Artikel ini adalah sejenis kelas master "DVC untuk mengotomatisasi eksperimen ML dan versi data", yang berlangsung pada 18 Juni di ML REPA (Machine Learning REPA:
Reproduksibilitas, Eksperimen, dan Otomatisasi Pipa) di lokasi bank kami.
Di sini saya akan berbicara tentang fitur-fitur pekerjaan internal DVC dan bagaimana menggunakannya dalam proyek.
Contoh kode yang digunakan dalam artikel tersedia di
sini . Kode diuji pada MacOS dan Linux (Ubuntu).
Isi
Bagian 1
Bagian 2
Pengaturan DVC
Kontrol Versi Data adalah alat yang dirancang untuk mengelola model dan versi data dalam proyek ML. Ini berguna baik pada tahap percobaan dan untuk menyebarkan model Anda ke dalam operasi.
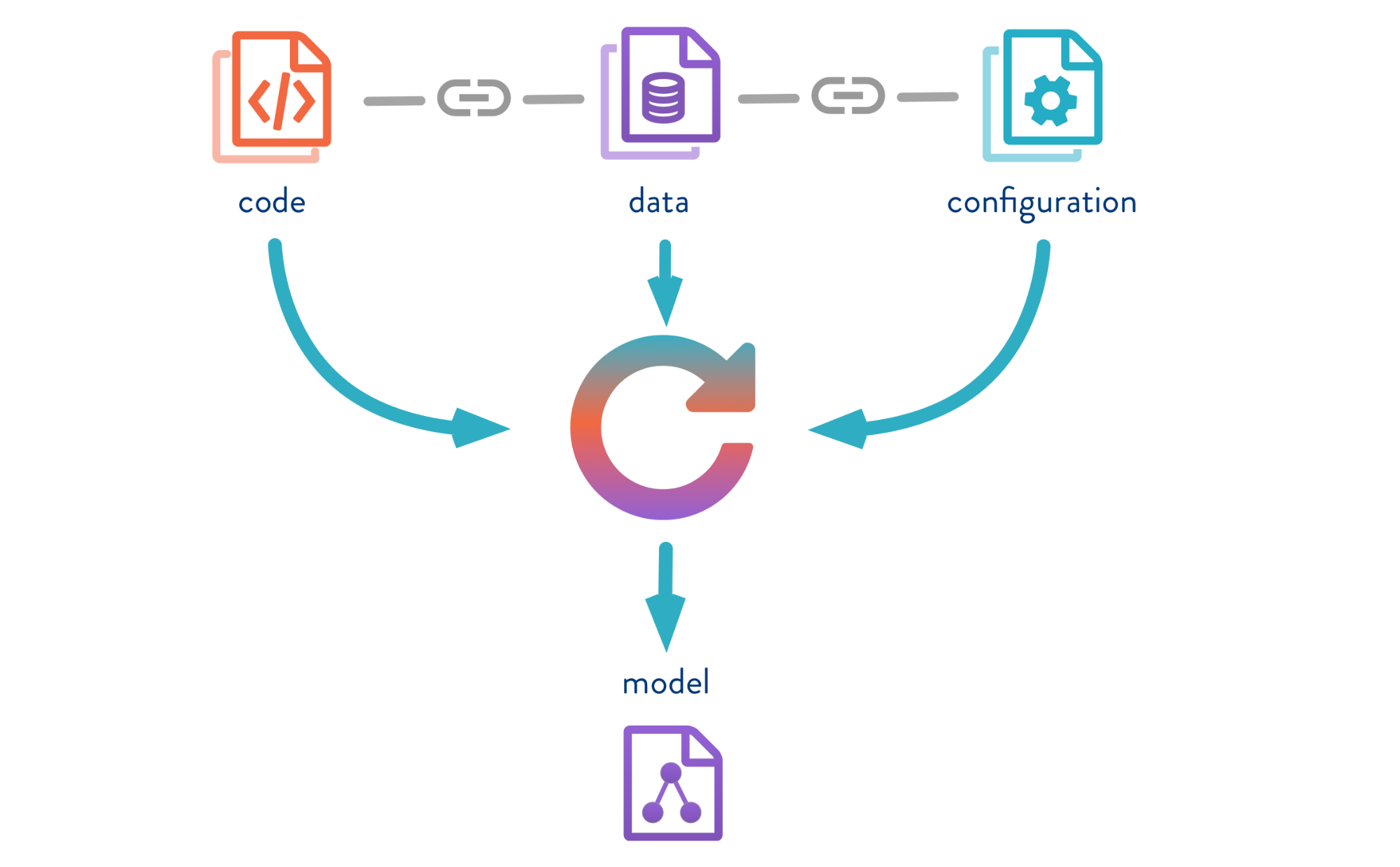
DVC memungkinkan Anda untuk versi model, data, dan jaringan pipa dalam proyek DS.
