
Nyatakan apa yang tidak bisa disampaikan oleh kata-kata; Rasakan emosi yang paling beragam terjalin dalam badai perasaan; melepaskan diri dari bumi, langit dan bahkan Semesta itu sendiri, melakukan perjalanan di mana tidak ada peta, tidak ada jalan, tidak ada tanda-tanda; untuk menciptakan, menceritakan, dan menghidupkan kembali keseluruhan cerita yang akan selalu tetap unik dan tak dapat ditiru. Semua ini memungkinkan Anda untuk membuat musik - sebuah seni yang telah ada selama ribuan tahun dan menyenangkan telinga dan hati kami.
Namun, musik, atau lebih tepatnya musik, dapat berfungsi tidak hanya untuk kesenangan estetika, tetapi juga untuk mentransmisikan informasi yang dikodekan di dalamnya, ditujukan untuk perangkat apa pun dan tidak terlihat oleh pendengar. Hari ini kami akan bertemu dengan Anda sebuah studi yang sangat tidak biasa di mana mahasiswa pascasarjana dari Sekolah Teknik Tinggi Swiss di Zurich dapat secara tidak sengaja memasukkan data tertentu ke dalam karya musik untuk telinga manusia, karena musik itu sendiri menjadi saluran transmisi data. Bagaimana tepatnya mereka menyadari teknologinya, apakah melodinya sangat berbeda dengan dan tanpa data yang disematkan, dan apa yang ditunjukkan tes praktis? Kami belajar tentang ini dari laporan para peneliti. Ayo pergi.
Dasar studi
Para peneliti menyebut teknologi mereka suatu teknik transmisi data akustik. Ketika seorang pembicara mereproduksi melodi yang diubah, seseorang melihatnya seperti biasa, tetapi, misalnya, smartphone dapat membaca informasi yang disandikan di antara baris, lebih tepatnya di antara catatan, jika saya bisa mengatakannya. Aspek yang paling penting dalam implementasi metode transfer data ini, para ilmuwan (fakta bahwa orang-orang ini masih mahasiswa pascasarjana tidak mencegah mereka menjadi ilmuwan) menyebut kecepatan dan keandalan transmisi dengan tetap menjaga level parameter ini, terlepas dari file audio yang dipilih. Psychoacoustics, mempelajari aspek psikologis dan fisiologis persepsi manusia tentang suara, membantu mengatasi tugas ini.
Inti dari transmisi data akustik dapat disebut OFDM (orthogonal frequency division multiplexing), yang, bersama dengan adaptasi subcarrier ke musik asli dari waktu ke waktu, memungkinkan untuk memaksimalkan penggunaan spektrum frekuensi yang ditransmisikan untuk mengirimkan informasi. Berkat ini, dimungkinkan untuk mencapai kecepatan transmisi 412 bit / s pada jarak 24 meter (tingkat kesalahan <10%). Eksperimen praktis yang melibatkan 40 sukarelawan membenarkan fakta bahwa hampir tidak mungkin untuk mendengar perbedaan antara melodi asli dan melodi yang menjadi tempat informasi itu ditanamkan.
Di mana teknologi ini dapat diterapkan dalam praktik? Para peneliti memiliki jawabannya sendiri: hampir semua smartphone modern, laptop, dan perangkat genggam lainnya dilengkapi dengan mikrofon, dan di banyak tempat umum (kafe, restoran, pusat perbelanjaan, dll.) Terdapat speaker dengan musik latar. Misalnya, data untuk menghubungkan ke jaringan Wi-Fi dapat disematkan dalam melodi latar belakang ini tanpa perlu melakukan tindakan tambahan.
Fitur umum transmisi data akustik telah menjadi jelas bagi kami, sekarang kita beralih ke studi rinci tentang struktur sistem ini.
Deskripsi sistem
Penggabungan data ke dalam melodi terjadi karena masking frekuensi. Dalam interval waktu, frekuensi masking diidentifikasi, dan subcarrier OFDM dekat dengan elemen masking ini diisi dengan data.
