Pengumpulan, penyimpanan, konversi, dan penyajian data adalah tantangan utama yang dihadapi para insinyur data. Departemen Badoo Intelijen Bisnis menerima dan memproses lebih dari 20 miliar peristiwa yang dikirim dari perangkat pengguna per hari, atau 2 TB data yang masuk.
Studi dan interpretasi dari semua data ini tidak selalu merupakan tugas sepele, kadang-kadang menjadi perlu untuk melampaui kemampuan database yang sudah jadi. Dan jika Anda memiliki keberanian dan memutuskan untuk melakukan sesuatu yang baru, Anda harus terlebih dahulu membiasakan diri dengan prinsip kerja dari solusi yang ada.
Singkatnya, penasaran dan pengembang yang berpikiran kuat, artikel ini ditujukan. Di dalamnya Anda akan menemukan deskripsi model tradisional pelaksanaan query di database relasional menggunakan bahasa demo PigletQL sebagai contoh.
Isi
Latar belakang
Kelompok insinyur kami terlibat dalam backend dan interface, memberikan peluang untuk analisis dan penelitian data di dalam perusahaan (omong-omong, kami memperluas ). Alat standar kami adalah database terdistribusi dari puluhan server (Exasol) dan cluster Hadoop untuk ratusan mesin (Hive dan Presto).
Sebagian besar pertanyaan pada basis data ini bersifat analitis, yaitu, memengaruhi dari ratusan ribu hingga milyaran catatan. Eksekusi mereka membutuhkan waktu beberapa menit, puluhan menit atau bahkan berjam-jam, tergantung pada solusi yang digunakan dan kompleksitas permintaan. Dengan kerja manual dari pengguna-analis, waktu seperti itu dianggap dapat diterima, tetapi tidak cocok untuk penelitian interaktif melalui antarmuka pengguna.
Seiring waktu, kami menyoroti kueri dan kueri analitik populer, yang sulit ditetapkan dalam hal SQL, dan mengembangkan basis data khusus kecil untuknya. Mereka menyimpan subset data dalam format yang sesuai untuk algoritma kompresi ringan (misalnya, streamvbyte), yang memungkinkan Anda untuk menyimpan data dalam satu mesin selama beberapa hari dan menjalankan query dalam hitungan detik.
Bahasa permintaan pertama untuk data ini dan penerjemahnya diimplementasikan pada firasat, kami harus terus-menerus memperbaikinya, dan setiap kali butuh waktu yang sangat lama.
Bahasa query tidak cukup fleksibel, meskipun tidak ada alasan yang jelas untuk membatasi kemampuan mereka. Akibatnya, kami beralih ke pengalaman pengembang penerjemah SQL, berkat itu kami dapat memecahkan sebagian masalah yang muncul.
Di bawah ini saya akan berbicara tentang model eksekusi permintaan paling umum di database relasional - Volcano. Kode sumber interpreter dari dialek SQL primitif, PigletQL , dilampirkan pada artikel , sehingga setiap orang yang tertarik dapat dengan mudah melihat detail dalam repositori.
Struktur penerjemah SQL
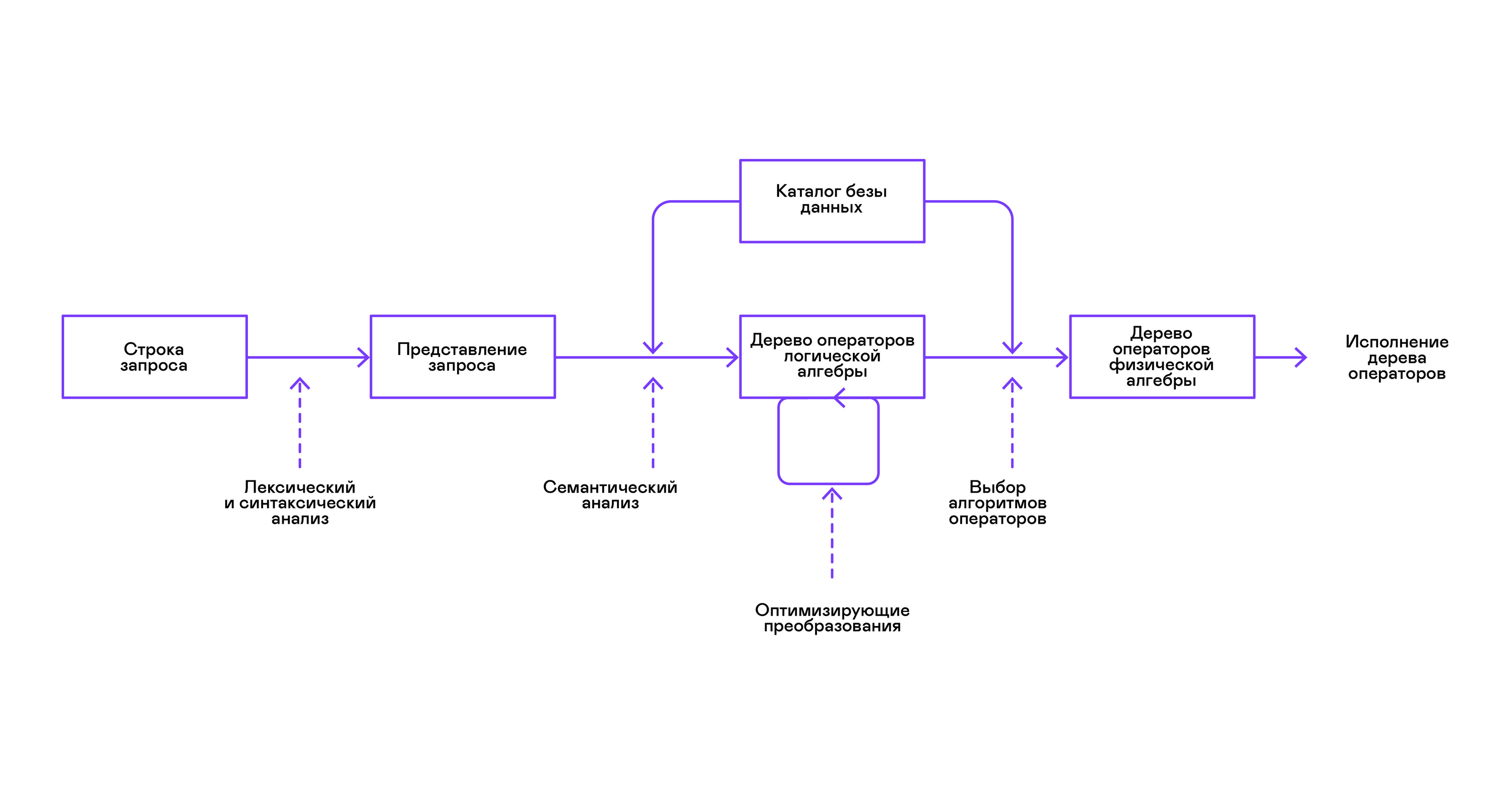
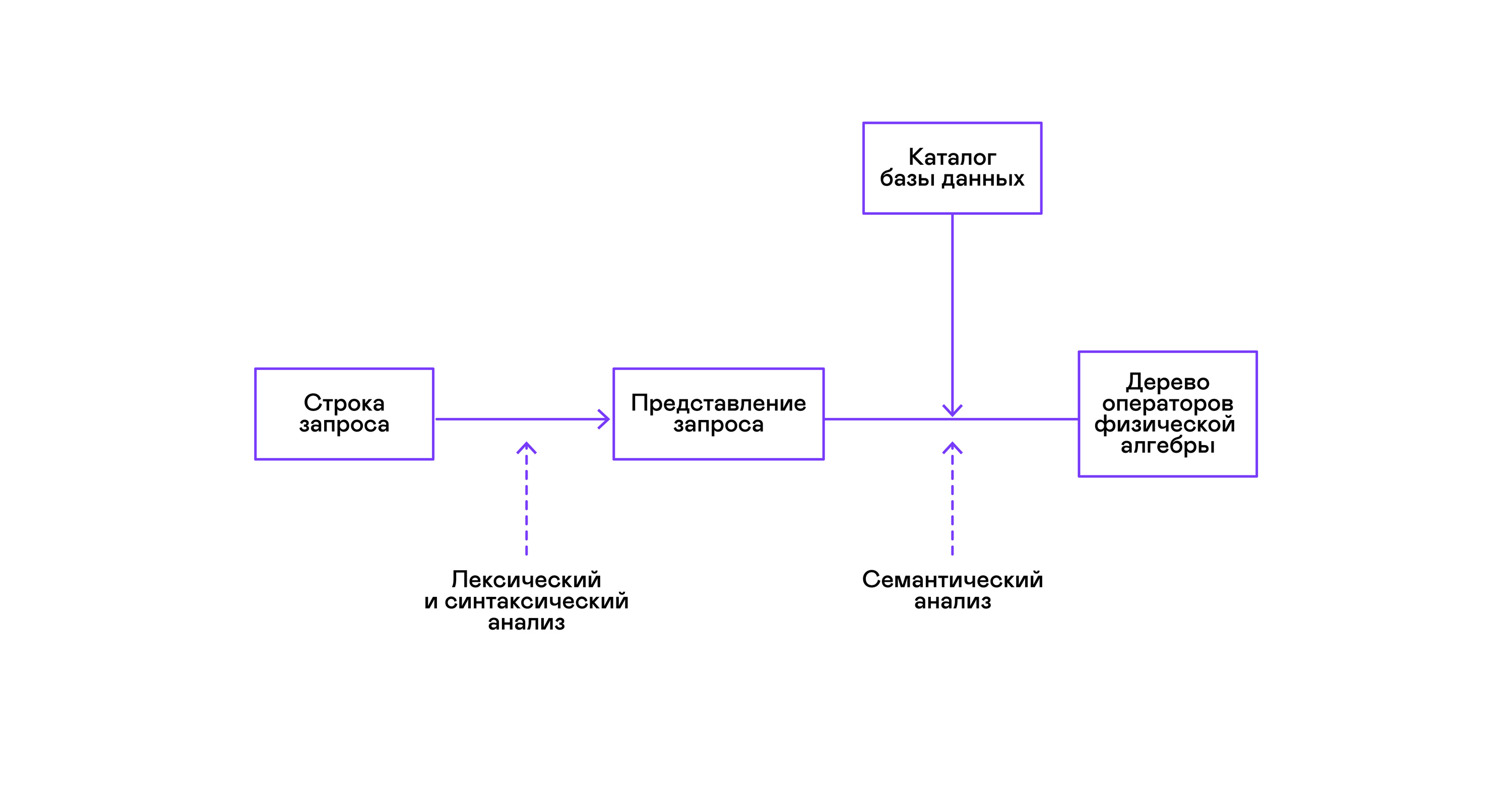
Kebanyakan basis data populer menyediakan antarmuka ke data dalam bentuk bahasa query SQL deklaratif. Kueri dalam bentuk string dikonversi oleh parser menjadi deskripsi kueri, mirip dengan pohon sintaksis abstrak. Dimungkinkan untuk mengeksekusi query sederhana yang sudah pada tahap ini, namun, untuk mengoptimalkan transformasi dan eksekusi selanjutnya, representasi ini tidak nyaman. Dalam database yang saya kenal, representasi perantara diperkenalkan untuk tujuan ini.
Aljabar relasional menjadi model untuk representasi menengah. Ini adalah bahasa di mana transformasi ( operator ) dilakukan pada data secara eksplisit dijelaskan: memilih subset data sesuai dengan predikat, menggabungkan data dari sumber yang berbeda, dll. Selain itu, aljabar relasional adalah aljabar dalam arti matematika, yaitu, sejumlah besar setara transformasi. Oleh karena itu, mudah untuk melakukan transformasi optimal atas permintaan dalam bentuk pohon operator aljabar relasional.
Ada perbedaan penting antara representasi internal dalam database dan aljabar relasional asli, sehingga lebih tepat untuk menyebutnya aljabar logis .
Verifikasi validitas kueri biasanya dilakukan ketika menyusun representasi awal kueri ke dalam operator aljabar logis dan sesuai dengan tahap analisis semantik dalam kompiler konvensional. Peran tabel simbol dalam basis data dimainkan oleh direktori basis data , yang menyimpan informasi tentang skema dan metadata basis data: tabel, kolom tabel, indeks, hak pengguna, dll.
Dibandingkan dengan interpreter tujuan umum, interpreter database memiliki satu lagi kekhasan: perbedaan dalam volume data dan meta-informasi tentang data yang seharusnya dibuat pertanyaan. Dalam tabel, atau hubungan dalam hal aljabar relasional, mungkin ada jumlah data yang berbeda, pada beberapa kolom ( atribut hubungan) indeks dapat dibangun, dll. Yaitu, tergantung pada skema database dan jumlah data dalam tabel, kueri harus dilakukan oleh algoritma yang berbeda , dan menggunakannya dalam urutan yang berbeda.
Untuk mengatasi masalah ini, representasi perantara lain diperkenalkan - aljabar fisik . Tergantung pada ketersediaan indeks pada kolom, jumlah data dalam tabel, dan struktur pohon aljabar logis, berbagai bentuk pohon aljabar fisik yang ditawarkan, dari mana pilihan terbaik dipilih. Pohon inilah yang ditampilkan ke database sebagai rencana kueri. Dalam kompiler konvensional, tahap ini secara kondisional sesuai dengan tahapan alokasi register, perencanaan, dan pemilihan instruksi.
Langkah terakhir dalam pekerjaan penerjemah adalah langsung eksekusi pohon operator aljabar fisik.
Eksekusi Model Volcano dan Query
Penerjemah pohon aljabar fisik selalu digunakan dalam database komersial tertutup, tetapi literatur akademik biasanya merujuk pada pengoptimal eksperimental Volcano, yang dikembangkan pada awal 90-an.
