
Entri
Selama bertahun-tahun mengembangkan proyek ML dan DL, studio kami telah mengumpulkan basis kode yang besar, banyak pengalaman, dan wawasan serta kesimpulan yang menarik. Saat memulai proyek baru, pengetahuan yang berguna ini membantu Anda untuk lebih percaya diri memulai penelitian, menggunakan kembali metode yang bermanfaat dan mendapatkan hasil pertama yang lebih cepat.
Sangat penting bahwa semua materi ini tidak hanya di benak pengembang, tetapi juga dalam bentuk yang dapat dibaca pada disk. Ini akan memungkinkan pelatihan karyawan baru yang lebih efektif, memperbarui mereka dan membenamkannya dalam proyek.
Tentu saja, ini tidak selalu terjadi. Kami menghadapi banyak masalah di tahap awal
- Setiap proyek diatur secara berbeda, terutama jika diprakarsai oleh orang yang berbeda.
- Mereka tidak melacak apa yang dilakukan kode, cara menjalankannya, dan siapa penulisnya.
- Mereka tidak menggunakan virtualisasi ke tingkat yang tepat, sering mencegah rekan mereka dari menginstal perpustakaan yang ada dari versi yang berbeda.
- Kesimpulan yang diambil dari grafik yang menetap dan mati di gunung notebook jupyter dilupakan.
- Kehilangan laporan tentang hasil dan kemajuan dalam proyek.
Untuk menyelesaikan masalah ini sekali dan untuk semua, kami memutuskan bahwa kami perlu bekerja baik pada organisasi proyek yang terpadu dan tepat, dan pada virtualisasi, abstraksi komponen individu dan penggunaan kembali kode yang berguna. Secara bertahap, semua kemajuan kita di bidang ini tumbuh menjadi kerangka kerja independen - Lautan.
Cherry on the cake - log proyek, yang dikumpulkan dan berubah menjadi situs yang indah, secara otomatis dikumpulkan menggunakan satu perintah.
Dalam artikel tersebut, kami akan memberi tahu Anda dengan contoh buatan kecil tentang bagian mana Ocean terdiri dan bagaimana menggunakannya.
Mengapa laut
Di dunia ML, ada opsi lain yang telah kami pertimbangkan. Pertama-tama, kita perlu menyebut cookiecutter-data-science (selanjutnya disebut CDS) sebagai inspirasi ideologis. Mari kita mulai dengan yang baik: CDS tidak hanya menawarkan struktur proyek yang nyaman, tetapi juga memberi tahu cara mengelola proyek sehingga semuanya baik-baik saja - oleh karena itu, kami sarankan Anda menyimpang dan melihat ide-ide kunci utama dari pendekatan ini dalam artikel CDS asli .
Berbekal CDS dalam draft kerja, kami segera membawa beberapa perbaikan padanya: kami menambahkan file logger yang nyaman, kelas koordinator yang bertanggung jawab untuk menavigasi proyek dan generator otomatis dokumentasi Sphinx. Selain itu, beberapa perintah dikirimkan ke Makefile, sehingga bahkan seorang yang belum tahu dalam detail manajer proyek pun nyaman untuk mengeksekusinya.
Namun, dalam prosesnya, minus dari pendekatan CDS mulai muncul:
- Folder data dapat tumbuh, tetapi skrip atau buku catatan mana yang menghasilkan file berikutnya tidak sepenuhnya jelas. Sejumlah besar file mudah bingung. Tidak jelas apakah, dalam kerangka implementasi fungsi baru, perlu untuk menggunakan beberapa file yang ada, karena tidak ada deskripsi atau dokumentasi untuk tujuan mereka di mana saja.
- Dalam data, tidak ada cukup banyak fitur subfolder di mana Anda dapat menyimpan tanda: statistik yang dihitung, vektor, dan karakteristik lain dari mana representasi akhir data yang berbeda akan dikumpulkan. Ini sudah sangat ditulis dalam posting blog.
- src adalah folder masalah lain. Ini memiliki fungsi yang relevan untuk seluruh proyek, misalnya, mempersiapkan dan membersihkan data modul src.data . Tetapi ada juga modul src.models , yang berisi semua model dari semua percobaan, dan mungkin ada lusinan di antaranya. Akibatnya, src diperbarui sangat sering, berkembang dengan perubahan yang sangat kecil, dan menurut filosofi CDS, setelah setiap pembaruan, Anda perlu membangun kembali proyek, dan ini juga waktunya ..., - yah, Anda mengerti.
- referensi disajikan, tetapi masih ada pertanyaan terbuka: siapa, kapan dan dalam bentuk apa harus membawa materi ke sana. Dan Anda dapat menceritakan banyak hal selama proyek: pekerjaan apa yang telah dilakukan, apa hasilnya, apa rencana masa depan.
Untuk mengatasi masalah di atas, esensi berikut disajikan di Lautan: percobaan . Eksperimen adalah repositori dari semua data yang terlibat dalam pengujian beberapa hipotesis. Ini dapat mencakup: data apa yang digunakan, data apa (artefak) yang dihasilkan, versi kode, waktu mulai dan berakhirnya percobaan, file yang dapat dieksekusi, parameter, metrik, dan log. Beberapa informasi ini dapat dilacak menggunakan utilitas khusus, misalnya, MLFlow. Namun, struktur percobaan yang disajikan di Samudra lebih kaya dan lebih fleksibel.
Modul satu percobaan adalah sebagai berikut:
<project_root> └── experiments ├── exp-001-Tree-models │ ├── config <- yaml- │ ├── models <- │ ├── notebooks <- │ ├── scripts <- , , train.py predict.py │ ├── Makefile <- │ ├── requirements.txt <- │ └── log.md <- │ ├── exp-002-Gradient-boosting ...
Kami berbagi basis kode: kode bagus yang dapat digunakan kembali yang relevan di seluruh proyek tetap dalam modul src di tingkat proyek. Ini jarang diperbarui, jadi lebih jarang Anda harus membangun sebuah proyek. Dan modul skrip dari satu percobaan harus berisi kode yang hanya relevan untuk percobaan saat ini. Dengan demikian, itu dapat sering diubah: itu tidak mempengaruhi kerja rekan dalam percobaan lain.
Mari kita pertimbangkan kemungkinan kerangka kerja kita menggunakan contoh proyek ML / DL abstrak.
Alur kerja proyek
Inisialisasi
Jadi, klien - polisi Chicago - mengunggah data dan tugas kepada kami: untuk menganalisis kejahatan yang dilakukan di kota selama 2011-2017 dan menarik kesimpulan.
Ayo mulai! Kami pergi ke terminal dan menjalankan perintah:
ocean project new -n Crimes
Kerangka kerja ini telah membuat folder proyek kejahatan yang sesuai. Kami melihat strukturnya:
crimes ├── crimes <- src- , ├── config <- , ├── data <- ├── demos <- ├── docs <- Sphinx- ├── experiments <- ├── notebooks <- EDA ├── Makefile <- ├── log.md <- ├── README.md └── setup.py
Koordinator dari modul dengan nama yang sama, yang sudah ditulis dan siap, membantu menavigasi semua folder ini. Untuk menggunakannya, proyek perlu dirakit:
make package
Ini adalah bug : jika make-command tidak ingin dieksekusi, maka tambahkan flag -B padanya, misalnya, "make -B package". Ini berlaku untuk semua contoh lebih lanjut.
Log dan eksperimen
Kita mulai dengan fakta bahwa data klien, dalam kasus kami file crimes.csv , ditempatkan di folder data / mentah .
Di situs web Chicago ada peta dengan pembagian kota ke dalam pos (“denyut” - lokasi berukuran terkecil tempat satu mobil patroli ditugaskan), sektor (“sektor”, terdiri dari 3-5 pos), bagian (“distrik”, terdiri dari 3 sektor), distrik administratif ("bangsal") dan, akhirnya, area publik ("area komunitas"). Data ini dapat digunakan untuk visualisasi. Pada saat yang sama, file json dengan koordinat bagian poligon dari setiap jenis bukan data yang dikirim oleh pelanggan, jadi kami menempatkannya dalam data / eksternal .
Selanjutnya, Anda perlu memperkenalkan konsep eksperimen. Semuanya sederhana: kami menganggap tugas terpisah sebagai eksperimen terpisah. Perlu mem-parsing / memompa data dan menyiapkannya untuk penggunaan di masa mendatang? Layak untuk dicoba. Mempersiapkan banyak visualisasi dan laporan? Percobaan terpisah. Uji hipotesis dengan menyiapkan model? Nah, Anda mengerti intinya.
Untuk membuat percobaan pertama dari folder proyek, kami melakukan:
ocean exp new -n Parsing -a ivanov
Sekarang folder baru dengan nama exp-001-Parsing telah muncul di folder kejahatan / percobaan , strukturnya diberikan di atas.
Setelah itu, Anda perlu melihat data. Untuk melakukan ini, buat laptop di folder buku catatan yang sesuai. Di Surf, kami mengikuti penamaan "nomor laptop - nama", dan laptop yang dibuat akan disebut 001-Parse-data.ipynb . Di dalam kami akan menyiapkan data untuk pekerjaan lebih lanjut.
Kode Persiapan Data import numpy as np import pandas as pd pd.options.display.max_columns = 100
Agar kolega Anda mengetahui apa yang telah Anda lakukan dan apakah hasil Anda dapat digunakan oleh mereka, Anda perlu mengomentari ini dalam log: file log.md. Struktur log (yang pada dasarnya adalah file penurunan harga yang dikenal) adalah sebagai berikut:

Bagian-bagian yang diisi dengan tangan disorot dalam warna. Meta utama dari eksperimen (warna plum terang) adalah penulis dan penjelasan tentang tugasnya, hasil yang menjadi tujuan percobaan. Tautan ke data, baik yang diambil dan dihasilkan dalam proses (warna hijau), membantu memantau file data dan memahami siapa, dalam apa dan mengapa menggunakannya. Log itu sendiri (warna kuning) menceritakan hasil kerja, kesimpulan dan alasannya. Semua data ini nantinya akan menjadi konten situs log proyek.
Berikutnya adalah tahap EDA ( Analisis Data Eksplorasi - "analisis data intelijen" ). Mungkin itu akan dilakukan oleh orang yang berbeda, dan, tentu saja, kita akan membutuhkan hasil dalam bentuk laporan dan grafik nanti. Argumen ini adalah kesempatan untuk membuat percobaan baru. Kami melakukan:
ocean exp new -n Eda -a ivanov
Di folder buku catatan percobaan, buat buku catatan 001-EDA.ipynb . Kode lengkap tidak masuk akal, tetapi tidak diperlukan, misalnya oleh kolega Anda. Tetapi Anda membutuhkan grafik dan kesimpulan. Banyak kode yang keluar di notebook, dan dengan sendirinya bukan apa yang ingin ditunjukkan kepada klien. Oleh karena itu, kami akan merekam temuan dan wawasan kami di file log.md , dan menyimpan gambar grafik dalam referensi .
Di sini, misalnya, adalah peta daerah aman Chicago, jika nasib membawa Anda ke sana:
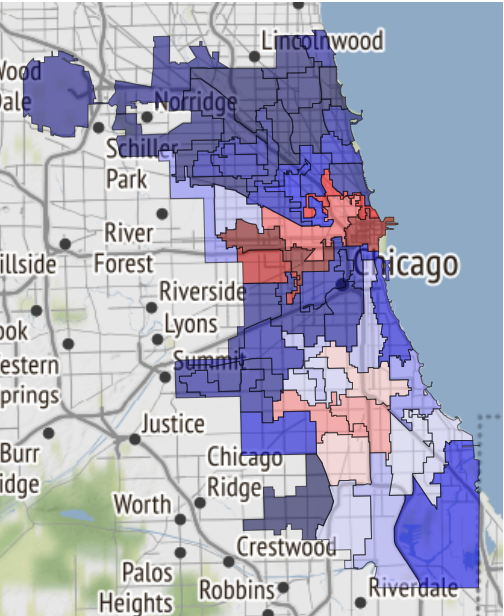
Itu baru saja diterima di buku catatan dan dipindahkan ke referensi .
Entri berikut telah ditambahkan ke log:
19.02.2019, 18:15 EDA conclusion: * The most common and widely spread crimes are theft (including burglary), battery and criminal damage done with firearms. * In 1 case out of 4 the suspect will be set free after detention. [!Criminal activity in different beats of the city](references/beats_activity.jpg) Actual exploration you can check in [the notebook](notebooks/001-Eda.ipynb)
Harap dicatat: bagan dirancang seperti memasukkan gambar ke file md. Dan jika Anda meninggalkan tautan ke buku catatan, itu akan dikonversi ke format html dan disimpan sebagai halaman terpisah di situs.
Untuk mengumpulkannya dari log percobaan, kami menjalankan perintah berikut di tingkat proyek:
ocean log new
Setelah itu, folder crime / project_log dibuat , dan index.html di dalamnya adalah log proyek.
Ini adalah bug : ketika ditampilkan di Jupyter, situs diimplementasikan sebagai iframe untuk keamanan yang lebih besar, dan oleh karena itu font tidak ditampilkan dengan benar. Karena itu, menggunakan Ocean, Anda dapat segera membuat arsip dengan salinan situs tersebut sehingga nyaman untuk mengunduh dan membukanya di komputer lokal atau mengirimkannya melalui surat. Seperti ini:
ocean log archive [-n NAME] [-p PASSWORD]
Dokumentasi
Mari kita lihat membangun dokumentasi menggunakan Sphinx. Buat fungsi di file crime / my_cool_module.py dan dokumentasikan. Perhatikan bahwa Sphinx menggunakan format Teks reStructured (RST):
my_cool_module.py def my_super_cool_random(max_value): ''' Returns a random number from [0; max_value) interval. Considers the number to be taken from uniform distribution. :param max_value: Maximum value that defines range. :returns: Random number. ''' return 4
Dan kemudian semuanya sangat sederhana: di tingkat proyek, kami mengeksekusi tim pembuat dokumentasi, dan Anda siap:
ocean docs new
Pertanyaan dari hadirin : Mengapa, jika kami mengumpulkan proyek melalui make , apakah Anda harus mengumpulkan dokumentasi melalui ocean ?
