Catatan perev. : Kami hadir untuk perhatian Anda perincian teknis tentang alasan downtime layanan cloud baru-baru ini yang dilayani oleh pencipta Grafana. Ini adalah contoh klasik tentang bagaimana fitur baru dan tampaknya sangat berguna yang dirancang untuk meningkatkan kualitas infrastruktur ... dapat sangat merugikan jika seseorang tidak melihat banyak nuansa penerapannya dalam realitas produksi. Luar biasa ketika materi seperti itu muncul yang memungkinkan Anda belajar tidak hanya dari kesalahan Anda. Rincian dalam terjemahan teks ini dari wakil presiden produk dari Grafana Labs.
Pada hari Jumat, 19 Juli, layanan Hosted Prometheus di Grafana Cloud berhenti bekerja selama sekitar 30 menit. Saya minta maaf kepada semua klien yang menderita kegagalan. Tugas kami adalah menyediakan alat yang diperlukan untuk pemantauan, dan kami memahami bahwa tidak dapat diaksesnya hal tersebut mempersulit hidup Anda. Kami menangani insiden ini dengan sangat serius. Catatan ini menjelaskan apa yang terjadi, bagaimana kami bereaksi terhadapnya, dan apa yang kami lakukan sehingga ini tidak terjadi lagi.
Latar belakang
Layanan Grafana Cloud Hosted Prometheus didasarkan pada
Cortex , sebuah proyek CNCF untuk membuat layanan Prometheus multi-tenant yang dapat diskalakan secara horizontal, sangat mudah diakses. Arsitektur Cortex terdiri dari serangkaian layanan microser terpisah, yang masing-masing menjalankan fungsinya: replikasi, penyimpanan, permintaan, dll. Cortex sedang dikembangkan secara aktif, terus-menerus memiliki peluang baru dan meningkatkan produktivitas. Kami secara teratur menyebarkan rilis Cortex baru ke cluster sehingga pelanggan dapat memanfaatkan peluang ini - untungnya, Cortex dapat memperbarui tanpa downtime.
Untuk pembaruan yang lancar, layanan Ingester Cortex memerlukan replika Ingester tambahan selama proses pembaruan.
( Catatan : Ingester adalah komponen inti Cortex. Tugasnya adalah mengumpulkan aliran sampel yang konstan, mengelompokkannya menjadi potongan Prometheus dan menyimpannya dalam basis data seperti DynamoDB, BigTable atau Cassandra.) Ini memungkinkan Ingesters yang lebih tua. meneruskan data saat ini ke Ingester baru. Perlu dicatat bahwa Ingester menuntut sumber daya. Untuk pekerjaan mereka perlu memiliki 4 core dan 15 GB memori per pod, mis. 25% dari daya prosesor dan memori mesin dasar dalam kasus kluster Kubernet kami. Secara umum, kami biasanya memiliki lebih banyak sumber daya yang tidak terpakai dalam sebuah cluster dari 4 core dan memori 15 GB, sehingga kami dapat dengan mudah menjalankan Ingester tambahan ini selama pembaruan.
Namun, sering terjadi bahwa selama operasi normal tidak satu pun dari mesin ini memiliki 25% dari sumber daya yang tidak diklaim. Ya, kami tidak berusaha: CPU dan memori selalu berguna untuk proses lain. Untuk mengatasi masalah ini, kami memutuskan untuk menggunakan
Kubernetes Pod Priorities . Idenya adalah untuk memberikan Ingester prioritas yang lebih tinggi daripada layanan microser lainnya (stateless). Saat kami perlu menjalankan Ingester tambahan (N +1), untuk sementara kami mengeluarkan pod lainnya yang lebih kecil. Pod ini ditransfer ke sumber daya gratis di mesin lain, meninggalkan "lubang" yang cukup besar untuk meluncurkan Ingester tambahan.
Pada hari Kamis, 18 Juli, kami meluncurkan empat tingkat prioritas baru dalam kelompok kami:
kritis ,
tinggi ,
sedang dan
rendah . Mereka diuji pada cluster internal tanpa lalu lintas klien selama sekitar satu minggu. Secara default, polong tanpa prioritas tertentu mendapat prioritas
sedang , kelas dengan prioritas
tinggi ditetapkan untuk Ingesters.