Dalam model Volcano, setiap operator dari pohon aljabar fisik berubah menjadi struktur dengan tiga fungsi: buka, berikutnya, tutup. Selain fungsi, operator berisi status pengoperasian. Fungsi terbuka memulai keadaan pernyataan, fungsi berikutnya mengembalikan tupel berikutnya (English tuple), atau NULL, jika tidak ada tupel yang tersisa, fungsi tutup mengakhiri pernyataan:
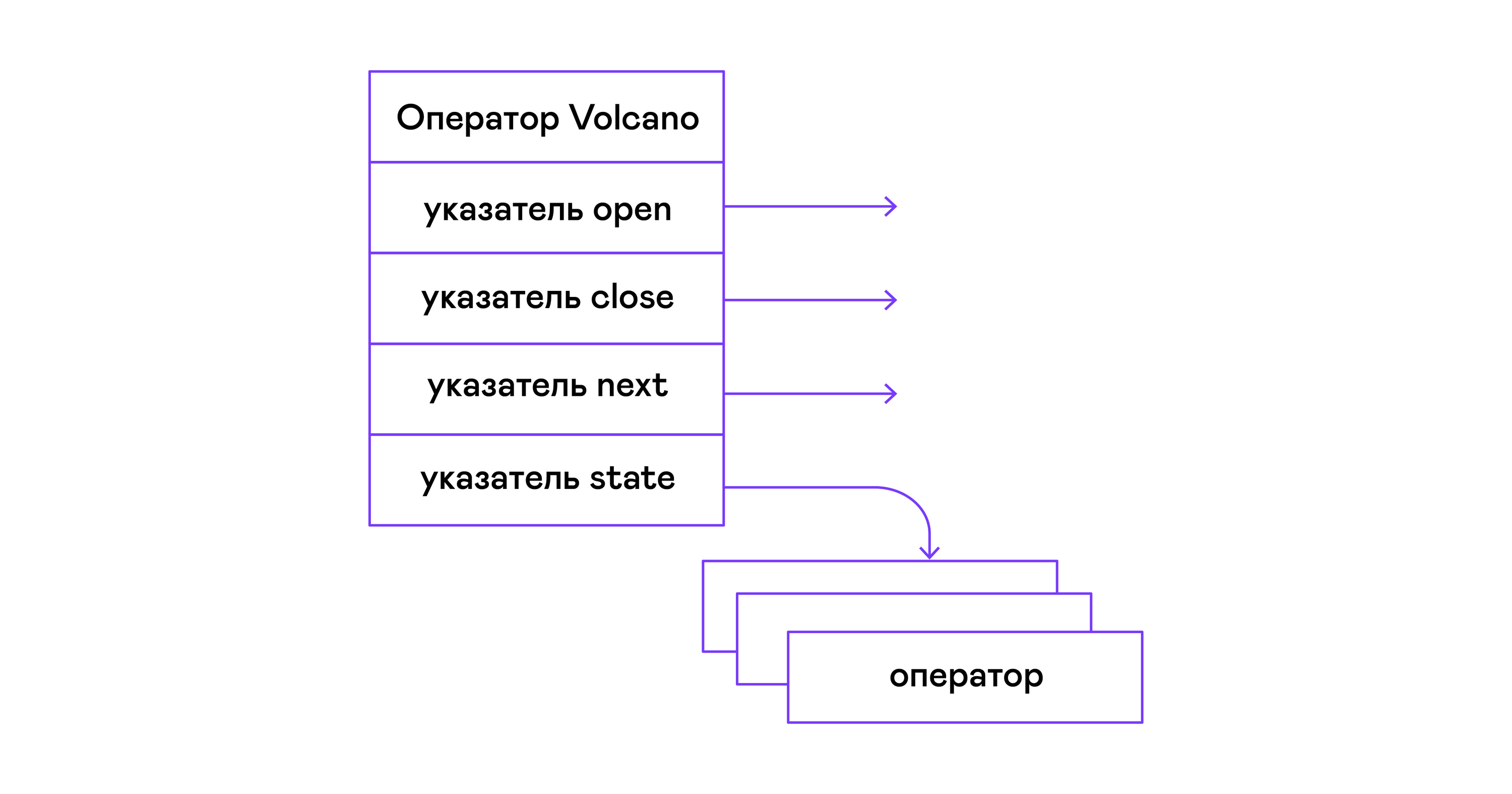
Operator dapat bersarang untuk membentuk pohon operator aljabar fisik. Setiap operator, dengan demikian, mengulangi tupel dari relasi yang ada pada media nyata atau relasi virtual yang dibentuk dengan menghitung tupel dari operator bersarang:
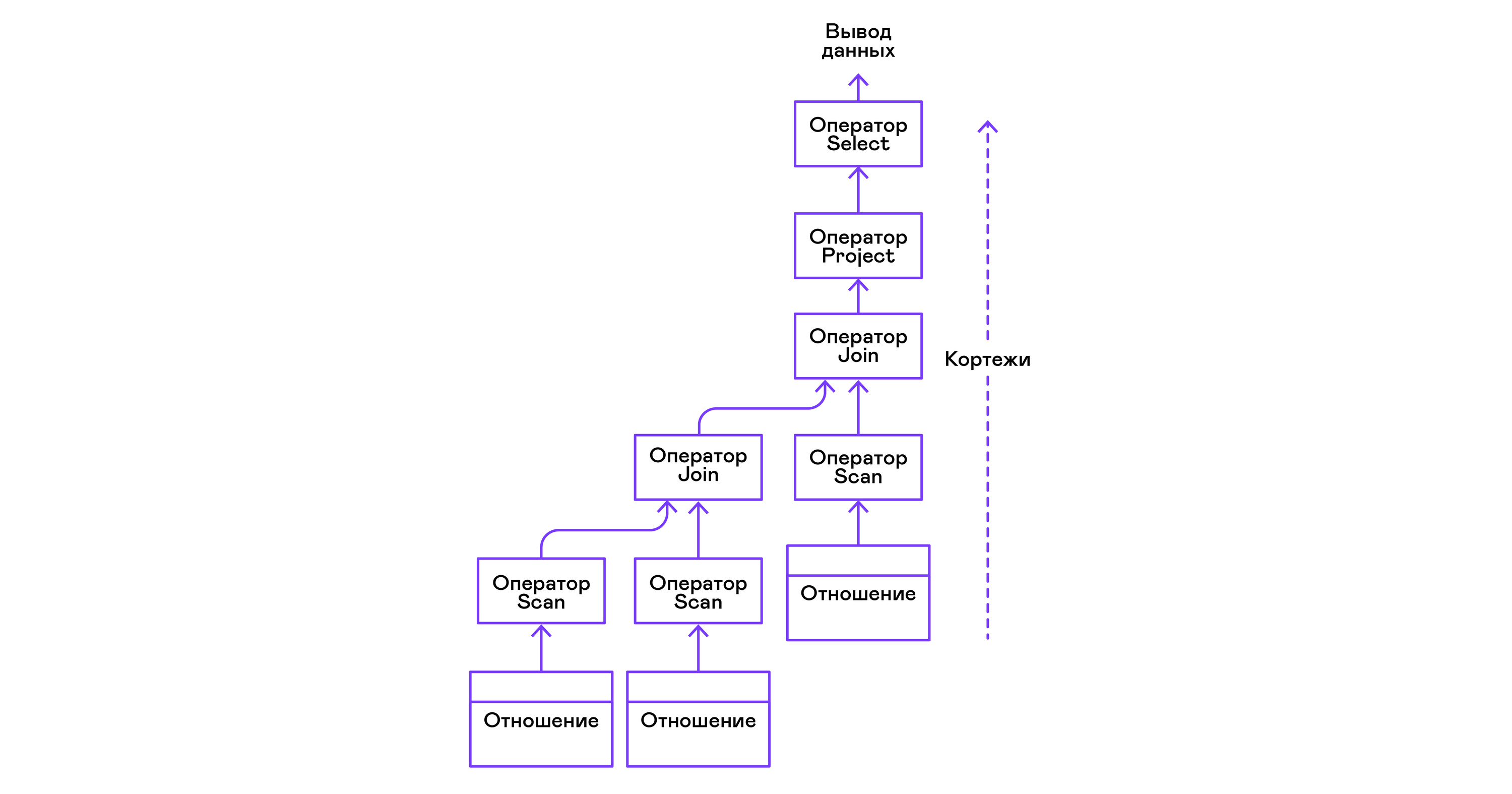
Dalam hal bahasa tingkat tinggi modern, pohon operator tersebut adalah kaskade iterator.
