Pada tanggal 27 April, di konferensi
Strike-2019 , dalam kerangka bagian DevOps, sebuah laporan dibuat berjudul "Penskalaan otomatis dan manajemen sumber daya di Kubernetes". Ini berbicara tentang bagaimana menggunakan K8 untuk memastikan ketersediaan aplikasi yang tinggi dan memastikan kinerja maksimum mereka.

Secara tradisi, kami senang menyajikan
video dengan laporan (44 menit, jauh lebih informatif daripada artikel) dan penekanan utama dalam bentuk teks. Ayo pergi!
Kami akan menganalisis topik laporan sesuai dengan kata-kata dan mulai dari akhir.
Kubernetes
Biarkan kami memiliki wadah Docker di host. Mengapa Untuk memastikan pengulangan dan isolasi, yang pada gilirannya memungkinkan untuk penyebaran sederhana dan baik, CI / CD. Kami memiliki banyak mesin dengan kontainer.
Apa yang dalam hal ini memberi Kubernetes?
- Kami berhenti memikirkan mesin ini dan mulai bekerja dengan "cloud", sekelompok wadah atau pod (kelompok wadah).
- Selain itu, kami bahkan tidak memikirkan pod individual, tetapi mengelola lebih banyak grup besar. Primitif tingkat tinggi semacam itu memungkinkan kita untuk mengatakan bahwa ada template untuk meluncurkan beban kerja tertentu, tetapi jumlah instance yang diperlukan untuk peluncurannya. Jika kami kemudian mengubah template, semua instance juga akan berubah.
- Menggunakan API deklaratif, alih-alih mengeksekusi urutan perintah tertentu, kami menggambarkan "perangkat dunia" (dalam YAML) yang dibuat Kubernetes. Dan lagi: ketika deskripsi berubah, tampilan aslinya juga akan berubah.
Manajemen sumber daya
CPU
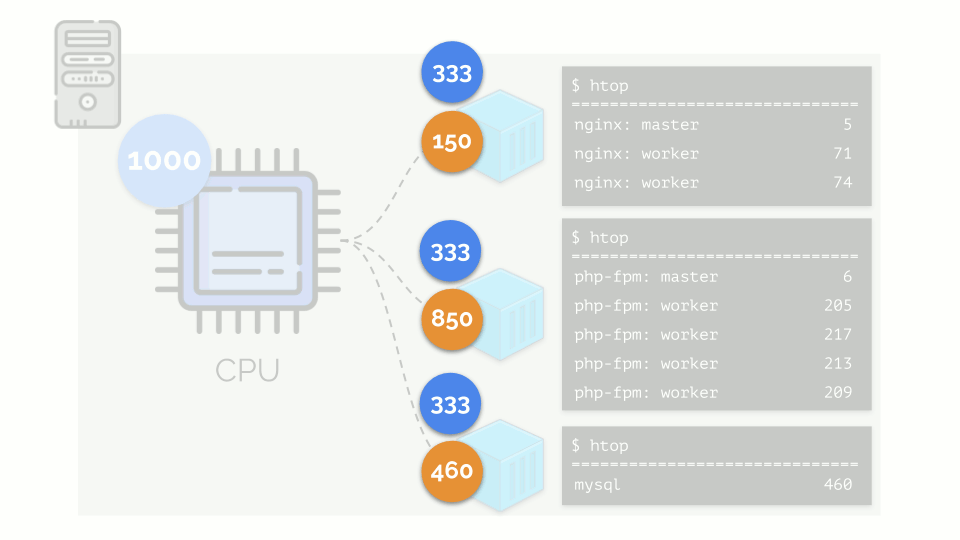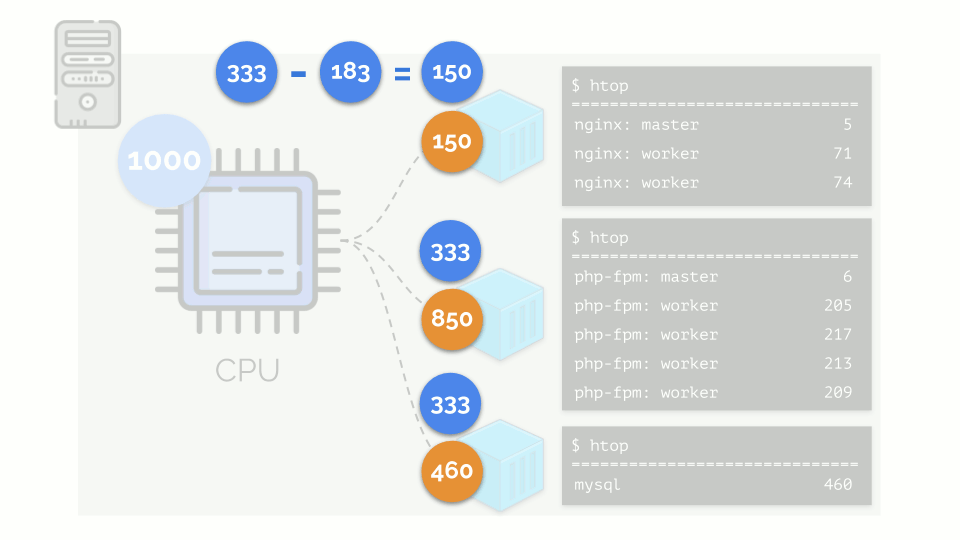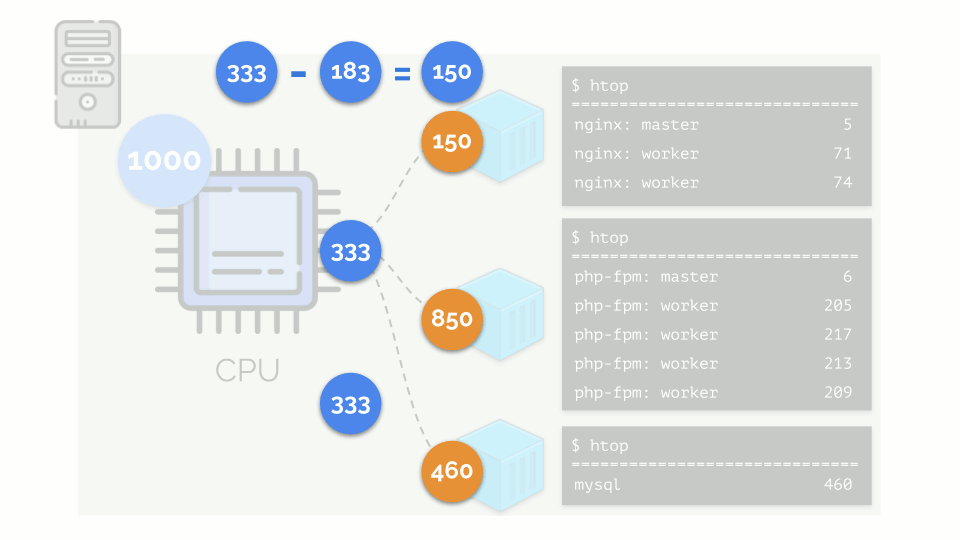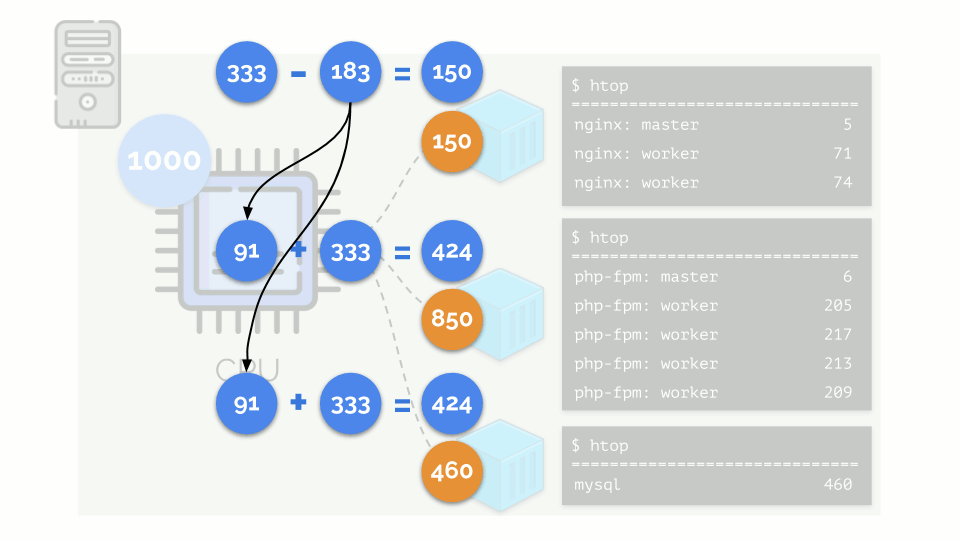
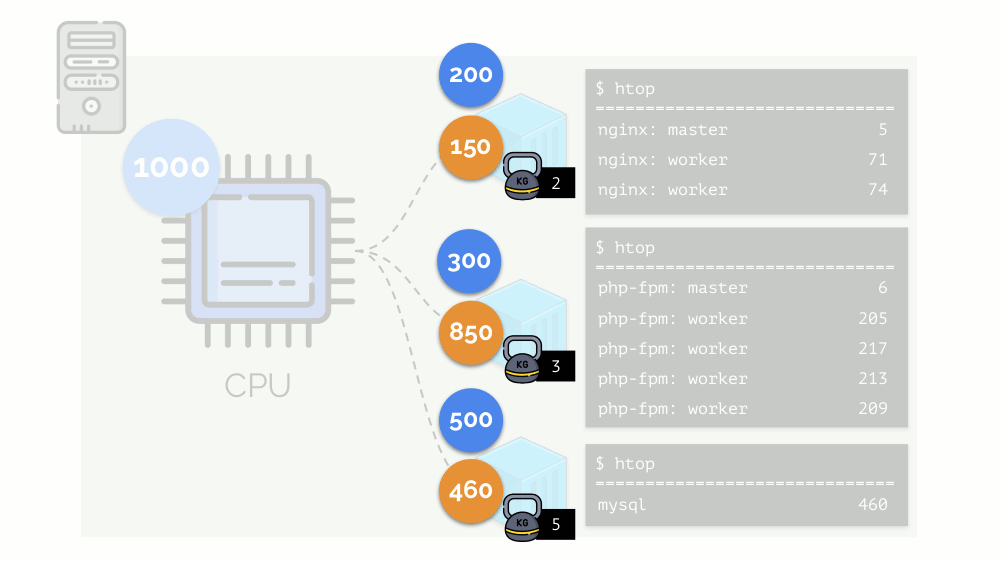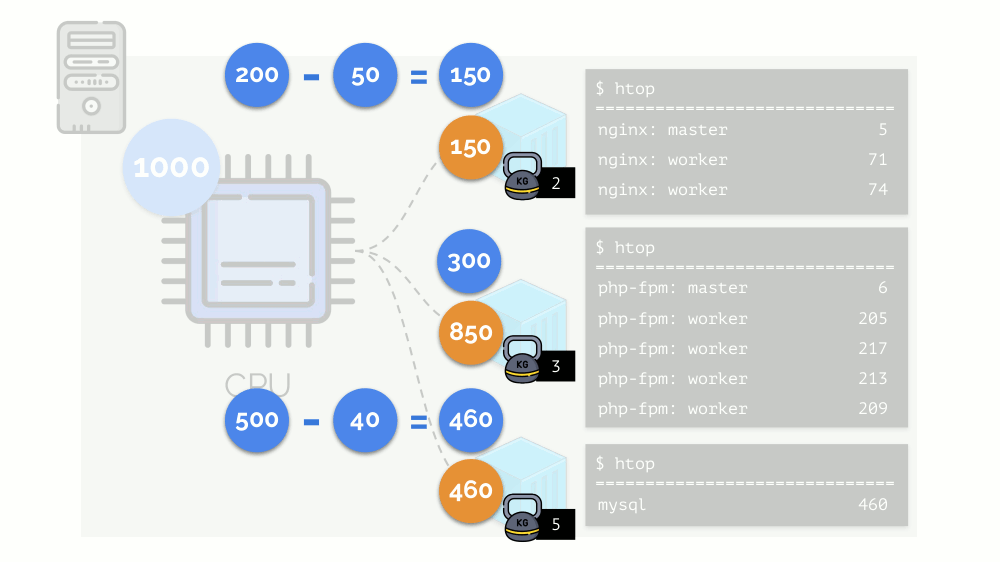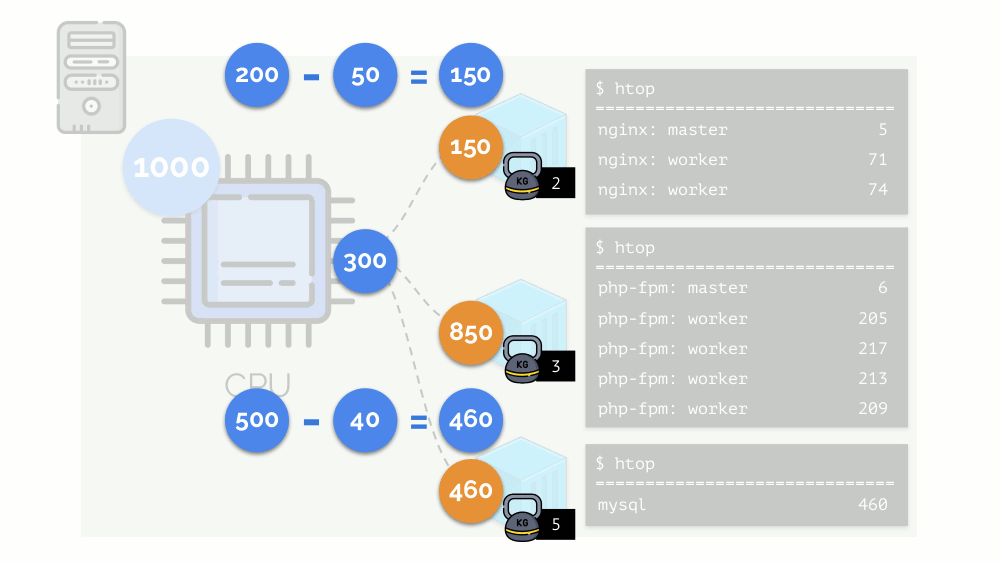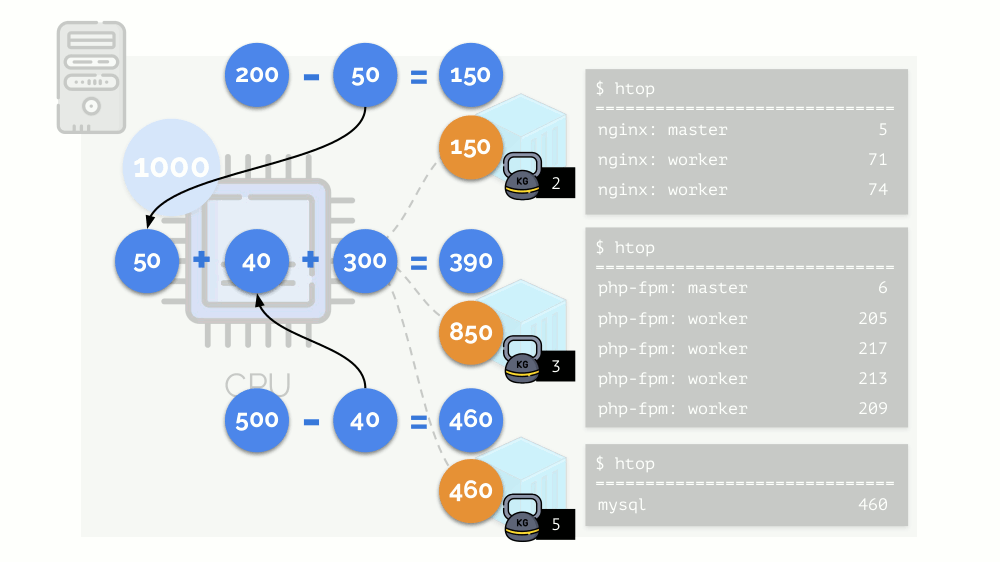
