Pada akhir Juni, sebuah tim dari Universitas Carnegie Mellon menunjukkan kepada kami XLNet, segera menyusun
publikasi ,
kode , dan model yang sudah jadi (
XLNet-Large , Cased: 24-layer, 1024-hidden, 16-heads). Ini adalah model pra-terlatih untuk menyelesaikan berbagai masalah pemrosesan bahasa alami.
Dalam publikasi, mereka segera menunjukkan perbandingan model mereka dengan
BERT Google. Mereka menulis bahwa XLNet lebih unggul daripada BERT dalam banyak tugas. Dan menunjukkan hasil dalam 18 tugas canggih.
BERT, XLNet, dan Transformer
Salah satu tren terbaru dalam pembelajaran yang mendalam adalah Transfer Learning. Kami melatih model untuk memecahkan masalah sederhana pada sejumlah besar data, dan kemudian kami menggunakan model pra-terlatih ini, tetapi untuk memecahkan masalah lain yang lebih spesifik. BERT dan XLNet hanyalah jaringan pra-terlatih yang dapat digunakan untuk memecahkan masalah pemrosesan bahasa alami.
Model-model ini mengembangkan ide
transformer - pendekatan yang saat ini dominan untuk membangun model untuk bekerja dengan urutan. Sangat detail dan dengan contoh kode pada transformer dan mekanisme Attention ditulis dalam
The Annotated Transformer .
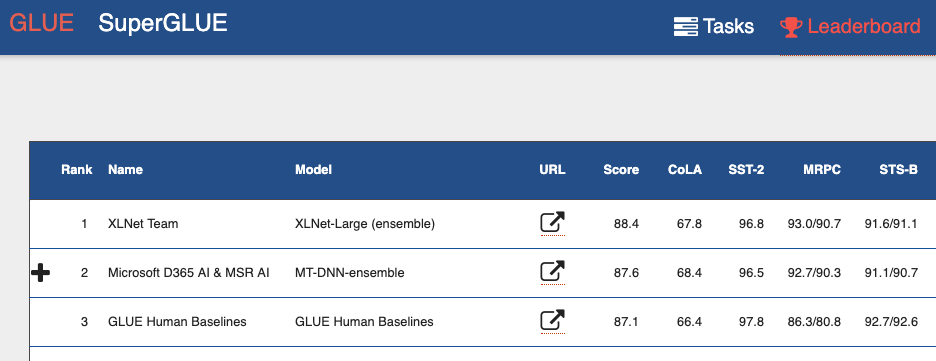
Jika Anda melihat
leaderboard benchmark General Language Understanding Evaluation (GLUE) , maka dari atas Anda dapat melihat banyak model berdasarkan transformator. Termasuk kedua model yang menunjukkan hasil lebih baik daripada manusia. Kita dapat mengatakan bahwa dengan transformer kita menyaksikan revolusi kecil dalam pemrosesan bahasa alami.
Kerugian BERT
BERT adalah auto-encoder (autoencoder, AE). Dia menyembunyikan dan merusak beberapa kata dalam urutan dan mencoba mengembalikan urutan kata asli dari konteks.
Ini menyebabkan kelemahan model:
- Setiap kata yang tersembunyi diprediksi secara individual. Kami kehilangan informasi tentang kemungkinan hubungan antara kata-kata yang di-mask. Artikel tersebut memberikan contoh yang disebut "New York." Jika kami mencoba secara independen memprediksi kata-kata ini dalam konteks, kami tidak akan memperhitungkan hubungan di antara mereka.
- Ketidakkonsistenan antara fase pelatihan model BERT dan penggunaan model BERT yang telah dilatih sebelumnya. Ketika kami melatih model - kami memiliki kata-kata tersembunyi (token) [MASKER], ketika kami menggunakan model yang sudah dilatih sebelumnya, kami belum menyediakan token tersebut ke input.
Namun, terlepas dari masalah ini, BERT menunjukkan hasil yang canggih pada banyak tugas pemrosesan bahasa alami.
Fitur XLNet
XLNet adalah pemodelan bahasa autoregresif, AR LM. Dia mencoba memprediksi token berikutnya dari urutan yang sebelumnya. Dalam model autoregresif klasik, urutan kontekstual ini diambil secara independen dari dua arah string asli.
XLNet menggeneralisasikan metode ini dan membentuk konteks dari berbagai tempat dalam urutan sumber. Bagaimana dia melakukannya? Dia mengambil semua (dalam teori) kemungkinan permutasi dari urutan asli dan memprediksi setiap token dalam urutan dari yang sebelumnya.
