Terjemahan disiapkan untuk siswa dari kursus "Analisis Terapan pada R" .
Ini adalah upaya pertama saya untuk mengelompokkan klien berdasarkan data nyata, dan itu memberi saya pengalaman berharga. Ada banyak artikel di Internet tentang pengelompokan menggunakan variabel numerik, tetapi menemukan solusi untuk data kategorikal, yang agak lebih sulit, tidak begitu sederhana. Metode pengelompokan untuk data kategorikal masih dalam pengembangan, dan di pos lain saya akan mencoba yang lain.
Di sisi lain, banyak orang percaya bahwa pengelompokan data kategorikal mungkin tidak menghasilkan hasil yang bermakna - dan ini sebagian benar (lihat
diskusi yang sangat baik tentang CrossValidated ). Pada satu titik, saya berpikir: “Apa yang saya lakukan? Mereka dapat dengan mudah dibagi menjadi beberapa kelompok. ” Namun, analisis kohort juga tidak selalu disarankan, terutama dengan sejumlah besar variabel kategori dengan sejumlah besar level: Anda dapat dengan mudah menangani 5-7 kohort, tetapi jika Anda memiliki 22 variabel dan masing-masing memiliki 5 level (misalnya, survei pelanggan dengan perkiraan terpisah 1 , 2, 3, 4 dan 5), dan Anda perlu memahami kelompok karakteristik apa dari klien yang Anda hadapi - Anda akan mendapatkan 22x5 kohort. Tidak ada yang mau repot dengan tugas seperti itu. Dan di sini pengelompokan bisa membantu. Jadi dalam posting ini saya akan berbicara tentang apa yang ingin saya ketahui segera setelah saya mulai mengelompokkan.
Proses pengelompokan itu sendiri terdiri dari tiga langkah:
- Membangun matriks ketidaksamaan tidak diragukan lagi adalah keputusan paling penting dalam pengelompokan. Semua langkah selanjutnya akan didasarkan pada matriks ketidaksamaan yang Anda buat.
- Pilihan metode pengelompokan.
- Evaluasi Cluster.
Posting ini akan menjadi semacam pengantar yang menjelaskan prinsip-prinsip dasar pengelompokan dan implementasinya di lingkungan R.
Matriks dissimilaritas
Dasar pengelompokan akan menjadi matriks ketidaksamaan, yang dalam istilah matematika menggambarkan betapa berbedanya titik-titik dalam kumpulan data (dihapus) dari satu sama lain. Ini memungkinkan Anda untuk lebih lanjut menggabungkan dalam kelompok titik-titik yang paling dekat satu sama lain, atau untuk memisahkan yang paling jauh satu sama lain - ini adalah gagasan utama pengelompokan.
Pada tahap ini, perbedaan antara tipe data adalah penting, karena matriks ketidaksamaan didasarkan pada jarak antara titik data individu. Mudah untuk membayangkan jarak antara titik-titik data numerik (contoh yang terkenal adalah
jarak Euclidean ), tetapi dalam kasus data kategorikal (faktor dalam R), semuanya tidak begitu jelas.
Untuk membangun matriks ketidaksamaan dalam hal ini, yang disebut jarak Gover harus digunakan. Saya tidak akan mempelajari bagian matematika dari konsep ini, saya hanya akan memberikan tautan:
di sana -
sini . Untuk ini, saya lebih suka menggunakan
daisy() dengan
metric = c("gower") dari paket
cluster .
Matriks ketidaksamaan siap. Untuk 200 pengamatan, ini dibangun dengan cepat, tetapi mungkin membutuhkan perhitungan yang sangat besar jika Anda berurusan dengan kumpulan data yang besar.
Dalam praktiknya, sangat mungkin Anda pertama-tama harus membersihkan set data, melakukan transformasi yang diperlukan dari baris menjadi faktor, dan melacak nilai yang hilang. Dalam kasus saya, kumpulan data juga berisi deretan nilai-nilai yang hilang yang indah mengelompok setiap kali, jadi sepertinya itu adalah harta - sampai saya melihat nilai-nilai (sayangnya!).
Algoritma Clustering
Anda mungkin sudah tahu bahwa pengelompokan adalah
k-means dan hierarkis . Dalam posting ini, saya fokus pada metode kedua, karena lebih fleksibel dan memungkinkan berbagai pendekatan: Anda dapat memilih algoritma pengelompokan
aglomeratif (dari bawah ke atas) atau
divisi (atas ke bawah).
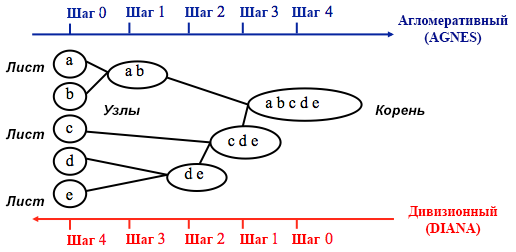 Sumber: Panduan Pemrograman UC Business Analytics R
Sumber: Panduan Pemrograman UC Business Analytics RPengelompokan aglomeratif dimulai dengan
n cluster, di mana
n adalah jumlah pengamatan: diasumsikan bahwa masing-masing dari mereka adalah cluster yang terpisah. Kemudian algoritma mencoba untuk menemukan dan mengelompokkan titik data yang paling mirip di antara mereka sendiri - ini adalah bagaimana pembentukan cluster dimulai.
Clustering divisi dilakukan dengan cara yang berlawanan - pada awalnya diasumsikan bahwa semua n titik data yang kita miliki adalah satu cluster besar, dan kemudian yang paling mirip dibagi menjadi kelompok-kelompok yang terpisah.
