Dalam database bibliografi Web of Science, panduan
"R: bahasa dan lingkungan untuk komputasi statistik" baru-baru ini * melewati sumber lain yang disebutkan di bagian Referensi publikasi yang diindeks oleh database ini. Sayangnya, akses ke sana terbatas, dan sulit untuk memberikan tautan (untuk setiap sesi, tautan dihasilkan), tetapi sejumlah pengguna ** dapat mereproduksi pengamatan saya, di bawah potongan itu dijelaskan bagaimana dan dengan pemesanan apa perlu dipahami judul berita utama.

Ilustrasi menunjukkan daftar sumber yang paling dikutip dalam publikasi diindeks oleh WoS, yang sendiri tidak diindeks oleh WoS dalam koleksi utama (Core Collection), tetapi hanya dalam database referensi bibliografi.
Selain fakta bahwa tiga publikasi yang diindeks (semuanya dalam biologi) masih di atas R manual, dan dalam banyak hal ini adalah catatan yang agak terbatas dengan sejumlah asumsi. Pertama, hanya menyangkut WoS, dalam database Scopus, yang sering disebutkan bersama WoS, nomenklatur "Manual Diagnostik dan Statistik gangguan mental" masih (tetapi dilihat dari tingkat pertumbuhan, tidak lama) menyalip manual pada R. Kedua, Tentu saja, saya sadar bahwa ini adalah catatan absolut, tanpa normalisasi berdasarkan bidang pengetahuan, tahun publikasi, dll. Ketiga, saya menggunakan mungkin bukan perhitungan yang paling jujur, yaitu, saya merangkum kutipan dari semua versi manual (serta referensi bibliografi lainnya - semua versi DSM, semua volume resep Numerik, dll.), Sedangkan dalam perhitungan biasa, tanpa dari penjumlahan apa pun, manual hanya ditemukan di tempat ke-40 (selanjutnya di 51, 61, dll. tempat itu juga ada, tetapi bertanggal tahun yang berbeda, ke versi manual yang berbeda, artikel a sebelum titik dua ditulis dalam huruf kapital, dll. .).
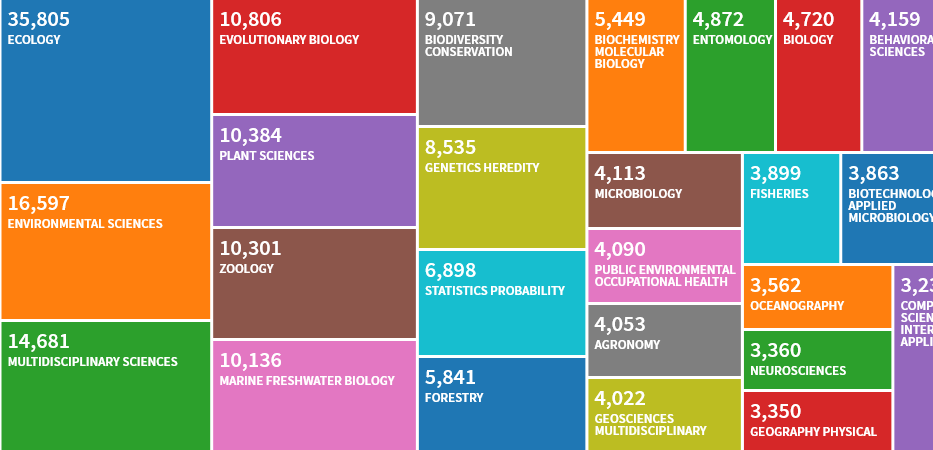 25 WoS TOP kategori dikutip oleh manual. Situasi serupa di Scopus.
25 WoS TOP kategori dikutip oleh manual. Situasi serupa di Scopus.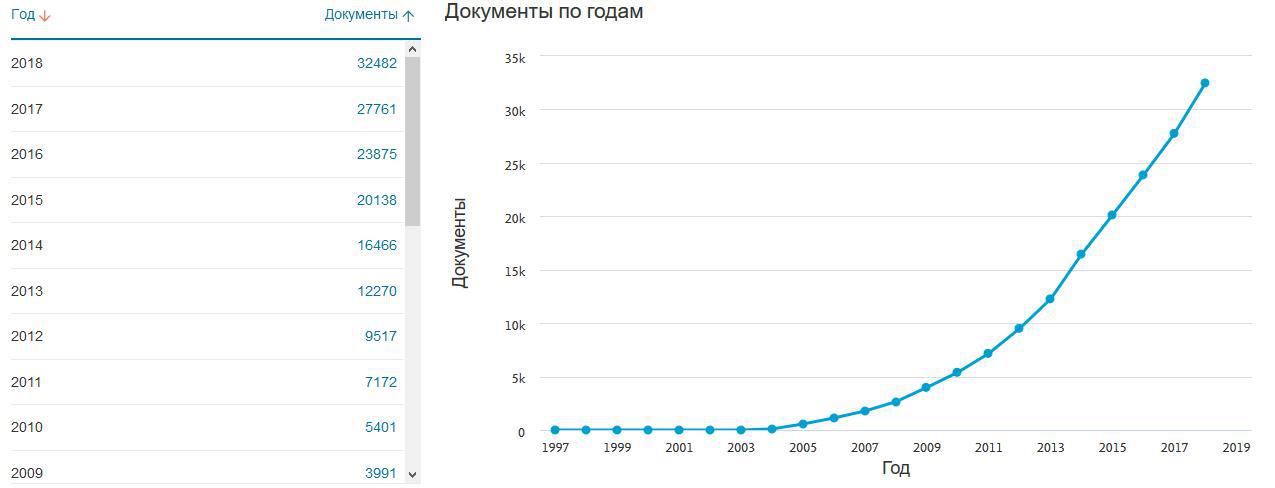 Peningkatan jumlah kutipan manual dalam Scopus, dengan nilai yang sama untuk WoS.
Peningkatan jumlah kutipan manual dalam Scopus, dengan nilai yang sama untuk WoS.Perlu juga diingat bahwa tidak dalam semua kasus, jika penulis publikasi akademis menggunakan beberapa alat (dalam arti luas, baik perangkat keras atau perangkat lunak, teorema, atau argumen logis, dll.), Maka mereka pasti akan memberikan tautan ke sana, sehingga subjek penelitian terpisah, seberapa sering menyebutkan manual mencerminkan penggunaannya yang sering dalam penulisan makalah ilmiah (diketahui bahwa R populer dalam sains, pertanyaannya berbeda, menurut angkanya, mungkin ada beberapa sumber non-akademik lainnya, de sebenarnya digunakan sering, tetapi tidak disebutkan dalam daftar pustaka).
Misalnya, menurut
ulasan ini, de facto, ketika mencari di database Google Cendekia dan menurut data untuk 2018, SPSS digunakan satu setengah kali lebih sering untuk menulis karya akademis. Penulis menjelaskan hal ini dengan kompleksitas penguasaan R. Saya ingin, bagaimanapun, analisis komparatif pada basis yang berbeda, karena pemilihan publikasi yang diindeks dan, oleh karena itu, indikator kutipan berbeda.
Mengapa R begitu penting bagi para ilmuwan? Andy Wills dalam Linux Journal
menulis tentang R dalam terang gagasan Open Science, dan sehubungan dengan relevansi krisis reproduktifitas dalam psikologi. Psikolog dan ilmuwan data
Evgeny Tomilov , yang saya
hubungi , membenarkan pentingnya R untuk sains dalam jawabannya:
R memungkinkan Anda membuat protokol riset yang dapat direproduksi, termasuk data dan pemrosesannya. Dalam kondisi pemalsuan total dan kebutuhan mendesak untuk meningkatkan reproduktifitas dan kredibilitas karya ilmiah, penggunaan alat ini setidaknya bermanfaat, dan setidaknya etis.
Z.Y. Sangat menarik juga bahwa di Google Cendekia ada
profil Tim Inti R mirip dengan profil masing-masing peneliti, dengan indeks Hirsch yang baik dari 50 (untuk ini Anda perlu memiliki lebih dari 50 publikasi, sedangkan publikasi 50 berturut-turut, ketika peringkat dengan jumlah kutipan, harus memiliki nomor kutipan sama dengan 50).
* Sulit untuk memberikan tanggal yang pasti karena keanehan dalam menghitung dan merinci data, kemungkinan besar ini telah terjadi dalam beberapa bulan terakhir.
** yaitu, pemilik kartu perpustakaan dari Perpustakaan Nasional Rusia, RSL, dan perpustakaan Gorky dan kartu pelajar dari Universitas Negeri St. Petersburg, serta beberapa universitas lainnya.
Cara mereproduksi KDPV:
Di bagian "Cari berdasarkan referensi bibliografi", Anda dapat memasukkan kueri 1000-2999 dalam pencarian berdasarkan tahun dan mendapatkan sampel dari 264 juta hasil dari 268 (sisanya mungkin tidak menunjukkan tahun, tetapi tidak mungkin bahwa mereka entah bagaimana penting untuk manipulasi berikutnya) . Diurutkan berdasarkan jumlah kutipan. Selanjutnya, ekspor hasilnya, dan saring yang memiliki kolom Sumber, tetapi tidak ada kolom Tajuk (misalnya, dalam kasus artikel jurnal, nama jurnal diberikan dalam kasus pertama, dan judul publikasi di yang kedua, kemudian isinya kedua kolom akan sama, dan hanya dalam kasus sumber yang tidak diindeks, kolom "Tajuk" akan kosong). Dan Anda dapat secara manual atau melalui skrip untuk mendapatkan hasil meringkas kutipan untuk setiap catatan unik (yaitu, menggabungkan data pada referensi bibliografi yang diekspor dikutip dalam ejaan yang berbeda, menunjukkan edisi yang berbeda, halaman individual, dll).