dan terpenting. Ada ketakutan besar terhadap dokumen kosong yang perlu diisi dengan teks yang bermakna. Jauh lebih mudah jika templat disiapkan. Biasanya itu terdiri dari bagian dan pertanyaan di dalamnya. Kami memasukkan jawaban untuk pertanyaan di setiap bagian, dan templat diisi.
Templat laporan insiden besar. Baca tentang mereka secara detail dengan guru. Semua dokumen dan buku yang saya rujuk berisi pola kejadian yang digunakan oleh perusahaan. Dalam pengalaman kami, saya bisa menambahkan yang berikut ini.
Buat memo dengan contoh
Templat kami memiliki bagian "Kerusakan" dengan subbagian.
Bagian "Penilaian kualitatif". Itu menggambarkan apa yang dilihat insinyur di depannya ketika dia mengisi bagian templat ini:
- fungsionalitas apa yang tidak berfungsi, berapa lama dan untuk siapa;
- apakah ada kehilangan atau kerusakan data.
Setelah mencapai tempat ini di templat, insinyur menulis: "Ada sejuta pengguna di platform blog kami, kami kehilangan semua entri dari salah satu dari mereka." Ini jauh lebih mudah daripada menulis esai dari awal, seperti dalam pelajaran sastra.
Bagian "Kuantifikasi":- berapa banyak permintaan yang hilang;
