Sekarang kerangka Visi mampu mengenali teks secara nyata, dan tidak seperti sebelumnya. Kami menantikan kapan kami dapat menerapkan ini pada Dodo IS. Sementara itu, terjemahan dari artikel tentang mengenali kartu dari permainan papan Magic The Gathering dan mengekstraksi informasi tekstual dari mereka.
Kerangka Visi pertama kali diperkenalkan kepada masyarakat umum di WWDC pada 2017, bersama dengan iOS 11.
Visi dibuat untuk membantu pengembang mengklasifikasikan dan mengidentifikasi objek, bidang horizontal, barcode, ekspresi wajah, dan teks.
Namun, ada masalah dengan pengenalan teks: Visi dapat menemukan tempat di mana teks berada, tetapi pengenalan teks yang sebenarnya tidak terjadi. Tentu saja, itu bagus untuk melihat kotak pembatas di sekitar fragmen teks individu, tetapi kemudian mereka harus ditarik dan dikenali secara independen.
Masalah ini diselesaikan dalam pembaruan Visi, yang termasuk dalam iOS 13. Sekarang kerangka kerja Visi memberikan pengenalan teks yang benar.
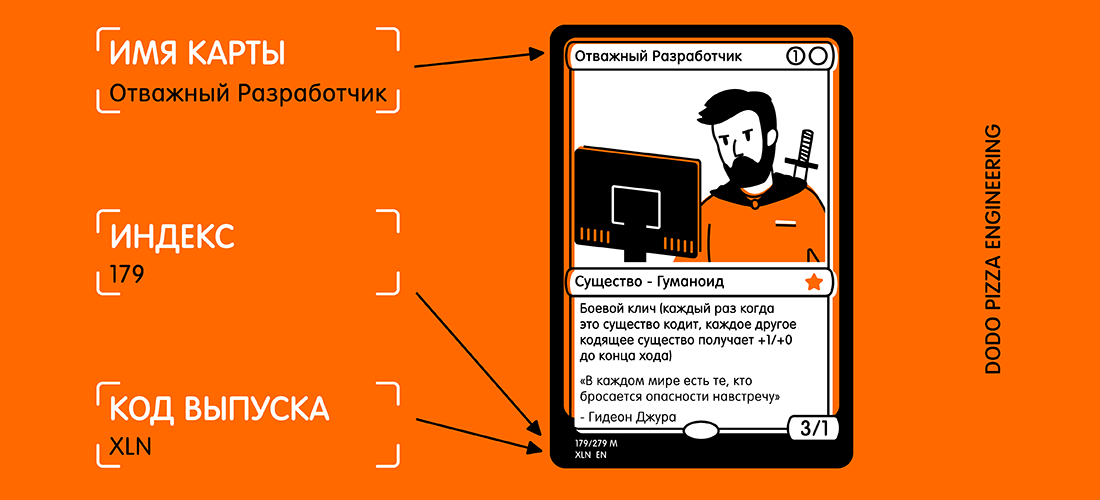
Untuk menguji ini, saya membuat aplikasi yang sangat sederhana yang dapat mengenali kartu dari papan permainan Magic The Gathering dan mengekstrak informasi teks darinya:
- nama kartu;
- kode rilis;
- nomor koleksi (alias kode pos).
Berikut adalah contoh peta dan teks terpilih yang ingin saya terima.

Melihat kartu, Anda mungkin berpikir: "Teks ini agak kecil, ditambah ada banyak teks lain pada kartu yang dapat mengganggu." Tetapi bagi Vision, ini bukan masalah.
Pertama-tama kita perlu membuat
VNRecognizeTextRequest . Intinya, ini adalah deskripsi dari apa yang kami harapkan untuk dikenali, ditambah pengaturan bahasa pengenalan dan tingkat akurasi:
let request = VNRecognizeTextRequest(completionHandler: self.handleDetectedText) request.recognitionLevel = .accurate request.recognitionLanguages = ["en_GB"]
Blok penyelesaian memiliki form
handleDetectedText(request: VNRequest?, error: Error?) . Kami meneruskannya ke konstruktor
VNRecognizeTextRequest dan kemudian mengatur properti yang tersisa.
Tersedia dua tingkat akurasi pengenalan:
.fast dan
.accurate . Karena kartu kami memiliki teks yang agak kecil di bagian bawah, saya memilih akurasi yang lebih tinggi. Opsi yang lebih cepat mungkin lebih cocok untuk volume teks yang besar.
Saya membatasi pengenalan pada Bahasa Inggris Britania, karena semua kartu saya ada di dalamnya. Anda dapat menentukan beberapa bahasa, tetapi Anda perlu memahami bahwa pemindaian dan pengenalan bisa memakan waktu sedikit lebih lama untuk setiap bahasa tambahan.
Ada dua properti yang layak disebutkan:
customWords : Anda dapat menambahkan larik string untuk digunakan di atas leksikon bawaan. Ini berguna jika ada kata-kata tidak biasa dalam teks Anda. Saya tidak menggunakan opsi untuk proyek ini. Tetapi jika saya membuat aplikasi komersial Magic The Gathering card recognition, saya akan menambahkan beberapa kartu yang paling kompleks (misalnya, Fblthp, the Lost ) untuk menghindari masalah.minimumTextHeight : ini adalah nilai float. Ini menunjukkan ukuran relatif terhadap ketinggian gambar di mana teks seharusnya tidak lagi dikenali. Jika saya membuat pemindai ini hanya untuk mendapatkan nama peta, akan berguna untuk menghapus semua teks lain yang tidak diperlukan. Tetapi saya membutuhkan potongan teks terkecil, jadi untuk saat ini saya telah mengabaikan properti ini. Jelas, jika Anda mengabaikan teks kecil, kecepatan pengenalan akan lebih tinggi.
Sekarang setelah kami memiliki permintaan kami, kami harus meneruskannya bersama dengan gambar ke penangan permintaan:
let requests = [textDetectionRequest] let imageRequestHandler = VNImageRequestHandler(cgImage: cgImage, orientation: .right, options: [:]) DispatchQueue.global(qos: .userInitiated).async { do { try imageRequestHandler.perform(requests) } catch let error { print("Error: \(error)") } }
Saya menggunakan gambar langsung dari kamera, mengubahnya dari
UIImage ke
CGImage . Ini digunakan dalam
VNImageRequestHandler bersama dengan bendera orientasi untuk membantu pawang memahami teks apa yang harus dikenali.
Sebagai bagian dari demo ini, saya hanya menggunakan ponsel dalam orientasi potret. Jadi secara alami, saya menambahkan orientasi.
.right . Jadi padaji!
Ternyata orientasi kamera pada perangkat Anda benar-benar terpisah dari rotasi perangkat dan selalu dianggap ke kiri (seperti bawaan pada 2009, bahwa untuk mengambil foto Anda harus menjaga ponsel dalam orientasi lanskap). Tentu saja, waktu telah berubah, dan pada dasarnya kami mengambil foto dan video dalam format potret, tetapi kamera masih sejajar di sebelah kiri.
Segera setelah penangan kami dikonfigurasi, kami masuk ke aliran dengan prioritas
.userInitiated dan mencoba memenuhi permintaan kami. Anda mungkin memperhatikan bahwa ini adalah susunan kueri. Ini terjadi karena Anda dapat mencoba menarik beberapa bagian data dalam satu pass (mis., Mengidentifikasi wajah dan teks dari gambar yang sama). Jika tidak ada kesalahan, panggilan balik yang dibuat menggunakan permintaan kami akan dipanggil setelah teks terdeteksi:
func handleDetectedText(request: VNRequest?, error: Error?) { if let error = error { print("ERROR: \(error)") return } guard let results = request?.results, results.count > 0 else { print("No text found") return } for result in results { if let observation = result as? VNRecognizedTextObservation { for text in observation.topCandidates(1) { print(text.string) print(text.confidence) print(observation.boundingBox) print("\n") } } } }
Handler kami mengembalikan kueri kami, yang sekarang memiliki properti hasil. Setiap hasil adalah
VNRecognizedTextObservation , yang bagi kami memiliki beberapa opsi untuk hasilnya (selanjutnya - kandidat).
Anda bisa mendapatkan hingga 10 kandidat untuk setiap unit teks yang dikenali, dan mereka disortir dalam urutan kepercayaan menurun. Ini bisa berguna jika Anda memiliki terminologi tertentu yang parser salah mengenali pada percobaan pertama. Tetapi menentukan dengan benar nanti, bahkan jika dia kurang percaya diri dalam kebenaran hasilnya.
Dalam contoh ini, kita hanya perlu hasil pertama, jadi kita mengulang melalui
observation.topCandidates(1) dan mengekstrak teks dan kepercayaan diri. Sementara kandidat sendiri memiliki teks dan kepercayaan diri yang berbeda,
.boundingBox tetap sama.
.boundingBox menggunakan sistem koordinat dinormalisasi dengan asal di sudut kiri bawah, jadi jika itu akan digunakan di UIKit di masa depan, untuk kenyamanan Anda perlu dikonversi.
Itu yang Anda butuhkan. Jika saya menjalankan
foto kartu melalui ini, saya mendapatkan hasil berikut dalam waktu kurang dari 0,5 detik pada iPhone XS Max:
Carnage Tyrant 1.0 (0.2654155572255453, 0.6955686092376709, 0.18710780143737793, 0.019915008544921786) Creature 1.0 (0.26317582130432127, 0.423814058303833, 0.09479101498921716, 0.013565015792846635) Dinosaur 1.0 (0.3883238156636556, 0.42648010253906254, 0.10021591186523438, 0.014479541778564364) Carnage Tyrant can't be countered. 1.0 (0.26538230578104655, 0.3742666244506836, 0.4300231456756592, 0.024643898010253906) Trample, hexproof 0.5 (0.2610074838002523, 0.34864263534545903, 0.23053167661031088, 0.022259855270385653) Sun Empire commanders are well versed 1.0 (0.2619712670644124, 0.31746063232421873, 0.45549616813659666, 0.022649812698364302) in advanced martial strategy. Still, the 1.0 (0.2623249689737956, 0.29798884391784664, 0.4314465204874674, 0.021180248260498136) correct maneuver is usually to deploy the 1.0 (0.2620727062225342, 0.2772137641906738, 0.4592740217844645, 0.02083740234375009) giant, implacable death lizard. 1.0 (0.2610833962758382, 0.252408218383789, 0.3502468903859457, 0.023736238479614258) 7/6 0.5 (0.6693102518717448, 0.23347826004028316, 0.04697717030843107, 0.018937730789184593) 179/279 M 1.0 (0.24829587936401368, 0.21893787384033203, 0.08339192072550453, 0.011646795272827193) XLN: EN N YEONG-HAO HAN 0.5 (0.246867307027181, 0.20903720855712893, 0.19095951716105145, 0.012227916717529319) TN & 0 2017 Wizards of the Coast 1.0 (0.5428387324015299, 0.21133480072021482, 0.19361832936604817, 0.011657810211181618)
Ini tidak bisa dipercaya! Setiap potongan teks dikenali, ditempatkan di kotak pembatasnya sendiri, dan dikembalikan sebagai hasilnya dengan peringkat kepercayaan 1,0.
Bahkan hak cipta yang sangat kecil sebagian besar benar. Semua ini dilakukan pada gambar 3024x4032 dengan berat 3,1 MB. Prosesnya akan lebih cepat jika saya mengurangi gambar. Perlu juga dicatat bahwa proses ini jauh lebih cepat pada chip bionik A12 baru, yang memiliki mesin saraf khusus.
Ketika teks dikenali, hal terakhir yang harus dilakukan adalah mencabut informasi yang saya butuhkan. Saya tidak akan meletakkan semua kode di sini, tetapi kuncinya adalah untuk
.boundingBox ke setiap
.boundingBox menentukan lokasi, sehingga saya dapat memilih teks di sudut kiri bawah dan di sudut kiri atas, mengabaikan apa pun lebih jauh ke kanan.
Hasil akhirnya adalah aplikasi kartu pemindaian dan mengembalikan hasilnya kepada saya dalam waktu kurang dari satu detik.
PS Sebenarnya, saya hanya perlu kode rilis dan nomor koleksi (ini adalah indeks). Kemudian mereka dapat digunakan dalam layanan API Scryfall untuk mendapatkan semua informasi yang mungkin tentang peta ini, termasuk aturan permainan dan biaya.
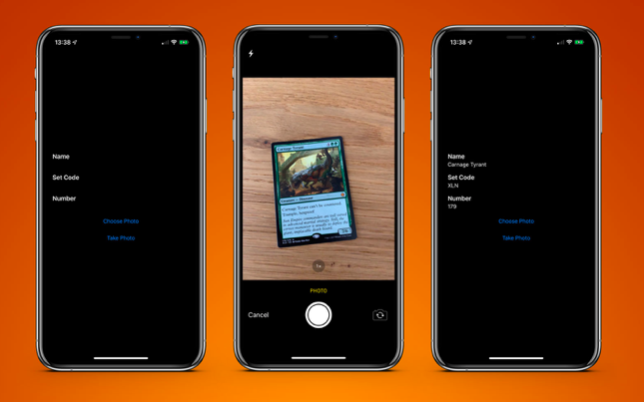
Contoh aplikasi tersedia di
GitHub .