Critical dicadangkan untuk pemantauan (Prometheus, Alertmanager, simpul-eksportir, metrik kube-state, dll.). Konfigurasi kami terbuka, dan lihat PR di
sini .
Kecelakaan
Pada hari Jumat, 19 Juli, salah satu insinyur meluncurkan kluster Cortex khusus baru untuk klien besar. Konfigurasi untuk klaster ini tidak termasuk prioritas pod baru, jadi semua pod baru diberi prioritas default -
medium .
Cluster Kubernetes tidak memiliki sumber daya yang cukup untuk cluster Cortex baru, dan cluster produksi Cortex yang ada tidak diperbarui (Ingester dibiarkan tanpa prioritas
tinggi ). Karena Ingesters dari cluster baru default ke prioritas
menengah , dan polong yang ada dalam produksi bekerja tanpa prioritas sama sekali, Ingester dari cluster baru mengusir Ingesters dari cluster produksi Cortex yang ada.
ReplicaSet untuk Ingester yang dikecualikan dalam klaster produksi mendeteksi pod yang dikecam dan membuat yang baru untuk mempertahankan jumlah salinan yang ditentukan. Pod baru ditetapkan ke prioritas
sedang secara default, dan Ingester "lama" berikutnya dalam produksi kehilangan sumber daya. Hasilnya adalah
proses seperti longsoran salju yang menyebabkan crowding out semua polong dari Ingester untuk cluster produksi Cortex.
Ingester menyimpan status dan menyimpan data selama 12 jam sebelumnya. Ini memungkinkan kita untuk mengompres mereka lebih efisien sebelum menulis ke penyimpanan jangka panjang. Untuk melakukan ini, Cortex membuang data seri menggunakan Tabel Hash Terdistribusi (DHT), dan mereplikasi setiap seri menjadi tiga Ingester menggunakan konsistensi kuorum gaya Dynamo. Cortex tidak menulis data ke Ingesters, yang dinonaktifkan. Jadi, ketika sejumlah besar Ingester meninggalkan DHT, Cortex tidak dapat memberikan replikasi yang memadai dari catatan, dan mereka "jatuh".
Deteksi dan eliminasi
Pemberitahuan Prometheus baru berdasarkan "berbasis
kesalahan-anggaran " (rincian
berbasis kesalahan akan muncul di artikel mendatang) mulai membunyikan alarm 4 menit setelah dimulainya penutupan. Selama sekitar lima menit berikutnya, kami melakukan diagnosa dan memperluas kluster Kubernetes yang mendasarinya untuk mengakomodasi kluster produksi baru dan yang sudah ada.
Lima menit kemudian, Ingesters lama berhasil merekam data mereka, dan yang baru mulai, dan cluster Cortex menjadi tersedia lagi.
Butuh 10 menit lagi untuk mendiagnosis dan memperbaiki kesalahan kehabisan memori (OOM) dari proksi otentikasi terbalik yang terletak di depan Cortex. Kesalahan OOM disebabkan oleh peningkatan sepuluh kali lipat dalam QPS (seperti yang kami yakini, karena permintaan yang terlalu agresif dari server klien Prometheus).
Konsekuensinya
Total waktu henti adalah 26 menit. Tidak ada data yang hilang. Ingester telah berhasil mengunggah semua data dalam memori ke penyimpanan jangka panjang. Selama shutdown, server klien Prometheus membuat
buffer entri menggunakan
API remote_write berbasis WAL
baru (ditulis oleh
Callum Styan dari Grafana Labs) dan mengulangi entri yang gagal setelah kegagalan.