Sumbernya ada di
sini .
Mari kita lihat operasi DVC menggunakan contoh masalah klasifikasi warna iris. Untuk ini,
Iris Data Set akan digunakan.
Contoh lain
dari bekerja dengan DVC ditunjukkan oleh Jupyter Notebook.
Apa yang perlu Anda lakukan:Jadi, kami mengkloning repositori, membuat lingkungan virtual, dan menginstal paket yang diperlukan. Petunjuk instalasi dan peluncuran ada di repositori README.
1. Kloning repositori ini
git clone https://gitlab.com/7labs.ru/tutorials-dvc/dvc-1-get-started.git cd dvc-1-get-started
2. Buat dan aktifkan lingkungan virtual
pip install virtualenv virtualenv venv source venv/bin/activate
3. Instal pustaka python (termasuk dvc)
pip install -r requirements.txt
Untuk menginstal DVC, gunakan perintah
pip install dvc dvc. Setelah instalasi, Anda harus menginisialisasi DVC dalam folder proyek dvc
dvc init , yang akan menghasilkan satu set folder untuk pekerjaan DVC selanjutnya.
4. checkout cabang baru di repositori demo (untuk tidak menghapus konten master branch)
git checkout -b dvc-tutorial
5. Inisialisasi DVC
dvc init commit dvc init git commit -m "Initialize DVC"
DVC berjalan di atas Git, menggunakan infrastrukturnya, dan memiliki sintaksis yang serupa.
Dalam prosesnya, DVC membuat file meta untuk menggambarkan saluran pipa dan file berversi, yang perlu Anda simpan di Git sejarah proyek Anda. Karena itu, setelah menjalankan
dvc init Anda harus menjalankan
git commit untuk melakukan semua pengaturan yang dibuat.
Folder
.dvc akan muncul di repositori Anda, di mana
cache dan
config akan terletak.
Isi
.dvc akan terlihat seperti ini:
./ ../ .gitignore cache/ config
Config adalah konfigurasi DVC, dan cache adalah folder sistem tempat DVC akan menyimpan semua data dan model yang akan Anda versi.
DVC juga akan membuat file
.gitignore , di mana ia akan menulis file dan folder yang tidak perlu dikomit ke repositori. Ketika Anda mentransfer file ke DVC untuk versi di Git, versi dan metadata akan disimpan, dan file itu sendiri akan disimpan dalam cache.
Sekarang Anda perlu menginstal semua dependensi, dan kemudian melakukan
checkout di cabang
dvc-tutorial , di mana kami akan bekerja. Dan unduh dataset Iris.
Dapatkan data
wget -P data/ https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
Fitur DVC
Model Versi dan Data
Sumbernya ada di
sini .
Biarkan saya mengingatkan Anda bahwa jika Anda mentransfer beberapa data di bawah kendali DVC, maka itu akan mulai melacak semua perubahan. Dan kita dapat bekerja dengan data ini dengan cara yang sama seperti dengan Git: simpan versi, kirim ke repositori jarak jauh, dapatkan versi data yang benar, ubah dan alihkan di antara versi. Antarmuka di DVC sangat sederhana.
Masukkan perintah
dvc add dan tentukan path ke file yang perlu kita versi. DVC akan membuat metafile iris.csv dengan ekstensi .dvc, dan menulis informasi tentangnya ke folder cache. Mari kita komit perubahan ini sehingga informasi di awal versi muncul di riwayat Git.
dvc add data/iris.csv
Di dalam file dvc yang dihasilkan, hash-nya disimpan dengan parameter standar.
Output - path ke file dalam folder dvc, yang kami tambahkan di bawah kendali DVC. Sistem mengambil data, memasukkannya ke dalam cache dan membuat tautan ke cache di direktori yang berfungsi. File ini dapat ditambahkan ke riwayat Git dan karenanya diversi. DVC mengambil alih pengelolaan data itu sendiri. Dua karakter pertama dari hash digunakan sebagai folder di dalam cache, dan karakter yang tersisa digunakan sebagai nama file yang dibuat.