Ketika memutuskan metode mana yang harus dipilih, selalu masuk akal untuk mencoba semua opsi, namun, secara umum,
pengelompokan aglomeratif lebih baik untuk mengidentifikasi kelompok kecil dan digunakan oleh sebagian besar program komputer, dan pengelompokan divisi lebih cocok untuk mengidentifikasi kelompok besar .
Secara pribadi, sebelum memutuskan metode mana yang akan digunakan, saya lebih suka melihat dendrogram - representasi grafis dari clustering. Seperti yang akan Anda lihat nanti, beberapa dendrogram sangat seimbang, sementara yang lain sangat kacau.
# Input utama untuk kode di bawah ini adalah ketidaksamaan (matriks jarak)
Penilaian Kualitas Clustering
Pada tahap ini, perlu untuk memilih antara algoritma clustering yang berbeda dan jumlah cluster yang berbeda. Anda dapat menggunakan berbagai metode penilaian, tidak lupa dibimbing oleh
akal sehat . Saya menggarisbawahi kata-kata ini dalam huruf tebal dan miring, karena kebermaknaan pilihan
sangat penting - jumlah kelompok dan metode pembagian data ke dalam kelompok harus praktis dari sudut pandang praktis. Jumlah kombinasi nilai-nilai variabel kategorik adalah terbatas (karena mereka diskrit), tetapi tidak ada gangguan berdasarkan mereka akan bermakna. Anda mungkin juga tidak ingin memiliki sangat sedikit cluster - dalam hal ini mereka akan terlalu digeneralisasi. Pada akhirnya, itu semua tergantung pada tujuan Anda dan tugas analisis.
Secara umum, saat membuat cluster, Anda tertarik untuk memperoleh kelompok titik data yang terdefinisi dengan jelas, sehingga jarak antara titik-titik tersebut dalam kelompok (
atau kekompakan ) minimal, dan jarak antara kelompok (
pemisahan ) semaksimal mungkin. Ini mudah dipahami secara intuitif: jarak antar titik adalah ukuran ketidaksamaan mereka, yang diperoleh berdasarkan matriks ketidaksamaan. Dengan demikian, penilaian kualitas clustering didasarkan pada penilaian kekompakan dan keterpisahan.
Selanjutnya, saya akan menunjukkan dua pendekatan dan menunjukkan bahwa salah satunya dapat memberikan hasil yang tidak berarti.
- Metode siku : mulailah dengan itu jika faktor yang paling penting untuk analisis Anda adalah kekompakan cluster, yaitu kesamaan dalam kelompok.
- Metode Penilaian Siluet : Grafik siluet yang digunakan sebagai ukuran konsistensi data menunjukkan seberapa dekat masing-masing titik dalam satu kluster dengan titik-titik dalam kelompok tetangga.
Dalam praktiknya, kedua metode ini sering memberikan hasil yang berbeda, yang dapat menyebabkan kebingungan - kekompakan maksimum dan pemisahan paling jelas akan dicapai dengan jumlah cluster yang berbeda, sehingga akal sehat dan pemahaman tentang apa yang sebenarnya berarti data Anda akan memainkan peran penting saat membuat keputusan akhir.
Ada juga sejumlah metrik yang dapat Anda analisis. Saya akan menambahkannya langsung ke kode.
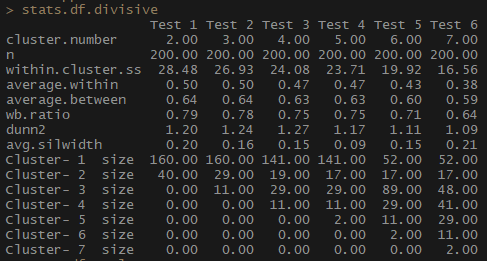
Jadi, indikator average.within, yang mewakili jarak rata-rata antara pengamatan di dalam cluster, berkurang, seperti halnya di dalam.cluster.ss (jumlah kuadrat dari jarak antara pengamatan dalam sebuah cluster). Lebar rata-rata siluet (avg.silwidth) bervariasi tidak begitu jelas, namun, hubungan terbalik masih dapat dilihat.
Perhatikan bagaimana ukuran cluster yang tidak proporsional. Saya tidak akan tergesa-gesa bekerja dengan jumlah pengamatan yang tidak ada bandingannya. Salah satu alasannya adalah bahwa kumpulan data mungkin tidak seimbang, dan beberapa kelompok pengamatan akan melebihi semua yang lain dalam analisis - ini tidak baik dan kemungkinan besar akan menyebabkan kesalahan.
stats.df.aggl <-cstats.table(gower.dist, aggl.clust.c, 7) #stats.df.aggl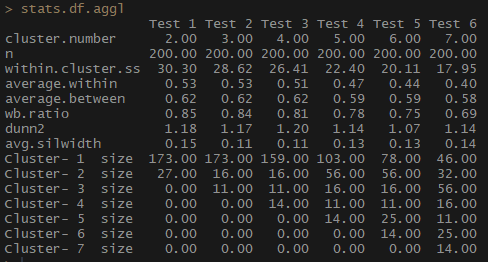
Perhatikan betapa jauh lebih baik jumlah pengamatan per kelompok diseimbangkan dengan pengelompokan hierarkis aglomeratif berdasarkan metode komunikasi penuh.
