Masalah utama bekerja dengan database terkait dengan fitur perangkat dari sistem operasi tempat database bekerja. Linux sekarang menjadi sistem operasi utama untuk basis data. Solaris, Microsoft dan bahkan HPUX masih digunakan di perusahaan, tetapi mereka tidak akan pernah menempati posisi pertama, bahkan ketika digabungkan. Linux dengan percaya diri mendapatkan dukungan karena semakin banyak basis data open source. Oleh karena itu, masalah interaksi database dengan OS jelas tentang database Linux. Ini ditumpangkan pada masalah DB abadi - kinerja IO. Adalah baik bahwa dalam beberapa tahun terakhir Linux telah mengalami perombakan besar dari tumpukan IO dan ada harapan untuk pencerahan.
Ilya Kosmodemyansky (
hydrobiont ) bekerja untuk Data Egret, sebuah perusahaan yang
berkonsultasi dan mendukung PostgreSQL, dan tahu banyak tentang interaksi antara OS dan basis data. Dalam sebuah laporan tentang HighLoad ++, Ilya berbicara tentang interaksi IO dan basis data menggunakan contoh PostgreSQL, tetapi juga menunjukkan bagaimana basis data lainnya bekerja dengan IO. Saya melihat tumpukan IO Linux, hal-hal baru dan bagus muncul di dalamnya dan mengapa semuanya tidak seperti beberapa tahun yang lalu. Sebagai pengingat yang berguna - daftar periksa pengaturan PostgreSQL dan Linux untuk kinerja maksimum subsistem IO di kernel baru.
Video laporan berisi banyak bahasa Inggris, yang sebagian besar kami terjemahkan dalam artikel.Mengapa berbicara tentang IO?
I / O yang cepat adalah hal yang paling penting bagi administrator database . Semua orang tahu apa yang bisa diubah dalam bekerja dengan CPU, bahwa memori dapat diperluas, tetapi I / O dapat merusak segalanya. Jika buruk dengan disk, dan terlalu banyak I / O, maka database akan mengerang. IO akan menjadi hambatan.
Agar semuanya berfungsi dengan baik, Anda perlu mengkonfigurasi semuanya.
Bukan hanya database atau hanya perangkat keras - itu saja. Bahkan Oracle tingkat tinggi, yang merupakan sistem operasi di beberapa tempat, memerlukan konfigurasi. Kami membaca instruksi di "Panduan Instalasi" dari Oracle: ubah parameter kernel seperti itu, ubah yang lain - ada banyak pengaturan. Selain fakta bahwa di Unbreakable Kernel, banyak sudah secara default kabel ke Oracle Linux.
Untuk PostgreSQL dan MySQL, diperlukan lebih banyak perubahan. Ini karena teknologi ini bergantung pada mekanisme OS. DBA yang bekerja dengan PostgreSQL, MySQL, atau NoSQL modern haruslah seorang insinyur operasi Linux dan memuntir kacang OS yang berbeda.
Setiap orang yang ingin berurusan dengan pengaturan kernel, beralih ke
LWN . Sumber daya cerdik, minimalis, berisi banyak informasi berguna, tetapi
ditulis oleh pengembang kernel untuk pengembang kernel . Apa yang ditulis dengan baik oleh pengembang kernel? Intinya, bukan artikelnya, bagaimana menggunakannya. Karena itu, saya akan mencoba menjelaskan semuanya kepada Anda untuk para pengembang, dan biarkan mereka menulis kernel.
Semuanya menjadi rumit berkali-kali oleh kenyataan bahwa pada awalnya pengembangan kernel Linux dan pemrosesan stacknya tertinggal, dan dalam beberapa tahun terakhir ini telah berjalan sangat cepat. Baik besi maupun pengembang dengan artikel di belakangnya mengikuti.
Basis data tipikal
Mari kita mulai dengan contoh untuk PostgreSQL - ini buffered I / O. Ini memiliki memori bersama, yang dialokasikan di
ruang pengguna dari sudut pandang OS, dan memiliki cache yang sama di cache kernel di
ruang Kernel .
 Tugas utama dari database modern
Tugas utama dari database modern :
- mengambil halaman dari disk di memori;
- ketika perubahan terjadi, tandai halaman sebagai kotor;
- tulis ke Write-Ahead Log;
- kemudian sinkronkan memori sehingga konsisten dengan disk.
Dalam situasi PostgreSQL, ini adalah perjalanan pulang-pergi yang konstan: dari memori bersama yang dikendalikan PostgreSQL di kernel Halaman Cache, dan kemudian ke disk melalui seluruh tumpukan Linux. Jika Anda menggunakan database pada sistem file, itu akan bekerja pada algoritma ini dengan sistem seperti UNIX dan dengan database apa pun. Perbedaan itu, tetapi tidak signifikan.
Menggunakan Oracle ASM akan berbeda - Oracle sendiri berinteraksi dengan disk. Tetapi prinsipnya sama: dengan Direct IO atau dengan Page Cache, tetapi tugasnya adalah
menggambar halaman melalui seluruh tumpukan I / O secepat mungkin , apa pun itu. Dan masalah bisa muncul di setiap tahap.
Dua masalah IO
Sementara semuanya
hanya dibaca , tidak ada masalah. Mereka membaca dan, jika ada cukup memori, semua data yang perlu dibaca ditempatkan dalam RAM. Fakta bahwa dalam kasus PostgreSQL di
Buffer Cache adalah sama, kami tidak terlalu khawatir.
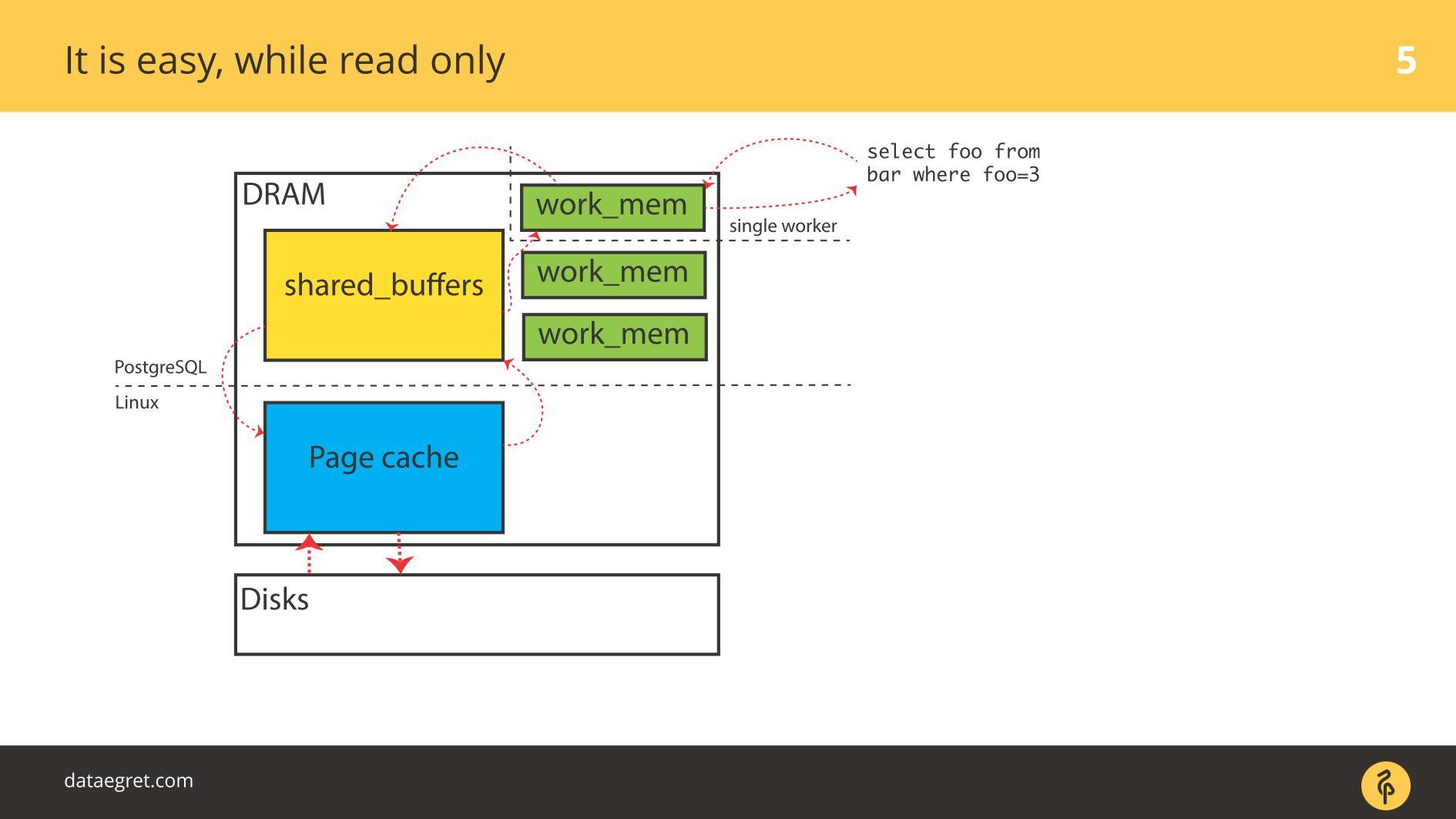 Masalah pertama dengan IO adalah sinkronisasi cache.
Masalah pertama dengan IO adalah sinkronisasi cache. Terjadi saat perekaman diperlukan. Dalam hal ini, Anda harus bolak-balik lebih banyak memori.
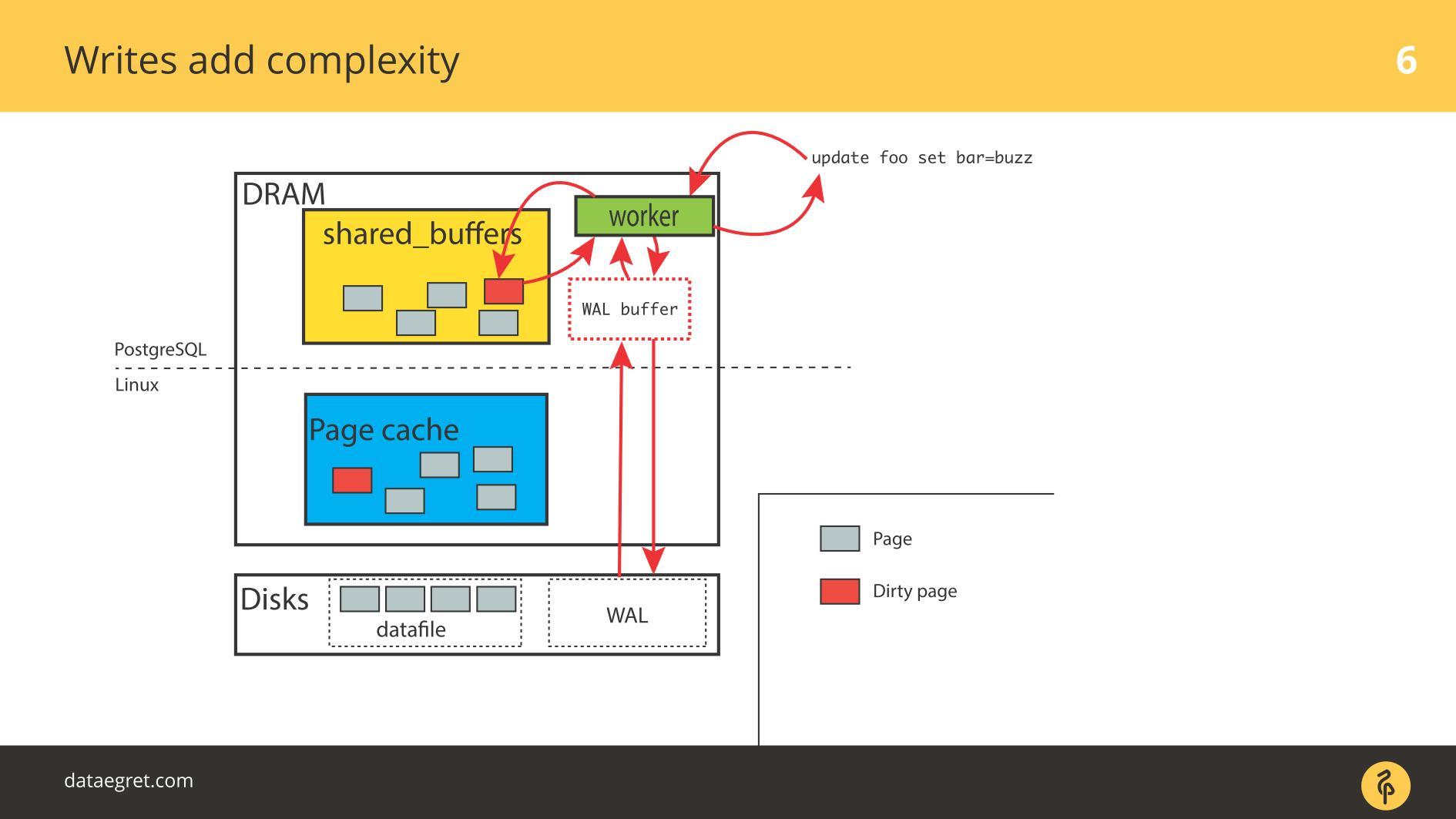
Oleh karena itu, Anda perlu mengonfigurasi PostgreSQL atau MySQL agar semuanya dapat disk dari memori bersama. Dalam kasus PostgreSQL - Anda masih perlu memperbaiki kecurangan latar belakang halaman-halaman kotor di Linux untuk mengirim semuanya ke disk.