 Otomatisasi saluran pipa ML
Otomatisasi saluran pipa MLSelain kontrol versi data, kita dapat membuat jaringan pipa (pipeline) - rantai perhitungan di mana dependensi didefinisikan. Berikut ini adalah saluran pipa standar untuk pelatihan dan penilaian pengklasifikasi:
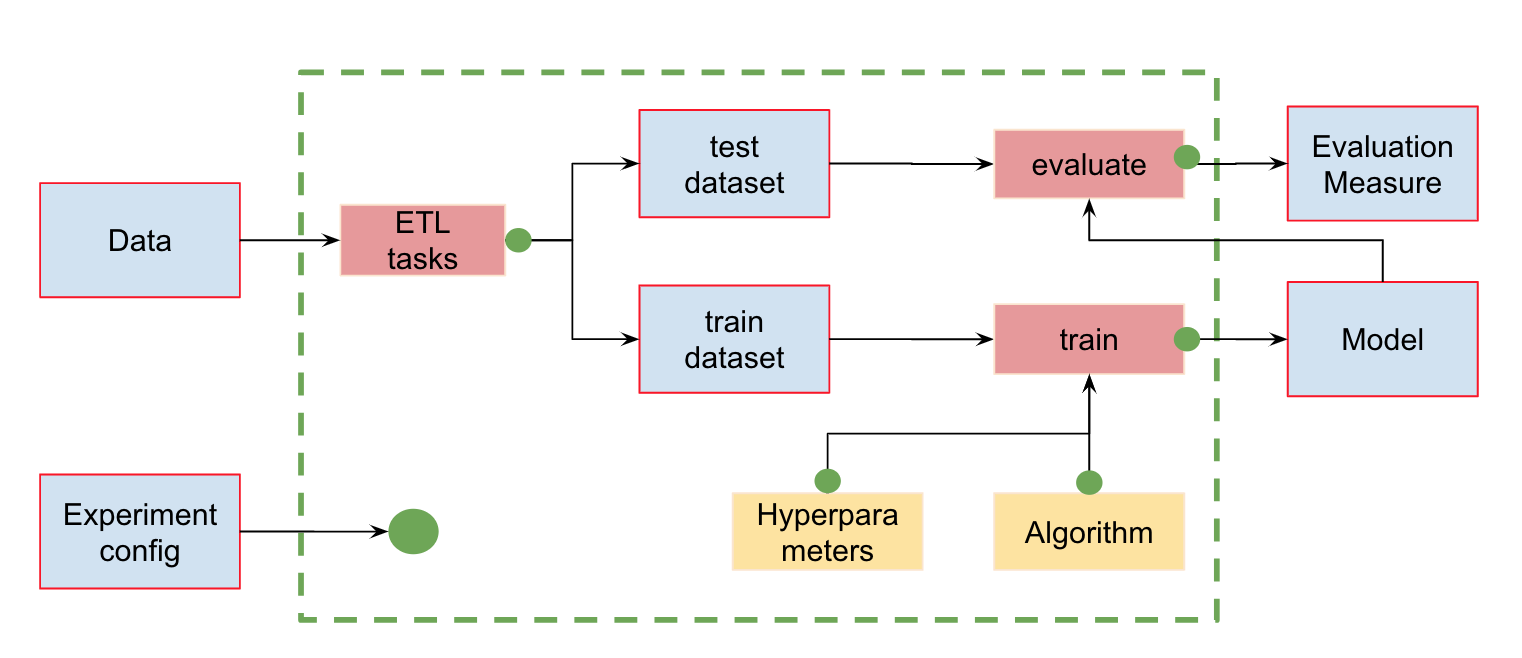
Pada input, kami memiliki data yang harus diproses lebih dulu, dibagi menjadi kereta dan tes, menghitung karakteristik dan hanya kemudian melatih model dan mengevaluasinya. Pipa ini dapat dipecah menjadi beberapa bagian yang terpisah. Misalnya, untuk membedakan tahap memuat dan memproses data, memisahkan data, mengevaluasi, dll., Dan menghubungkan rantai-rantai ini bersama-sama.
Untuk melakukan ini, DVC memiliki perintah dvc
dvc run luar biasa, di mana kita memberikan parameter tertentu dan menentukan modul Python yang perlu kita jalankan.
Sekarang - misalnya, fase peluncuran perhitungan tanda. Pertama, mari kita lihat isi modul featureization.py:
import pandas as pd def get_features(dataset): features = dataset.copy()
Kode ini mengambil dataset, menghitung karakteristik dan menyimpannya di iris_featurized.csv. Kami meninggalkan perhitungan tanda-tanda tambahan ke tahap berikutnya.
Untuk membuat pipa, Anda perlu menjalankan perintah untuk setiap tahap perhitungan
dvc run .

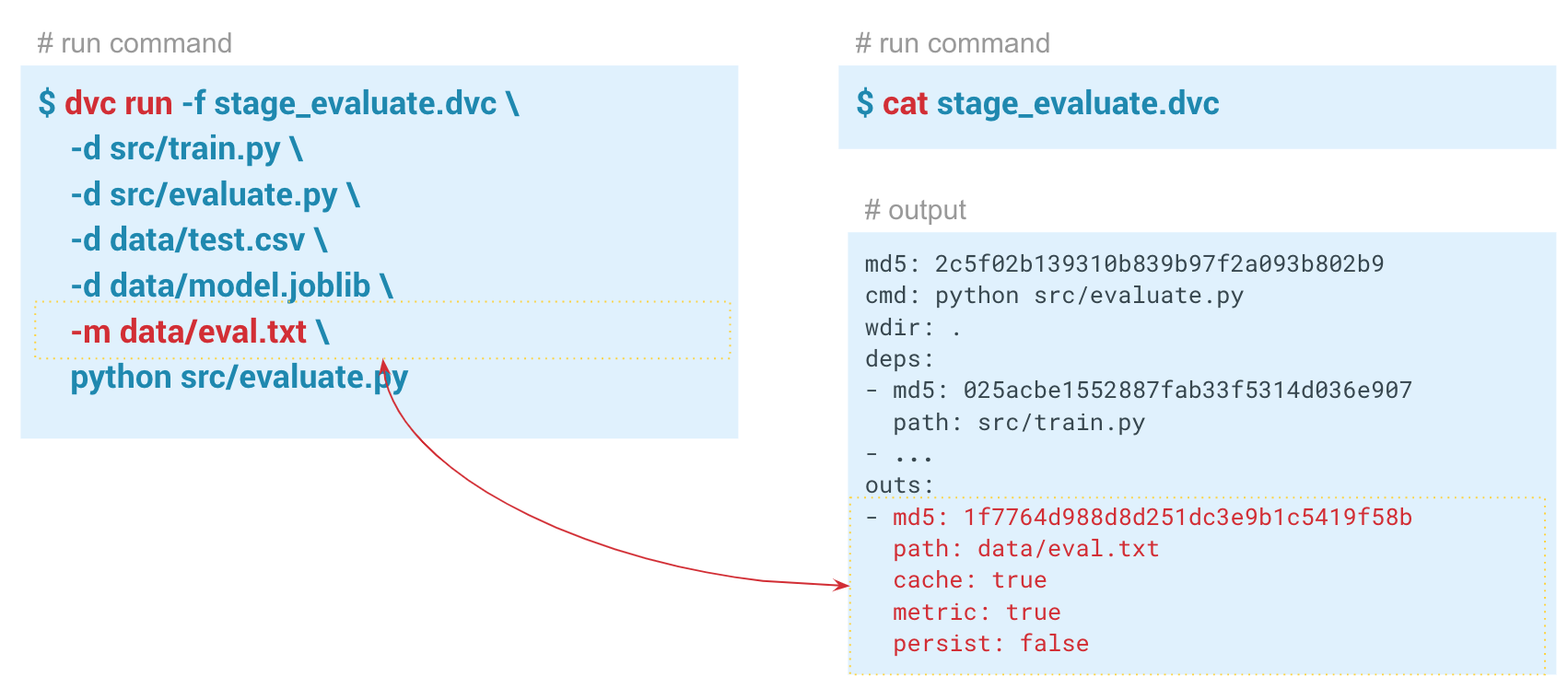
Pertama, dalam perintah
dvc run dvc, tentukan nama metafile stage_feature_extraction.dvc, di mana DVC akan menulis metadata yang diperlukan tentang tahap perhitungan. Melalui argumen
-d , kita menentukan dependensi yang diperlukan: modul featureization.py dan file data iris.csv. Kami juga menentukan file iris_featurized.csv, di mana tanda-tanda disimpan, dan perintah peluncuran python src / Featureization.py itu sendiri.
dvc run -f stage_feature_extraction.dvc \ -d src/featurization.py \ -d data/iris.csv \ -o data/iris_featurized.csv \ python src/featurization.py
DVC akan membuat metafile dan melacak perubahan pada modul Python dan file iris.csv.
Jika ada perubahan di dalamnya, DVC akan memulai kembali langkah perhitungan ini di dalam pipa.
File stage_feature_extraction.dvc yang dihasilkan akan berisi hash, perintah mulai, dependensi, dan output (ada parameter tambahan untuk mereka yang dapat ditemukan dalam metadata).
Sekarang Anda perlu menyimpan file ini dalam riwayat komit Git. Jadi, kita bisa membuat cabang baru dan mendorongnya ke repositori Git. Anda dapat berkomitmen pada cerita Git baik dengan membuat setiap tahap secara individual, atau semua tahap sekaligus.
Ketika kami membangun rantai seperti itu untuk seluruh percobaan kami, DVC membangun grafik perhitungan (DAG), yang dengannya ia dapat mulai menghitung ulang seluruh pipa atau sebagian. Hash dari output dari satu tahap pergi ke input dari yang lain. Menurut mereka, DVC melacak dependensi dan membuat grafik perhitungan. Jika Anda mengubah kode di suatu tempat di split_dataset.py, DVC tidak akan memuat data dan mungkin menghitung ulang tanda-tanda, tetapi akan memulai kembali tahap ini dan pelatihan berikutnya dan tahap evaluasi.
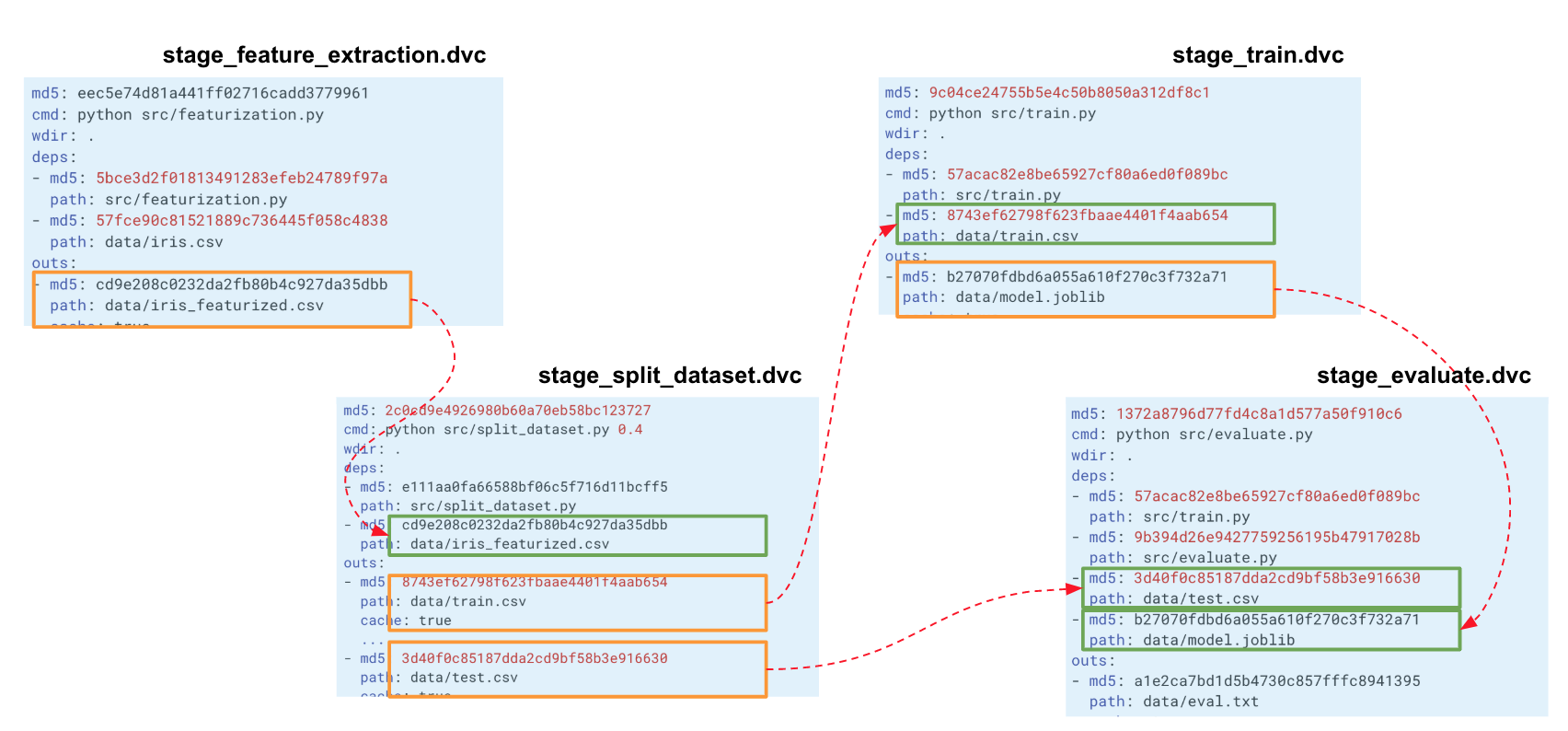 Pelacakan metrik
Pelacakan metrikMenggunakan perintah
dvc metrics show , Anda dapat menampilkan metrik dari peluncuran saat ini, cabang tempat kami berada. Dan jika kita melewati opsi
-a , DVC akan menampilkan semua metrik yang ada dalam sejarah Git. Agar DVC memulai metrik pelacakan, saat membuat langkah evaluasi, kami meneruskan parameter
-m melalui data / eval.txt. Modul evalu.py menulis metrik ke file ini, dalam hal ini
f1 dan
confusion metrics . Dalam folder output di file dvc dari langkah ini,
cache dan