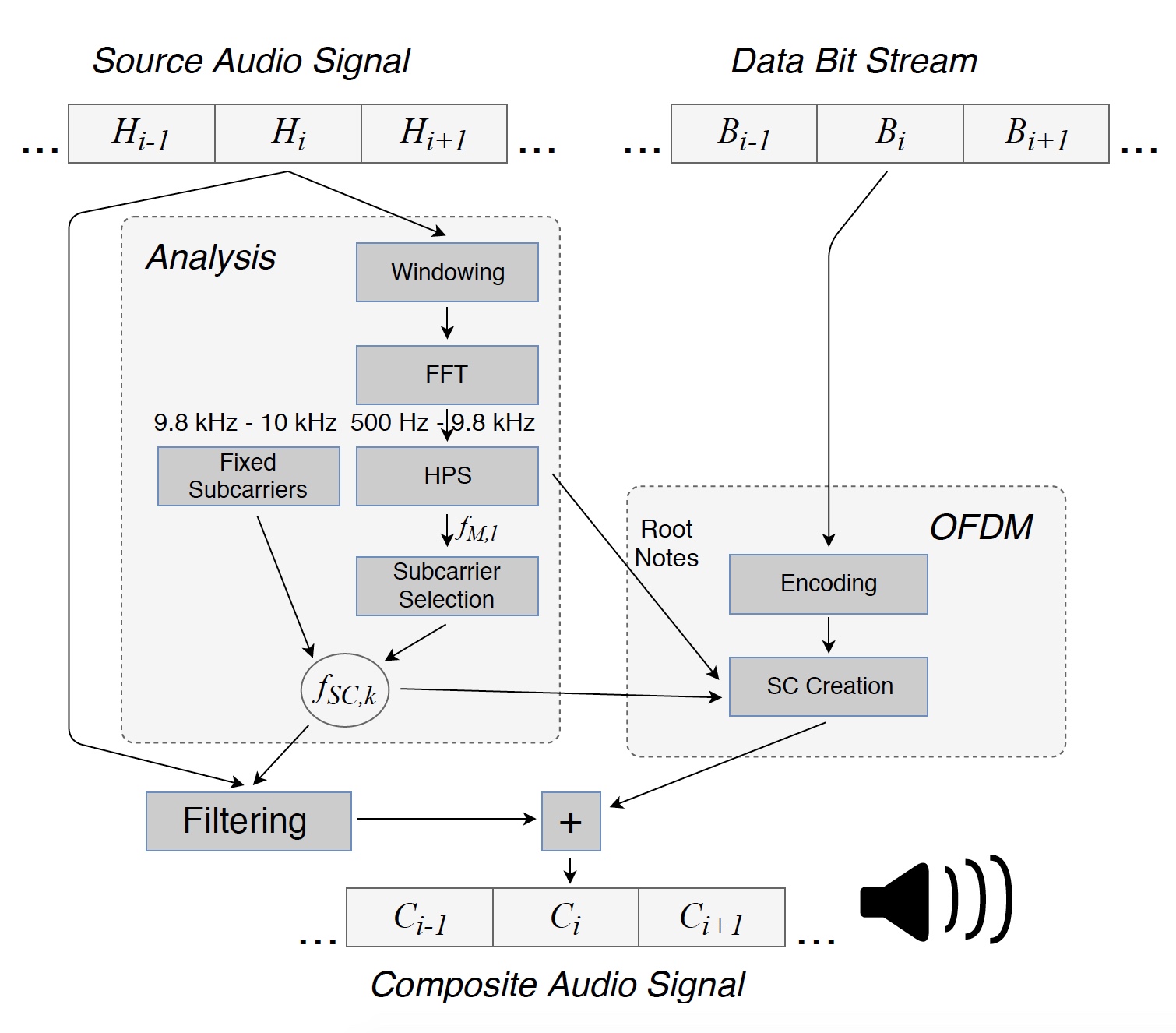 Gambar # 1: Konversikan file sumber ke sinyal komposit (melodi + data) yang dikirimkan melalui speaker.
Gambar # 1: Konversikan file sumber ke sinyal komposit (melodi + data) yang dikirimkan melalui speaker.Untuk mulai dengan, sinyal audio asli dibagi menjadi beberapa segmen untuk analisis. Setiap segmen (H
i ) dari sampel L = 8820, sama dengan 200 ms, dikalikan dengan
jendela * untuk meminimalkan efek batas.
Jendela * adalah fungsi bobot yang digunakan untuk mengontrol efek karena keberadaan lobus samping dalam perkiraan spektral.
Kemudian, frekuensi dominan dari sinyal awal ditemukan dalam kisaran dari 500 Hz hingga 9,8 kHz, yang memungkinkan untuk mendapatkan frekuensi masking f
M, l untuk segmen ini. Selain itu, data ditransmisikan dalam kisaran kecil dari 9,8 hingga 10 kHz untuk menentukan lokasi subcarrier di penerima. Batas atas rentang frekuensi yang digunakan ditetapkan ke 10 kHz karena sensitivitas rendah mikrofon smartphone pada frekuensi tinggi.
