Catatan perev. : Penulis materi ini adalah Cindy Sridharan, seorang insinyur dari imgix yang terlibat dalam pengembangan API dan, khususnya, menguji layanan-layanan mikro. Dalam artikel ini, ia berbagi visi terperinci tentang masalah aktual di bidang penelusuran terdistribusi, di mana, menurut pendapatnya, ada kekurangan alat yang benar-benar efektif untuk menyelesaikan masalah mendesak. [Ilustrasi dipinjam dari bahan lain tentang penelusuran yang didistribusikan.]
[Ilustrasi dipinjam dari bahan lain tentang penelusuran yang didistribusikan.]Dipercayai bahwa
penelusuran terdistribusi sulit untuk diterapkan, dan pengembaliannya
meragukan . "Masalah" jejak dijelaskan oleh banyak alasan, sering merujuk pada kompleksitas pengaturan setiap komponen sistem untuk mengirimkan header yang sesuai bersama dengan setiap permintaan. Meskipun masalah ini memang terjadi, itu tidak bisa disebut tidak dapat diatasi sama sekali. By the way, itu tidak menjelaskan mengapa pengembang tidak terlalu suka melacak (bahkan sudah berfungsi).
Kesulitan utama dengan penelusuran terdistribusi adalah tidak mengumpulkan data, tidak membakukan format untuk mendistribusikan dan menyajikan hasil, dan tidak menentukan kapan, di mana dan bagaimana sampel. Saya sama sekali tidak berusaha menyajikan "masalah-masalah kecernaan" ini sebagai
hal sepele - pada kenyataannya, ada cukup banyak masalah teknis dan (jika kita benar-benar melihat
standar dan protokol Open Source) tantangan-tantangan politik yang harus diatasi sehingga masalah-masalah ini dapat dipertimbangkan terselesaikan.
Namun, jika Anda membayangkan bahwa semua masalah ini telah diatasi, kemungkinan tidak ada yang akan berubah secara signifikan dalam hal
pengalaman pengguna akhir . Melacak mungkin masih tidak praktis dalam skenario debugging paling umum - bahkan setelah itu telah dikerahkan.
Jejak yang sangat berbeda
Pelacakan terdistribusi mencakup beberapa komponen yang berbeda:
- melengkapi aplikasi dan middleware dengan kontrol;
- Transmisi konteks terdistribusi
- koleksi jejak;
- penyimpanan jejak;
- ekstraksi dan visualisasi mereka.
Banyak pembicaraan tentang penelusuran terdistribusi datang untuk mempertimbangkannya sebagai semacam operasi yang tidak disadari, satu-satunya tujuan adalah untuk membantu dalam diagnosis lengkap sistem. Ini sebagian besar disebabkan oleh cara di mana konsep pelacakan terdistribusi terbentuk. Dalam
posting blog yang dibuat ketika sumber Zipkin dibuka, disebutkan bahwa
ia [Zipkin] membuat Twitter lebih cepat . Penawaran komersial pertama untuk penelusuran juga dipromosikan sebagai
alat APM .
Catatan perev. : Agar teks lebih lanjut dapat dipahami dengan lebih baik, kami mendefinisikan dua istilah dasar sesuai dengan dokumentasi proyek OpenTracing :- Rentang - elemen dasar dari penelusuran terdistribusi. Ini adalah deskripsi alur kerja tertentu (misalnya, kueri basis data) dengan nama, waktu mulai dan akhir, tag, log, dan konteks.
- Rentang biasanya berisi tautan ke rentang lain, yang memungkinkan Anda untuk menggabungkan banyak rentang di Trace - visualisasi kehidupan permintaan saat bergerak melalui sistem terdistribusi.
Trace'y berisi data yang sangat berharga yang dapat membantu dalam tugas-tugas seperti: pengujian dalam produksi, melakukan tes pemulihan bencana, pengujian dengan pengenalan kesalahan, dll. Bahkan, beberapa perusahaan sudah menggunakan pelacakan untuk tujuan seperti itu. Untuk mulai dengan,
transfer konteks universal memiliki kegunaan lain selain hanya mentransfer rentang ke sistem penyimpanan:
- Misalnya, Uber menggunakan hasil penelusuran untuk membedakan antara lalu lintas uji dan lalu lintas produksi.
