Jaringan saraf - ini adalah topik yang menyebabkan minat besar dan keinginan untuk memahaminya. Tapi, sayangnya, itu tidak cocok untuk semua orang. Ketika Anda melihat volume literatur yang tidak jelas, Anda kehilangan keinginan untuk belajar, tetapi Anda masih ingin menyadari apa yang sedang terjadi.
Pada akhirnya, bagi saya tampaknya tidak ada cara yang lebih baik untuk mengetahuinya daripada hanya mengambil dan membuat proyek kecil Anda sendiri.
Anda dapat membaca latar belakang lirik dengan memperluas teks, atau Anda dapat melewati ini dan langsung ke
deskripsi jaringan saraf.Apa gunanya mengerjakan proyek Anda.Pro:
- Anda lebih memahami bagaimana neuron diatur
- Anda lebih memahami cara bekerja dengan perpustakaan yang ada
- Mempelajari sesuatu yang baru secara paralel
- Gelitik Ego Anda, buat sesuatu milik Anda sendiri
Cons:
- Anda membuat sepeda, lebih mungkin lebih buruk daripada yang ada
- Tidak ada yang peduli dengan proyek Anda.
Pilihan bahasa.Pada saat memilih bahasa, saya kurang lebih tahu C ++, dan akrab dengan dasar-dasar Python. Lebih mudah untuk bekerja dengan neuron dalam Python, tetapi C ++ lebih tahu dan tidak ada paralelisasi komputasi yang lebih mudah daripada OpenMP. Karena itu, saya memilih C ++, dan API untuk Python, agar tidak repot, akan membuat
swig yang berfungsi pada Windows dan Linux. (
Contoh cara membuat pustaka Python dari kode C ++)
Akselerasi OpenMP dan GPU.Saat ini, OpenMP versi 2.0 dipasang di Visual Studio, di mana hanya ada akselerasi CPU. Namun, dimulai dengan versi 3.0, OpenMP juga mendukung akselerasi GPU, sedangkan sintaks arahannya tidak rumit. Tetap menunggu hingga OpenMP 3.0 akan didukung oleh semua kompiler. Sementara itu, untuk kesederhanaan, hanya CPU.
Rake pertama saya.Ada poin berikut dalam menghitung nilai neuron: sebelum kita menghitung fungsi aktivasi, kita perlu menambahkan perkalian bobot dengan data input. Cara belajar melakukan ini di universitas: sebelum menjumlahkan vektor besar jumlah kecil, itu harus disortir dalam urutan menaik. Jadi disini. Dalam jaringan saraf, selain memperlambat program N kali, ini tidak memberikan apa-apa. Tapi saya menyadari ini hanya ketika saya sudah menguji jaringan saya di MNIST.
Menempatkan proyek di GitHub.Saya bukan orang pertama yang memposting kreasi saya di GitHub. Tetapi dalam kebanyakan kasus, mengikuti tautan, Anda hanya melihat banyak kode dengan tulisan di README.md
"Ini adalah jaringan saraf saya, tonton dan pelajari .
" Agar lebih baik daripada yang lain, setidaknya dalam hal ini, ia kurang lebih menggambarkan
README.md dan mengisi
Wiki . Pesannya sederhana -
isi Wiki. Pengamatan yang menarik: jika judul dalam Wiki di GitHub ditulis dalam bahasa Rusia, maka
jangkar pada judul ini tidak berfungsi.
LisensiKetika Anda membuat proyek kecil Anda, lisensi lagi merupakan cara untuk menggelitik ego Anda. Berikut ini adalah
artikel yang menarik tentang untuk apa sebuah lisensi. Saya memilih untuk
APACHE 2.0 .
Deskripsi jaringan.
Karakteristik
Keuntungan utama perpustakaan saya adalah pembuatan jaringan dengan satu baris kode.
Sangat mudah untuk melihat bahwa dalam lapisan linier jumlah neuron dalam satu lapisan sama dengan jumlah parameter input di lapisan berikutnya. Pernyataan lain yang jelas - jumlah neuron di lapisan terakhir sama dengan jumlah nilai output jaringan.
Mari kita buat jaringan yang menerima tiga parameter pada input, yang memiliki tiga lapisan dengan 5, 4 dan 2 neuron.
import foxnn nn = foxnn.neural_network([3, 5, 4, 2])
Jika Anda melihat gambar, Anda bisa melihat: pertama 3 parameter input, lalu satu lapisan dengan 5 neuron, kemudian satu lapisan dengan 4 neuron dan, akhirnya, lapisan terakhir dengan 2 neuron.
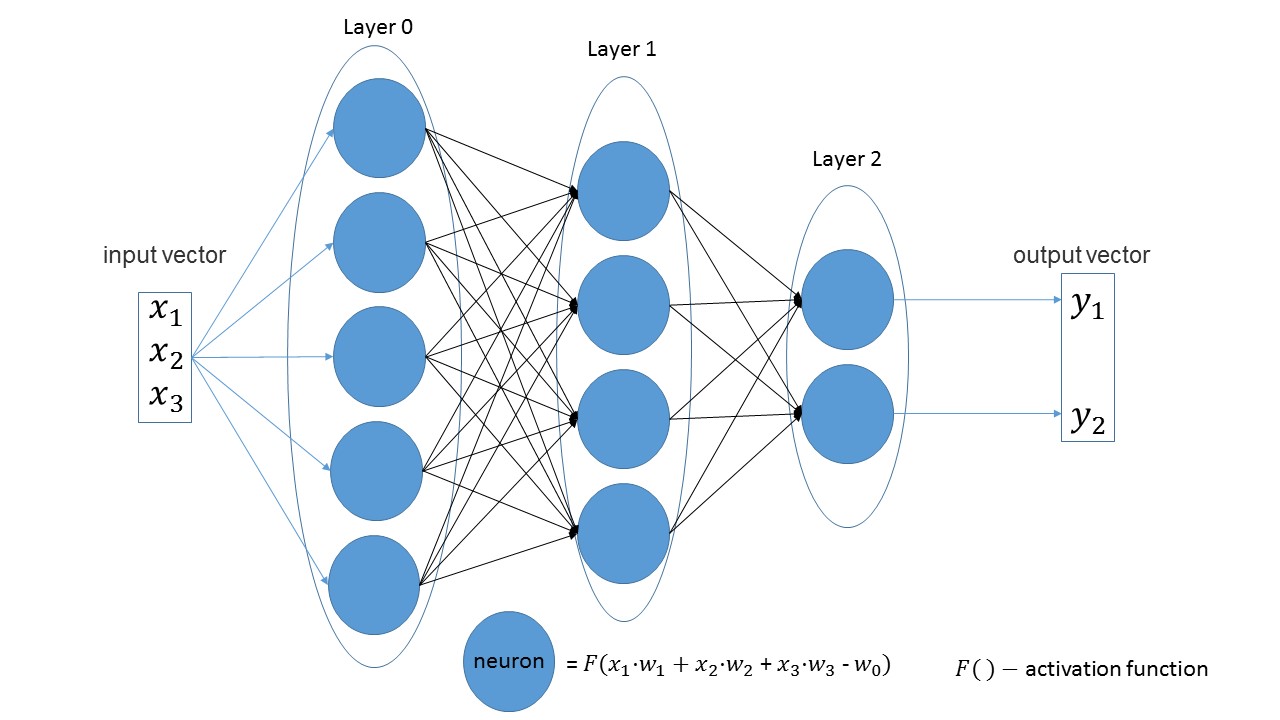
Secara default, semua fungsi aktivasi adalah sigmoid (saya lebih menyukainya).
Jika diinginkan, pada setiap lapisan dapat diubah ke fungsi lain.
Fitur aktivasi paling populer tersedia. nn.get_layer(0).set_activation_function("gaussian")
Mudah untuk membuat set pelatihan. Vektor pertama adalah data input, vektor kedua adalah data target.
data = foxnn.train_data() data.add_data([1, 2, 3], [1, 0])
Pelatihan Jaringan:
nn.train(data_for_train=data, speed=0.01, max_iteration=100, size_train_batch=98)
Mengaktifkan optimasi:
nn.settings.set_mode("Adam")
Dan metode untuk hanya mendapatkan nilai jaringan:
nn.get_out([0, 1, 0.1])
Sedikit tentang nama metode.Secara terpisah, dapatkan terjemahan cara mendapatkannya , dan keluar berarti output . Saya ingin mendapatkan nama " beri nilai output ", dan mendapatkannya. Baru kemudian saya perhatikan ternyata keluar . Tapi itu lebih menyenangkan, dan memutuskan untuk pergi.
Pengujian
Sudah menjadi tradisi tidak tertulis untuk menguji jaringan apa pun berdasarkan
MNIST . Dan saya tidak terkecuali. Semua kode dengan komentar dapat ditemukan di
sini .
Membuat sampel pelatihan: from mnist import MNIST import foxnn mndata = MNIST('C:download/') mndata.gz = True imagesTrain, labelsTrain = mndata.load_training() def get_data(images, labels): train_data = foxnn.train_data() for im, lb in zip(images, labels): data_y = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Buat jaringan: tiga lapisan, 784 parameter untuk input, dan 10 untuk output: nn = foxnn.neural_network([784, 512, 512, 10]) nn.settings.n_threads = 7
Kami melatih: nn.train(data_for_train=train_data, speed=0.001, max_iteration=10000, size_train_batch=98)
Apa yang terjadi:
Dalam sekitar 10 menit (hanya akselerasi CPU), akurasi 75% dapat diperoleh. Dengan optimasi Adam, akurasi 88% persen dapat diperoleh dalam 5 menit. Pada akhirnya, saya berhasil mencapai akurasi 97%.
Kerugian utama (sudah ada rencana revisi):- Dengan Python, kesalahan belum dilakukan, mis. di python, kesalahan tidak akan dicegat dan program hanya akan keluar dengan kesalahan.
- Sementara pelatihan ditunjukkan dalam iterasi, dan bukan di era, seperti kebiasaan di jaringan lain.
- Tidak ada akselerasi GPU
- Belum ada jenis lapisan lain.
- Kami perlu mengunggah proyek ke PyPi.
Untuk sedikit penyelesaian proyek, artikel ini kurang. Jika setidaknya sepuluh orang tertarik dan bermain, maka sudah akan ada kemenangan. Selamat datang di
github saya.
PS: Jika Anda perlu membuat sesuatu sendiri untuk mencari tahu, jangan takut dan buat.