Frekuensi masking ditentukan secara individual untuk setiap segmen yang dianalisis. Menggunakan metode HPS (spektrum harmonik produk), tiga frekuensi dominan ditetapkan, setelah itu dibulatkan ke nada terdekat dari skala kromatik harmonik. Itu adalah bagaimana catatan utama f
, i = 1 ... 3, terletak di antara tombol C0 (16,35 Hz) dan B0 (30,87 Hz) diperoleh. Berdasarkan fakta bahwa nada utama terlalu rendah untuk digunakan dalam transmisi data, dalam kisaran 500 Hz ... 9,8 kHz oktaf lebih tinggi mereka 2
kf F, saya dihitung. Banyak frekuensi ini (f
O, l 1 ) lebih jelas karena sifat HPS.
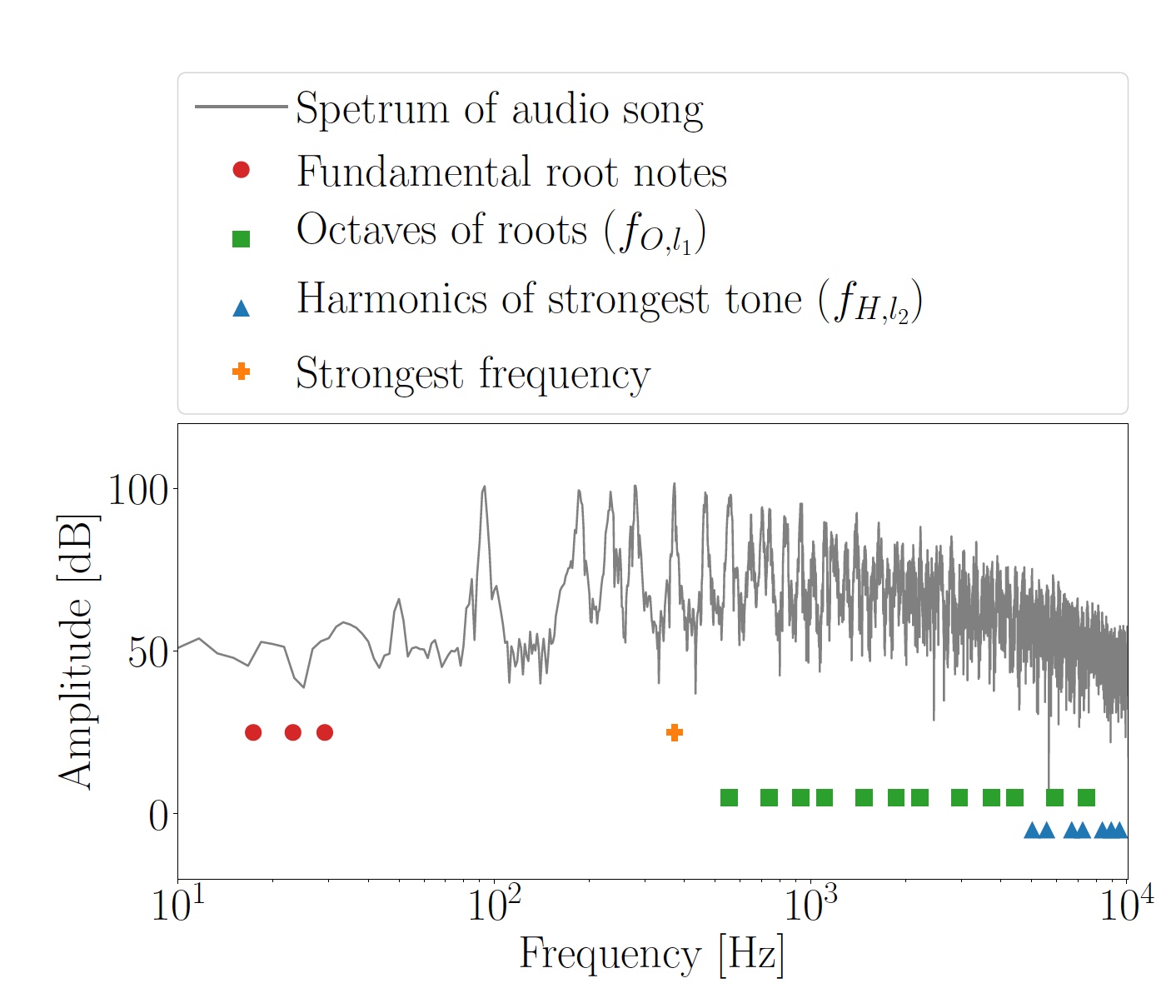 Gambar No. 2: oktaf dihitung f O, l 1 untuk nada utama dan harmonik f H, l 2 dari nada terkuat.