- berapa banyak latensi yang tumbuh dalam metrik aplikasi dan aplikasi klien;
- berapa banyak panggilan yang hilang;
- Ukuran antrian untuk dukungan teknis pengguna untuk masalah tersebut.
Seperangkat pertanyaan seperti itu adalah polanya.
Contoh dari salah satu template yang sudah selesai.
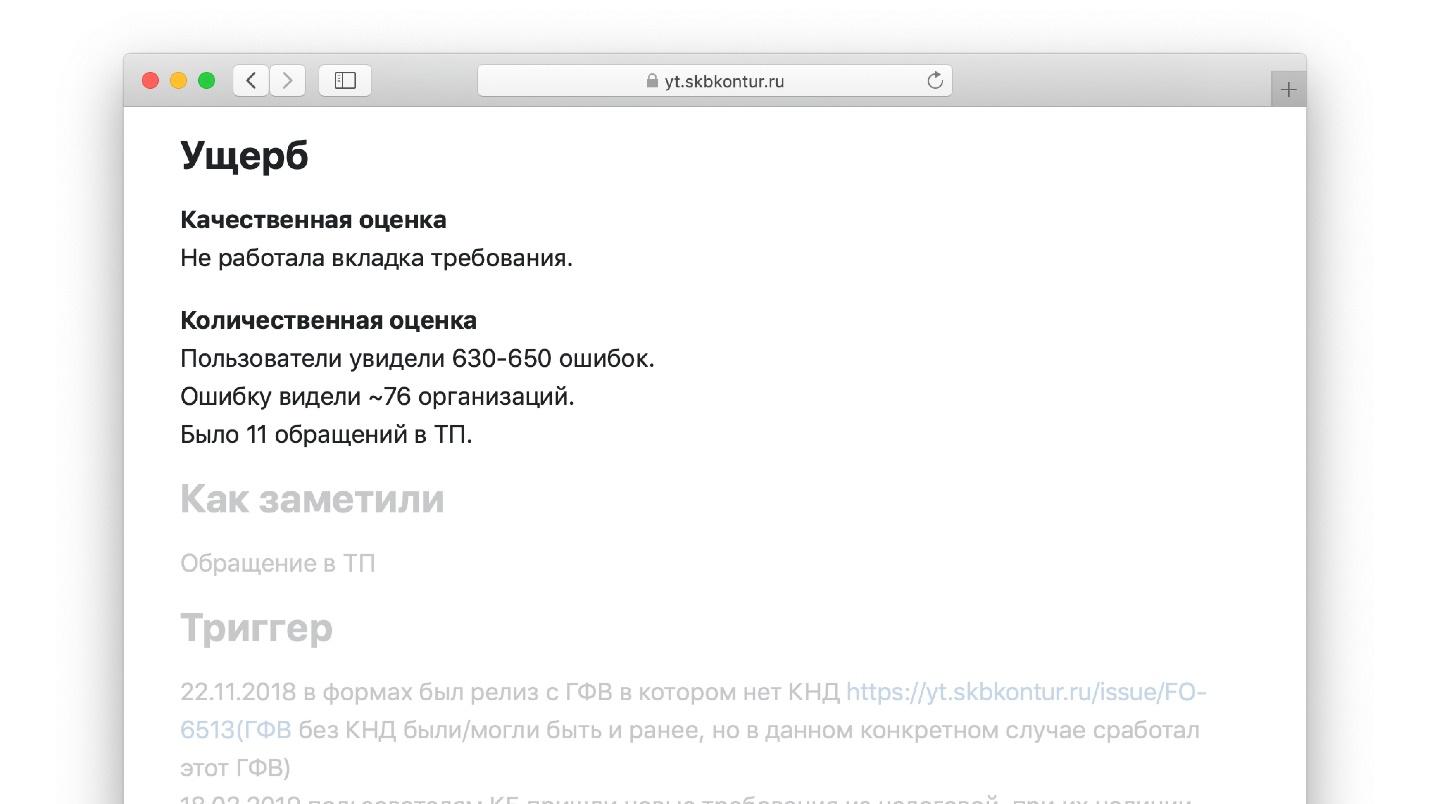
Tambahkan glosarium
Peretasan lain untuk laporan kecelakaan, yang tidak saya lihat di buku bersama guru. Saat menulis laporan, nyaman untuk menggunakan istilah yang Anda ketahui dengan baik. Misalnya, jika saya bekerja dengan Graphite, di mana metrik disimpan, saya tahu apa itu "relay". Tetapi insinyur yang akan membaca laporan dalam setahun mungkin tidak akrab dengan istilah tersebut. Sepertinya dia tidak akan bisa membaca laporan, yang terdiri dari kata-kata yang tidak dikenalnya. Di sisi lain, jika setiap istilah dan definisi terus-menerus dikunyah di dalam laporan, kemalasan akan membuatnya takut dan laporan tidak akan selesai.
Tulis glosarium kecil yang menjelaskan semua istilah yang digunakan dalam laporan.
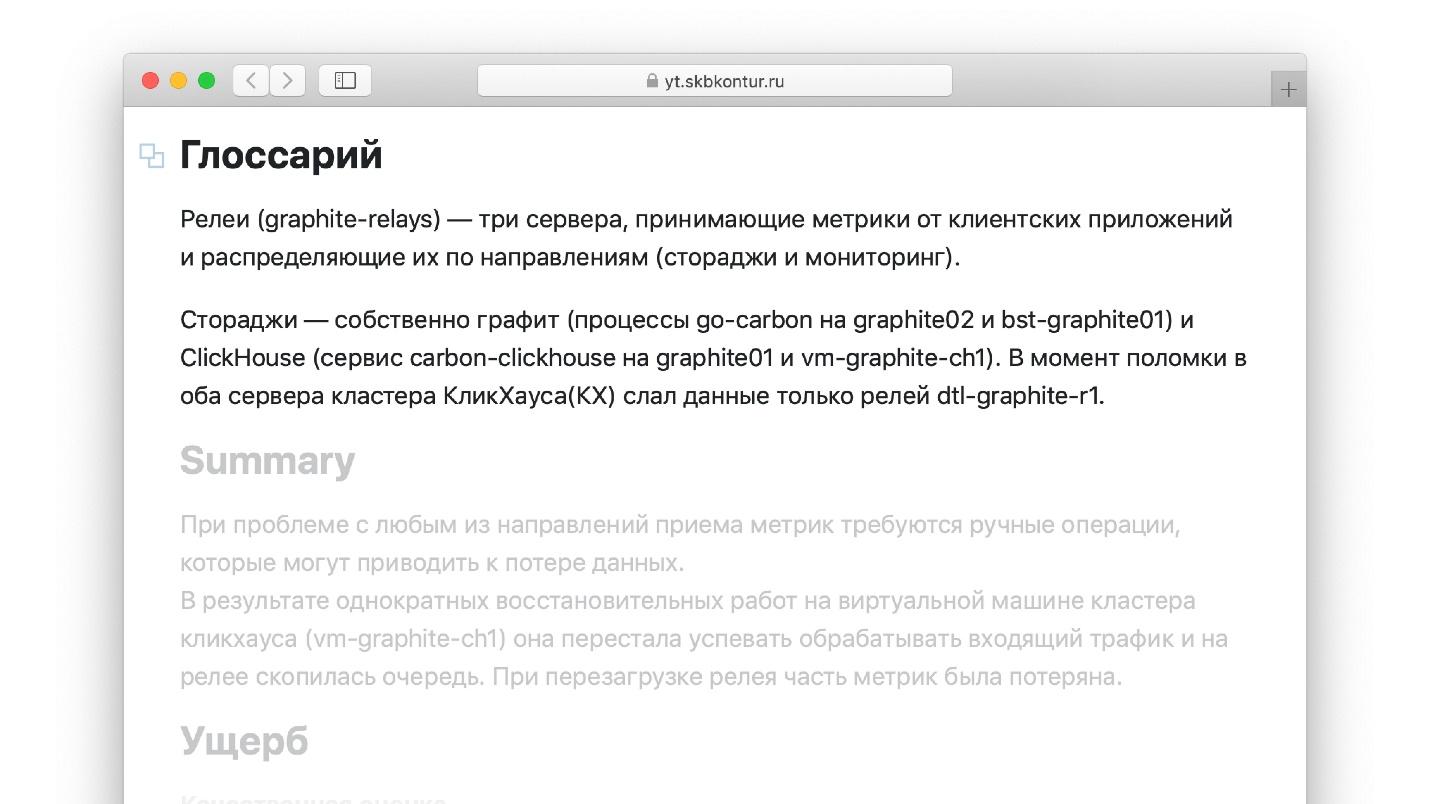
Salin semua artefak
Jika Anda melampirkan artefak ke laporan: snapshot di Grafana, riwayat pesan dalam obrolan, di mana insiden dianalisis dengan insinyur lain, buat salinannya. Metrik memiliki kemampuan untuk "berputar", dan obrolan berubah. Setahun yang lalu Anda berada di Slack, sekarang di Telegram - tautan obrolan sudah usang dan tidak berfungsi, dan metrik retensi akan jatuh - disimpan selama setahun.
Salin artefak - peretasan kehidupan ini memudahkan untuk mengisi laporan.
Keberatan No 3: Tidak Ada Yang Akan Membaca
Pertanyaan terbesar dan tidak dapat dipahami yang diajukan oleh para insinyur adalah: "Siapa yang akan membaca laporan ini?" Misalkan saya mengatasi kemalasan dan menulis kronologi peristiwa selama kecelakaan itu. Kemudian dia mengumpulkan kekuatannya dan menambahkan laporan beberapa halaman tentang apa yang terjadi dan penyebab kecelakaan itu. Tetapi jika tidak ada pemahaman tentang siapa yang akan membaca semua ini dan siapa yang akan mendapat manfaat, maka tidak ada keinginan untuk mengisi laporan.
Post-mortem adalah umpan balik dalam proses peningkatan berkelanjutan dari proses pembangunan.
Dalam buku guru mana pun, misalnya, dalam
Buku Pegangan Insiden Atlassian , tertulis bahwa sesuai dengan hasil setiap post-mortem, diperlukan:
- merumuskan tugas-tugas dalam pengembangan;
- buat tugas di bugtracker dari mana pengembang Anda akan mengambilnya;
- letakkan tautan dari post-mortem ke tugas-tugas ini.
Umpan balik ditutup : di sini adalah post-mortem, di sini di dalamnya
item tindakan - tugas yang perlu diselesaikan agar kecelakaan tidak terjadi lagi. Tugas jatuh ke dalam tumpukan tim, tim mengembangkannya, meluncurkan - lagi fakap dan post-mortem. Roda samsara telah ditutup.
Inilah yang semua guru gabungkan. Tidak ada yang perlu diperdebatkan - manfaatnya jelas.
Contoh tugas item tugas dari post-mortem nyata.
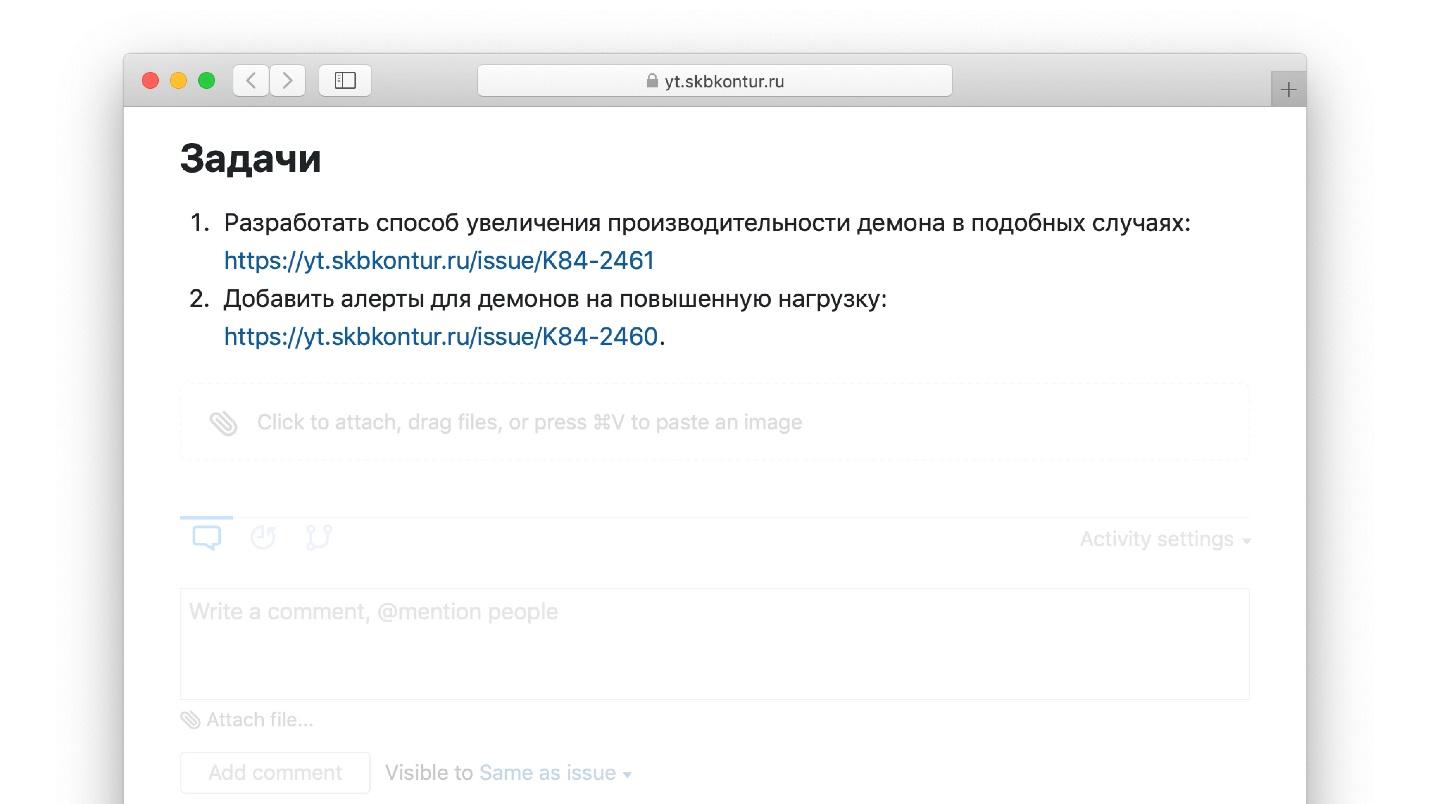
Tapi kami di Kontur menambahkan analis untuk ini.
Analisis sofa
Kami biasa menganalisis kejadian itu secara terpisah. Kegagalan terjadi sendiri dalam satu tim, dalam satu sistem hosting - ada yang rusak, kami memperbaikinya.
Tetapi ada banyak insiden. Selama tiga tahun terakhir, lebih dari 1.000 laporan insiden telah terakumulasi di sirkuit. Saya ingin tahu apakah mungkin mendapatkan manfaat dari seluruh kumpulan laporan yang terakumulasi, dan tidak hanya dari masing-masing individu. Apakah mungkin atas dasar mereka untuk menghitung statistik sistem dan melihat apa yang harus diperbaiki dalam sistem secara keseluruhan.
Tim infrastruktur khusus bekerja di Kontur, yang bergerak dalam analisis post-mortem dan menerbitkan hasil dan kesimpulan berdasarkan seluruh massa laporan yang dikumpulkan. Kami menyebutnya "analitik sofa." Saya akan memberikan fragmen dari salah satu artikel tim, yang dipublikasikan di jaringan internal kami untuk karyawan.
Apa yang kami analisis dalam analisis sofa?
Durasi Fakap
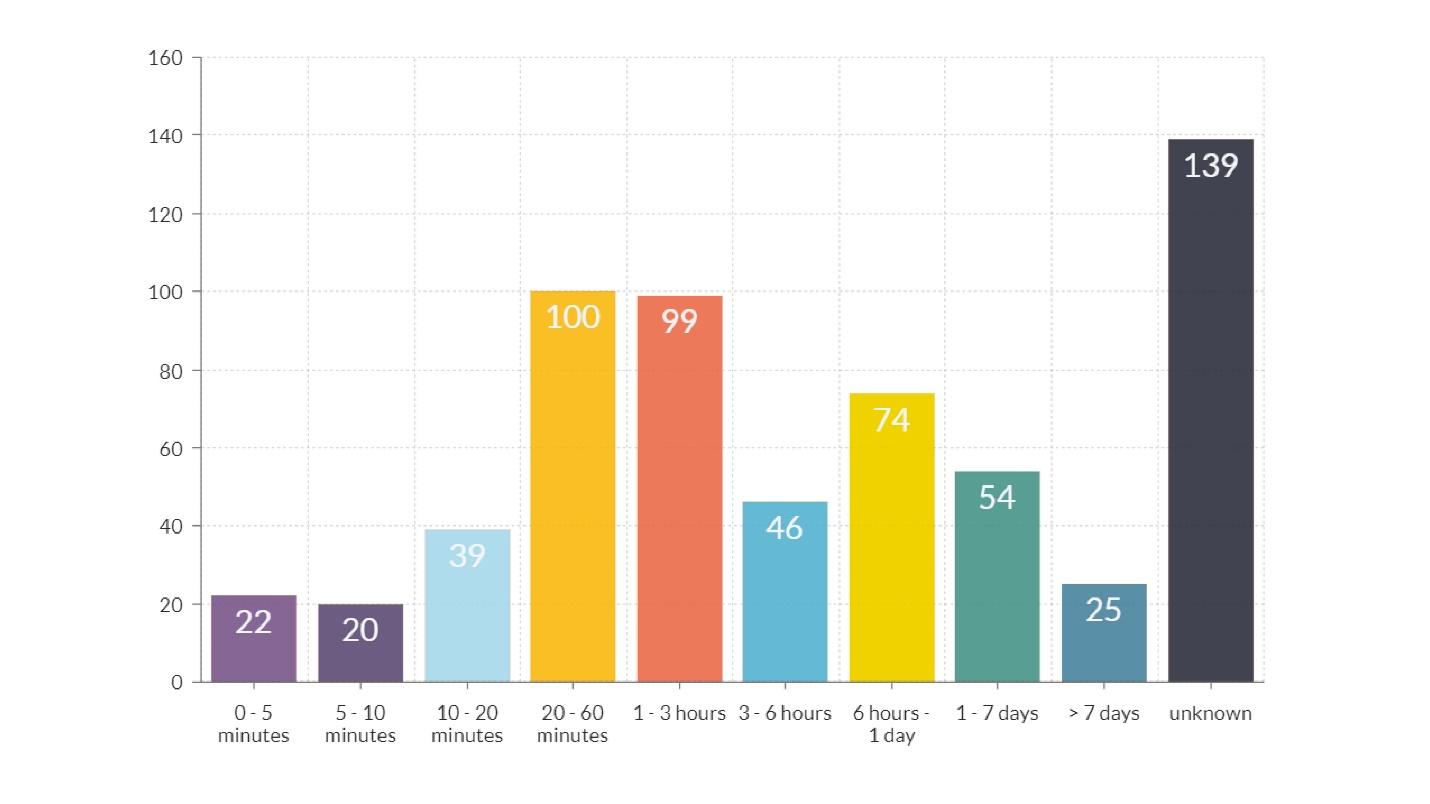 Dalam diagram, selain kolom terakhir, di mana waktu tidak diketahui, ada dua puncak yang lebih jelas.Durasi urutan satu jam
Dalam diagram, selain kolom terakhir, di mana waktu tidak diketahui, ada dua puncak yang lebih jelas.Durasi urutan satu jam - oranye dan bar merah. Sebagian besar waktu ini dihabiskan untuk mentransmisikan informasi tentang apa yang terjadi, mulai dari insinyur yang memperhatikan kecelakaan hingga insinyur yang tahu cara memperbaikinya.
Masalahnya adalah komunikasi .
Jika kami memperbaiki alat kami sehingga insinyur yang memperbaiki masalah menerima informasi lebih cepat, maka durasi fakap dan kerusakan dari mereka akan sangat berkurang. Ini adalah sesuatu yang tidak akan kita kenali dengan melihat setiap fakap secara individual.
Durasi sekitar 12 jam - kolom kuning. Penjelasan untuk fakta bahwa ada banyak fakap yang bertahan lebih dari 12 jam adalah sederhana: mereka meluncurkan rilis di malam hari, dan di pagi hari pengguna datang dan semuanya rusak. Kesimpulan dari apa yang harus dilakukan untuk mengurangi jumlah fakaps tersebut jelas.
Kerusakan kualitas

Kerusakan kualitatif dibagi menjadi beberapa kategori. 3 teratas termasuk:
- tidak dapat diaksesnya, kesalahan;
- rem, peningkatan latensi;
- terlihat perilaku yang salah.
Menurut analitik, sebagian besar kesalahan tersebut. Di satu sisi, ini adalah kabar baik. Tiga jenis kesalahan yang paling umum mudah dideteksi - kami menyesuaikan metrik dengan latensi dan jumlah kesalahan, dan dengan cepat memperhatikan hal-hal seperti itu.