- Facebook menggunakan jejak data untuk menganalisis jalur kritis dan untuk mengubah lalu lintas selama tes pemulihan bencana reguler.
- Jejaring sosial ini juga menggunakan notebook Jupyter, yang memungkinkan pengembang untuk mengeksekusi permintaan arbitrer atas hasil penelusuran.
- Penganut Kegagalan Injeksi Lineage Driven ( LDFI) menggunakan jejak terdistribusi untuk pengujian kesalahan.
Tak satu pun dari opsi di atas yang sepenuhnya berhubungan dengan skenario
debugging , di mana insinyur mencoba untuk memecahkan masalah dengan melihat jejak.
Ketika datang ke skenario debugging, diagram
jejak tetap antarmuka utama (meskipun beberapa juga menyebutnya
"Gantt chart" atau
"diagram berjenjang" ). Dengan
traceview, maksud saya semua bentang dan metadata terkait yang bersama-sama membentuk jejak. Setiap sistem penelusuran open source, serta setiap solusi penelusuran komersial, menawarkan antarmuka pengguna berbasis-
pelacakan -
jejak untuk memvisualisasikan, merinci, dan memfilter data jejak.
Masalah dengan semua sistem jejak yang saya kenal saat ini adalah bahwa
visualisasi terakhir
(traceview) hampir sepenuhnya mencerminkan fitur dari proses pembuatan jejak. Bahkan ketika visualisasi alternatif ditawarkan: peta intensitas (peta panas), topologi layanan, histogram latensi - pada akhirnya mereka masih turun ke
penelusuran jejak .
Di masa lalu, saya
mengeluh bahwa sebagian besar "inovasi" dalam keterlacakan sehubungan dengan UI / UX tampaknya terbatas untuk
memasukkan metadata tambahan dalam jejak, menanamkan informasi dengan
kardinalitas tinggi di dalamnya, atau menyediakan kemampuan untuk menelusuri ke rentang tertentu atau menjalankan kueri
antar dan intra-jejak . Dalam hal ini,
traceview tetap menjadi alat utama visualisasi. Selama kondisi ini tetap ada, penelusuran terdistribusi akan (paling baik) menempati posisi ke-4 sebagai alat debugging, diikuti oleh metrik, log, dan tumpukan jejak, dan paling buruk itu akan menjadi pemborosan uang dan waktu.
Masalah dengan traceview
Tujuan
penelusuran jejak adalah untuk memberikan gambaran lengkap tentang pergerakan permintaan individu di semua komponen sistem terdistribusi yang terkait. Beberapa sistem penelusuran yang lebih maju memungkinkan Anda menelusuri bentang individual dan melihat rincian waktu
dalam satu proses tunggal (saat bentang memiliki batas fungsional).
Premis dasar arsitektur layanan microsoft adalah gagasan bahwa struktur organisasi tumbuh dengan kebutuhan perusahaan. Para pendukung layanan mikro berpendapat bahwa distribusi berbagai tugas bisnis di berbagai layanan terpisah memungkinkan tim pengembangan kecil dan otonom untuk mengendalikan seluruh siklus hidup layanan tersebut, memungkinkan mereka untuk secara mandiri membuat, menguji, dan menggunakan layanan ini. Namun, kelemahan dari distribusi ini adalah hilangnya informasi tentang bagaimana setiap layanan berinteraksi dengan yang lain. Dalam keadaan seperti itu, klaim penelusuran terdistribusi menjadi alat yang sangat diperlukan untuk
men -
debug interaksi kompleks antara layanan.
Jika Anda memiliki
sistem distribusi yang benar
- benar
menakjubkan , maka tidak ada yang dapat mengingat gambaran
lengkapnya . Bahkan, mengembangkan alat berdasarkan asumsi bahwa secara umum mungkin adalah sedikit antipattern (pendekatan yang tidak efisien dan tidak produktif). Idealnya, debugging memerlukan alat untuk membantu
mempersempit pencarian Anda sehingga para insinyur dapat fokus pada subset dimensi (layanan / pengguna / host, dll.) Yang relevan dengan skenario yang dimaksud. Ketika menentukan penyebab kegagalan, para insinyur tidak diharuskan untuk memahami apa yang terjadi di
semua layanan sekaligus , karena persyaratan seperti itu akan bertentangan dengan gagasan arsitektur layanan mikro.
Namun, traceview
hanya itu. Ya, beberapa sistem jejak menawarkan tampilan jejak terkompresi ketika jumlah bentang dalam penelusuran sangat besar sehingga tidak dapat ditampilkan dalam satu visualisasi. Namun, karena banyaknya informasi yang terkandung bahkan dalam visualisasi terpotong seperti itu, para insinyur masih
dipaksa untuk "menyaringnya", secara manual mempersempit pilihan menjadi serangkaian sumber masalah layanan. Sayangnya, dalam bidang ini mesin jauh lebih cepat daripada manusia, lebih tidak rentan terhadap kesalahan, dan hasilnya lebih berulang.
Alasan lain saya pikir metode traceview salah adalah karena tidak cocok untuk debugging hipotesis. Pada intinya, debugging adalah proses
berulang dimulai dengan hipotesis, diikuti dengan memeriksa berbagai pengamatan dan fakta yang diterima dari sistem menggunakan vektor yang berbeda, kesimpulan / generalisasi, dan penilaian lebih lanjut tentang kebenaran hipotesis.
Kemampuan
untuk menguji hipotesis
dengan cepat dan murah dan meningkatkan model mental yang sesuai adalah
landasan debugging. Alat debugging apa pun harus
interaktif dan mempersempit ruang pencarian atau, dalam kasus jejak palsu, memungkinkan pengguna untuk kembali dan fokus pada area lain dari sistem. Alat yang ideal akan melakukan ini secara
proaktif , segera menarik perhatian pengguna ke area yang berpotensi bermasalah.
Sayangnya,
traceview tidak dapat disebut alat antarmuka interaktif. Yang terbaik yang dapat Anda harapkan ketika menggunakannya adalah mendeteksi sumber penundaan tertentu yang meningkat dan melihat semua jenis tag dan log yang terkait dengannya. Ini tidak membantu insinyur untuk mengidentifikasi
pola dalam lalu lintas, seperti spesifikasi distribusi keterlambatan, atau untuk mendeteksi korelasi antara pengukuran yang berbeda.
Analisis jejak umum dapat mengatasi beberapa masalah ini. Memang,
ada contoh analisis yang berhasil menggunakan pembelajaran mesin untuk mengidentifikasi rentang abnormal dan mengidentifikasi subset tag yang mungkin terkait dengan perilaku abnormal. Namun demikian, saya belum menemukan visualisasi yang meyakinkan dari temuan yang dibuat menggunakan pembelajaran mesin atau analisis data yang diterapkan pada bentang yang akan sangat berbeda dari traceview atau DAG (directional acyclic graph).
Rentang levelnya terlalu rendah
Masalah mendasar dengan traceview adalah
rentang yang terlalu primitif untuk analisis latensi dan analisis akar penyebab. Ini seperti menganalisis setiap perintah prosesor dalam upaya untuk menghilangkan pengecualian, mengetahui bahwa ada alat yang jauh lebih tinggi seperti backtrace, yang jauh lebih nyaman untuk digunakan.
Selain itu, saya akan mengambil kebebasan menyatakan hal berikut: idealnya, kita tidak perlu
gambaran lengkap tentang apa yang terjadi selama siklus hidup permintaan, yang diwakili oleh alat modern untuk melacak. Alih-alih, beberapa bentuk abstraksi tingkat yang lebih tinggi diperlukan, berisi informasi tentang apa yang
salah (mirip dengan backtrace), bersama dengan beberapa konteks. Alih-alih mengamati seluruh jejak, saya lebih suka melihat
bagiannya di mana sesuatu yang menarik atau tidak biasa terjadi. Saat ini, pencarian dilakukan secara manual: insinyur menerima jejak dan secara independen menganalisis rentang untuk mencari sesuatu yang menarik. Pendekatan ketika orang menatap bentang di jejak terpisah dengan harapan mendeteksi aktivitas yang mencurigakan tidak berskala sama sekali (terutama ketika mereka harus memahami semua metadata yang disandikan dalam bentang yang berbeda, seperti span ID, nama metode RPC, durasi span 'a, log, tag, dll.)
Traceview alternatif
Melacak hasil sangat berguna ketika mereka dapat divisualisasikan sedemikian rupa untuk mendapatkan ide non-sepele tentang apa yang terjadi di bagian-bagian sistem yang saling berhubungan. Sampai saat ini terjadi, proses debugging sebagian besar tetap
lembam dan tergantung pada kemampuan pengguna untuk melihat korelasi yang benar, memeriksa bagian-bagian yang benar dari sistem atau mengumpulkan potongan-potongan mosaik bersama-sama - tidak seperti
alat yang membantu pengguna merumuskan hipotesis ini.
Saya bukan perancang visual atau spesialis UX, tetapi di bagian selanjutnya saya ingin berbagi beberapa ide tentang bagaimana visualisasi tersebut akan terlihat.
Fokus pada layanan tertentu
Dalam lingkungan di mana industri ini berkonsolidasi di sekitar ide-ide
SLO (tujuan tingkat layanan) dan SLI (indikator tingkat layanan) , tampaknya masuk akal bahwa tim individu harus terlebih dahulu memantau kesesuaian layanan mereka dengan tujuan-tujuan ini. Oleh karena itu visualisasi yang
berorientasi layanan paling cocok untuk tim tersebut.
Jejak, terutama tanpa pengambilan sampel, adalah gudang informasi tentang setiap komponen sistem terdistribusi. Informasi ini dapat diumpankan ke penangan rumit yang akan memberikan temuan berorientasi
layanan kepada pengguna, yang dapat dideteksi sebelumnya - bahkan sebelum pengguna melihat jejak:
- Tunda diagram distribusi hanya untuk permintaan yang sangat berbeda (permintaan outlier) ;
- Tunda diagram distribusi untuk kasus-kasus ketika sasaran layanan SLO tidak tercapai;
- Tag yang paling "umum", "menarik" dan "aneh" dalam kueri, yang paling sering diulang ;
- Rincian penundaan untuk kasus-kasus ketika dependensi layanan tidak mencapai sasaran SLO yang ditetapkan;
- Rincian penundaan untuk berbagai layanan hilir.
Metrik bawaan tidak bisa menjawab beberapa pertanyaan ini, memaksa pengguna mempelajari bentang dengan cermat. Akibatnya, kami memiliki mekanisme yang sangat bermusuhan dengan pengguna.
Dalam hal ini, muncul pertanyaan: bagaimana dengan interaksi kompleks antara berbagai layanan yang dikendalikan oleh tim yang berbeda? Bukankah
traceview dianggap sebagai alat yang paling tepat untuk mengatasi situasi seperti itu?
Pengembang seluler, pemilik layanan tanpa kewarganegaraan, pemilik layanan stateful yang dikelola (seperti basis data) dan pemilik platform mungkin tertarik pada
pandangan lain
tentang sistem terdistribusi;
traceview adalah solusi yang terlalu universal untuk kebutuhan yang berbeda secara mendasar ini. Bahkan dalam arsitektur layanan mikro yang sangat kompleks, pemilik layanan tidak perlu pengetahuan mendalam tentang lebih dari dua atau tiga layanan hulu dan hilir. Intinya, dalam sebagian besar skenario, pengguna hanya perlu menjawab pertanyaan terkait
serangkaian layanan terbatas .
Ini seperti melihat sekelompok kecil layanan melalui kaca pembesar demi penelitian yang cermat. Ini akan memungkinkan pengguna untuk mengajukan pertanyaan yang lebih mendesak mengenai interaksi kompleks antara layanan ini dan ketergantungan langsung mereka. Ini mirip dengan backtrace di dunia layanan, di mana insinyur tahu
apa yang salah, dan juga memiliki beberapa gagasan tentang apa yang terjadi di layanan sekitarnya untuk memahami
mengapa .
Pendekatan yang saya promosikan adalah kebalikan dari pendekatan top-down yang didasarkan pada traceview, ketika analisis dimulai dengan seluruh jejak, dan kemudian secara bertahap turun ke rentang individu. Sebaliknya, pendekatan bottom-up dimulai dengan analisis area kecil yang dekat dengan potensi penyebab insiden, dan kemudian ruang pencarian diperluas jika perlu (dengan kemungkinan keterlibatan tim lain untuk menganalisis berbagai layanan yang lebih luas). Pendekatan kedua lebih cocok untuk dengan cepat menguji hipotesis awal. Setelah mendapatkan hasil tertentu, akan mungkin untuk beralih ke analisis yang lebih fokus dan terperinci.
Bangunan topologi
Pandangan yang terkait dengan layanan tertentu dapat sangat berguna jika pengguna tahu layanan atau kelompok layanan mana yang bertanggung jawab untuk meningkatkan keterlambatan atau merupakan sumber kesalahan. Namun, dalam sistem yang kompleks, mengidentifikasi penyusup mungkin bukan tugas sepele selama kegagalan, terutama jika tidak ada pesan kesalahan yang diterima dari layanan.
Membangun topologi layanan dapat sangat membantu dalam mencari tahu layanan mana yang menunjukkan lonjakan tingkat kesalahan atau peningkatan latensi, yang menyebabkan penurunan nyata dalam kinerja layanan. Berbicara tentang membangun topologi, maksud saya bukan
peta layanan yang menampilkan setiap layanan yang tersedia dalam sistem dan dikenal dengan
peta arsitekturnya dalam bentuk bintang kematian . Representasi seperti itu tidak lebih baik daripada penelusuran jejak berdasarkan grafik asiklik terarah. Sebaliknya, saya ingin melihat
topologi layanan yang dihasilkan secara dinamis berdasarkan atribut tertentu, seperti tingkat kesalahan, waktu respons, atau parameter yang ditentukan pengguna yang membantu memperjelas situasi dengan layanan mencurigakan tertentu.
Mari kita lihat sebuah contoh. Bayangkan sebuah situs berita hipotetis. Layanan
halaman depan berkomunikasi dengan Redis, dengan layanan rekomendasi, dengan layanan iklan dan layanan video. Layanan video mengambil video dari S3, dan metadata dari DynamoDB. Layanan rekomendasi menerima metadata dari DynamoDB, mengunduh data dari Redis dan MySQL, menulis pesan ke Kafka. Layanan iklan menerima data dari MySQL dan menulis pesan ke Kafka.
Berikut ini adalah representasi skematis dari topologi ini (banyak program perutean komersial membangun topologi). Ini bisa berguna jika Anda perlu memahami dependensi layanan. Namun, selama
debugging , ketika layanan tertentu (katakanlah, layanan video) menunjukkan peningkatan waktu respons, topologi seperti itu tidak terlalu berguna.
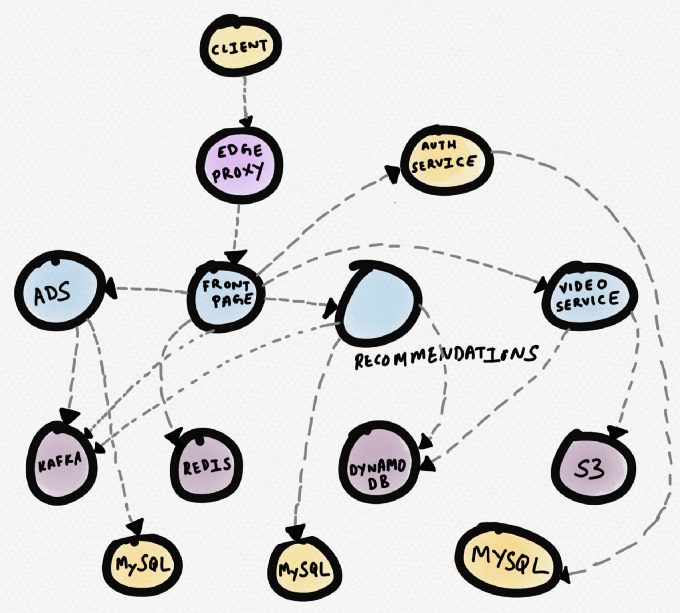 Skema Layanan Situs Berita Hipotesis
Skema Layanan Situs Berita HipotesisDiagram di bawah ini akan lebih baik. Di atasnya layanan bermasalah
(video) digambarkan tepat di tengah. Pengguna segera memperhatikannya. Dari visualisasi ini, menjadi jelas bahwa layanan video bekerja secara tidak normal karena meningkatnya waktu respons S3, yang mempengaruhi kecepatan pengunduhan bagian halaman utama.
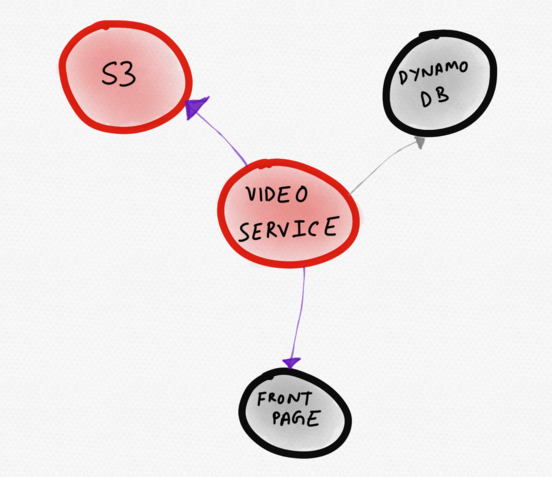 Topologi dinamis yang hanya menampilkan layanan "menarik"
Topologi dinamis yang hanya menampilkan layanan "menarik"Skema topologi yang dihasilkan secara dinamis bisa lebih efisien daripada peta layanan statis, terutama dalam infrastruktur fleksibel dan dapat diskalakan. Kemampuan untuk membandingkan dan membedakan topologi layanan memungkinkan pengguna untuk mengajukan pertanyaan yang lebih relevan. Pertanyaan yang lebih tepat tentang sistem lebih cenderung mengarah pada pemahaman yang lebih baik tentang cara kerja sistem.
Tampilan komparatif
Visualisasi lain yang bermanfaat adalah tampilan komparatif. Jejak saat ini tidak cocok untuk perbandingan berdampingan, sehingga
rentang biasanya dibandingkan. Dan ide utama dari artikel ini adalah bentang yang terlalu rendah untuk mengekstrak informasi yang paling berharga dari hasil penelusuran.
Perbandingan dua trace'ov tidak menuntut visualisasi baru yang fundamental. Bahkan, sesuatu seperti histogram yang mewakili informasi yang sama dengan traceview sudah cukup. Anehnya, bahkan metode sederhana ini dapat menghasilkan lebih banyak buah daripada studi sederhana tentang dua jejak secara terpisah. Yang lebih kuat lagi adalah kemampuan untuk
memvisualisasikan perbandingan jejak
dalam agregat . Akan sangat berguna untuk melihat bagaimana perubahan konfigurasi database yang baru-baru ini digunakan dengan dimasukkannya GC (pengumpulan sampah) memengaruhi waktu respons layanan hilir dalam beberapa jam. Jika apa yang saya jelaskan di sini seperti analisis A / B tentang dampak perubahan infrastruktur
di berbagai layanan menggunakan hasil penelusuran, maka Anda tidak terlalu jauh dari kebenaran.
Kesimpulan
Saya tidak mempertanyakan kegunaan dari jejak itu sendiri. Saya dengan tulus percaya bahwa tidak ada cara lain untuk mengumpulkan data yang kaya, santai, dan kontekstual seperti yang terkandung dalam jejak. , . , traceview-, , , trace'. , , .
, , . ,
, . , production , , , , .
, , , , , . , , , trace' span'.
( UI). , , . , . . .
PS dari penerjemah
Baca juga di blog kami: