Pendahuluan
Beberapa waktu yang lalu, saya perlu menyelesaikan masalah segmentasi titik dalam Point Cloud (awan titik adalah data yang diperoleh dari lidar).
Contoh data dan tugas yang harus diselesaikan:
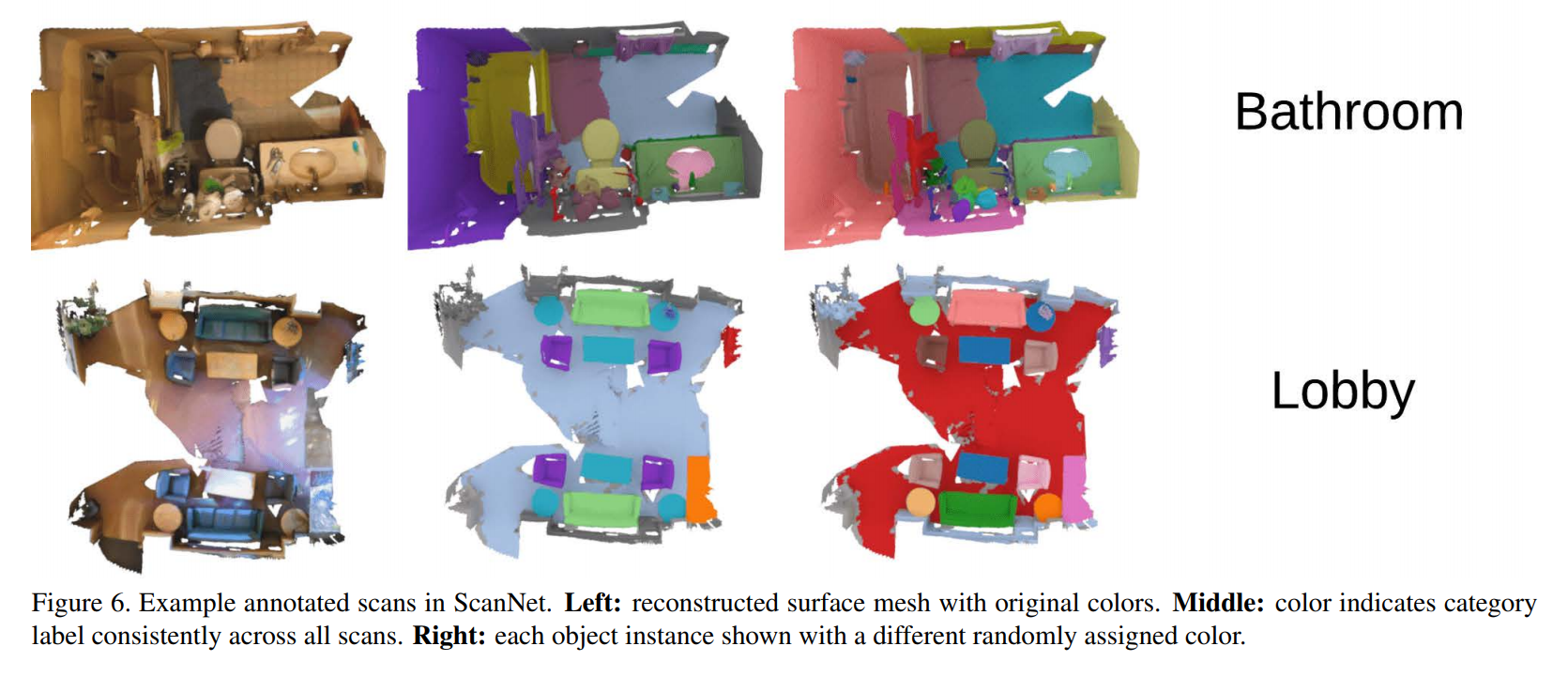
Pencarian untuk ikhtisar umum dari metode yang ada tidak berhasil, jadi saya harus mengumpulkan informasi sendiri. Anda dapat melihat hasilnya: di sini dikumpulkan artikel yang paling penting dan menarik (menurut saya) selama beberapa tahun terakhir. Semua model yang dipertimbangkan menyelesaikan masalah segmentasi awan titik (yang termasuk dalam kelas mana setiap titik).
Artikel ini akan berguna bagi mereka yang akrab dengan jaringan saraf dan ingin memahami bagaimana menerapkannya pada data yang tidak terstruktur (misalnya, grafik).
Kumpulan data yang ada
Sekarang di domain publik ada dataset berikut tentang topik ini:
Fitur kerja dengan Point Clouds
Jaringan saraf telah datang ke daerah ini baru-baru ini. Dan arsitektur standar seperti jaringan yang sepenuhnya terhubung dan konvolusional tidak berlaku untuk menyelesaikan masalah ini. Mengapa
Karena urutan poin tidak penting di sini. Objek adalah sekumpulan titik dan tidak masalah urutan urutannya. Jika setiap piksel memiliki tempat pada gambar, maka kita dapat dengan aman mencampurkan titik-titik dan objek tidak berubah. Hasil dari jaringan saraf standar, sebaliknya, tergantung pada lokasi data. Jika Anda mencampur piksel ke dalam gambar, Anda mendapatkan objek baru.
Sekarang mari kita lihat bagaimana jaringan saraf diadaptasi untuk memecahkan masalah ini.
Artikel Paling Penting
Tidak banyak arsitektur dasar di daerah ini. Jika Anda bermaksud untuk bekerja dengan grafik atau data yang tidak terstruktur, Anda perlu memiliki gagasan tentang model-model berikut:
Mari kita pertimbangkan secara lebih detail.
- PointNet: Pembelajaran mendalam tentang Point Sets untuk Klasifikasi dan Segmentasi 3D
Pelopor dalam bekerja dengan data yang tidak terstruktur.
- bagaimana mereka memutuskan: Artikel ini menjelaskan dua model: untuk segmentasi poin dan klasifikasi suatu objek. Bagian umum terdiri dari blok-blok berikut:
- jaringan untuk menentukan transformasi (terjemahan sistem koordinat), yang kemudian berlaku untuk semua poin
- transformasi diterapkan ke setiap titik secara individual (persepsi reguler)
- maxpooling, yang menggabungkan informasi dari berbagai titik dan membuat vektor fitur global untuk seluruh objek.
- maka perbedaan antara model dimulai:
- model klasifikasi: vektor fitur global pergi ke input dari lapisan yang terhubung sepenuhnya untuk menentukan kelas cloud titik keseluruhan
- model untuk segmentasi: vektor fitur global dan fitur yang dihitung untuk setiap titik pergi ke input dari lapisan yang terhubung penuh yang mendefinisikan kelas untuk setiap titik.
- kode

- PointNet ++: Pembelajaran Fitur Hirarki Dalam pada Point Sets di Metric Space
Orang-orang yang sama dari Stanford yang menggambarkan PointNet.
- bagaimana mereka memutuskan: pointNet diterapkan secara rekursif ke sub-cloud yang lebih kecil, mirip dengan jaringan konvolusi. Artinya, kubus membagi ruang, PointNet diterapkan untuk masing-masing, kemudian kubus baru terdiri dari kubus ini. Ini memungkinkan Anda untuk menyoroti tanda-tanda lokal bahwa versi sebelumnya dari jaringan itu hilang.
- kode


Artikel berdasarkan PointNet dan PointNet ++:
Sebagian besar artikel berbeda dalam hal jumlah kesalahan atau kedalaman dan kompleksitas blok kompleks.

- Ketahui Apa Yang Dilakukan Tetangga Anda: Segmentasi 3D Semantik Point Clouds
- bagaimana mereka memutuskan: Pada awalnya, mereka mempertimbangkan tanda-tanda untuk waktu yang lama, lebih rumit daripada di PointNet, dengan banyak koneksi residual, dan jumlah, tetapi secara umum - hal yang sama. Sedikit perbedaan - mereka menghitung tanda untuk setiap titik dalam koordinat global dan lokal.
Perbedaan utama di sini adalah kesalahan menghitung lagi. Ini bukan crossentropy standar, tetapi jumlah dari dua kesalahan:
- kehilangan jarak berpasangan - titik dari satu objek harus lebih dekat dari τ_near dan titik dari objek yang berbeda harus lebih panjang dari τ_far .
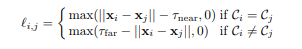
- loss centroid - poin dari satu objek harus dekat satu sama lain
Artikel berbasis DGCNN:
DGCNN diterbitkan baru-baru ini (2018), jadi ada beberapa artikel berdasarkan arsitektur ini. Saya ingin menarik perhatian Anda pada satu hal:
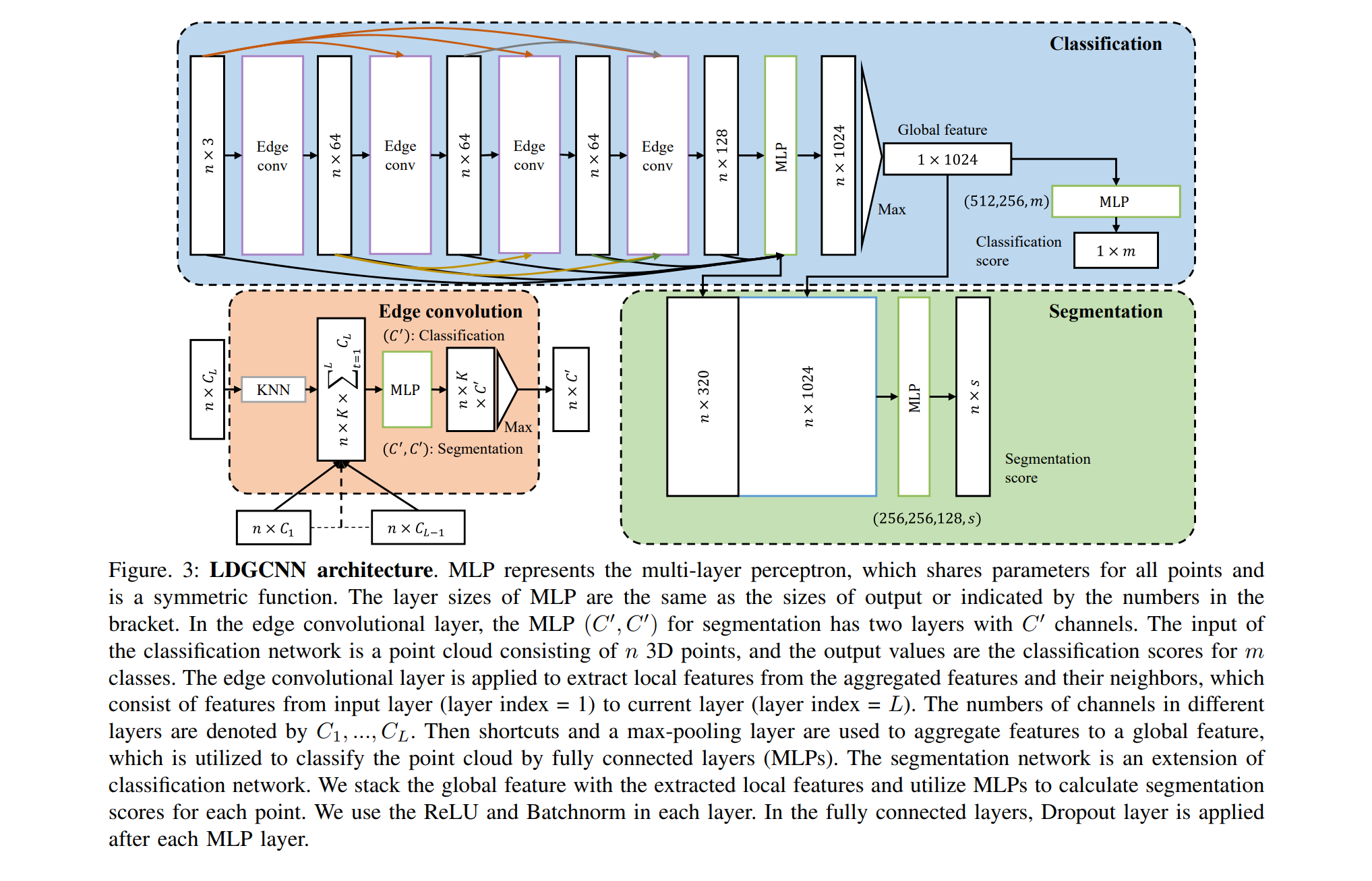
Kesimpulan
Di sini Anda dapat menemukan informasi singkat tentang metode modern untuk menyelesaikan masalah klasifikasi dan segmentasi di Point Clouds. Ada dua model utama (PointNet ++, DGCNN), modifikasi yang sekarang digunakan untuk menyelesaikan masalah ini. Paling sering, untuk modifikasi, fungsi kesalahan diubah dan arsitektur ini rumit dengan menambahkan lapisan dan tautan.