Berita buruknya adalah bahwa ada sebagian besar kesalahan ini. Ini adalah kesalahan teknis yang sederhana, yang berarti bahwa kita dapat meningkatkan sesuatu dalam pengujian pipa, melakukan lebih banyak uji tekanan dan meningkatkan sistem pemantauan.
Pemicu
Inilah yang secara langsung menyebabkan kerusakan, yaitu, bukan akar penyebab kecelakaan, tetapi "sedotan terakhir": log memenuhi disk dan karena ini, semuanya pecah, dilepaskan - semuanya meledak.

Di tempat pertama adalah "pembaruan instalasi". Alasan ini memungkinkan kami untuk memahami di mana kami, sebagai tim infrastruktur, harus berinvestasi. Misalnya, untuk meningkatkan sistem penyebaran dan memperkenalkan penyebaran kenari. Ini adalah titik aktivitas yang akan memiliki dampak terbesar pada kualitas sistem kami.
Ini adalah poin dari semua analitik - untuk memahami di mana tim infrastruktur kecil harus berinvestasi saat ini dalam kondisi sumber daya yang terbatas.
Apa yang harus ditingkatkan - lansiran atau penerapan? Apa yang harus dilakukan - hosting atau keindahan grafik?
Berikut ini adalah wawasan bagus lainnya. Di tempat kedua adalah "penyebabnya tidak diketahui." Ini merupakan indikator pelaporan laporan insiden yang buruk.
Kemungkinan "pil"
Itu memungkinkan solusi teknis sederhana untuk mengurangi jumlah kecelakaan dari jenis tertentu. Misalnya, kita tahu bahwa hal terpenting yang mengurangi jumlah fakap adalah pemberitahuan dari sistem pemantauan. Jika ada lebih banyak peringatan dalam memantau peristiwa ini, berapa banyak insiden yang bisa kita cegah? Persentase menunjukkan berapa banyak:
- pada jumlah kesalahan HTTP dari klien - 10%;
- pada tampilan jenis kesalahan baru dalam log: instalasi, pengaturan notifikasi - 8%;
- pada sumber daya sistem: CPU, memori, disk, utas, GC - 6%.
Jika peringatan itu dikonfigurasi dengan benar, dan insinyur yang diinginkan menerima pemberitahuan tepat waktu, 24% dari insiden tidak akan terjadi atau akan memiliki durasi yang jauh lebih pendek. Kesimpulan ini dapat dibuat atas dasar analisis seluruh massa insiden.
Di sini saya sekali lagi akan mengiklankan sistem peringatan
Moira kami, yang terletak di Open Source.
Jika Anda memiliki Graphite, Anda dapat mengunduh dan menggunakannya. Saya berharap akan ada lebih sedikit insiden.
Rekomendasi
Rekomendasi organisasi yang dapat diikuti oleh tim, dan juga mengurangi jumlah kecelakaan. 3 teratas kami.
- Kesamaan situs tes dan pertempuran . 5% insiden terjadi karena fakta bahwa lokasi uji tidak cukup mirip dengan lokasi pertempuran.
- Kompatibilitas mundur dalam rilis . Rilis ini kempes, tidak kompatibel dengan yang sebelumnya, migrasi data muncul - 4% kesalahan.
- Penolakan rilis malam hari . Jika Anda berhenti menyebarkan rilis yang rusak, pada malam hari, 4% insiden lainnya akan hilang.
Saya menekankan bahwa ini bukan instruksi, tetapi cerita tentang bagaimana kami mengumpulkan analitik. Analitik Anda mungkin berbeda.
Bagaimana cara menulis
Jika Anda menyadari bahwa analitik kejadian adalah hal yang keren dan Anda perlu menulis laporan, saya akan memberi tahu Anda cara melakukannya.
Posting post-mortem dan tugas dalam satu pelacak bug
Di bugtracker, tidak seperti Google Docs atau Wiki, ada bidang yang tetap di mana Anda dapat mengatur serangkaian nilai. Ini memfasilitasi analisis statistik grafik nanti.
