
Bayangkan Anda berdebat dengan teman tentang apa yang terjadi sebelumnya -
ayam atau telur, kenaikan pajak, misalnya, atau berita tentang topik ini, atau peristiwa penting benar-benar menenggelamkan awan berita tentang lagu baru, katakanlah, Kirkorov. Akan lebih mudah untuk menghitung berapa banyak berita pada setiap topik pada saat tertentu, dan kemudian memvisualisasikannya. Sebenarnya, inilah yang ditangani proyek “Runet News Radar”. Di bawah potongan, kami akan memberi tahu Anda apa yang harus dilakukan dengan pembelajaran mesin dengan hal itu dan bagaimana setiap sukarelawan dapat ambil bagian dalam hal ini.
Referensi cepat
Machine Learning for Good Good (ML4SG) adalah sebuah inisiatif dalam komunitas ODS yang bertujuan menciptakan kondisi untuk proyek, seperti namanya, yang menggunakan pembelajaran mesin untuk membawa beberapa manfaat bagi masyarakat. Penciptaan kondisi di sini mengacu terutama pada sumber daya organisasi. Kelihatannya seperti ini: seseorang merumuskan ide proyek dan mendorong sukarelawan, sementara seseorang hanya bergabung dengan proyek, demi ide, pengalaman, atau minat lain. Semuanya bersandar pada antusiasme, paling sering di waktu luang dari pekerjaan utama. Radar berita runet, atau kami menyebutnya sebentar di tim berita, adalah salah satu proyek dalam ML4SG.
Penafian
Dalam beberapa ilustrasi dalam artikel ini, beberapa peristiwa atau orang politik akan disebutkan. Mari kita tinggalkan opini tentang mereka untuk diri kita sendiri. Habr bukan untuk politik.
Apa yang kita lakukan
Singkatnya tentang motivasi
Sekarang proyek diposisikan sebagai alat untuk menganalisis media secara keseluruhan. Jika ada hipotesis tentang bagaimana perhatian dalam berita berkembang ke berbagai topik, peristiwa, orang, dan sebagainya, maka kita dapat berbicara berdasarkan angka-angka tertentu, bukan spekulasi.
Gagasan awalnya adalah ini: kami mengambil semua data berita yang kami temukan, menerapkan pemodelan tematik, menyusun hasil dalam waktu dan menggambar hasilnya.
Apa itu pemodelan tematikDefinisi dari machinelearning.ru:
Model topik adalah kumpulan dokumen teks yang menentukan topik milik masing-masing dokumen koleksi. Algoritma untuk membangun model tematik menerima kumpulan dokumen teks pada input. Output untuk setiap dokumen adalah vektor numerik yang terdiri dari perkiraan tingkat kepemilikan dokumen ini untuk masing-masing topik. Dimensi vektor ini, sama dengan jumlah topik, dapat diatur pada input, atau ditentukan secara otomatis oleh model.
Lebih detail di
sini .
Jelas bahwa ini membutuhkan berita itu sendiri, dan kami mengunduhnya. Dan karena kita akan memiliki korps berita besar, Anda dapat melakukan banyak hal menarik lainnya, tidak terbatas pada tema saja. Tetapi dengan mempertimbangkan kondisi nyata, yang akan kita bicarakan, yaitu, bahwa kerumunan sukarelawan, dan bukan tim spesialis bayaran yang bekerja dengan baik, akan melaksanakan proyek, pada awalnya kita masih menyelesaikan masalah yang hampir tidak berubah.

Sekarang kita sampai pada format visualisasi ini, itu disebut plot ridgeline. Pada slide, omong-omong, topik-topik ini adalah layar dari demo internal lama. Artinya, di sini kita punya waktu pada sumbu absis, ketebalan strip sebanding dengan seberapa banyak topik pada saat itu diwakili di antara berita lainnya. Dalam hal ini, agregasi berdasarkan bulan.
Dalam rencana dasar, kami memiliki pilihan sumber berita dan pilihan bagaimana menampilkan grafik. Anda juga dapat memilih data tambahan bukan dari berita, misalnya, bagaimana harga minyak atau indikator lainnya berperilaku pada waktu itu dalam periode waktu yang sama. Pilihan judul dan serangkaian topik di dalamnya. Selain itu, ada lebih banyak ide, tetapi lebih banyak tentang itu nanti.
Proyek serupa
Ada banyak proyek lain yang berbeda terkait dengan visualisasi berita. Saya suka
keduanya . Yang pertama membandingkan bagaimana berita yang sama disajikan dalam sumber yang berbeda, dan pada saat yang sama merupakan bentuk presentasi dan interaktivitas yang sangat baik. Yang kedua hanya memiliki sikap informativeness yang sangat baik terhadap kesederhanaan. Ini membandingkan berapa banyak yang dikatakan tentang berbagai penyebab kematian dalam berita, seberapa sering apa penyebab kematian disebutkan dalam permintaan pencarian, dan bagaimana penyebabnya secara statistik. Nah, dalam kesimpulan tentang bagaimana terorisme terlalu banyak ditaksir dan bagaimana penyakit jantung dan kanker diremehkan.
Bagaimana kita melakukannya?
Proyek ini sangat mudah. Pertama kita mengunduh data, lalu memprosesnya, kita melakukan pembelajaran mesin, dan kita menggambar grafik. Lalu kami membuat situs web, dan semua orang menonton. Semuanya jelas (ya, tentu saja).

Pengumpulan data
Untuk memulai, kami memiliki dataset ru tape selama 20 tahun. Pada dasarnya, kami melakukan semua percobaan di atasnya. Sekarang kami telah mengumpulkan beberapa sumber lagi dan terus mengumpulkan segala yang kami raih. Ada banyak materi terperinci tentang pengikisan dan laba-laba, jadi kami tidak akan membahas topik ini di sini secara rinci.
Nlp
Saya paling khawatir tentang bagian NLP, karena sulit untuk memformalkan persyaratan untuk hasil theming. Selain itu, ada banyak subtugas samping. Sekarang kami telah melakukan cukup banyak percobaan dengan berbagai alat untuk pemodelan tematik, sebelum kami menyingkirkan preprocessing, membuat banyak tolok ukur dan perbandingan. Saat ini, bigARTM ternyata menjadi pemimpin yang tidak perlu dalam hal sumber daya dan kualitas. Sekarang ini adalah pilihan kami, sampai seseorang menunjukkan sesuatu yang lebih baik.