Mari kita jalankan nginx, php-fpm dan mysql di server. Layanan ini sebenarnya akan memiliki lebih banyak proses yang berjalan, yang masing-masing membutuhkan sumber daya komputasi:
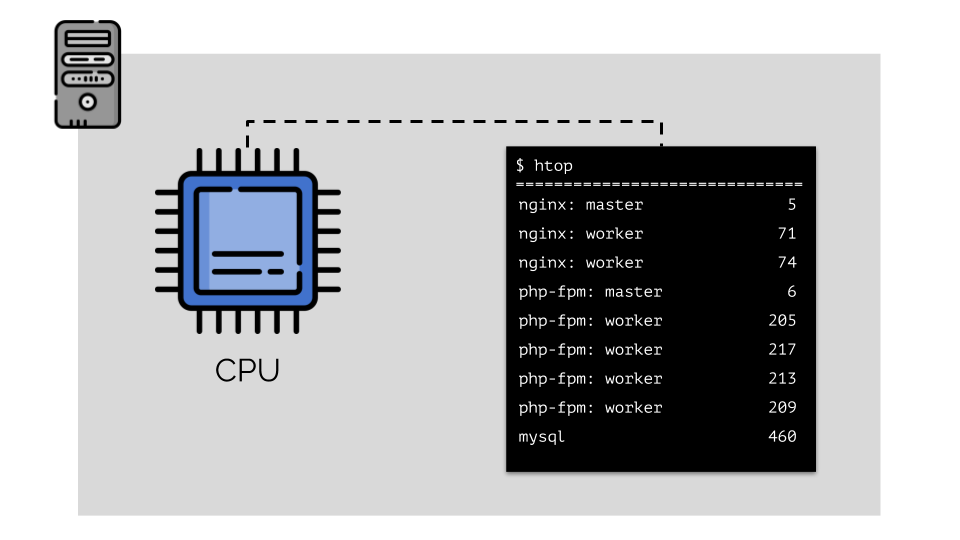 (angka-angka pada slide adalah "burung beo," kebutuhan abstrak dari setiap proses untuk daya komputasi)
(angka-angka pada slide adalah "burung beo," kebutuhan abstrak dari setiap proses untuk daya komputasi)Untuk membuatnya nyaman untuk bekerja dengan ini, adalah logis untuk menggabungkan proses menjadi grup (misalnya, semua proses nginx menjadi satu grup "nginx"). Cara sederhana dan jelas untuk melakukan ini adalah menempatkan masing-masing kelompok dalam wadah:
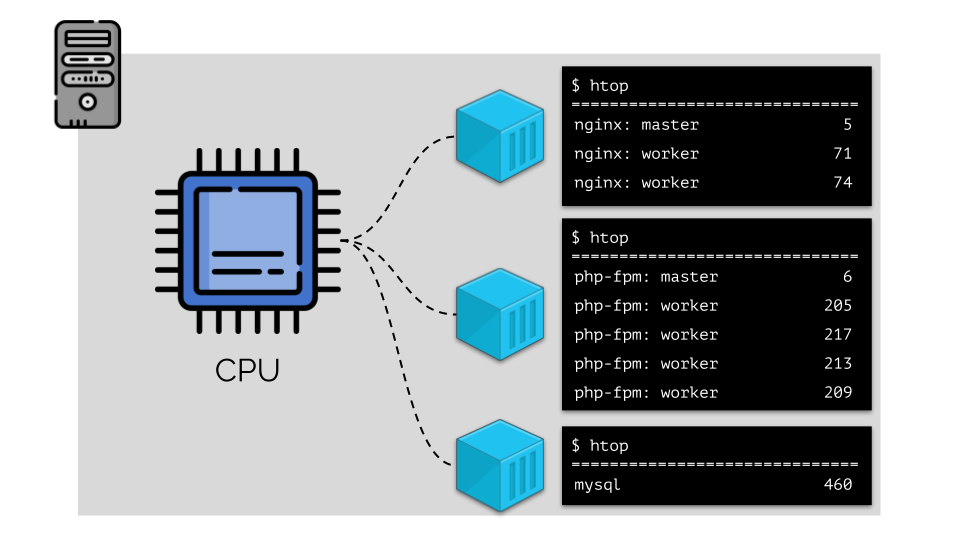
Untuk melanjutkan, Anda perlu mengingat apa itu wadah (di Linux). Penampilan mereka dimungkinkan berkat tiga fitur utama di kernel, yang diimplementasikan untuk waktu yang lama:
kemampuan ,
ruang nama , dan
grup . Dan teknologi lainnya (termasuk "cangkang" yang mudah digunakan seperti Docker) berkontribusi pada pengembangan lebih lanjut:
Dalam konteks laporan, kami hanya tertarik pada
cgroup , karena kelompok kontrol adalah bagian dari fungsi kontainer (Docker, dll.) Yang menerapkan manajemen sumber daya. Proses, yang disatukan dalam kelompok, seperti yang kita inginkan, adalah kelompok kontrol.
Mari kita kembali ke persyaratan CPU untuk proses ini, dan sekarang ke grup proses:
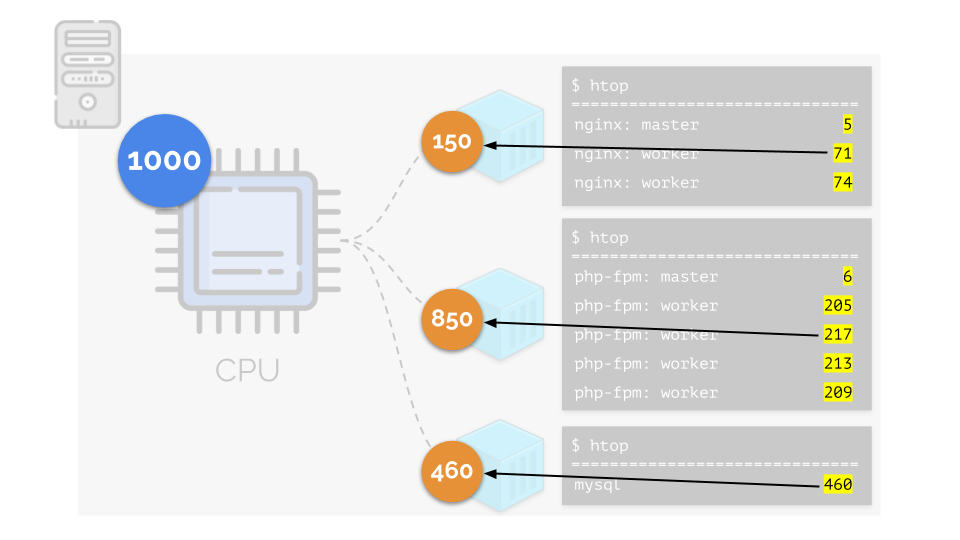 (Saya ulangi bahwa semua angka adalah ekspresi abstrak dari persyaratan sumber daya)
(Saya ulangi bahwa semua angka adalah ekspresi abstrak dari persyaratan sumber daya)Pada saat yang sama, CPU itu sendiri memiliki sumber daya final tertentu
(dalam contoh itu adalah 1000) , yang mungkin tidak cukup untuk semua orang (jumlah kebutuhan semua kelompok adalah 150 + 850 + 460 = 1460). Apa yang akan terjadi dalam kasus ini?