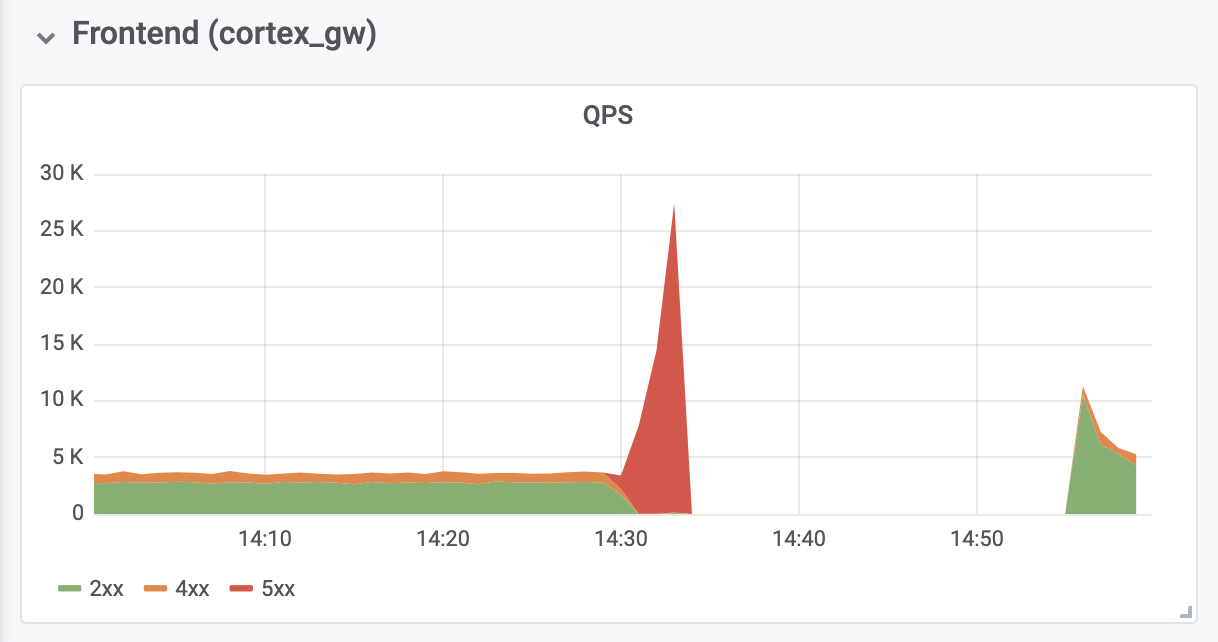 Operasi Penulisan Klaster Produksi
Operasi Penulisan Klaster ProduksiKesimpulan
Penting untuk belajar dari kejadian ini dan mengambil langkah-langkah yang diperlukan untuk menghindari terulangnya kejadian tersebut.
Melihat ke belakang, kita harus mengakui bahwa kita tidak boleh menetapkan prioritas
medium default, sampai semua Ingester dalam produksi menerima prioritas
tinggi . Selain itu, mereka harus menjaga prioritas
tinggi mereka terlebih dahulu. Sekarang semuanya sudah diperbaiki. Kami berharap pengalaman kami akan membantu organisasi lain mempertimbangkan penggunaan prioritas pod di Kubernetes.
Kami akan menambahkan tingkat kontrol tambahan atas penyebaran objek tambahan apa pun yang konfigurasinya bersifat global untuk kluster. Selanjutnya, perubahan tersebut akan dievaluasi oleh lebih banyak orang. Selain itu, modifikasi yang menyebabkan kegagalan dianggap terlalu tidak signifikan untuk dokumen proyek yang terpisah - itu hanya dibahas dalam masalah GitHub. Mulai sekarang, semua perubahan konfigurasi tersebut akan disertai dengan dokumentasi proyek yang sesuai.
Terakhir, kami mengotomatiskan pengubahan ukuran proksi otentikasi terbalik untuk mencegah OOM selama kemacetan, yang telah kami saksikan, dan menganalisis pengaturan Prometheus default yang terkait dengan rollback dan penskalaan untuk mencegah masalah serupa di masa mendatang.
Kegagalan yang dialami juga memiliki beberapa konsekuensi positif: setelah menerima sumber daya yang diperlukan, Cortex secara otomatis pulih tanpa intervensi tambahan. Kami juga mendapatkan pengalaman berharga dengan
Grafana Loki , sistem agregasi log baru kami, yang membantu memastikan bahwa semua Ingester berperilaku baik selama dan setelah kecelakaan.
PS dari penerjemah
Baca juga di blog kami: