GitHub meng-host lebih dari 300 bahasa pemrograman - dari bahasa yang umum digunakan seperti Python, Jawa, dan Javascript ke bahasa esoterik seperti
Befunge , hanya diketahui oleh komunitas yang sangat kecil.
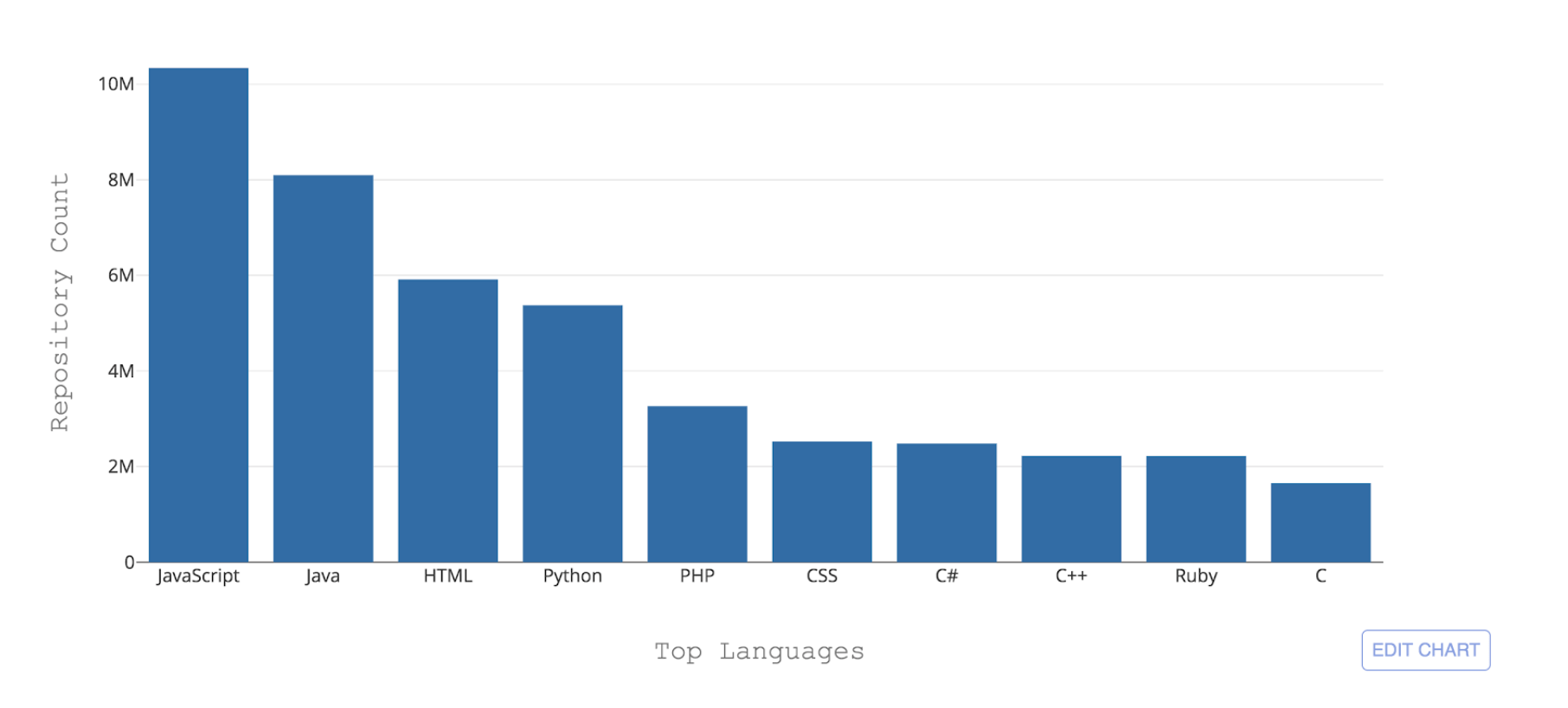 Gambar 1: 10 bahasa pemrograman teratas yang dihosting oleh GitHub dengan jumlah repositori
Gambar 1: 10 bahasa pemrograman teratas yang dihosting oleh GitHub dengan jumlah repositoriSalah satu tantangan penting yang dihadapi GitHub adalah untuk dapat mengenali bahasa-bahasa yang berbeda ini. Ketika beberapa kode didorong ke repositori, penting untuk mengenali jenis kode yang ditambahkan untuk keperluan pencarian, peringatan kerentanan keamanan, dan penyorotan sintaksis - dan untuk menunjukkan distribusi konten repositori kepada pengguna.
