Halo semuanya! Sebuah konferensi tentang pengembangan aplikasi yang sangat dimuat HighLoad ++ Siberia 2019 diadakan di Novosibirsk pada bulan Juni. Sebelumnya dalam artikel tentang Habré, kami menyebutkan bahwa kami di Plesk melakukan retrospeksi konferensi dan laporan yang kami hadiri agar tidak kehilangan pengetahuan yang didapat dan kemudian menerapkannya. Kami akan memberi tahu Anda laporan mana yang kami catat untuk kami sendiri, dan juga membagikan resep retrospektif kepada Anda. Panitia secara bertahap memposting video di sini:
saluran youtube . Bagian dari apa yang kami uraikan sudah bisa dilihat.
Ikhtisar Laporan
Victor Eremchenko (Miro)Ini adalah laporan ulasan tentang keberhasilan migrasi Redis -> PostgreSQL -> Pgbouncer + PostgreSQL -> Patroni Consul + Pgbouncer + PostgreSQL. Penulis memberikan skema, tipuan khas dari solusi yang jelas, berbicara tentang solusi alternatif dan mengapa mereka tidak cocok. Dari yang menarik:
- Insinyur Miro telah mengumpulkan solusi mereka agar tidak membayar untuk Amazon RDS, dan solusi ini sejauh ini cocok untuk mereka.
- Likbez pada manajer koneksi untuk PostgreSQL.
- Menjelaskan proses memperbarui node cluster tanpa menghentikan aplikasi.
- Memperlihatkan trik untuk memperbarui PostgreSQL dengan cepat.
Sangat berguna untuk melihat mereka yang menggunakan atau akan menggunakan PostgreSQL, dan yang memiliki jumlah data yang semakin banyak.
Vasily Bogonatov (Yandex)Sebagai pembicara pengantar, ia membuat perbandingan singkat dari beberapa fitur Kafka dan RabbitMQ. Secara singkat: Kafka - antrian sederhana, penerima yang kompleks; RabbitMQ adalah antrian kompleks, penerima sederhana. Penulis juga berbicara tentang jenis-jenis jaminan untuk mengirimkan pesan dari antrian. Catatan penting: tidak ada antrian yang dapat memastikan pengiriman pesan tepat 1 kali tanpa dukungan pada pengirim dan penerima.
Laporan ini didedikasikan untuk YandexMQ. YandexMQ (YMQ) adalah API yang kompatibel dengan antrian Amazon SQS. Dasar dari YandexMQ adalah Yandex Database (YDB). Dengan mudah menunjukkan keunggulan YandexMQ, cara mencapai konsistensi dan keandalan yang ketat, dan memberikan gambaran arsitektur YMQ. YMQ mengimplementasikan pola konsumen yang bersaing - satu pesan ke satu konsumen. Chip YMQ: ketika konsumen meminta pesan, pesan itu disembunyikan dalam antrian sehingga tidak ada orang lain yang memprosesnya. Jika ada masalah selama pemrosesan, maka setelah VisibilityTimeout pesan menjadi terlihat dalam antrian lagi. Pembicara mengklaim bahwa Apache Kafka memiliki masalah kehilangan data ketika prosesnya tiba-tiba mati, Yandex MessageQueue tahan terhadap hal ini.

Laporan ini direkomendasikan untuk semua orang yang ingin memahami fitur mendasar dari antrian.
Ivan Muratov (Perusahaan Pemantau Pertama)Laporkan cara menyimpan dan memproses data dalam seri waktu PostgreSQL.
TimescaleDB memungkinkan Anda untuk menyimpan volume besar karena partisi licik, dan PipelineDB menyediakan pekerjaan dengan stream langsung di PostgreSQL (serta integrasi dengan antrian).
TimescaleDB:
- Ini memiliki kecepatan perekaman yang sangat stabil dengan peningkatan volume database di bawah beban berat dan dengan peningkatan jumlah partisi, diukur dalam ribuan.
- Memungkinkan Anda menggunakan fitur PostgreSQL standar seperti SQL, replikasi, cadangan, pemulihan, dll.
- Satu set integrasi yang baik diumumkan, misalnya, dengan Prometheus, Telegraf, Grafana, Zabbix, Kubernetes.
- Ada versi open source gratis.
Gagasan utama: TimescaleDB diperlukan terutama untuk menyimpan data.
PipelineDB:
- Memungkinkan Anda untuk terus memproses data yang masuk menggunakan SQL dan menambahkan hasilnya ke tabel.
- Memiliki antarmuka SQL.
- Ada kinerja prosedur tersimpan di bawah kondisi.
- Integrasi dengan Apache Kafka dan Amazon Kinesis dimungkinkan.
- Ada versi open source gratis.
- Pengembangan PipelineDB dibekukan pada versi 1.0, dan sekarang hanya perbaikan bug yang dirilis.
Gagasan utama: PipelineDB dibutuhkan terutama untuk pemrosesan data.
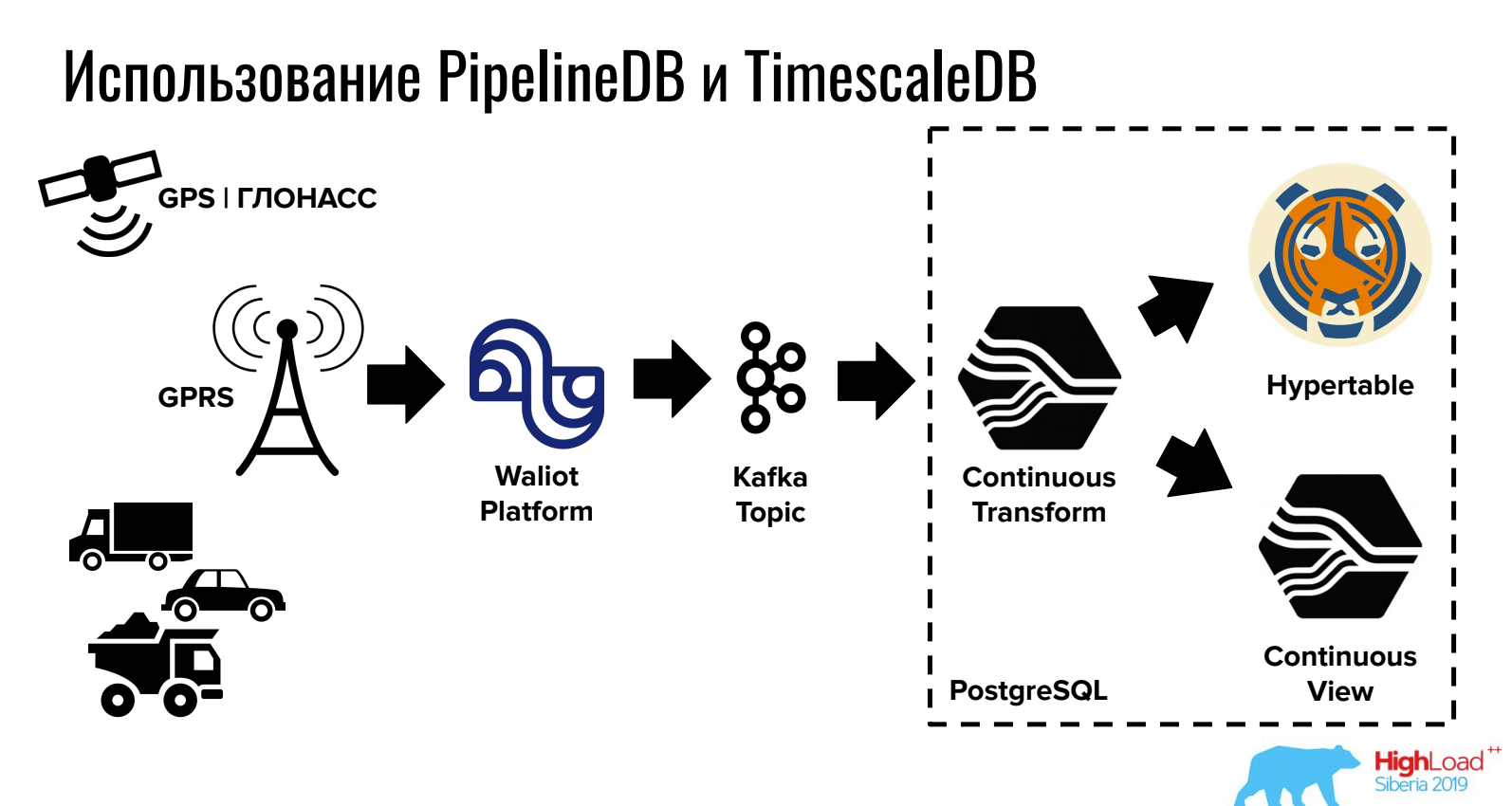
Untuk tugas-tugas di mana DBMS relasional, NoSQL dan seri waktu diperlukan pada saat yang sama, opsi ini bisa sangat nyaman.
Pavel Luzanov (Postgres Professional)Laporan ikhtisar yang baik tentang PostgreSQL, pewarisan tabel, dan kinerja Tips & Trik PostgreSQL 10, 11, 12+. Partisi melalui warisan, sharding. Sangat berguna untuk melihat semua orang yang menggunakan PostgreSQL dan ingin membuatnya sedikit lebih cepat.
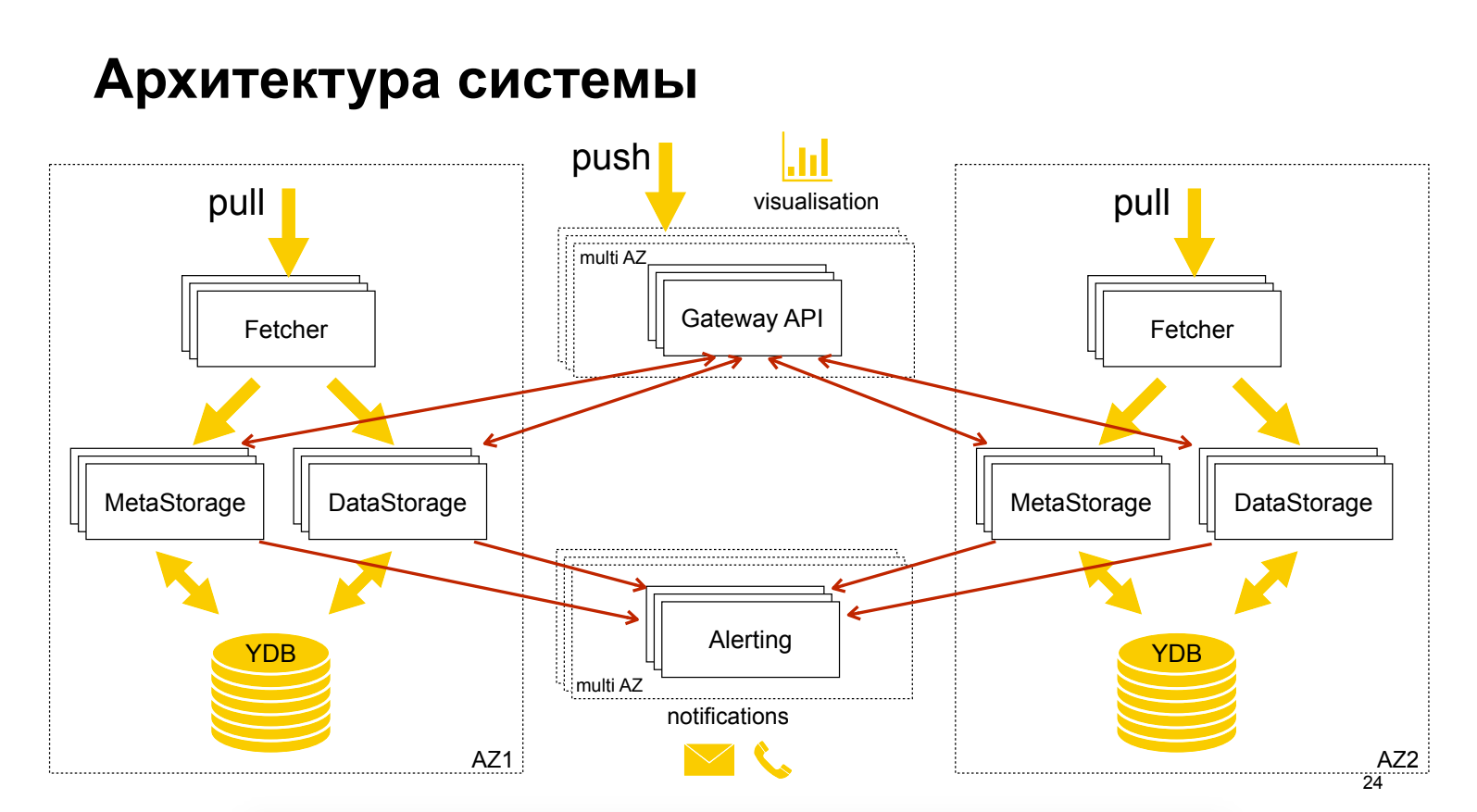
Sergey Polovko (Yandex)Tentang produk cloud Pemantauan Yandex, yang masih dalam tahap "Pratinjau", gratis. Cukup banyak tentang arsitektur. Teknik yang menarik ditunjukkan - pemisahan metadata dari data, yang memungkinkan penskalaan dan optimisasi independen. Grafana digunakan sebagai GUI, sedangkan peringatannya tidak di Grafana.
 Andrey Salnikov (Data Egret)
Andrey Salnikov (Data Egret)Pengalaman dalam administrasi sistem komersial dari banyak server PostgreSQL. Ini menceritakan tentang parameter server mana yang dipantau secara otomatis, bagaimana tugas diprioritaskan.
Data Egret menggunakan pengalaman umum dalam Wiki dengan resep, daftar periksa - ini adalah dasar untuk artikel dan laporan di masa depan. Mereka menggunakan database kejadian dengan deskripsi masalah dan solusi - ini secara signifikan menghemat sumber daya. Merilis sejumlah utilitas untuk bekerja dengan PostgreSQL, menyediakan tautan ke sana.
 Evgeny Sokolov (Yandex.Market)
Evgeny Sokolov (Yandex.Market)Laporkan arsitektur aplikasi Yandex.Market yang kompleks, sangat mudah diakses, dan tentang proses dan alat untuk pengembangan, pengujian, pembaruan, pemantauan. Dari yang menarik:
- "Stop-crane" adalah solusinya untuk aplikasi cepat dan kembalikan konfigurasi, membantu menguji fungsionalitas baru.
- Lalu lintas dialihkan dari pusat data saat ini oleh penyeimbang ke pusat data lain jika ada masalah.
- Graphite dan Grafana digunakan untuk pemantauan.
- Ada duplikat pemantauan dasar pada tumpukan teknologi lain.
- Cluster bayangan digunakan untuk pengembang, yang menggandakan bagian dari lalu lintas pengguna. Pengguna tidak melihat respons dari cluster Shadow.
- Perhitungan kualitas otomatis dilakukan selama pengujian A / B.
 Anton Alekseev (2GIS)
Anton Alekseev (2GIS)Laporkan tentang apa yang dimiliki ClickHouse dan cara memasaknya bersama dengan Grafana. Yang menarik utama:
- Jika tidak ada kecepatan yang cukup, Anda harus menggunakan sampling (dikatakan bahwa keakuratan data setelah sampling cukup). Pengambilan sampel di ClickHouse - pengambilan sampel sebagian data dengan agregasi sambil mempertahankan rasio berbagai nilai dalam kunci tabel, memungkinkan Anda untuk mempercepat agregasi pada waktu dan pada saat yang sama memiliki hasil yang sangat dekat dengan real.
- ClickHouse dapat digunakan untuk menyelidiki insiden dengan cepat (contoh menarik dalam laporan).
- ClickHouse juga memiliki MaterializedView untuk mempercepat pengambilan.
- Antarmuka HTTP ClickHouse untuk permintaan dan pemuatan data dijelaskan.
Sebagai kesimpulan dari tinjauan laporan, saya ingin mencatat bahwa kami juga sangat menyukai laporan
"Panggilan video: dari jutaan per hari hingga 100 peserta dalam satu konferensi" (
Alexander Tobol / Odnoklassniki), yang dimasukkan dalam daftar laporan terbaik konferensi berdasarkan hasil pemungutan suara. Ini adalah gambaran yang bagus tentang cara kerja konferensi video untuk sekelompok peserta. Laporan ini dibedakan dengan presentasi sistemik yang dapat dipahami. Jika tiba-tiba Anda harus melakukan panggilan video, Anda dapat melihat laporan untuk dengan cepat mendapatkan wawasan tentang area subjek.
Struktur Kilas Balik Konferensi Plesk
Dan sekarang, untuk hidangan penutup, tentang bagaimana kita menulis retrospektif di dalam perusahaan. Pertama-tama, kami mencoba menulis retro di minggu pertama setelah menghadiri konferensi, sementara ingatan kami masih segar. Ngomong-ngomong, bahan retrospektif kemudian dapat berfungsi sebagai dasar untuk artikel, seperti yang Anda duga;)
Tujuan penulisan retrospektif tidak hanya untuk mengkonsolidasikan pengetahuan, tetapi juga untuk membagikannya kepada mereka yang tidak hadir di konferensi, tetapi ingin terus mengikuti tren terbaru, solusi menarik. Daftar yang sudah jadi membantu mengurangi waktu untuk mencari laporan yang menarik untuk dilihat. Kami menulis pelajaran yang telah kami pelajari untuk diri kami sendiri, menandai orang-orang tertentu dengan catatan, mengapa Anda perlu melihat laporan dan berpikir tentang ide dan keputusan orang lain. Pelajaran tertulis membantu untuk fokus dan tidak kehilangan apa yang ingin kita lakukan. Melihat rekaman dalam 3-6 bulan, kita akan mengerti jika kita lupa tentang sesuatu yang penting.
Kami menyimpan dokumentasi di perusahaan di Confluence, untuk konferensi kami memiliki pohon halaman terpisah, sepotong kayu:
Seperti yang dapat dilihat dari tangkapan layar, kami menata materi berdasarkan tahun untuk kemudahan navigasi.
Di dalam halaman yang didedikasikan untuk konferensi tertentu, kami menyimpan bagian-bagian berikut: ikhtisar dengan tautan ke situs web acara, jadwal, video dan presentasi, daftar peserta (secara langsung dan siaran), kesan umum (kesan keseluruhan) dan tinjauan terperinci (tinjauan terperinci) ) Omong-omong, kami membuat halaman untuk retro dari templat di mana seluruh struktur sudah ada. Kami juga membuat konten pos sehingga Anda dapat dengan cepat melihat daftar laporan dan beralih ke yang diinginkan.
Bagian Keseluruhan kesan memberikan penilaian singkat dari konferensi dan memberikan kesan para peserta. Jika para peserta menghadiri konferensi dalam beberapa tahun terakhir, mereka dapat membandingkan level mereka dan secara umum memahami manfaat menghadiri acara tersebut.
Bagian Gambaran terperinci berisi tabel:

Contoh mengisi tabel:

Kami akan tertarik untuk mengetahui tentang laporan yang Anda sukai di Highload Siberia 2019, serta tentang pengalaman Anda dalam melakukan retrospektif.