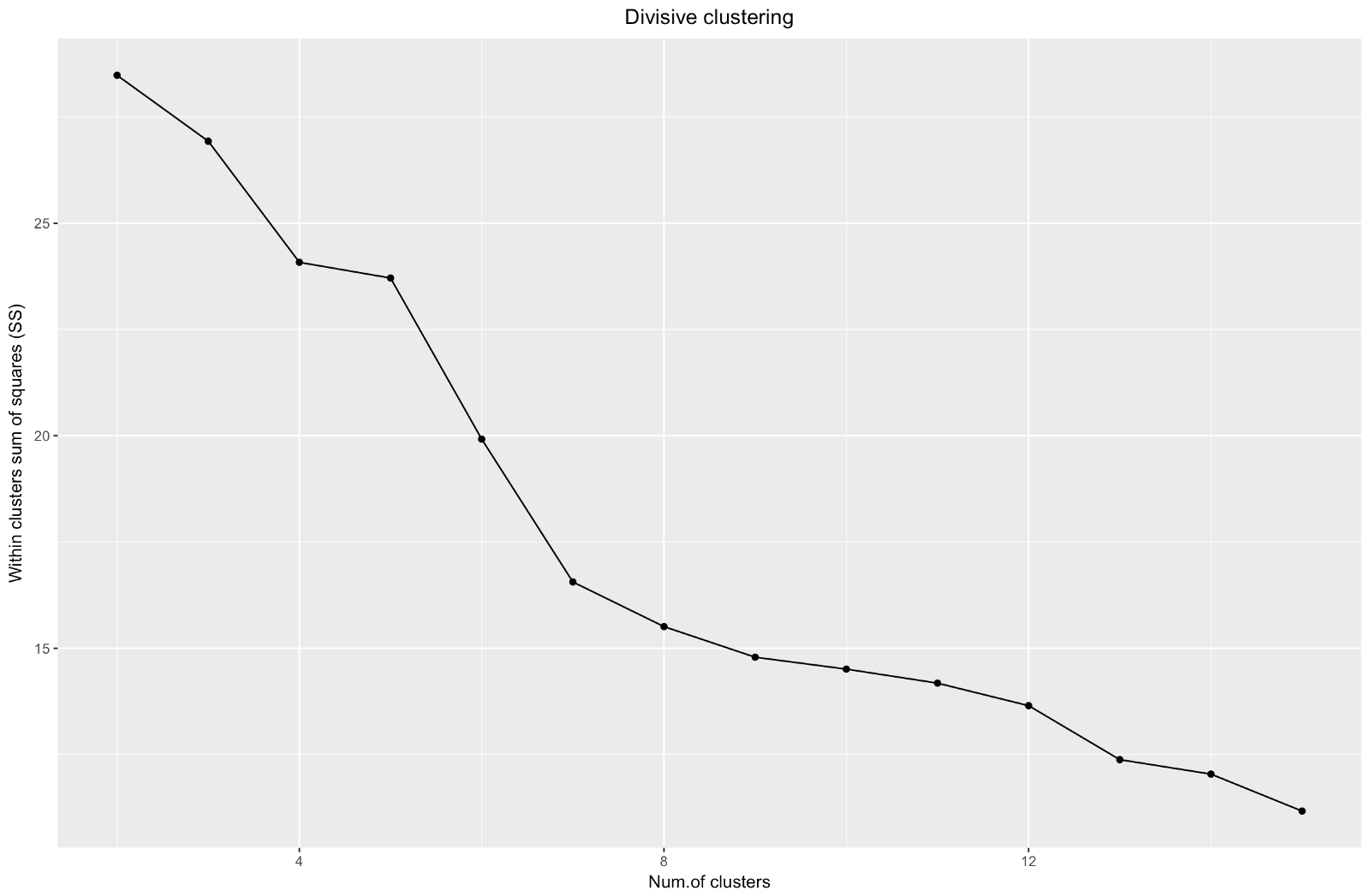
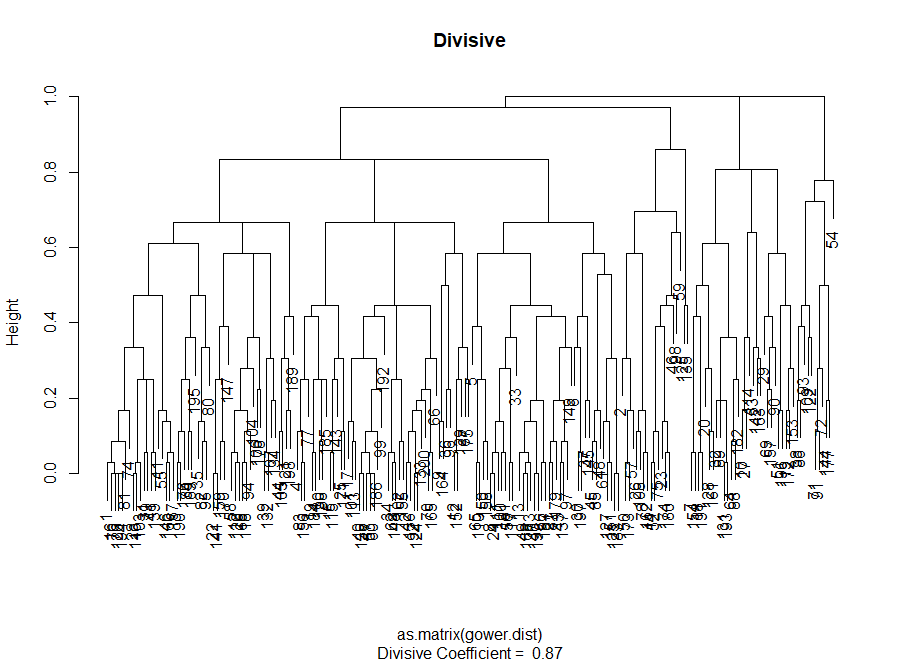
Jadi, kami telah membuat grafik "siku". Ini menunjukkan bagaimana jumlah jarak kuadrat antara pengamatan (kami menggunakannya sebagai ukuran kedekatan pengamatan - semakin kecil, semakin dekat pengukuran di dalam cluster satu sama lain) bervariasi untuk jumlah cluster yang berbeda. Idealnya, kita harus melihat "tikungan siku" yang berbeda pada titik di mana pengelompokan lebih lanjut hanya memberikan sedikit penurunan dalam jumlah kuadrat (SS). Untuk grafik di bawah ini, saya akan berhenti di sekitar 7. Meskipun dalam kasus ini salah satu cluster hanya akan terdiri dari dua pengamatan. Mari kita lihat apa yang terjadi selama pengelompokan aglomeratif.