Bahkan interpreter permintaan industri dalam DBMS relasional ditolak dari model Volcano, jadi saya menganggapnya sebagai dasar untuk juru bahasa PigletQL.
PigletQL
Untuk mendemonstrasikan model, saya mengembangkan interpreter dari bahasa query terbatas PigletQL . Ini ditulis dalam C, mendukung pembuatan tabel dalam gaya SQL, tetapi terbatas pada satu jenis - bilangan bulat positif 32-bit. Semua tabel ada dalam memori. Sistem beroperasi dalam satu utas dan tidak memiliki mekanisme transaksi.
Tidak ada optimizer di PigletQL, dan kueri SELECT dikompilasi langsung ke pohon operator aljabar fisik. Kueri yang tersisa (CREATE TABLE dan INSERT) berfungsi langsung dari tampilan internal primer.
Contoh sesi pengguna dalam PigletQL:
> ./pigletql > CREATE TABLE tab1 (col1,col2,col3); > INSERT INTO tab1 VALUES (1,2,3); > INSERT INTO tab1 VALUES (4,5,6); > SELECT col1,col2,col3 FROM tab1; col1 col2 col3 1 2 3 4 5 6 rows: 2 > SELECT col1 FROM tab1 ORDER BY col1 DESC; col1 4 1 rows: 2
Leksikal dan parser
PigletQL adalah bahasa yang sangat sederhana, dan implementasinya tidak diperlukan pada tahap analisis leksikal dan parsing.
Alat analisis leksikal ditulis dengan tangan. Objek analyzer ( scanner_t ) dibuat dari string kueri, yang memberikan token satu per satu:
scanner_t *scanner_create(const char *string); void scanner_destroy(scanner_t *scanner); token_t scanner_next(scanner_t *scanner);
Parsing dilakukan menggunakan metode keturunan rekursif. Pertama, objek parser_t dibuat , yang, setelah menerima analisa leksikal (scanner_t), mengisi objek query_t dengan informasi tentang permintaan:
query_t *query_create(void); void query_destroy(query_t *query); parser_t *parser_create(void); void parser_destroy(parser_t *parser); bool parser_parse(parser_t *parser, scanner_t *scanner, query_t *query);
Hasil penguraian dalam query_t adalah salah satu dari tiga jenis permintaan yang didukung oleh PigletQL:
typedef enum query_tag { QUERY_SELECT, QUERY_CREATE_TABLE, QUERY_INSERT, } query_tag; typedef struct query_t { query_tag tag; union { query_select_t select; query_create_table_t create_table; query_insert_t insert; } as; } query_t;
Jenis kueri paling rumit dalam PigletQL adalah SELECT. Ini sesuai dengan struktur data query_select_t :
typedef struct query_select_t { attr_name_t attr_names[MAX_ATTR_NUM]; uint16_t attr_num; rel_name_t rel_names[MAX_REL_NUM]; uint16_t rel_num; query_predicate_t predicates[MAX_PRED_NUM]; uint16_t pred_num; bool has_order; attr_name_t order_by_attr; sort_order_t order_type; } query_select_t;
Struktur ini berisi deskripsi kueri (array atribut yang diminta oleh pengguna), daftar sumber data - hubungan, array predikat tupel pemfilteran, dan informasi tentang atribut yang digunakan untuk mengurutkan hasil.
Penganalisis semantik
Fase analisis semantik dalam SQL biasa melibatkan memeriksa keberadaan tabel yang terdaftar, kolom dalam tabel, dan ketik memeriksa ekspresi kueri. Untuk pemeriksaan terkait dengan tabel dan kolom, direktori basis data digunakan, tempat semua informasi tentang struktur data disimpan.
Tidak ada ekspresi kompleks di PigletQL, jadi pengecekan kueri dikurangi menjadi pengecekan metadata katalog tabel dan kolom. Kueri SELECT, misalnya, divalidasi oleh fungsi validate_select . Saya akan membawanya dalam bentuk singkat:
static bool validate_select(catalogue_t *cat, const query_select_t *query) { for (size_t rel_i = 0; rel_i < query->rel_num; rel_i++) { if (catalogue_get_relation(cat, query->rel_names[rel_i])) continue; fprintf(stderr, "Error: relation '%s' does not exist\n", query->rel_names[rel_i]); return false; } if (!rel_names_unique(query->rel_names, query->rel_num)) return false; if (!attr_names_unique(query->attr_names, query->attr_num)) return false; return true; }
Jika permintaan tersebut valid, maka langkah selanjutnya adalah mengkompilasi parse tree menjadi tree operator.
Mengkompilasi Pertanyaan ke Tampilan Menengah
Dalam penerjemah SQL penuh, biasanya ada dua representasi menengah: aljabar logis dan fisik.
Seorang juru bahasa PigletQL sederhana melakukan CREATE TABLE dan INSERT queries langsung dari pohon parsing, yaitu, query_create_table_t dan struktur query_insert_t . Permintaan SELECT yang lebih kompleks dikompilasi menjadi representasi perantara tunggal, yang akan dieksekusi oleh penerjemah.
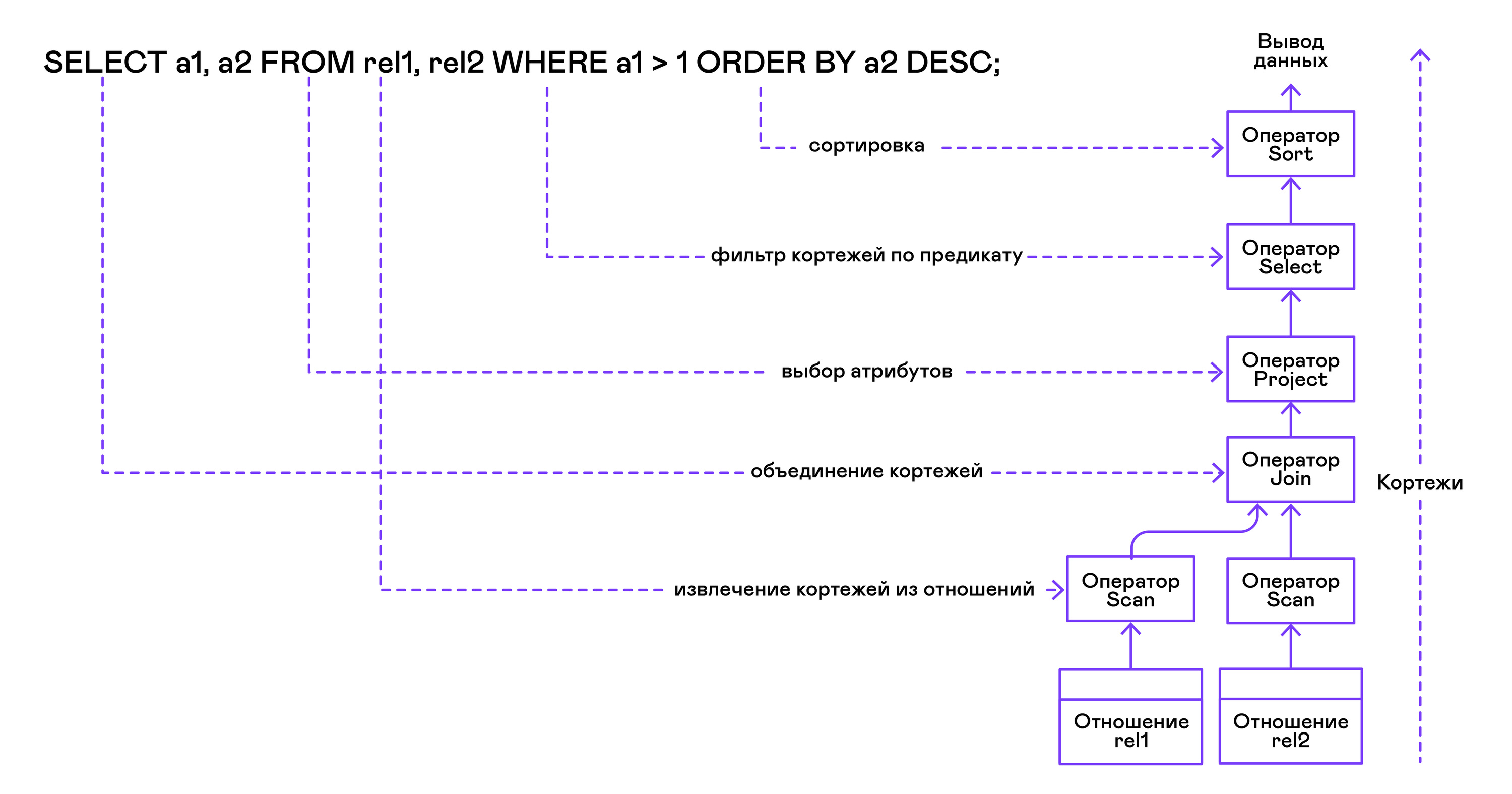
Pohon operator dibuat dari daun ke akar dalam urutan berikut:
Dari bagian kanan kueri ("... FROM relation1, relation2, ..."), nama-nama relasi yang diinginkan diperoleh, untuk masing-masing pernyataan pemindaian dibuat.
Mengekstrak tupel dari relasi, operator pemindaian digabungkan menjadi pohon biner sisi kiri melalui operator gabungan.
Atribut yang diminta oleh pengguna ("SELECT attr1, attr2, ...") dipilih oleh pernyataan proyek.
Jika ada predikat ditentukan ("... WHERE a = 1 AND b> 10 ..."), maka pernyataan pilih ditambahkan ke pohon di atas.
Jika metode untuk menyortir hasil ditentukan ("... ORDER BY attr1 DESC"), maka operator penyortiran ditambahkan ke bagian atas pohon.
Kompilasi dalam kode PigletQL:
operator_t *compile_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = NULL; { size_t rel_i = 0; relation_t *rel = catalogue_get_relation(cat, query->rel_names[rel_i]); root_op = scan_op_create(rel); rel_i += 1; for (; rel_i < query->rel_num; rel_i++) { rel = catalogue_get_relation(cat, query->rel_names[rel_i]); operator_t *scan_op = scan_op_create(rel); root_op = join_op_create(root_op, scan_op); } } root_op = proj_op_create(root_op, query->attr_names, query->attr_num); if (query->pred_num > 0) { operator_t *select_op = select_op_create(root_op); for (size_t pred_i = 0; pred_i < query->pred_num; pred_i++) { query_predicate_t predicate = query->predicates[pred_i]; } root_op = select_op; } if (query->has_order) root_op = sort_op_create(root_op, query->order_by_attr, query->order_type); return root_op; }
Setelah pohon terbentuk, transformasi optimasi biasanya dilakukan, tetapi PigletQL segera melanjutkan ke tahap pelaksanaan representasi perantara.
Eksekusi presentasi sementara
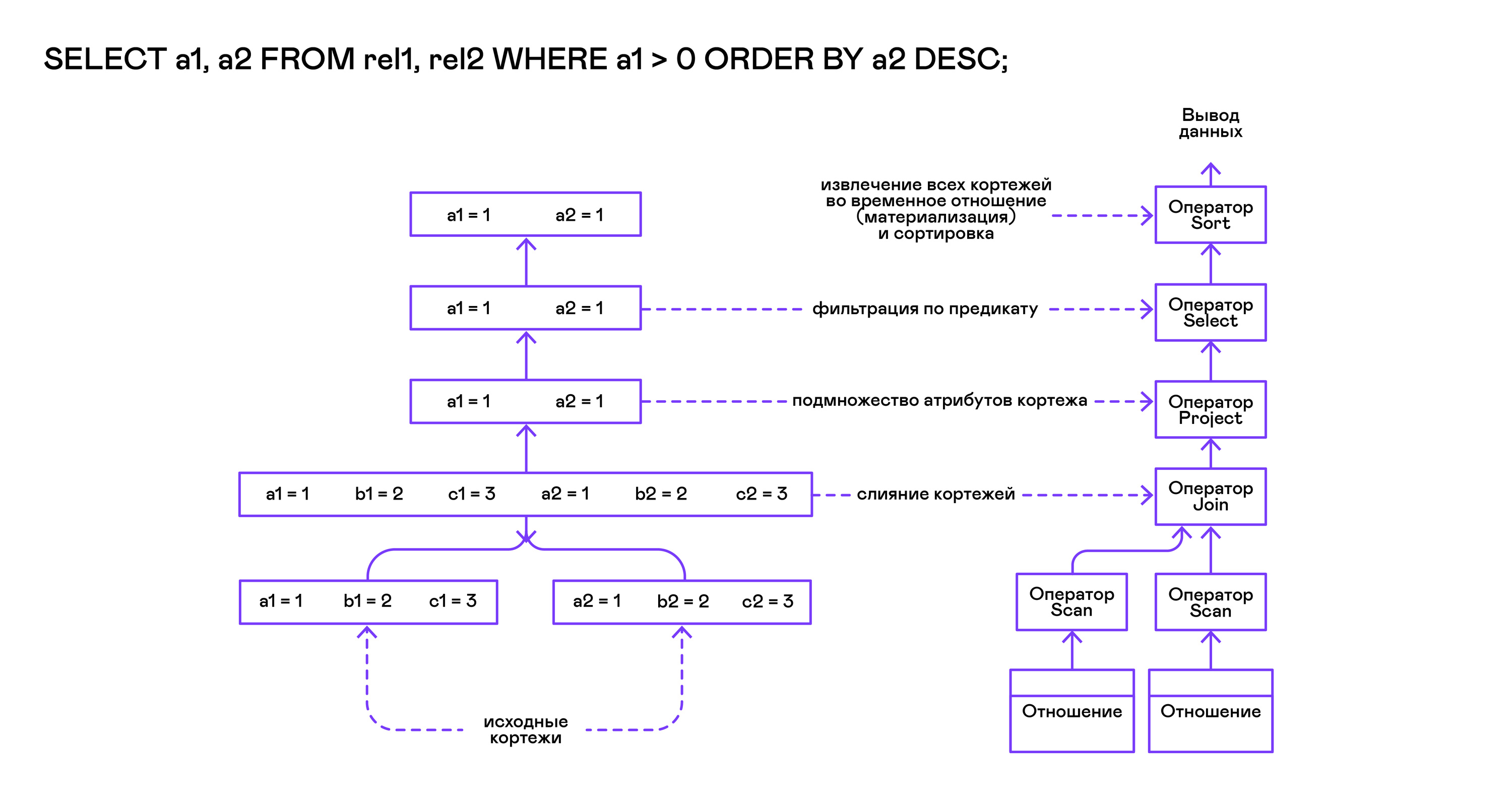
Model Volcano menyiratkan antarmuka untuk bekerja dengan operator melalui tiga operasi terbuka / berikutnya / penutupan umum. Intinya, setiap pernyataan Volcano adalah sebuah iterator yang darinya tupel "ditarik" satu per satu, sehingga pendekatan eksekusi ini juga disebut model tarik.
Masing-masing iterator itu sendiri dapat memanggil fungsi iterator bersarang yang sama, membuat tabel sementara dengan hasil antara, dan mengonversi tupel yang masuk.
Mengeksekusi kueri SELECT dalam PigletQL:
bool eval_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = compile_select(cat, query); { root_op->open(root_op->state); size_t tuples_received = 0; tuple_t *tuple = NULL; while((tuple = root_op->next(root_op->state))) { if (tuples_received == 0) dump_tuple_header(tuple); dump_tuple(tuple); tuples_received++; } printf("rows: %zu\n", tuples_received); root_op->close(root_op->state); } root_op->destroy(root_op); return true; }
Permintaan pertama dikompilasi oleh fungsi compile_select, yang mengembalikan root dari pohon operator, setelah itu fungsi buka / berikutnya / tutup yang sama dipanggil pada operator root. Setiap panggilan ke berikutnya mengembalikan tuple berikutnya atau NULL. Dalam kasus terakhir, ini berarti bahwa semua tupel telah diekstraksi, dan fungsi iterator yang dekat harus dipanggil.
Tupel yang dihasilkan dihitung ulang dan output oleh tabel ke aliran output standar.
Operator
Hal yang paling menarik tentang PigletQL adalah pohon operator. Saya akan menunjukkan perangkat beberapa dari mereka.
Operator memiliki antarmuka umum dan terdiri dari pointer ke fungsi buka / berikutnya / tutup dan fungsi penghancuran tambahan, yang melepaskan sumber daya dari seluruh pohon operator sekaligus:
typedef void (*op_open)(void *state); typedef tuple_t *(*op_next)(void *state); typedef void (*op_close)(void *state); typedef void (*op_destroy)(operator_t *op); struct operator_t { op_open open; op_next next; op_close close; op_destroy destroy; void *state; } ;
Selain fungsi, operator dapat berisi keadaan internal yang sewenang-wenang (penunjuk keadaan).
Di bawah ini saya akan menganalisis perangkat dari dua operator yang menarik: pemindaian paling sederhana dan membuat semacam hubungan perantara.
Pernyataan pemindaian
Pernyataan yang memulai kueri apa pun adalah pemindaian. Dia hanya melewati semua tupel hubungan. Keadaan internal pemindaian adalah penunjuk ke relasi tempat tupel akan diambil, indeks tupel berikutnya dalam relasi, dan struktur tautan ke tupel saat ini yang diteruskan ke pengguna:
typedef struct scan_op_state_t { const relation_t *relation; uint32_t next_tuple_i; tuple_t current_tuple; } scan_op_state_t;
Untuk membuat status pernyataan pemindaian, Anda memerlukan relasi sumber; segala sesuatu yang lain (pointer ke fungsi yang sesuai) sudah diketahui:
operator_t *scan_op_create(const relation_t *relation) { operator_t *op = calloc(1, sizeof(*op)); assert(op); *op = (operator_t) { .open = scan_op_open, .next = scan_op_next, .close = scan_op_close, .destroy = scan_op_destroy, }; scan_op_state_t *state = calloc(1, sizeof(*state)); assert(state); *state = (scan_op_state_t) { .relation = relation, .next_tuple_i = 0, .current_tuple.tag = TUPLE_SOURCE, .current_tuple.as.source.tuple_i = 0, .current_tuple.as.source.relation = relation, }; op->state = state; return op; }
Buka / tutup operasi dalam kasus tautan setel ulang pindai kembali ke elemen pertama hubungan:
void scan_op_open(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; } void scan_op_close(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; }
Panggilan berikutnya akan mengembalikan tupel berikutnya, atau NULL jika tidak ada lagi tupel dalam relasi:
tuple_t *scan_op_next(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; if (op_state->next_tuple_i >= op_state->relation->tuple_num) return NULL; tuple_source_t *source_tuple = &op_state->current_tuple.as.source; source_tuple->tuple_i = op_state->next_tuple_i; op_state->next_tuple_i++; return &op_state->current_tuple; }
Sortir pernyataan
Pernyataan sortir menghasilkan tupel dalam urutan yang ditentukan oleh pengguna. Untuk melakukan ini, buat hubungan sementara dengan tupel yang diperoleh dari operator bersarang dan urutkan.
Keadaan internal operator:
typedef struct sort_op_state_t { operator_t *source; attr_name_t sort_attr_name; sort_order_t sort_order; relation_t *tmp_relation; operator_t *tmp_relation_scan_op; } sort_op_state_t;
Penyortiran dilakukan sesuai dengan atribut yang ditentukan dalam permintaan (sort_attr_name dan sort_order) atas rasio waktu (tmp_relation). Semua ini terjadi ketika fungsi terbuka disebut:
void sort_op_open(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; operator_t *source = op_state->source; source->open(source->state); tuple_t *tuple = NULL; while((tuple = source->next(source->state))) { if (!op_state->tmp_relation) { op_state->tmp_relation = relation_create_for_tuple(tuple); assert(op_state->tmp_relation); op_state->tmp_relation_scan_op = scan_op_create(op_state->tmp_relation); } relation_append_tuple(op_state->tmp_relation, tuple); } source->close(source->state); relation_order_by(op_state->tmp_relation, op_state->sort_attr_name, op_state->sort_order); op_state->tmp_relation_scan_op->open(op_state->tmp_relation_scan_op->state); }
Pencacahan elemen hubungan sementara dilakukan oleh operator sementara tmp_relation_scan_op:
tuple_t *sort_op_next(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; return op_state->tmp_relation_scan_op->next(op_state->tmp_relation_scan_op->state);; }
Hubungan sementara dinonaktifkan dalam fungsi dekat:
void sort_op_close(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; if (op_state->tmp_relation) { op_state->tmp_relation_scan_op->close(op_state->tmp_relation_scan_op->state); scan_op_destroy(op_state->tmp_relation_scan_op); relation_destroy(op_state->tmp_relation); op_state->tmp_relation = NULL; } }
Di sini Anda dapat melihat dengan jelas mengapa menyortir operasi pada kolom tanpa indeks bisa memakan banyak waktu.
Contoh kerja
Saya akan memberikan beberapa contoh pertanyaan PigletQL dan pohon terkait dari aljabar fisik.
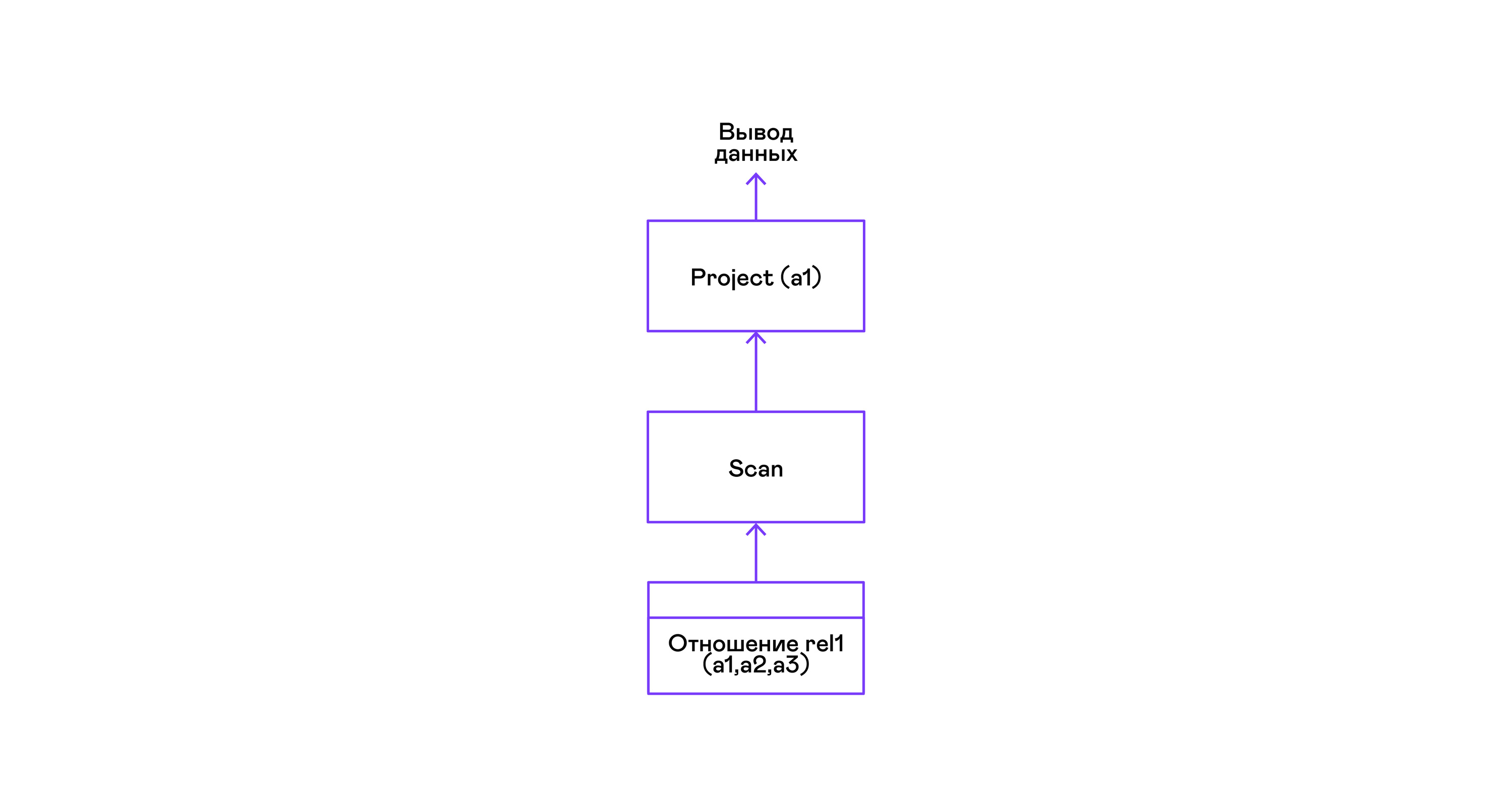
Contoh paling sederhana di mana semua tupel dari relasi dipilih:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1; a1 1 4 rows: 2 >
Untuk kueri yang paling sederhana, hanya mengambil tupel dari relasi pemindaian yang digunakan, dan memilih satu-satunya atribut proyek dari tupel:
Memilih tupel dengan predikat:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 where a1 > 3; a1 4 rows: 1 >
Predikat diekspresikan oleh pernyataan pilih:
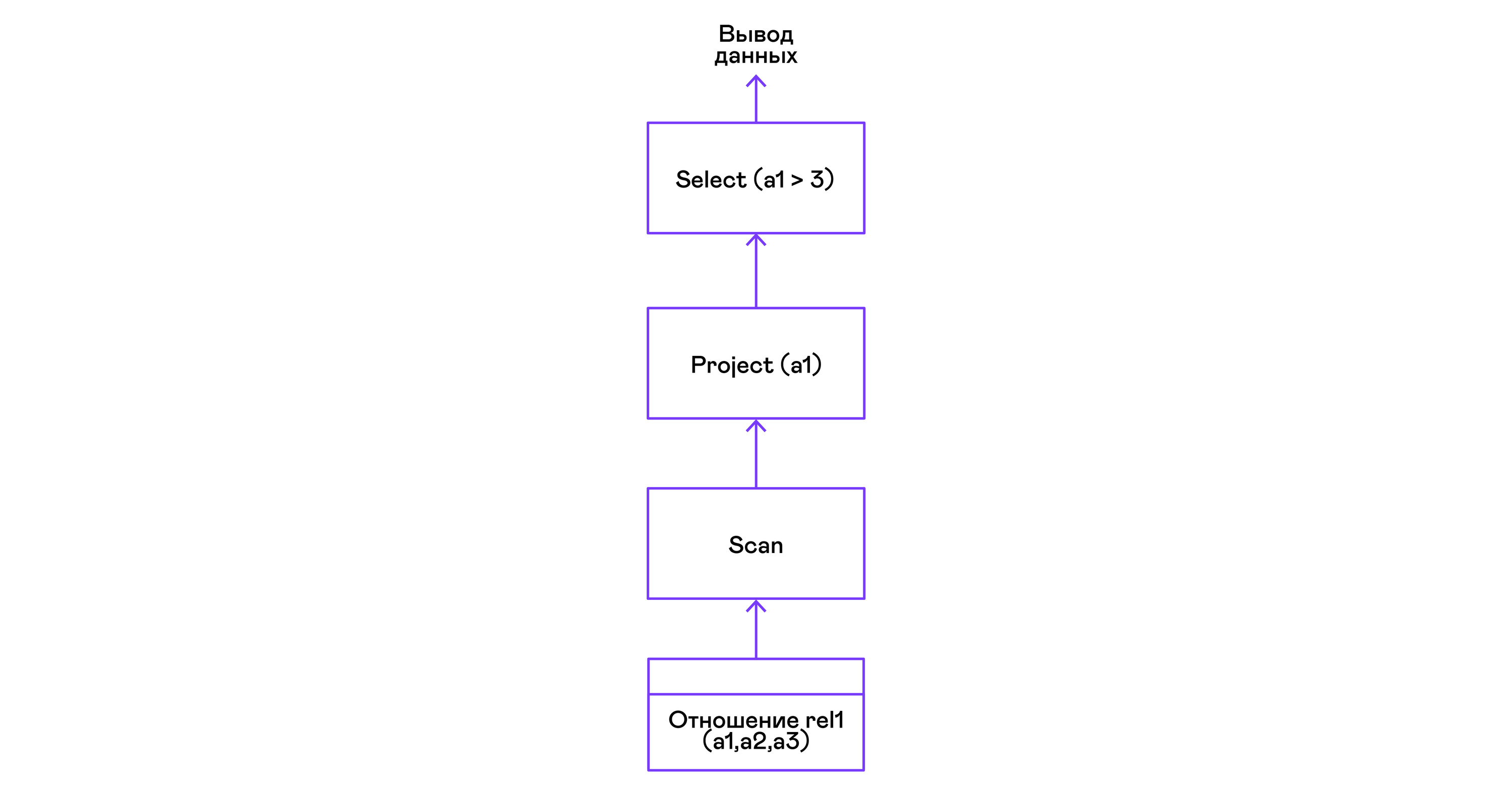
Pilihan tupel dengan penyortiran:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 order by a1 desc; a1 4 1 rows: 2
Operator sortir dalam panggilan terbuka menciptakan ( mematerialisasi ) hubungan sementara, menempatkan semua tupel yang masuk di sana, dan menyortir keseluruhannya. Setelah itu, dalam panggilan berikutnya, ia menyimpulkan tupel dari hubungan sementara dalam urutan yang ditentukan oleh pengguna:

Menggabungkan tupel dua hubungan dengan predikat:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > create table rel2 (a4,a5,a6); > insert into rel2 values (7,8,6); > insert into rel2 values (9,10,6); > select a1,a2,a3,a4,a5,a6 from rel1, rel2 where a3=a6; a1 a2 a3 a4 a5 a6 4 5 6 7 8 6 4 5 6 9 10 6 rows: 2
Operator gabungan di PigletQL tidak menggunakan algoritme kompleks apa pun, tetapi cukup membentuk produk Cartesian dari kumpulan tupel subpohon kiri dan kanan. Ini sangat tidak efisien, tetapi untuk penerjemah demo, ini akan berhasil:
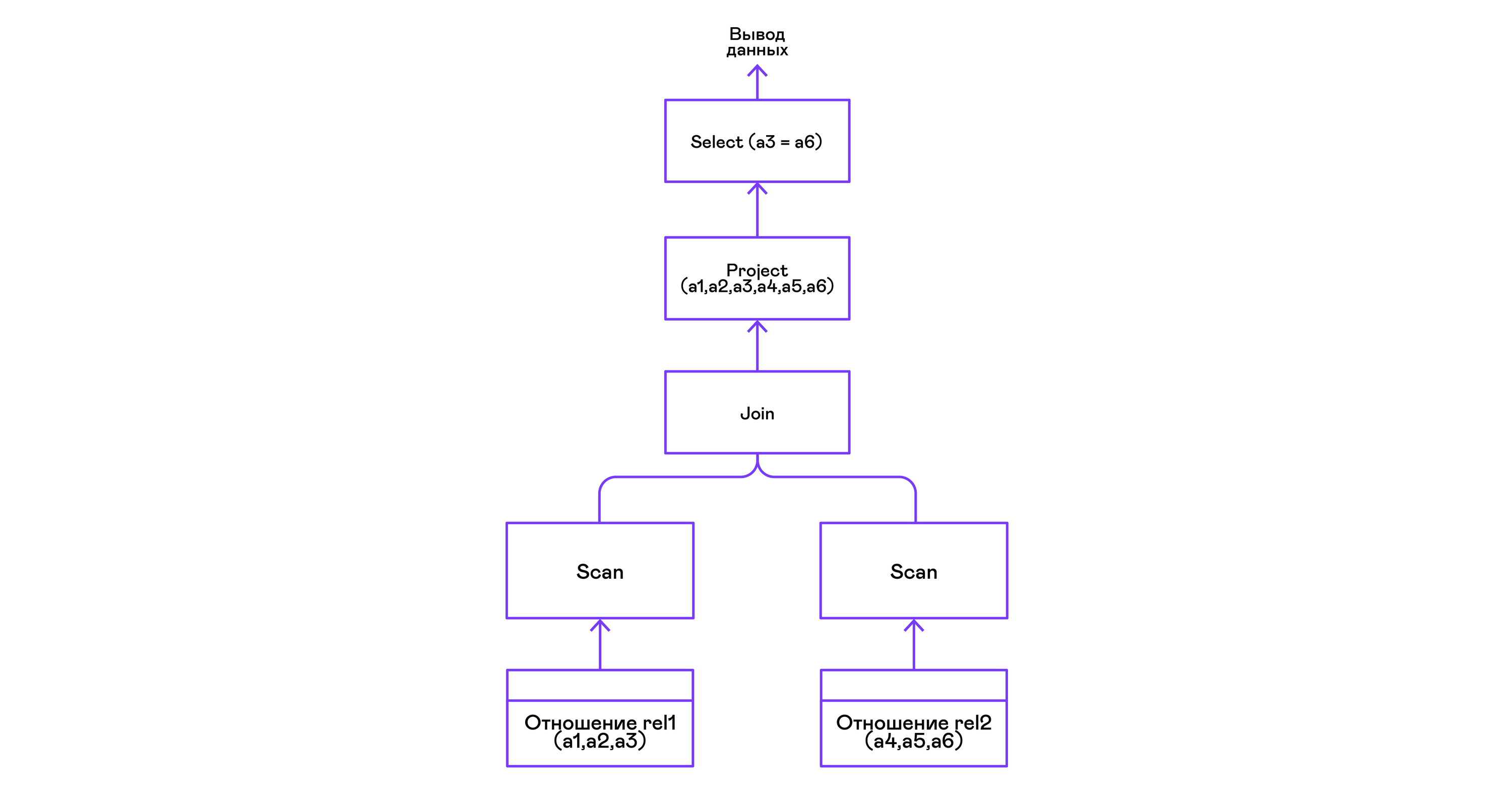
Kesimpulan
Sebagai kesimpulan, saya perhatikan bahwa jika Anda membuat juru bahasa yang mirip dengan SQL, maka Anda mungkin harus mengambil salah satu dari banyak basis data relasional yang tersedia. Ribuan orang-tahun telah diinvestasikan dalam pengoptimal dan pengalih permintaan modern dari basis data populer, dan butuh bertahun-tahun untuk mengembangkan bahkan basis data keperluan umum yang paling sederhana.
Bahasa demo PigletQL meniru karya penerjemah SQL, tetapi dalam kenyataannya kami hanya menggunakan elemen individu dari arsitektur Volcano dan hanya untuk itu (jarang!) Jenis pertanyaan yang sulit untuk diungkapkan dalam kerangka model relasional.
Namun demikian, saya ulangi: bahkan seorang kenalan dangkal dengan arsitektur penerjemah seperti itu berguna dalam kasus-kasus di mana perlu untuk bekerja secara fleksibel dengan aliran data.
Sastra
Jika Anda tertarik pada masalah dasar pengembangan basis data, maka buku lebih baik daripada “Implementasi sistem basis data” (Garcia-Molina H., Ullman JD, Widom J., 2000), Anda tidak akan menemukannya.
Satu-satunya kelemahan adalah orientasi teoretis. Secara pribadi, saya suka ketika contoh konkret kode atau bahkan proyek demo dilampirkan ke materi. Untuk ini, Anda bisa merujuk ke buku "Perancangan dan implementasi basis data" (Sciore E., 2008), yang menyediakan kode lengkap untuk basis data relasional di Jawa.
Database relasional paling populer masih menggunakan variasi pada tema Volcano. Publikasi asli ditulis dalam bahasa yang sangat mudah diakses dan dapat dengan mudah ditemukan di Google Cendekia: "Gunung berapi - sistem evaluasi kueri paralel dan diperluas" (Graefe G., 1994).
Meskipun SQL interpreter telah berubah sedikit lebih detail selama beberapa dekade terakhir, struktur yang sangat umum dari sistem ini tidak berubah untuk waktu yang sangat lama. Anda bisa mendapatkan ide dari makalah ulasan oleh penulis yang sama, "Teknik evaluasi kueri untuk database besar" (Graefe G. 1993).