Masalah umum kedua adalah kegagalan tulis Write-Ahead Log . Itu muncul ketika beban sangat kuat sehingga bahkan log yang direkam berurutan bersandar pada disk. Dalam situasi ini, itu juga perlu direkam dengan cepat.
Situasinya tidak jauh berbeda dari
sinkronisasi cache . Dalam PostgreSQL, kami bekerja dengan sejumlah besar buffer bersama, database memiliki mekanisme untuk perekaman Write-Ahead Log yang efisien, dioptimalkan hingga batasnya. Satu-satunya hal yang dapat dilakukan untuk membuat log itu sendiri lebih efisien adalah mengubah pengaturan Linux.
Masalah utama bekerja dengan database
Segmen memori bersama bisa sangat besar . Saya mulai membicarakan hal ini di konferensi pada tahun 2012. Lalu saya mengatakan bahwa memori telah jatuh harga, bahkan ada server dengan 32 GB RAM. Pada 2019, mungkin sudah ada lebih banyak di laptop, lebih dan lebih sering di server 128, 256, dll.
Benar-benar banyak memori . Rekaman banal membutuhkan waktu dan sumber daya, dan
teknologi yang kami gunakan untuk ini konservatif . Database sudah tua, mereka telah dikembangkan untuk waktu yang lama, mereka perlahan berkembang. Mekanisme dalam database tidak sepenuhnya tepat dengan teknologi terbaru.
Menyinkronkan halaman dalam memori dengan hasil disk dalam operasi IO besar . Ketika kami menyinkronkan cache, aliran besar IO muncul, dan masalah lain muncul -
kami tidak dapat memutar sesuatu dan melihat efeknya. Dalam eksperimen ilmiah, para peneliti mengubah satu parameter - dapatkan efeknya, yang kedua - dapatkan efeknya, yang ketiga. Kami tidak akan berhasil. Kami memutar beberapa parameter di PostgreSQL, mengkonfigurasi pos pemeriksaan - kami tidak melihat efeknya. Kemudian konfigurasikan kembali seluruh tumpukan untuk mendapatkan setidaknya beberapa hasil. Memutar satu parameter tidak berfungsi - kita dipaksa untuk mengkonfigurasi semuanya sekaligus.
Kebanyakan IO PostgreSQL menghasilkan sinkronisasi halaman: pos-pos pemeriksaan dan mekanisme sinkronisasi lainnya. Jika Anda bekerja dengan PostgreSQL, Anda mungkin telah melihat titik-titik pemeriksaan melonjak ketika "gergaji" muncul secara berkala di grafik. Sebelumnya, banyak yang menghadapi masalah ini, tetapi sekarang ada manual tentang cara memperbaikinya, menjadi lebih mudah.
SSD saat ini sangat menghemat situasi. Di PostgreSQL, sesuatu jarang bersandar langsung pada catatan nilai. Semuanya tergantung pada sinkronisasi: ketika sebuah pos pemeriksaan terjadi, fsync dipanggil dan ada semacam “pemukulan” terhadap satu pos pemeriksaan yang lain. Terlalu banyak IO. Satu pos pemeriksaan belum berakhir, belum menyelesaikan semua fsync-nya, tetapi sudah mendapatkan pos pemeriksaan lain, dan sudah dimulai!
PostgreSQL memiliki fitur unik -
autovacuum . Ini adalah sejarah panjang kruk untuk arsitektur basis data. Jika autovacuum gagal, mereka biasanya mengaturnya sehingga bekerja secara agresif dan tidak mengganggu sisanya: ada banyak pekerja autovacuum, sering tersandung sedikit, memproses tabel dengan cepat. Kalau tidak, akan ada masalah dengan DDL dan dengan kunci.
Tetapi ketika Autovacuum agresif, ia mulai mengunyah IO.
Jika autovacuum ditumpangkan pada pos pemeriksaan, maka sebagian besar disk waktu hampir 100% didaur ulang, dan ini adalah sumber masalahnya.
Anehnya, ada masalah
isi ulang Cache . Dia biasanya kurang dikenal untuk DBA. Contoh khas: basis data dimulai, dan untuk beberapa saat semuanya melambat dengan sedih. Oleh karena itu, bahkan jika Anda memiliki banyak RAM, beli disk yang bagus sehingga tumpukan menghangatkan cache.
Semua ini sangat memengaruhi kinerja. Masalah mulai tidak segera setelah me-restart database, tetapi kemudian. Misalnya, pos pemeriksaan lulus, dan banyak halaman kotor di seluruh basis data. Mereka disalin ke disk karena Anda perlu menyinkronkannya. Kemudian permintaan meminta versi halaman baru dari disk, dan basis data melorot. Grafik akan menunjukkan bagaimana isi ulang Cache setelah setiap pos pemeriksaan menyumbangkan persentase tertentu ke beban.