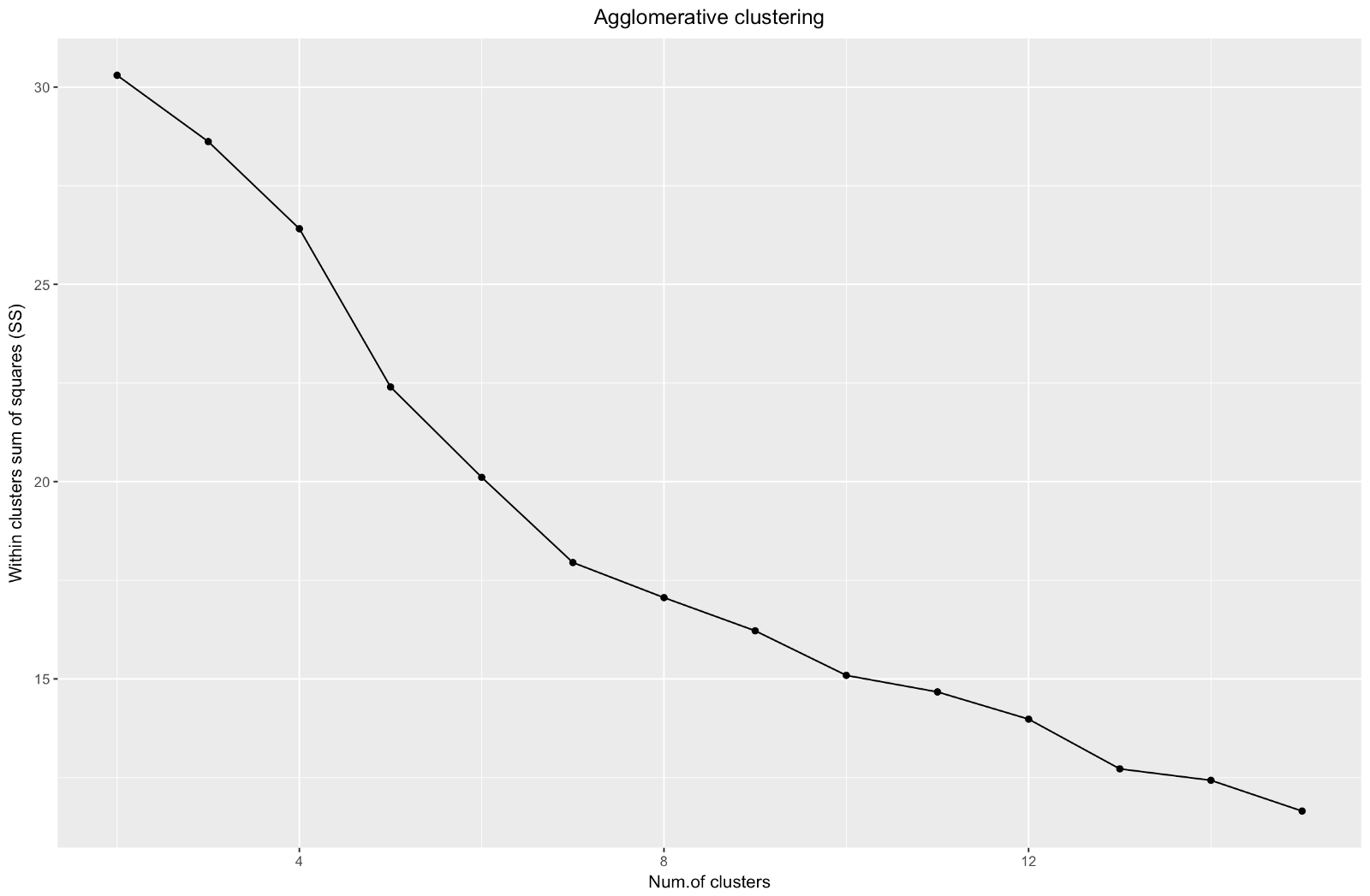
"Siku" agglomeratif mirip dengan divisional, tetapi grafiknya terlihat lebih halus - lengkungan tidak terlalu terasa. Seperti halnya pengelompokan divisional, saya akan fokus pada 7 klaster, namun, ketika memilih di antara kedua metode ini, saya lebih suka ukuran kluster yang diperoleh dengan metode aglomerasi - lebih baik bahwa mereka dapat dibandingkan satu sama lain.
