Di sekolah, saya punya teman sekelas yang bisa mendengarkan bagaimana mobil itu bekerja di halaman, dan dengan wajah serius membuat keputusan: semuanya beres, atau ada yang rusak, dan saya sangat perlu berlari untuk mencari suku cadang baru / oli / alat! Saya, seperti teko mutlak dalam bisnis otomotif, selalu mendengar deringan dvenashka berikutnya, tidak memperhatikan adanya perbedaan dan hanya diam-diam mengagumi pendengaran dan keterampilannya.
Sekarang saya tidak lebih memahami bagian dalam mobil, tetapi saya mulai bekerja dengan memproses sinyal suara dan pembelajaran mesin, dan di sini kita akan mencoba memahami apakah mungkin untuk mengajar komputer untuk menangkap ketidaknormalan dalam suara mesin?
Minimal, itu hanya menarik untuk diperiksa, dan di masa depan, teknologi seperti itu bisa menghemat banyak uang bagi pemilik mobil. Setidaknya menurut saya, kegagalan kritis terjadi secara bertahap di bawah tenda, dan pada tahap awal, banyak dari mereka dapat didengar, dengan cepat dan murah diperbaiki, menghemat waktu, uang, dan saraf yang sudah goyah.
Yah, mungkin sudah waktunya untuk beralih dari kata-kata ke perbuatan. Ayo pergi!
Saya ingin segera mengatakan bahwa dalam segala hal yang berkaitan dengan matematika dan algoritma, saya akan lebih menekankan pada makna dan pemahaman, tidak akan ada rumus dan perhitungan matematika di sini. Saya belum mengembangkan algoritma baru di sini, untuk rumus, jika Anda mau, lebih baik untuk google dan Wikipedia, serta menggunakan tautan yang akan saya tinggalkan di seluruh artikel.
Saya akan memberikan semua penjelasan tentang contoh suara mesin rusak yang diambil dari video ini di YouTube .
File yang diunduh dari YouTube (Anda dapat mengunduhnya menggunakan ekstensi browser atau hanya dengan mengubah tautan youtube ke ssyoutube) kami konversi ke format wav menggunakan ffmpeg:
ffmpeg -i input_video.mp4 -c:a pcm_s16le -ar 16000 -ac 1 engine_sound.wav
Sebelum mulai memproses file ini, saya akan mengatakan beberapa kata tentang apa itu spektogram dan bagaimana hal itu berguna bagi kami dalam menyelesaikan masalah ini. Banyak dari Anda, pasti, telah melihat gambar yang sama - ini adalah representasi amplitudo-temporal suara atau osilogram.
Jika secara sederhana, maka suara adalah gelombang, dan nilai amplitudo gelombang ini diamati pada osilogram pada waktu tertentu.
Untuk mendapatkan spektogram dari representasi semacam itu, kita membutuhkan transformasi Fourier. Dengan bantuannya, Anda bisa mendapatkan representasi frekuensi amplitudo suara atau spektrum amplitudo. Spektrum seperti itu menunjukkan frekuensi apa dan dengan amplitudo apa sinyal yang diteliti diekspresikan.
Faktanya, spektrogram adalah seperangkat spektrum potongan sinyal pendek berurutan. Mungkin "definisi" seperti itu akan cukup bagi kita untuk tidak terlalu terganggu oleh tugas. Semuanya akan menjadi lebih jelas jika Anda melihat visualisasi spektrogram (gambar diperoleh menggunakan WaveAssistant ). Waktu diplot pada sumbu X, frekuensi pada sumbu Y, yaitu, setiap kolom dalam matriks ini adalah modulus spektrum pada titik waktu tertentu.
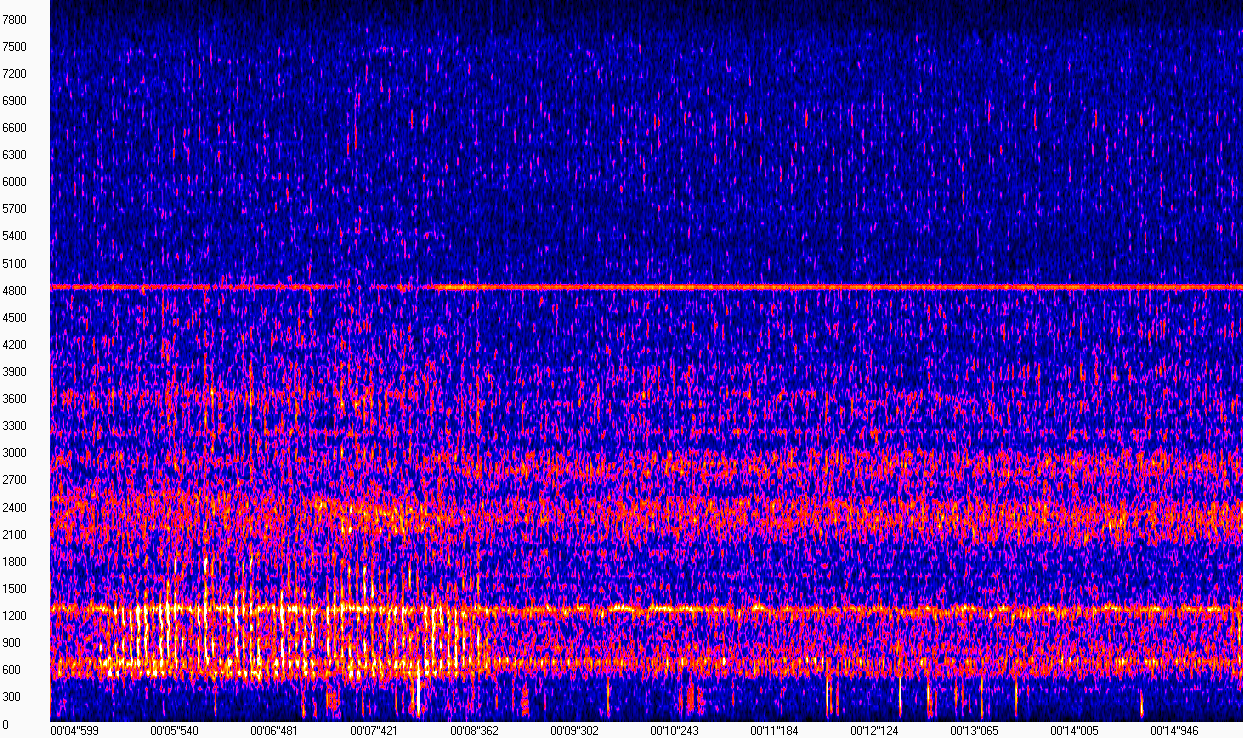
Spektrogram ini menunjukkan bahwa suara mesin tanpa ketukan "terlihat" hampir sama, dan diekspresikan pada frekuensi di sekitar 600, 1200, 2400 dan 4800 Hz. Suara ketukan yang mengganggu pemilik sangat berbeda dalam rentang frekuensi 600-1200 Hz dari 5 hingga 8 detik. Karena rekaman dibuat dalam kondisi yang agak bising di jalan, suara-suara ini juga hadir di spektrogram, yang agak menyulitkan tugas kami.
Namun demikian, melihat spektogram semacam itu, kita dapat dengan yakin mengatakan di mana ketukan itu dan di mana tidak. Komputer tidak memiliki mata, oleh karena itu, kita perlu memilih algoritma yang akan dapat membedakan antara penyimpangan tersebut (dan lebih disukai tidak hanya itu), tergantung pada adanya suara dalam rekaman.
Spektrogram dapat dihitung menggunakan perpustakaan librosa sebagai berikut:
from librosa.util import buf_to_float from librosa.core import stft
Solusi
Sebenarnya, kita perlu memecahkan masalah klasifikasi biner, di mana kita perlu menentukan apakah mesin rusak atau beroperasi secara normal. Kolega saya dan saya telah menggambarkan tugas serupa di artikel kami sebelumnya , di mana kami menggunakan jaringan saraf convolutional untuk mengklasifikasikan acara akustik. Di sini, solusi seperti itu hampir tidak mungkin: neuron sangat suka ketika mereka diberikan dataset besar. Kami berhadapan dengan satu indentasi yang berlangsung lebih dari satu menit, yang jelas tidak bisa disebut dataset besar.
Pilihan dihentikan pada Gaussian Mixture Model (model campuran Gaussian). Artikel bagus yang merinci prinsip operasi dan pelatihan model ini dapat ditemukan di sini. Gagasan umum model ini adalah untuk menggambarkan data menggunakan distribusi kompleks dalam bentuk kombinasi linear dari beberapa distribusi normal multidimensi (lebih lanjut tentang distribusi normal multidimensi di sini ).
Karena mesin selama operasinya terdengar kira-kira "sama", suara operasinya dapat dianggap diam, dan ide untuk menggambarkan suara ini menggunakan distribusi semacam itu tampaknya cukup bermakna. Untuk memahami esensi GMM, saya sangat merekomendasikan melihat contoh pelatihan dan memilih jumlah gaussoid di sini .
Kasus kami berbeda dari contoh di atas bahwa alih-alih titik pada bidang dua dimensi, nilai spektrum yang diambil dari spektogram sinyal akan digunakan. Anda dapat memilih parameter distribusi, seperti jenis matriks kovarians menggunakan kriteria BIC ( contoh , deskripsi ), namun, dalam kasus saya, parameter optimal dari sudut pandang kriteria ini menunjukkan diri mereka lebih buruk daripada yang ditunjukkan dalam kode di bawah ini:
from sklearn.mixture import GaussianMixture n_components = 3 gmm_clf = GaussianMixture(n_components) gmm_clf.fit(X_train)
Dengan asumsi bahwa suara operasi normal dijelaskan oleh distribusi, parameter yang dipilih selama proses pelatihan, dimungkinkan untuk mengukur seberapa dekat suara apa pun dengan distribusi ini.
Untuk melakukan ini, Anda dapat menghitung kemungkinan rata-rata kolom-kolom dari spektogram sinyal yang diteliti, dan kemudian memilih ambang yang akan memisahkan kemungkinan suara-suara dari pekerjaan yang baik dari yang lainnya. Kredibilitas untuk setiap detik adalah sebagai berikut:
n_seconds = len(full_wav_data) // sr gmm_scores = []
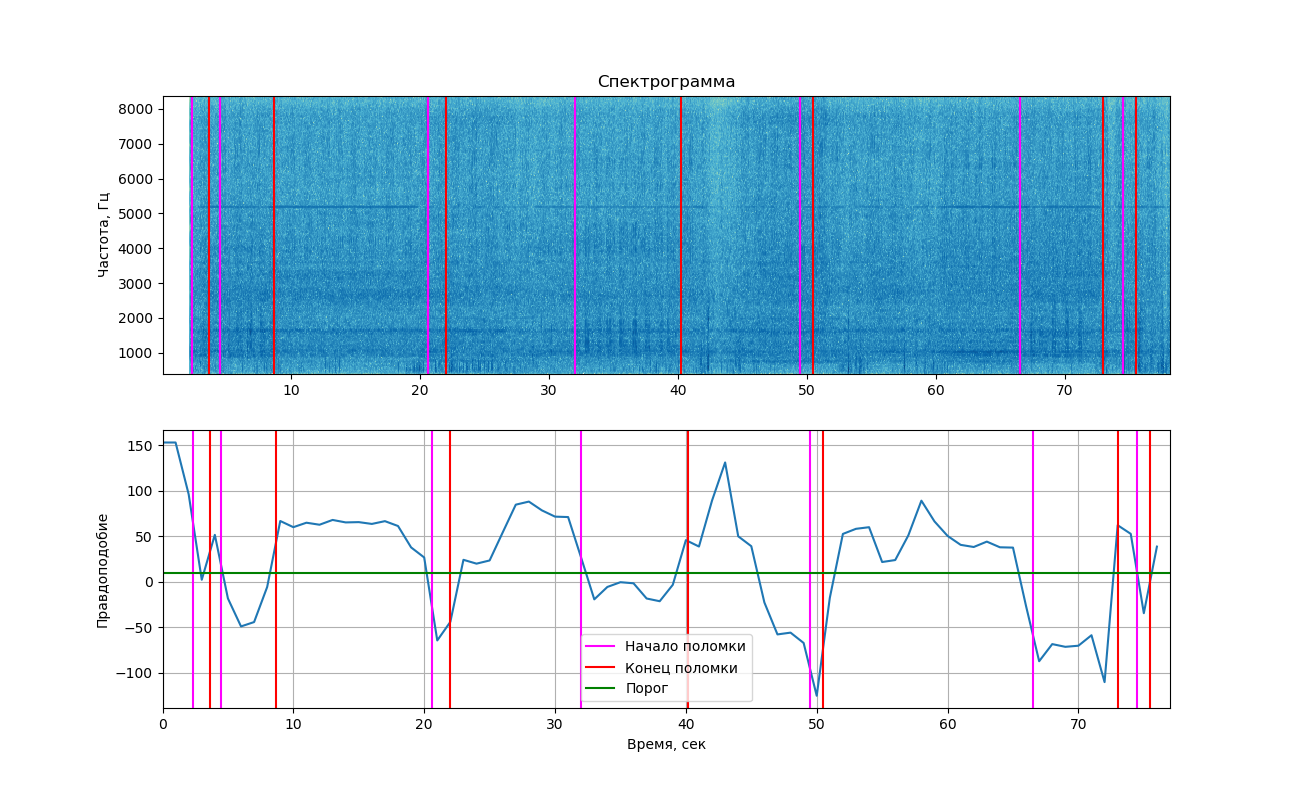
Jika Anda menampilkan kemungkinan yang diperoleh pada grafik, kami mendapatkan gambar berikut.
Bagian atas menunjukkan spektrogram dari sinyal yang ditampilkan menggunakan perpustakaan matplotlib. Perubahan yang disebabkan oleh ketukan tidak terlihat sama seperti pada contoh di atas (itulah sebabnya Anda melihat 2 gambar di sini). Meskipun demikian, jika Anda melihat lebih dekat, mereka masih bisa dilihat. Garis vertikal menandai waktu mulai dan berakhirnya ketukan.
Kesimpulan
Seperti yang dapat Anda lihat dari grafik, pada saat bunyi ketukan, kemungkinannya benar-benar turun di bawah ambang batas, yang berarti kita dapat memisahkan dua kelas ini (bekerja dengan dan tanpa mengetuk). Tetapi saya harus mengatakan bahwa nilai ini cukup dekat dengan ambang pintu dan di area di mana ketukan tidak terdengar. Ini karena noise asing sering ditemukan dalam rekaman, yang juga memengaruhi kemungkinan.
Kami menambahkan pelatihan di sini hanya dalam beberapa detik suara, kondisi perekaman buruk, dan Anda sudah dapat terkejut sama sekali bahwa percobaan itu entah bagaimana berhasil!
Kemungkinan besar, untuk menerapkan metode ini dan memastikan keandalannya, Anda harus merekam lebih banyak suara, dan juga menempatkan mikrofon dengan baik untuk meminimalkan kebisingan dari memasuki rekaman.
Artikel ini hanyalah upaya untuk memecahkan masalah yang sama, tidak mengklaim kebenaran mutlak, jika Anda memiliki ide dan saran, atau mungkin pertanyaan, mari kita bahas bersama-sama dalam komentar atau secara langsung.
Kode github lengkap ada di sini