metrics disetel ke true. Artinya, perintah acara metrik dvc akan menampilkan konten file eval.txt ke konsol. Juga, dengan menggunakan argumen dari perintah ini, Anda hanya dapat menampilkan
f1_score atau hanya
confusion_matrix .
Dalam contoh ini, kami mendapat hasil ini:
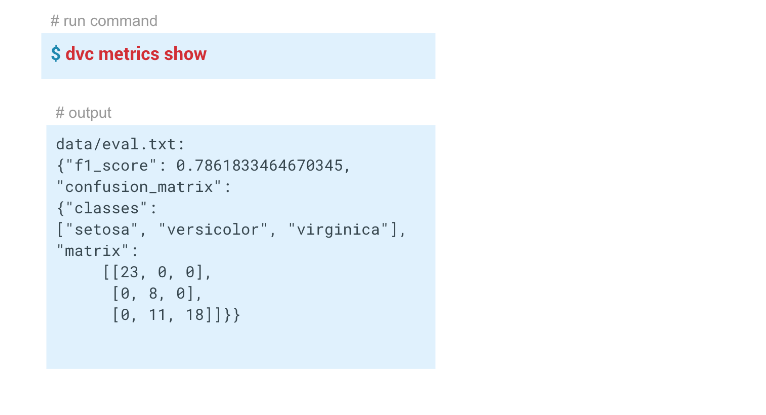 Reproduksibilitas pipa
Reproduksibilitas pipaMereka yang telah bekerja dengan dataset ini tahu bahwa sangat sulit untuk membangun model yang bagus di atasnya.
Sekarang kami memiliki saluran pipa yang dibuat menggunakan DVC. Sistem melacak riwayat data dan model, dapat memulai ulang secara keseluruhan atau sebagian, dan dapat menampilkan metrik. Kami telah menyelesaikan semua otomatisasi yang diperlukan.
Kami memiliki model dengan f1 = 0,78. Kami ingin memperbaikinya dengan mengubah beberapa parameter. Untuk melakukan ini, restart seluruh pipa, idealnya, dengan satu perintah. Selain itu, jika Anda bekerja dalam sebuah tim, Anda mungkin ingin meneruskan model dan kode tersebut kepada kolega sehingga mereka dapat terus mengerjakannya.
dvc repro memungkinkan
dvc repro untuk me-restart pipa atau tahapan individu (dalam hal ini, Anda perlu menentukan tahap yang direproduksi setelah perintah).
dvc repro stage_evaluate , tahap akan mencoba untuk me-restart seluruh pipa. Tetapi jika kita melakukan ini dalam keadaan saat ini, DVC tidak akan melihat perubahan dan tidak akan memulai ulang. Dan jika kita mengubah sesuatu, dia akan menemukan perubahan dan memulai kembali pipa sejak saat itu.
$ dvc repro stage_evaluate.dvc Stage 'data/iris.csv.dvc' didn't change. Stage 'stage_feature_extraction.dvc' didn't change. Stage 'stage_split_dataset.dvc' didn't change. Stage 'stage_train.dvc' didn't change. Stage 'stage_evaluate.dvc' didn't change. Pipeline is up to date. Nothing to reproduce.
Dalam hal ini, DVC tidak melihat perubahan apa pun dalam dependensi stage_evaluate dan menolak untuk memulai kembali. Dan jika kita menentukan opsi
-f , maka itu akan memulai kembali semua langkah awal dan menunjukkan peringatan bahwa itu menghapus versi sebelumnya dari data yang dilacak. Setiap kali DVC me-restart panggung, itu menghapus cache sebelumnya, sebenarnya menimpa itu agar tidak menggandakan data. Saat ini file DVC diluncurkan, hash-nya akan diperiksa, dan jika sudah berubah, pipeline akan restart dan menimpa semua output yang dimiliki pipeline ini. Jika Anda ingin menghindari ini, maka Anda harus terlebih dahulu menjalankan versi data tertentu di beberapa repositori jarak jauh.
Kemampuan untuk memulai ulang pipa dan melacak dependensi setiap tahap memungkinkan Anda untuk bereksperimen dengan model lebih cepat.
Misalnya, Anda dapat mengubah karakteristik ('batalkan komentar' pada baris untuk menghitung karakteristik dalam
featurization.py ). DVC akan melihat perubahan ini dan memulai ulang seluruh pipa.
Menyimpan data ke repositori jarak jauh
DVC dapat bekerja tidak hanya dengan penyimpanan versi lokal. Jika Anda menjalankan perintah dvc
dvc push , DVC akan mengirimkan versi model dan data saat ini ke repositori repositori jarak jauh yang telah dikonfigurasi sebelumnya. Jika kolega Anda membuat
git clone repositori dan
dvc pull , ia akan mendapatkan versi data dan model yang dimaksudkan untuk cabang ini. Yang utama adalah bahwa setiap orang memiliki akses ke repositori ini.
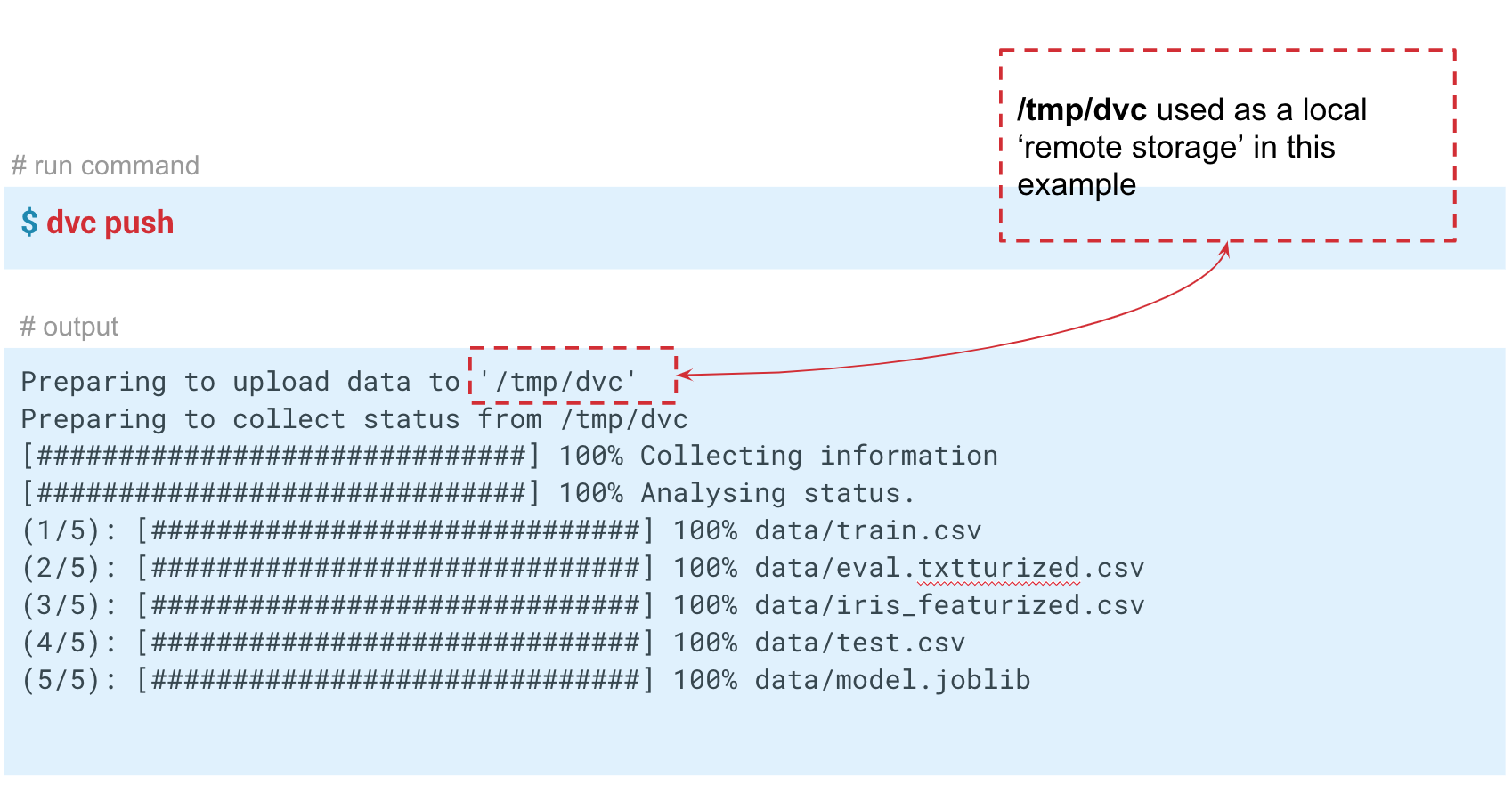
Dalam hal ini, kami mensimulasikan penyimpanan "jarak jauh" di folder temp / dvc. Dengan cara yang kira-kira sama, penyimpanan jarak jauh dibuat di cloud. Komit perubahan ini sehingga tetap dalam cerita Git. Sekarang kita bisa melakukan
dvc push untuk mengirim data ke penyimpanan ini, dan kolega Anda hanya melakukan
dvc pull untuk mendapatkannya.
Jadi , kami memeriksa tiga situasi di mana DVC dan fungsi dasar berguna:
- Versi data dan model . Jika Anda tidak memerlukan saluran pipa dan repositori jarak jauh, Anda dapat membuat versi data untuk proyek tertentu, bekerja pada mesin lokal. DVC memungkinkan Anda untuk dengan cepat bekerja dengan data dalam puluhan gigabyte.