Kernel mulai mendistribusikan sumber daya dan melakukannya dengan “jujur”, memberikan jumlah sumber daya yang sama untuk setiap kelompok. Tetapi dalam kasus pertama ada lebih banyak dari yang diperlukan (333> 150), sehingga kelebihan (333-150 = 183) tetap dalam cadangan, yang juga terdistribusi secara merata antara dua wadah lainnya:
Akibatnya: wadah pertama memiliki sumber daya yang cukup, yang kedua - tidak cukup, yang ketiga - tidak cukup. Ini adalah hasil dari
penjadwal "jujur" di Linux -
CFS . Pekerjaannya dapat diatur dengan menetapkan
berat untuk masing-masing wadah. Misalnya, seperti ini:
Mari kita lihat kasus kekurangan sumber daya di wadah kedua (php-fpm). Semua sumber daya kontainer didistribusikan di antara proses-proses tersebut secara merata. Hasilnya, proses master bekerja dengan baik, dan semua pekerja melambat, menerima kurang dari setengah dari yang dibutuhkan:
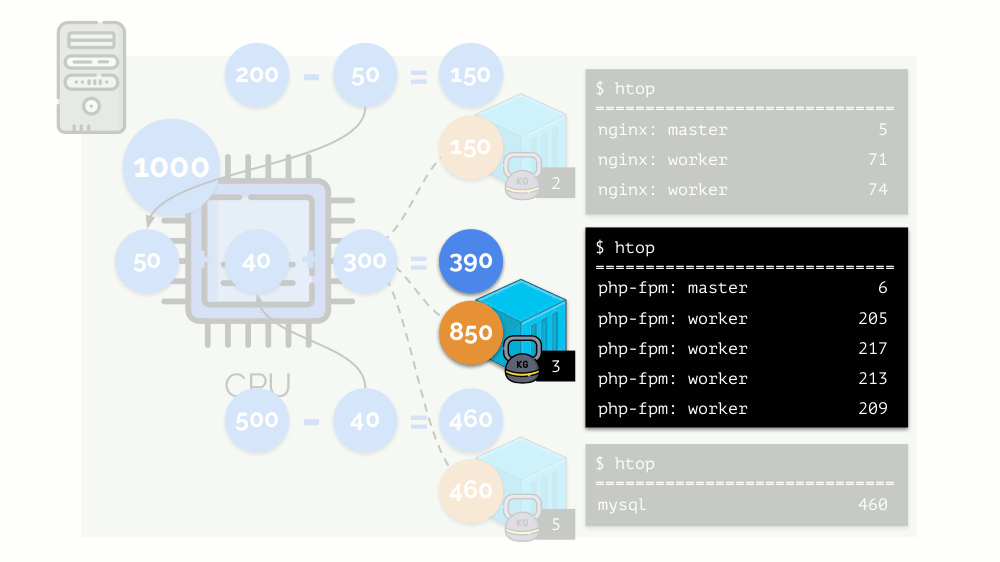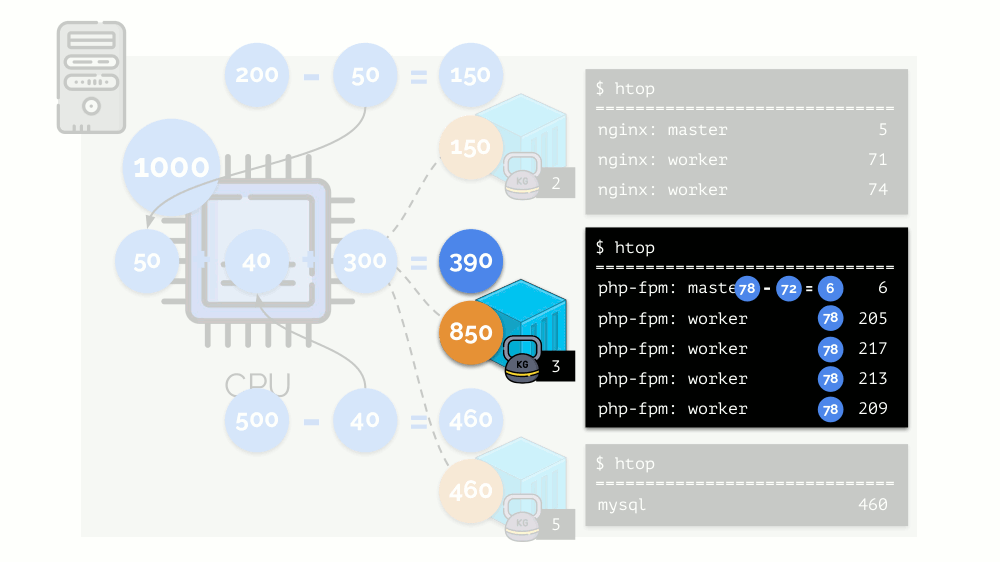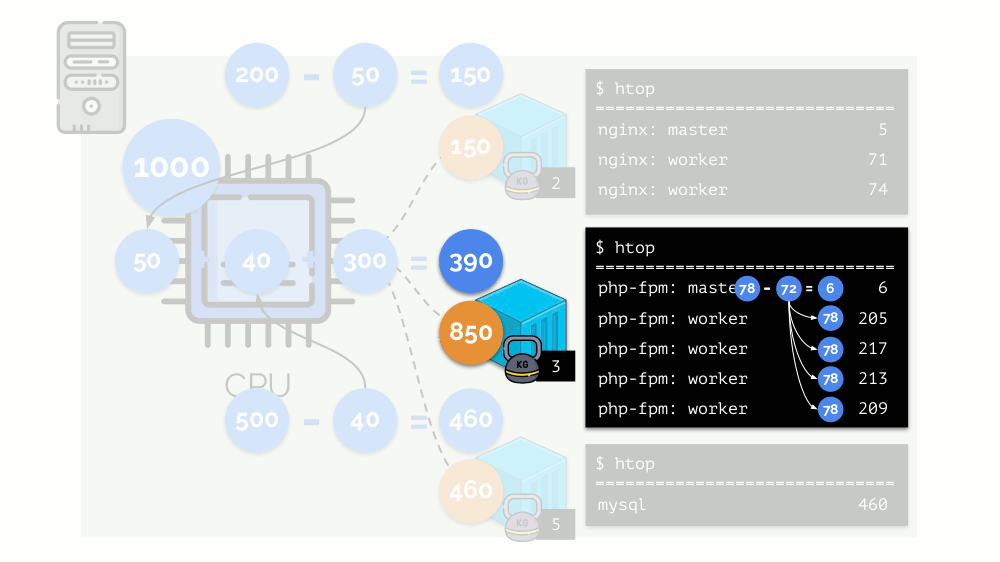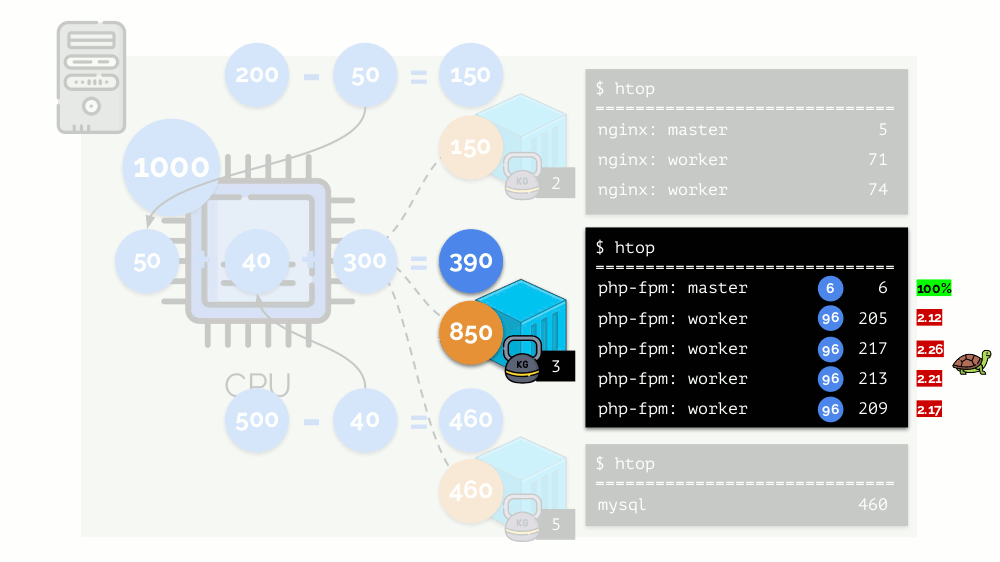
Ini adalah cara kerja penjadwal CFS. Bobot yang kami tetapkan untuk kontainer akan disebut
permintaan di masa mendatang. Kenapa begitu - lihat di bawah.
Mari kita lihat keseluruhan situasi dari sisi lain. Seperti yang Anda tahu, semua jalan mengarah ke Roma, dan dalam kasus komputer ke CPU. Satu CPU, banyak tugas - Anda perlu lampu lalu lintas. Cara termudah untuk mengelola sumber daya adalah "lampu lalu lintas": mereka memberi satu proses waktu akses tetap ke CPU, lalu yang berikutnya, dll.
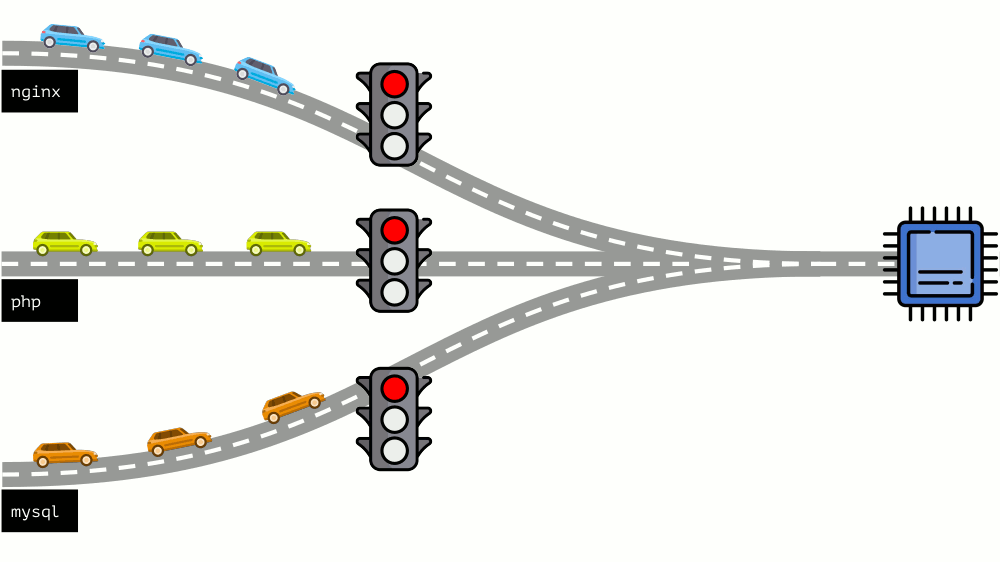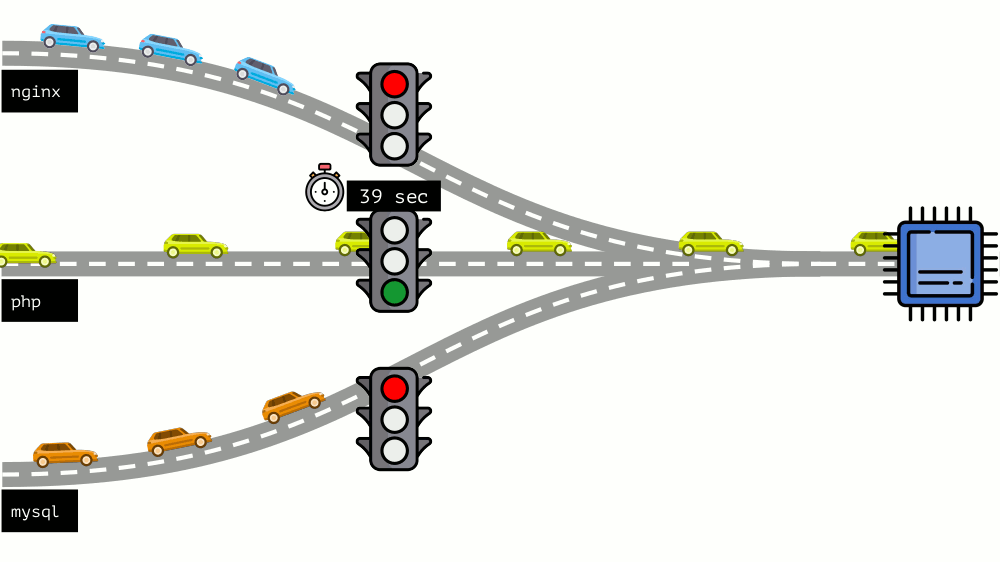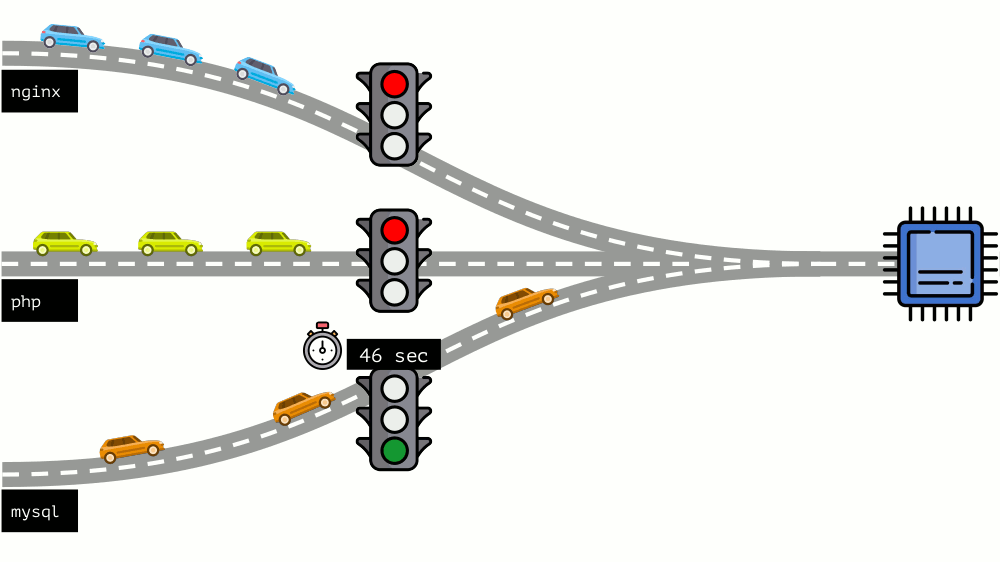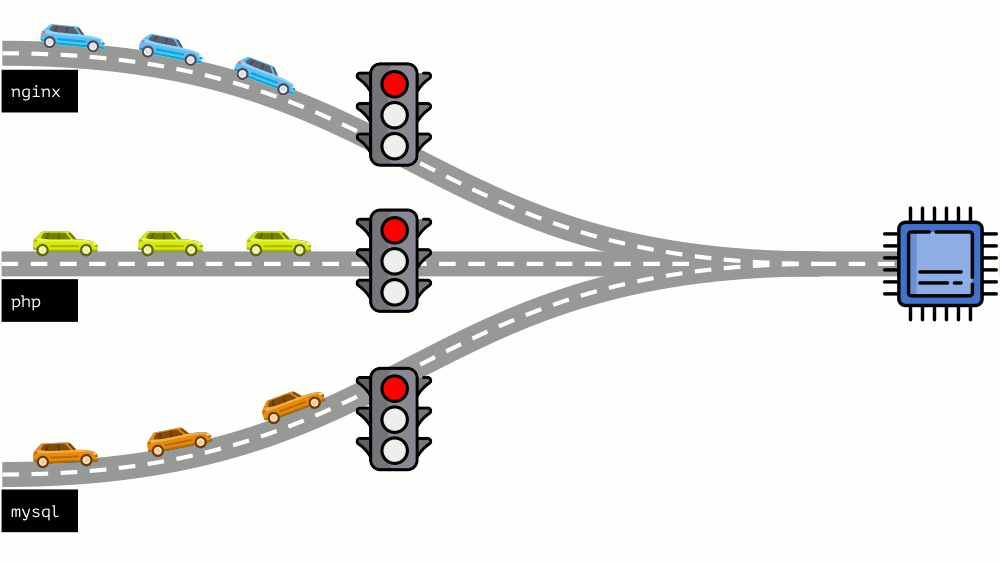
Pendekatan ini disebut
pembatasan keras . Ingat itu hanya sebagai
batas . Namun, jika Anda mendistribusikan batas ke semua kontainer, muncul masalah: mysql sedang bepergian di sepanjang jalan dan pada titik tertentu kebutuhannya untuk CPU berakhir, tetapi semua proses lainnya terpaksa menunggu saat CPU
diam .