Gambar No. 2: oktaf dihitung f O, l 1 untuk nada utama dan harmonik f H, l 2 dari nada terkuat.Totalitas oktaf dan harmonik digunakan sebagai frekuensi masking, berdasarkan frekuensi OFDM dari subcarrier f
SC, k diperoleh. Di bawah dan di atas setiap frekuensi masking, dua subcarrier dimasukkan.
Kemudian, spektrum segmen audio H
i disaring pada frekuensi subcarrier f
SC, k . Kemudian, berdasarkan bit informasi dalam Bi, simbol OFDM dibuat, yang dengannya segmen komposit C
i dapat ditransmisikan melalui speaker. Nilai dan fase subcarrier harus dipilih sehingga penerima dapat mengambil data yang ditransmisikan, sementara pendengar tidak melihat perubahan dalam melodi.
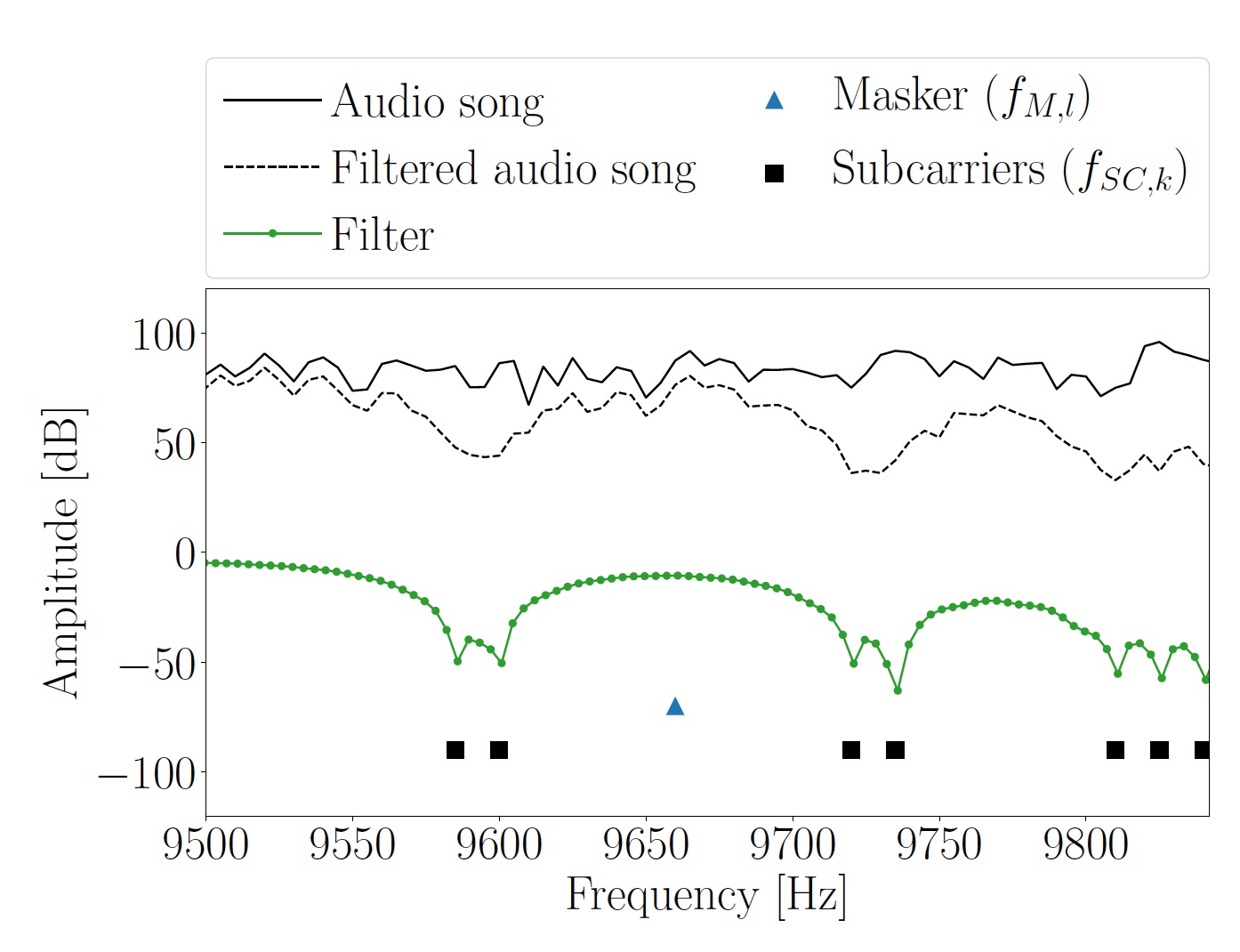 Gambar 3: plot spektrum dan frekuensi subcarrier dari segmen Hi melodi asli
Gambar 3: plot spektrum dan frekuensi subcarrier dari segmen Hi melodi asliKetika sinyal audio dengan informasi yang dikodekan di dalamnya direproduksi melalui speaker, mikrofon perangkat penerima merekamnya. Untuk menemukan posisi awal simbol OFDM yang disematkan, entri pertama-tama harus dilewati melalui penyaringan bandpass. Dengan cara ini, rentang frekuensi atas diekstraksi di mana tidak ada sinyal gangguan musik antara subcarrier. Anda dapat menemukan awal simbol OFDM menggunakan awalan siklik.
Setelah mendeteksi awal simbol OFDM, penerima memperoleh informasi tentang catatan yang paling dominan dengan mendekode domain frekuensi atas. Selain itu, OFDM cukup kuat terhadap sumber gangguan pita sempit, karena mereka hanya mempengaruhi beberapa subcarrier.
Tes praktis
Speaker KRK Rokit 8 bertindak sebagai sumber melodi yang diubah, dan smartphone Nexus 5X memainkan sisi host.
 Gambar 4: Perbedaan antara manifestasi nyata OFDM dan puncak korelasi yang diukur di dalam ruangan pada jarak 5 m antara pembicara dan mikrofon.
Gambar 4: Perbedaan antara manifestasi nyata OFDM dan puncak korelasi yang diukur di dalam ruangan pada jarak 5 m antara pembicara dan mikrofon.Sebagian besar poin OFDM berkisar dari 0 hingga 25 ms, sehingga Anda dapat menemukan awal yang valid dalam awalan siklik 66,6 ms. Peneliti mencatat bahwa penerima (dalam percobaan ini, smartphone) memperhitungkan bahwa simbol OFDM direproduksi secara berkala, yang meningkatkan deteksi mereka.
Hal pertama yang perlu diperiksa adalah efek jarak pada bit error rate (BER). Untuk melakukan ini, tiga tes dilakukan di berbagai jenis kamar: koridor dengan karpet, kantor dengan linoleum di lantai dan audiens dengan lantai kayu.
Lagu "And The Cradle Will Rock" oleh Van Halen terpilih sebagai "subjek uji".Volume suara disesuaikan sehingga tingkat suara yang diukur oleh smartphone pada jarak 2 m dari speaker adalah 63 dB.
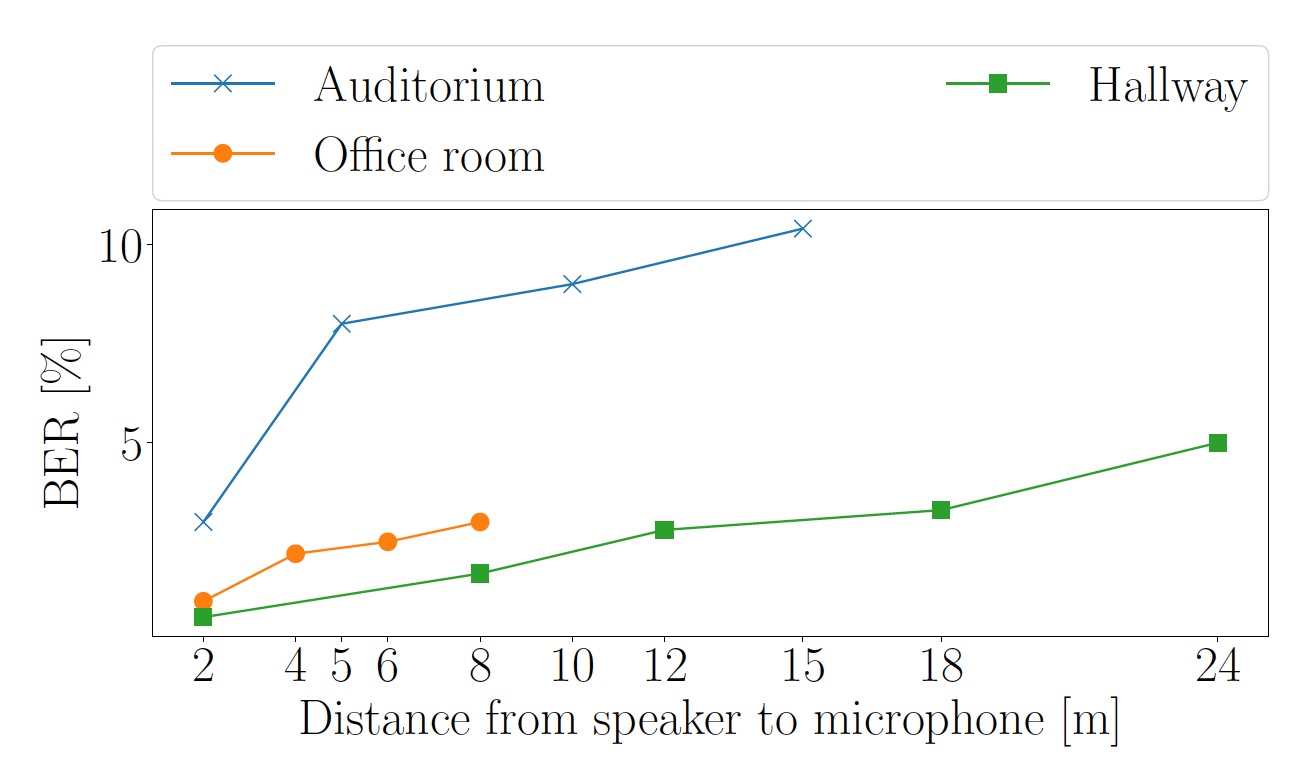 Gambar No. 5: Indikator BER tergantung pada jarak antara speaker dan mikrofon (garis biru - audiens, koridor hijau, kantor oranye).
Gambar No. 5: Indikator BER tergantung pada jarak antara speaker dan mikrofon (garis biru - audiens, koridor hijau, kantor oranye).Di koridor, suara 40 dB diambil oleh smartphone pada jarak hingga 24 meter dari speaker. Di antara penonton pada jarak 15 m, suara adalah 55 dB, dan di kantor pada jarak 8 meter, tingkat suara yang dirasakan oleh smartphone mencapai 57 dB.
Karena fakta bahwa audiens dan kantor lebih bergema, simbol OFDM akhir gema melebihi panjang awalan siklik dan meningkatkan BER.
Reverb * - penurunan intensitas suara secara bertahap karena pantulannya yang berlipat ganda.
Selanjutnya, para peneliti menunjukkan fleksibilitas sistem mereka dengan menerapkannya pada 6 lagu yang berbeda dari tiga genre (tabel di bawah).
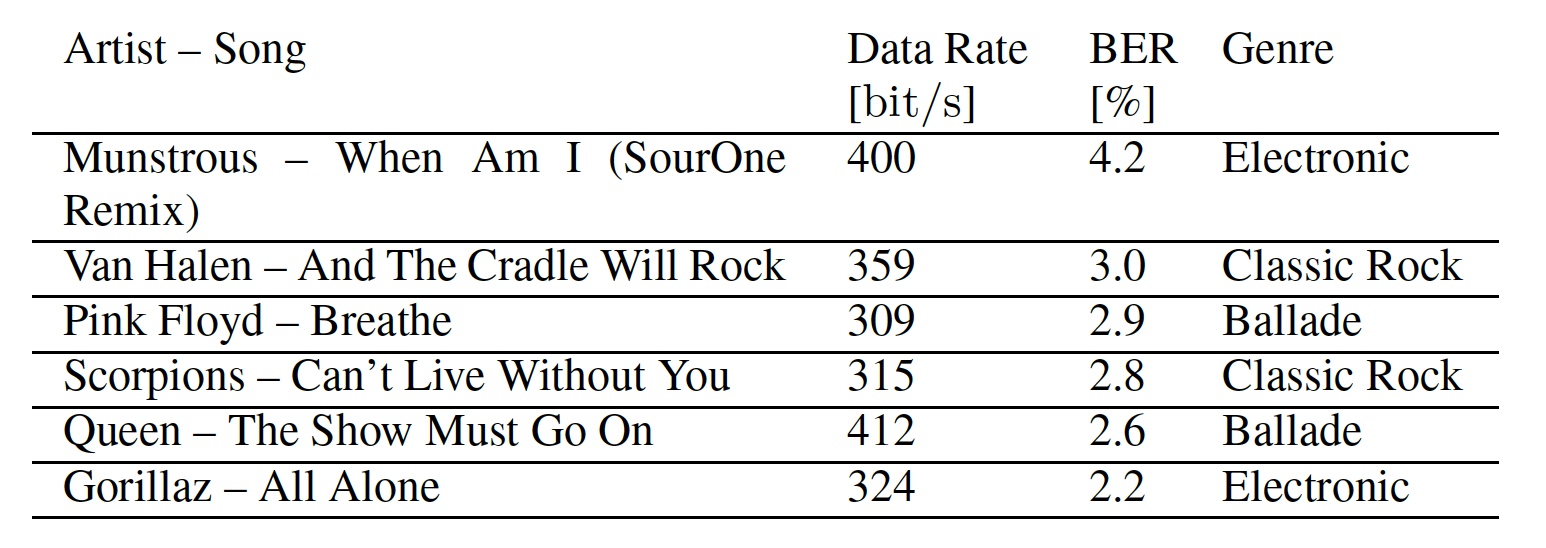 Tabel No. 1: lagu yang digunakan dalam tes.
Tabel No. 1: lagu yang digunakan dalam tes.Juga, melalui data dalam tabel, kita dapat melihat laju bit dan laju kesalahan bit untuk setiap lagu. Kecepatan transfer data berbeda karena diferensial BPSK (pengalihan fase) bekerja lebih baik ketika subcarrier yang sama digunakan. Dan ini dimungkinkan ketika segmen yang berdekatan mengandung elemen masking yang sama. Lagu yang bersuara nyaring memberikan dasar yang optimal untuk menyembunyikan data, karena frekuensi masking lebih jelas dalam rentang frekuensi yang luas. Musik yang berubah dengan cepat dapat menutupi simbol OFDM hanya sebagian karena panjangnya tetap jendela analisis.
Selanjutnya, orang mulai menguji sistem, yang seharusnya menentukan melodi mana yang asli dan yang dimodifikasi oleh informasi yang tertanam di dalamnya. Untuk ini, kutipan lagu selama 12 detik dari tabel No. 1 diposting di situs khusus.
Dalam percobaan pertama (E1), setiap peserta diberikan dengan fragmen yang dimodifikasi atau asli untuk mendengarkan, dan ia harus memutuskan apakah fragmen ini asli atau diubah. Dalam percobaan kedua (E2), peserta dapat mendengarkan kedua opsi sebanyak yang mereka suka, dan kemudian memutuskan mana yang asli dan mana yang diubah.
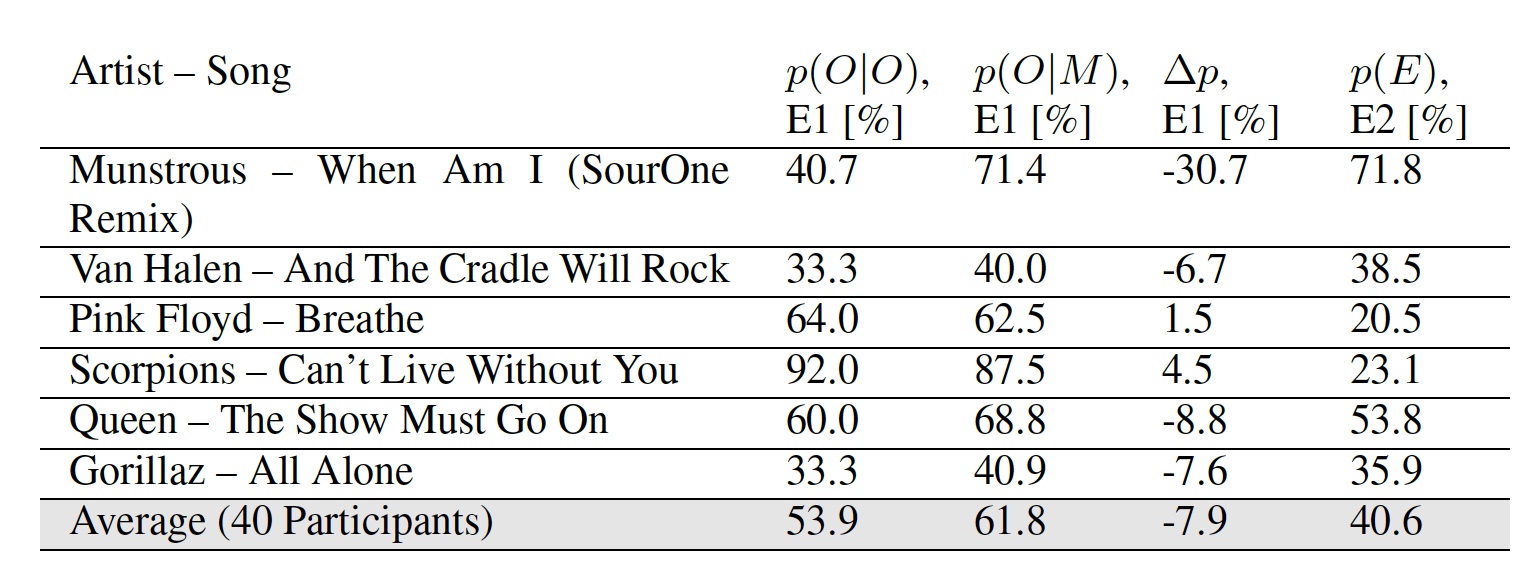 Tabel No. 2: hasil percobaan E1 dan E2.
Tabel No. 2: hasil percobaan E1 dan E2.Hasil percobaan pertama memiliki dua indikator: p ( | ) - persentase peserta yang menandai melodi asli dengan benar dan p ( | ) - persentase peserta yang menandai versi perubahan melodi sebagai orisinal.
Sangat mengherankan bahwa beberapa peserta, menurut para peneliti, menganggap melodi modifikasi tertentu lebih orisinal daripada yang asli. Indikator rata-rata dari kedua percobaan menunjukkan bahwa pendengar rata-rata tidak akan melihat perbedaan antara melodi biasa dan melodi yang digunakan untuk menyimpan data.
Secara alami, penikmat musik dan musisi akan dapat menangkap beberapa ketidakakuratan dan elemen yang mencurigakan dalam melodi yang diubah, tetapi elemen-elemen ini tidak begitu signifikan sehingga menyebabkan ketidaknyamanan.
Dan sekarang kita sendiri dapat berpartisipasi dalam percobaan. Di bawah ini adalah dua opsi untuk melodi yang sama - asli dan dimodifikasi. Apakah Anda mendengar perbedaannya?
Versi asli melodivs.
Versi melodi yang dimodifikasiUntuk pengenalan yang lebih rinci dengan nuansa penelitian, saya sarankan Anda melihat
laporan kelompok riset.
Anda juga dapat mengunduh arsip ZIP file audio melodi asli dan modifikasi yang digunakan dalam studi di
tautan ini .
Epilog
Dalam karya ini, mahasiswa pascasarjana dari Sekolah Teknik Tinggi Swiss di Zurich menggambarkan sistem transfer data yang luar biasa di dalam musik. Untuk melakukan ini, mereka menggunakan masking frekuensi, yang memungkinkan untuk menanamkan data dalam melodi yang dimainkan oleh pembicara. Melodi ini dirasakan oleh mikrofon perangkat, yang mengenali data yang disembunyikan dan menerjemahkannya, sedangkan pendengar rata-rata bahkan tidak menyadari perbedaannya. Di masa depan, mereka berencana untuk mengembangkan sistem mereka, memilih metode yang lebih maju untuk menanamkan data dalam audio.
Ketika seseorang menemukan sesuatu yang tidak biasa, dan yang terpenting bekerja, kami selalu bahagia. Tetapi yang lebih membahagiakan adalah bahwa penemuan ini diciptakan oleh orang-orang muda. Sains tidak memiliki batasan umur. Dan jika orang-orang muda menganggap sains membosankan, maka disajikan dalam sudut yang salah, demikianlah. Bagaimanapun, seperti kita ketahui, sains adalah dunia yang menakjubkan yang tidak pernah berhenti membuat takjub.
Jumat off-top:
Karena kita berbicara tentang musik, dan lebih khusus lagi tentang musik rock, inilah perjalanan yang luar biasa melalui hamparan rock.
Ratu, Radio Ga Ga (1984).
Terima kasih atas perhatian Anda, tetap ingin tahu, dan selamat berakhir pekan, semuanya! :)
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikannya kepada teman-teman Anda,
diskon 30% untuk pengguna Habr pada analog unik dari server entry-level yang kami temukan untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps dari $ 20 atau bagaimana membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
Dell R730xd 2 kali lebih murah? Hanya kami yang memiliki
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV dari $ 199 di Belanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - mulai dari $ 99! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?