Jawab : proses pembuatan dokumentasi tidak hanya eksekusi dari perintah Sphinx, yang dapat ditempatkan di make . Ocean mengambil alih pemindaian katalog kode sumber Anda, membuat indeks untuk Sphinx dari mereka, dan hanya kemudian Sphinx itu sendiri mulai bekerja.
Dokumentasi html siap pakai menanti Anda di sepanjang jalan kriminal / docs / _build / html / index.html . Dan modul kami dengan komentar sudah muncul di sana:

Model
Langkah selanjutnya adalah membangun model. Kami melakukan:
ocean exp new -n Model -a ivanov
Dan kali ini, lihat apa yang ada di folder skrip di dalam percobaan. File train.py kosong untuk proses pelatihan di masa depan. File sudah berisi kode boilerplate yang melakukan beberapa hal sekaligus.
- Fungsi pembelajaran mengambil beberapa jalur file:
- Ke file konfigurasi, ke mana masuk akal untuk mentransfer parameter model, parameter pelatihan, dan opsi lain yang nyaman untuk dikendalikan dari luar, tanpa menggali ke dalam kode.
- Ke file data.
- Jalur ke direktori tempat Anda ingin menyimpan dump model akhir.
- Melacak metrik yang diperoleh dalam proses pembelajaran dalam mlflow . Segala sesuatu yang diminta dapat dilihat melalui mlflow UI dengan menjalankan perintah
make dashboard di folder percobaan. - Mengirimkan peringatan ke Telegram Anda bahwa proses pembelajaran telah selesai. Untuk menerapkan mekanisme ini, bot Alarmerbot digunakan . Untuk membuat ini bekerja, Anda perlu melakukan sedikit: mengirim perintah / mulai ke bot, dan kemudian mentransfer token yang dikeluarkan oleh bot ke file crime / config / alarm_config.yml . String mungkin terlihat seperti ini:
ivanov: a5081d-1b6de6-5f2762 - Itu dikendalikan dari konsol.
Mengapa mengelola skrip kami dari konsol? Semuanya diatur sedemikian rupa sehingga proses pembelajaran atau mendapatkan prediksi model apa pun mudah diatur oleh pengembang pihak ketiga yang tidak terbiasa dengan detail implementasi percobaan Anda. Agar semua potongan puzzle cocok , setelah desain train.py, Anda perlu mengatur Makefile . Ini memiliki konsep perintah kereta , dan Anda hanya perlu mengatur jalur dengan benar ke file konfigurasi yang diperlukan yang tercantum di atas, dan daftar semua orang yang ingin menerima pemberitahuan Telegram dalam nilai parameter nama pengguna. Khususnya, alias all berfungsi, yang akan mengirimkan peringatan ke semua anggota tim.
Setelah semuanya siap, percobaan kami dimulai dengan perintah make train , sederhana dan elegan.
Jika Anda ingin menggunakan jaringan saraf orang lain, lingkungan virtual ( venv ) akan membantu. Membuat dan menghapusnya sebagai bagian dari eksperimen sangat mudah:
ocean env new akan menciptakan lingkungan baru. Tidak hanya aktif secara default, tetapi juga membuat kernel (kernel) tambahan untuk notebook dan untuk penelitian lebih lanjut. Itu akan dipanggil dengan cara yang sama dengan nama percobaan.ocean env list menampilkan daftar inti.ocean env delete akan ocean env delete lingkungan yang dibuat dalam percobaan.
Apa yang hilang
- Ocean tidak berteman dengan conda (
karena kita tidak menggunakannya ) - Template proyek hanya dalam bahasa Inggris.
- Masalah lokalisasi masih berlaku untuk situs: pembangunan log proyek mengasumsikan bahwa semua log dalam bahasa Inggris.
Kesimpulan
Kode sumber proyek ada di sini .
Jika Anda tertarik - hebat! Anda dapat menemukan informasi lebih lanjut di README di repositori Samudra .
Dan seperti yang biasa mereka katakan dalam kasus seperti itu, kontribusi diterima, kami hanya akan senang jika Anda berpartisipasi dalam meningkatkan proyek.