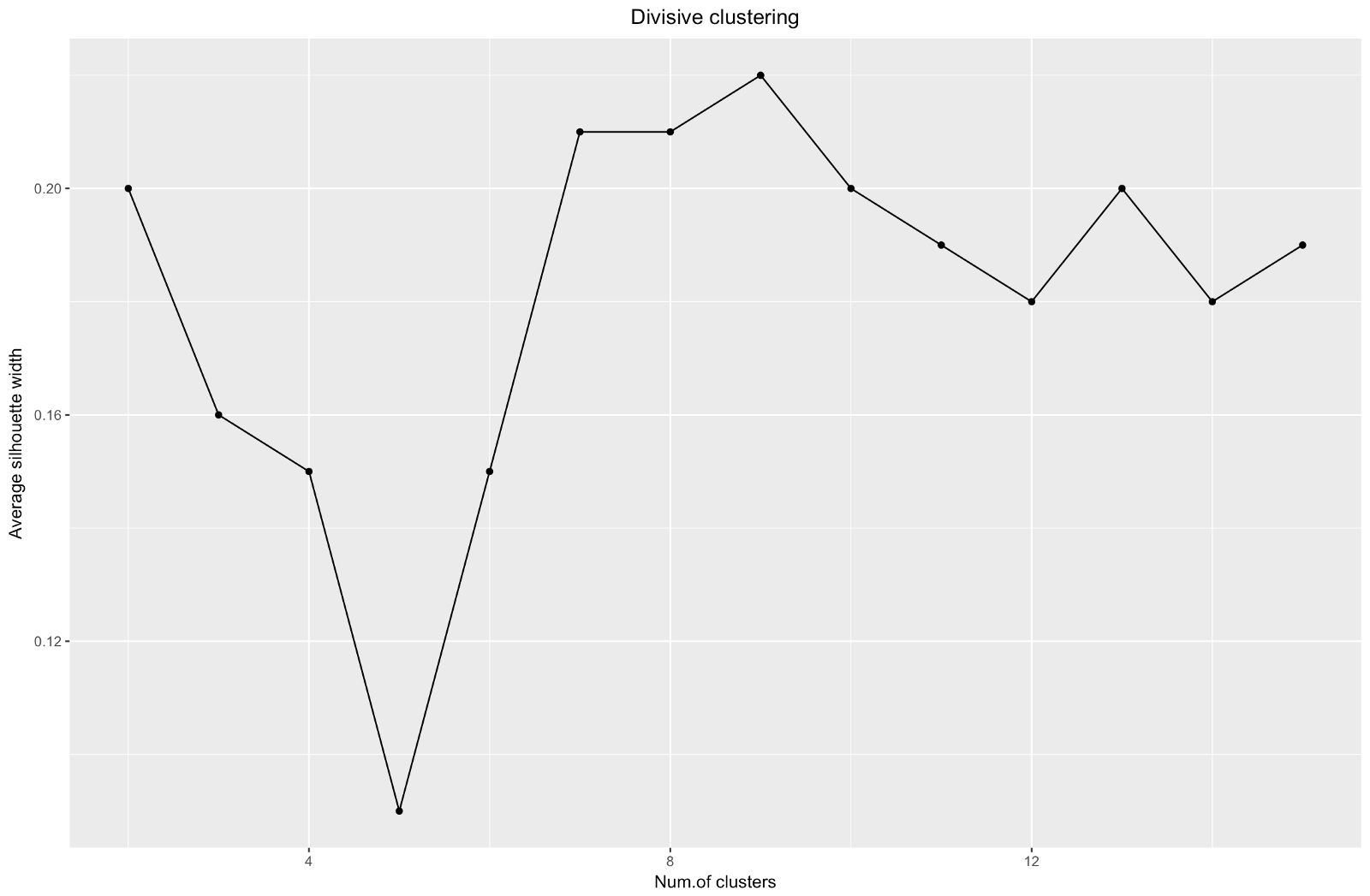
Saat menggunakan metode estimasi siluet, Anda harus memilih jumlah yang memberikan koefisien siluet maksimum, karena Anda memerlukan kelompok yang terpisah cukup jauh untuk dianggap terpisah.
Koefisien siluet dapat berkisar dari -1 hingga 1, dengan 1 sesuai dengan konsistensi yang baik dalam kelompok, dan –1 tidak terlalu baik.
Dalam kasus grafik di atas, Anda akan memilih 9 daripada 5 cluster.
Sebagai perbandingan: dalam kasus "sederhana", grafik siluet mirip dengan yang di bawah ini. Tidak seperti kita, tetapi hampir.
