Seperti yang Anda ketahui, indeks memainkan peran penting dalam DBMS, menyediakan pencarian cepat dari catatan yang diperlukan. Karena itu, sangat penting untuk melayani mereka tepat waktu. Cukup banyak materi yang telah ditulis tentang analisis dan optimisasi, termasuk di Internet. Misalnya, ulasan terbaru tentang topik ini dibuat dalam
publikasi ini .
Ada banyak solusi berbayar dan gratis untuk ini. Misalnya, ada
solusi turnkey berdasarkan metode optimasi indeks adaptif.
Selanjutnya, pertimbangkan utilitas
SQLIndexManager gratis, yang ditulis oleh
AlanDenton .
Perbedaan teknis utama antara SQLIndexManager dan sejumlah analog lainnya dibuat oleh penulis di
sini dan di
sini .
Dalam artikel yang sama, kami melihat proyek dan kemungkinan menggunakan solusi perangkat lunak ini.
Diskusikan utilitas ini di
sini .
Seiring waktu, sebagian besar komentar dan bug telah diperbaiki.
Jadi, sekarang mari kita beralih ke utilitas SQLIndexManager itu sendiri.
Aplikasi ini ditulis dalam C # .NET Framework 4.5 di Visual Studio 2017 dan menggunakan DevExpress untuk formulir:
dan terlihat seperti ini:
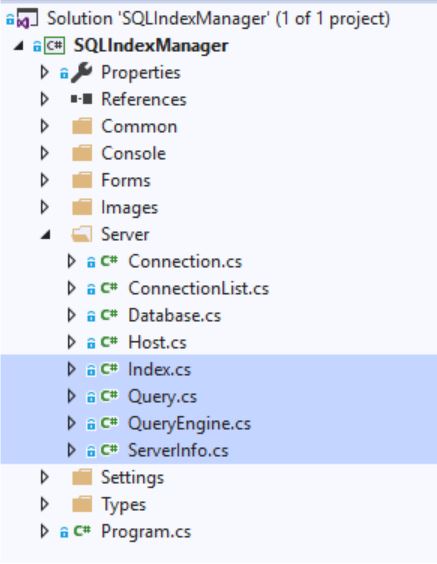
Semua permintaan dihasilkan dalam file berikut:
- Indeks
- Pertanyaan
- Queryengine
- ServerInfo
Saat menghubungkan ke database dan mengirim permintaan ke DBMS, aplikasi ditandatangani sebagai berikut:
ApplicationName=”SQLIndexManager”
Saat aplikasi dimulai, jendela modal terbuka untuk menambahkan koneksi:
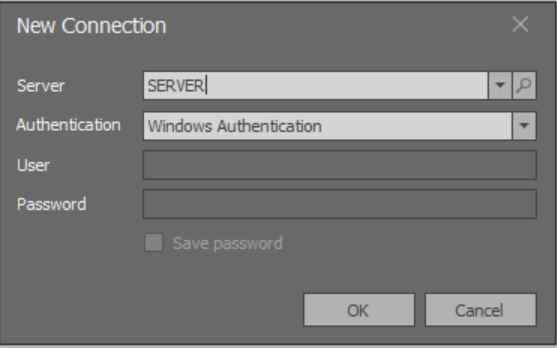
Di sini memuat daftar lengkap semua contoh MS SQL Server yang tersedia melalui jaringan lokal belum berfungsi.
Anda juga dapat menambahkan koneksi menggunakan tombol paling kiri pada menu utama:
Selanjutnya, permintaan DBMS berikut akan diluncurkan:
Memperoleh Informasi DBMS SELECT ProductLevel = SERVERPROPERTY('ProductLevel') , Edition = SERVERPROPERTY('Edition') , ServerVersion = SERVERPROPERTY('ProductVersion') , IsSysAdmin = CAST(IS_SRVROLEMEMBER('sysadmin') AS BIT)
Mendapatkan daftar database yang tersedia dengan properti singkatnya SELECT DatabaseName = t.[name] , d.DataSize , DataUsedSize = CAST(NULL AS BIGINT) , d.LogSize , LogUsedSize = CAST(NULL AS BIGINT) , RecoveryModel = t.recovery_model_desc , LogReuseWait = t.log_reuse_wait_desc FROM sys.databases t WITH(NOLOCK) LEFT JOIN ( SELECT [database_id] , DataSize = SUM(CASE WHEN [type] = 0 THEN CAST(size AS BIGINT) END) , LogSize = SUM(CASE WHEN [type] = 1 THEN CAST(size AS BIGINT) END) FROM sys.master_files WITH(NOLOCK) GROUP BY [database_id] ) d ON d.[database_id] = t.[database_id] WHERE t.[state] = 0 AND t.[database_id] != 2 AND ISNULL(HAS_DBACCESS(t.[name]), 1) = 1
Setelah mengeksekusi skrip di atas, sebuah jendela muncul yang berisi informasi singkat tentang database dari instance MS SQL Server yang dipilih:
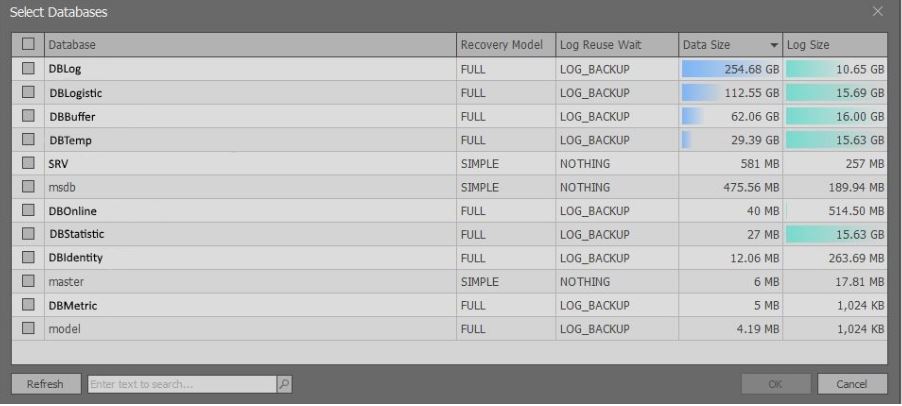
Perlu dicatat bahwa informasi tambahan ditampilkan berdasarkan hak. Jika ada
sysadmin , maka Anda dapat memilih data dari tampilan
sys.master_files . Jika tidak ada hak seperti itu, maka lebih sedikit data yang dikembalikan agar tidak memperlambat permintaan.
