Halo, Habr! Nama saya Nikolai, dan saya terlibat dalam konstruksi dan implementasi model pembelajaran mesin di Sberbank. Hari ini saya akan berbicara tentang mengembangkan sistem rekomendasi untuk pembayaran dan transfer dalam aplikasi di ponsel cerdas Anda.
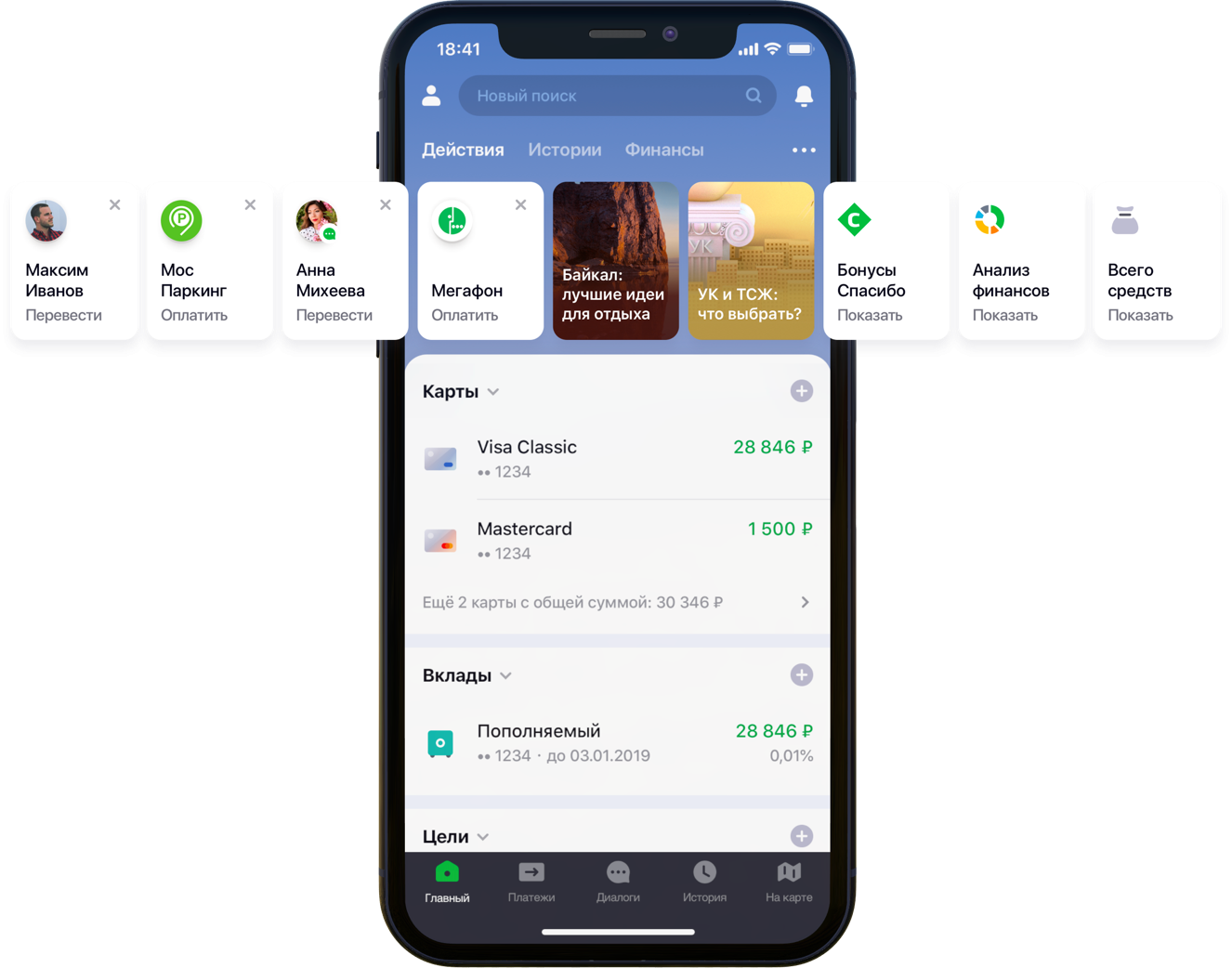 Desain layar utama aplikasi seluler dengan rekomendasi
Desain layar utama aplikasi seluler dengan rekomendasiKami memiliki dua ratus ribu opsi pembayaran, 55 juta pelanggan, 5 sumber perbankan berbeda, setengah kolom pengembang dan segudang aktivitas perbankan, algoritme dan semua itu, semua warna, serta satu liter benih acak, sekotak hiperparameter, setengah liter faktor koreksi, dan dua puluhan perpustakaan. Bukan berarti semua ini diperlukan dalam pekerjaan, tetapi karena ia mulai meningkatkan kehidupan klien, maka pergilah hobi Anda sampai akhir. Di bawah potongan adalah kisah pertempuran untuk UX, perumusan masalah yang benar, perjuangan melawan dimensi data, kontribusi untuk open-source dan hasil kami.
Pernyataan masalah
Seiring perkembangan dan peningkatan, aplikasi Sberbank Online mendapatkan fitur yang bermanfaat dan fungsionalitas tambahan. Secara khusus, dalam aplikasi Anda dapat mentransfer uang atau membayar layanan berbagai organisasi.
“Kami dengan cermat melihat semua jalur pengguna di dalam aplikasi dan menyadari bahwa banyak di antaranya dapat dikurangi secara signifikan. Untuk melakukan ini, kami memutuskan untuk mempersonalisasi layar utama dalam beberapa tahap. Pertama, kami mencoba menghapus dari layar apa yang tidak digunakan klien, dimulai dengan kartu bank. Kemudian mereka mengemukakan tindakan-tindakan yang sudah dilakukan klien sebelumnya dan untuk itu ia bisa masuk ke aplikasi sekarang. Sekarang daftar tindakan termasuk pembayaran ke organisasi dan transfer ke kontak, maka daftar tindakan tersebut akan diperluas, ”kata kolega saya Sergey Komarov, yang mengembangkan fungsionalitas dari sudut pandang klien di tim Sberbank Online. Penting untuk membangun model yang akan mengisi slot yang ditunjuk dalam widget Tindakan (gambar di atas) dengan rekomendasi pribadi tentang pembayaran dan transfer, bukan aturan sederhana.
Solusi
Kami di tim menguraikan tugas menjadi dua bagian:
- rekomendasi pengulangan operasi untuk membayar layanan atau mentransfer dana (blok "Operasi yang disarankan")
- rekomendasi contoh permintaan pencarian untuk pembayaran untuk layanan yang sebelumnya tidak digunakan oleh klien ini (memblokir "Contoh Pencarian")
Kami memutuskan untuk menguji fungsionalitas terlebih dahulu pada tab pencarian:
Desain Layar Pencarian yang DisarankanOperasi yang Disarankan
Optimalisasi penilaian
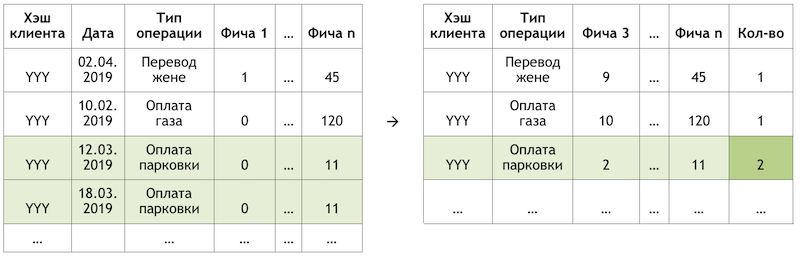
Jika kami menetapkan subtugas sebagai rekomendasi untuk mengulangi operasi, ini memungkinkan kami untuk menyingkirkan perhitungan dan evaluasi triliunan kombinasi dari semua operasi yang mungkin untuk semua pelanggan dan fokus pada jumlah yang jauh lebih terbatas. Jika, dari seluruh rangkaian operasi yang tersedia untuk klien kami, klien hipotetis dengan hasy YYY hanya menggunakan pembayaran untuk gas dan parkir, maka kami akan mengevaluasi kemungkinan mengulang hanya operasi ini untuk klien ini:
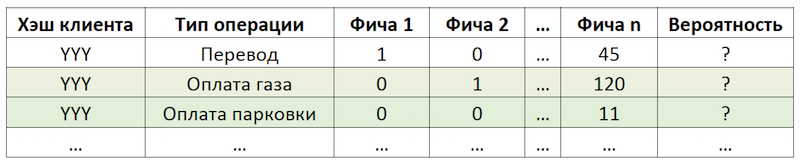 Contoh mengurangi dimensi data untuk penilaian
Contoh mengurangi dimensi data untuk penilaianMempersiapkan dataset
Sampel adalah observasi transaksional, diperkaya dengan faktor-faktor demografi klien, agregat keuangan dan berbagai karakteristik frekuensi operasi tertentu.