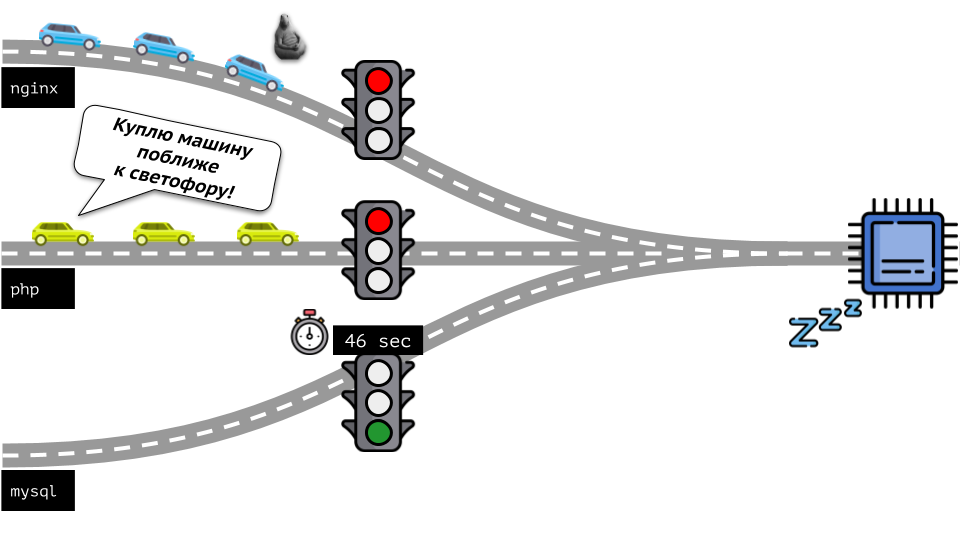
Mari kita kembali ke kernel Linux dan interaksinya dengan CPU - gambaran keseluruhannya adalah sebagai berikut:
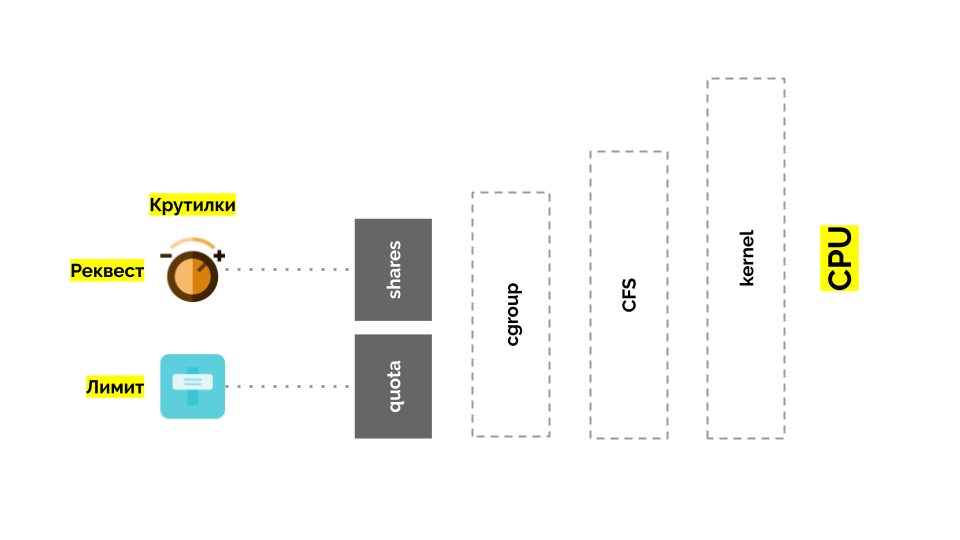
Cgroup memiliki dua pengaturan - pada kenyataannya, ini adalah dua "tikungan" sederhana yang memungkinkan Anda untuk menentukan:
- berat untuk wadah (permintaan) dibagi ;
- persentase dari total waktu CPU untuk mengerjakan tugas kontainer (batas) adalah kuota .
Bagaimana cara mengukur CPU?
Ada berbagai cara:
- Apa itu burung beo , tidak ada yang tahu - setiap kali Anda harus setuju.
- Bunga lebih jelas, tetapi relatif: 50% dari server dengan 4 core dan 20 core adalah hal yang sama sekali berbeda.
- Anda dapat menggunakan bobot yang telah disebutkan di Linux, tetapi mereka juga relatif.
- Opsi yang paling memadai adalah mengukur sumber daya komputasi dalam hitungan detik . Yaitu dalam detik waktu prosesor relatif terhadap detik waktu nyata: mereka mengeluarkan 1 detik waktu prosesor dalam 1 detik nyata - ini adalah satu inti CPU keseluruhan.
Untuk membuatnya lebih mudah untuk dikatakan, mereka mulai mengukur langsung di
inti , yang berarti waktu CPU relatif terhadap yang asli. Karena Linux memahami bobot daripada waktu prosesor / inti, diperlukan mekanisme penerjemahan dari satu ke yang lain.
Pertimbangkan contoh sederhana dengan server dengan 3 core CPU, di mana tiga pod akan memilih bobot (500, 1000 dan 1500) yang mudah dikonversi ke bagian terkait dari core yang dialokasikan untuk mereka (0,5, 1 dan 1,5).
