Catatan perev. : Kami senang membagikan terjemahan materi yang luar biasa ini dari penginjil teknologi senior dari AWS - Adrian Hornsby. Dengan kata sederhana, ia menjelaskan pentingnya percobaan yang dirancang untuk mengurangi konsekuensi dari kegagalan dalam sistem TI. Anda mungkin sudah pernah mendengar tentang Chaos Monkey (atau bahkan menggunakan solusi serupa)? Saat ini, pendekatan untuk penciptaan alat-alat tersebut dan implementasinya dalam konteks yang lebih luas dilakukan sebagai bagian dari kegiatan yang disebut chaos engineering. Baca lebih lanjut di artikel ini.
"Tapi di balik semua keindahan ini terletak kekacauan dan kegilaan." - penyamak dinding
Petugas pemadam kebakaran . Spesialis berkualifikasi tinggi ini mempertaruhkan nyawa mereka setiap hari, melawan api. Apakah Anda tahu bahwa sebelum menjadi petugas pemadam kebakaran, Anda perlu menghabiskan setidaknya 600 jam dalam pelatihan? Dan ini baru permulaan. Menurut laporan, petugas pemadam kebakaran melatih hingga 80% dari waktu kerja mereka.
Mengapa
Ketika seorang petugas pemadam kebakaran berjuang dengan api sungguhan, ia membutuhkan
intuisi yang tepat. Untuk mengembangkannya, Anda harus melatih jam demi jam, hari demi hari. Seperti yang mereka katakan, latihan adalah keajaiban.
“Sepertinya mereka menembus esensi api; analog seperti Dr. Phil untuk nyala api. " - Melawan Kebakaran Hutan dengan Komputer dan Intuisi
Catatan perev. : Phillip Calvin "Phil" McGraw adalah seorang psikolog Amerika, penulis, presenter program televisi populer "Doctor Phil," di mana presenter menawarkan solusi kepada peserta untuk masalah mereka.Once Upon a Time di Seattle
Pada awal 2000-an,
Jesse Robbins , yang memegang posisi resmi di Amazon dengan nama resmi
Master of Disaster , menciptakan dan memimpin program GameDay. Itu berdasarkan pengalamannya sebagai petugas pemadam kebakaran. GameDay dirancang untuk menguji, mendidik, dan menyiapkan berbagai sistem, perangkat lunak, dan orang-orang Amazon untuk situasi krisis potensial.
Sama seperti petugas pemadam kebakaran mengembangkan intuisi untuk melawan api, Jesse akan membantu timnya mengembangkan intuisi untuk melawan peristiwa bencana skala besar.
"GameDay: Menciptakan Resiliensi Melalui Penghancuran" - Jesse RobbinsGameDay dirancang untuk meningkatkan daya tahan situs ritel Amazon dengan secara sengaja memasukkan kesalahan ke dalam sistem misi-kritis.
GameDay dimulai dengan serangkaian pengumuman untuk seluruh perusahaan bahwa alarm pelatihan direncanakan - kadang-kadang berskala sangat besar, misalnya, menonaktifkan seluruh pusat data. Rincian tentang penutupan yang direncanakan disediakan minimal, dan tim diberikan beberapa bulan untuk mempersiapkan. Tujuan utama dari latihan ini adalah untuk memeriksa apakah staf dapat mengatasi krisis lokal dan dengan cepat menghilangkan konsekuensinya.
Selama latihan ini, alat dan proses khusus, seperti pemantauan, peringatan dan panggilan darurat, digunakan untuk menganalisis dan mengidentifikasi kesalahan dalam prosedur respons insiden. Ternyata, GameDay dengan sempurna mengungkapkan masalah arsitektur klasik. Kadang-kadang juga mungkin untuk mendeteksi apa yang disebut "cacat tersembunyi" - masalah yang muncul karena kekhususan insiden tersebut. Misalnya, sistem manajemen kejadian yang penting untuk proses pemulihan gagal karena efek samping tak terduga yang disebabkan oleh masalah buatan manusia.
Ketika perusahaan tumbuh, jari-jari teoritis kekalahan dari GameDay meluas. Pada akhirnya, latihan-latihan ini berhenti: potensi kerusakan pada perusahaan menjadi terlalu besar jika terjadi kesalahan. Sejak itu, program ini telah merosot menjadi serangkaian eksperimen bisnis yang berbeda dan tidak berdampak bagi personel pelatihan dalam situasi krisis. Saya tidak akan membahas rincian percobaan dalam artikel ini, tetapi saya akan melakukannya di masa mendatang. Kali ini saya ingin membahas ide penting yang mendasari GameDay:
rekayasa ketahanan , juga dikenal sebagai
rekayasa kekacauan .
Monyet Naik
Anda mungkin pernah mendengar tentang Netflix, penyedia konten video online. Netflix mulai pindah dari pusat data sendiri ke AWS Cloud pada Agustus 2008. Langkah ini disebabkan oleh kerusakan serius pada basis data, karena pengiriman DVD ditunda selama tiga hari (ya, Netflix memulai dengan mengirim film melalui surat biasa). Migrasi ke cloud dikaitkan dengan kebutuhan untuk menahan beban streaming yang jauh lebih tinggi, serta keinginan untuk meninggalkan arsitektur monolitik dan pindah ke layanan-layanan mikro yang mudah untuk diukur tergantung pada jumlah pengguna dan ukuran tim teknik. Bagian pengguna layanan streaming pindah ke AWS pertama, antara 2010 dan 2011, diikuti oleh IT perusahaan dan semua struktur lainnya. Pusat data Netflix sendiri ditutup pada tahun 2016. Perusahaan mengukur aksesibilitas sebagai rasio dari jumlah upaya yang berhasil untuk meluncurkan film dengan jumlah total, dan bukan sebagai perbandingan sederhana antara waktu aktif dan waktu henti, dan mencoba untuk mencapai angka 0,9999 di setiap wilayah secara triwulanan (seringkali berhasil). Arsitektur global Netflix mencakup tiga wilayah AWS. Dengan demikian, jika terjadi masalah di salah satu daerah, perusahaan memiliki kemampuan untuk mengarahkan pengguna ke yang lain.
Saya ulangi salah satu kutipan favorit saya:
“Kegagalan tidak bisa dihindari; pada akhirnya, sistem apa pun akan macet seiring waktu. ” - Werner Vogels
Bahkan, kegagalan dalam sistem terdistribusi, terutama yang berskala besar, tidak dapat dihindari bahkan di cloud. Namun, cloud AWS dan primitif redundansi - khususnya,
prinsip beberapa zona akses tempat ia dibangun - memungkinkan siapa pun untuk merancang layanan yang sangat andal.
Menggunakan prinsip redundansi dan
degradasi yang anggun , Netflix
berhasil selamat dari kegagalan tanpa mempengaruhi pengguna akhir.
Sejak awal, Netflix telah menganut prinsip arsitektur yang paling ketat. Salah satu aplikasi pertama yang mereka sebarkan ke AWS adalah
Chaos Monkey - untuk mendukung layanan mikro kewarganegaraan autoscale. Dengan kata lain, setiap instance dapat dihentikan dan secara otomatis diganti tanpa kehilangan status. Chaos Monkey memastikan bahwa tidak ada yang melanggar prinsip ini.
Catatan perev. : Ngomong-ngomong, untuk Kubernetes ada analog yang disebut kube-monyet , yang pengembangannya tampaknya telah berhenti pada bulan Maret tahun ini.Netflix memiliki satu aturan lagi, yang menyediakan distribusi setiap layanan dalam tiga zona ketersediaan. Ini harus terus berfungsi jika hanya dua yang tersedia. Untuk memastikan aturan ini dipenuhi,
Chaos Gorilla menonaktifkan zona ketersediaan. Lebih global lagi,
Chaos Kong dapat menonaktifkan seluruh wilayah AWS untuk mengonfirmasi bahwa semua pengguna Netflix dapat dilayani dari salah satu dari tiga wilayah. Dan mereka melakukan tes skala besar ini setiap beberapa minggu dalam produksi untuk memastikan tidak ada yang luput dari perhatian.
Akhirnya, Netflix juga mengembangkan
alat Chaos Testing yang lebih fokus untuk membantu mendeteksi masalah dengan layanan microservice dan arsitektur penyimpanan. Anda dapat mempelajari lebih lanjut tentang teknik-teknik ini dari buku Chaos Engineering, yang saya rekomendasikan kepada siapa pun yang tertarik dengan topik ini.
"Dengan melakukan eksperimen secara teratur yang meniru pemadaman regional, kami dapat mengidentifikasi berbagai kelemahan sistemik dan menghilangkannya pada tahap awal." - Netflix Blog
Saat ini, prinsip-prinsip rekayasa kekacauan
diformalkan ; mereka diberi definisi berikut:
"Rekayasa kekacauan adalah pendekatan yang melibatkan melakukan percobaan pada sistem produksi untuk memastikan kemampuannya menahan berbagai gangguan yang terjadi selama operasi." - principofchaos.org
Namun, dalam sebuah
pidato di AWS re: Invent 2018 tentang rekayasa chaos,
Adrian Cockcroft , mantan pencipta arsitektur cloud Netflix, yang membantu perusahaan beralih sepenuhnya ke infrastruktur cloud, memperkenalkan definisi alternatif rekayasa chaos. Menurut pendapat saya, ini lebih akurat dan mapan:
"Rekayasa kekacauan adalah eksperimen yang dirancang untuk mengurangi konsekuensi dari kegagalan."
Faktanya, kita tahu bahwa crash selalu terjadi. Dengan respons yang tepat, mereka seharusnya tidak memengaruhi pengguna akhir. Tujuan utama dari chaos engineering adalah untuk mendeteksi masalah yang tidak terselesaikan dengan baik.
Prasyarat untuk menciptakan kekacauan
Sebelum memulai rekayasa kekacauan, pastikan untuk melakukan semua pekerjaan yang diperlukan untuk memastikan keberlanjutan di semua tingkatan organisasi. Menciptakan sistem yang toleran terhadap kesalahan bukan hanya tentang perangkat lunak. Itu dimulai pada tingkat
infrastruktur , meluas ke
jaringan dan data , mempengaruhi struktur
aplikasi , dan akhirnya merangkul
orang dan budaya . Di masa lalu, saya banyak menulis tentang model stabilitas dan kegagalan (di
sini , di
sini , di
sini dan di
sini ) dan saya tidak akan fokus pada hal ini sekarang, tetapi saya tidak dapat melakukannya tanpa sedikit pengingat.
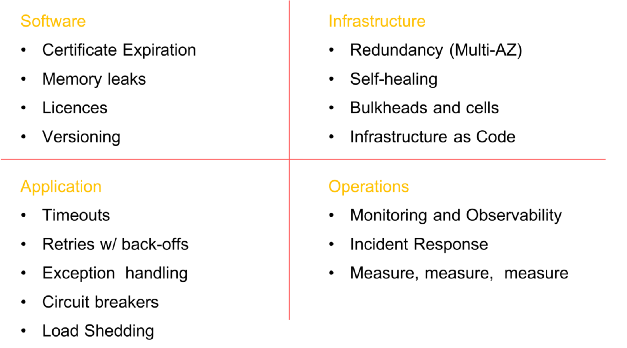 Beberapa elemen wajib sebelum memasukkan kekacauan ke dalam sistem (daftar tidak lengkap)
Beberapa elemen wajib sebelum memasukkan kekacauan ke dalam sistem (daftar tidak lengkap)Tahapan Rekayasa Kekacauan
Penting untuk dipahami bahwa esensi rekayasa chaos adalah
BUKAN membiarkan monyet kehilangan dan membiarkan mereka menghancurkan segala sesuatu secara berurutan, tanpa tujuan apa pun. Inti dari disiplin ini adalah untuk menghancurkan beberapa elemen sistem dalam lingkungan yang terkontrol melalui eksperimen yang terencana dengan baik untuk memeriksa apakah aplikasi Anda dapat menahan kondisi yang bergejolak.
Untuk melakukan ini, Anda harus mengikuti proses formal yang didefinisikan dengan jelas seperti yang ditunjukkan pada gambar di bawah. Dengan itu, Anda dapat beralih dari memahami kondisi mantap sistem Anda ke merumuskan hipotesis, mengujinya, dan akhirnya, menganalisis pengalaman yang diperoleh selama percobaan dan meningkatkan stabilitas sistem itu sendiri.
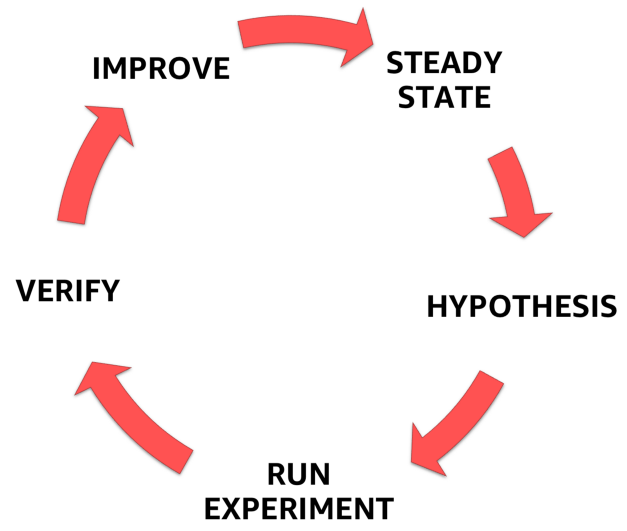 Tahapan Rekayasa Kekacauan
Tahapan Rekayasa Kekacauan1. Kondisi stabil
Salah satu elemen terpenting dari rekayasa kekacauan adalah memahami perilaku suatu sistem dalam kondisi normal.
Mengapa Sederhana: setelah pengenalan kegagalan artifisial, Anda harus memastikan bahwa sistem telah kembali ke kondisi stabil yang telah dipelajari dengan baik dan percobaan tidak lagi mengganggu perilaku normalnya.
Poin kunci di sini adalah bahwa Anda perlu fokus bukan pada atribut internal sistem (prosesor, memori, dll.), Tetapi untuk memantau sinyal output terukur yang menghubungkan kinerja dengan pengalaman pengguna. Agar sinyal output ini dalam keadaan stabil, perilaku yang diamati dari sistem harus memiliki pola yang dapat diprediksi, tetapi berubah secara signifikan ketika terjadi kegagalan fungsi dalam sistem.
Mengingat
definisi rekayasa kekacauan yang diusulkan di atas oleh Adrian Cockcroft, keadaan stabil ini berubah ketika kegagalan di luar kendali menyebabkan masalah yang tidak terduga dan menandakan bahwa eksperimen kekacauan harus dihentikan.
Sebagai contoh kondisi stabil, mari kita kutip pengalaman Amazon. Perusahaan menggunakan jumlah pesanan sebagai salah satu metrik kondisi stabil, dan untuk alasan yang baik. Pada tahun 2007, Greg Linden, yang sebelumnya bekerja di Amazon, berbicara tentang bagaimana, sebagai bagian dari percobaan menggunakan metode
pengujian A / B, ia mencoba memperlambat waktu pemuatan halaman di situs dalam peningkatan 100 ms dan menemukan bahwa bahkan sedikit keterlambatan hasil untuk penurunan serius dalam pendapatan. Dengan peningkatan waktu muat 100 ms, jumlah pesanan (dan karenanya penjualan) menurun sebesar 1%. Itulah sebabnya jumlah pesanan adalah kandidat yang sangat baik untuk metrik stabil.
Netflix menggunakan metrik sisi-server yang terkait dengan awal pemutaran - jumlah klik pada tombol putar. Mereka memperhatikan adanya keteraturan dalam perilaku indikator SPS (mulai per detik) dan fluktuasi yang signifikan jika terjadi kegagalan sistem. Metrik ini disebut "Pulse of Netflix" (
Pulse of Netflix ).
Jumlah pesanan dalam kasus Amazon dan Netflix Pulse adalah barometer stabilitas yang sangat baik, karena mereka menggabungkan pengalaman pengguna dan metrik operasional menjadi satu indikator, terukur dan sangat dapat diprediksi.
Ukur, ukur dan ukur lagi
Tak perlu dikatakan bahwa jika Anda tidak dapat merekam dengan baik kinerja sistem, maka Anda tidak akan dapat memantau perubahan dalam keadaan stabil (atau bahkan mendeteksinya). Perhatian khusus untuk menghapus semua parameter / indikator, dari jaringan, perangkat keras, dan diakhiri dengan aplikasi dan orang-orang. Gambarlah grafik dari pengukuran ini, bahkan jika mereka tidak berubah seiring waktu. Anda akan terkejut menemukan korelasi yang tidak Anda sadari.
"Buat semudah mungkin bagi insinyur untuk mengakses data yang dapat mereka hitung atau terjemahkan ke dalam bentuk grafis." - Ian Malpass
2. Hipotesis
Setelah berurusan dengan keadaan stabil, kita dapat melanjutkan untuk merumuskan hipotesis.

- Bagaimana jika mekanisme rekomendasi berhenti?
- Bagaimana jika penyeimbang beban jatuh?
- Bagaimana jika caching jatuh?
- Bagaimana jika penundaan meningkat 300 ms?
- Bagaimana jika basis induk crash?
Tentu saja, hanya satu hipotesis yang harus dipilih dan tidak perlu menyulitkannya. Mulai dari yang kecil. Saya suka memulai dengan hipotesis staf. Pernahkah Anda mendengar tentang
faktor bus ? Faktor bus adalah ukuran risiko yang terkait dengan fakta bahwa pengetahuan tidak didistribusikan secara merata di antara anggota tim. Hal ini memungkinkan Anda untuk menghitung jumlah minimum peserta, setelah kehilangan tiba-tiba dimana proyek akan berhenti karena kurangnya pengetahuan atau pengalaman.
Banyak perusahaan memiliki ahli teknis yang menghilang secara tiba-tiba (“ditabrak bus”) akan berdampak buruk pada proyek dan tim. Identifikasi orang-orang ini dan lakukan eksperimen kekacauan dengan partisipasi mereka: misalnya, ambil komputer dari mereka dan kirim pulang selama sehari, dan kemudian amati hasil (seringkali kacau).
Buat masalah umum untuk semua!
Libatkan
seluruh tim dalam mengembangkan hipotesis. Biarkan semua orang berpartisipasi dalam brainstorming: pemilik produk, manajer teknis, pengembang backend dan frontend, desainer, arsitek, dll. Setiap orang yang dengan satu atau lain cara terhubung dengan produk.
Pertama-tama, minta semua orang untuk menulis jawaban mereka sendiri untuk pertanyaan "Bagaimana jika ...?" di selembar kertas. Anda akan melihat bahwa dalam kebanyakan kasus semua orang akan memiliki jawaban mereka sendiri, dan Anda akan memahami bahwa beberapa bagian dari tim masih belum memikirkan masalah seperti itu sama sekali.
Berhentilah pada titik ini dan diskusikan mengapa anggota tim memiliki pandangan berbeda tentang perilaku produk dalam kasus "Bagaimana jika ...?". Kembali ke spesifikasinya dan pastikan bahwa semua orang dengan benar memahami kemungkinan perkembangan acara.
Ambil, misalnya, situs ritel Amazon yang disebutkan. Bagaimana jika layanan Toko oleh Kategori berhenti memuat di halaman utama?

Haruskah saya mengembalikan kesalahan 404? Apakah layak untuk memuat halaman, meninggalkan ruang kosong seperti pada tangkapan layar di bawah ini?

Apakah layak mengorbankan bagian dari fungsi dan, misalnya, membiarkan halaman meluas dan menyembunyikan kesalahan?
Dan ini hanya di sisi antarmuka pengguna. Apa yang harus terjadi di backend? Haruskah peringatan dikirimkan? Haruskah layanan yang gagal terus menerima permintaan setiap kali pengguna memuat halaman rumah, atau haruskah backend harus memotongnya sepenuhnya?
Dan yang terakhir. Tolong jangan merumuskan hipotesis, yang diketahui sebelumnya bahwa itu akan mematahkan kayu bakar! Percobaan dengan bagian-bagian dari sistem yang, menurut Anda, stabil - pada akhirnya, ini adalah inti dari seluruh percobaan.3. Desain dan jalankan percobaan
- Pilih satu hipotesis;
- Tentukan ruang lingkup percobaan;
- Tetapkan indikator terkait yang akan diukur;
- Beri tahu organisasi.
Saat ini, banyak orang, serta situs web
principofchaos , mempromosikan gagasan rekayasa kekacauan dalam produksi. Meskipun ini harus menjadi tujuan akhir, sebagian besar organisasi takut akan pendekatan ini, jadi Anda tidak boleh memulainya.
Bagi saya, chaos engineering tidak hanya penghancuran berbagai elemen sistem produksi. Ini sebuah perjalanan. Sebuah perjalanan ke dunia pengetahuan, terkait erat dengan kegiatan seperti penghancuran sistem dalam lingkungan yang terkendali - lingkungan apa pun, apakah itu lingkungan pengembang lokal, beta, pementasan atau prod. Penghancuran melalui percobaan yang dirancang dengan baik untuk membangun kepercayaan pada kemampuan aplikasi Anda untuk mentolerir kondisi yang bergejolak. "
Membangun kepercayaan diri " adalah poin kunci dalam kasus ini, karena ini merupakan pendahulu dari perubahan budaya yang diperlukan untuk keberhasilan penerapan rekayasa kekacauan dan praktik meningkatkan keandalan di perusahaan Anda.
Jujur, sebagian besar tim akan belajar banyak dengan memecahkan banyak hal bahkan dalam lingkungan non-produksi. Cobalah untuk membuat
docker stop database di lingkungan lokal Anda dan lihat apakah Anda dapat menangani masalah ini tanpa konsekuensi. Peluang tinggi yang tidak.
Berhenti Database - ContohMulai dari yang kecil dan secara bertahap membangun kepercayaan dalam tim dan organisasi Anda. Anda akan diberitahu bahwa "lalu lintas produksi nyata adalah satu-satunya cara untuk menangkap perilaku sistem dengan andal." Dengarkan, tersenyumlah, dan terus lakukan apa yang Anda lakukan secara perlahan. Hal terburuk yang dapat Anda lakukan adalah menerapkan teknik chaos pada produksi dan gagal total. Setelah itu, tidak ada yang akan mempercayai Anda, dan Anda akan dipaksa untuk melupakan "monyet kekacauan" selamanya.
Dapatkan kredibilitas terlebih dahulu. Tunjukkan kepada organisasi dan kolega bahwa Anda tahu apa yang Anda lakukan. Menjadi petugas pemadam kebakaran dan belajar tentang nyala api sebanyak mungkin sebelum melanjutkan ke pelatihan dengan tembakan langsung. Hasilkan kredibilitas. Ingat
cerita tentang kura-kura dan kelinci ? Perlombaan selalu dimenangkan oleh yang lambat dan sabar.
Salah satu poin paling penting selama percobaan adalah memahami potensi
radius kerusakan dari malfungsi yang Anda perkenalkan dan meminimalkannya. Tanyakan kepada diri Anda pertanyaan-pertanyaan berikut:
- Berapa banyak pelanggan yang akan terpengaruh oleh percobaan?
- Fungsi apa yang akan menderita?
- Tempat apa yang akan terpengaruh?
Pikirkan "tombol berhenti darurat" atau cara untuk segera menghentikan percobaan dan kembali ke kondisi stabil sesegera mungkin. Saya suka melakukan eksperimen menggunakan apa yang disebut. Peluncuran "Canary". Teknik ini mengurangi risiko kegagalan ketika meluncurkan versi baru aplikasi dalam produksi dengan secara bertahap meluncurkan perubahan ke subset kecil pengguna dan kemudian perlahan-lahan menyebarkannya di seluruh infrastruktur dan semua pengguna. Saya suka peluncuran kenari hanya karena mereka memenuhi prinsip
infrastruktur tetap , dan eksperimen itu sendiri cukup mudah dihentikan.
 Contoh peluncuran canary berbasis DNS untuk eksperimen chaos
Contoh peluncuran canary berbasis DNS untuk eksperimen chaosHati-hati dengan eksperimen yang mengubah status aplikasi (cache atau database) atau yang tidak dapat dibatalkan (dengan mudah atau pada prinsipnya).
Sangat mengherankan bahwa Adrian Cockcroft mengatakan kepada saya bahwa salah satu alasan Netflix mulai menggunakan database NoSQL adalah kurangnya skema untuk perubahan atau kembalikan di dalamnya, sehingga jauh lebih mudah untuk secara bertahap memperbarui atau memperbaiki catatan individual dengan data (mis. Mereka lebih ramah terhadap rekayasa kekacauan).
4. Amati dan pelajari
Untuk mempelajari sesuatu yang baru dan memantau kemajuan percobaan, Anda harus dapat melacak kinerja sistem. Seperti yang disebutkan sebelumnya, perhatikan semua jenis metrik dan parameter! Kemudian kuantifikasi hasilnya dan selalu - selalu! - Catat waktu sampai tanda-tanda awal masalah muncul. Dalam sejarah saya, telah berulang kali terjadi bahwa sistem peringatan menolak dan yang pertama melaporkan masalah tersebut kepada pelanggan di Twitter ... percayalah, Anda tidak akan ingin berada dalam situasi ini, jadi gunakan percobaan kekacauan untuk memeriksa sistem pemantauan dan peringatan Anda.
- Waktunya menemukan?
- Waktu untuk mengingatkan dan memulai tindakan aktif?
- Waktunya untuk pemberitahuan publik?
- Saatnya kehilangan sebagian fungsi?
- Lamanya periode penyembuhan diri?
- Waktu untuk pemulihan penuh atau sebagian?
- Saatnya untuk mengakhiri krisis dan kembali ke keadaan stabil?
Ingatlah bahwa tidak ada satu pun penyebab kegagalan yang terisolasi. Kecelakaan besar selalu merupakan hasil dari beberapa kegagalan kecil yang menumpuk dan menyebabkan krisis skala besar.
Lakukan analisis postmortem terperinci untuk setiap percobaan!Di AWS, kami memberikan perhatian besar untuk menganalisis kegagalan yang terdeteksi dan memahami penyebab yang menyebabkan mereka mencegah masalah serupa di masa mendatang. Semua kesimpulan dan hasil percobaan dirangkum dalam dokumen yang disebut Koreksi-Kesalahan (COE). COE memungkinkan kita untuk belajar dari kesalahan kita, apakah cacat dalam teknologi, proses atau bahkan organisasi. Kami menggunakan mekanisme ini untuk menghilangkan akar penyebab kerusakan dan pengembangan berkelanjutan.
Kunci keberhasilan dalam proses ini adalah keterbukaan dan transparansi mengenai apa yang salah. Salah satu prinsip terpenting ketika menulis COE yang baik adalah bersikap tidak memihak dan menghindari menyebut orang tertentu. Ini seringkali sulit di lingkungan yang tidak mendorong perilaku seperti itu dan tidak memungkinkan untuk gagal. Amazon menggunakan kumpulan
Prinsip Kepemimpinan untuk mempromosikan perilaku ini - misalnya,
kritik sendiri, pendekatan analitik, komitmen terhadap standar tertinggi, dan tanggung jawab adalah komponen kunci dari proses COE dan keunggulan operasional secara umum.
Laporan COE memiliki lima bagian utama:
- Apa yang terjadi (urutan kronologis)?
- Apa dampaknya bagi pelanggan?
- Mengapa kesalahan itu terjadi? ( Lima "mengapa?" )
- Apa yang kami pelajari?
- Bagaimana cara mencegahnya di masa depan?
Lebih sulit untuk menjawab pertanyaan-pertanyaan ini daripada yang terlihat pada pandangan pertama, karena Anda perlu memastikan bahwa setiap momen yang tidak dapat dipahami / tidak diketahui dipelajari dengan cermat.
Untuk mengubah mekanisme COE menjadi proses penuh, kami terus melakukan pemeriksaan dalam bentuk pertemuan mingguan dengan analisis wajib metrik operasional. Selain itu, para pakar teknis terkemuka melakukan tinjauan metrik mingguan dengan semua staf AWS.
5. Perbaiki dan tingkatkan!
Pelajaran utama di sini adalah
, pertama-tama, untuk menghilangkan masalah yang diidentifikasi selama percobaan kekacauan, menugaskan mereka prioritas yang lebih tinggi daripada pengembangan fungsi baru . Libatkan manajemen puncak dalam proses ini dan perkenalkan kepadanya gagasan bahwa memperbaiki masalah saat ini jauh lebih penting daripada mengembangkan fungsionalitas baru.
Suatu kali, dengan bantuan percobaan kekacauan, saya membantu klien mengidentifikasi masalah stabilitas kritis, tetapi karena tekanan dari departemen penjualan, prioritas perbaikan diperbaiki dan semua upaya diarahkan untuk memperkenalkan hal baru yang “sangat penting” bagi pelanggan. Dua minggu kemudian, downtime 16 jam memaksa perusahaan untuk mengatasi masalah yang sama yang kami identifikasi selama eksperimen kekacauan. Hanya kerugiannya jauh lebih tinggi.
Manfaat rekayasa kekacauan
Ada banyak keuntungan. Saya akan menyoroti dua, menurut saya, yang paling penting:
Pertama, chaos engineering membantu memecahkan masalah yang tidak diketahui dalam sistem dan memperbaikinya sebelum menyebabkan kegagalan produksi, misalnya, pada jam 3 pagi pada hari Minggu. Artinya, itu
meningkatkan resistensi terhadap kecelakaan dan, pada kenyataannya, kualitas tidur .
Kedua, eksperimen kekacauan yang dilakukan secara efisien selalu menyebabkan perubahan yang lebih luas (terutama budaya) daripada yang diantisipasi. Mungkin yang paling penting dari ini adalah evolusi alami ke
budaya " tidak menyalahkan" , ketika pertanyaan "Mengapa Anda melakukan ini?" berubah menjadi "Bagaimana kita bisa menghindari ini di masa depan?". Hasilnya, tim menjadi lebih bahagia, lebih efisien, lebih tertarik dan sukses.
Dan ini luar biasa!Pada bagian ini, bagian pertama berakhir. Saya harap Anda menikmatinya. Harap tulis ulasan, bagikan pendapat, atau tepuk tangan Anda di
Medium . Pada bagian selanjutnya, saya akan melihat alat dan teknik untuk memperkenalkan kegagalan sistem. Sampai - sampai jumpa!
Bagi mereka yang ingin berkenalan dengan bagian kedua, saya menawarkan presentasi saya tentang topik chaos engineering di NDC di Oslo. Di dalamnya, saya berbicara tentang banyak alat favorit saya:
PS dari penerjemah
Bagian kedua artikel dalam bahasa Inggris telah muncul dan kami juga akan menerjemahkannya jika kami melihat minat yang cukup dari para pembaca Habré terhadap materi ini - komentar yang relevan pada artikel tersebut disambut baik! DIPERBARUI (3 September): Terjemahan dari bagian kedua juga
diterbitkan .
DIPERBARUI (19 Desember):
Terjemahan bagian ketiga telah tersedia.
Baca juga di blog kami: