
Solusi dari masalah pengenalan gambar (OCR) penuh dengan berbagai kesulitan. Gambar itu tidak dapat dikenali karena skema warna yang tidak standar atau karena distorsi. Bahwa pelanggan ingin mengenali semua gambar tanpa batasan, dan ini masih jauh dari mungkin. Masalahnya berbeda, dan tidak selalu mungkin untuk segera menyelesaikannya. Dalam posting ini, kami akan memberikan beberapa tips berguna berdasarkan pengalaman menyelesaikan situasi nyata dengan pelanggan.
Tapi pertama-tama, sedikit sejarah. Banyak waktu telah berlalu sejak publikasi artikel tentang
bagaimana kami menulis ulang layanan penyaringan . Di dalamnya, kami berbicara sedikit tentang pemfilteran dan pemrosesan pesan, tentang bagaimana layanan pemfilteran kami secara keseluruhan diatur. Kali ini kami akan mencoba menjawab pertanyaan "Bagaimana kami memproses gambar, bagaimana layanan berinteraksi, dan apa yang terjadi pada sistem yang sedang dimuat?" Jika kami beroperasi pada artikel tentang layanan penyaringan, maka sekarang kami akan mempertimbangkan hanya satu cabang interaksi layanan - ini adalah interaksi dari layanan penyaringan dan OCR.
Apa itu OCR?
Sebelum berbicara tentang interaksi layanan dan masalah menggunakan OCR, mari kita coba untuk memahami apa itu OCR. Ambil definisi yang
rumit dari Wikipedia.
Pengenalan karakter
optis (OCR) - terjemahan mekanis atau elektronik dari gambar teks tulisan tangan, diketik atau diketik ke dalam data teks yang digunakan untuk mewakili karakter di komputer (misalnya, dalam editor teks).
Sederhananya, mereka mengambil foto, mengirimkannya untuk dikenali, lalu
sihir itu di luar Hogwarts dan menerima teks.

Anda juga dapat mengambil definisi OCR dari situs ABBYY, yang terlihat lebih sederhana.
Optical Character Recognition (OCR) adalah teknologi yang memungkinkan Anda mengonversi berbagai jenis dokumen, seperti dokumen yang dipindai, file PDF atau foto dari kamera digital, ke dalam format yang dapat diedit yang dapat dicari.
Dan mengapa kita perlu (pengenalan gambar)?
Kita dapat menggunakan pengenalan gambar bahkan pada PC rumahan untuk mengubah gambar digital menjadi data teks yang dapat diedit.Tetapi tugas di depan kita jauh lebih luas (sistem DLP): kita perlu mengendalikan aliran informasi dalam organisasi.
Sistem DLP telah lama muncul di pasar dan sekarang menjadi bagian dari sistem keamanan informasi perusahaan (alat perlindungan informasi). DLP dihadapkan dengan tugas mengendalikan pergerakan informasi grafis (dokumen yang dipindai, tangkapan layar, foto). Dan tidak hanya mengontrol pergerakan file grafik, tetapi, pertama-tama, analisis isinya. Sistem harus dapat memahami dengan tepat informasi apa yang dihadapinya, membandingkannya dengan sampel informasi yang dilindungi dan memberikan peluang bagi pengguna untuk mencari informasi ini lebih lanjut. Penggunaan alat analisis lain, seperti perbandingan dengan sidik jari digital, perhitungan hash, analisis berdasarkan format file, ukuran dan struktur, juga merupakan sumber informasi yang berharga, tetapi mereka tidak memungkinkan menjawab pertanyaan: "teks apa yang dikirimkan dalam gambar ini?" Sementara itu, teks masih merupakan pembawa informasi terstruktur yang paling umum, termasuk dalam file grafik.
Secara tradisional, teknologi OCR digunakan untuk mengenali informasi grafis (apa yang telah kami tentukan). Bahkan, OCR umumnya satu-satunya kelas teknologi yang memberikan kemampuan untuk mengekstrak informasi teks dari gambar. Oleh karena itu, ini bukan tentang pendekatan tradisional, tetapi lebih pada kurangnya pilihan.
Berapa banyak gambar yang diproses per sistem DLP?
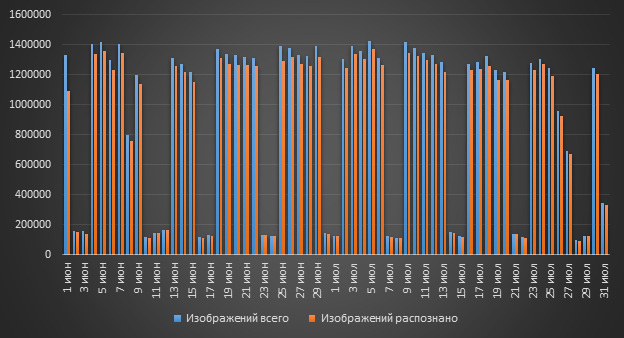
Tidak bisakah Anda melakukannya tanpa OCR? Apakah ada begitu banyak gambar di DLP sehingga Anda perlu menerapkan OCR? Jawaban untuk pertanyaan ini adalah "Ya!". Lebih dari satu juta gambar dapat memasuki sistem per hari, dan semua gambar ini dapat berisi teks.
OCR sebagai bagian dari sistem DLP Rostelecom-Solar digunakan oleh perusahaan minyak dan gas dan lembaga pemerintah. Semua pelanggan menggunakan OCR untuk mendeteksi data sensitif dalam dokumen yang dipindai. Apa yang bisa dimasukkan dalam "jadwal" seperti itu? Ya apa saja. Ini dapat berupa pemindaian berbagai dokumen internal, misalnya, berisi PD. Atau informasi dari kategori rahasia dagang, chipboard (untuk penggunaan resmi), laporan keuangan, dll.
Bagaimana OCR mengenali gambar?
Prosesnya adalah sebagai berikut: DLP memotong pesan yang berisi gambar (pemindaian dokumen, foto, dll.), Menentukan bahwa gambar tersebut sebenarnya ada di dalam pesan, mengekstraknya dan mengirimkannya ke OCR untuk pengakuan. Pada output, DLP menerima informasi tentang konten gambar (dan pesan secara umum) dalam bentuk TEXT / PLAIN yang diekstraksi.
Jika kita berbicara tentang interaksi layanan langsung di sistem Solar Dozor kita, maka layanan penyaringan mengirim gambar (jika ada) dari pesan ke layanan ekstraksi teks gambar (OCR). Yang terakhir, setelah pengenalan selesai, mengirim teks yang diterima ke mailfilter. Ternyata sesuatu seperti juggling gambar dan teks.

Mari kita perhatikan mekanisme pengenalan lebih dalam dengan contoh teknologi OCR ABBYY, yang kita gunakan dalam DLP kita sendiri.
Mungkin masalah utama untuk OCR ketika mengenali teks adalah ejaan karakter. Jika kita mengambil huruf alfabet (misalnya, Rusia atau Inggris), maka untuk setiap huruf kita akan menemukan beberapa opsi ejaan. Mesin OCR mengatasi masalah ini dengan beberapa cara:
- Menemukan karakter berdasarkan pola. Misalnya, menggunakan berbagai font ejaan.
- Identifikasi tanda-tanda untuk menulis karakter.
Jika Anda memberikan contoh pekerjaan yang agak kasar, maka OCR memecah teks menjadi karakter yang sebelumnya diidentifikasi dalam gambar, dan memaksakannya pada template yang sudah jadi. Kemudian diperiksa apakah simbolnya terlihat seperti ejaan templat atau tidak. Ketika karakter diidentifikasi, itu dikonversi ke kode karakter dalam pengkodean yang digunakan. Sebagai hasil dari proses ini, simbol ditambahkan ke dalam kata-kata, kalimat ke dalam teks akhir.
Ada banyak artikel berbeda tentang pekerjaan OCR. Anda dapat membaca lebih lanjut tentang karya OCR, misalnya, di sini
https://sysblok.ru/knowhow/iz-pikselej-v-bukvy-kak-rabotaet-raspoznavanie-teksta/Bagaimana cara mempersiapkan OCR secara keseluruhan untuk pengakuan?
Kami telah menemukan bahwa lebih dari satu juta gambar dapat masuk ke DLP. Tetapi apakah semua gambar dari sejuta ini bermanfaat bagi kita?
Jawaban atas pertanyaan itu lebih dari jelas - tentu saja tidak. Tapi mengapa tidak semua gambar akan berguna bagi kita? Jawaban atas pertanyaan ini juga cukup transparan: banyak gambar dari tanda tangan di pesan “berjalan” di surat. Mungkin 90% pesan (jika tidak lebih) akan berisi logo perusahaan.
Gambar seperti itu terlalu kecil untuk dikenali, mungkin tidak ada teks sama sekali di dalamnya. Di sini kami dapat menyarankan (dan bahkan sangat merekomendasikan) untuk menetapkan batasan pada ukuran gambar yang dikenali. Dalam hal ini, batasan harus ditetapkan pada batas bawah dan batas atas. Kemungkinan mengirim file berat untuk diproses lebih rendah daripada untuk gambar dari tanda tangan, tetapi masih cukup tinggi.Perlu dicatat bahwa gambar digital sering memiliki cacat yang berbeda. DLP tidak akan selalu mendapatkan pemindaian dokumen dalam resolusi yang baik. Sebaliknya, pemindaian tidak akan selalu dalam kualitas terbaik dan dengan banyak cacat.
Misalnya, dalam foto digital, perspektifnya mungkin terdistorsi, mungkin berubah menjadi disorot atau dibalik, dan garis pemindaian mungkin melengkung. Distorsi semacam itu dapat mempersulit pengenalan. Oleh karena itu, mesin OCR dapat melakukan pra-proses gambar untuk mempersiapkan mereka untuk dikenali. Misalnya, gambar dapat diputar, dikonversi menjadi b / w, warna terbalik, dan kemiringan garis yang benar.
Semua ini dapat diatur dalam pengaturan OCR dan, sebagai hasilnya, alat ini dapat membantu meningkatkan pengenalan teks dalam gambar.Sebagai hasilnya, kami sampai pada prinsip dasar mempersiapkan OCR untuk pengakuan:
- Tentukan ukuran gambar yang akan kita kenali, baik dalam piksel dan dalam Mb.
- Aktifkan preprocessing gambar.
Untuk meningkatkan efisiensi OCR, Anda juga dapat menyimpan data yang dikenali agar tidak mengirim gambar yang sama beberapa kali untuk pengakuan.
Apa lagi yang harus Anda perhatikan ketika menyiapkan OCR, kami akan jelaskan di bawah ini pada contoh penggunaan teknologi ini dalam praktik pertempuran.
Tantangan apa yang mungkin terjadi ketika menggunakan OCR di DLP di bawah beban berat?
1. Batas terlalu luas pada ukuran gambar yang dikenaliMari kita mulai dengan apa yang telah kita sebutkan - dengan batasan.
Berdasarkan praktik kami, pelanggan sering menetapkan batas terlalu luas pada ukuran file gambar yang dikenali. Ya, agar OCR berfungsi dengan baik, Anda perlu membatasi ukuran gambar. Tetapi pelanggan berusaha untuk mengendalikan segalanya, percaya bahwa bahkan dalam gambar 100x100 piksel dan ukuran 5 KB, data yang berharga dapat bocor. Secara umum, tentu saja, 100x100 piksel dan 5 Kb juga merupakan batasan, tetapi ambang ini terlalu rendah.
Ekstrem lainnya adalah keinginan untuk mengenali file berat beberapa ratus MB. Jelas bahwa gambar seperti itu tidak akan merayapi melalui surat perusahaan karena batasan pada ukuran pesan yang dikirim. Tapi di sini di saluran intersepsi lain (misalnya, dari bola jaringan perusahaan) file-file yang berat berusaha untuk dikenali. Jika pelanggan ingin menambahkan gambar beresolusi tinggi dalam jumlah besar, maka untuk ini Anda harus memiliki kapasitas server yang sesuai. Sebagai hasilnya, dengan ambang lebar minimum dan maksimum yang sedemikian luas untuk ukuran file yang dikenali, beban prosesor yang tinggi dibuat pada server, yang memperlambat pengoperasian semua subsistem.
Apa yang bisa direkomendasikan di sini? Pertama-tama, analisis “jadwal” mana yang digunakan oleh perusahaan yang berisi data rahasia, lalu perkirakan batasan minimum dan maksimum yang masuk akal pada ukuran gambar yang dipantau. Kami biasanya menyarankan pelanggan memperbaiki batas resolusi gambar yang lebih rendah dari 200 piksel, idealnya dari 400 piksel (sepanjang sumbu X dan Y), dan ukuran file minimal 20 Kb, lebih baik lebih besar. Tidak masuk akal untuk mengirim gambar berat ke OCR - mereka hanya akan membebani server Anda dan bukan fakta bahwa mereka akan dikenali.2. Memfilter antrian dan meminta batas waktu pemrosesanBeban berlebih pada server, yang timbul karena alasan di atas, mengarah di sepanjang rantai untuk meningkatkan waktu pengenalan gambar dan pemrosesan permintaan secara umum. Akibatnya, antrian pesan untuk penyaringan mulai meningkat di sistem DLP. Selain itu, file grafik yang tidak dapat dikenali pada prinsipnya (file berat, kualitas buruk, dll.) Dapat tiba di modul OCR, menghasilkan batas waktu pemrosesan gambar. Jika ada banyak file yang tidak dikenal, dan sistem memiliki batas waktu pengenalan yang tinggi, layanan pemfilteran menunggu hingga batas waktu ini terjadi, dan baru kemudian dilanjutkan untuk memproses permintaan berikutnya. Seluruh proses pemrosesan bisa sangat terhambat.
Apa yang bisa kami sarankan? Jika ada antrian untuk memproses gambar grafik, Anda perlu melihat pengaturan OCR di sistem DLP dan mencoba mencari penyebab pengereman. Ini dapat terjadi, misalnya, karena masalah komunikasi antarproses pada server itu sendiri. Secara umum, masalah-masalah ini pantas dibahas secara terpisah. Beberapa perincian tentang masalah umum dapat ditemukan di artikel “Memperkenalkan Komunikasi Antar Proses di Linux” .Selain itu, poin penting saat mengatur OCR adalah mengatur batas waktu yang memadai untuk pengenalan gambar. Secara umum, 90 detik sudah cukup untuk gambar dikenali secara akurat. Jika tidak ada teks yang diekstraksi dari gambar dalam 90 detik, maka dapat diasumsikan bahwa OCR tidak mengenali gambar pada prinsipnya. Pada titik ini, masalah konfigurasi OCR juga dapat terjadi ketika mereka menetapkan batas waktu pengenalan tinggi dan dengan demikian berusaha untuk mengenali yang tidak dikenal.Apa lagi yang bisa menyebabkan waktu habis? Di sini kita kembali ke masalah konfigurasi sistem. Layanan penyaringan, seperti layanan OCR, beroperasi dengan utas yang memproses pesan dan gambar. Sistem mungkin tidak dikonfigurasikan dengan benar dalam hal jumlah penangan layanan penyaringan dan jumlah penangan OCR. Misalnya, layanan penyaringan akan memiliki banyak penangan utas, sementara OCR hanya memiliki satu penangan. Dalam situasi seperti itu, pada beberapa titik OCR mungkin tidak punya waktu untuk memproses semua permintaan pengakuan, dan dengan demikian waktu pemrosesan gambar akan muncul.
Perilaku sistem ini menyarankan pemikiran tentang masalah desain dan bug dalam arsitektur, tetapi kenyataannya tidak. Arsitektur DLP kami memberikan fleksibilitas untuk mengkonfigurasi sistem dan menyesuaikannya dengan kebutuhan pelanggan. Misalnya, kita cukup mengonfigurasi satu OCR agar berfungsi dengan dua layanan pemfilteran tanpa mengorbankan kinerja.
3. Gambar yang tidak dikenaliJika gambar yang OCR tidak dapat kenali masuk ke sistem DLP untuk analisis, ada beberapa solusi untuk masalah tersebut.
Untuk alasan apa gambar mungkin tidak dikenali? Misalnya, dengan yang berikut:
1. Skema warna non-standar dari gambar.
2. Gambar beresolusi rendah.
3. Orientasi gambar yang salah dan teks yang terkandung di dalamnya dalam ruang.
4. Garis miring dan distorsi proporsi teks pada gambar, dll.
Berikut ini sebuah contoh: salah satu pelanggan selama proses pemantauan menemukan bahwa OCR tidak mengenali dokumen pdf yang dieksekusi dalam skema warna yang tidak standar. Yaitu, gambar diekstraksi dari dokumen PDF dalam mode normal, tetapi ketika harus memproses modul OCR, ia tidak memahami skema warna gambar dan menghasilkan "kotak Malevich" pada output. Di antarmuka kami, gambarnya terlihat seperti ini:
 Mesin OCR memiliki berbagai fungsi untuk koreksi gambar otomatis, yang sangat meningkatkan peluang keberhasilan pengenalan teks yang terkandung di dalamnya. Namun, dalam praktiknya, alat ajaib ini tidak selalu berfungsi. Dalam kasus khusus ini, kami telah menyesuaikan modul OCR untuk pelanggan sehingga ia mengenali skema warna non-standar ini.
Mesin OCR memiliki berbagai fungsi untuk koreksi gambar otomatis, yang sangat meningkatkan peluang keberhasilan pengenalan teks yang terkandung di dalamnya. Namun, dalam praktiknya, alat ajaib ini tidak selalu berfungsi. Dalam kasus khusus ini, kami telah menyesuaikan modul OCR untuk pelanggan sehingga ia mengenali skema warna non-standar ini.5. Inkonsistensi dari salah satu parameter dokumen dengan ukuran yang ditentukan dikenali
gambar.
Misalnya, dalam konfigurasi sistem, batas ukuran gambar yang dikenali diatur ke 200x1000 piksel, dan file berukuran 500x1500 piksel diterima dalam OCR (batas atas terlampaui).
Dalam hal ini, Anda perlu memperbaiki pengaturan OCR untuk mengenali gambar tersebut.Ini mungkin salah satu skenario rekonfigurasi sistem yang paling populer setelah kita diberi tahu bahwa OCR tidak berfungsi.
Mengapa OCR tidak pada agen?
OCR dalam sistem DLP diimplementasikan dalam dua versi - pada agen dan pada server. Kami mendukung pendekatan kedua, karena pengenalan gambar langsung pada workstation menciptakan beban tinggi pada prosesornya dan, karenanya, memperlambat kerja aplikasi lain. OCR sendiri adalah teknologi yang sangat rakus, bahkan untuk server, dan penerapannya membutuhkan perencanaan kapasitas prosesor dan pemantauan kinerja yang tepat.
Namun, banyak perusahaan domestik, terutama di sektor publik, masih memiliki armada PC yang cukup lama. Apa yang terjadi dalam kasus ini? Pengguna mulai mengeluh kepada departemen TI tentang "pengereman" PC, dan spesialis TI akhirnya mengetahui bahwa penyebab pengereman adalah modul OCR dari sistem DLP. Ini mengganggu mereka, dan pengguna yang tidak bisa dengan cepat menyelesaikan tugas kerja. Pada akhirnya, semua ini menambah sakit kepala bagi seorang penjaga keamanan yang memiliki banyak tugas lain.
Penggunaan OCR pada agen hanya dibenarkan ketika sistem DLP bekerja “secara terpisah”. Dalam hal ini, pengenalan gambar harus terjadi tepat pada saat pengguna melakukan tindakan dengan file grafik ini di stasiun kerjanya. Artinya, sistem DLP harus secara instan memutuskan nasib dokumen yang berisi gambar ini - memungkinkannya untuk dikirim / disalin atau dilarang. Namun dalam praktiknya, hanya beberapa pelanggan yang menggunakan sistem DLP dalam mode blocking aktif, dan ini tidak hanya berlaku untuk DLP kita sendiri. Di sini prinsip kerjanya: "semua yang dapat diambil untuk pemeriksaan di server harus dilakukan di server."
Total
Teknologi OCR memberikan kemampuan pengenalan grafis, dan sebagai tambahan, kami selalu memberikan rekomendasi umum untuk konfigurasi sistem. Namun, dalam proyek tertentu, mungkin perlu mengkonfigurasi ulang modul OCR untuk memenuhi kebutuhan spesifik pelanggan baik pada tahap uji coba dan implementasi solusi, dan pada tahap operasi industrinya. Ini bukan hanya normal - ini adalah satu-satunya cara yang tepat yang akan memberikan hasil nyata, membuat OCR bekerja di perusahaan seefisien mungkin dan meminimalkan kebocoran informasi rahasia melalui gambar grafik.
Nikita Igonkin, Teknisi Layanan Utama, Rostelecom Solar