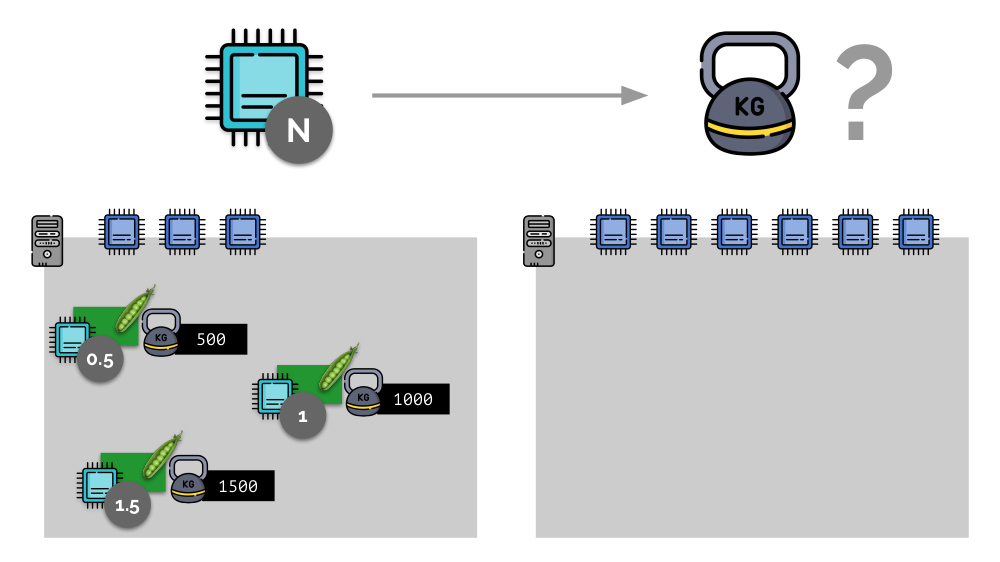
Jika Anda mengambil server kedua, di mana akan ada dua kali lebih banyak core (6), dan menempatkan pod yang sama di sana, distribusi core dapat dengan mudah dihitung dengan hanya mengalikannya dengan 2 (masing-masing 1, 2 dan 3). Tetapi poin penting terjadi ketika pod keempat muncul di server ini, yang beratnya adalah 3.000 untuk kenyamanan. Ini menghilangkan beberapa sumber daya CPU (setengah inti), dan sisa pod menceritakannya kembali (membagi dua):
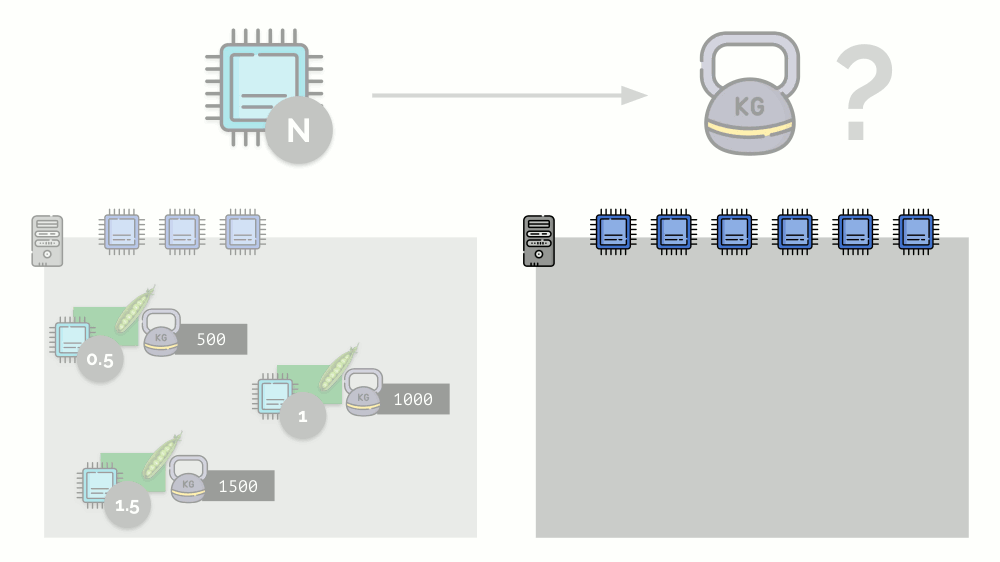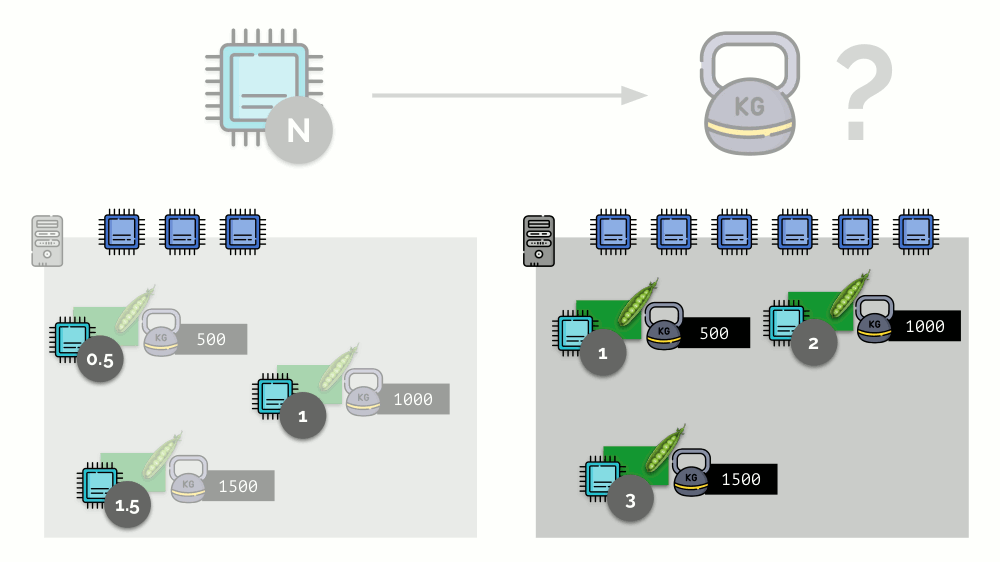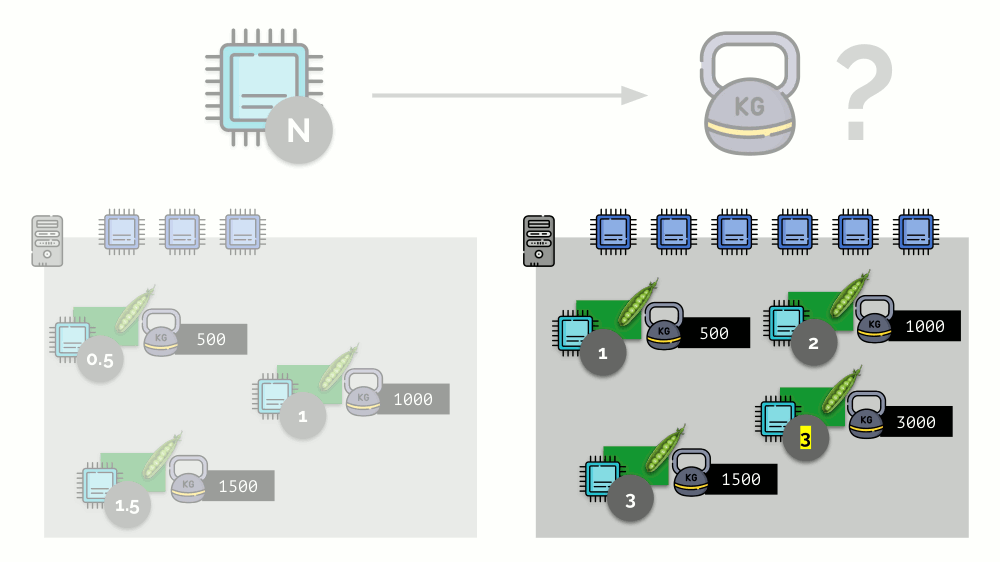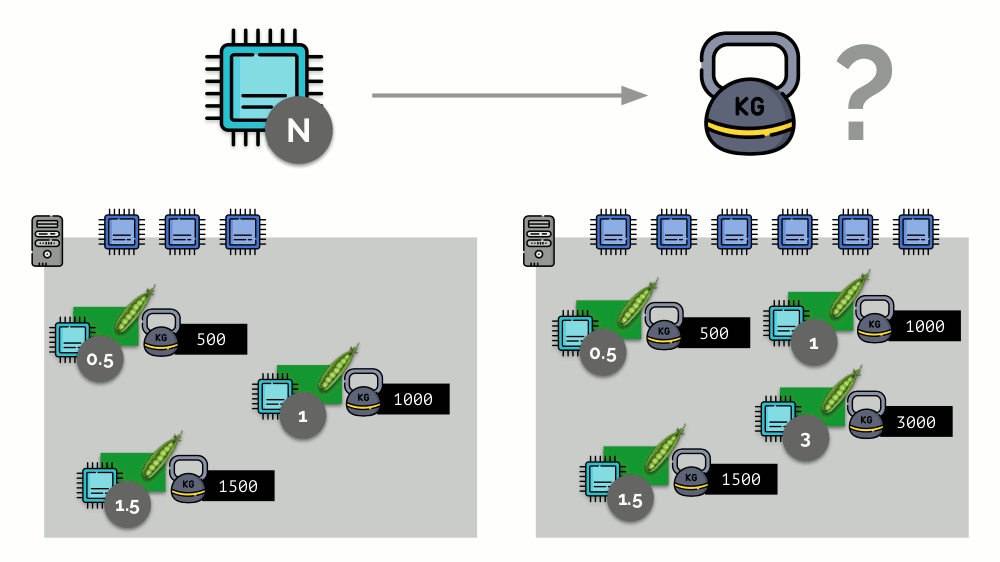
Kubernet dan Sumber Daya CPU
Di Kubernetes, sumber daya CPU biasanya diukur dalam
mili-core , yaitu Kernel 0,001 diambil sebagai berat dasar.
(Hal yang sama dalam terminologi Linux / cgroup disebut CPU share, meskipun, lebih tepatnya, 1000 CPU = 1024 share CPU.) K8s memastikan untuk tidak menempatkan lebih banyak pod pada server daripada sumber daya CPU untuk jumlah bobot semua polong.
Bagaimana kabarnya? Ketika server ditambahkan ke kluster Kubernetes, server melaporkan berapa banyak core CPU yang tersedia. Dan ketika membuat pod baru, scheduler Kubernetes tahu berapa core yang dibutuhkan pod ini. Dengan demikian, pod akan ditentukan di server, di mana ada cukup inti.
Apa yang akan terjadi jika permintaan
tidak ditentukan (mis., Pod tidak menentukan jumlah kernel yang dibutuhkan)? Mari kita lihat bagaimana Kubernet umumnya menghitung sumber daya.
Pod dapat menentukan permintaan (penjadwal CFS) dan batasan (ingat lampu lalu lintas?):
- Jika mereka sama, maka kelas QoS dijamin ditugaskan ke pod. Jumlah kernel yang selalu tersedia untuknya dijamin.
- Jika permintaan kurang dari batas, kelas QoS bisa meledak . Yaitu kami berharap bahwa pod, misalnya, selalu menggunakan 1 inti, tetapi nilai ini bukan batasan untuk itu: kadang-kadang pod dapat menggunakan lebih banyak (ketika ada sumber daya gratis di server untuk ini).
- Ada juga kelas QoS upaya terbaik - pod yang tidak ditentukan permintaannya. Sumber daya diberikan terakhir kepada mereka.
Memori
Situasinya mirip dengan memori, tetapi sedikit berbeda - setelah semua, sifat sumber daya ini berbeda. Secara umum, analoginya adalah sebagai berikut:
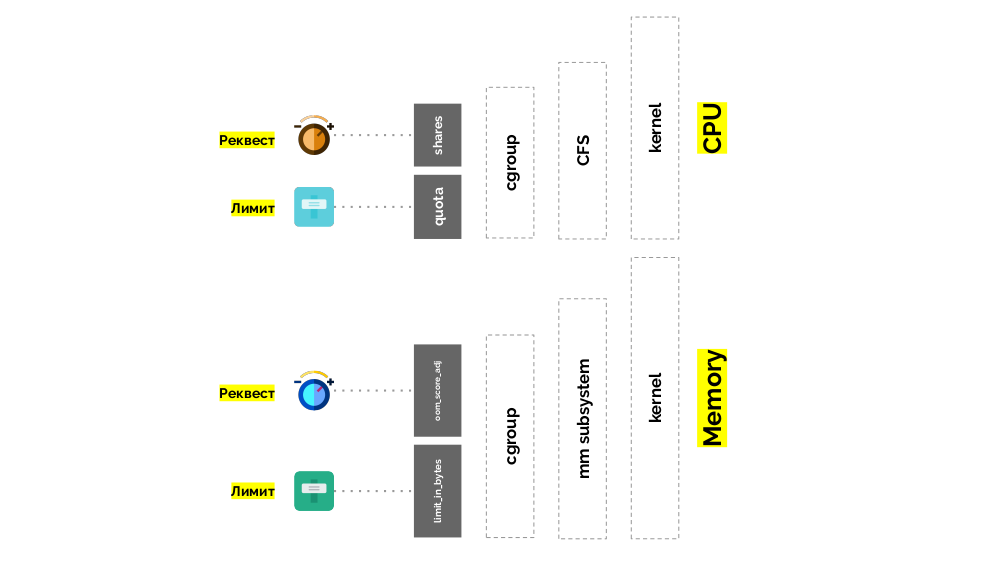
Mari kita lihat bagaimana permintaan diimplementasikan dalam memori. Biarkan pod hidup di server, ubah memori yang dikonsumsi, hingga salah satunya menjadi sangat besar sehingga memori habis. Dalam hal ini, pembunuh OOM muncul dan membunuh proses terbesar:
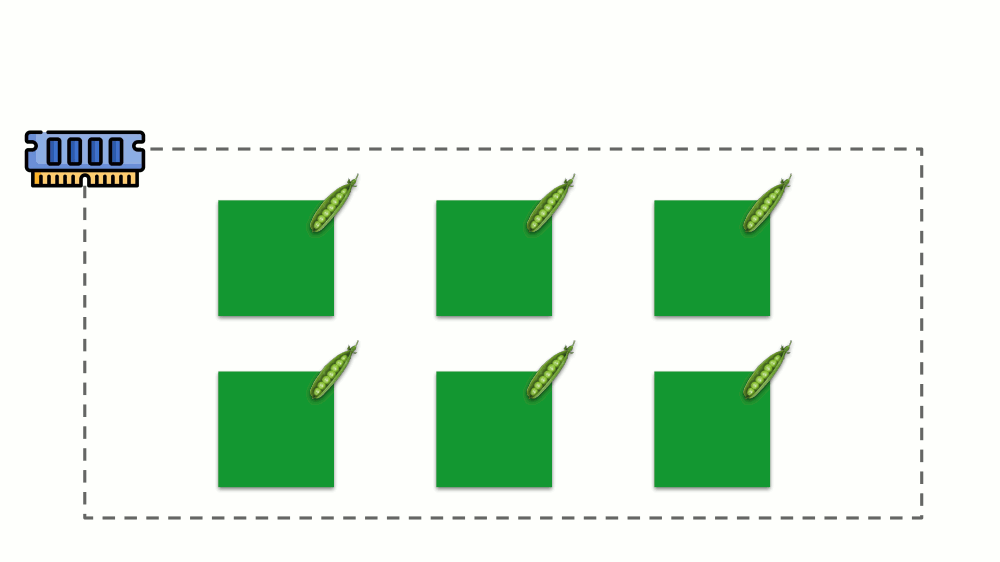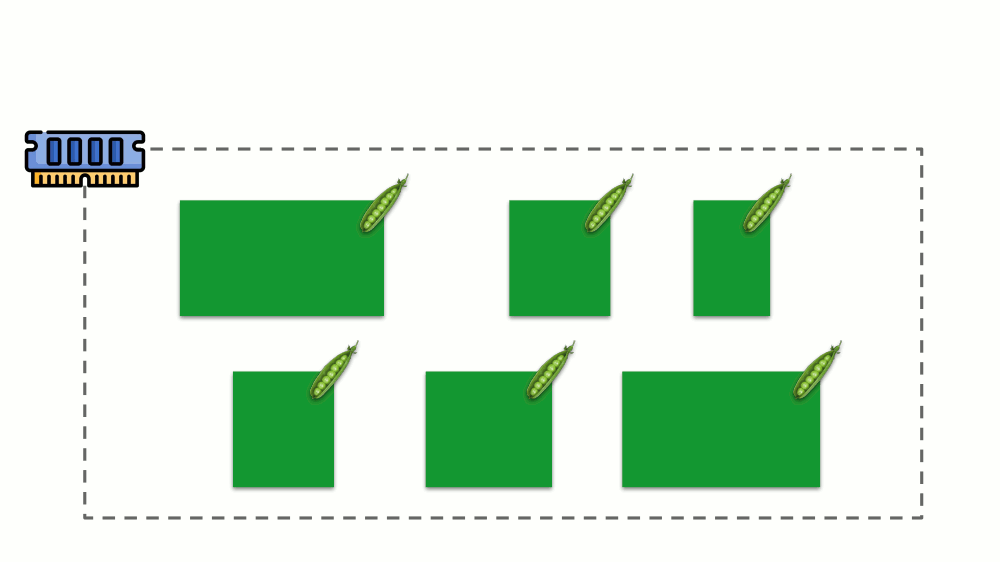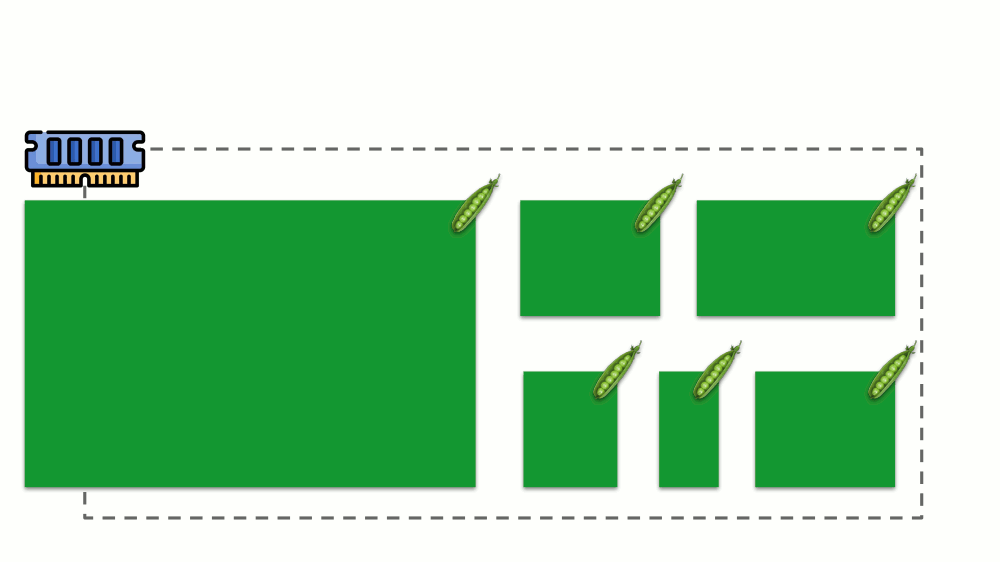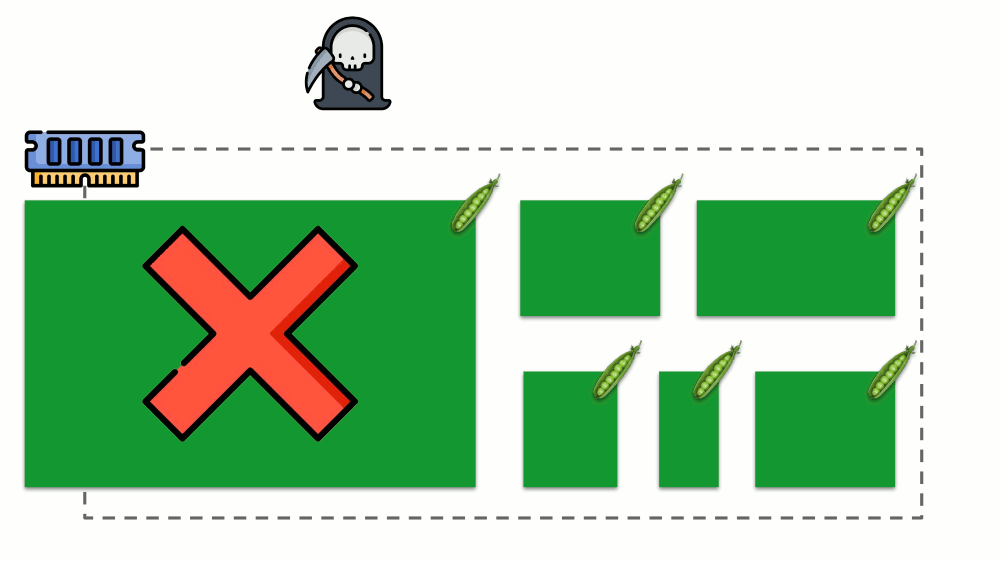
Ini tidak selalu cocok untuk kita, oleh karena itu, dimungkinkan untuk mengatur proses mana yang penting bagi kita dan tidak boleh dibunuh. Untuk melakukan ini, gunakan parameter
oom_score_adj .
Mari kita kembali ke kelas QoS dari CPU dan menggambar analogi dengan nilai-nilai oom_score_adj, yang menentukan prioritas untuk pod pada konsumsi memori:
- Nilai oom_score_adj terendah dari sebuah pod adalah -998, yang berarti bahwa pod tersebut harus dibunuh di tempat terakhir, ini dijamin .
- Yang tertinggi - 1000 - adalah upaya terbaik , polong seperti itu terbunuh sebelum orang lain.
- Untuk menghitung sisa nilai ( burstable ), ada formula yang esensinya bermuara pada fakta bahwa semakin banyak pod meminta sumber daya, semakin sedikit peluang itu akan dibunuh.

"
Putar " kedua -
limit_in_bytes - untuk batas. Semuanya lebih sederhana dengan itu: kami hanya menetapkan jumlah maksimum memori yang akan dikeluarkan, dan di sini (tidak seperti CPU) tidak ada pertanyaan apa itu (memori) diukur.
Total
Permintaan dan
limits ditetapkan untuk setiap pod di Kubernetes - baik parameter untuk CPU dan untuk memori:
- berdasarkan permintaan, penjadwal Kubernet berfungsi, yang mendistribusikan pod di seluruh server;
- berdasarkan semua parameter, kelas QodS pod ditentukan;
- Bobot relatif dihitung berdasarkan permintaan CPU;
- Berdasarkan permintaan CPU, penjadwal CFS dikonfigurasikan;
- Berdasarkan permintaan memori, pembunuh OOM dikonfigurasi;
- Berdasarkan batas CPU, "lampu lalu lintas" dikonfigurasi;
- berdasarkan batas memori, batas ditetapkan pada cgroup.
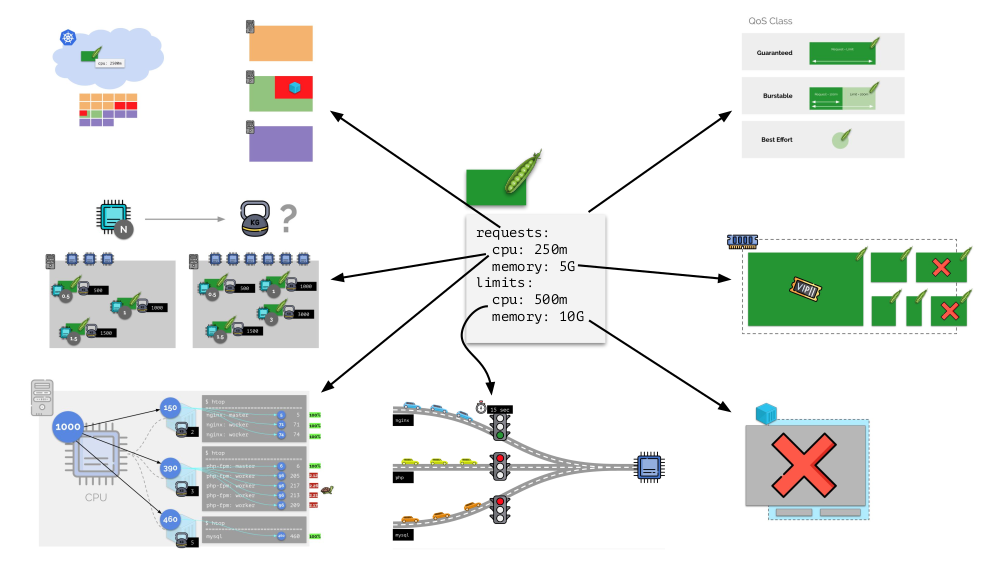
Secara umum, gambar ini menjawab semua pertanyaan tentang bagaimana bagian utama dari manajemen sumber daya di Kubernetes terjadi.
Autoscaling
K8s cluster-autoscaler
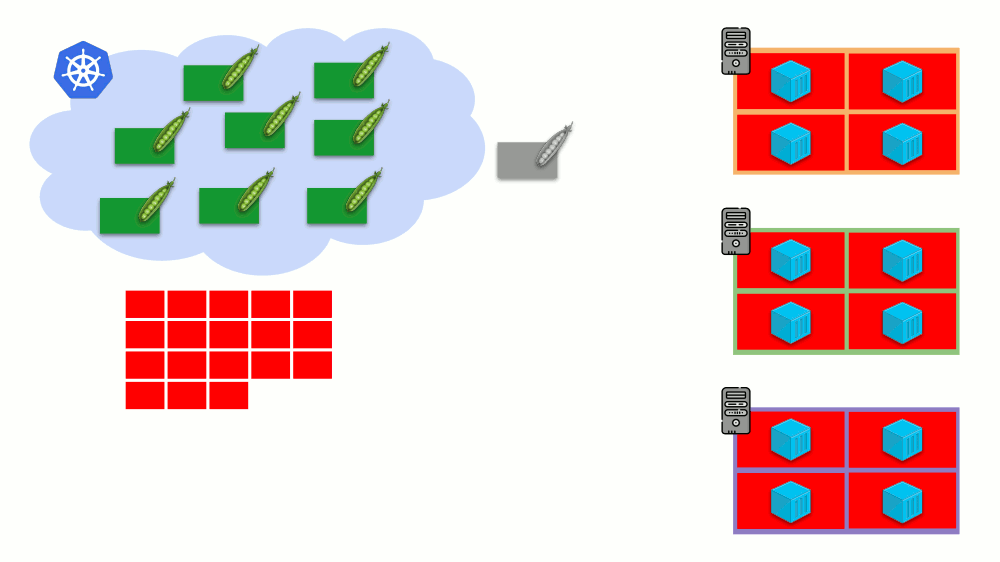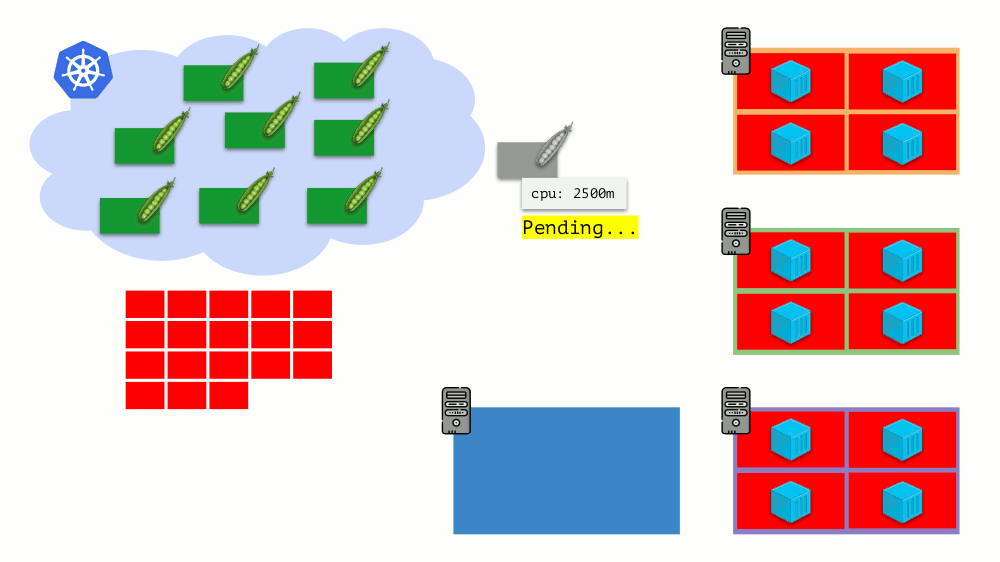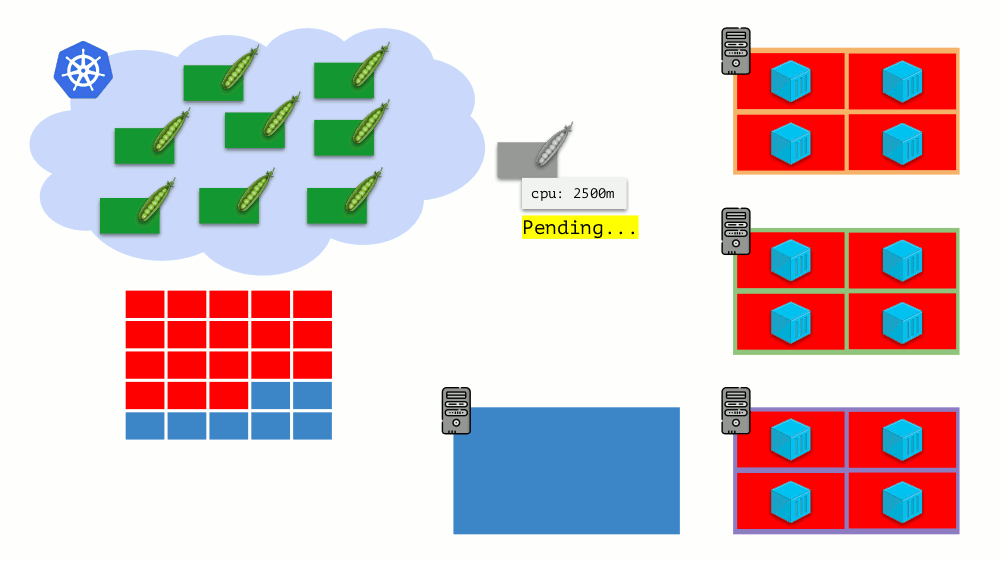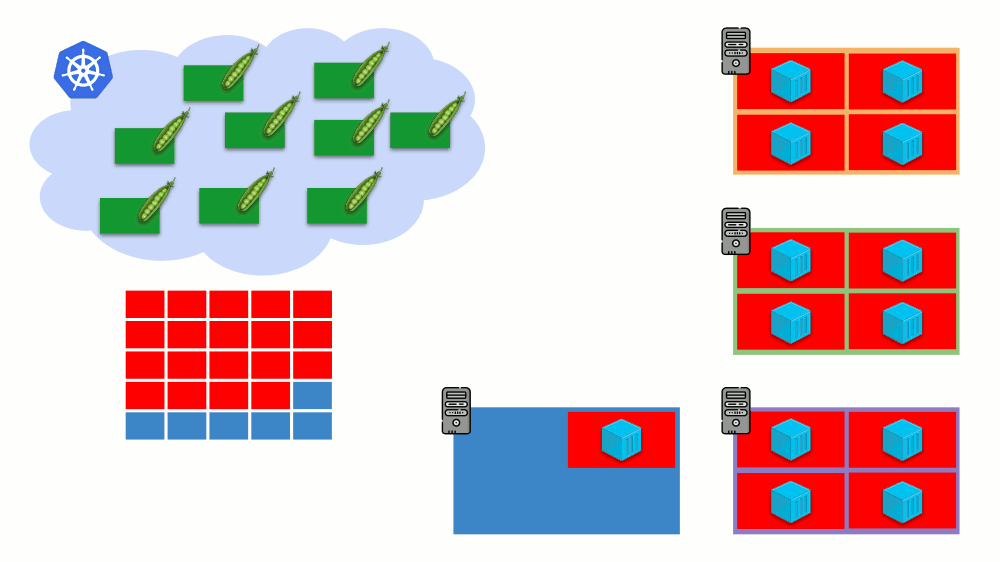
Bayangkan bahwa seluruh cluster sudah terisi dan pod baru harus dibuat. Meskipun pod tidak dapat muncul, ia menggantung dalam status
Ditunda . Agar muncul, kita dapat menghubungkan server baru ke cluster atau ... menempatkan cluster-autoscaler, yang akan melakukannya untuk kita: memesan mesin virtual dari penyedia cloud (dengan permintaan API) dan menghubungkannya ke cluster, setelah itu pod akan ditambahkan .
Ini adalah penskalaan otomatis kluster Kubernetes, yang sangat bagus (menurut pengalaman kami). Namun, seperti di tempat lain, ada beberapa nuansa di sini ...
Ketika kami meningkatkan ukuran cluster, semuanya baik-baik saja, tetapi apa yang terjadi ketika cluster
mulai bebas ? Masalahnya adalah bermigrasi pod (ke host gratis) secara teknis sangat sulit dan mahal dalam hal sumber daya. Kubernetes memiliki pendekatan yang sangat berbeda.
Pertimbangkan sekelompok 3 server di mana ada Penyebaran. Ia memiliki 6 pod: sekarang 2 untuk setiap server. Untuk beberapa alasan, kami ingin mematikan salah satu server. Untuk melakukan ini, gunakan perintah
kubectl drain , yang:
- melarang pengiriman pod baru ke server ini;
- hapus pod yang ada di server.
Karena Kubernetes memantau pemeliharaan jumlah polong (6), ia hanya akan membuatnya
kembali di node lain, tetapi tidak pada yang terputus, karena sudah ditandai sebagai tidak dapat diakses untuk menempatkan polong baru. Ini adalah mekanisme dasar untuk Kubernetes.

Namun, ada nuansa di sini. Dalam situasi yang sama untuk tindakan StatefulSet (bukan Penempatan) akan berbeda. Sekarang kita sudah memiliki aplikasi stateful - misalnya, tiga pod dengan MongoDB, salah satunya memiliki beberapa masalah (data rusak atau kesalahan lain yang mencegah pod memulai dengan benar). Dan lagi kami memutuskan untuk memutuskan satu server. Apa yang akan terjadi
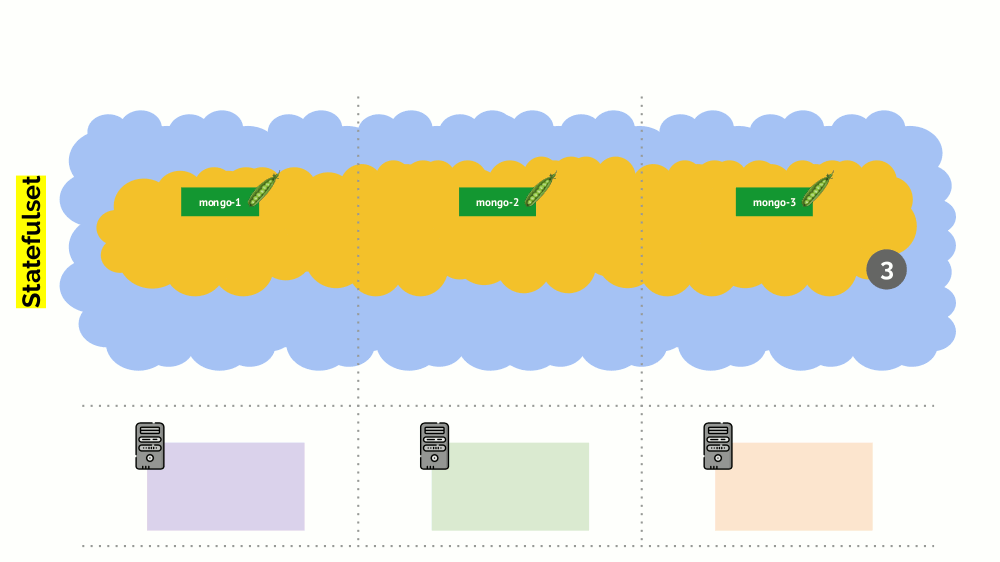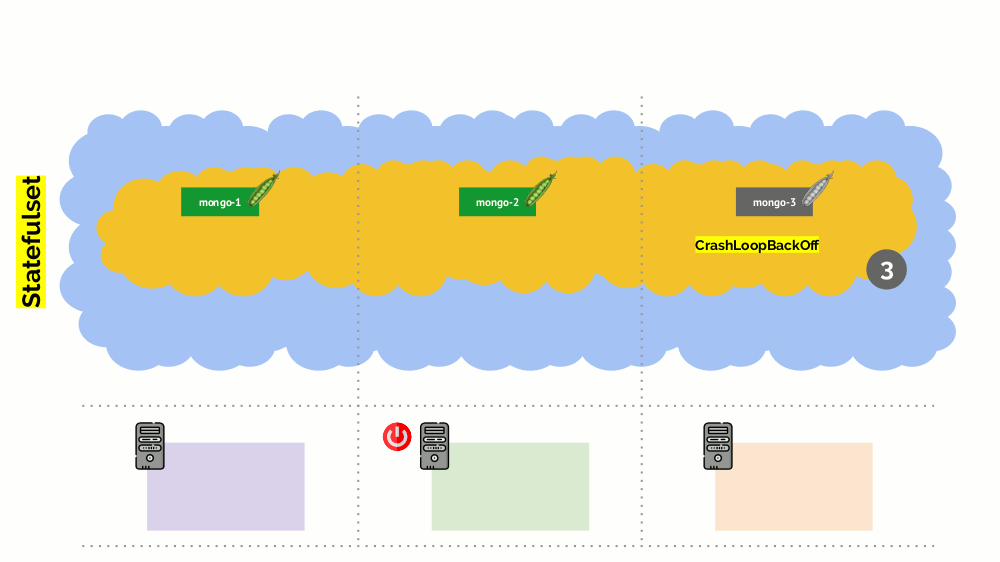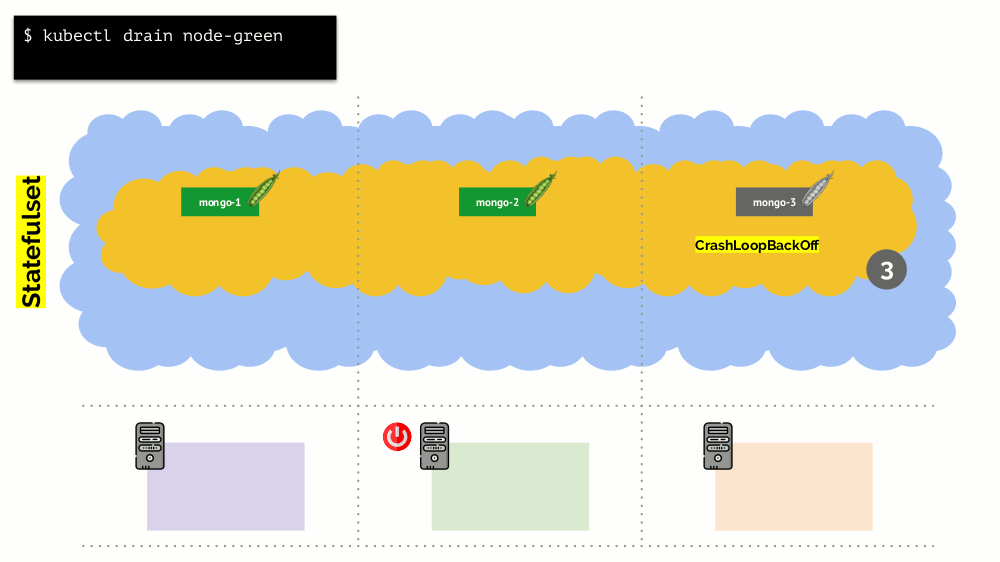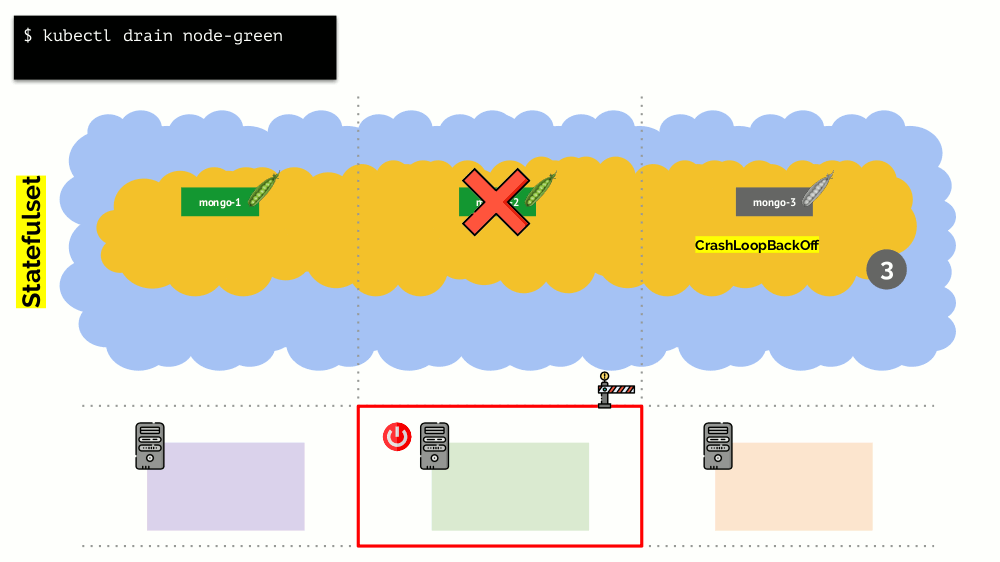
MongoDB
bisa mati karena membutuhkan kuorum: untuk sekelompok tiga instalasi, setidaknya dua harus berfungsi. Namun, ini
tidak terjadi - terima kasih kepada
PodDisruptionBudget . Parameter ini menentukan jumlah minimum yang diperlukan untuk pod yang berfungsi. Mengetahui bahwa salah satu pod dengan MongoDB tidak lagi berfungsi, dan melihat bahwa minAvailable diatur untuk MongoDB di
minAvailable: 2 , Kubernetes tidak akan membiarkan Anda menghapus pod.