Di sini Anda perlu memilih basis data yang menarik dan klik tombol "OK".
Selanjutnya, skrip berikut akan dieksekusi untuk setiap database yang dipilih untuk menganalisis status indeks:
Analisis Status Indeks declare @Fragmentation float=15; declare @MinIndexSize bigint=768; declare @MaxIndexSize bigint=1048576; declare @PreDescribeSize bigint=32768; SET NOCOUNT ON SET ARITHABORT ON SET NUMERIC_ROUNDABORT OFF IF OBJECT_ID('tempdb.dbo.#AllocationUnits') IS NOT NULL DROP TABLE
Seperti yang Anda lihat dari kueri sendiri, tabel sementara sering digunakan. Hal ini dilakukan agar tidak ada kompilasi ulang, dan dalam kasus skema besar, rencana dapat dihasilkan secara paralel saat memasukkan data, karena memasukkan dengan variabel tabel dimungkinkan hanya dalam satu aliran.
Setelah menjalankan skrip di atas, sebuah jendela dengan tabel indeks akan muncul:

Di sini Anda juga dapat menampilkan informasi terperinci lainnya, seperti:
- sebuah database
- jumlah bagian
- tanggal dan waktu panggilan terakhir
- kompresi
- filegroup
dll.
Kolom itu sendiri dapat disesuaikan:
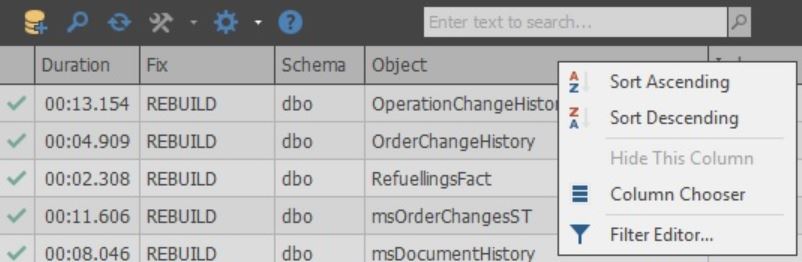
Di sel-sel kolom Fix, Anda dapat memilih tindakan apa yang akan dilakukan selama optimasi. Juga, ketika pemindaian selesai, tindakan default dipilih berdasarkan pengaturan yang dipilih:
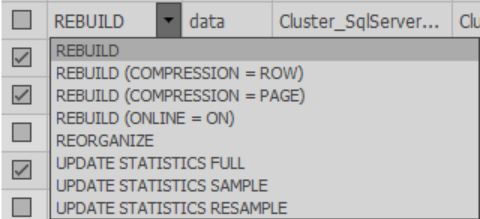
Anda harus memilih indeks yang diinginkan untuk diproses.
Dengan menggunakan menu utama, Anda dapat menyimpan skrip (tombol yang sama memulai proses pengoptimalan indeks itu sendiri):
simpan tabel dalam berbagai format (tombol yang sama memungkinkan Anda membuka pengaturan terperinci untuk analisis dan optimalisasi indeks):

Juga, informasi dapat diperbarui dengan mengklik tombol ketiga di sebelah kiri di menu utama di sebelah kaca pembesar.
Sebuah tombol dengan kaca pembesar memungkinkan Anda memilih basis data yang diinginkan untuk dipertimbangkan.