Berikut ini adalah contoh dari artikel bagaimana x3 token dari berbagai permutasi dari urutan asli diprediksi.
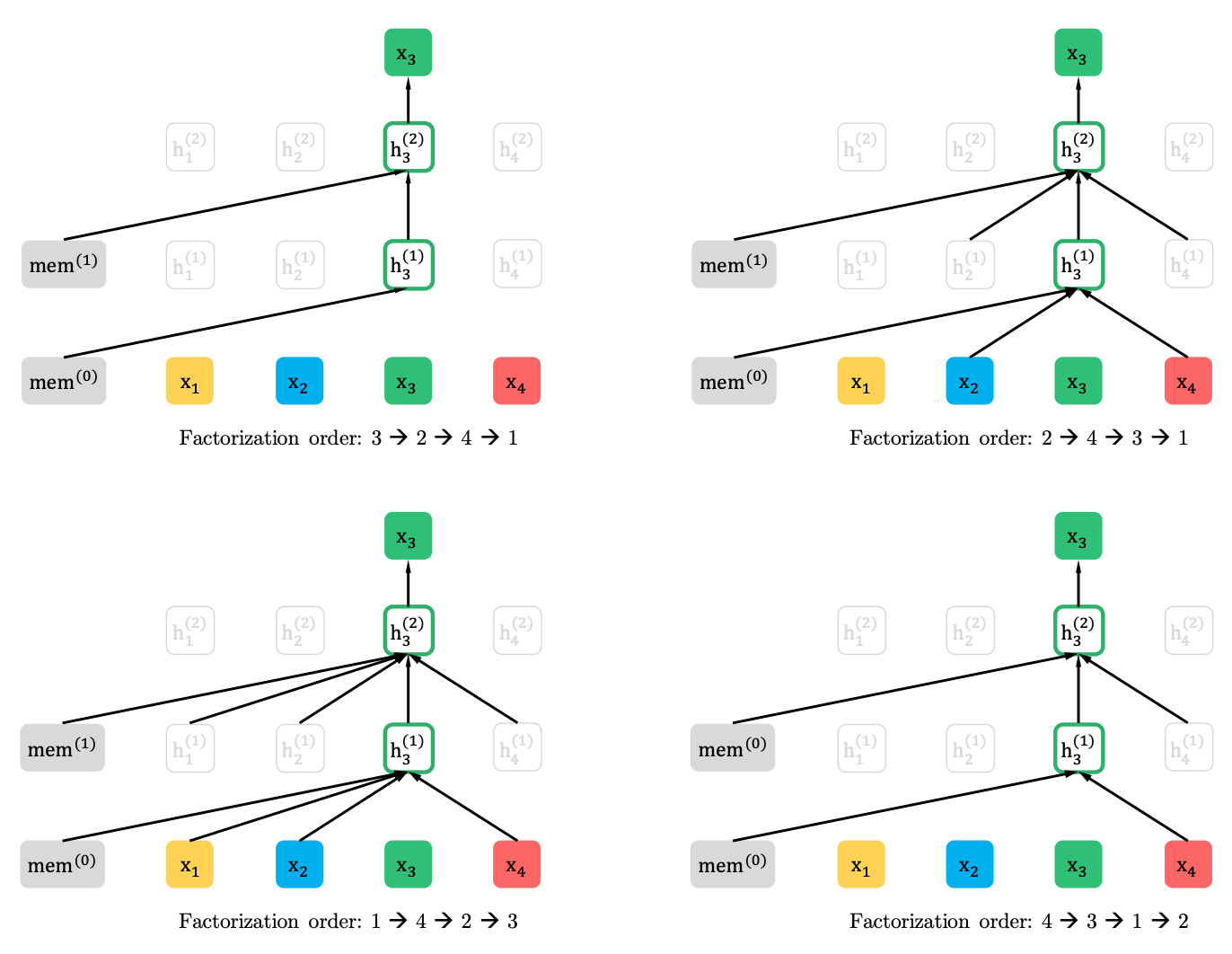
Selain itu, konteks bukanlah kantong kata-kata. Informasi tentang urutan awal token juga diberikan ke model.