Variabel target dalam kasus ini adalah biner dan mencerminkan fakta peristiwa pada hari setelah hari faktor-faktor dihitung. Dengan demikian, secara iteratif menggerakkan hari menghitung faktor-faktor dan menetapkan bendera variabel target, kami melipatgandakan dan menandai operasi yang sama dan menandainya secara berbeda tergantung pada posisi relatif terhadap hari ini.
Skema PengamatanMenghitung pemotongan pada 17/03/2019 untuk klien "YYY", kami mendapatkan dua pengamatan:
Contoh pengamatan untuk dataset"Fitur 1" dapat berarti, misalnya, keseimbangan pada semua kartu klien, "Fitur 2" - keberadaan jenis operasi ini dalam minggu terakhir.
Kami melakukan transaksi yang sama, tetapi membentuk pengamatan untuk pelatihan pada tanggal yang berbeda:
Skema PengamatanKami akan mendapatkan pengamatan untuk dataset dengan nilai lain dari kedua fitur dan variabel target:
 Contoh pengamatan untuk dataset
Contoh pengamatan untuk datasetDalam contoh di atas, untuk kejelasan, nilai aktual dari faktor diberikan, tetapi pada kenyataannya, nilai diproses oleh algoritma otomatis: hasil
konversi WOE diumpankan ke input model. Hal ini memungkinkan Anda untuk membawa variabel ke hubungan monoton dengan variabel target dan pada saat yang sama menyingkirkan efek pencilan. Misalnya, kami memiliki faktor "Jumlah kartu" dan beberapa distribusi variabel target:
 Contoh konversi WOE
Contoh konversi WOETransformasi WOE memungkinkan kita untuk mengubah ketergantungan nonlinear menjadi setidaknya monotonik. Setiap nilai faktor yang dianalisis dikaitkan dengan nilai WOE sendiri dan dengan demikian faktor baru terbentuk, dan yang asli dihapus dari dataset:
 Pengaruh transformasi WOE pada hubungan dengan variabel target
Pengaruh transformasi WOE pada hubungan dengan variabel targetKamus untuk mengonversi nilai variabel ke WOE disimpan dan digunakan nanti untuk penilaian. Artinya, jika kita perlu menghitung probabilitas untuk besok, kita membuat dataset seperti pada tabel dengan contoh pengamatan di atas, mengubah variabel yang diperlukan menjadi WOE dengan kode yang disimpan, dan menerapkan model pada data ini.
Pelatihan
Pilihan metode sangat terbatas - interpretabilitas. Oleh karena itu, untuk memenuhi tenggat waktu, diputuskan untuk menunda penjelasan menggunakan
SHAP yang sama di bagian kedua dari masalah dan menguji metode yang relatif sederhana: regresi dan neuron dangkal. Alat itu adalah SAS Miner, perangkat lunak untuk preprocessing, menganalisis dan membangun model pada berbagai data dalam bentuk interaktif, yang menghemat banyak waktu dalam menulis kode.