Di buku SRE, Google menyediakan templat di Google Documents tempat mereka menulis laporan dalam dokumen internal mereka. Saya tidak bisa membayangkan bagaimana kami dapat mengumpulkan analitik yang kami kumpulkan dari dokumen Google yang tidak terstruktur.
Kami menulis laporan dalam pelacak bug yang sama dengan tugas utama, karena kami dapat menghubungkan tugas dengan post-mortem. Mari kita melihat post-mortem dan segera melihat tugas-tugas yang ditutup, mana yang tidak, dan yang harus dilakukan.
Buat bidang khusus
Saya sudah bicara tentang bidang khusus. Kami memiliki yang berikut ini.
- Awal dan akhir fakap dapat dianalisis secara otomatis. Jika Anda menempatkan prangko waktu yang dapat dibaca mesin, Anda dapat merencanakan durasi fakap tersebut.
- Awal dan akhir investigasi.
- Pemicu Siapkan daftar pemicu drop-down, lebih nyaman.
- Seperti dicatat.
- Kerusakan kuantitatif dan kualitatif.
- Tim dan layanan yang terpengaruh.
Semua data dari bidang khusus memungkinkan Anda memahami cara kerja infrastruktur Anda.
Contoh laporan insiden lengkap kami.

Bidang kolom kanan hanya diisi melalui pemilihan dari daftar drop-down.
Kumpulkan tim insinyur yang peduli dengan kualitas
Untuk mendapatkan laporan yang akan membantu Anda memahami bagaimana mengembangkan infrastruktur Anda, Anda akan membutuhkan orang-orang yang peduli dengan kualitas layanan Anda. Tidak harus insinyur yang terlibat dalam analisis purna waktu post-mortem saja. Adalah penting bahwa ini adalah orang-orang yang sangat peduli dengan apa yang terjadi. Dari waktu ke waktu mereka akan berkumpul, menganalisis seluruh massa insiden, menulis artikel besar dan membawa manfaat - tutup cincin umpan balik.
Tim kami disebut tim-Q - dari kata "Kualitas". Ini memiliki 3 orang - salah satu insinyur paling berbakat dari perusahaan yang bekerja di bidang infrastruktur.
Total
Baca guru - artikel John Allspaw dan buku manajemen kejadian:
Rekayasa Keandalan Situs ,
Proses PagerDuty Post-Mortem ,
Atlassian Incident Handbook .
Dan ketika Anda datang kerja besok,
ambil saja
langkah pertama :
- memulai proyek untuk fakaps di bugtracker di mana Anda melakukan tugas;
- ambil templat apa pun - jangan mencoba untuk menulis milik Anda, ambil milik kami , atau dari Google di SRE;
- ketika sesuatu meledak, tulis saja.
Pada saat Anda menulis laporan pertama, kedua, ketiga, Anda tidak akan memiliki analitik yang indah dengan kolom multi-warna. Tetapi setelah satu atau dua tahun, ketika data telah terkumpul, Anda melihat ke belakang dan berterima kasih pada diri sendiri untuk langkah pertama.
Kami harap, maka Anda akan mengingat dan berterima kasih kepada Alexei atas kisah pengalaman seperti itu. Dan kami, pada gilirannya, akan mencoba untuk mengumpulkan laporan berguna baru ke dalam program DevOpsConf , rekomendasi dari mana Anda dapat pergi dan mendaftar. Konferensi ini akan diadakan 30–1 September 2019 , hingga 20 Agustus kami masih menunggu aplikasi dari pendukung DevOps, tetapi 12 telah disetujui, artinya kompetisi akan semakin tinggi mendekati tenggat waktu.
Jika Anda ingin berbagi pengalaman, buat keputusan dan kirim abstrak Anda . Jika Anda ingin menerima berita program - berlangganan buletin dan saluran telegram kami .