
Kami terus mempublikasikan analisis tugas yang diusulkan di kejuaraan baru-baru ini. Baris berikutnya adalah tugas yang diambil dari babak kualifikasi untuk spesialis pembelajaran mesin. Ini adalah trek ketiga dari empat (backend, frontend, ML, analytics). Peserta perlu membuat model untuk memperbaiki kesalahan ketik dalam teks, mengusulkan strategi untuk bermain di mesin slot, mengingatkan sistem rekomendasi untuk konten, dan menyusun beberapa program lagi.
A. Kesalahan Pengetikan
Ketentuan
(epigraf) (dari satu forum)
- Siapa yang menyusun omong kosong ini?
- Ahli astrofisika. Mereka juga manusia.
- Anda membuat 10 kesalahan dalam kata "jurnalis".
Banyak pengguna membuat kesalahan pengetikan, beberapa karena menekan tombol, dan beberapa karena buta huruf. Kami ingin memeriksa apakah pengguna benar-benar dapat mengingat kata lain selain yang diketiknya.
Secara lebih formal, anggaplah bahwa model kesalahan berikut terjadi: pengguna mulai dengan kata yang ingin ia tulis, dan kemudian membuat sejumlah kesalahan di dalamnya. Setiap kesalahan adalah substitusi dari beberapa substring kata untuk substring lain. Satu kesalahan terkait dengan mengganti hanya dalam satu posisi (yaitu, jika pengguna ingin membuat kesalahan tunggal dengan aturan "abc" → "cba", maka dari string "abcabc" ia bisa mendapatkan "cbaabc" atau "abccba"). Setelah setiap kesalahan, proses berulang. Aturan yang sama dapat digunakan beberapa kali dalam langkah yang berbeda (misalnya, dalam contoh di atas, "cbacba" dapat diperoleh dalam dua langkah).
Hal ini diperlukan untuk menentukan jumlah kesalahan minimum yang dapat dilakukan pengguna jika ia memikirkan satu kata tertentu dan menulis yang lain.
Format dan Contoh I / OFormat input
Baris pertama berisi kata, yang, menurut asumsi kami, yang ada di benak pengguna (terdiri dari huruf-huruf alfabet Latin dalam huruf kecil, panjangnya tidak melebihi 20).
Baris kedua berisi kata yang sebenarnya ia tulis (juga terdiri dari huruf-huruf alfabet Latin dalam huruf kecil, panjangnya tidak melebihi 20).
Baris ketiga berisi angka tunggal N (N <50) - jumlah penggantian yang menggambarkan berbagai kesalahan.
Baris N berikutnya berisi kemungkinan penggantian dalam format & lt "benar" urutan huruf & gt <spasi> <"salah" urutan huruf>. Urutan tidak lebih dari 6 karakter.
Format output
Diperlukan untuk mencetak satu nomor - jumlah kesalahan minimum yang bisa dilakukan pengguna. Jika angka ini melebihi 4 atau tidak mungkin mendapatkan yang lain dari satu kata, cetak -1.
Contoh
Solusi
Mari kita coba untuk menghasilkan dari ejaan yang benar semua kata yang mungkin dengan tidak lebih dari 4 kesalahan. Dalam kasus terburuk, mungkin ada O ((L﹒N)
4 ). Dalam batasan masalah, ini adalah angka yang agak besar, jadi Anda perlu mencari cara untuk mengurangi kompleksitas. Alih-alih, Anda dapat menggunakan algoritme meet-in-the-middle: menghasilkan kata-kata dengan tidak lebih dari 2 kesalahan, serta kata-kata dari mana Anda bisa mendapatkan kata yang ditulis pengguna tanpa lebih dari 2 kesalahan. Perhatikan bahwa ukuran masing-masing set ini tidak akan melebihi 10
6 . Jika jumlah kesalahan yang dilakukan oleh pengguna tidak melebihi 4, maka set ini akan berpotongan. Demikian pula, kami dapat memverifikasi bahwa jumlah kesalahan tidak melebihi 3, 2, dan 1.
struct FromTo { std::string from; std::string to; }; std::pair<size_t, std::string> applyRule(const std::string& word, const FromTo &fromTo, int pos) { while(true) { int from = word.find(fromTo.from, pos); if (from == std::string::npos) { return {std::string::npos, {}}; } int to = from + fromTo.from.size(); auto cpy = word; for (int i = from; i < to; i++) { cpy[i] = fromTo.to[i - from]; } return {from, std::move(cpy)}; } } void inverseRules(std::vector<FromTo> &rules) { for (auto& rule: rules) { std::swap(rule.from, rule.to); } } int solve(std::string& wordOrig, std::string& wordMissprinted, std::vector<FromTo>& replaces) { std::unordered_map<std::string, int> mapping; std::unordered_map<int, std::string> mappingInverse; mapping.emplace(wordOrig, 0); mappingInverse.emplace(0, wordOrig); mapping.emplace(wordMissprinted, 1); mappingInverse.emplace(1, wordMissprinted); std::unordered_map<int, std::unordered_set<int>> edges; auto buildGraph = [&edges, &mapping, &mappingInverse](int startId, const std::vector<FromTo>& replaces, bool dir) { std::unordered_set<int> mappingLayer0; mappingLayer0 = {startId}; for (int i = 0; i < 2; i++) { std::unordered_set<int> mappingLayer1; for (const auto& v: mappingLayer0) { auto& word = mappingInverse.at(v); for (auto& fromTo: replaces) { size_t from = 0; while (true) { auto [tmp, wordCpy] = applyRule(word, fromTo, from); if (tmp == std::string::npos) { break; } from = tmp + 1; { int w = mapping.size(); mapping.emplace(wordCpy, w); w = mapping.at(wordCpy); mappingInverse.emplace(w, std::move(wordCpy)); if (dir) { edges[v].emplace(w); } else { edges[w].emplace(v); } mappingLayer1.emplace(w); } } } } mappingLayer0 = std::move(mappingLayer1); } }; buildGraph(0, replaces, true); inverseRules(replaces); buildGraph(1, replaces, false); { std::queue<std::pair<int, int>> q; q.emplace(0, 0); std::vector<bool> mask(mapping.size(), false); int level{0}; while (q.size()) { auto [w, level] = q.front(); q.pop(); if (mask[w]) { continue; } mask[w] = true; if (mappingInverse.at(w) == wordMissprinted) { return level; } for (auto& v: edges[w]) { q.emplace(v, level + 1); } } } return -1; }
B. Bandit berlengan banyak
Ketentuan
Ini adalah tugas interaktif.
Anda sendiri tidak tahu bagaimana itu terjadi, tetapi Anda mendapati diri Anda berada di aula dengan mesin slot dengan seluruh kantong token. Sayangnya, di box office, mereka menolak untuk menerima token kembali, dan Anda memutuskan untuk mencoba keberuntungan Anda. Ada banyak mesin slot di aula yang bisa Anda mainkan. Untuk satu game dengan mesin slot Anda menggunakan satu token. Jika menang, mesin memberi Anda satu dolar, jika terjadi kerugian - tidak ada. Setiap mesin memiliki probabilitas tetap untuk menang (yang Anda tidak tahu), tetapi berbeda untuk mesin yang berbeda. Setelah mempelajari situs web produsen mesin ini, Anda menemukan bahwa probabilitas menang untuk setiap mesin dipilih secara acak pada tahap pembuatan dari
distribusi beta dengan parameter tertentu.
Anda ingin memaksimalkan kemenangan yang Anda harapkan.
Format dan Contoh I / OFormat input
Satu eksekusi dapat terdiri dari beberapa tes.
Setiap tes dimulai dengan fakta bahwa program Anda di telepon berisi dua bilangan bulat yang dipisahkan oleh spasi: angka N adalah jumlah token di tas Anda, dan M adalah jumlah mesin di aula (N ≤ 10
4 , M ≤ min (N, 100) ) Baris berikutnya berisi dua bilangan real α dan β (1 ≤ α, β ≤ 10) - parameter distribusi beta dari probabilitas menang.
Protokol komunikasi dengan sistem pemeriksaan adalah ini: Anda membuat permintaan N persis. Untuk setiap permintaan, cetak dalam baris terpisah nomor mesin yang akan Anda mainkan (dari 1 hingga M inklusif). Sebagai jawaban, di baris terpisah akan ada "0" atau "1", yang berarti masing-masing kalah dan menang dalam permainan dengan mesin slot yang diminta.