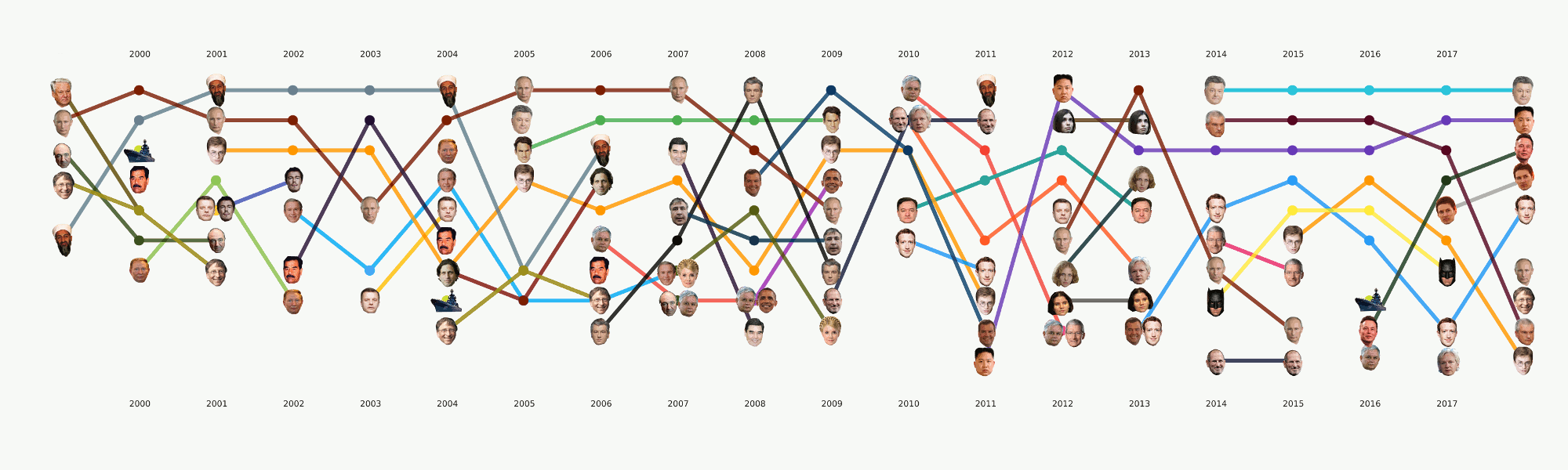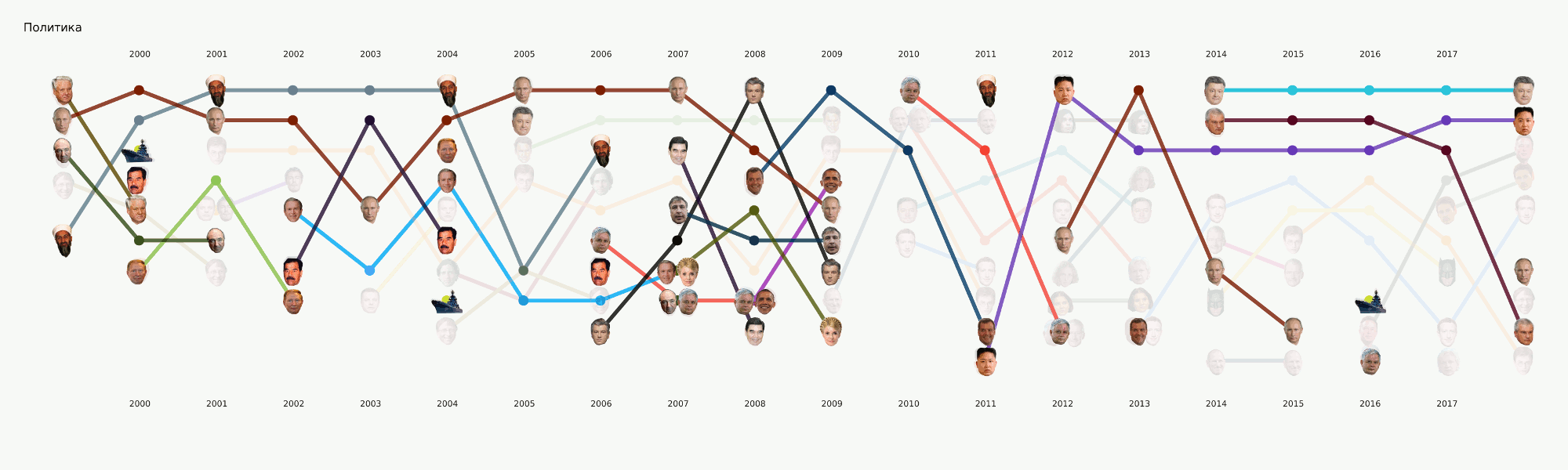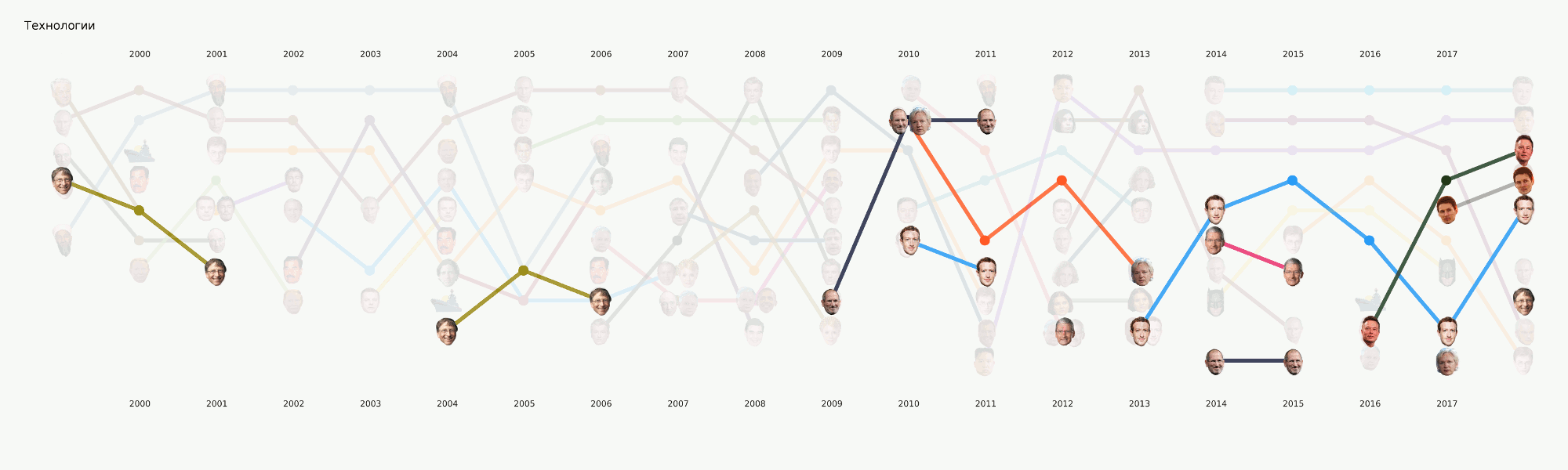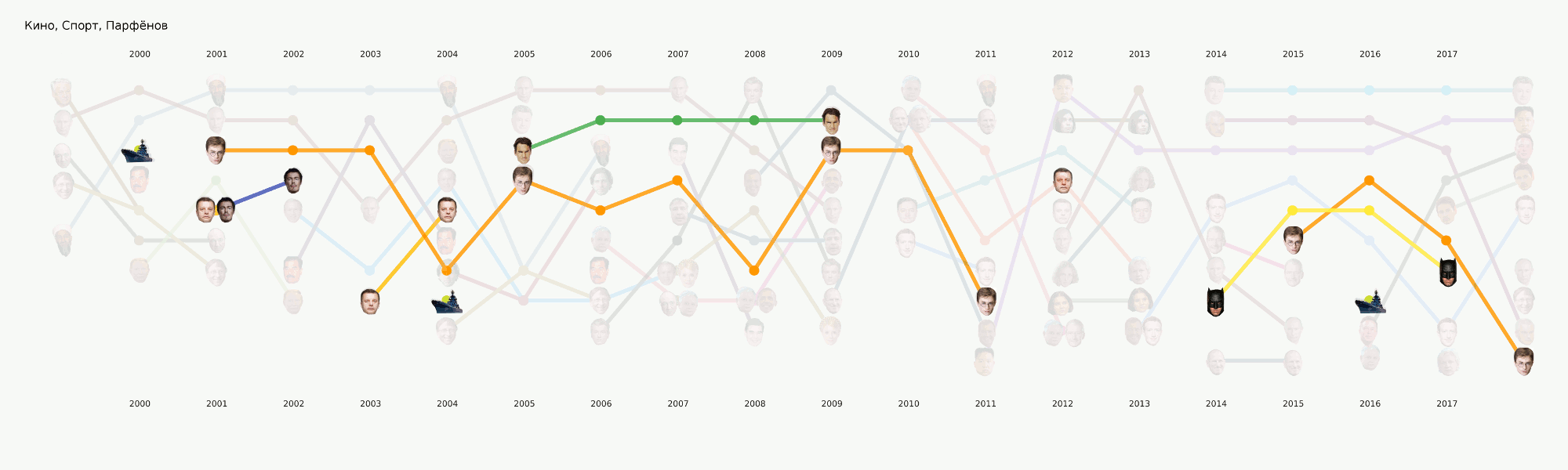
Secara umum, semua pembelajaran mesin terkonsentrasi terutama di bagian ini. Selain tugas utama mengatur tema, ada banyak lainnya yang juga akan membawa kesimpulan menarik. Misalnya, NER. Kami telah mengeluarkan semua nama dari data yang kami miliki, menyusun kamus, menghitung siapa yang kami sebutkan berkali-kali. Ternyata, misalnya, bahwa tentang Poroshenko di Lente.ru untuk semua waktu yang mereka tulis empat kali lebih banyak daripada tentang Putin. Menjadi menarik bagi saya bahwa Assange berjalan serempak dengan Magnitsky, dan semua ini terjadi tepat setelah Bush pergi. Tapi Batman lebih populer daripada Medvedev.
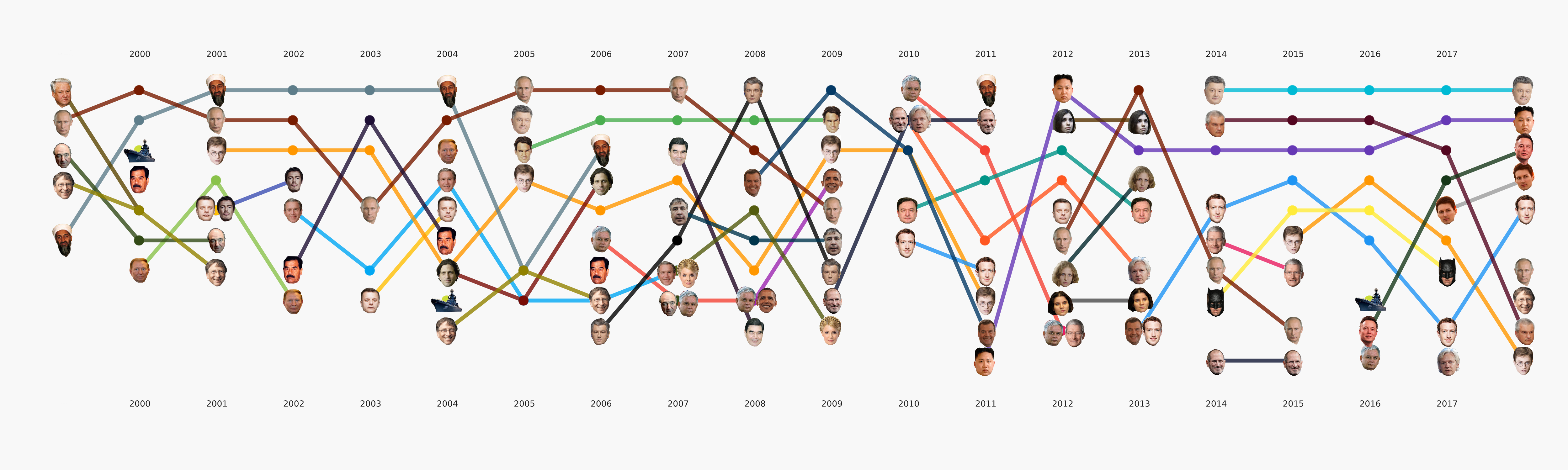

Animasi dipecah menjadi beberapa kategoriIni adalah semacam teaser untuk artikel kami yang akan datang, di mana kami akan berbicara lebih detail tentang bagaimana gambar ini muncul dan kesimpulan mana yang bisa diambil darinya.
Meskipun tahap ini masih dalam proses, kami telah melakukan sejumlah besar percobaan dan membandingkan banyak alat dan pendekatan. Dalam prosesnya, tutorial besar tentang berbagai tugas NLP dengan contoh kode dan tolok ukur alat yang paling populer dan tidak biasa.
Visualisasi
Tahap ini sepertinya tidak terlalu rumit, tetapi untuk beberapa alasan hampir tidak ada yang siap untuk menghadapinya. Persyaratan visualisasi sedikit lebih jauh dari pendekatan EDA biasa dalam dataense. Menggambar grafik untuk diri sendiri atau pusat data lain jauh lebih mudah daripada menggambar grafik untuk masyarakat umum. Kami sibuk dengan format dan alat untuk waktu yang sangat lama dan sekarang kami telah mencapai beberapa pendekatan yang tampaknya paling masuk akal, tetapi masih ada banyak pekerjaan di depan, karena praktis tidak ada alat yang siap pakai untuk tugas kami. Misalnya, bagan dengan wajah-wajah di atas dilakukan dalam dua tahap - elemen utama dihasilkan dalam kode, dan kemudian tahap menggambar ulang manual yang panjang diikuti sehingga setidaknya ada sesuatu yang dibaca. Dalam hal analisis rinci dari visualisasi ini dalam artikel terpisah, itu mencerminkan sejarah Rusia selama 20 tahun terakhir.
Tim
Secara kondisional mungkin untuk membagi peserta menjadi dua kelompok: pemula dan pro. Untuk pemula, motivasinya sederhana - taruh di celengan beberapa jenis proyek untuk ditunjukkan kepada majikan, atau sekadar mendapatkan pengalaman, belajar sesuatu. Dan saya sudah diberitahu bahwa hal-hal berbeda yang kami lakukan dalam kerangka proyek bermanfaat dalam pekerjaan para peserta, pihak berwenang menghargai. Kelebihan datang baik karena tujuan proyek, karena mereka tertarik untuk bergabung dengan ide, atau karena mereka ingin mencoba beberapa ide mereka di berita.
Bahkan, ada kelompok peserta lain - ini adalah ninja yang sulit ditangkap yang cocok dan tidak melakukan apa-apa atau hanya memulai, dan kemudian menghilang. Tapi seperti yang sudah saya jelaskan, tidak ada yang bekerja di proyek untuk mendapatkan uang, jadi disorganisasi sumber daya manusia tidak bisa dihindari. Pengamatan dari sisi keingintahuan juga dimungkinkan.

Sekarang secara resmi ada sekitar 80 orang, dimana sekitar 10-20 aktif dan 2-4 orang aktif hampir terus-menerus. Dalam format ini, Anda dapat mengganti kekurangan pengalaman dari waktu ke waktu. Banyak orang menulis bahwa tidak ada pengetahuan tentang bagaimana melakukannya, ada rasa takut gagal karena ketidakmampuan, tetapi sebenarnya penting untuk melakukannya dan tidak menunggu sebentar. Karena ml4sg adalah aktivitas yang sangat keren. Anda dapat membawa manfaat dan pada saat yang sama mendapatkan keuntungan dalam bentuk pengalaman dan portofolio, sementara risiko hanya waktu, manajer juga memiliki reputasi, tentu saja, tetapi sumber daya utama di sini adalah waktu, yang akhirnya terbayar.
Rencana selanjutnya
Sekarang saya mencoba memposisikannya sebagai alat penelitian. Kami berencana untuk menambahkan pencarian "eksplorasi" yang dapat mengevaluasi topik permintaan dan menyediakan statistik tentang berita topik ini, grafik berbagai data non-berita, tetapi relevan dengan topik proyek. Maka akan mungkin untuk menguji segala macam hipotesis tentang bagaimana media berperilaku, bagaimana peristiwa dan indikator sewenang-wenang lainnya, sosial atau ekonomi, saling terkait. Alat seperti itu untuk meneliti media secara keseluruhan.
Siapa yang butuh proyek
- Kami memiliki sangat sedikit orang yang terlibat dalam visualisasi. Kami melampaui alat datacenterist biasa seperti matplotlib atau plotly, jadi kami membutuhkan orang-orang yang benar-benar menyukai visualisasi data dan ingin memompa jauh ke dalamnya.
- Kami membutuhkan orang yang memahami sesuatu dalam pengembangan web.
- Kami membutuhkan orang yang akan memberi tahu kami apa yang harus dicari. Bahkan, seharusnya pelanggan kami yang tertarik melakukan penelitian dan memahami beberapa hal tentang bagaimana media berbahasa Rusia telah berubah belakangan ini.
- Kami selalu membutuhkan spesialis di NLP, saya pikir tidak perlu dijelaskan di sini. Dan ada sesuatu yang harus dilakukan untuk mereka yang ingin belajar, dan untuk orang-orang yang berpengalaman, karena ada banyak masalah menarik di bidang ini.
- Dan tentu saja kita perlu membangun proyek yang layak sehingga semuanya tidak bekerja dengan pita listrik, jadi jika Anda meraba-raba arsitektur proyek, Anda dapat memasang kembali banyak eksperimen menjadi satu pipa dan siap untuk berbagi pengalaman Anda, maka silakan saja. Jika Anda ingin belajar dalam perjalanan, selamat datang juga.