Ahli bahasa adalah alat yang saat ini kami gunakan untuk mendeteksi bahasa pengkodean di GitHub. Ahli bahasa aplikasi berbasis Ruby yang menggunakan berbagai strategi untuk deteksi bahasa, meningkatkan konvensi penamaan dan ekstensi file dan juga mempertimbangkan modelines Vim atau Emacs, serta konten di bagian atas file (shebang). Ahli bahasa menangani disambiguasi bahasa melalui heuristik dan, gagal itu, melalui pengklasifikasi Naif Bayes dilatih pada sampel data kecil.
Meskipun Linguist melakukan pekerjaan yang baik dengan membuat prediksi bahasa tingkat file (akurasi 84%), kinerjanya menurun secara signifikan ketika file menggunakan konvensi penamaan yang tidak terduga dan, yang terpenting, ketika ekstensi file tidak disediakan. Ini membuat Ahli Bahasa tidak cocok untuk konten seperti GitHub Intisari atau cuplikan kode di dalam README, masalah, dan permintaan tarik.
Untuk membuat deteksi bahasa lebih kuat dan dapat dipelihara dalam jangka panjang, kami mengembangkan classifier pembelajaran mesin bernama Octo Lingua berdasarkan arsitektur Jaringan Syaraf Tiruan (JST) yang dapat menangani prediksi bahasa dalam skenario yang rumit. Versi model saat ini dapat membuat prediksi untuk 50 bahasa teratas yang diselenggarakan oleh GitHub dan melampaui Linguist dalam hal akurasi dan kinerja.
Mur dan Baut Dibalik OctoLingua
OctoLingua dibangun dari awal menggunakan Python, Keras dengan backend TensorFlow - dan dibuat agar akurat, kuat, dan mudah dirawat. Di bagian ini, kami menjelaskan sumber data kami, arsitektur model, dan tolok ukur kinerja untuk OctoLingua. Kami juga menjelaskan apa yang diperlukan untuk menambahkan dukungan untuk bahasa baru.
Sumber data
Versi OctoLingua saat ini dilatih tentang file yang diambil dari
Rosetta Code dan dari serangkaian repositori kualitas internal crowdsourced. Kami membatasi bahasa kami disetel ke 50 bahasa teratas yang dihosting di GitHub.
Rosetta Code adalah dataset pemula yang sangat baik karena mengandung kode sumber untuk tugas yang sama diekspresikan dalam bahasa pemrograman yang berbeda. Misalnya, tugas menghasilkan
urutan Fibonacci dinyatakan dalam C, C ++, CoffeeScript, D, Java, Julia, dan banyak lagi. Namun, cakupan antar bahasa tidak seragam di mana beberapa bahasa hanya memiliki beberapa file dan beberapa file terlalu sedikit populasinya. Oleh karena itu, menambah rangkaian pelatihan kami dengan beberapa sumber tambahan diperlukan dan secara substansial meningkatkan cakupan dan kinerja bahasa.
Proses kami untuk menambahkan bahasa baru sekarang sepenuhnya otomatis. Kami secara pemrograman mengumpulkan kode sumber dari repositori publik di GitHub. Kami memilih repositori yang memenuhi kriteria kualifikasi minimum seperti memiliki jumlah garpu minimum, mencakup bahasa target dan mencakup ekstensi file tertentu. Untuk tahap pengumpulan data ini, kami menentukan bahasa utama repositori menggunakan klasifikasi dari Linguist.