Setelah tes terakhir, alih-alih angka N dan M, akan ada dua nol.
Format output
Tugas tersebut akan dianggap selesai jika keputusan Anda tidak lebih buruk dari keputusan juri. Jika keputusan Anda secara signifikan lebih buruk daripada keputusan juri, Anda akan menerima vonis "jawaban salah".
Dijamin bahwa jika keputusan Anda tidak lebih buruk dari keputusan juri, maka kemungkinan menerima putusan “jawaban salah” tidak melebihi
10-6 .
Catatan
Contoh Interaksi:
____________________ stdin stdout ____________________ ____________________ 5 2 2 2 2 1 1 0 1 1 2 1 2 1
Solusi
Masalah ini sudah diketahui, bisa diselesaikan dengan berbagai cara. Keputusan utama juri menerapkan strategi
pengambilan sampel Thompson , tetapi karena jumlah langkah diketahui pada awal program, ada strategi yang lebih optimal (misalnya, UCB1). Selain itu, seseorang bahkan bisa bertahan dengan strategi epsilon-serakah: dengan probabilitas tertentu ε memainkan mesin acak dan dengan probabilitas (1 - ε) memainkan mesin dengan statistik kemenangan terbaik.
class SolverFromStdIn(object): def __init__(self): self.regrets = [0.] self.total_win = [0.] self.moves = [] class ThompsonSampling(SolverFromStdIn): def __init__(self, bandits_total, init_a=1, init_b=1): """ init_a (int): initial value of a in Beta(a, b). init_b (int): initial value of b in Beta(a, b). """ SolverFromStdIn.__init__(self) self.n = bandits_total self.alpha = init_a self.beta = init_b self._as = [init_a] * self.n
C. Penyelarasan kalimat
Ketentuan
Salah satu tugas paling penting untuk melatih model terjemahan mesin yang baik adalah kasus kalimat paralel yang baik. Biasanya, sumber untuk penawaran paralel adalah dokumen paralel. Ternyata seringkali untuk membangun korpus kalimat paralel tertentu, Anda tidak perlu tahu apa-apa selain panjangnya. Secara khusus, Anda mungkin memperhatikan bahwa semakin lama kalimat dalam bahasa sumber, semakin lama kemungkinan akan diterjemahkan. Beberapa kesulitan terletak pada kenyataan bahwa selama terjemahan jumlah kalimat dalam teks dapat berubah: kadang-kadang dua kalimat yang berdekatan dalam terjemahan dapat digabungkan menjadi satu, atau sebaliknya - satu kalimat dapat dibagi menjadi dua. Dalam beberapa kasus yang jarang terjadi, kalimat dapat dihilangkan seluruhnya dalam terjemahan, atau terjemahan mungkin muncul dalam terjemahan yang tidak asli.
Lebih formal, anggap model generatif berikut untuk penutup paralel adalah benar. Pada setiap langkah, kami melakukan salah satu dari yang berikut:
1. BerhentiDengan probabilitas p
h, generasi lambung berakhir.
2. [1-0] Melewati penawaranDengan probabilitas p
d kita menganggap satu kalimat ke teks asli. Kami tidak menghubungkan apa pun dengan terjemahan. Panjang kalimat dalam bahasa asli L ≥ 1 dipilih dari distribusi diskrit:
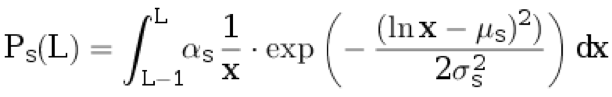
.
Di sini
μ s ,
σ s adalah parameter distribusi, dan
α s adalah koefisien normalisasi yang dipilih

.
3. [0-1] Masukkan proposalDengan probabilitas p
i, kami menetapkan satu kalimat untuk terjemahan. Kami tidak menganggap apa pun dari aslinya. Panjang kalimat dalam bahasa terjemahan L ≥ 1 dipilih dari distribusi diskrit:

.
Di sini
μ t ,
σ t adalah parameter distribusi, dan
α t adalah koefisien normalisasi yang dipilih

.