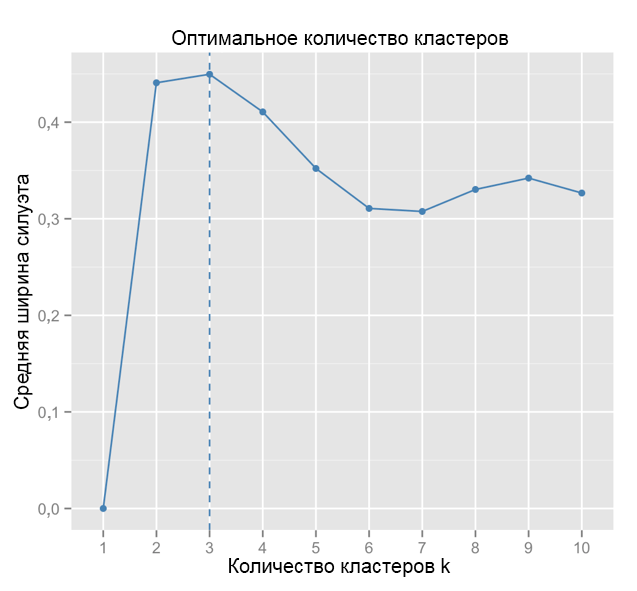 Sumber: Pelaut Data
Sumber: Pelaut Data ggplot(data = data.frame(t(cstats.table(gower.dist, aggl.clust.c, 15))), aes(x=cluster.number, y=avg.silwidth)) + geom_point()+ geom_line()+ ggtitle("Agglomerative clustering") + labs(x = "Num.of clusters", y = "Average silhouette width") + theme(plot.title = element_text(hjust = 0.5))
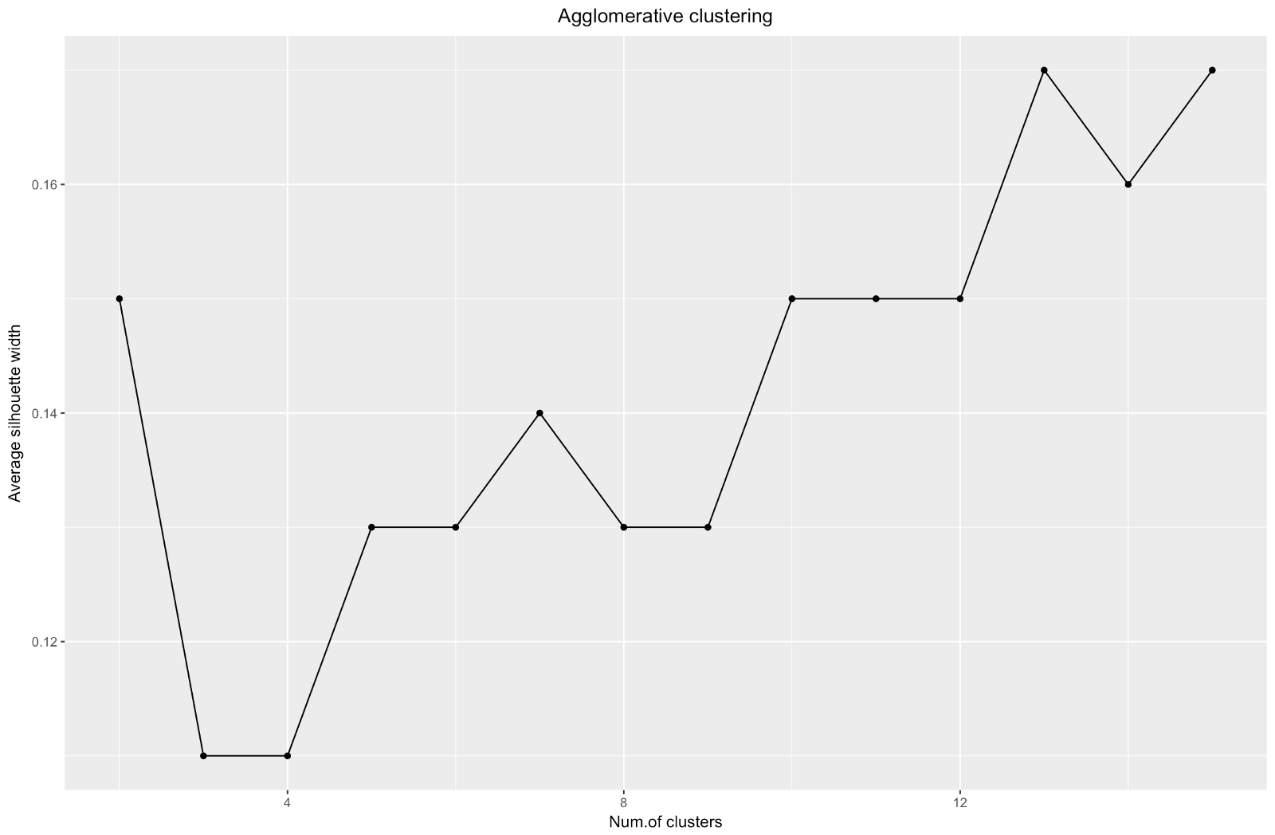
Bagan lebar siluet memberi tahu kami: semakin banyak Anda membagi kumpulan data, semakin jelas klaster menjadi. Namun, pada akhirnya Anda akan mencapai poin individual, dan Anda tidak membutuhkan ini. Namun, inilah yang akan Anda lihat jika Anda mulai menambah jumlah
k . Misalnya, untuk
k=30 saya mendapat grafik berikut:
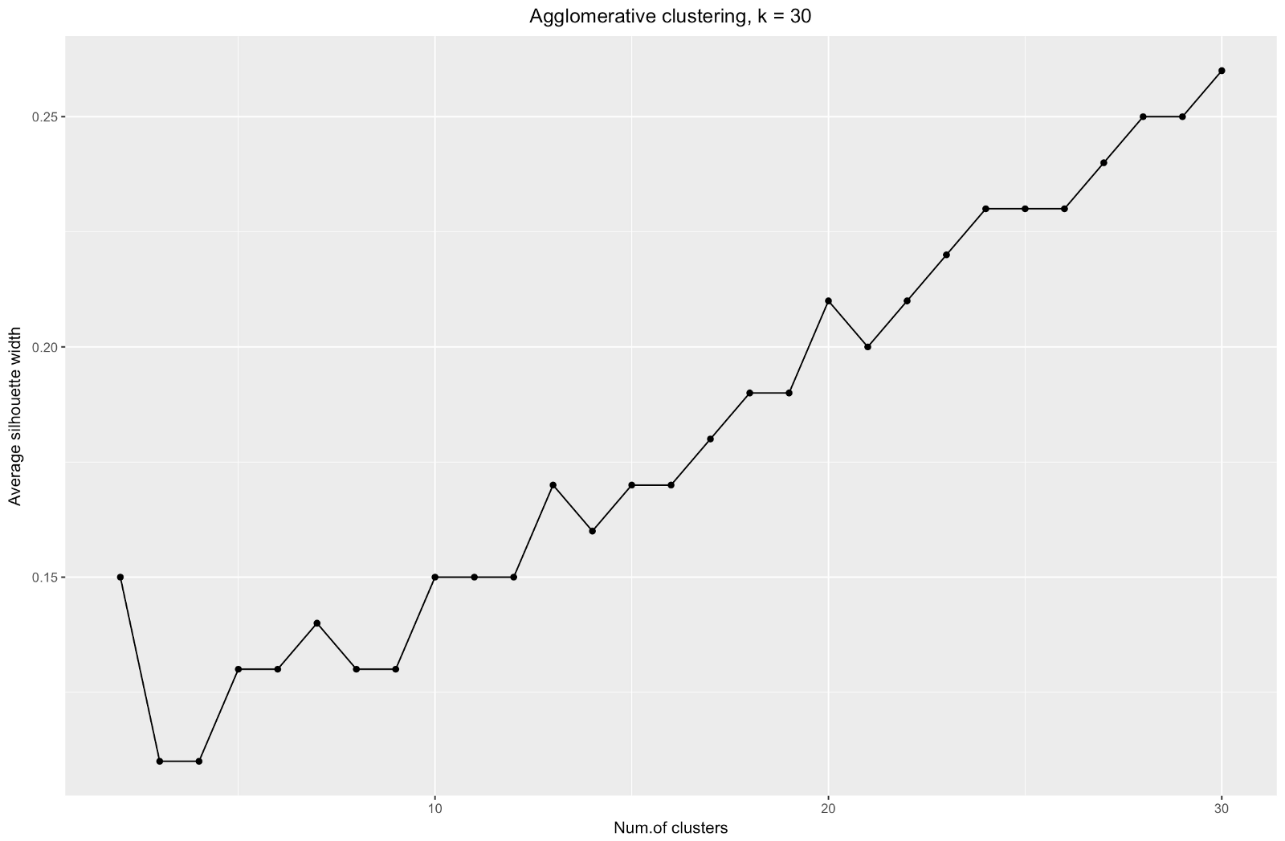
Untuk meringkas: semakin Anda membagi dataset, semakin baik cluster, tetapi kami tidak dapat mencapai poin individu (misalnya, dalam bagan di atas kami memilih 30 cluster, dan kami hanya memiliki 200 poin data).
Jadi, pengelompokan aglomeratif dalam kasus kami bagi saya jauh lebih seimbang: ukuran klaster lebih atau kurang sebanding (lihat saja satu klaster yang hanya memiliki dua pengamatan ketika membaginya dengan metode pembagian!), Dan saya akan berhenti di 7 klaster yang diperoleh dengan metode ini. Mari kita lihat bagaimana mereka terlihat dan terbuat dari apa mereka.
Kumpulan data terdiri dari 6 variabel yang perlu divisualisasikan dalam 2D atau 3D, jadi Anda harus bekerja keras! Sifat data kategorikal juga membebankan beberapa batasan, sehingga solusi yang sudah jadi mungkin tidak berfungsi. Saya perlu: a) melihat bagaimana pengamatan dibagi menjadi beberapa kelompok, b) memahami bagaimana pengamatan dikategorikan. Oleh karena itu, saya membuat a) dendrogram warna, b) peta panas dari jumlah pengamatan per variabel di dalam setiap cluster.
library("ggplot2") library("reshape2") library("purrr") library("dplyr")
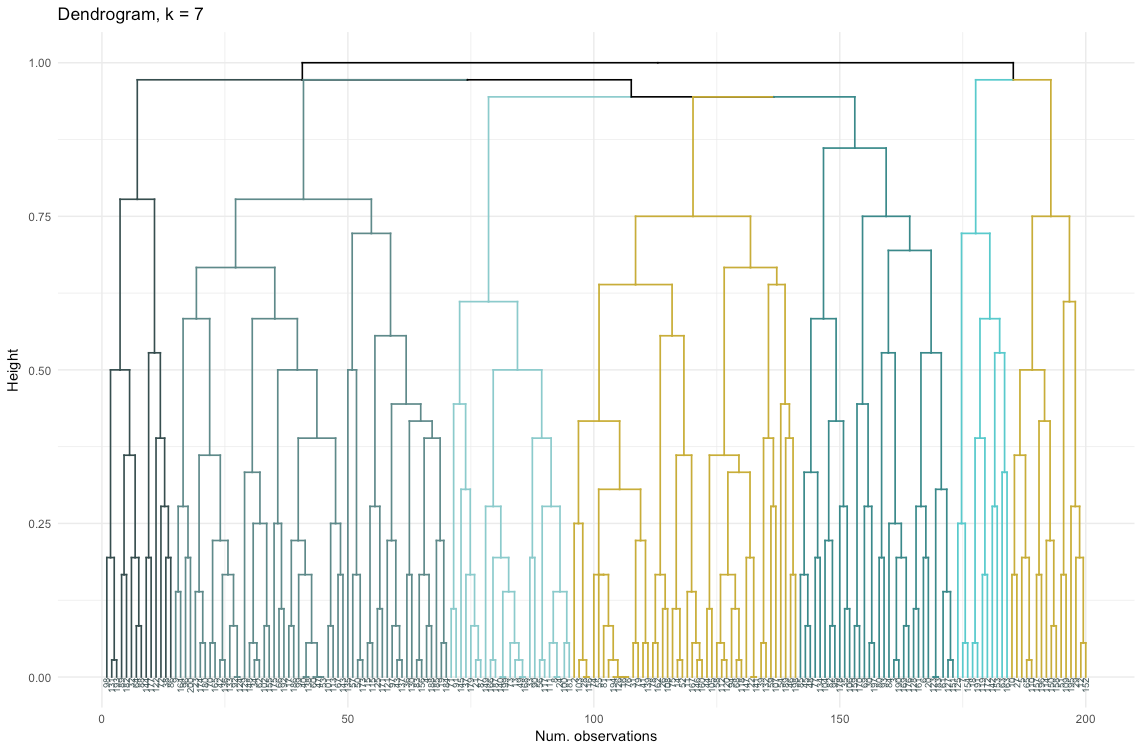

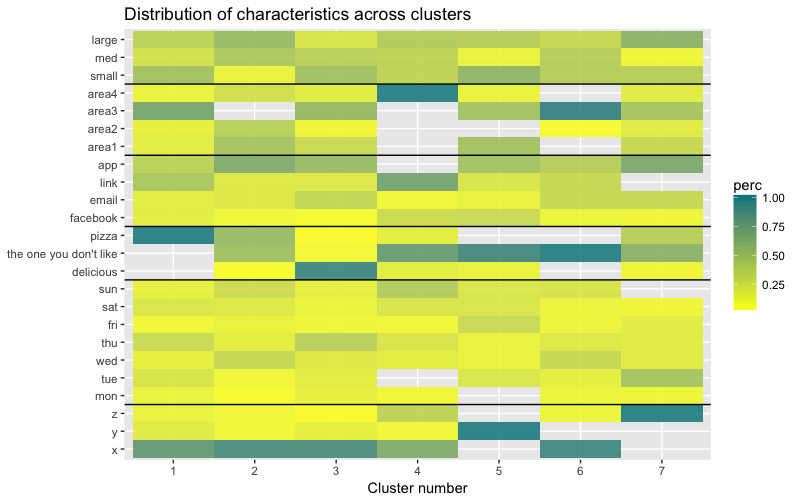
Peta panas menunjukkan secara grafis berapa banyak pengamatan yang dilakukan untuk setiap tingkat faktor untuk faktor awal (variabel yang kami mulai dengan). Warna biru gelap sesuai dengan jumlah pengamatan yang relatif besar di dalam cluster. Peta panas ini juga menunjukkan bahwa untuk hari dalam seminggu (matahari, sat ... mon) dan ukuran keranjang (besar, med, kecil), jumlah pelanggan di setiap sel hampir sama - ini mungkin berarti bahwa kategori ini tidak determinatif untuk analisis, dan Mungkin mereka tidak perlu diperhitungkan.
Kesimpulan
Dalam artikel ini, kami menghitung matriks ketidaksamaan, menguji metode aglomerasi dan divisi pengelompokan hierarkis, dan membiasakan diri dengan metode siku dan siluet untuk menilai kualitas cluster.
Pengelompokan hierarkis divisi dan aglomeratif adalah awal yang baik untuk mempelajari topik tersebut, tetapi jangan berhenti di situ jika Anda ingin benar-benar menguasai analisis klaster. Ada banyak metode dan teknik lain. Perbedaan utama dari pengelompokan data numerik adalah perhitungan matriks perbedaan. Ketika menilai kualitas pengelompokan, tidak semua metode standar akan memberikan hasil yang andal dan bermakna - metode siluet sangat mungkin tidak cocok.
Dan akhirnya, karena beberapa waktu telah berlalu sejak saya membuat contoh ini, sekarang saya melihat sejumlah kekurangan dalam pendekatan saya dan akan dengan senang hati menerima umpan balik. Salah satu masalah signifikan dari analisis saya tidak terkait dengan pengelompokan seperti itu -