Fitur: meningkatkan pengetahuan sebelumnya
Secara tradisional, untuk masalah klasifikasi teks dengan Neural Networks, arsitektur berbasis memori seperti Recurrent Neural Networks (RNN) dan Long Short Term Memory Networks (LSTM) sering digunakan. Namun, mengingat bahwa bahasa pemrograman memiliki perbedaan dalam kosa kata, gaya komentar, ekstensi file, struktur, gaya impor perpustakaan dan perbedaan kecil lainnya, kami memilih pendekatan yang lebih sederhana yang memanfaatkan semua informasi ini dengan mengekstraksi beberapa fitur yang relevan dalam bentuk tabel untuk diumpankan ke classifier kami. Fitur yang saat ini diekstraksi adalah sebagai berikut:
- Lima karakter khusus teratas per file
- 20 token teratas per file
- Ekstensi file
- Kehadiran karakter khusus tertentu yang biasa digunakan dalam file kode sumber seperti titik dua, kurung kurawal, dan titik koma
Model Jaringan Syaraf Tiruan (JST)
Kami menggunakan fitur di atas sebagai input ke Jaringan Syaraf Tiruan dua lapis yang dibangun menggunakan Keras dengan backend Tensorflow.
Diagram di bawah ini menunjukkan bahwa langkah ekstraksi fitur menghasilkan input tabel n-dimensi untuk classifier kami. Ketika informasi bergerak di sepanjang lapisan jaringan kami, ia diatur oleh dropout dan pada akhirnya menghasilkan output 51-dimensi yang mewakili probabilitas yang diprediksi bahwa kode yang diberikan ditulis dalam masing-masing dari 50 bahasa GitHub teratas ditambah probabilitas bahwa itu tidak tertulis di salah satu dari mereka.
Gambar 2: Struktur JST model awal kami (50 bahasa + 1 untuk "lainnya")Kami menggunakan 90% dari dataset kami untuk pelatihan selama kurang lebih delapan zaman. Selain itu, kami menghapus persentase ekstensi file dari data pelatihan kami pada langkah pelatihan, untuk mendorong model untuk belajar dari kosakata file, dan tidak overfit pada fitur ekstensi file, yang sangat prediktif.
Tolok ukur kinerja
OctoLingua vs Ahli bahasaPada Gambar 3, kami menunjukkan
Skor F1 (rata-rata harmonis antara presisi dan recall) dari OctoLingua dan Linguist yang dihitung pada set tes yang sama (10% dari sumber data awal kami).
Di sini kami menunjukkan tiga tes. Tes pertama adalah dengan set tes yang tidak tersentuh dengan cara apa pun. Tes kedua menggunakan set file tes yang sama dengan informasi ekstensi file dihapus dan tes ketiga juga menggunakan set file yang sama tetapi kali ini dengan ekstensi file diacak sehingga membingungkan pengelompokkan (misalnya, file Java mungkin memiliki ". txt "ekstensi dan file Python mungkin memiliki ekstensi" .java ").
Intuisi di balik pengacakan atau menghapus ekstensi file dalam set pengujian kami adalah untuk menilai kekokohan OctoLingua dalam mengklasifikasikan file ketika fitur utama dihapus atau menyesatkan. Penggolong yang tidak terlalu bergantung pada ekstensi akan sangat berguna untuk mengklasifikasikan intisari dan cuplikan, karena dalam kasus-kasus tersebut adalah umum bagi orang-orang untuk tidak memberikan informasi ekstensi yang akurat (misalnya, banyak intisari terkait kode memiliki ekstensi .txt).
Tabel di bawah ini menunjukkan bagaimana OctoLingua mempertahankan kinerja yang baik dalam berbagai kondisi, menunjukkan bahwa model belajar terutama dari kosakata kode, daripada dari informasi meta (yaitu ekstensi file), sedangkan Ahli Bahasa gagal segera setelah informasi tentang ekstensi file diubah.
Gambar 3: Kinerja OctoLingua vs. Ahli bahasa pada set tes yang samaEfek menghapus ekstensi file selama waktu pelatihanSeperti disebutkan sebelumnya, selama waktu pelatihan kami menghapus persentase ekstensi file dari data pelatihan kami untuk mendorong model untuk belajar dari kosakata file. Tabel di bawah ini menunjukkan kinerja model kami dengan fraksi berbeda dari ekstensi file yang dihapus selama waktu pelatihan.
 Gambar 4: Kinerja OctoLingua dengan persentase berbeda dari ekstensi file yang dihapus pada tiga variasi pengujian kami
Gambar 4: Kinerja OctoLingua dengan persentase berbeda dari ekstensi file yang dihapus pada tiga variasi pengujian kamiPerhatikan bahwa tanpa ekstensi file yang dihapus selama waktu pelatihan, kinerja OctoLingua pada file uji tanpa ekstensi dan ekstensi acak menurun secara signifikan dari pada data uji reguler. Di sisi lain, ketika model dilatih pada dataset di mana beberapa ekstensi file dihapus, kinerja model tidak banyak menurun pada set tes yang dimodifikasi. Ini menegaskan bahwa menghapus ekstensi file dari sebagian kecil file pada waktu pelatihan mendorong classifier kami untuk belajar lebih banyak dari kosakata. Ini juga menunjukkan bahwa fitur ekstensi file, meskipun sangat prediktif, memiliki kecenderungan untuk mendominasi dan mencegah lebih banyak bobot ditugaskan ke fitur konten.
Mendukung bahasa baru
Menambahkan bahasa baru di OctoLingua cukup mudah. Itu dimulai dengan memperoleh sejumlah besar file dalam bahasa baru (kita bisa melakukan ini secara terprogram seperti yang dijelaskan dalam sumber data). File-file ini dipecah menjadi pelatihan dan set uji dan kemudian dijalankan melalui preprocessor dan extractor fitur kami. Kumpulan tes dan kereta baru ini ditambahkan ke kumpulan data pelatihan dan pengujian kami yang ada. Set pengujian baru memungkinkan kami untuk memverifikasi bahwa akurasi model kami tetap dapat diterima.
Gambar 5: Menambahkan bahasa baru dengan OctoLinguaRencana kami
Sampai sekarang, OctoLingua berada pada "tahap prototyping lanjutan". Mesin klasifikasi bahasa kami sudah kuat dan andal, tetapi belum mendukung semua bahasa pengkodean di platform kami. Selain memperluas dukungan bahasa - yang akan lebih mudah - kami bertujuan untuk memungkinkan deteksi bahasa pada berbagai tingkat granularity. Implementasi kami saat ini sudah memungkinkan kami, dengan sedikit modifikasi pada mesin pembelajaran mesin kami, untuk mengklasifikasikan snipet kode. Tidak akan terlalu jauh untuk membawa model ke tahap di mana ia dapat mendeteksi dan mengklasifikasikan bahasa tertanam dengan andal.
Kami juga mempertimbangkan kemungkinan sumber terbuka model kami dan akan senang mendengar dari komunitas jika Anda tertarik.
Ringkasan
Dengan OctoLingua, tujuan kami adalah untuk menyediakan layanan yang memungkinkan deteksi bahasa kode sumber yang kuat dan andal di berbagai tingkat granularitas, dari level file atau level snippet hingga deteksi dan klasifikasi bahasa tingkat level yang berpotensi. Akhirnya, layanan ini dapat mendukung, antara lain, pencarian kode, berbagi kode, menyoroti bahasa, dan rendering berbeda - semua ini ditujukan untuk mendukung pengembang dalam pekerjaan pengembangan mereka sehari-hari di samping membantu mereka menulis kode kualitas. Jika Anda tertarik untuk memanfaatkan atau berkontribusi pada pekerjaan kami, silakan menghubungi Twitter
@github !