Saat ini tidak ada sistem bantuan lengkap. Karena itu, menekan tombol “?” itu hanya akan menyebabkan munculnya jendela modal yang berisi informasi dasar tentang produk perangkat lunak:
Selain semua hal di atas, menu utama memiliki bilah pencarian:

Saat memulai proses pengoptimalan indeks:

Juga di bagian bawah jendela Anda dapat melihat log tindakan yang dilakukan:
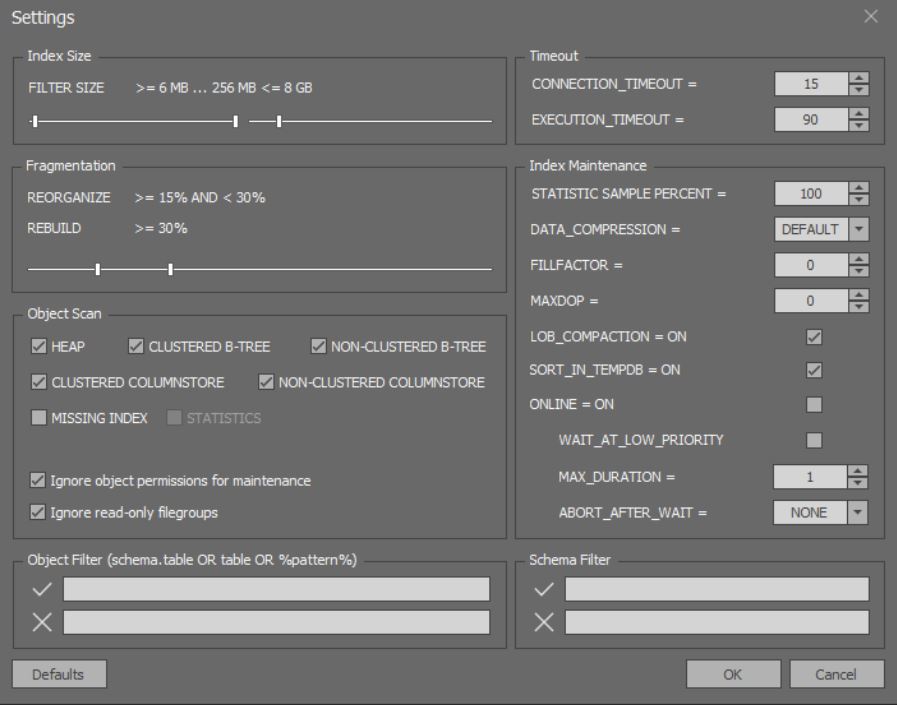
Di jendela untuk analisis terperinci dan optimalisasi indeks, Anda dapat mengonfigurasi opsi yang lebih halus:
 Saran untuk aplikasi:
Saran untuk aplikasi:- memungkinkan pembaruan statistik selektif tidak hanya untuk indeks tetapi juga dengan cara yang berbeda (sepenuhnya diperbarui atau sebagian)
- memungkinkan tidak hanya untuk memilih database, tetapi juga server yang berbeda (ini sangat nyaman ketika ada banyak contoh MS SQL Server)
- untuk fleksibilitas yang lebih besar dalam penggunaan, diusulkan untuk membungkus perintah di perpustakaan, dan mengeluarkannya ke perintah PowerShell, seperti yang dilakukan, misalnya, di sini: dbatools.io/commands
- memungkinkan untuk menyimpan dan mengubah pengaturan pribadi baik untuk seluruh aplikasi dan, jika perlu, untuk setiap instance dari MS SQL Server dan setiap database
- dari klausa 2 dan 4 mengikuti keinginan untuk membuat grup pada database dan grup pada contoh MS SQL Server, yang pengaturannya sama
- mencari indeks duplikat (penuh dan tidak lengkap, yang sedikit berbeda atau hanya berbeda dalam kolom yang disertakan)
- Karena SQLIndexManager hanya digunakan untuk DBMS MS SQL Server, Anda perlu mencerminkan ini dalam nama, misalnya, sebagai berikut: SQLIndexManager untuk MS SQL Server
- Hapus semua bagian aplikasi dari GUI ke dalam modul terpisah dan tulis ulang menjadi .NET Core 2.1
Pada saat penulisan, artikel 6 dari keinginan sedang dikembangkan secara aktif dan sudah ada dukungan dalam bentuk pencarian untuk duplikat lengkap dan serupa:
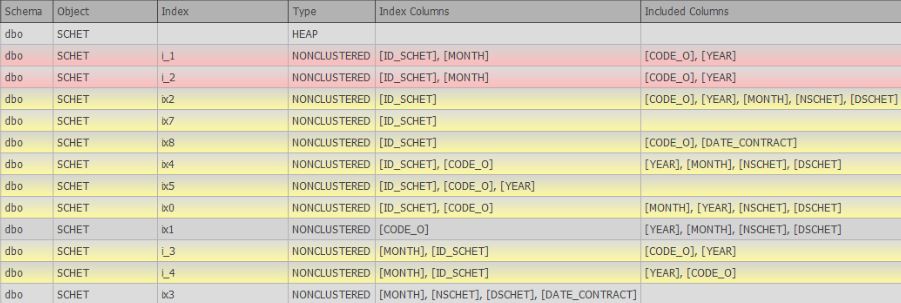
Sumber