set data saya tidak seimbang dalam banyak hal, dan saat ini tetap tidak terhitung. Ini memiliki efek yang nyata pada pengelompokan: 70% klien termasuk dalam satu tingkat faktor “kewarganegaraan”, dan kelompok ini mendominasi sebagian besar kelompok yang diperoleh, sehingga sulit untuk menghitung perbedaan dalam tingkat faktor lainnya. Lain kali saya akan mencoba menyeimbangkan kumpulan data dan membandingkan hasil pengelompokan. Tetapi lebih lanjut tentang itu di pos lain.
Terakhir, jika Anda ingin mengkloning kode saya, berikut ini tautan ke github:
https://github.com/khunreus/cluster-categoricalSaya harap Anda menikmati artikel ini!
Sumber yang membantu saya:
Panduan pengelompokan hierarki (persiapan data, pengelompokan, visualisasi) - blog ini akan menarik bagi mereka yang tertarik dengan analitik bisnis di lingkungan R:
http://uc-r.imtqy.com/hc_clustering dan
https: // uc-r. imtqy.com/kmeans_clusteringValidasi Cluster:
http://www.sthda.com/english/articles/29-cluster-validation-essentials/97-cluster-validation-statistics-must-ofu-methods/( k-):
https://eight2late.wordpress.com/2015/07/22/a-gentle-introduction-to-cluster-analysis-using-r/denextend, :
https://cran.r-project.org/web/packages/dendextend/vignettes/introduction.html#the-set-function, :
https://www.r-statistics.com/2010/06/clustergram-visualization-and-diagnostics-for-cluster-analysis-r-code/:
https://jcoliver.imtqy.com/learn-r/008-ggplot-dendrograms-and-heatmaps.html,
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5025633/ ( GitHub:
https://github.com/khunreus/EnsCat ).