Hal yang paling tidak menyenangkan dalam input / output dari database adalah
Worker IO. Ketika setiap pekerja yang Anda minta, mulai menghasilkan IO-nya. Di Oracle, lebih mudah dengan itu, tetapi di PostgreSQL itu masalah.
Ada banyak alasan untuk masalah dengan
Worker IO : tidak ada cukup cache untuk "memposting" halaman baru dari disk. Misalnya, semua buffer dibagi, semuanya kotor, pos pemeriksaan belum. Agar pekerja dapat melakukan pemilihan yang paling sederhana, Anda perlu mengambil cache dari suatu tempat. Untuk melakukan ini, pertama-tama Anda harus menyimpan semuanya ke disk. Anda tidak memiliki proses checkpointer khusus, dan pekerja mulai fsync untuk membebaskan dan mengisinya dengan sesuatu yang baru.
Ini menimbulkan masalah yang lebih besar: pekerja adalah hal yang tidak terspesialisasi, dan seluruh proses tidak dioptimalkan sama sekali. Dimungkinkan untuk mengoptimalkan di suatu tempat di tingkat Linux, tetapi di PostgreSQL ini adalah tindakan darurat.
Masalah IO utama untuk DB
Masalah apa yang kita pecahkan ketika kita mengatur sesuatu? Kami ingin memaksimalkan perjalanan halaman kotor antara disk dan memori.
Tetapi sering terjadi hal-hal ini tidak menyentuh disk secara langsung. Kasus khas - Anda melihat rata-rata beban yang sangat besar. Kenapa begitu Karena seseorang sedang menunggu disk, dan semua proses lain juga menunggu. Tampaknya tidak ada pemanfaatan disk yang eksplisit dari disk, hanya sesuatu yang memblokir disk di sana, dan masalahnya adalah dengan input / output.
Masalah I / O basis data tidak selalu hanya menyangkut disk.
Semuanya terlibat dalam masalah ini: disk, memori, CPU, Penjadwal IO, sistem file, dan pengaturan basis data. Sekarang mari kita melihat tumpukan, melihat apa yang harus dilakukan dengannya, dan hal-hal baik apa yang telah ditemukan di Linux sehingga semuanya bekerja lebih baik.
Disk
Selama bertahun-tahun, disk sangat lambat dan tidak ada yang terlibat dalam latensi atau optimalisasi tahap transisi. Mengoptimalkan fsyncs tidak masuk akal. Disk berputar, kepala bergerak seperti catatan fonograf, dan fsyncs begitu lama sehingga masalah tidak muncul.
Memori
Percuma untuk melihat kueri teratas tanpa menyetel basis data. Anda akan mengonfigurasi jumlah memori bersama yang memadai, dll., Dan Anda akan memiliki kueri teratas baru - Anda harus mengonfigurasinya lagi. Ini kisah yang sama. Seluruh tumpukan Linux dibuat dari perhitungan ini.
Bandwidth dan latensi
Memaksimalkan kinerja IO dengan memaksimalkan throughput mudah sampai titik tertentu. Proses PageWriter tambahan ditemukan di PostgreSQL yang menurunkan pos pemeriksaan. Pekerjaan telah menjadi paralel, tetapi masih ada dasar untuk penambahan paralelisme. Dan untuk meminimalkan latensi adalah tugas dari mil terakhir, yang membutuhkan teknologi super.
Teknologi super ini adalah SSD. Ketika mereka muncul, latensi turun tajam. Tetapi pada semua tahap tumpukan lainnya, muncul masalah: baik dari sisi pabrikan basis data maupun dari pabrikan Linux. Masalah perlu diatasi.
Pengembangan basis data berpusat pada memaksimalkan throughput, seperti halnya pengembangan kernel Linux. Banyak metode untuk mengoptimalkan era I / O disk berputar tidak begitu baik untuk SSD.
Di antaranya, kami terpaksa membuat cadangan untuk infrastruktur Linux saat ini, tetapi dengan disk baru. Kami menyaksikan pengujian kinerja dari pabrikan dengan sejumlah besar IOPS berbeda, dan basis data tidak membaik, karena basis data tidak hanya dan tidak begitu banyak tentang IOPS. Sering terjadi bahwa kita dapat melewati 50.000 IOPS per detik, itu bagus. Tetapi jika kita tidak tahu latensi, tidak tahu distribusinya, maka kita tidak bisa mengatakan apa-apa tentang kinerja. Pada titik tertentu, database akan mulai memeriksa, dan latensi akan meningkat secara dramatis.
Untuk waktu yang lama, seperti sekarang, ini telah menjadi masalah kinerja besar pada database virtuala. Virtual IO ditandai dengan latensi yang tidak merata, yang tentu saja juga menimbulkan masalah.
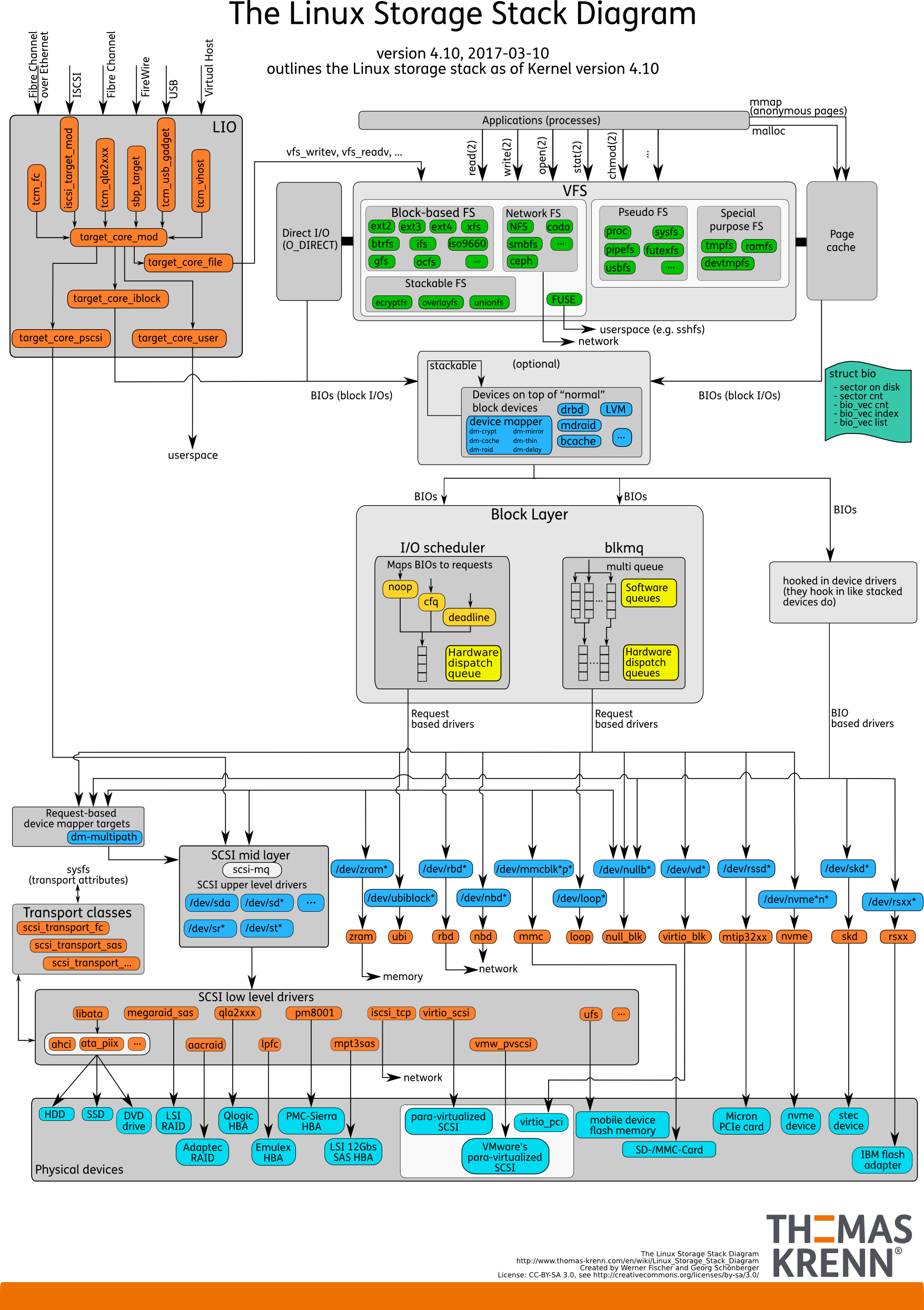
Tumpukan IO. Seperti sebelumnya
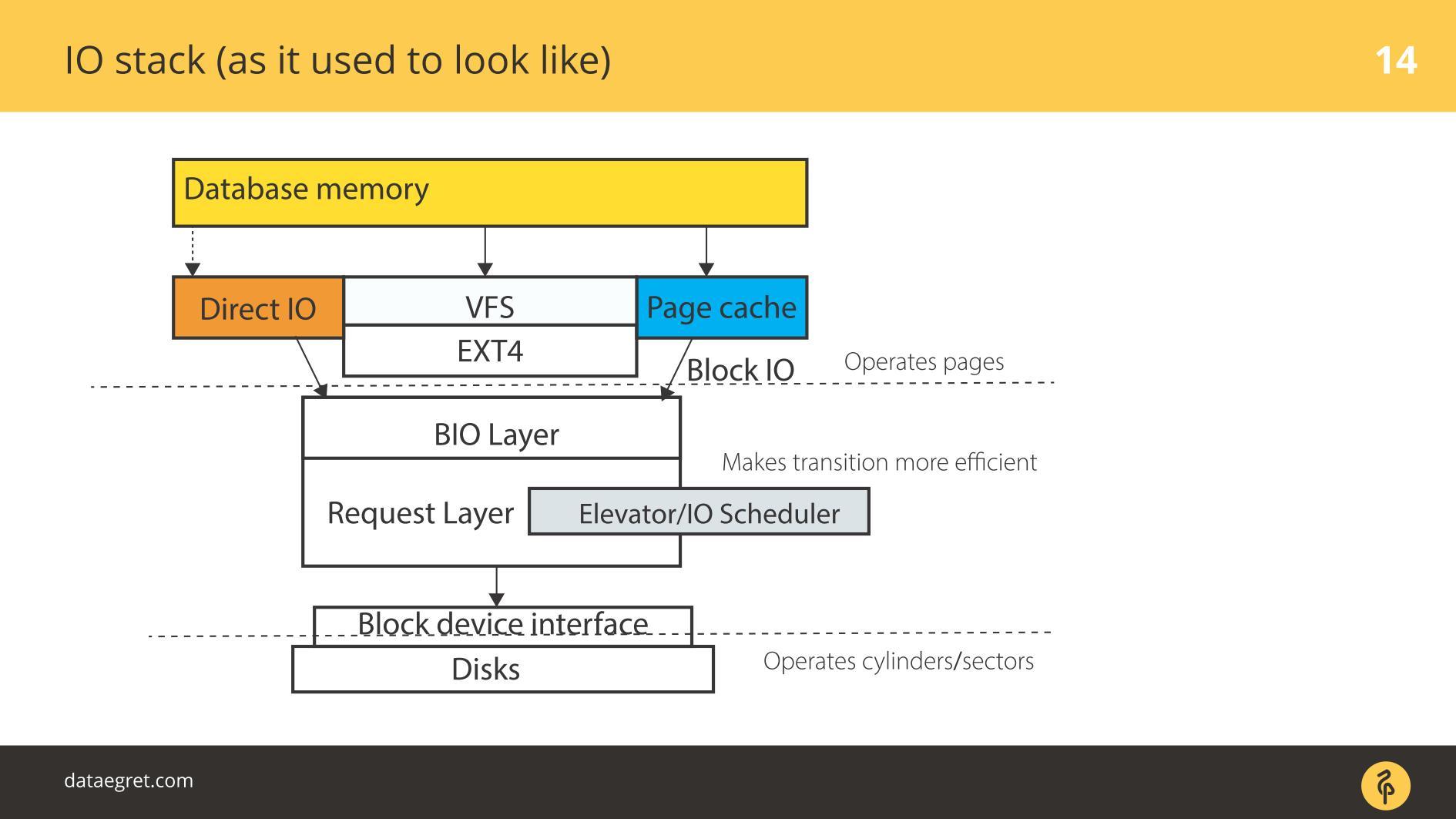
Ada ruang pengguna - memori itu, yang dikelola oleh database itu sendiri. Dalam DB dikonfigurasi sehingga semuanya berfungsi sebagaimana mestinya. Ini dapat dilakukan dalam laporan terpisah, dan bahkan tidak satu. Kemudian semuanya pasti akan melalui Page Cache atau melalui antarmuka IO langsung itu memasuki lapisan
Input / Output Block .
Bayangkan sebuah antarmuka sistem file. Halaman-halaman yang ada di Buffer Cache, karena mereka awalnya di database, yaitu, blok, keluar melaluinya. Blok IO berurusan dengan layer berikut. Ada struktur C yang menggambarkan blok di kernel. Struktur mengambil blok ini dan mengumpulkan dari mereka vektor (array) dari permintaan input atau output. Di bawah lapisan BIO adalah lapisan pemohon. Vektor dikumpulkan pada layer ini dan akan melangkah lebih jauh.
Untuk waktu yang lama, dua lapisan ini di Linux dipertajam untuk perekaman yang efisien pada disk magnetik. Itu tidak mungkin dilakukan tanpa transisi. Ada beberapa blok yang nyaman untuk dikelola dari basis data. Hal ini diperlukan untuk merakit blok-blok ini menjadi vektor yang mudah ditulis ke disk sehingga mereka berada di suatu tempat di dekatnya. Agar ini berfungsi secara efektif, mereka datang dengan Elevators, atau Schedulers IO.
Elevator
Elevators terutama terlibat dalam menggabungkan dan menyortir vektor. Semua agar driver blok SD - driver quasidisk - blok rekaman untuk tiba dalam urutan yang nyaman baginya. Pengemudi menerjemahkan dari blok ke sektornya dan menulis ke disk.
Masalahnya adalah bahwa perlu untuk melakukan beberapa transisi, dan pada masing-masing menerapkan logika mereka sendiri dari proses optimal.
Elevators: hingga kernel 2.6
Sebelum kernel 2.6, ada Linus Elevator - Penjadwal IO paling primitif, yang ditulis oleh Anda menebak siapa. Untuk waktu yang lama ia dianggap benar-benar tak tergoyahkan dan baik, sampai mereka mengembangkan sesuatu yang baru.
Linus Elevator punya banyak masalah.
Dia menggabungkan dan mengurutkan berdasarkan cara merekam dengan lebih efisien . Dalam hal memutar disk mekanis, ini menyebabkan munculnya "
kelaparan" : situasi di mana efisiensi perekaman tergantung pada rotasi disk. Jika Anda tiba-tiba perlu membaca secara efektif pada saat yang sama, tetapi sudah diputar salah, buruk dibaca dari disk seperti itu.
Secara bertahap, menjadi jelas bahwa ini adalah cara yang tidak efisien. Oleh karena itu, dimulai dengan kernel 2.6, seluruh kebun binatang penjadwal mulai muncul, yang dimaksudkan untuk tugas yang berbeda.
Elevator: antara 2,6 dan 3
Banyak orang mengacaukan penjadwal ini dengan penjadwal sistem operasi karena mereka memiliki nama yang mirip.
CFQ - Antrian Sepenuhnya Adil tidak sama dengan penjadwal OS. Hanya namanya saja yang mirip. Itu diciptakan sebagai penjadwal universal.
Apa itu penjadwal universal? Apakah Anda pikir Anda memiliki beban rata-rata atau, sebaliknya, beban yang unik? Database memiliki fleksibilitas yang sangat buruk. Beban universal dapat dibayangkan sebagai laptop biasa. Segala sesuatu terjadi di sana: kita mendengarkan musik, memutar, mengetik teks. Untuk ini, hanya penjadwal universal yang ditulis.
Tugas utama dari penjadwal universal: dalam kasus Linux, untuk setiap terminal dan proses virtual, buat antrian permintaan. Ketika kami ingin mendengarkan musik di pemutar audio, IO untuk pemain akan mengantre. Jika kita ingin mencadangkan sesuatu menggunakan perintah cp, ada sesuatu yang lain yang terlibat.
Dalam kasus database, terjadi masalah. Sebagai aturan, database adalah proses yang dimulai, dan selama operasi, proses paralel muncul yang selalu berakhir dalam antrian I / O yang sama. Alasannya adalah bahwa ini adalah aplikasi yang sama, proses induk yang sama. Untuk muatan yang sangat kecil, penjadwalan seperti itu cocok, untuk yang lain tidak masuk akal. Lebih mudah untuk mematikan dan tidak digunakan jika memungkinkan.
Secara bertahap,
deadline scheduler muncul - ia bekerja lebih licik, tetapi pada dasarnya itu adalah penggabungan dan pengurutan untuk disk yang berputar. Mengingat desain subsistem disk tertentu, kami mengumpulkan vektor blok untuk menuliskannya secara optimal. Dia memiliki lebih sedikit masalah dengan
kelaparan , tetapi mereka ada di sana.
Oleh karena itu, lebih dekat ke kernel Linux ketiga muncul
noop or
none , yang bekerja lebih baik dengan penyebaran SSD. Termasuk penjadwal noop, kami sebenarnya menonaktifkan penjadwalan: tidak ada penyortiran, penggabungan, dan hal serupa yang dilakukan CFQ dan tenggat waktu.
Ini berfungsi lebih baik dengan SSD, karena SSD secara inheren paralel: ia memiliki sel memori. Semakin banyak elemen ini dijejalkan pada satu papan PCIe, semakin efisien itu akan bekerja.