- Pertukaran data dan model antar tim . Anda dapat menggunakan solusi cloud untuk menyimpan data. Ini adalah opsi yang nyaman jika Anda memiliki tim yang didistribusikan atau ada batasan pada ukuran file yang dikirim melalui pos. Juga, teknik ini dapat digunakan dalam situasi ketika Anda saling mengirim Notebook, tetapi mereka tidak memulai.
- Organisasi kerja tim di dalam server besar . Tim dapat bekerja dengan data besar versi lokal, misalnya, beberapa puluh atau ratusan gigabyte, sehingga Anda tidak menyalinnya bolak-balik, tetapi menggunakan satu penyimpanan jarak jauh yang akan mengirim dan menyimpan hanya versi kritis model atau data.
Bagian 2
Bagaimana cara mengimplementasikan DVC dalam proyek Anda?Untuk memastikan reproduktifitas proyek, persyaratan tertentu harus diperhatikan.
Inilah yang utama:
- semua pipa otomatis;
- kontrol parameter peluncuran setiap tahap perhitungan;
- kontrol versi terhadap kode, data, dan model;
- kontrol lingkungan;
- dokumentasi.
Jika semua ini dilakukan, maka proyek lebih mungkin direproduksi. DVC memungkinkan Anda untuk memenuhi 3 persyaratan pertama dalam daftar ini.
Ketika mencoba menerapkan DVC di perusahaan Anda, Anda mungkin menemui keengganan: “Mengapa kami membutuhkan ini? Kami memiliki Notebook Jupyter. " Mungkin beberapa rekan Anda hanya bekerja dengan Jupyter Notebook, dan jauh lebih sulit bagi mereka untuk menulis pipa dan kode seperti itu di IDE. Dalam hal ini, Anda bisa melalui implementasi langkah-demi-langkah.
- Cara termudah untuk memulai adalah dengan mengversi kode dan model.
Dan kemudian beralih ke mengotomatisasi jalur pipa. - Pertama mengotomatiskan langkah-langkah yang sering dimulai ulang dan diubah,
dan kemudian seluruh pipa.
Jika Anda memiliki proyek baru dan beberapa penggemar dalam satu tim, maka lebih baik segera menggunakan DVC. Jadi, misalnya, ternyata di tim kami! Ketika memulai proyek baru, kolega saya mendukung saya, dan kami mulai menggunakan DVC sendiri. Kemudian mereka mulai berbagi dengan kolega dan tim lain. Seseorang mengambil tugas kita. Saat ini, DVC belum menjadi alat yang diterima secara umum di bank kami, tetapi digunakan dalam beberapa proyek.