Intinya: untuk memindahkan (dan benar-benar membuat ulang) pod dengan benar ketika cluster dilepaskan, Anda perlu mengonfigurasi PodDisruptBudget.
Penskalaan horisontal
Pertimbangkan situasi yang berbeda. Ada aplikasi yang berjalan sebagai Penerapan di Kubernetes. Lalu lintas pengguna datang ke podnya (misalnya, ada tiga di antaranya), dan kami mengukur indikator tertentu di dalamnya (katakanlah, beban CPU). Ketika beban meningkat, kami memperbaikinya sesuai jadwal dan menambah jumlah polong untuk mendistribusikan permintaan.
Hari ini di Kubernetes Anda tidak perlu melakukan ini secara manual: Anda dapat secara otomatis menambah / mengurangi jumlah polong tergantung pada nilai indikator beban yang diukur.
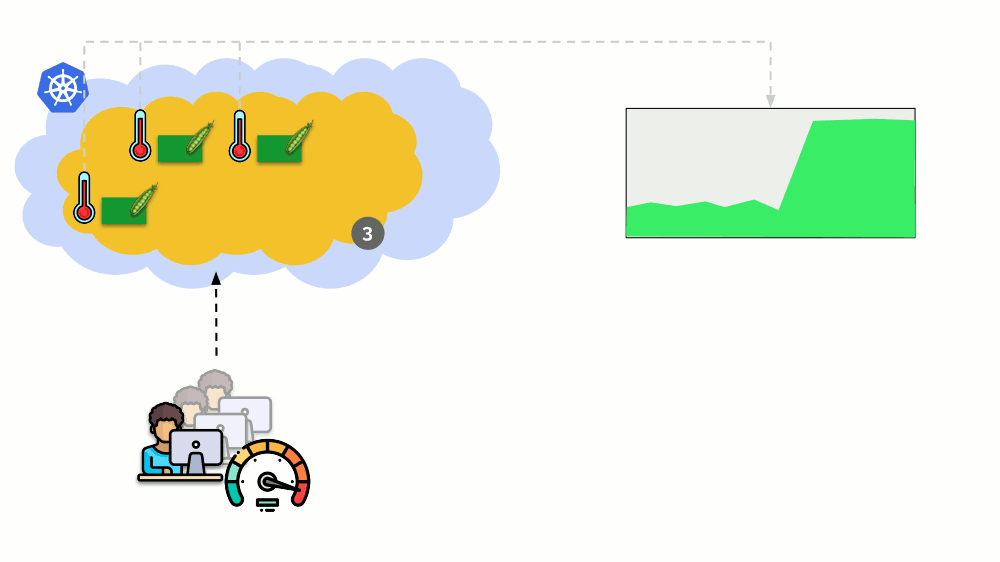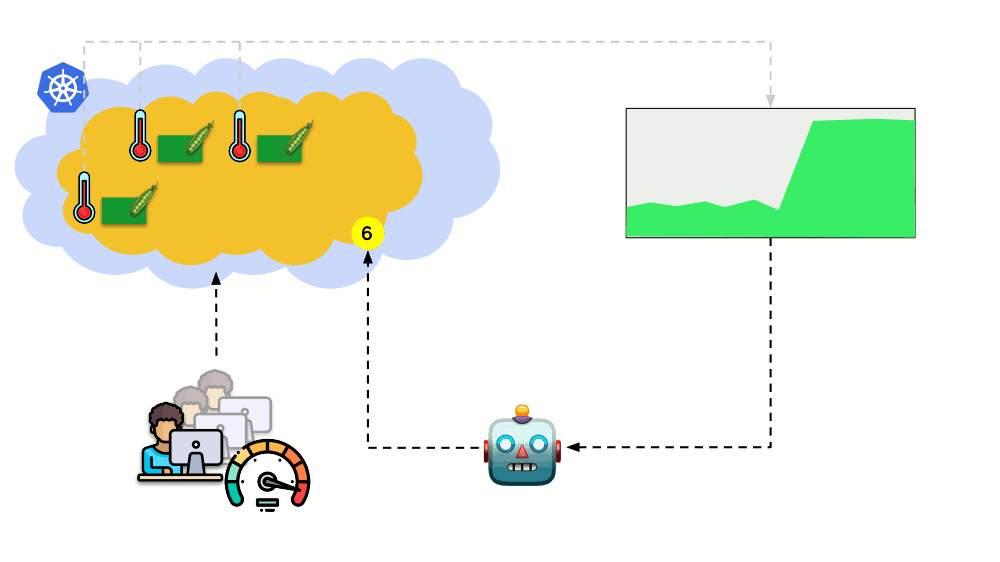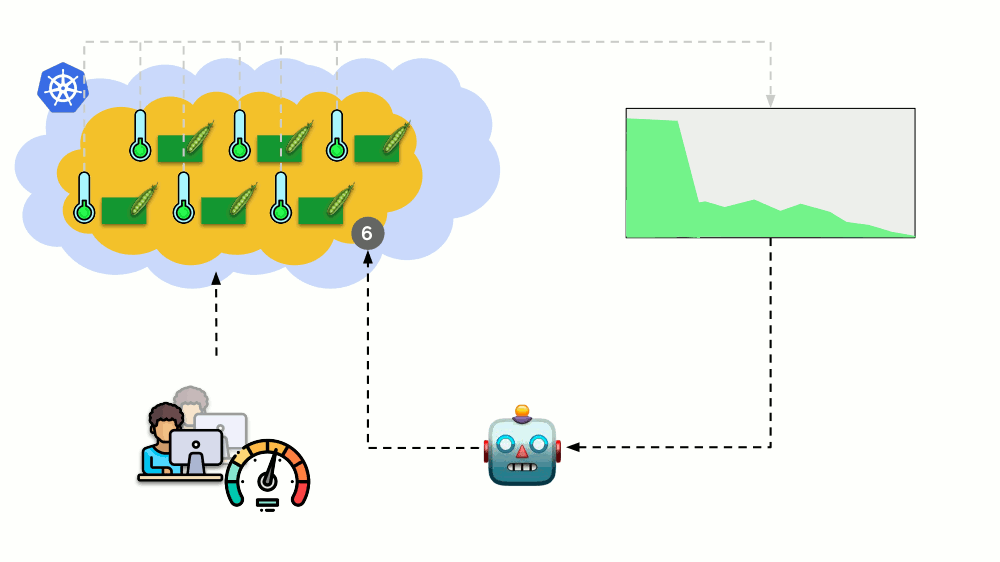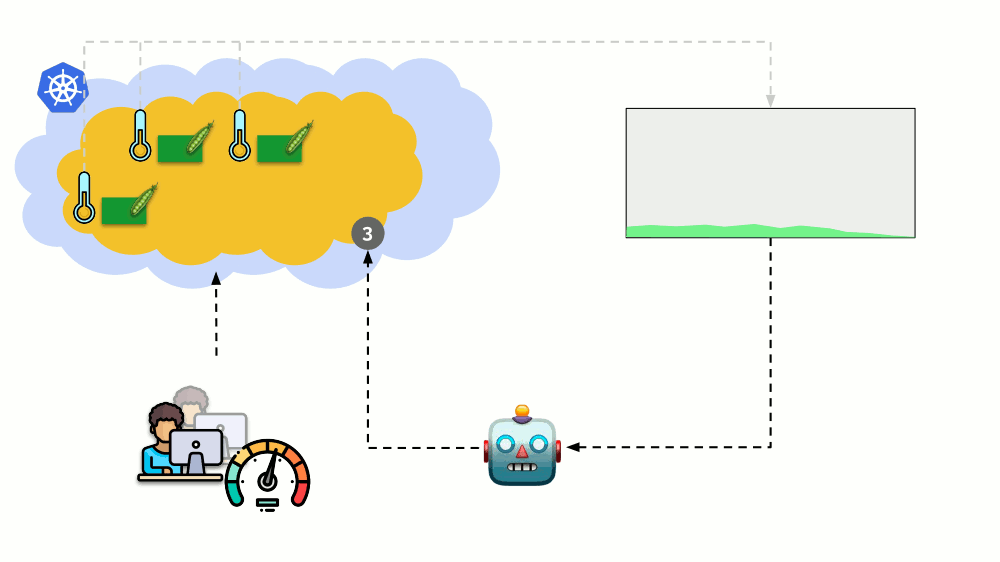
Pertanyaan utama di sini adalah
apa sebenarnya yang diukur dan
bagaimana menafsirkan nilai yang diperoleh (untuk membuat keputusan tentang mengubah jumlah polong). Anda bisa mengukur banyak:

Cara melakukannya secara teknis - kumpulkan metrik, dll. - Saya berbicara secara rinci dalam laporan tentang
Pemantauan dan Kubernet . Dan saran utama untuk memilih parameter optimal adalah
bereksperimen !
Ada
metode USE (Utilization Saturation and Errors ), artinya adalah sebagai berikut. Atas dasar apa masuk akal untuk mengukur, misalnya, php-fpm? Berdasarkan kenyataan bahwa pekerja berakhir, itu adalah
pemanfaatan . Dan jika pekerja sudah selesai dan koneksi baru tidak diterima - ini adalah
kejenuhan . Kedua parameter ini perlu diukur, dan tergantung pada nilainya, penskalaan harus dilakukan.
Alih-alih sebuah kesimpulan
Laporan ini memiliki kelanjutan: tentang penskalaan vertikal dan tentang bagaimana memilih sumber daya yang tepat. Saya akan membicarakan ini di video mendatang di
YouTube kami - berlangganan, agar tidak ketinggalan!
Video dan slide
Video dari kinerja (44 menit):
Penyajian laporan:
PS
Laporan Kubernet lainnya di blog kami: