Kami ingin memperkenalkan alat baru kami untuk tokenisasi teks - YouTokenToMe. Ini bekerja 7-10 kali lebih cepat daripada versi populer lainnya dalam bahasa yang mirip strukturnya dengan Eropa, dan 40-50 kali - dalam bahasa Asia. Kami berbicara tentang YouTokenToMe dan membagikannya dengan Anda di sumber terbuka di GitHub. Tautkan di akhir artikel!

Saat ini, sebagian besar tugas untuk algoritma jaringan saraf adalah pengolah kata. Tetapi, karena jaringan saraf bekerja dengan angka, teks perlu dikonversi sebelum dipindahkan ke model.
Kami mencantumkan solusi populer yang biasanya digunakan untuk ini:
- ruang istirahat
- algoritma berbasis aturan: spaCy, NLTK;
- stemming, lemmatization.
Masing-masing dari mereka memiliki kelemahannya sendiri:
- Anda tidak dapat mengontrol ukuran kamus token. Ukuran lapisan embedding dalam model secara langsung tergantung pada ini;
- informasi tentang kekerabatan kata yang berbeda dengan sufiks atau awalan tidak digunakan, misalnya: sopan - tidak sopan;
- tergantung pada bahasa.
Baru-baru ini, pendekatan
Encoding Pasangan Byte telah populer. Awalnya, algoritma ini dimaksudkan untuk kompresi teks, tetapi beberapa tahun yang lalu digunakan untuk menandai teks dalam terjemahan mesin. Sekarang ini digunakan untuk berbagai tugas, termasuk yang digunakan dalam model BERT dan GPT-2.
Implementasi BPE yang paling efektif adalah
SentencePiece , yang dikembangkan oleh para insinyur Google, dan
fastBPE , yang dibuat oleh Facebook AI Research. Tetapi kami berhasil membuktikan bahwa tokenization dapat dipercepat secara signifikan. Kami mengoptimalkan algoritma BPE dan menerbitkan kode sumber, dan juga memposting paket yang sudah selesai dalam repositori pip.
Di bawah ini Anda dapat membandingkan hasil pengukuran kecepatan algoritma kami dan versi lainnya. Sebagai contoh, kami mengambil 100 MB pertama
dari korpus data Wikipedia dalam bahasa Rusia, Inggris, Jepang, dan Cina.
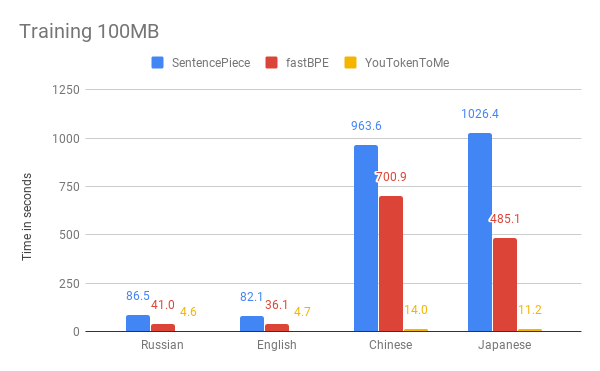

Grafik menunjukkan bahwa waktu operasi sangat tergantung pada bahasa. Ini karena bahasa Asia memiliki lebih banyak huruf, dan kata-kata tidak dipisahkan oleh spasi. YouTokenToMe bekerja 7-10 kali lebih cepat dalam bahasa yang mirip strukturnya dengan Eropa, dan 40-50 kali dalam bahasa Asia. Tokenisasi dipercepat setidaknya dua kali, dan dalam beberapa tes lebih dari sepuluh kali.
Kami mencapai hasil ini berkat dua ide utama:
- algoritma baru memiliki runtime linier tergantung pada ukuran kasing untuk pelatihan. SentencePiece dan fastBPE memiliki perilaku asimptotik yang kurang efektif;
- algoritma baru ini dapat secara efektif menggunakan beberapa aliran baik dalam proses pembelajaran dan dalam proses tokenization - ini memungkinkan Anda untuk mendapatkan akselerasi beberapa kali lebih banyak.
Anda dapat menggunakan YouTokenToMe melalui antarmuka untuk bekerja dari baris perintah dan langsung dari Python.
Anda dapat menemukan informasi lebih lanjut di repositori:
github.com/vkcom/YouTokenToMe