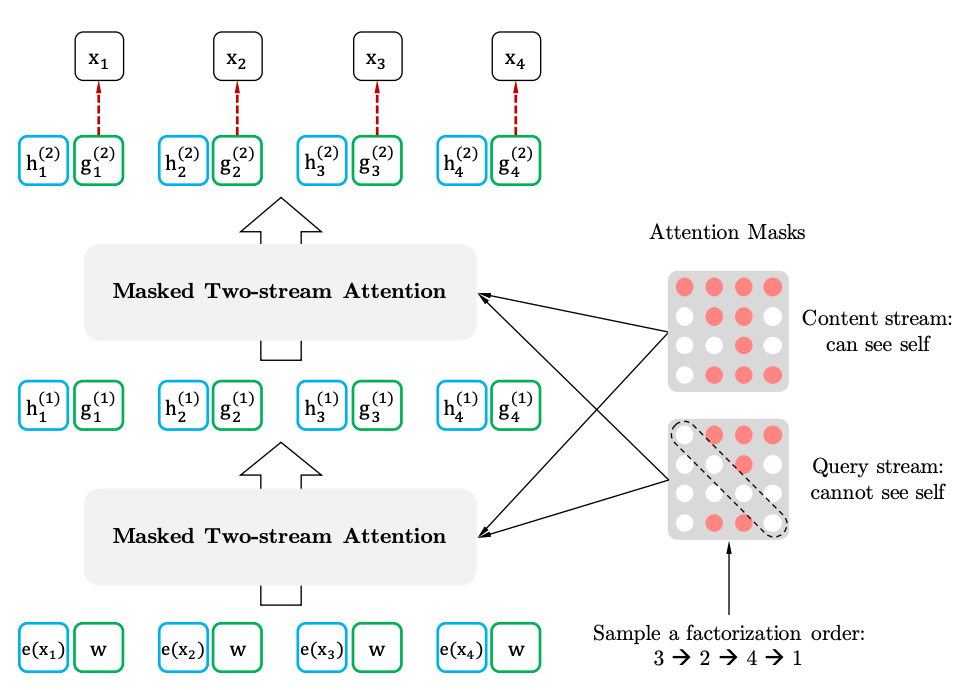
Jika kita menggambar analogi dengan BERT, ternyata kita tidak menyembunyikan token terlebih dahulu, melainkan menggunakan set token tersembunyi yang berbeda untuk permutasi yang berbeda. Pada saat yang sama, masalah kedua BERT menghilang - kurangnya token tersembunyi saat menggunakan model pra-terlatih. Dalam kasus XLNet, seluruh rangkaian, tanpa topeng, sudah dimasukkan.
Dari mana XL berasal dari namanya. XL - karena XLNet menggunakan mekanisme Perhatian dan ide-ide dari model Transformer-XL. Meskipun bahasa jahat mengklaim bahwa XL mengisyaratkan jumlah sumber daya yang dibutuhkan untuk melatih jaringan.
Dan tentang sumber daya. Di Twitter, mereka memposting
perhitungan berapa biaya untuk melatih jaringan dengan parameter dari artikel. Ternyata 245.000 dolar. Benar, kemudian seorang insinyur dari Google datang dan
mengoreksi bahwa artikel tersebut menyebutkan 512 chip TPU, empat di antaranya ada di perangkat. Artinya, biayanya sudah 62.440 dolar, atau bahkan 32.720 dolar, mengingat 512 core, yang juga disebutkan dalam artikel.
XLNet vs BERT
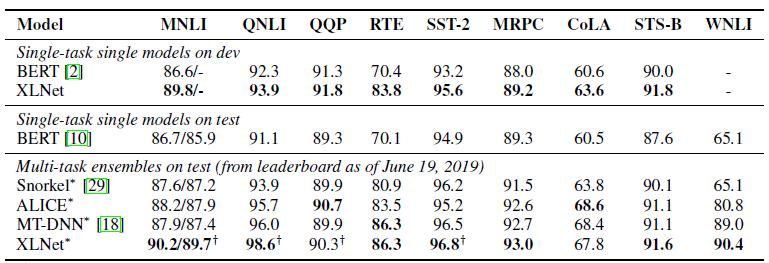
Sejauh ini, hanya satu model pra-terlatih untuk Bahasa Inggris yang telah disiapkan untuk artikel (XLNet-Large, Cased). Tetapi artikel itu juga menyebutkan percobaan dengan model yang lebih kecil. Dan dalam banyak tugas, model XLNet menunjukkan hasil yang lebih baik dibandingkan dengan model BERT serupa.
Munculnya BERT dan terutama model pra-pelatihan menarik banyak perhatian peneliti dan menyebabkan sejumlah besar karya terkait. Sekarang di sini adalah XLNet. Sangat menarik untuk melihat apakah akan menjadi standar de facto dalam NLP untuk beberapa waktu, atau sebaliknya akan memacu para peneliti dalam mencari arsitektur baru dan pendekatan untuk memproses bahasa alami.