4. TerjemahanDengan probabilitas (1 - p
d - p
i - p
h ) kami mengambil panjang kalimat dalam bahasa asli L
s ≥ 1 dari distribusi p
s (dengan pembulatan ke atas). Selanjutnya, kami menghasilkan panjang kalimat dalam bahasa terjemahan
Lt ≥ 1 dari distribusi diskrit bersyarat:
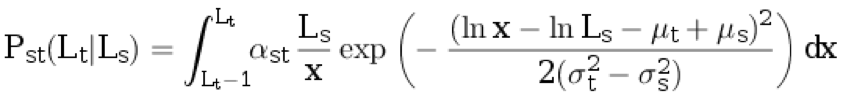
.
Di sini,
α st adalah koefisien normalisasi, dan parameter yang tersisa dijelaskan dalam paragraf sebelumnya.
Berikutnya adalah langkah lain:
1. [2-1] Dengan probabilitas p
split s, kalimat yang dihasilkan dalam bahasa asli terbagi menjadi dua yang tidak kosong, sehingga jumlah total kata
bertambah tepat satu . Probabilitas bahwa kalimat dengan panjang Ls
akan terpisah menjadi bagian-bagian dengan panjang L1 dan L2 (yaitu, L1 + L2 = Ls + 1) sebanding dengan Ps (L
1 ) ⋅ Ps (L
2 ).
2. [1-2] Dengan probabilitas p
split t, kalimat yang dihasilkan dalam bahasa target dibagi menjadi dua kalimat yang tidak kosong, sehingga jumlah total kata bertambah tepat satu. Probabilitas bahwa kalimat dengan panjang
Lt akan terpecah menjadi beberapa bagian dengan panjang L1 dan L2 (yaitu, L1 + L2 =
Lt + 1) sebanding dengan
Pt (L1) ⋅ Pt (L
2 ).
3. 3. [1-1] Dengan probabilitas (1 -
pisah s - p
split t ), tidak satu pun dari pasangan kalimat yang dihasilkan akan meluruh.
Format, Contoh, dan Catatan I / OFormat input
Baris pertama file berisi parameter distribusi: p
h , p
d , p
i , p
split s , p
split t , μ
s , σ
s , μ
t , σ
t . 0,1 ≤ σ
s <σ
t ≤ 3. 0 ≤ μ
s , μ
t ≤ 5.
Baris berikutnya berisi angka Ns dan
Nt - jumlah kalimat dalam kasus dalam bahasa asli dan bahasa target, masing-masing (1 ≤ N
s , N
t ≤ 1000).
Baris berikutnya berisi bilangan bulat N - panjang kalimat dalam bahasa asli. Baris berikutnya berisi bilangan bulat N - panjang kalimat dalam bahasa target.
Baris berikutnya berisi dua angka: j dan k (1 ≤ j ≤ N
s , 1 ≤ k ≤ N
t ).
Format output
Diperlukan untuk memperoleh probabilitas bahwa kalimat dengan indeks j dan k dalam teks, masing-masing, adalah paralel (yaitu, bahwa mereka dihasilkan pada satu langkah algoritma dan tidak satupun dari mereka adalah hasil dari pembusukan).
Jawaban Anda akan diterima jika kesalahan absolut tidak melebihi
10-4 .
Contoh 1
Contoh 2
Contoh 3
Catatan
Dalam contoh pertama, urutan awal angka dapat diperoleh dengan tiga cara:
• Pertama, dengan probabilitas p
d menambahkan satu kalimat ke teks asli, kemudian dengan probabilitas p
i menambahkan satu kalimat ke terjemahan, kemudian dengan probabilitas p
h menyelesaikan generasi.
Probabilitas acara ini adalah P
1 = p
d * P
s (4) * p
i * P
t (20) * p
h .
• Pertama, dengan probabilitas p
d menambahkan satu kalimat ke teks asli, kemudian dengan probabilitas p
i menambahkan satu kalimat ke terjemahan, kemudian dengan probabilitas p
h menyelesaikan generasi.
Probabilitas acara ini sama dengan P
2 = p
i * P
t (20) * p
d * P
s (4) * p
h .
• Dengan probabilitas (1 - p
h - p
d - p
i ) menghasilkan dua kalimat, maka dengan probabilitas (1 - p
s s - p
split t ) biarkan semuanya apa adanya (yaitu, jangan pisahkan yang asli atau terjemahan menjadi dua kalimat ) dan setelah itu dengan probabilitas p
h menyelesaikan generasi.
Probabilitas acara ini adalah

.
Akibatnya, jawabannya dihitung sebagai

.
Solusi
Tugas ini merupakan kasus penyelarasan khusus menggunakan model Markov tersembunyi (penyelarasan HMM). Gagasan utamanya adalah Anda dapat menghitung probabilitas menghasilkan sepasang dokumen tertentu menggunakan model ini dan
algoritma penerusan : dalam kasus ini, negara adalah sepasang awalan dokumen. Dengan demikian, probabilitas yang diperlukan untuk menyelaraskan pasangan kalimat paralel tertentu dapat dihitung dengan algoritma
maju-mundur .
Kode #include <iostream> #include <iomanip> #include <cmath> #include <vector> double p_h, p_d, p_i, p_tr, p_ss, p_st, mu_s, sigma_s, mu_t, sigma_t; double lognorm_cdf(double x, double mu, double sigma) { if (x < 1e-9) return 0.0; double res = std::log(x) - mu; res /= std::sqrt(2.0) * sigma; res = 0.5 * (1 + std::erf(res)); return res; } double length_probability(int l, double mu, double sigma) { return lognorm_cdf(l, mu, sigma) - lognorm_cdf(l - 1, mu, sigma); } double translation_probability(int ls, int lt) { double res = length_probability(ls, mu_s, sigma_s); double mu = mu_t - mu_s + std::log(ls); double sigma = std::sqrt(sigma_t * sigma_t - sigma_s * sigma_s); res *= length_probability(lt, mu, sigma); return res; } double split_probability(int l1, int l2, double mu, double sigma) { int l_sum = l1 + l2; double total_prob = 0.0; for (int i = 1; i < l_sum; ++i) { total_prob += length_probability(i, mu, sigma) * length_probability(l_sum - i, mu, sigma); } return length_probability(l1, mu, sigma) * length_probability(l2, mu, sigma) / total_prob; } double log_prob10(int ls) { return std::log(p_d * length_probability(ls, mu_s, sigma_s)); } double log_prob01(int lt) { return std::log(p_i * length_probability(lt, mu_t, sigma_t)); } double log_prob11(int ls, int lt) { return std::log(p_tr * (1 - p_ss - p_st) * translation_probability(ls, lt)); } double log_prob21(int ls1, int ls2, int lt) { return std::log(p_tr * p_ss * split_probability(ls1, ls2, mu_s, sigma_s) * translation_probability(ls1 + ls2 - 1, lt)); } double log_prob12(int ls, int lt1, int lt2) { return std::log(p_tr * p_st * split_probability(lt1, lt2, mu_t, sigma_t) * translation_probability(ls, lt1 + lt2 - 1)); } double logsum(double v1, double v2) { double res = std::max(v1, v2); v1 -= res; v2 -= res; v1 = std::min(v1, v2); if (v1 < -30) { return res; } return res + std::log(std::exp(v1) + 1.0); } double loginc(double* to, double from) { *to = logsum(*to, from); } constexpr double INF = 1e25; int main(void) { using std::cin; using std::cout; cin >> p_h >> p_d >> p_i >> p_ss >> p_st >> mu_s >> sigma_s >> mu_t >> sigma_t; p_tr = 1.0 - p_h - p_d - p_i; int Ns, Nt; cin >> Ns >> Nt; using std::vector; vector<int> ls(Ns), lt(Nt); for (int i = 0; i < Ns; ++i) cin >> ls[i]; for (int i = 0; i < Nt; ++i) cin >> lt[i]; vector< vector< double> > fwd(Ns + 1, vector<double>(Nt + 1, -INF)), bwd = fwd; fwd[0][0] = 0; bwd[Ns][Nt] = 0; for (int i = 0; i <= Ns; ++i) { for (int j = 0; j <= Nt; ++j) { if (i >= 1) { loginc(&fwd[i][j], fwd[i - 1][j] + log_prob10(ls[i - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j] + log_prob10(ls[Ns - i])); } if (j >= 1) { loginc(&fwd[i][j], fwd[i][j - 1] + log_prob01(lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i][Nt - j + 1] + log_prob01(lt[Nt - j])); } if (i >= 1 && j >= 1) { loginc(&fwd[i][j], fwd[i - 1][j - 1] + log_prob11(ls[i - 1], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 1] + log_prob11(ls[Ns - i], lt[Nt - j])); } if (i >= 2 && j >= 1) { loginc(&fwd[i][j], fwd[i - 2][j - 1] + log_prob21(ls[i - 1], ls[i - 2], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 2][Nt - j + 1] + log_prob21(ls[Ns - i], ls[Ns - i + 1], lt[Nt - j])); } if (i >= 1 && j >= 2) { loginc(&fwd[i][j], fwd[i - 1][j - 2] + log_prob12(ls[i - 1], lt[j - 1], lt[j - 2])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 2] + log_prob12(ls[Ns - i], lt[Nt - j], lt[Nt - j + 1])); } } } int j, k; cin >> j >> k; double rlog = fwd[j - 1][k - 1] + bwd[j][k] + log_prob11(ls[j - 1], lt[k - 1]) - bwd[0][0]; cout << std::fixed << std::setprecision(12) << std::exp(rlog) << std::endl; }
D. Rekaman rekomendasi
Ketentuan
Pertimbangkan umpan rekomendasi untuk konten heterogen. Ini mencampur objek dari berbagai jenis (gambar, video, berita, dll.). Objek-objek ini biasanya dipesan berdasarkan relevansinya dengan pengguna: semakin relevan (menarik) objek dengan pengguna, semakin dekat ke bagian atas daftar rekomendasi. Namun, dengan pemesanan seperti itu, situasi sering muncul di mana beberapa objek dari jenis yang sama muncul dalam daftar rekomendasi. Ini sangat memperburuk variasi eksternal dari rekomendasi kami dan oleh karena itu pengguna tidak menyukainya. Diperlukan untuk mengimplementasikan suatu algoritma yang, sesuai dengan daftar rekomendasi, akan membuat daftar baru yang akan bebas dari masalah ini dan akan menjadi yang paling relevan.
Biarkan daftar rekomendasi awal diberi = [a
0 , a
1 , ..., a
n - 1 ] dengan panjang n> 0. Objek dengan angka i memiliki tipe dengan angka b
i ∈ {0, ..., m - 1}. Selain itu, objek di bawah angka i memiliki relevansi r (a
i ) = 2
−i . Pertimbangkan daftar yang diperoleh dari yang awal dengan memilih subset objek dan mengatur ulang mereka: x = [a
i 0 , a
i 1 , ..., a
i k - 1 ] dengan panjang k (0 ≤ k ≤ n). Daftar disebut dapat diterima jika tidak ada dua objek berurutan di dalamnya bertepatan dengan tipe, mis., B
i j ≠ b
i j + 1 untuk semua j = 0, ..., k - 2. Relevansi daftar dihitung oleh rumus
. Anda perlu menemukan daftar relevansi maksimum di antara semua yang valid.
Format dan Contoh I / OFormat input
Pada baris pertama, angka n dan m ditulis dengan spasi (1 ≤ n ≤ 100000, 1 ≤ m ≤ n). Baris n berikutnya berisi angka b
i untuk i = 0, ..., n - 1 (0 ≤ b
i ≤ m - 1).
Format output
Tulis, dengan spasi, jumlah objek dalam daftar akhir: i
0 , i
1 , ..., i
k - 1 .
Contoh 1
Contoh 2
Contoh 3
Solusi
Dengan menggunakan perhitungan matematis sederhana, dapat ditunjukkan bahwa masalahnya dapat diselesaikan dengan pendekatan "serakah", yaitu, dalam daftar rekomendasi yang optimal, setiap item memiliki objek paling relevan dari semua yang valid pada awal daftar yang sama. Implementasi dari pendekatan ini sederhana: kita mengambil objek dalam satu baris dan menambahkannya ke jawabannya, jika memungkinkan. Ketika objek yang tidak valid ditemukan (jenis yang bertepatan dengan jenis yang sebelumnya), kami mengesampingkannya dalam antrian terpisah, dari mana kami memasukkannya ke dalam respons sesegera mungkin. Perhatikan bahwa pada setiap saat, semua objek dalam antrian ini akan memiliki jenis yang cocok. Pada akhirnya, beberapa objek mungkin tetap dalam antrian, mereka tidak akan lagi dimasukkan dalam respons.
std::vector<int> blend(int n, int m, const std::vector<int>& types) { std::vector<int> result; std::queue<int> repeated; for (int i = 0; i < n; ++i) { if (result.empty() || types[result.back()] != types[i]) { result.push_back(i); if (!repeated.empty() && types[repeated.front()] != types[result.back()]) { result.push_back(repeated.front()); repeated.pop(); } } else { repeated.push(i); } } return result; }
D. Klasterisasi urutan karakter
Ada alfabet terbatas A = {a
1 , a
2 , ..., a
K - 1 , a
K = S}, a
i ∈ {a, b, ..., z}, S adalah akhir dari baris.
Pertimbangkan metode berikut untuk menghasilkan string acak di atas alfabet A:
1. Karakter pertama x
1 adalah variabel acak dengan distribusi P (x
1 = a
i ) = q
i (diketahui bahwa q
K = 0).
2. Setiap karakter berikutnya dihasilkan berdasarkan yang sebelumnya sesuai dengan distribusi kondisional P (x
i = a
j | | x
i - 1 = a
l ) = p
jl .
3. Jika x
i = S, generasi berhenti dan hasilnya x
1 x
2 ... x
i - 1 .
Himpunan garis yang dihasilkan dari campuran dua model yang dijelaskan dengan parameter yang berbeda diberikan. Adalah perlu untuk setiap baris untuk memberikan indeks rantai dari mana ia dihasilkan.
Format, Contoh, dan Catatan I / OFormat input
Baris pertama berisi dua angka 1000 ≤ N ≤ 2000 dan 3 ≤ K ≤ 27 - jumlah garis dan ukuran alfabet, masing-masing.
Baris kedua berisi baris yang terdiri dari K - 1 huruf kecil berbeda dari alfabet Latin, yang menunjukkan elemen K - 1 pertama dari alfabet.
Setiap baris N berikut dihasilkan sesuai dengan algoritma yang dijelaskan dalam kondisi.
Format output
N baris, baris ke-i berisi nomor cluster (0/1) untuk urutan pada baris ke-1 dari file input. Kebetulan dengan jawaban yang benar minimal harus 80%.
Contoh
Catatan
Catatan untuk pengujian dari kondisi: di dalamnya 50 baris pertama dihasilkan dari distribusi
P (x
i = a | x
i - 1 = a) = 0,5, P (x
i = S | x
i - 1 = a) = 0,5, P (x
1 = a) = 1; 50 detik - dari distribusi
P (x
i = b | x
i - 1 = b) = 0,5, P (x
i = S | x
i - 1 = b) = 0,5, P (x
1 = b) = 1.
Solusi
Masalah diselesaikan dengan menggunakan
algoritma EM : diasumsikan bahwa sampel yang disajikan dihasilkan dari campuran dua rantai Markov yang parameternya dipulihkan selama iterasi. Pembatasan 80% dari jawaban yang benar dibuat sehingga kebenaran solusi tidak terpengaruh oleh contoh-contoh yang memiliki probabilitas tinggi di kedua rantai. Contoh-contoh ini, oleh karena itu, ketika dipulihkan dengan benar, dapat ditugaskan ke rantai yang tidak benar dalam hal respons yang dihasilkan.
import random import math EPS = 1e-9 def empty_row(size): return [0] * size def empty_matrix(rows, cols): return [empty_row(cols) for _ in range(rows)] def normalized_row(row): row_sum = sum(row) + EPS return [x / row_sum for x in row] def normalized_matrix(mtx): return [normalized_row(r) for r in mtx] def restore_params(alphabet, string_samples): n_tokens = len(alphabet) n_samples = len(string_samples) samples = [tuple([alphabet.index(token) for token in s] + [n_tokens - 1, n_tokens - 1]) for s in string_samples] probs = [random.random() for _ in range(n_samples)] for _ in range(200): old_probs = [x for x in probs]
.