
Halo pembaca Habr! Dalam artikel sebelumnya, kami berbicara tentang alat toleransi bencana sederhana dalam sistem penyimpanan ENERGI AERODISK - tentang replikasi. Pada artikel ini, kita akan membahas topik yang lebih kompleks dan menarik - metro cluster, yaitu alat perlindungan bencana otomatis untuk dua pusat data, yang memungkinkan pusat data bekerja dalam mode aktif-aktif. Kami akan memberi tahu, menunjukkan, merusak, dan memperbaikinya.
Seperti biasa, di awal teori
Cluster metro adalah kluster yang ditempatkan di beberapa situs dalam kota atau distrik. Kata "cluster" jelas mengisyaratkan kepada kita bahwa kompleks itu otomatis, yaitu, beralih dari node cluster jika terjadi kegagalan secara otomatis.
Di sinilah perbedaan utama antara kluster metro dan replikasi biasa. Otomatisasi operasi. Yaitu, dalam kasus insiden tertentu (kegagalan pusat data, saluran rusak, dll.), Sistem penyimpanan akan secara independen melakukan tindakan yang diperlukan untuk menjaga ketersediaan data. Saat menggunakan replika biasa, tindakan ini dilakukan sepenuhnya atau sebagian secara manual oleh administrator.
Untuk apa ini?
Tujuan utama yang dikejar pelanggan menggunakan satu atau beberapa implementasi dari metro cluster adalah untuk meminimalkan RTO (Recovery Time Objective). Artinya, meminimalkan waktu pemulihan layanan TI setelah kegagalan. Jika Anda menggunakan replikasi normal, waktu pemulihan akan selalu lebih lama dari waktu pemulihan dengan metro cluster. Mengapa Sangat sederhana. Administrator harus berada di tempat kerja dan mengganti replikasi dengan tangan, dan cluster metro melakukan ini secara otomatis.
Jika Anda tidak memiliki administrator khusus yang bertugas yang tidak tidur, makan, merokok atau sakit, dan melihat status penyimpanan 24 jam sehari, maka tidak ada cara untuk memastikan bahwa administrator akan tersedia untuk pengalihan manual selama kegagalan.
Dengan demikian, RTO dengan tidak adanya metro cluster atau admin abadi level 99 Layanan administrator yang bertugas akan sama dengan jumlah waktu pengalihan semua sistem dan periode waktu maksimum setelah mana administrator dijamin untuk mulai bekerja dengan sistem penyimpanan dan sistem terkait.
Dengan demikian, kami sampai pada kesimpulan yang jelas bahwa metro cluster harus digunakan jika persyaratan untuk RTO adalah menit, bukan jam atau hari, yaitu, ketika dalam kasus penurunan pusat data terburuk, departemen TI harus menyediakan waktu untuk mengembalikan akses ke TI kepada bisnis. -layanan dalam hitungan menit, atau bahkan detik.
Bagaimana cara kerjanya?
Di tingkat yang lebih rendah, kluster metro menggunakan mekanisme replikasi data sinkron, yang kami jelaskan di artikel sebelumnya (lihat tautan ). Karena replikasi sinkron, persyaratan untuk itu sesuai, atau lebih tepatnya:
- serat sebagai fisika, 10 gigabit Ethernet (atau lebih tinggi);
- jarak antara pusat data tidak lebih dari 40 kilometer;
- Keterlambatan saluran optik antara pusat data (antara sistem penyimpanan) hingga 5 milidetik (secara optimal 2).
Semua persyaratan ini bersifat penasehat, yaitu, kluster metro akan beroperasi walaupun persyaratan ini tidak terpenuhi, tetapi harus dipahami bahwa konsekuensi dari ketidakpatuhan terhadap persyaratan ini sama dengan perlambatan kedua sistem penyimpanan di kluster metro.
Jadi, replika sinkron digunakan untuk mentransfer data antara sistem penyimpanan, dan bagaimana replika secara otomatis beralih, dan yang paling penting, bagaimana cara menghindari split-brain? Untuk ini, pada level di atas, entitas tambahan digunakan - arbiter.
Bagaimana cara wasit bekerja dan apa tugasnya?
Arbiter adalah mesin virtual kecil, atau kluster perangkat keras, yang harus dijalankan pada platform ketiga (misalnya, di kantor) dan menyediakan akses ke penyimpanan melalui ICMP dan SSH. Setelah peluncuran, arbiter harus mengatur IP, dan kemudian dari sisi penyimpanan menunjukkan alamatnya, ditambah alamat pengendali jarak jauh yang berpartisipasi dalam cluster metro. Setelah itu, wasit siap bekerja.
Arbiter terus-menerus memonitor semua sistem penyimpanan di metro cluster dan, jika sistem penyimpanan tidak tersedia, setelah mengkonfirmasikan tidak dapat diaksesnya dari anggota cluster lain (salah satu sistem penyimpanan "langsung"), ia membuat keputusan untuk memulai prosedur untuk beralih aturan dan pemetaan replikasi.
Poin yang sangat penting. Arbiter harus selalu berada di situs yang berbeda dari yang di mana penyimpanan berada, yaitu, tidak di pusat data-1, di mana penyimpanan 1 berada, atau di pusat data-2, di mana penyimpanan 2 dipasang.
Mengapa Karena satu-satunya cara seorang wasit dengan bantuan salah satu sistem penyimpanan yang masih hidup dapat dengan jelas dan akurat menentukan jatuhnya salah satu dari dua situs di mana sistem penyimpanan dipasang. Cara lain untuk menempatkan arbiter dapat menyebabkan otak terbelah.
Sekarang selami rincian arbiter
Arbiter menjalankan beberapa layanan yang secara konstan diinterogasi oleh semua pengontrol penyimpanan. Jika hasil survei berbeda dari yang sebelumnya (tersedia / tidak dapat diakses), maka dicatat dalam database kecil, yang juga berfungsi sebagai penengah.
Pertimbangkan logika arbiter secara lebih rinci.
Langkah 1. Penentuan tidak dapat diaksesnya. Sinyal peristiwa tentang kegagalan sistem penyimpanan adalah tidak adanya ping dari kedua pengontrol sistem penyimpanan yang sama selama 5 detik.
Langkah 2. Mulai prosedur switching. Setelah arbiter memahami bahwa salah satu sistem penyimpanan tidak tersedia, ia mengirim permintaan ke sistem penyimpanan "langsung" untuk memastikan bahwa sistem penyimpanan "mati" benar-benar mati.
Setelah menerima perintah seperti itu dari arbiter, sistem penyimpanan kedua (langsung) juga memeriksa ketersediaan sistem penyimpanan pertama yang jatuh dan, jika tidak, mengirimkan konfirmasi arbiter dari tebakannya. Penyimpanan benar-benar tidak tersedia.
Setelah menerima konfirmasi tersebut, arbiter memulai prosedur jarak jauh untuk mengalihkan replikasi dan meningkatkan pemetaan pada replika yang aktif (utama) pada penyimpanan yang dijatuhkan, dan mengirimkan perintah ke penyimpanan kedua untuk membuat replika ini dari sekunder ke primer dan meningkatkan pemetaan. Nah, sistem penyimpanan kedua, masing-masing, melakukan prosedur ini, setelah itu memberikan akses ke LUN yang hilang dari dirinya sendiri.
Mengapa saya perlu verifikasi tambahan? Untuk kuorum. Artinya, sebagian besar dari jumlah ganjil total (3) anggota cluster harus mengkonfirmasi jatuhnya salah satu node cluster. Hanya dengan demikian keputusan ini akan tepat. Ini diperlukan untuk menghindari pergantian yang salah dan, dengan demikian, otak terbelah.
Langkah 2 dalam waktu memakan waktu sekitar 5 - 10 detik, jadi, dengan mempertimbangkan waktu yang diperlukan untuk menentukan tidak dapat diaksesnya (5 detik), dalam 10 - 15 detik setelah kecelakaan, LUN dengan penyimpanan yang jatuh akan secara otomatis tersedia untuk bekerja dengan penyimpanan langsung.
Jelas bahwa untuk menghindari terputusnya host, Anda juga harus menjaga pengaturan timeout yang benar pada host. Batas waktu yang disarankan setidaknya 30 detik. Ini tidak akan memungkinkan host untuk memutuskan sambungan dari sistem penyimpanan selama transfer beban selama kecelakaan dan akan dapat menjamin bahwa tidak ada gangguan input-output.
Sebentar, ternyata, jika semuanya baik-baik saja dengan cluster metro, mengapa Anda perlu replikasi reguler?
Padahal, semuanya tidak sesederhana itu.
Pertimbangkan pro dan kontra dari kluster metro
Jadi, kami menyadari bahwa keuntungan nyata dari kluster metro dibandingkan dengan replikasi konvensional adalah:
- Otomatisasi penuh memberikan waktu pemulihan minimum jika terjadi bencana;
- Dan hanya itu :-).
Dan sekarang, perhatian, kontra:
- Biaya keputusan. Meskipun cluster metro dalam sistem Aerodisk tidak memerlukan lisensi tambahan (lisensi yang sama digunakan untuk replika), biaya solusi masih akan lebih tinggi daripada menggunakan replikasi sinkron. Penting untuk menerapkan semua persyaratan untuk replika sinkron, ditambah persyaratan untuk kluster metro yang terkait dengan peralihan tambahan dan situs tambahan (lihat perencanaan kluster metro);
- Kompleksitas keputusan. Cluster metro jauh lebih kompleks daripada replika biasa, dan membutuhkan lebih banyak perhatian dan tenaga untuk perencanaan, konfigurasi, dan dokumentasi.
Pada akhirnya. Metro cluster, tentu saja, solusi yang sangat teknologi dan baik ketika Anda benar-benar perlu menyediakan RTO dalam hitungan detik atau menit. Tetapi jika tidak ada tugas seperti itu, dan RTO dalam hitungan jam tidak masalah untuk bisnis, maka tidak ada gunanya menembak burung pipit dari meriam. Replikasi kerja-petani yang biasa sudah cukup, karena cluster metro akan mengeluarkan biaya tambahan dan menyulitkan infrastruktur TI.
Perencanaan Metro Cluster
Bagian ini tidak mengklaim sebagai panduan komprehensif untuk desain cluster metro, tetapi hanya menunjukkan arah utama yang harus dikerjakan jika Anda memutuskan untuk membangun sistem seperti itu. Oleh karena itu, dengan implementasi aktual dari metro cluster, pastikan untuk melibatkan pabrik sistem penyimpanan (yaitu, kami) dan sistem terkait lainnya untuk konsultasi.
Platform
Seperti yang ditunjukkan di atas, minimal tiga situs diperlukan untuk kluster metro. Dua pusat data, tempat sistem penyimpanan dan sistem terkait akan bekerja, serta platform ketiga tempat arbiter akan bekerja.
Jarak yang disarankan antara pusat data tidak lebih dari 40 kilometer. Jarak yang lebih besar cenderung menyebabkan penundaan tambahan, yang sangat tidak diinginkan dalam kasus cluster metro. Ingat, penundaan harus mencapai 5 milidetik, meskipun diinginkan untuk memenuhi 2.
Penundaan juga disarankan untuk diperiksa selama proses perencanaan. Setiap penyedia dewasa yang kurang lebih menyediakan serat antara pusat data, pemeriksaan kualitas dapat diatur dengan cukup cepat.
Adapun penundaan sebelum arbiter (yaitu, antara platform ketiga dan dua yang pertama), ambang batas yang disarankan hingga 200 milidetik, yaitu, koneksi VPN korporat reguler melalui Internet cocok.
Switching dan Jaringan
Tidak seperti skema replikasi, di mana cukup untuk menghubungkan sistem penyimpanan dari situs yang berbeda, skema dengan metro cluster memerlukan penghubung host dengan kedua sistem penyimpanan di situs yang berbeda. Untuk memperjelas perbedaannya, kedua skema tercantum di bawah ini.
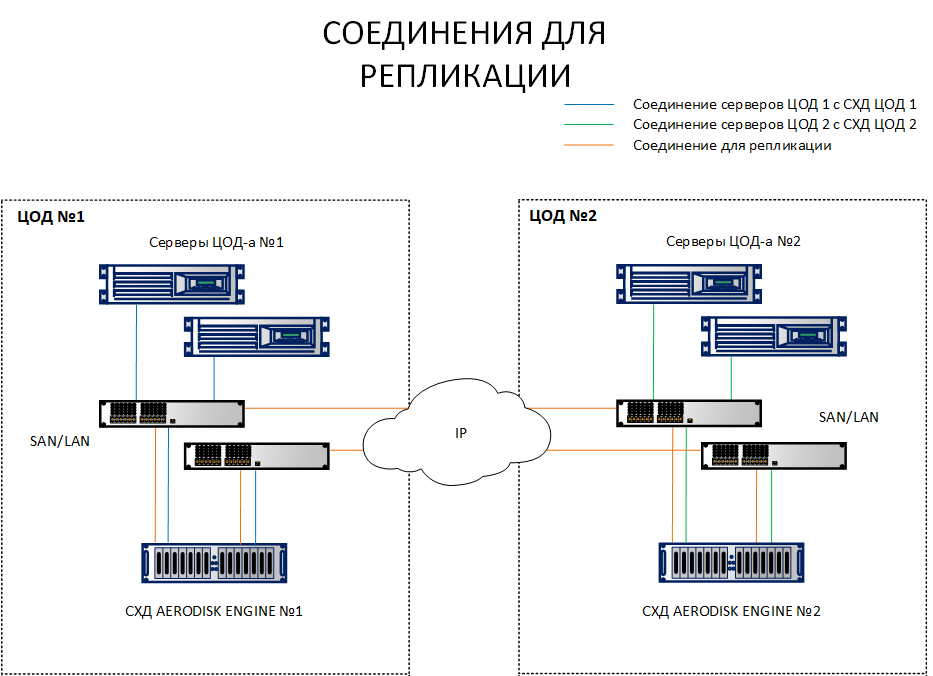

Seperti yang dapat Anda lihat dari diagram, host di situs 1 melihat SHD1 dan SHD 2. Selain itu, host platform 2 melihat SHD 2 dan SHD1. Artinya, setiap host melihat kedua sistem penyimpanan. Ini adalah prasyarat untuk pengoperasian kluster metro.
Tentu saja, tidak perlu menarik setiap host dengan kabel optik ke pusat data yang berbeda, tidak ada port dan tali yang cukup. Semua koneksi ini harus dilakukan melalui switch Ethernet 10G + atau FibreChannel 8G + (FC hanya untuk menghubungkan host dan penyimpanan untuk IO, saluran replikasi saat ini hanya tersedia melalui IP (Ethernet 10G +).
Sekarang beberapa kata tentang topologi jaringan. Poin penting adalah konfigurasi subnet yang benar. Anda harus segera mengidentifikasi beberapa subnet untuk jenis lalu lintas berikut:
- Subnet untuk replikasi di mana data antara sistem penyimpanan akan disinkronkan. Mungkin ada beberapa, dalam hal ini tidak masalah, semuanya tergantung pada topologi jaringan saat ini (sudah diterapkan). Jika ada dua dari mereka, maka jelas rute di antara mereka harus dikonfigurasi;
- Subnet penyimpanan tempat host akan mengakses sumber daya penyimpanan (jika iSCSI). Harus ada satu subnet di setiap pusat data;
- Subnet kontrol, yaitu, tiga subnet yang dapat dirutekan di tiga lokasi dari mana manajemen penyimpanan dilakukan, dan ada juga seorang wasit.
Kami tidak mempertimbangkan subnet untuk mengakses sumber daya host di sini, karena mereka sangat bergantung pada tugas.
Memisahkan lalu lintas yang berbeda ke dalam subnet yang berbeda sangat penting (sangat penting untuk memisahkan replika dari I / O), karena jika Anda mencampur semua lalu lintas menjadi satu subnet "tebal", maka lalu lintas ini tidak mungkin untuk dikendalikan, dan dalam kondisi dua pusat data masih dapat menyebabkan perbedaan opsi tumbukan jaringan. Kami tidak akan membahas masalah ini banyak dalam kerangka artikel ini, karena Anda dapat membaca tentang perencanaan jaringan yang membentang antara pusat data tentang sumber daya dari produsen peralatan jaringan, di mana ia dijelaskan dengan sangat rinci.
Konfigurasi Wasit
Arbiter harus menyediakan akses ke semua antarmuka manajemen penyimpanan melalui protokol ICMP dan SSH. Anda juga harus mempertimbangkan toleransi kesalahan arbiter. Ada nuansa.
Toleransi kesalahan arbiter sangat diinginkan, tetapi opsional. Dan apa yang terjadi jika wasit jatuh pada waktu yang salah?
- Pengoperasian cluster metro dalam mode normal tidak akan berubah, karena arbtir tidak mempengaruhi pengoperasian cluster metro dalam mode normal dengan cara apa pun (tugasnya adalah untuk mengalihkan beban di antara pusat data secara tepat waktu)
- Selain itu, jika arbiter karena satu dan lain alasan jatuh dan "membangunkan" kecelakaan di pusat data, maka tidak ada peralihan yang akan terjadi, karena tidak akan ada orang yang memberikan perintah yang diperlukan untuk beralih dan mengatur kuorum. Dalam hal ini, metro cluster akan berubah menjadi skema replikasi reguler, yang harus diganti dengan tangan saat terjadi bencana, yang akan memengaruhi RTO.
Apa yang mengikuti dari ini? Jika Anda benar-benar perlu memastikan RTO minimum, Anda harus memastikan toleransi kesalahan arbiter. Ada dua opsi untuk ini:
- Jalankan mesin virtual dengan arbiter pada hypervisor failover, karena semua hypervisor dewasa mendukung failover;
- Jika di situs ketiga (di kantor bersyarat)
kemalasan untuk menempatkan cluster normal Karena tidak ada cluster hypervizor yang ada, kami telah menyediakan versi perangkat keras dari arbiter, yang dibuat dalam kotak 2U, di mana dua server x-86 biasa bekerja dan yang dapat bertahan dari kegagalan lokal.
Kami sangat merekomendasikan bahwa arbiter menjadi toleran terhadap kesalahan meskipun fakta bahwa cluster metro tidak memerlukannya dalam mode normal. Namun baik teori maupun praktik menunjukkan bahwa jika Anda membangun infrastruktur tahan bencana yang benar-benar andal, maka lebih baik memainkannya dengan aman. Lebih baik untuk melindungi diri Anda dan bisnis Anda dari "hukum kekejaman", yaitu, dari kegagalan arbiter dan salah satu situs di mana sistem penyimpanan berada.
Arsitektur Solusi
Mempertimbangkan persyaratan di atas, kami memperoleh arsitektur solusi umum berikut.

LUN harus didistribusikan secara merata di dua lokasi untuk menghindari kemacetan yang parah. Pada saat yang sama, ketika ukuran di kedua pusat data, perlu untuk meletakkan tidak hanya volume ganda (yang diperlukan untuk menyimpan data secara bersamaan pada dua sistem penyimpanan), tetapi juga kinerja ganda di IOPS dan MB / s, untuk mencegah degradasi aplikasi jika terjadi kegagalan salah satu pusat data - Ov.
Secara terpisah, kami mencatat bahwa dengan pendekatan yang tepat untuk ukuran (yaitu, asalkan kami telah memberikan batas atas yang tepat untuk IOPS dan MB / s, serta sumber daya CPU dan RAM yang diperlukan), jika salah satu sistem penyimpanan gagal di cluster metro, tidak akan ada penurunan kinerja yang serius di bawah pekerjaan sementara pada satu sistem penyimpanan.
Hal ini disebabkan oleh kenyataan bahwa di bawah kondisi dua situs secara bersamaan, replikasi sinkron bekerja "makan" setengah dari kinerja perekaman, karena setiap transaksi harus ditulis ke dua sistem penyimpanan (mirip dengan RAID-1/10). Jadi, jika salah satu sistem penyimpanan gagal, efek replikasi sementara (sampai sistem penyimpanan gagal naik) menghilang, dan kami mendapatkan peningkatan dua kali lipat dalam kinerja penulisan. Setelah LUN sistem penyimpanan yang gagal dihidupkan kembali pada sistem penyimpanan yang berfungsi, peningkatan dua kali lipat ini menghilang karena beban dari LUN sistem penyimpanan lain, dan kami kembali ke tingkat kinerja yang sama dengan yang kami miliki sebelum "drop", tetapi hanya dalam kerangka satu platform.
Dengan bantuan ukuran yang kompeten, dimungkinkan untuk memberikan kondisi di mana pengguna tidak akan merasakan kegagalan dari keseluruhan sistem penyimpanan sama sekali. Tetapi sekali lagi, ini membutuhkan ukuran yang sangat hati-hati, untuk yang, kebetulan, Anda dapat menghubungi kami secara gratis :-).
Pengaturan Metro Cluster
Menyiapkan cluster metro sangat mirip dengan mengatur replikasi reguler, yang kami jelaskan di artikel sebelumnya . Karena itu, kami hanya fokus pada perbedaan. Kami membuat dudukan di laboratorium berdasarkan arsitektur di atas, hanya dalam versi minimal: dua sistem penyimpanan yang dihubungkan oleh 10G Ethernet satu sama lain, dua sakelar 10G dan satu host yang memeriksa sakelar di kedua port penyimpanan dengan port 10G. Arbiter berjalan di mesin virtual.

Saat mengatur IP virtual (VIP) untuk replika, pilih tipe VIP untuk cluster metro.

Kami membuat dua tautan replikasi untuk dua LUN dan mendistribusikannya di dua sistem penyimpanan: LUN TEST Primer pada SHD1 (tautan METRO), LUN TEST2 Primer pada SHD2 (tautan METRO2).

Bagi mereka, kami menetapkan dua target identik (dalam kasus kami iSCSI, tetapi FC juga didukung, logika pengaturannya sama).
SHD1:

SHD2:

Untuk koneksi replikasi, mereka membuat pemetaan pada setiap sistem penyimpanan.
SHD1:

SHD2:

Multipath yang dikonfigurasi dan disajikan ke host.


Konfigurasikan wasit
Anda tidak perlu melakukan sesuatu yang khusus dengan arbiter itu sendiri, Anda hanya perlu mengaktifkannya di platform ketiga, memberinya IP dan mengonfigurasi akses melalui ICMP dan SSH. Konfigurasi itu sendiri dilakukan dari sistem penyimpanan itu sendiri. Dalam hal ini, cukup untuk mengkonfigurasi arbiter sekali pada salah satu pengontrol penyimpanan di metro cluster, pengaturan ini akan didistribusikan ke semua pengontrol secara otomatis.
Di bagian Replikasi Jarak Jauh >> Metrocluster (pada sembarang pengontrol) >> Konfigurasikan tombol.
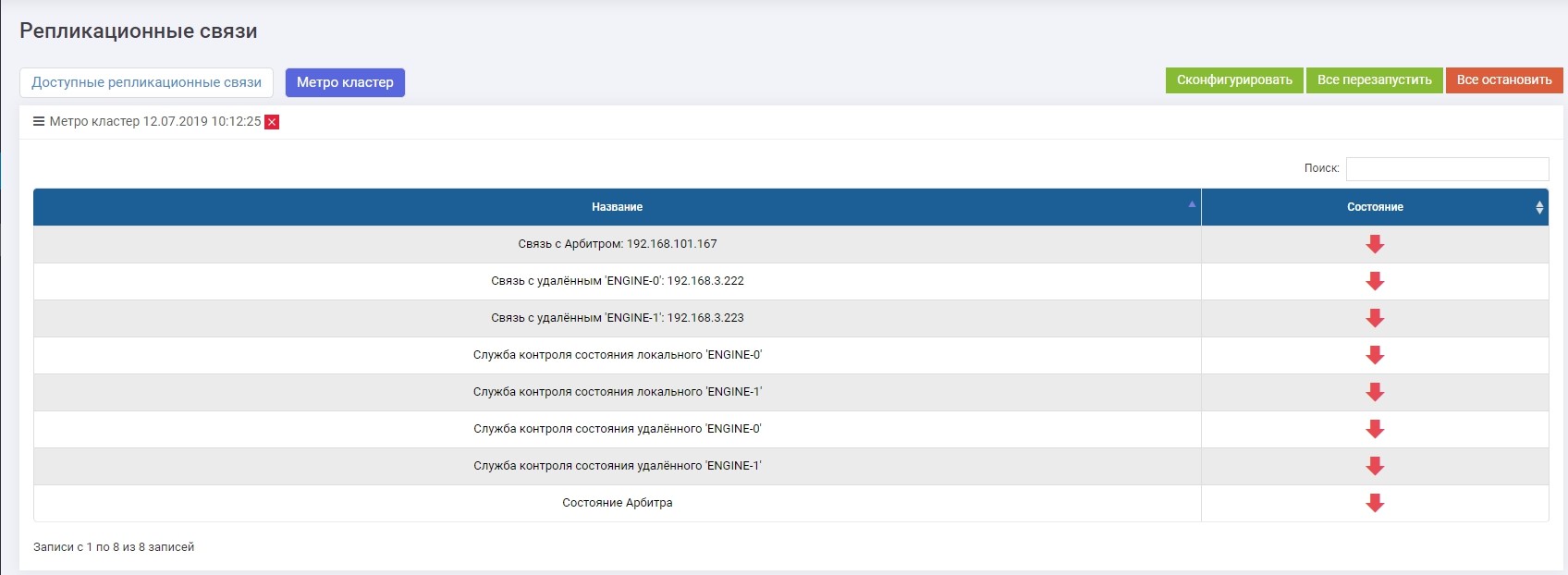
Kami memperkenalkan IP arbiter, serta antarmuka kontrol dari dua pengontrol sistem penyimpanan jarak jauh.

Setelah itu, Anda harus mengaktifkan semua layanan (tombol "Restart Everything"). Jika terjadi konfigurasi ulang di masa mendatang, layanan harus dimulai ulang agar pengaturan dapat berlaku.

Periksa apakah semua layanan berjalan.

Ini melengkapi pengaturan cluster metro.
Tes kerusakan
Tes kerusakan dalam kasus kami akan sangat sederhana dan cepat, karena fungsi replikasi (switching, konsistensi, dll.) Dipertimbangkan dalam artikel sebelumnya . Oleh karena itu, untuk menguji keandalan cluster metro, cukup bagi kita untuk memeriksa otomatisasi deteksi kecelakaan, switching, dan tidak adanya kehilangan rekaman (I / O berhenti).
Untuk melakukan ini, kami meniru kegagalan lengkap dari salah satu sistem penyimpanan dengan mematikan secara fisik kedua pengontrolnya, dengan mulai menyalin awal file besar ke LUN, yang harus diaktifkan pada sistem penyimpanan lainnya.

Nonaktifkan satu penyimpanan. Pada sistem penyimpanan kedua, kita melihat peringatan dan pesan di log bahwa koneksi dengan sistem tetangga telah hilang. Jika Anda telah mengkonfigurasi peringatan untuk pemantauan SMTP atau SNMP, maka administrator akan menerima peringatan yang sesuai.

Tepat 10 detik kemudian (terlihat di kedua tangkapan layar), tautan replikasi METRO (yang merupakan Pratama pada sistem penyimpanan yang macet) secara otomatis menjadi Pratama pada sistem penyimpanan yang berjalan. Dengan menggunakan pemetaan yang ada, LUN TEST tetap tersedia untuk tuan rumah, rekaman sedikit merosot (dalam 10 persen yang dijanjikan), tetapi tidak pecah.


Tes selesai dengan sukses.
Untuk meringkas
Implementasi metrocluster saat ini dalam sistem penyimpanan Seri-A Engine AERODISK sepenuhnya memungkinkan penyelesaian masalah di mana perlu untuk menghilangkan atau meminimalkan waktu henti layanan TI dan memastikan operasi mereka 24/7/365 dengan biaya tenaga kerja minimal.
, , , … , , . , , , .
, .