
Nama saya Eduard Tyantov, saya memimpin tim Computer Vision di Mail.ru Group. Selama beberapa tahun keberadaan kami, tim kami telah memecahkan puluhan masalah penglihatan komputer, dan hari ini saya akan memberi tahu Anda tentang metode apa yang kami gunakan untuk berhasil membuat model pembelajaran mesin yang bekerja pada berbagai tugas. Saya akan membagikan trik yang dapat mempercepat model di semua tahapan: mengatur tugas, menyiapkan data, pelatihan, dan penerapan dalam produksi.
Visi Komputer di Mail.ru
Untuk memulainya, apa itu Computer Vision di Mail.ru, dan proyek apa yang kami lakukan. Kami memberikan solusi dalam produk kami, seperti Mail, Mail.ru Cloud (aplikasi untuk menyimpan foto dan video), Vision (solusi B2B berdasarkan visi komputer) dan lainnya. Saya akan memberikan beberapa contoh.
The Cloud (ini adalah klien pertama dan utama kami) menampung 60 miliar foto. Kami mengembangkan berbagai fitur berdasarkan pembelajaran mesin untuk pemrosesan cerdas mereka, misalnya, pengenalan wajah dan jalan-jalan (
ada pos terpisah tentang ini ). Semua foto pengguna dijalankan melalui model pengenalan, yang memungkinkan Anda untuk mengatur pencarian dan pengelompokan berdasarkan orang, tag, kota dan negara yang dikunjungi, dan sebagainya.
Untuk Mail, kami melakukan OCR - pengenalan teks dari gambar. Hari ini saya akan memberi tahu Anda sedikit lebih banyak tentang dia.
Untuk produk B2B, kami melakukan pengenalan dan menghitung orang dalam antrian. Misalnya, ada antrian untuk lift ski, dan Anda perlu menghitung berapa banyak orang di dalamnya. Untuk mulai dengan, untuk menguji teknologi dan bermain, kami menyebarkan prototipe di ruang makan di kantor. Ada beberapa meja kas dan, karenanya, beberapa antrian, dan kami, menggunakan beberapa kamera (satu untuk setiap antrian), menggunakan model, kami menghitung berapa banyak orang yang berada dalam antrian dan berapa banyak kira-kira menit yang tersisa di masing-masing. Dengan cara ini kita bisa menyeimbangkan garis di ruang makan.

Pernyataan masalah
Mari kita mulai dengan bagian penting dari tugas apa pun - formulasinya. Hampir semua pengembangan ML membutuhkan setidaknya satu bulan (ini adalah yang terbaik ketika Anda tahu apa yang harus dilakukan), dan dalam kebanyakan kasus beberapa bulan. Jika tugas itu tidak benar atau tidak akurat, maka ada peluang besar di akhir pekerjaan untuk mendengar dari manajer produk sesuatu dalam semangat: “Semuanya salah. Ini tidak baik. Saya menginginkan sesuatu yang lain. " Untuk mencegah hal ini terjadi, Anda perlu mengambil beberapa langkah. Apa yang istimewa tentang produk berbasis ML? Berbeda dengan tugas mengembangkan situs, tugas pembelajaran mesin tidak dapat diformalkan dengan teks saja. Terlebih lagi, sebagai suatu peraturan, tampaknya bagi orang yang tidak siap bahwa segala sesuatu sudah jelas, dan hanya diperlukan untuk melakukan segala sesuatu dengan "indah". Tetapi detail kecil apa yang ada, yang bahkan mungkin tidak diketahui oleh manajer tugas, tidak pernah memikirkannya dan tidak akan berpikir sampai mereka melihat produk akhir dan berkata: "Apa yang telah Anda lakukan?"
Masalahnya
Mari kita pahami dengan contoh masalah apa yang bisa terjadi. Misalkan Anda memiliki tugas pengenalan wajah. Anda menerimanya, bersukacitalah dan panggil ibumu: "Hore, tugas yang menarik!" Tetapi apakah mungkin untuk langsung memecah dan mulai melakukan? Jika Anda melakukan ini, maka pada akhirnya Anda mungkin mengharapkan kejutan:
- Ada beberapa negara. Misalnya, tidak ada orang Asia atau orang lain di dataset. Model Anda, karenanya, tidak tahu cara mengenalinya sama sekali, dan produk membutuhkannya. Atau sebaliknya, Anda menghabiskan tiga bulan ekstra untuk revisi, dan produk hanya akan memiliki Kaukasia, dan ini tidak perlu.
- Ada anak-anak. Untuk ayah tanpa anak seperti saya, semua anak berada di satu sisi. Saya benar-benar setuju dengan model itu, ketika dia mengirim semua anak ke satu cluster - benar-benar tidak jelas bagaimana mayoritas anak berbeda! ;) Tetapi orang yang memiliki anak memiliki pendapat yang sama sekali berbeda. Biasanya mereka juga pemimpin Anda. Atau masih ada kesalahan pengakuan lucu ketika kepala anak berhasil dibandingkan dengan siku atau kepala pria botak (kisah nyata).
- Apa yang harus dilakukan dengan karakter yang dilukis umumnya tidak jelas. Apakah saya perlu mengenalinya atau tidak?
Aspek-aspek tugas seperti itu sangat penting untuk diidentifikasi di awal. Karena itu, Anda perlu bekerja dan berkomunikasi dengan manajer sejak awal "pada data". Penjelasan lisan tidak dapat diterima. Perlu untuk melihat data. Ini diinginkan dari distribusi yang sama di mana model akan bekerja.
Idealnya, dalam proses diskusi ini, beberapa dataset uji akan diperoleh yang akhirnya Anda dapat menjalankan model dan memeriksa apakah itu berfungsi sesuai keinginan manajer. Dianjurkan untuk memberikan bagian dari dataset uji kepada manajer sendiri, sehingga Anda tidak memiliki akses ke sana. Karena Anda dapat dengan mudah melatih ulang set tes ini, Anda adalah pengembang ML!
Menetapkan tugas dalam ML adalah pekerjaan konstan antara manajer produk dan spesialis di ML. Sekalipun pada awalnya Anda mengatur tugas dengan baik, maka ketika model berkembang, semakin banyak masalah baru akan muncul, fitur-fitur baru yang akan Anda pelajari tentang data Anda. Semua ini perlu terus dibahas dengan manajer. Manajer yang baik selalu menyiarkan ke tim ML mereka bahwa mereka perlu bertanggung jawab dan membantu manajer untuk mengatur tugas.
Kenapa begitu Pembelajaran mesin adalah bidang yang cukup baru. Manajer tidak memiliki (atau memiliki sedikit) pengalaman mengelola tugas seperti itu. Seberapa sering orang belajar menyelesaikan masalah baru? Tentang kesalahan. Jika Anda tidak ingin proyek favorit Anda menjadi kesalahan, maka Anda harus terlibat dan bertanggung jawab, ajarkan manajer produk untuk mengatur tugas dengan benar, kembangkan daftar periksa dan kebijakan; semua ini banyak membantu. Setiap kali saya menarik diri (atau seseorang dari kolega saya menarik saya) ketika tugas baru yang menarik tiba, dan kami berlari untuk melakukannya. Semua yang baru saja saya katakan, saya sendiri lupa. Karena itu, penting untuk memiliki semacam daftar periksa untuk memeriksa diri Anda sendiri.
Data
Data sangat penting dalam ML. Untuk pembelajaran mendalam, semakin banyak data yang Anda masukkan model, semakin baik. Grafik biru menunjukkan bahwa model pembelajaran yang dalam biasanya sangat meningkat ketika data ditambahkan.
Dan algoritma "lama" (klasik) dari beberapa titik tidak dapat lagi ditingkatkan.
Biasanya dalam dataset ML kotor. Mereka ditandai oleh orang-orang yang selalu berbohong. Asesor sering lalai dan membuat banyak kesalahan. Kami menggunakan teknik ini: kami mengambil data yang kami miliki, melatih model pada mereka, dan kemudian dengan bantuan model ini kami membersihkan data dan mengulangi siklus lagi.
Mari kita perhatikan contoh pengenalan wajah yang sama. Katakanlah kita mengunduh avatar pengguna VKontakte. Misalnya, kami memiliki profil pengguna dengan 4 avatar. Kami mendeteksi wajah yang ada di semua 4 gambar dan menjalankan melalui model pengenalan wajah. Jadi kita mendapatkan pernikahan orang, dengan bantuan yang mereka dapat "merekatkan" orang yang sama ke dalam kelompok (cluster). Selanjutnya, kami memilih cluster terbesar, dengan asumsi bahwa avatar pengguna sebagian besar berisi wajahnya. Dengan demikian, kita dapat membersihkan semua wajah lain (yang berisik) dengan cara ini. Setelah itu, kita dapat mengulangi siklus itu lagi: pada data yang dibersihkan, latih modelnya dan gunakan untuk membersihkan data. Anda dapat mengulangi beberapa kali.
Hampir selalu untuk pengelompokan seperti itu kami menggunakan algoritma CLink. Ini adalah algoritma pengelompokan hierarkis di mana sangat mudah untuk menetapkan nilai ambang batas untuk "menempelkan" objek yang serupa (inilah yang diperlukan untuk pembersihan). CLink menghasilkan kluster bola. Ini penting, karena kita sering belajar ruang metrik dari embed ini. Algoritma ini memiliki kompleksitas O (n
2 ), yang pada prinsipnya adalah sekitar.
Terkadang data sangat sulit untuk diperoleh atau ditandai sehingga tidak ada yang tersisa untuk dilakukan segera setelah Anda mulai membuatnya. Pendekatan generatif memungkinkan Anda menghasilkan sejumlah besar data. Tetapi untuk ini, Anda perlu memprogram sesuatu. Contoh paling sederhana adalah OCR, pengenalan teks pada gambar. Markup teks untuk tugas ini sangat mahal dan berisik: Anda perlu menyorot setiap baris dan setiap kata, menandatangani teks dan sebagainya. Penilai (orang markup) akan menghabiskan seratus halaman teks untuk waktu yang sangat lama, dan lebih banyak lagi diperlukan untuk pelatihan. Jelas, Anda dapat entah bagaimana menghasilkan teks dan entah bagaimana "memindahkan" sehingga model belajar darinya.
Kami telah menemukan sendiri bahwa toolkit terbaik dan paling nyaman untuk tugas ini adalah kombinasi dari PIL, OpenCV dan Numpy. Mereka memiliki segalanya untuk bekerja dengan teks. Anda dapat memperumit gambar dengan teks dengan cara apa pun sehingga jaringan tidak melatih kembali untuk contoh sederhana.

Terkadang kita membutuhkan beberapa objek dunia nyata. Misalnya barang di rak toko. Salah satu gambar ini dihasilkan secara otomatis. Apakah Anda berpikir ke kiri atau ke kanan?

Faktanya, keduanya dihasilkan. Jika Anda tidak melihat detail kecil, maka Anda tidak akan melihat perbedaan dari kenyataan. Kami melakukan ini menggunakan Blender (analog dari 3dmax).
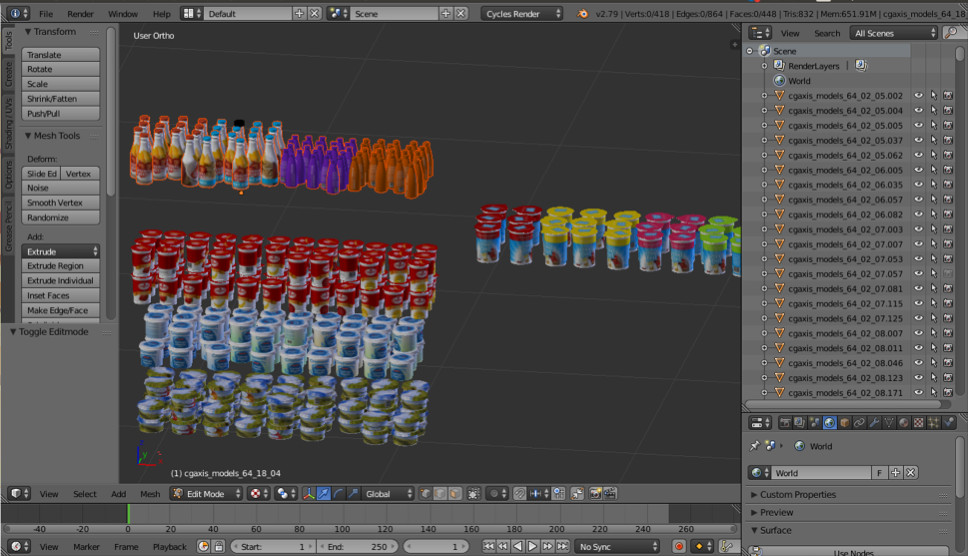
Keuntungan penting utama adalah open source. Ini memiliki API Python yang sangat baik, yang memungkinkan Anda untuk langsung menempatkan objek dalam kode, mengkonfigurasi dan mengacak proses dan akhirnya mendapatkan dataset yang beragam.
Untuk rendering, ray tracing digunakan. Ini adalah prosedur yang agak mahal, tetapi menghasilkan hasil dengan kualitas yang sangat baik. Pertanyaan paling penting: di mana mendapatkan model untuk objek? Sebagai aturan, mereka harus dibeli. Tetapi jika Anda adalah siswa yang miskin dan ingin bereksperimen dengan sesuatu, selalu ada deras. Jelas bahwa untuk produksi Anda perlu membeli atau memesan model yang diberikan dari seseorang.
Itu semua tentang data. Mari beralih ke pembelajaran.
Pembelajaran metrik
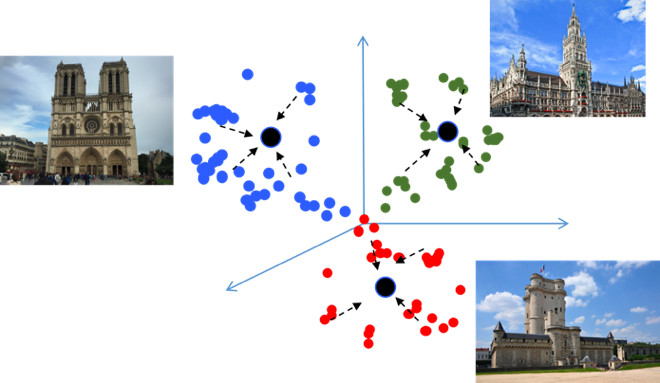
Tujuan pembelajaran Metric adalah untuk melatih jaringan sehingga menerjemahkan objek yang mirip ke wilayah yang serupa di ruang metrik embedding. Saya akan kembali memberikan contoh dengan pemandangan, yang tidak biasa karena pada dasarnya itu adalah tugas klasifikasi, tetapi untuk puluhan ribu kelas. Tampaknya, mengapa di sini pembelajaran metrik, yang, sebagai suatu peraturan, sesuai untuk tugas-tugas seperti pengenalan wajah? Mari kita coba mencari tahu.
Jika Anda menggunakan kerugian standar saat melatih masalah klasifikasi, misalnya, Softmax, maka kelas-kelas di ruang metrik dipisahkan dengan baik, tetapi di ruang embedding, titik-titik kelas yang berbeda dapat dekat satu sama lain ...

Ini menciptakan kesalahan potensial selama generalisasi, seperti sedikit perbedaan dalam sumber data dapat mengubah hasil klasifikasi. Kami benar-benar ingin poinnya lebih kompak. Untuk ini, berbagai teknik pembelajaran metrik digunakan. Sebagai contoh, kehilangan Center, ide yang sangat sederhana: kami hanya mengumpulkan poin ke pusat pembelajaran setiap kelas, yang akhirnya menjadi lebih kompak.
Kerugian tengah diprogram secara harfiah dalam 10 baris dengan Python, ia bekerja sangat cepat, dan yang paling penting, ia meningkatkan kualitas klasifikasi, karena kekompakan menyebabkan kemampuan generalisasi yang lebih baik.
Softmax sudut
Kami mencoba berbagai metode pembelajaran metrik dan sampai pada kesimpulan bahwa Angular Softmax menghasilkan hasil terbaik. Di antara komunitas penelitian, ia juga dianggap canggih.
Mari kita lihat contoh pengenalan wajah. Di sini kita punya dua orang. Jika Anda menggunakan Softmax standar, maka bidang pemisah akan ditarik di antara keduanya - berdasarkan dua vektor bobot. Jika kita membuat embedding norma 1, maka poinnya akan terletak pada lingkaran, mis. pada bola dalam case n-dimensional (gambar di sebelah kanan).
Kemudian Anda dapat melihat bahwa sudut di antara mereka sudah bertanggung jawab untuk pemisahan kelas, dan itu dapat dioptimalkan. Tapi itu saja tidak cukup. Jika kita terus mengoptimalkan sudut, maka tugas tidak akan berubah, karena kami hanya merumuskannya kembali dalam istilah lain. Saya ingat, tujuan kami adalah membuat kluster menjadi lebih kompak.
Dalam beberapa hal, perlu adanya sudut pandang yang lebih besar di antara kelas-kelas - untuk mempersulit tugas jaringan saraf. Misalnya, sedemikian rupa sehingga dia berpikir bahwa sudut antara titik-titik satu kelas lebih besar daripada kenyataan, sehingga dia mencoba untuk mengompres mereka lebih dan lebih lagi. Ini dicapai dengan memperkenalkan parameter m, yang mengontrol perbedaan dalam cosinus sudut.
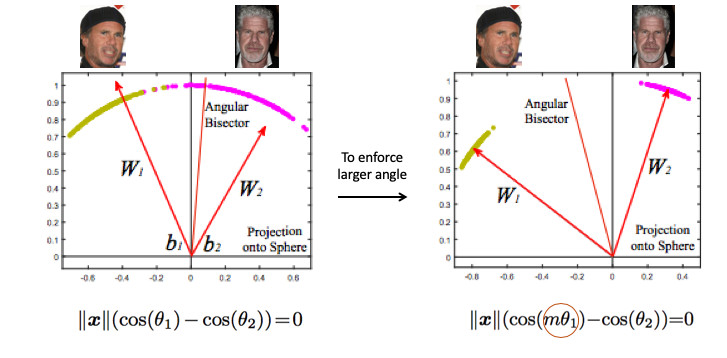
Ada beberapa opsi untuk Angular Softmax. Mereka semua bermain dengan fakta yang dikalikan dengan m sudut ini atau menambah, atau mengalikan dan menambah. State-of-the-art - ArcFace.
Bahkan, ini cukup mudah untuk diintegrasikan ke dalam klasifikasi pipa.
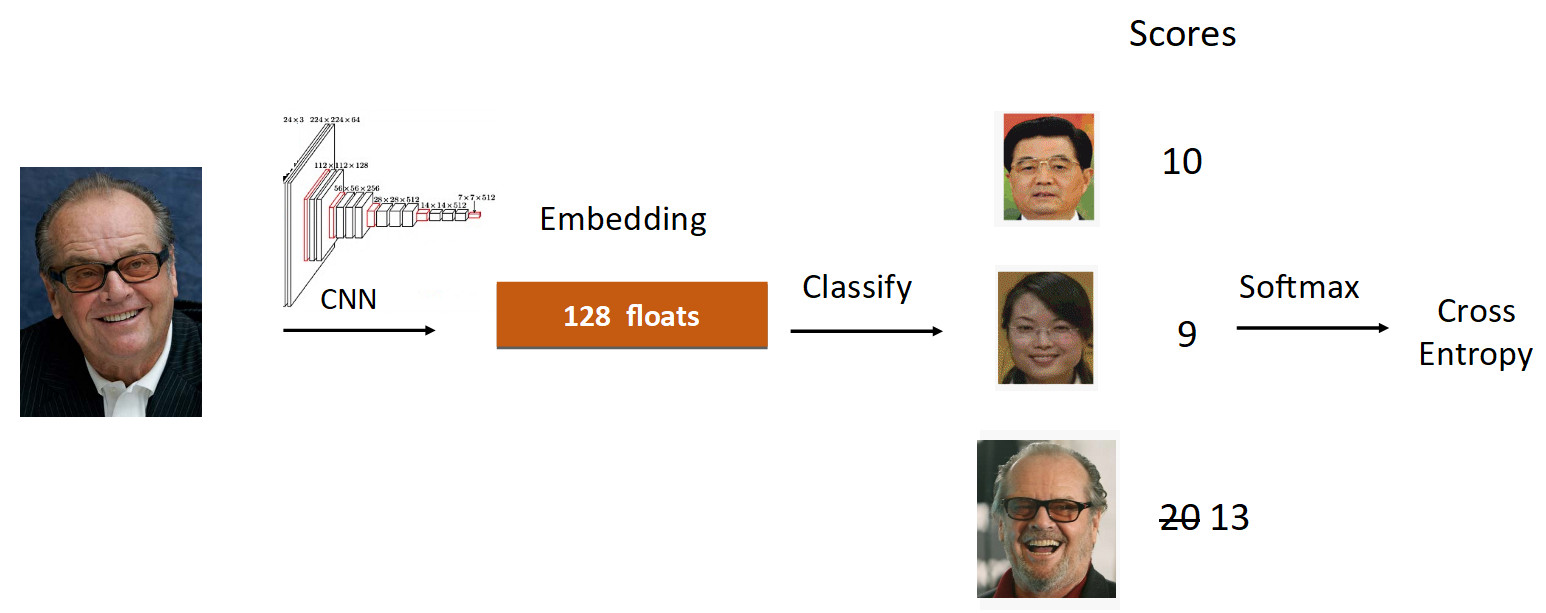
Mari kita lihat contoh Jack Nicholson. Kami menjalankan fotonya melalui grid dalam proses pembelajaran. Kami mendapatkan embedding, kami menjalankan melalui lapisan linier untuk klasifikasi dan kami mendapatkan skor pada output, yang mencerminkan tingkat kepemilikan kelas. Dalam hal ini, foto Nicholson memiliki kecepatan 20, yang terbesar. Lebih lanjut, menurut formula dari ArcFace, kami mengurangi kecepatan dari 20 menjadi 13 (dilakukan hanya untuk kelas groundtruth), mempersulit tugas untuk jaringan saraf. Lalu kami melakukan semuanya seperti biasa: Softmax + Cross Entropy.
Secara total, lapisan linier yang biasa digantikan oleh lapisan ArcFace, yang ditulis bukan dalam 10, tetapi dalam 20 baris, tetapi memberikan hasil yang sangat baik dan minimum overhead untuk implementasi. Hasilnya, ArcFace lebih baik daripada kebanyakan metode lain untuk sebagian besar tugas. Ini terintegrasi dengan sempurna dengan tugas-tugas klasifikasi dan meningkatkan kualitas.
Transfer belajar
Hal kedua yang ingin saya bicarakan adalah Transfer belajar - menggunakan jaringan pra-terlatih pada tugas yang sama untuk melatih kembali pada tugas baru. Dengan demikian, pengetahuan ditransfer dari satu tugas ke tugas lainnya.
Kami melakukan pencarian pada gambar. Inti dari tugas ini adalah untuk menghasilkan yang serupa secara semantik dari database dalam gambar (permintaan).

Adalah logis untuk mengambil jaringan yang telah dipelajari pada sejumlah besar gambar - pada dataset ImageNet atau OpenImages, di mana terdapat jutaan gambar, dan latih data kami.
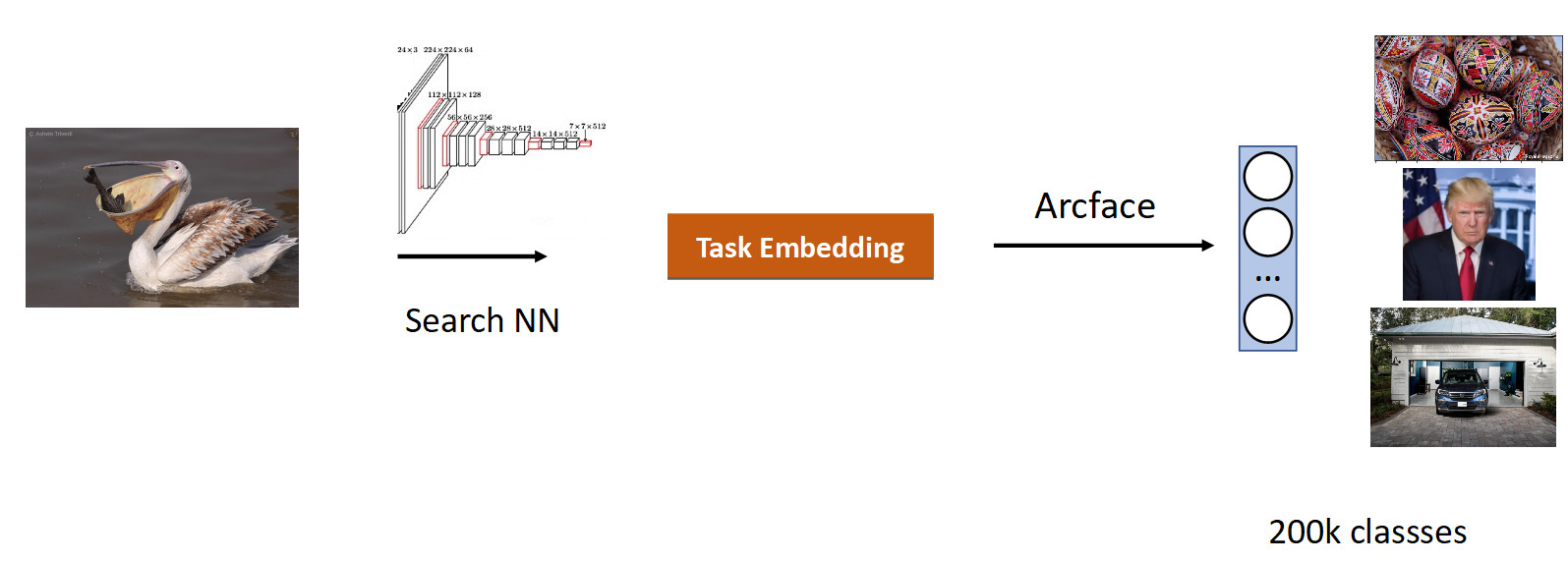
Kami mengumpulkan data untuk tugas ini berdasarkan kesamaan gambar dan klik pengguna dan mendapat 200 ribu kelas. Setelah pelatihan dengan ArFace, kami mendapat hasil sebagai berikut.

Pada gambar di atas, kita melihat bahwa untuk pelican yang diminta, burung pipit juga masuk ke masalah. Yaitu embedding ternyata benar secara semantik - itu adalah burung, tetapi tidak memiliki ras. Hal yang paling menjengkelkan adalah bahwa model asli yang kami latih kembali mengenal kelas-kelas ini dan membedakannya dengan sempurna. Di sini kita melihat efek yang umum untuk semua jaringan saraf, yang disebut pelepasan katastropik. Artinya, selama pelatihan ulang, jaringan melupakan tugas sebelumnya, kadang-kadang bahkan sepenuhnya. Inilah yang mencegah dalam tugas ini untuk mencapai kualitas yang lebih baik.
Distilasi pengetahuan
Ini diperlakukan menggunakan teknik yang disebut distilasi pengetahuan, ketika satu jaringan mengajarkan yang lain dan "mentransfer pengetahuannya untuk itu". Tampilannya (pipeline pelatihan lengkap pada gambar di bawah).
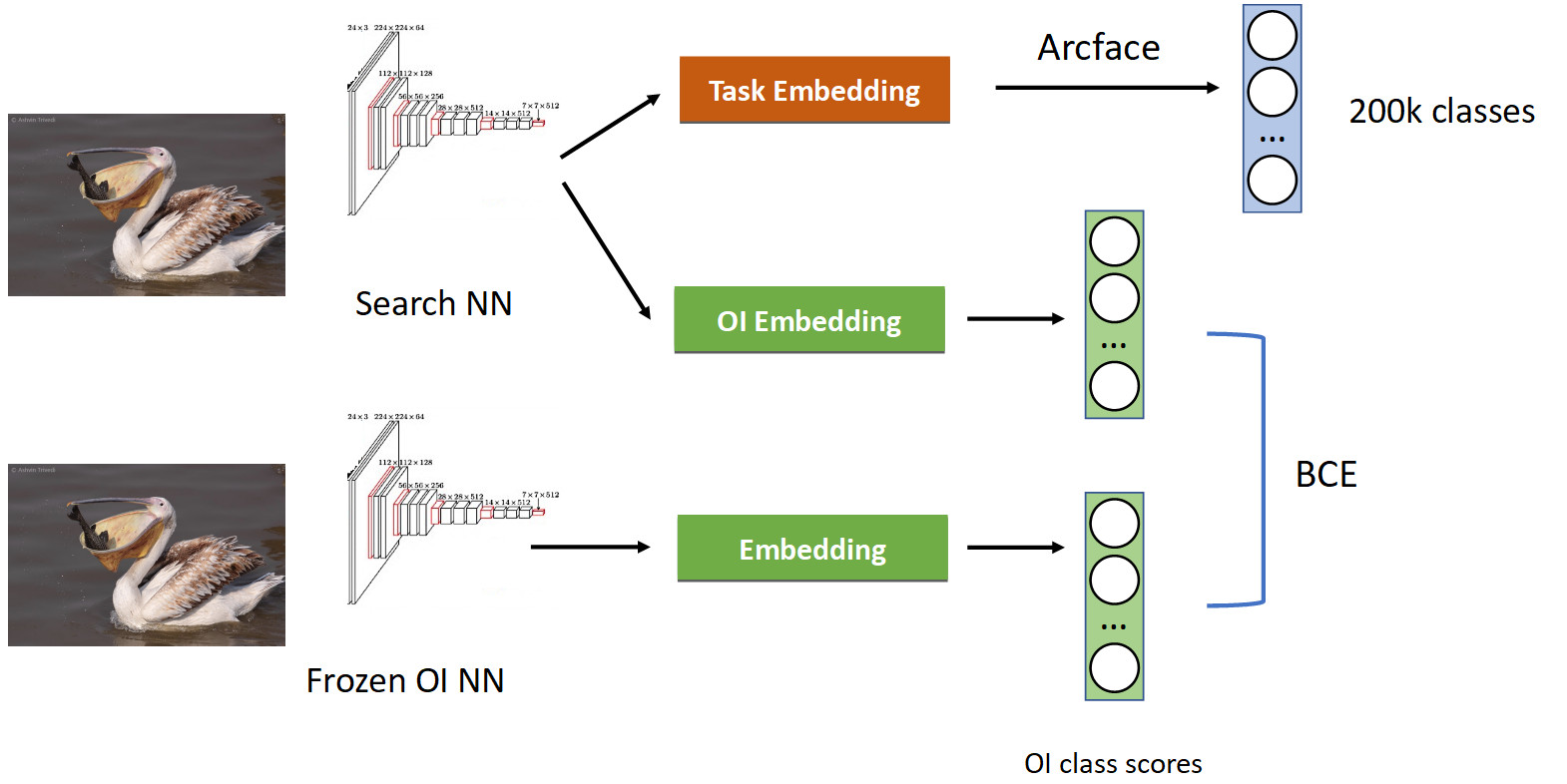
Kami sudah memiliki pipa klasifikasi yang akrab dengan Arcface. Ingatlah bahwa kita memiliki jaringan tempat kita berpura-pura. Kami membekukannya dan menghitung embeddings-nya di semua foto di mana kami mempelajari jaringan kami, dan mendapatkan kelas-kelas OpenImages dengan cepat: pelikan, burung gereja, mobil, orang, dll. Kami beranjak dari jaringan saraf asli yang terlatih dan belajar menanamkan lain untuk kelas OpenImages, yang menghasilkan skor serupa. Dengan BCE, kami membuat jaringan menghasilkan distribusi skor yang serupa. Dengan demikian, di satu sisi, kami sedang belajar tugas baru (di bagian atas gambar), tetapi kami juga membuat jaringan tidak melupakan akarnya (di bagian bawah) - ingat kelas yang dulu ia ketahui. Jika Anda menyeimbangkan gradien dengan benar dalam proporsi bersyarat 50/50, maka ini akan meninggalkan semua pelikan di bagian atas dan membuang semua burung pipit dari sana.

Ketika kami menerapkan ini, kami mendapat persentase penuh di peta. Ini cukup banyak.
Jadi jika jaringan Anda lupa tugas sebelumnya, maka perlakukan menggunakan distilasi pengetahuan - ini berfungsi dengan baik.
Kepala tambahan
Ide dasarnya sangat sederhana. Lagi pada contoh Pengenalan Wajah. Kami memiliki satu set orang di dataset. Tetapi juga sering dalam dataset ada karakteristik wajah lainnya. Misalnya, berapa umur, warna mata apa, dll. Semua ini dapat ditambahkan sebagai satu lagi penambahan. sinyal: ajarkan setiap kepala untuk memprediksi data ini. Dengan demikian, jaringan kami menerima sinyal yang lebih beragam, dan sebagai hasilnya, mungkin lebih baik untuk mempelajari tugas utama.
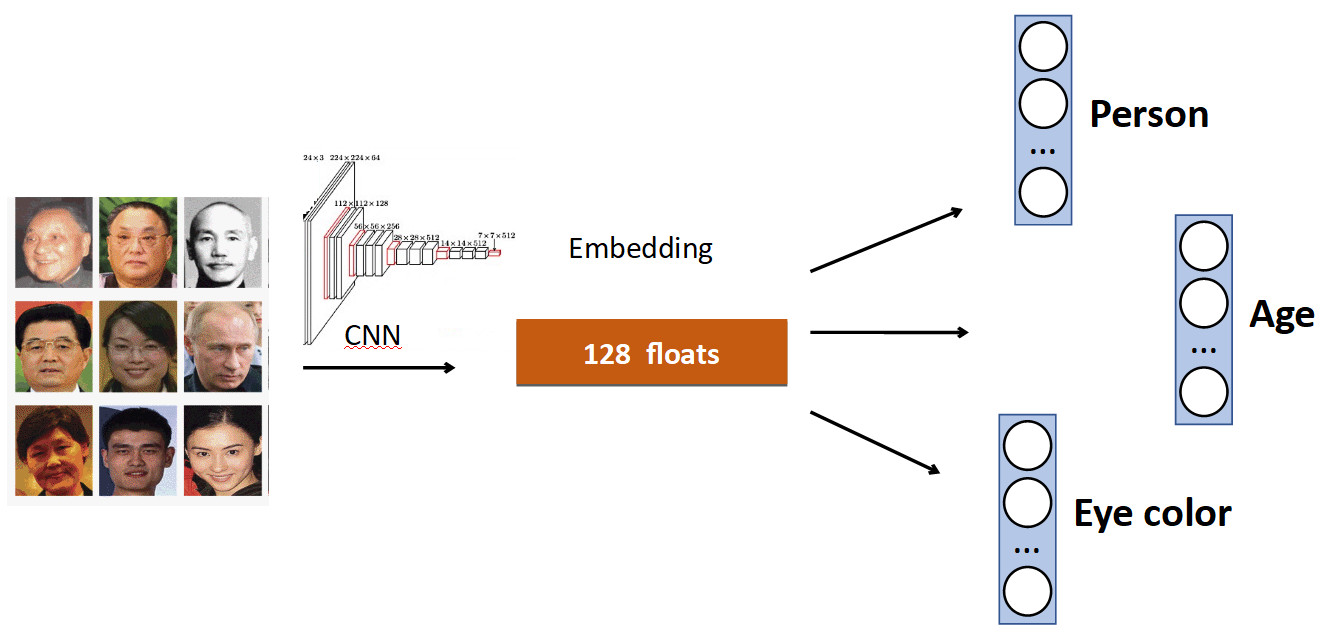
Contoh lain: deteksi antrian.

Seringkali dalam kumpulan data dengan orang-orang, selain tubuh, ada tanda yang terpisah dari posisi kepala, yang, jelas, dapat digunakan. Oleh karena itu, kami menambahkan ke jaringan prediksi kotak terikat orang tersebut dan prediksi kotak terikat kepala, dan kami mendapat peningkatan akurasi (mAP) 0,5%, yang layak. Dan yang paling penting - gratis dalam hal kinerja, karena pada produksi, kepala tambahan "terputus".

OCR
Kasus yang lebih kompleks dan menarik adalah OCR, yang telah disebutkan di atas. Pipa standar seperti itu.
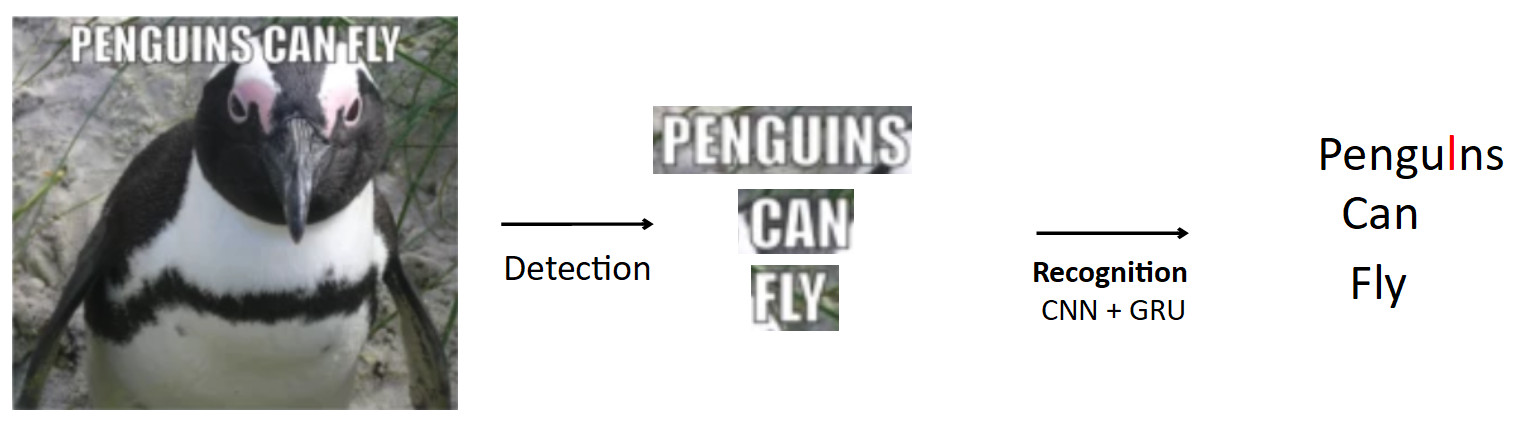
Biarkan ada poster dengan penguin, teks tertulis di atasnya. Menggunakan model pendeteksian, kami menyoroti teks ini. Selanjutnya, kami mengumpankan teks ini ke input dari model pengenalan, yang menghasilkan teks yang dikenali. Katakanlah jaringan kami salah dan bukannya "i" dalam kata penguin memprediksi "l". Ini sebenarnya masalah yang sangat umum di OCR ketika jaringan membingungkan karakter yang sama. Pertanyaannya adalah bagaimana menghindari ini - menerjemahkan penguin menjadi penguin? Ketika seseorang melihat contoh ini, jelas baginya bahwa ini adalah kesalahan, karena dia memiliki pengetahuan tentang struktur bahasa. Oleh karena itu, pengetahuan tentang distribusi karakter dan kata-kata dalam bahasa harus tertanam dalam model.
Kami menggunakan sesuatu yang disebut BPE (byte-pair encoding) untuk ini. Ini adalah algoritma kompresi yang umumnya ditemukan kembali di tahun 90-an bukan untuk pembelajaran mesin, tetapi sekarang sangat populer dan digunakan dalam pembelajaran yang mendalam. Arti dari algoritma ini adalah bahwa teks yang sering muncul kemudian diganti dengan karakter baru. Misalkan kita memiliki string "aaabdaaabac", dan kami ingin mendapatkan BPE untuk itu. Kami menemukan bahwa pasangan karakter "aa" adalah yang paling sering dalam kata kami. Kami menggantinya dengan karakter baru "Z", kami mendapatkan string "ZabdZabac". Kami mengulangi iterasi: kami melihat bahwa ab adalah proses yang paling sering, ganti dengan "Y", kami mendapatkan string "ZYdZYac". Sekarang "ZY" adalah urutan yang paling sering, kita ganti dengan "X", kita dapatkan "XdXac". Dengan demikian, kami menyandikan beberapa dependensi statistik dalam distribusi teks. Jika kita menemukan kata yang sangat "aneh" (jarang untuk korps pengajaran) selanjutnya, maka kata ini mencurigakan.
aaabdaaabac
ZabdZabac Z=aa
ZY d ZY ac Y=ab
X d X ac X=ZYBagaimana semua itu cocok dengan pengakuan.
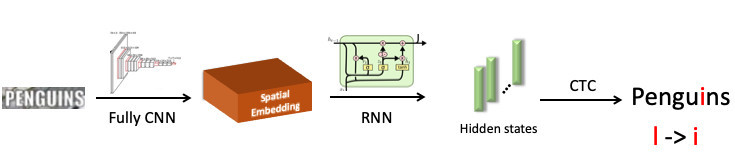
Kami menyoroti kata "penguin", mengirimkannya ke jaringan saraf convolutional, yang menghasilkan penanaman spasial (vektor dengan panjang tetap, misalnya 512). Vektor ini menyandikan informasi simbol spasial. Selanjutnya, kami menggunakan jaringan pengulangan (UPD: pada kenyataannya, kami sudah menggunakan model Transformer), ia memberikan beberapa status tersembunyi (bilah hijau), di mana masing-masing distribusi probabilitas dijahit - yang, menurut model, simbol digambarkan pada posisi tertentu. Kemudian, dengan menggunakan CTC-Loss, kami melepas kondisi ini dan mendapatkan prediksi kami untuk seluruh kata, tetapi dengan kesalahan: L di tempat i.
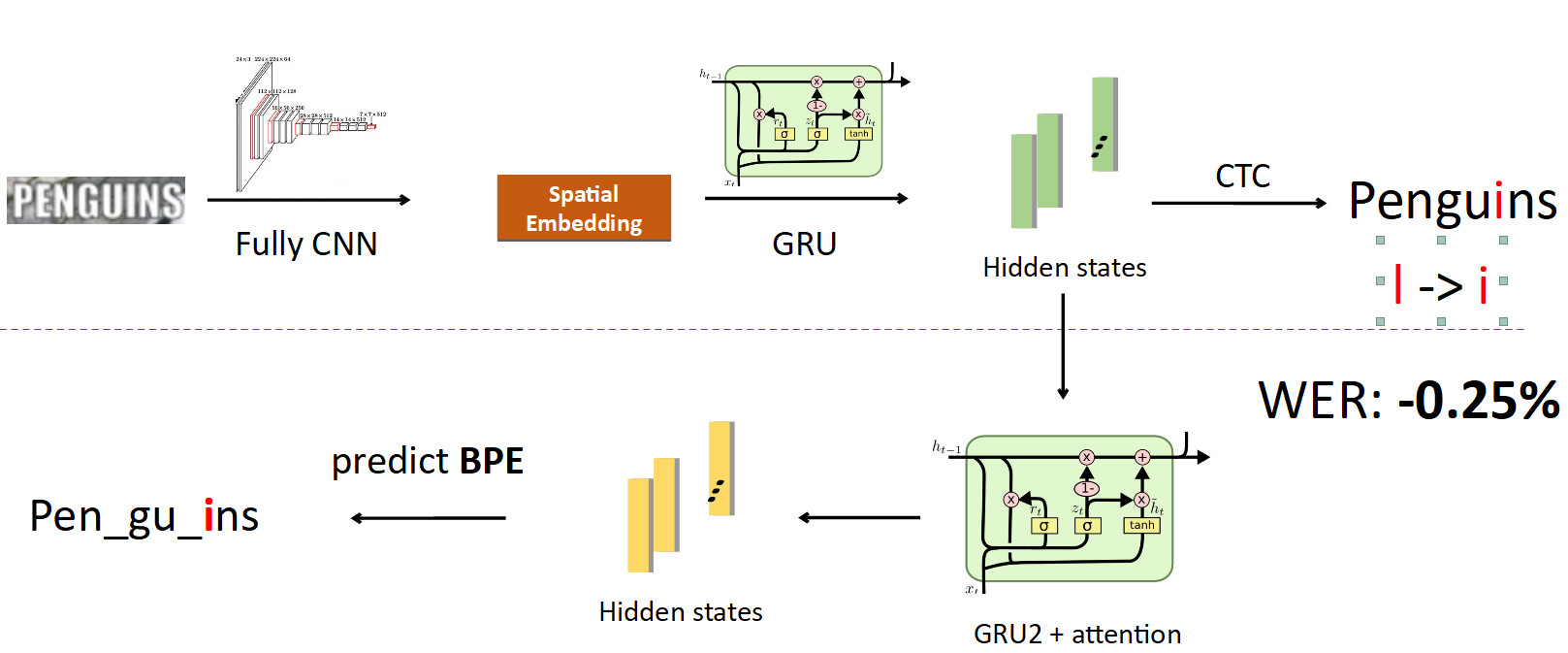
Sekarang mengintegrasikan BPE di dalam pipa. Kami ingin melepaskan diri dari memprediksi karakter individu ke kata-kata, jadi kami bercabang dari negara di mana informasi tentang karakter dijahit dan menetapkan jaringan rekursif lain pada mereka; dia memprediksi BPE. Dalam kasus kesalahan yang dijelaskan di atas, 3 BPE diperoleh: "peng", "ul", "ns". Ini berbeda secara signifikan dari urutan yang benar untuk kata penguin, yaitu, pena, gu, in. Jika Anda melihat ini dari sudut pandang pelatihan model, maka, dalam prediksi karakter per kata, jaringan membuat kesalahan hanya dalam satu huruf dari delapan (kesalahan 12,5%); dan dalam hal BPE, dia 100% keliru dalam memprediksi ketiga BPE secara salah. Ini adalah sinyal yang jauh lebih besar untuk jaringan bahwa ada sesuatu yang salah dan Anda perlu memperbaiki perilaku Anda. Ketika kami menerapkan ini, kami dapat memperbaiki kesalahan semacam ini dan mengurangi Word Error Rate sebesar 0,25% - itu banyak. Kepala tambahan ini dihilangkan saat menyimpulkan, memenuhi perannya dalam pelatihan.
FP16
Hal terakhir yang ingin saya katakan tentang pelatihan adalah FP16. Kebetulan secara historis bahwa jaringan dilatih pada GPU dalam keakuratan unit, yaitu FP32. Tapi ini berlebihan, terutama untuk inferensi, di mana setengah akurasi (FP16) sudah cukup tanpa kehilangan kualitas. Namun, ini tidak terjadi dengan pelatihan.
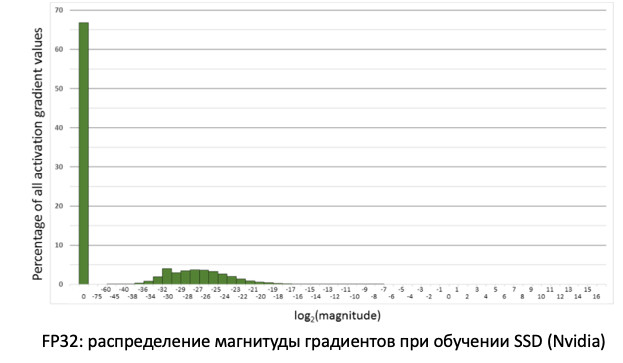
Jika kita melihat distribusi gradien, informasi yang memperbarui bobot kita ketika menyebarkan kesalahan, kita akan melihat bahwa ada puncak besar di nol. Dan secara umum, banyak nilai mendekati nol. Jika kita hanya mentransfer semua bobot ke FP16, ternyata kita memotong sisi kiri di wilayah nol (dari garis merah).
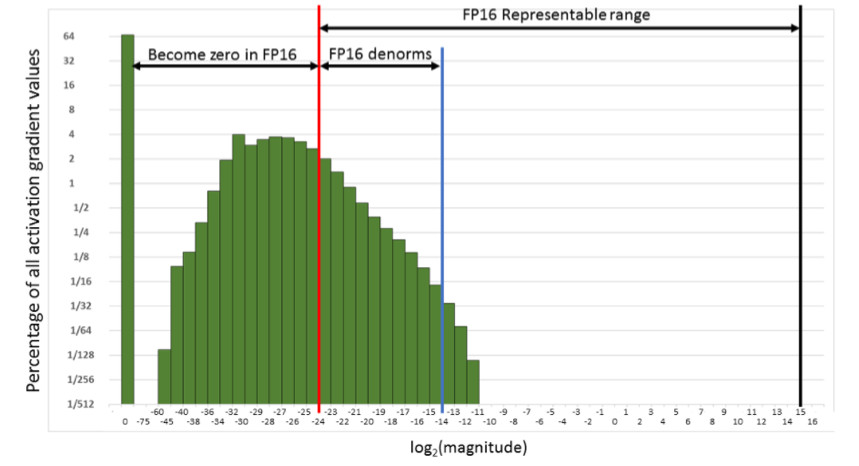
Artinya, kami akan mengatur ulang sejumlah besar gradien. Dan bagian yang tepat, dalam rentang kerja FP16, tidak digunakan sama sekali. Akibatnya, jika Anda melatih dahi pada FP16, maka prosesnya cenderung bubar (grafik abu-abu pada gambar di bawah).
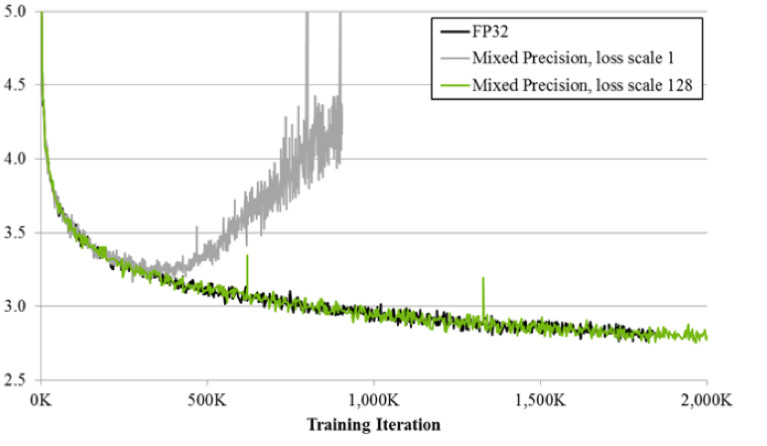
Jika Anda berlatih menggunakan teknik presisi campuran, hasilnya hampir identik dengan FP32. Presisi campuran menerapkan dua trik.
Pertama: kita hanya mengalikan kehilangan dengan konstanta, misalnya, 128. Dengan demikian, kita skala semua gradien, dan memindahkan nilainya dari nol ke rentang kerja FP16. Kedua: kami menyimpan versi master keseimbangan FP32, yang hanya digunakan untuk memperbarui, dan dalam operasi penghitungan jaringan pass maju dan mundur, hanya FP16 yang digunakan.
Kami menggunakan Pytorch untuk melatih jaringan. NVIDIA membuat perakitan khusus untuknya dengan yang disebut APEX, yang mengimplementasikan logika yang dijelaskan di atas. Ia memiliki dua mode. Yang pertama adalah presisi campuran otomatis. Lihat kode di bawah ini untuk melihat betapa mudahnya menggunakannya.

Secara harfiah dua baris ditambahkan ke kode pelatihan yang membungkus kerugian dan prosedur inisialisasi model dan pengoptimal. Apa yang dilakukan AMP? Dia monyet menambal semua fungsi. Apa yang sebenarnya terjadi? Misalnya, ia melihat bahwa ada fungsi konvolusi, dan dia menerima keuntungan dari FP16. Kemudian ia menggantinya dengan miliknya, yang pertama kali dilemparkan ke FP16, dan kemudian melakukan operasi konvolusi. Jadi AMP tidak untuk semua fungsi yang dapat digunakan di jaringan. Bagi sebagian orang, itu tidak. tidak akan ada akselerasi. Untuk sebagian besar tugas, metode ini cocok.
Opsi kedua: Pengoptimal FP16 untuk penggemar kontrol penuh. Cocok jika Anda sendiri ingin menentukan lapisan mana yang akan di FP16 dan yang di FP32. Tetapi ia memiliki sejumlah keterbatasan dan kesulitan. Itu tidak dimulai dengan setengah tendangan (setidaknya kami harus berkeringat untuk memulainya). Juga FP_optimizer hanya berfungsi dengan Adam, dan itupun hanya dengan Adam itu, yang ada di APEX (ya, mereka memiliki Adam sendiri di repositori, yang memiliki antarmuka yang sama sekali berbeda dari Paytorch).
Kami membuat perbandingan ketika belajar pada kartu Tesla T4.
Di Inference, kami memiliki akselerasi yang diharapkan dua kali. Dalam pelatihan, kami melihat bahwa kerangka kerja Apex memberikan akselerasi 20% dengan FP16 yang relatif sederhana. Sebagai hasilnya, kami mendapatkan latihan yang dua kali lebih cepat dan menghabiskan memori 2 kali lebih sedikit, dan kualitas pelatihan tidak menderita sama sekali. Freebie.
Kesimpulan
Karena Karena kami menggunakan PyTorch, pertanyaannya adalah bagaimana menerapkannya dalam produksi.
Ada 3 opsi untuk bagaimana melakukannya (dan semuanya kami gunakan).
- ONNX -> Caffe2
- ONNX -> TensorRT
- Dan baru-baru ini Pytorch C ++
Mari kita lihat masing-masing.
ONNX dan Caffe2
ONNX muncul 1,5 tahun yang lalu. Ini adalah kerangka kerja khusus untuk mengkonversi model antara kerangka kerja yang berbeda. Dan Caffe2 adalah kerangka kerja yang berdekatan dengan Pytorch, keduanya sedang dikembangkan di Facebook. Secara historis, Pytorch berkembang jauh lebih cepat daripada Caffe2. Caffe2 tertinggal di belakang fitur Pytorch, jadi tidak setiap model yang Anda latih di Pytorch dapat dikonversi ke Caffe2. Seringkali Anda harus belajar kembali dengan layer lain. Misalnya, dalam Caffe2 tidak ada operasi standar seperti upsampling dengan interpolasi tetangga terdekat. Hasilnya, kami sampai pada kesimpulan bahwa untuk setiap model kami mendapatkan gambar buruh pelabuhan khusus, di mana kami memakukan versi kerangka dengan paku untuk menghindari perbedaan selama pembaruan di masa mendatang, sehingga ketika salah satu versi diperbarui lagi, kami tidak membuang waktu untuk kompatibilitasnya. . Semua ini sangat tidak nyaman dan memperpanjang proses penyebaran.
Tensor rt
Ada juga Tensor RT, kerangka kerja NVIDIA yang mengoptimalkan arsitektur jaringan untuk mempercepat inferensi. Kami melakukan pengukuran kami (pada peta Tesla T4).
Jika Anda melihat grafik, Anda dapat melihat bahwa transisi dari FP32 ke FP16 memberikan akselerasi 2x di Pytorch, dan TensorRT pada saat yang sama memberikan sebanyak 4x. Perbedaan yang sangat signifikan. Kami mengujinya pada Tesla T4, yang memiliki kernel tensor yang sangat baik menggunakan perhitungan FP16, yang jelas sangat baik di TensorRT. Karena itu, jika ada model yang sangat sarat dengan lusinan kartu grafis, maka ada semua motivator untuk mencoba Tensor RT.
Namun, ketika bekerja dengan TensorRT bahkan ada lebih banyak rasa sakit daripada di Caffe2: lapisan bahkan kurang didukung di dalamnya. Sayangnya, setiap kali kita menggunakan kerangka ini, kita harus sedikit menderita untuk mengubah model. Tetapi untuk model yang sarat muatan, Anda harus melakukan ini. ;) Saya perhatikan bahwa pada peta tanpa kernel tensor peningkatan sebesar itu tidak diamati.
Pytorch C ++
Dan yang terakhir adalah Pytorch C ++. Enam bulan lalu, pengembang Pytorch menyadari rasa sakit orang-orang yang menggunakan kerangka kerja mereka dan merilis
tutorial TorchScript , yang memungkinkan Anda untuk melacak dan membuat serial model Python ke dalam grafik statis tanpa gerakan yang tidak perlu (JIT). Ini dirilis pada Desember 2018, kami segera mulai menggunakannya, segera menangkap beberapa bug kinerja dan menunggu beberapa bulan untuk
perbaikan dari
Chintala . Tetapi sekarang ini adalah teknologi yang cukup stabil, dan kami secara aktif menggunakannya untuk semua model. Satu-satunya hal adalah kurangnya dokumentasi, yang sedang ditambah secara aktif. Tentu saja, Anda selalu dapat melihat file *. H, tetapi bagi orang yang tidak tahu plusnya, itu sulit. Tapi kemudian ada pekerjaan yang benar-benar identik dengan Python. Di C ++, j-code dijalankan pada juru bahasa Python minimal, yang secara praktis menjamin identitas C ++ dengan Python.
Kesimpulan
- Pernyataan masalah itu sangat penting. Anda harus berkomunikasi dengan manajer produk tentang data. Sebelum Anda mulai melakukan tugas, disarankan untuk memiliki set uji siap pakai yang kami ukur metrik terakhir sebelum tahap implementasi.
- Kami membersihkan data diri kami dengan bantuan pengelompokan. Kami mendapatkan model pada sumber data, membersihkan data menggunakan CLink clustering, dan ulangi prosesnya sampai konvergensi.
- Pembelajaran metrik: bahkan klasifikasi membantu. State-of-the-art - ArcFace, yang mudah diintegrasikan ke dalam proses pembelajaran.
- Jika Anda melakukan transfer pembelajaran dari jaringan pra-terlatih, maka agar jaringan tidak melupakan tugas lama, gunakan distilasi pengetahuan.
- Juga berguna untuk menggunakan beberapa kepala jaringan yang akan memanfaatkan sinyal berbeda dari data untuk meningkatkan tugas utama.
- Untuk FP16, Anda harus menggunakan perangkat Apex dari NVIDIA, Pytorch.
- Dan pada kesimpulan, nyaman untuk menggunakan Pytorch C ++.