Penjadwal dari beberapa dunia lain, dari sudut pandang SSD, pertimbangan, mengumpulkan beberapa vektor dan mengirimkannya ke suatu tempat. Semuanya berakhir dengan corong. Jadi kita membunuh konkurensi SSD, jangan menggunakannya secara maksimal. Oleh karena itu, shutdown sederhana, ketika vektor berjalan secara acak tanpa penyortiran, bekerja lebih baik dalam hal kinerja. Karena itu, diyakini bahwa pembacaan acak, penulisan acak lebih baik pada SSD.
Elevator: 3,13 dan seterusnya
Dimulai dengan kernel 3.13,
blk-mq muncul . Sedikit sebelumnya ada prototipe, tetapi pada 3.13 versi yang berfungsi pertama kali muncul.
Blk-mq dimulai sebagai penjadwal, tetapi sulit untuk menyebutnya penjadwal - itu berdiri sendiri secara arsitektur. Ini adalah pengganti untuk lapisan permintaan di kernel. Perlahan-lahan, pengembangan blk-mq menyebabkan perombakan besar-besaran dari seluruh tumpukan I / O Linux.
Idenya adalah ini: mari kita gunakan kemampuan asli SSD untuk melakukan konkurensi yang efisien untuk I / O. Bergantung pada berapa banyak aliran I / O paralel yang dapat Anda gunakan, ada antrian yang jujur di mana kami cukup menulis seperti pada SSD. Setiap CPU memiliki antrian sendiri untuk merekam.
Saat ini
blk-mq sedang aktif mengembangkan dan bekerja. Tidak ada alasan untuk tidak menggunakannya. Dalam core modern, dari 4 ke atas, dari
blk-mq, keuntungannya terlihat - bukan 5-10%, tetapi lebih signifikan.
blk-mq mungkin merupakan opsi terbaik untuk bekerja dengan SSD.
Dalam bentuknya saat ini,
blk-mq secara langsung terkait dengan driver
NVMe Linux. Tidak hanya driver untuk Linux, tetapi juga driver untuk Microsoft. Tetapi ide untuk membuat
blk-mq dan driver NVMe adalah sangat pemrosesan tumpukan Linux, dari mana database sangat diuntungkan.
Konsorsium beberapa perusahaan memutuskan untuk membuat spesifikasi, protokol ini. Sekarang sudah dalam versi produksi berfungsi dengan baik untuk SSD PCIe lokal. Solusi yang hampir siap untuk array disk yang terhubung melalui optik.
Driver blk-mq dan NVMe lebih dari sekadar penjadwal. Sistem ini bertujuan untuk mengganti seluruh tingkat permintaan.
Mari selami itu untuk memahami apa itu. Spesifikasi NVMe besar, jadi kami tidak akan mempertimbangkan semua detail, tetapi hanya membahasnya.
Pendekatan lama untuk elevator

Kasus paling sederhana: ada CPU, ada gilirannya, dan entah bagaimana kita pergi ke disk.
Elevators yang lebih maju bekerja secara berbeda. Ada beberapa CPU dan beberapa antrian. Entah bagaimana, misalnya, tergantung pada proses induk mana pekerja basis data berputar, IO akan antri pada disk.
Pendekatan baru untuk lift
blk-mq adalah pendekatan yang sama sekali baru. Setiap CPU, setiap zona NUMA menambahkan input / output sendiri pada gilirannya. Lebih lanjut, data jatuh pada disk, tidak peduli seberapa terhubung, karena driver baru. Tidak ada driver SD yang beroperasi dengan konsep silinder, balok.
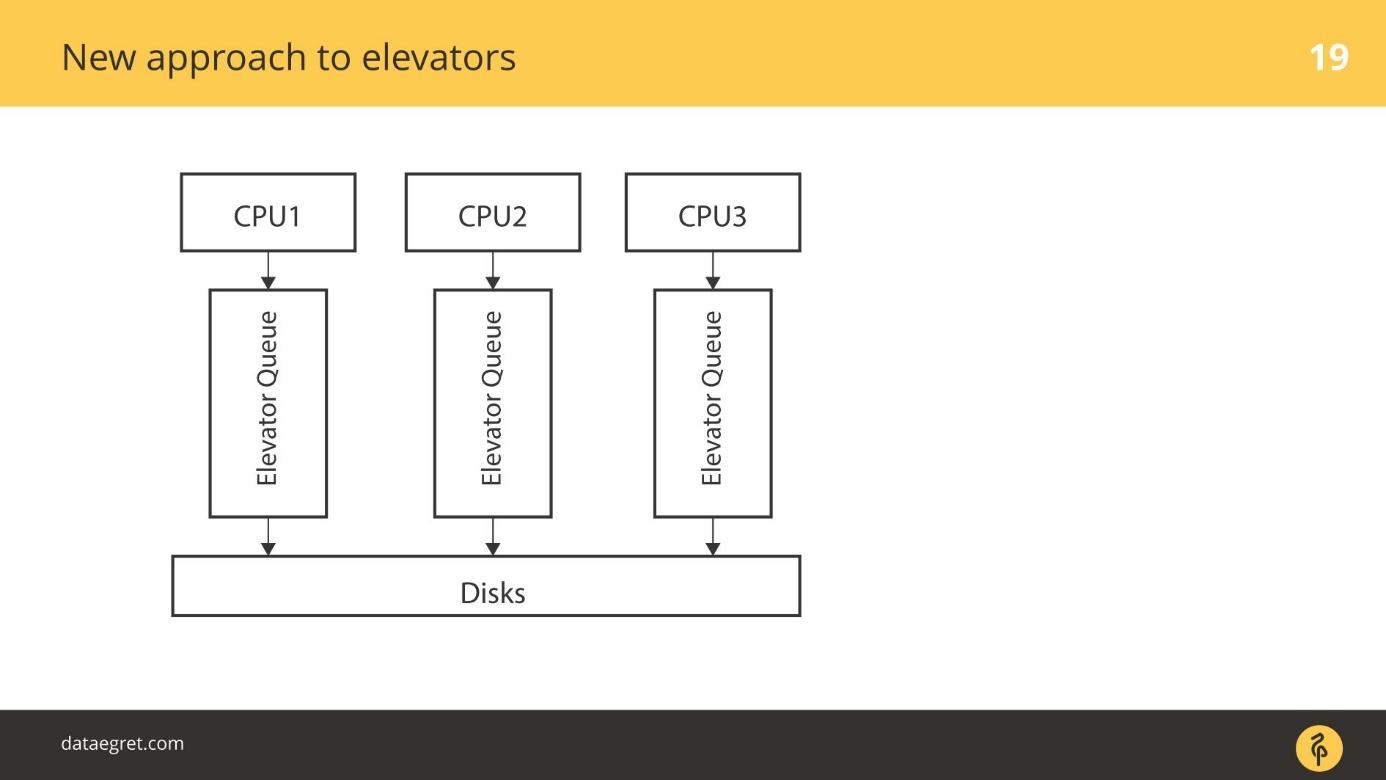
Ada masa transisi. Pada titik tertentu, semua vendor array RAID mulai menjual add-on yang memungkinkan mereka untuk mem-bypass cache RAID. Jika SSD terhubung, tulis langsung di sana. Mereka mematikan penggunaan driver SD untuk produk mereka, seperti blq-mq.
Tumpukan baru dengan blk-mq
Beginilah tampilan tumpukan dalam formulir baru.

Dari atas semuanya tetap ada juga. Sebagai contoh, basis data jauh di belakang. I / O dari database sama seperti sebelumnya, jatuh ke dalam lapisan Block IO. Ada sangat
blk-mq yang menggantikan lapisan kueri, bukan penjadwal.
Di kernel 3.13, seluruh optimisasi berakhir pada saat itu, tetapi teknologi baru digunakan dalam kernel modern. Penjadwal khusus untuk
blk-mq mulai muncul, yang dirancang untuk paralelisme yang lebih kuat. Linux schedulers IO — Kyber BFQ.
blk-mq .
BFQ — Budget Fair Queueing — FQ . , . BFQ — scheduler . IO. IO, / . , . — . BFQ, , .
Kyber — . BFQ, . Kyber scheduler . — CPU . Kyber .
—
blk-mq SD- . , , , IO-. blk-mq NVMe driver . .
— latency, . SSD, — . -, , NVMe-, blk-mq , . .
Linux IO
/ Linux.
, , , Elevators, .
, , .
NVM Express
NVM Express NVMe — , , SSD. Linux. Linux — .
. 20 / SSD , NVMe , , —
32 / . SD , , .
, , .
Begitu database ditulis untuk memutar disk dan berorientasi padanya - mereka memiliki indeks dalam bentuk B-tree, misalnya.
Muncul pertanyaan:
apakah basis data siap untuk NVMe ? Apakah database mampu mengunyah beban seperti itu?
Belum, tetapi mereka beradaptasi. Milis PostgreSQL baru-baru ini memiliki beberapa
pwrite() dan hal-hal serupa. Pengembang PostgreSQL dan MySQL berinteraksi dengan pengembang kernel. Tentu saja, saya ingin lebih banyak interaksi.
Perkembangan Terkini
Selama satu setengah tahun terakhir, NVMe telah menambahkan
polling IO .
Pada awalnya ada cakram berputar dengan latensi tinggi. Kemudian muncul SSD, yang jauh lebih cepat. Tetapi ada masalah: fsync berlanjut, rekaman dimulai, dan pada tingkat yang sangat rendah - jauh di dalam pengemudi, permintaan dikirim langsung ke perangkat keras - tuliskan.
Mekanismenya sederhana - mereka mengirimkannya dan kami menunggu sampai interupsi diproses. Menunggu pemrosesan interupsi bukanlah masalah dibandingkan dengan menulis ke disk pemintalan. Butuh waktu lama untuk menunggu sehingga segera setelah rekaman berakhir, interupsi itu bekerja.
Karena SSD menulis dengan sangat cepat, mekanisme untuk polling perangkat keras tentang rekaman telah muncul dengan paksa. Pada versi pertama, peningkatan kecepatan I / O mencapai 50% karena fakta bahwa kami tidak menunggu gangguan, tetapi kami secara aktif bertanya pada besi tentang catatan tersebut.
Mekanisme ini disebut polling IO .
Itu diperkenalkan dalam versi terbaru. Dalam versi 4.12,
penjadwal IO muncul, khusus dipertajam untuk bekerja dengan
blk-mq dan NVMe, tentang yang saya katakan
Kyber dan BFQ . Mereka sudah resmi di kernel, mereka bisa digunakan.
Sekarang dalam bentuk yang dapat digunakan ada yang disebut
penandaan IO . Sebagian besar produsen cloud dan mesin virtual akan berkontribusi pada pengembangan ini. Secara kasar, masukan dari aplikasi tertentu dapat diatasi dan memberikan prioritas. Basis data belum siap untuk ini, tetapi tetap disini. Saya pikir ini akan menjadi mainstream segera.
Catatan IO Langsung
PostgreSQL tidak mendukung Direct IO, dan ada sejumlah masalah yang membuatnya sulit untuk mengaktifkan dukungan . Sekarang ini hanya didukung untuk nilai, dan hanya jika replikasi tidak diaktifkan. Diperlukan
untuk menulis banyak kode khusus OS , dan untuk saat ini semua orang tidak melakukan hal ini.
Terlepas dari kenyataan bahwa Linux sangat bergantung pada gagasan Direct IO dan bagaimana implementasinya, semua database masuk ke sana. Di Oracle dan MySQL, Direct IO banyak digunakan. PostgreSQL adalah satu-satunya basis data yang tidak dapat ditoleransi oleh IO Langsung.
Periksa daftar
Cara melindungi diri Anda dari kejutan fsync di PostgreSQL:
- Atur pos pemeriksaan agar lebih jarang dan lebih besar.
- Atur penulis latar belakang untuk membantu pos pemeriksaan.
- Tarik Autovacuum sehingga tidak ada I / O palsu yang tidak perlu.
Menurut tradisi, pada bulan November kami menunggu pengembang profesional dari layanan yang sangat dimuat di Skolkovo di HighLoad ++ . Masih ada satu bulan untuk mengajukan laporan, tetapi kami telah menerima laporan pertama ke program . Mendaftar untuk buletin kami dan belajar tentang topik baru secara langsung.