 Antarmuka SAS Miner
Antarmuka SAS MinerPenilaian kualitas
Perbandingan metrik GINI pada sampel out-of-time menunjukkan bahwa jaringan saraf mengatasi tugas terbaik:
Tabel perbandingan model kualitas dan aturan frekuensiModel memiliki dua titik keluar. Rekomendasi dalam bentuk kartu widget di layar utama termasuk operasi yang perkiraannya di atas ambang batas tertentu (lihat gambar pertama di pos). Perbatasan dipilih berdasarkan keseimbangan kualitas dan jangkauan, yang dalam arsitektur semacam itu adalah setengah dari semua operasi yang dilakukan. Operasi 4 besar dikirim ke blok "operasi yang direkomendasikan" pada layar pencarian (lihat gambar kedua).
Contoh Pencarian
Beralih ke bagian kedua dari tugas, kami kembali ke masalah sejumlah besar opsi pembayaran yang mungkin untuk layanan penyedia yang perlu dievaluasi dan disortir dalam setiap klien - triliunan pasangan. Selain itu, kami memiliki data tersirat, yaitu, tidak ada informasi tentang penilaian pembayaran yang dilakukan, atau mengapa klien tidak melakukan pembayaran apa pun. Oleh karena itu, sebagai permulaan, diputuskan untuk menguji berbagai metode memperluas matriks pembayaran dari pelanggan ke penyedia: ALS dan FM.
ALS
ALS (Alternating Least Squares) atau Alternating Least Squares - dalam penyaringan kolaboratif, salah satu metode untuk memecahkan masalah faktorisasi dari matriks interaksi. Kami akan menyajikan data transaksional kami tentang pembayaran layanan dalam bentuk matriks di mana kolom adalah pengidentifikasi unik dari semua layanan penyedia, dan baris adalah pelanggan unik. Dalam sel kami menempatkan jumlah operasi klien tertentu dengan penyedia spesifik untuk periode waktu tertentu:
 Prinsip dekomposisi matriks
Prinsip dekomposisi matriksArti dari metode ini adalah kita membuat dua matriks dengan dimensi yang lebih rendah, perkalian yang memberikan hasil terdekat dengan matriks besar asli dalam sel yang diisi. Model belajar untuk membuat deskripsi faktorial tersembunyi untuk pelanggan dan penyedia. Implementasi metode di perpustakaan
implisit digunakan. Pelatihan berlangsung sesuai dengan algoritma berikut:
- Matriks klien dan penyedia dengan faktor tersembunyi diinisialisasi. Jumlah mereka adalah hiperparameter model.
- Matriks faktor-faktor tersembunyi penyedia diperbaiki dan turunan dari fungsi kerugian untuk koreksi matriks klien dipertimbangkan. Penulis menggunakan metode konjugasi gradien yang menarik , yang memungkinkan Anda mempercepat langkah ini.
- Langkah sebelumnya diulangi sama untuk matriks faktor tersembunyi pelanggan.
- Langkah 2-3 bergantian sampai algoritma menyatu.
Persiapan
Data transaksional ditransformasikan ke dalam matriks interaksi dengan tingkat kelangkaan ~ 99% dengan ketidakmerataan yang besar di antara penyedia. Untuk memisahkan data menjadi sampel latih dan validasi, kami secara acak menutupi proporsi sel yang diisi:
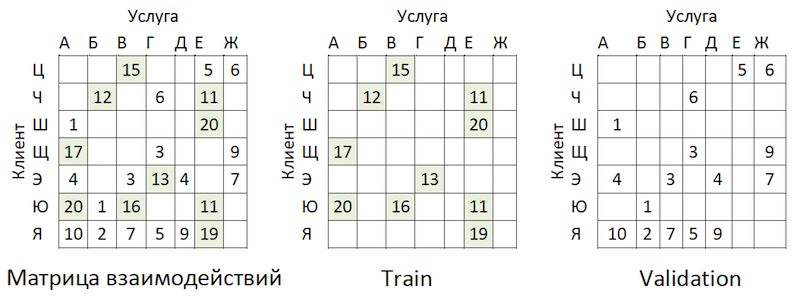 Contoh Berbagi Data
Contoh Berbagi DataTransaksi diambil sebagai tes untuk periode waktu setelah pelatihan, dan ditata dalam matriks dengan format yang sama - ternyata out-of-time.
Pelatihan
Model ini memiliki beberapa hiperparameter yang dapat disesuaikan untuk meningkatkan kualitas:
- Alpha adalah koefisien dengan mana matriks ditimbang, menyesuaikan tingkat kepercayaan ( C_iu ) bahwa layanan yang diberikan benar-benar "disukai" oleh klien.
- Jumlah faktor dalam matriks tersembunyi dari klien dan penyedia adalah jumlah kolom dan baris, masing-masing.
- Koefisien pengaturan L2 λ.
- Jumlah iterasi metode.
Kami menggunakan pustaka
hyperopt , yang memungkinkan kami untuk mengevaluasi efek hyperparameter pada metrik kualitas menggunakan metode
TPE dan memilih nilai optimalnya. Algoritma dimulai dengan awal yang dingin dan membuat beberapa penilaian metrik kualitas tergantung pada nilai-nilai dari parameter yang dianalisis. Kemudian, pada dasarnya, ia mencoba untuk memilih satu set nilai hyperparameters yang lebih cenderung memberikan nilai yang baik untuk metrik kualitas. Hasilnya disimpan dalam kamus di mana Anda dapat membuat grafik dan mengevaluasi secara visual hasil pengoptimal (biru lebih baik):
Grafik ketergantungan metrik kualitas pada kombinasi hiperparameterGrafik menunjukkan bahwa nilai-nilai hiperparameter sangat mempengaruhi kualitas model. Karena perlu menerapkan rentang untuk masing-masing input ke metode, grafik selanjutnya dapat menentukan apakah masuk akal untuk memperluas ruang nilai atau tidak. Sebagai contoh, dalam tugas kita jelas bahwa masuk akal untuk menguji nilai-nilai besar untuk sejumlah faktor. Di masa depan, ini benar-benar meningkatkan model.
Metrik dan kompleksitas penilaian kualitas
Bagaimana cara mengevaluasi kualitas model? Salah satu metrik yang paling umum digunakan untuk sistem rekomendasi di mana pesanan penting adalah
MAP @ k atau Mean Average Precision di K. Metrik ini memperkirakan keakuratan model pada rekomendasi K, dengan mempertimbangkan urutan item dalam daftar rekomendasi ini rata-rata untuk semua pelanggan.
Sayangnya, operasi penilaian kualitas bahkan pada sampel memakan waktu beberapa jam. Setelah menyingsingkan lengan baju kami, kami mulai membuat profil fungsi mean_average_pecision_at_k () dengan pustaka line_profiler. Tugas itu semakin rumit oleh fakta bahwa fungsi tersebut menggunakan kode cython dan harus diperhitungkan dengan benar, jika tidak, statistik yang diperlukan tidak dikumpulkan. Akibatnya, kami kembali menghadapi masalah dimensi data kami. Untuk menghitung metrik ini, Anda perlu mendapatkan beberapa perkiraan setiap layanan dari semua kemungkinan untuk setiap klien dan memilih rekomendasi pribadi top-K dengan mengurutkan dari array yang dihasilkan. Bahkan mempertimbangkan penggunaan penyortiran parsial numpy.argpartition () dengan O (n) kompleksitas, menyortir nilai ternyata menjadi langkah terpanjang memperluas kualitas penilaian dari jam ke jam. Karena numpy.argpartition () tidak menggunakan semua kernel di server kami, diputuskan untuk meningkatkan algoritme dengan menulis ulang bagian ini dalam C ++ dan OpenMP melalui cython. Algoritma baru yang singkat adalah sebagai berikut:
- Data dipotong-potong oleh pelanggan.
- Matriks kosong dan pointer ke memori diinisialisasi.
- String batch oleh pointer diurutkan dalam dua cara: oleh fungsi partial_sort dan kemudian urutkan berdasarkan pustaka algoritma C ++.
- Hasilnya ditulis ke sel-sel matriks kosong secara paralel.
- Data dikembalikan dalam python.
Ini memungkinkan kami untuk mempercepat perhitungan rekomendasi beberapa kali. Revisi telah
ditambahkan ke repositori resmi.
Analisis Hasil OOT
Dan sekarang saatnya untuk mengevaluasi kualitas model. Mengapa kita perlu pengambilan sampel yang tidak tepat waktu? Jika kita melihat distribusi operasi oleh penyedia, kita akan melihat gambar berikut:
Distribusi popularitas penyedia layananAda ketidakseimbangan. Ini mengarah pada fakta bahwa model ini mencoba untuk merekomendasikan layanan populer. Kembali ke gambar di atas:
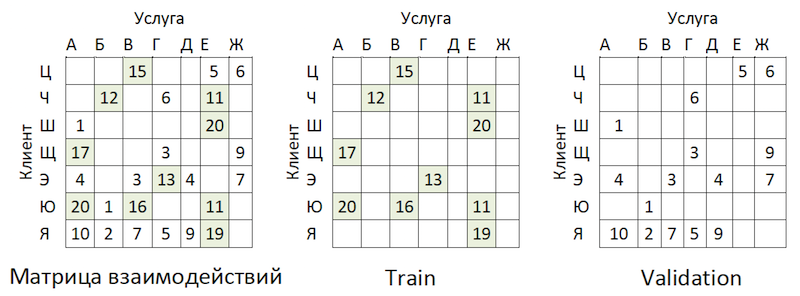
Masalahnya adalah jika Anda memeriksa keakuratan model dengan menutupi matriks yang sama, seperti yang disarankan hampir di mana-mana, maka untuk sebagian besar pelanggan (contoh marginal: "W", "E" dan "I") kualitas perkiraan validasi (kami akan berpura-pura bahwa dia tidak berpartisipasi dalam pemilihan hiperparameter) akan tinggi jika ini adalah penyedia paling populer. Sebagai hasilnya, kami mendapatkan kepercayaan salah pada kekuatan model. Karena itu, kami bertindak sebagai berikut:
- Perkiraan penyedia dibentuk berdasarkan model.
- Pasangan layanan klien yang ada dikeluarkan dari peringkat (lihat gambar di bawah) dan matriks OOT.
- Dibentuk dari peringkat yang tersisa dari rekomendasi K-top dan memberi peringkat MAP @ k pada OOT yang tersisa.
 Logika mempersiapkan matriks untuk menghasilkan perkiraan
Logika mempersiapkan matriks untuk menghasilkan perkiraanSebagai garis dasar, kami menyusun daftar penyedia, diurutkan berdasarkan popularitas, dan dikalikan dengan semua pelanggan, sekali lagi tidak termasuk pasangan layanan pelanggan yang ada. Ternyata itu menyedihkan dan sama sekali tidak seperti yang kami harapkan dan lihat pada sampel validasi kereta:
Benchmark dan Bagan Perbandingan Kualitas ModelHentikan itu! Kami memiliki faktor klien dan parameter penyedia. Kami mendapatkan mesin faktorisasi.
FM
Mesin faktorisasi (mesin faktorisasi) - algoritma pembelajaran dengan guru, yang dirancang untuk menemukan hubungan antara faktor-faktor yang menggambarkan entitas yang berinteraksi, yang disajikan dalam bentuk matriks yang jarang. Kami menggunakan implementasi FM dari pustaka
LightFM .
Format data
Selain matriks interaksi yang dinormalisasi,
metode ini menggunakan dua set data tambahan dengan faktor-faktor untuk pelanggan dan untuk layanan penyedia dalam bentuk matriks satu-panas-dikodekan terhubung ke yang tunggal:
 Logika mempersiapkan matriks untuk menghasilkan perkiraan
Logika mempersiapkan matriks untuk menghasilkan perkiraanPenilaian kualitas
Kualitas model FM pada data kami ternyata lebih rendah dari ALS:
Tabel perbandingan model kualitas dan baselineUbah Arsitektur Model - Meningkatkan
Diputuskan untuk datang dari sisi lain. Mengingat distribusi popularitas layanan, kami mengidentifikasi 300 dari mereka, transaksi yang mencakup 80% dari semua operasi, dan melatih classifier pada mereka. Di sini, data mewakili agregat transaksi pelanggan yang diperkaya dengan fitur klien:
 Skema agregasi transaksi
Skema agregasi transaksiKenapa hanya sisi klien, Anda bertanya? Karena dalam hal ini, untuk menyiapkan rekomendasi, cukup bagi kita untuk memiliki satu jalur per klien. Menerapkan model untuk itu, kami mendapatkan vektor output probabilitas untuk semua kelas, dari mana mudah untuk memilih rekomendasi top-K. Jika kita menambahkan fitur layanan penyedia ke set pelatihan, maka pada tahap penerapan model kita akan dipaksa untuk menyiapkan 300 baris untuk setiap klien - satu untuk setiap layanan penyedia dengan fitur yang menggambarkan mereka, atau membangun model lain untuk calon penyortiran skor pre-sorting .
Menambahkan fitur ke klien dari ALS tidak menambah data kami, karena kami sudah memperhitungkan aktivitas transaksional - misalnya, di bagian PKS atau kategori dengan gaya "gamer" atau "teater". Dalam format ini, kami berhasil mendapatkan hasil yang baik:
Tabel perbandingan model kualitas dan baselineFilter regional
Terlepas dari kualitas model yang tinggi, satu masalah lagi tetap dalam pendekatan ini. Karena arsitektur data dan model tidak menyiratkan penggunaan fitur layanan penyedia, model tidak sepenuhnya memperhitungkan geografi akun dan dapat merekomendasikan agar orang membayar untuk layanan penyedia lokal dari wilayah lain. Untuk meminimalkan risiko ini, kami telah mengembangkan filter kecil untuk memotong opsi sebelum memasukkan ke dalam rekomendasi. Rekursi yang mudah dilemparkan ke algoritma:
- Kami mengumpulkan informasi tentang wilayah klien dari profil bank dan sumber internal lainnya.
- Kami memilih wilayah utama kehadiran untuk setiap penyedia.
- Kami mengklarifikasi / mengisi informasi tentang wilayah klien dengan wilayah penyedia yang dia gunakan.
Setelah manipulasi ini, menggunakan
indeks Herfindahl, kami memisahkan penyedia regional, yang diwakili dalam rangkaian wilayah terbatas, dari yang federal:
Pemisahan penyedia dengan kehadiran di daerahKami membentuk topeng dengan penyedia regional yang dapat diterima untuk pelanggan dan mengecualikan item yang tidak perlu dari prediksi model sebelum membuat daftar rekomendasi.
Kesimpulan
Kami telah mengembangkan dua model yang bersama-sama membentuk serangkaian rekomendasi lengkap tentang pembayaran dan transfer. Dimungkinkan untuk mengurangi jalur klien untuk setengah operasi berulang menjadi satu klik. Dalam rencana masa depan untuk meningkatkan model "operasi yang direkomendasikan" menggunakan data umpan balik (kartu dapat disembunyikan, dll.), Yang akan mengurangi ambang batas untuk memilih rekomendasi dan meningkatkan cakupan. Juga direncanakan untuk memperluas cakupan pembayaran yang direkomendasikan dalam model "contoh pencarian" dan mengembangkan algoritma untuk penilaian optimasi untuk itu.
Kami telah melalui jalur sulit membangun sistem pembayaran dan transfer yang direkomendasikan. Di tengah jalan, kami mendapatkan masalah dan mendapatkan pengalaman dalam mendekomposisi dan menyederhanakan tugas-tugas tersebut, mengevaluasi dengan benar sistem tersebut, penerapan metode, kerja optimal dengan volume data yang besar, dan secara signifikan memperluas pemahaman kami tentang spesifikasi tugas-tugas tersebut. Sepanjang jalan, saya berhasil berkontribusi pada open-source, yang kami gunakan sendiri. Saya berharap Anda melakukan tugas yang menarik, garis dasar yang realistis dan F1 tunggal. Terima kasih atas perhatian anda!