Sebelum setiap layanan menghasilkan setidaknya 1 Mb / s lalu lintas Internet, muncul pertanyaan: “Bagaimana? lebih dari TCP atau lebih dari UDP? " Di bidang aplikasi, termasuk platform pengiriman, preferensi dan tradisi pengambilan keputusan telah dikembangkan.
Secara teori, jika, misalnya, ketika pengembang yang malas tidak mencoba menggunakan ML-nya dengan Python (karena dia hanya mengetahuinya), dunia kemungkinan besar tidak akan pernah dipenuhi dengan cinta seperti itu untuk bahasa "super-Java encoders" yang tercela. Dan hari ini, kelemahan bahasa ini dalam konteks aplikasi masa lalu tanpa syarat memberikannya keunggulan dalam penyebaran dan peluncuran banyak penambangan A / B.
Anda dapat membandingkan banyak: ARM dengan Intel, iOS dan Android, dan Mortal Kombat dengan Ketidakadilan. Dan mengalami holivar luar angkasa, jadi kembali ke topik pengiriman konten multi-format dalam jumlah besar.
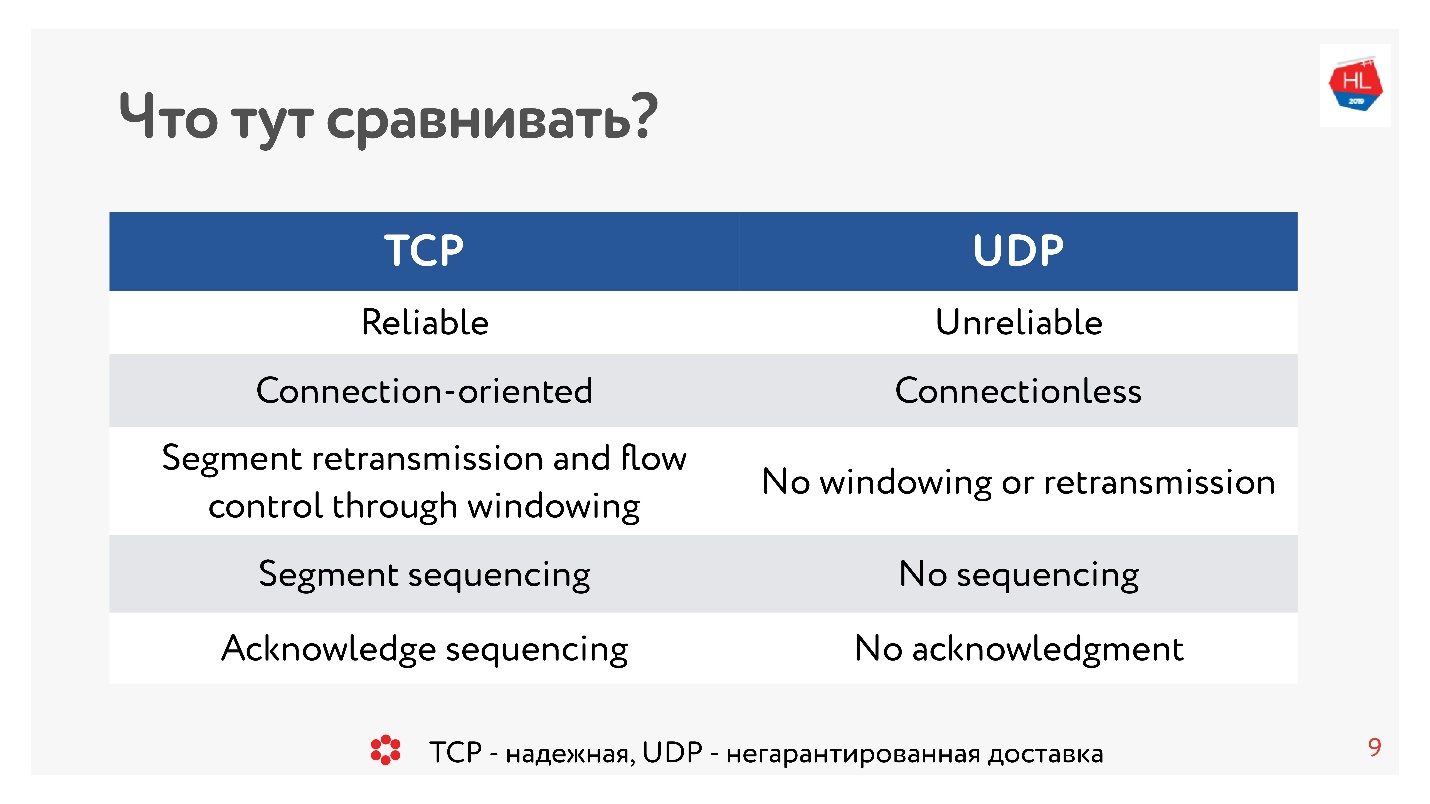
Sepuluh tahun yang lalu, semua orang benar-benar yakin UDP adalah sesuatu tentang pengiriman yang tidak dijamin. Jika Anda memerlukan protokol yang andal, ini TCP. Dan bertentangan dengan tradisi dalam artikel ini, kita akan membandingkan hal-hal yang tampaknya tak tertandingi seperti TCP dan UDP.
 Perhatian, di bawah potongan 99 ilustrasi dan diagram dan semuanya penting.
Perhatian, di bawah potongan 99 ilustrasi dan diagram dan semuanya penting.Perbandingan dilakukan oleh kepala pengembangan platform Video dan Tape di OK
Alexander Tobol (
alatobol ). Layanan Video dan Umpan Berita di jejaring sosial OK - secara eksklusif tentang konten dan pengirimannya ke semua platform klien yang ada dalam kondisi jaringan yang buruk atau luar biasa, dan pertanyaan tentang bagaimana mengirimkannya - melalui TCP atau UDP - sangat penting.
TCP vs UDP. Teori minimum
Untuk mendapatkan perbandingan, kita perlu sedikit teori dasar.
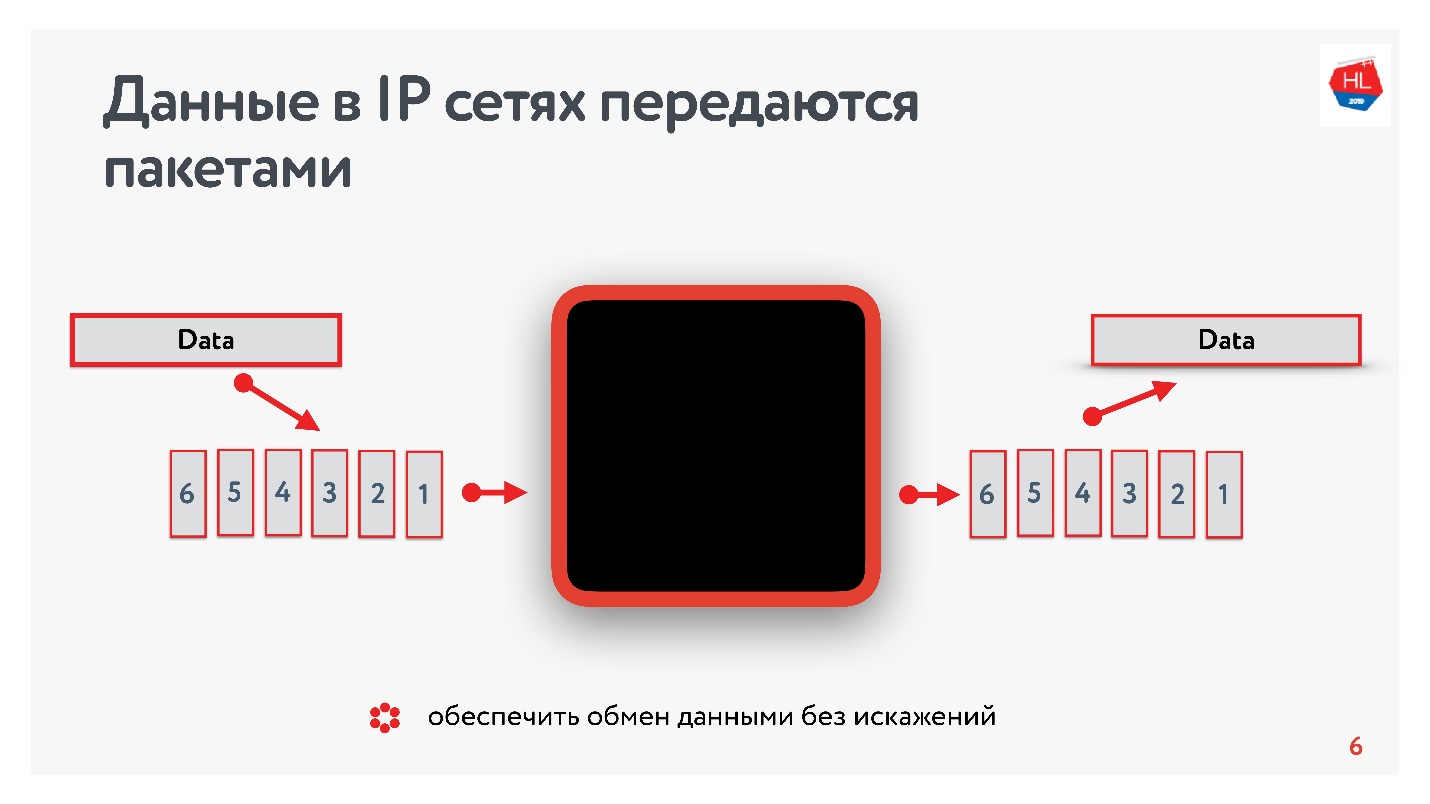
Apa yang kita ketahui tentang jaringan IP? Aliran data yang Anda kirim dibagi menjadi beberapa paket, semacam kotak hitam mengirimkan paket-paket ini ke klien. Klien mengumpulkan paket dan menerima aliran data. Biasanya ini semua transparan dan tidak perlu memikirkan apa yang ada di level bawah.
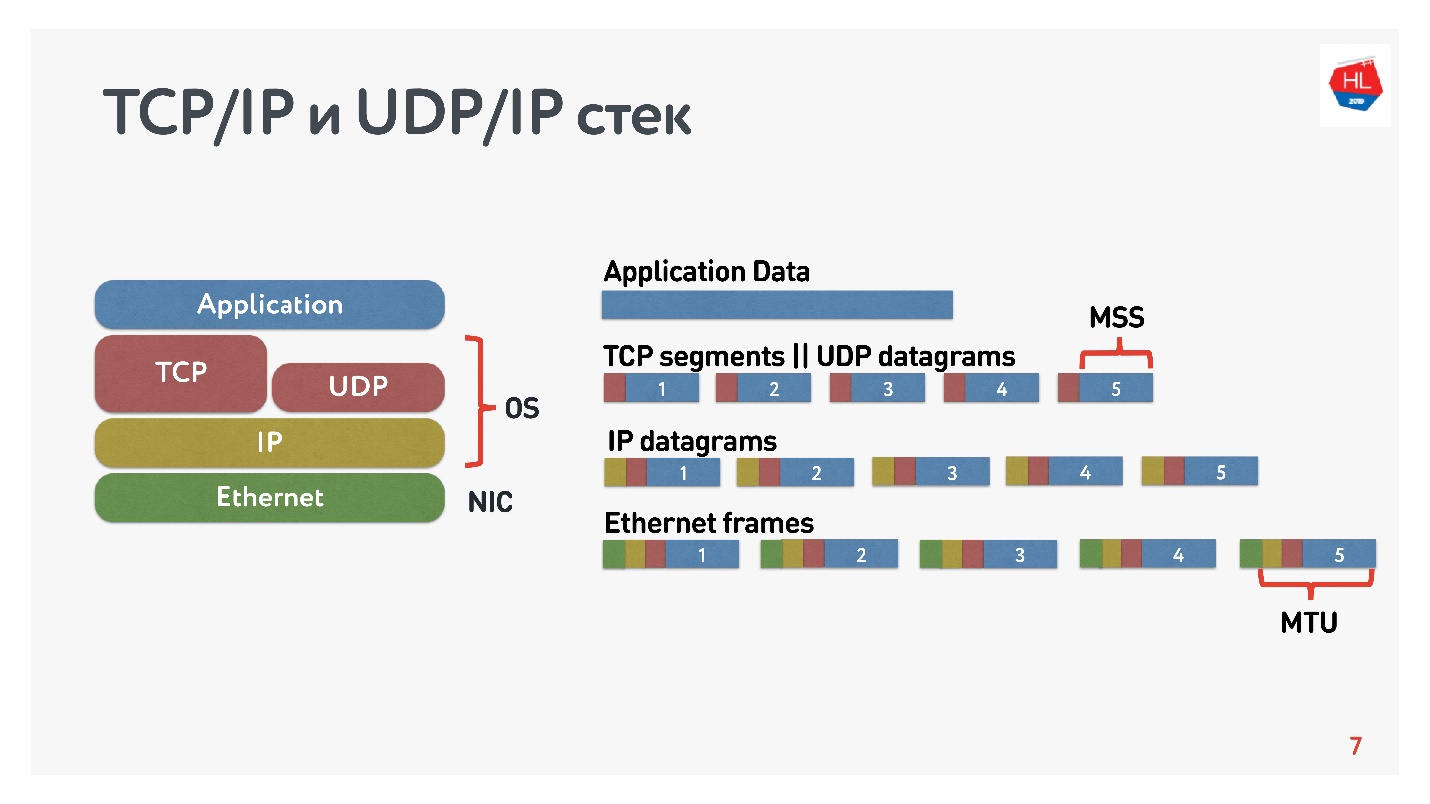
Diagram menunjukkan tumpukan TCP / IP dan UDP / IP. Di bagian bawah ada paket Ethernet, paket IP, dan selanjutnya di tingkat OS ada TCP dan UDP. TCP dan UDP dalam tumpukan ini tidak jauh berbeda satu sama lain. Mereka dienkapsulasi dalam paket IP, dan aplikasi dapat menggunakannya. Untuk melihat perbedaannya, Anda perlu melihat ke dalam paket TCP dan UDP.
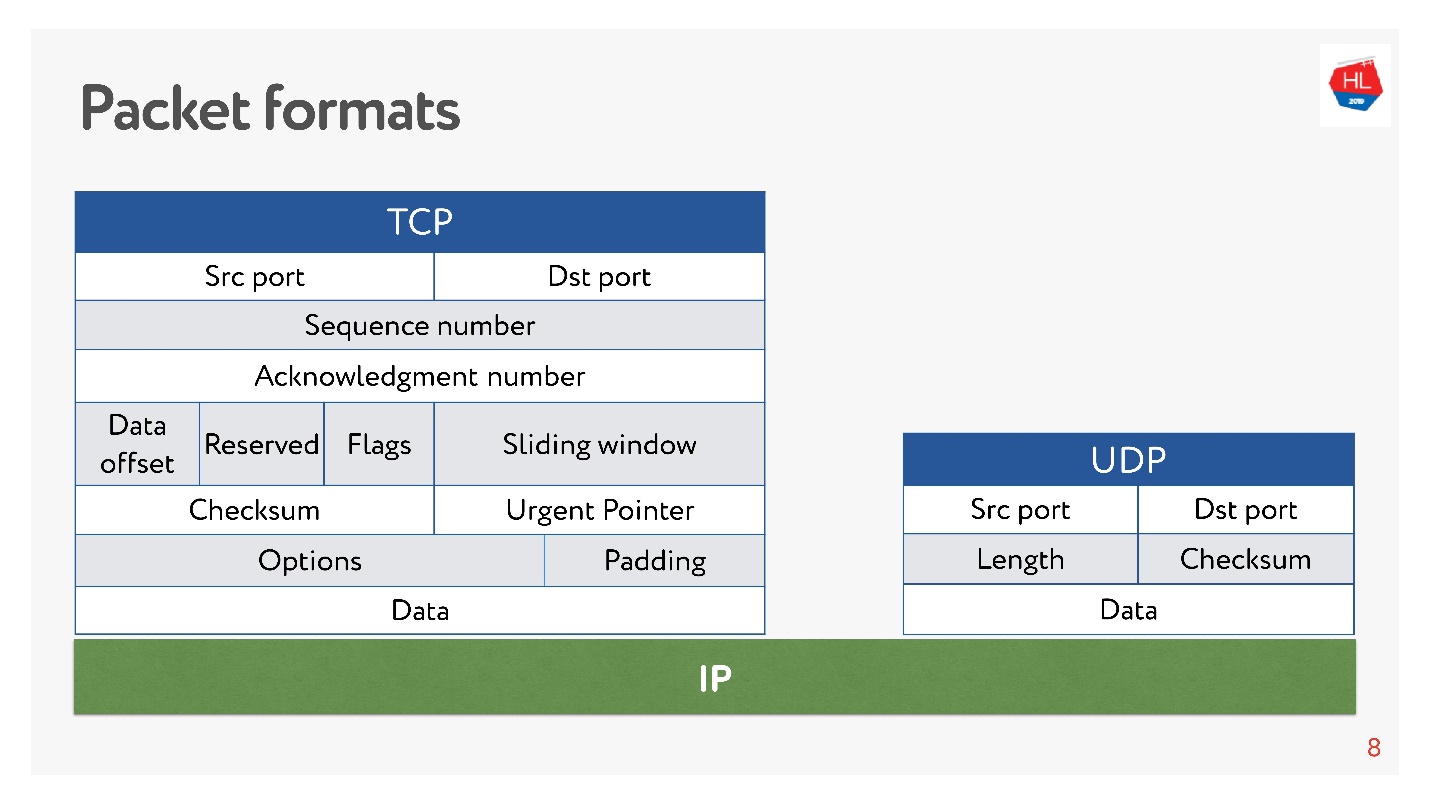
Baik di sana maupun di sana ada porta. Tetapi
dalam UDP hanya ada checksum - panjang paket, protokol ini sesederhana mungkin. Dan dalam TCP, ada banyak data yang secara jelas menunjukkan jendela, pengakuan, urutan, paket, dan sebagainya. Jelas
TCP lebih kompleks .
Berbicara sangat kasar, TCP adalah protokol pengiriman yang andal, dan UDP adalah protokol yang tidak bisa diandalkan.
Namun, terlepas dari dugaan tidak dapat diandalkannya UDP, kami akan mencari tahu apakah mungkin untuk mengirimkan data lebih cepat dan lebih dapat diandalkan daripada menggunakan TCP. Mari kita coba melihat jaringan dari dalam dan memahami cara kerjanya. Sepanjang jalan, kita akan menyentuh pertanyaan-pertanyaan berikut:
- mengapa membandingkan TCP atau apa yang salah dengannya;
- dengan apa dan apa yang harus Anda bandingkan TCP;
- apa yang Google lakukan dan keputusan apa yang diambilnya;
- apa masa depan protokol jaringan menunggu kita.
Artikel ini tidak akan memiliki teori: level dan model OSI, model matematika yang kompleks, meskipun semuanya dapat dihitung melalui mereka. Kami akan menganalisis secara maksimal bagaimana menyentuh jaringan tidak secara teori, tetapi dengan tangan kita sendiri.
Mengapa membandingkan TCP atau apa yang salah dengannya
TCP ditemukan pada 1974, dan 20 tahun kemudian, ketika saya pergi ke sekolah, saya membeli kartu Internet, menghapus kode, dan menelepon ke suatu tempat. Apalagi, jika Anda menelepon dari 2 malam hingga 7 pagi, maka internet gratis, tetapi sulit untuk dilewati.
Lain 20 tahun berlalu, dan pengguna pada jaringan nirkabel seluler mulai menang atas pengguna "kabel", sementara TCP secara konseptual tidak berubah.
Dunia seluler menang, protokol nirkabel muncul, dan TCP masih tidak berubah.
Saat ini, 80% pengguna menggunakan Wi-Fi atau jaringan nirkabel 3G-4G.

Dalam jaringan nirkabel, ada:
- packet loss - sekitar 0,6% dari paket yang kami kirim hilang di sepanjang jalan;
- penataan ulang - penataan ulang paket di tempat, dalam kehidupan nyata adalah fenomena yang agak langka, tetapi terjadi pada 0,2% kasus;
- jitter - ketika paket dikirim secara merata dan tiba dalam antrian dengan penundaan sekitar 50 ms.
TCP berhasil menyembunyikan semua fitur transfer data ini di jaringan heterogen dari Anda, dan Anda tidak perlu masuk ke dalamnya.
Di bawah ini pada peta adalah laju data TCP rata-rata di Rusia. Jika Anda menghapus bagian barat, jelas bahwa kecepatan diukur lebih dalam kilobit daripada di megabit.
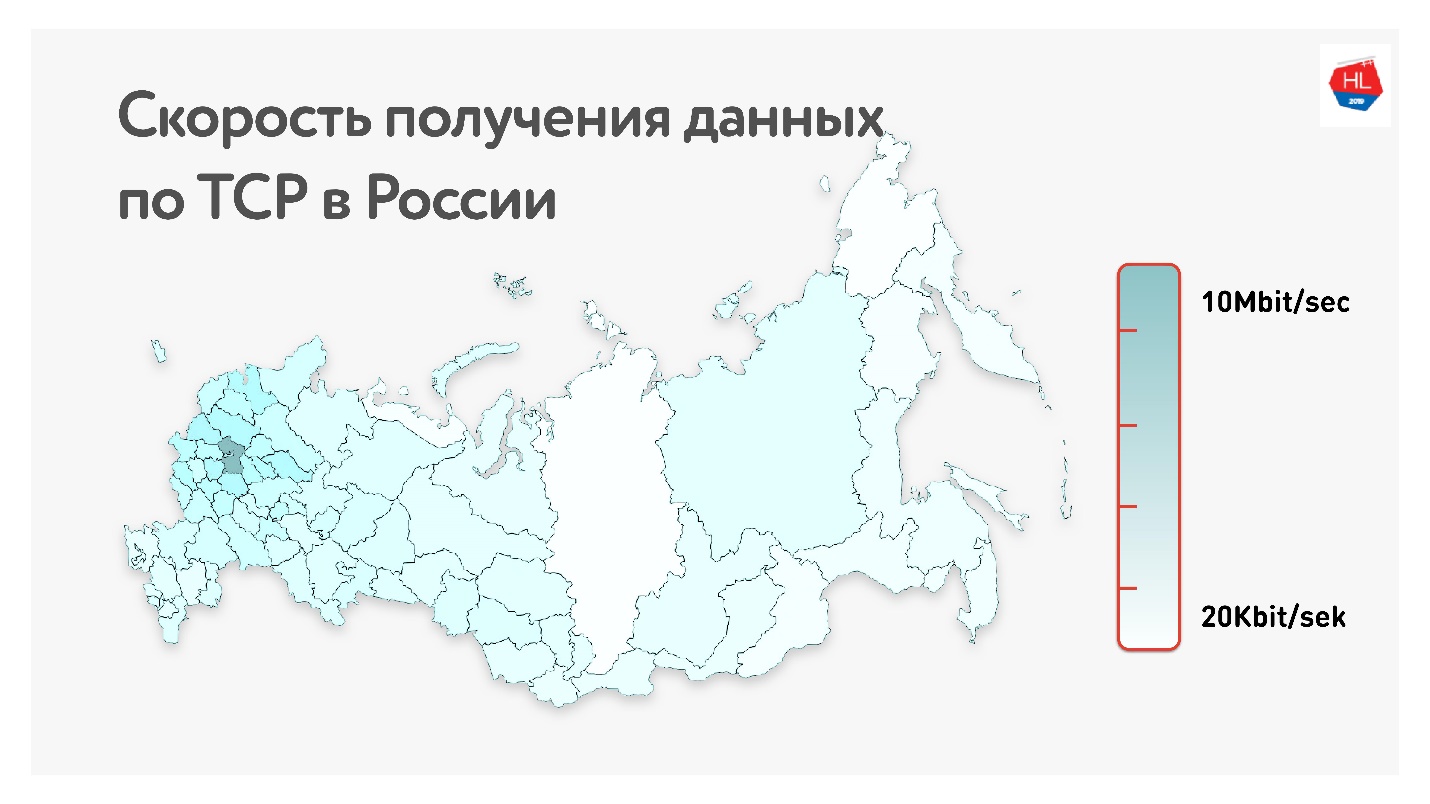
Itu, rata-rata, untuk pengguna kami (tidak termasuk bagian barat Rusia): throughput 1,1 Mbps, paket loss 0,6%, RTT (waktu pulang-pergi) sekitar 200 ms.
Bagaimana cara menghitung RTT
Ketika saya melihat rata-rata 200 ms, saya berpikir bahwa ada kesalahan dalam statistik, dan memutuskan untuk mengukur RTT ke server kami di MSC dengan cara alternatif menggunakan RIPE Atlas. Ini adalah sistem untuk mengumpulkan data tentang keadaan Internet. Probe
RIPE Atlas tersedia secara gratis.
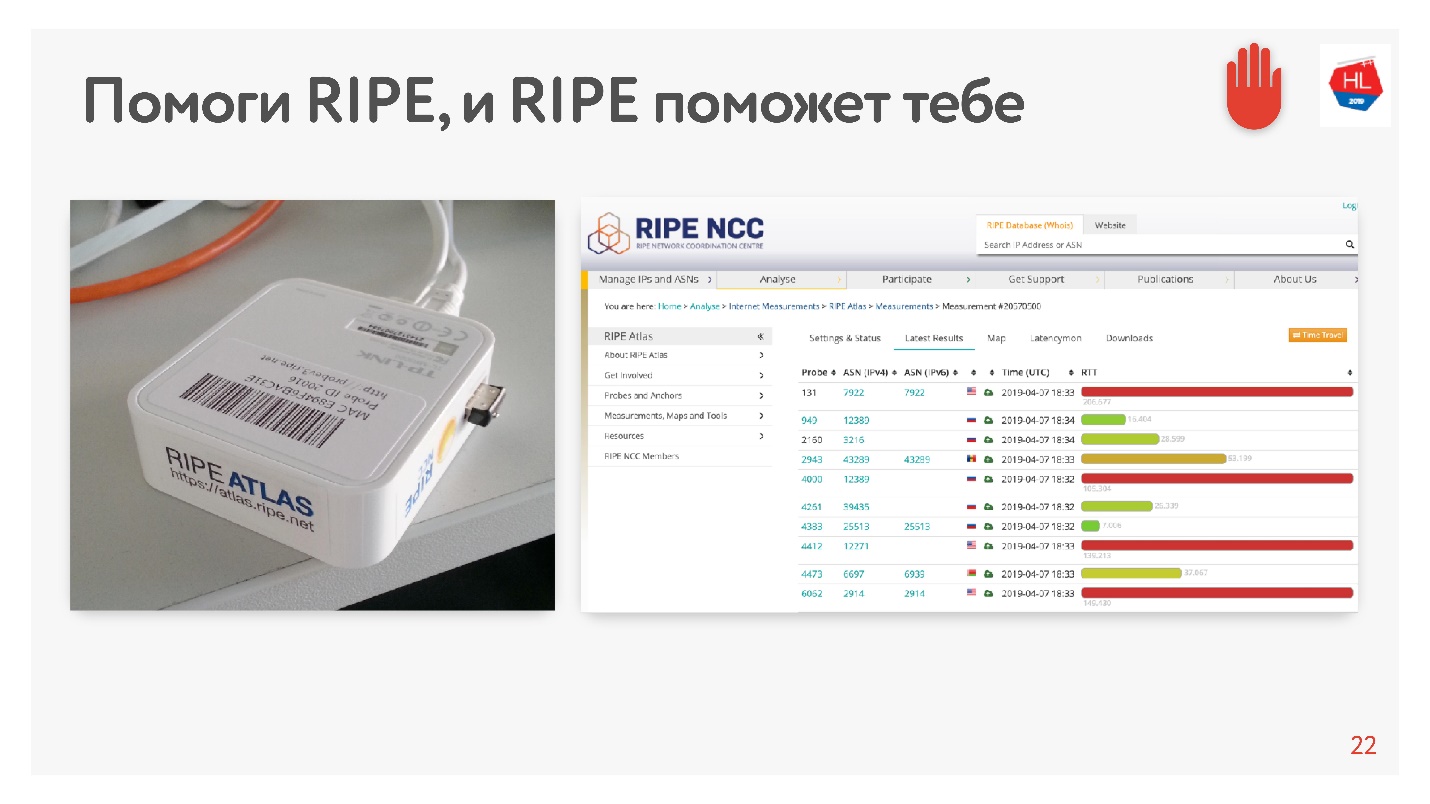
Intinya adalah bahwa Anda menghubungkannya ke Internet di rumah Anda dan mengumpulkan "karma". Dia bekerja selama berhari-hari, beberapa orang memenuhi beberapa permintaannya. Kemudian Anda dapat mengatur berbagai tugas sendiri. Contoh dari tugas seperti itu: secara tidak sengaja mengambil 30 poin di Internet, dan meminta untuk mengukur RTT, yaitu, jalankan perintah ping ke situs web Odnoklassniki.
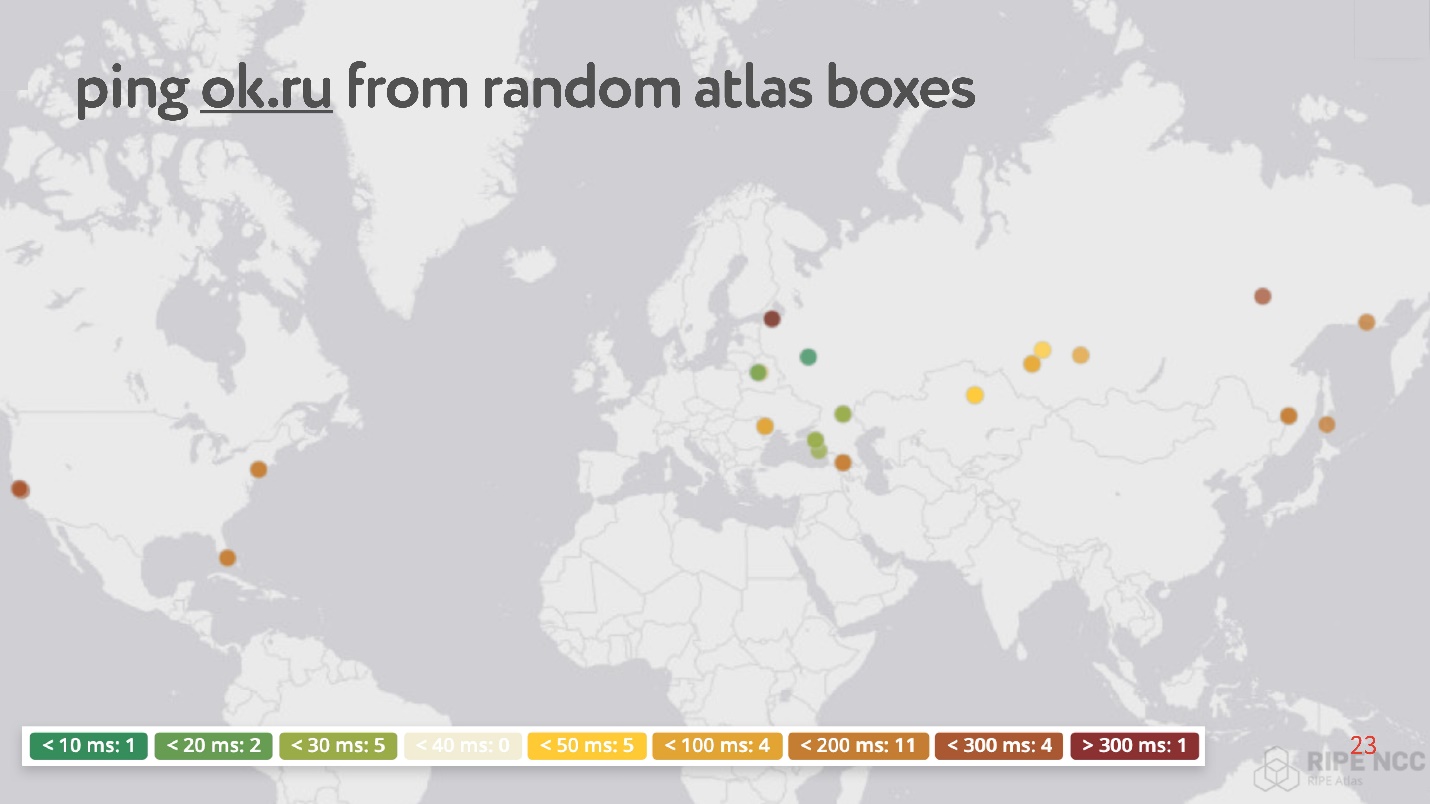
Anehnya, di antara titik-titik acak ada banyak yang memiliki ping dari 200 hingga 300 ms.
Secara keseluruhan,
jaringan nirkabel populer dan tidak stabil (meskipun yang terakhir biasanya diabaikan, karena diyakini bahwa TCP dapat menangani ini):
- Lebih dari 80% pengguna menggunakan internet nirkabel;
- Parameter jaringan nirkabel berubah secara dinamis tergantung, misalnya, pada kenyataan bahwa pengguna telah berbelok;
- Jaringan nirkabel memiliki tingkat kehilangan paket, jitter, pemesanan ulang yang tinggi;
- Memperbaiki saluran asimetris, mengubah alamat IP.
Konsumsi Konten Tergantung pada Kecepatan Internet
Ini sangat mudah diverifikasi - ada banyak statistik. Saya mengambil
statistik pada video, yang mengatakan bahwa semakin tinggi kecepatan internet di negara itu, semakin banyak pengguna menonton video.
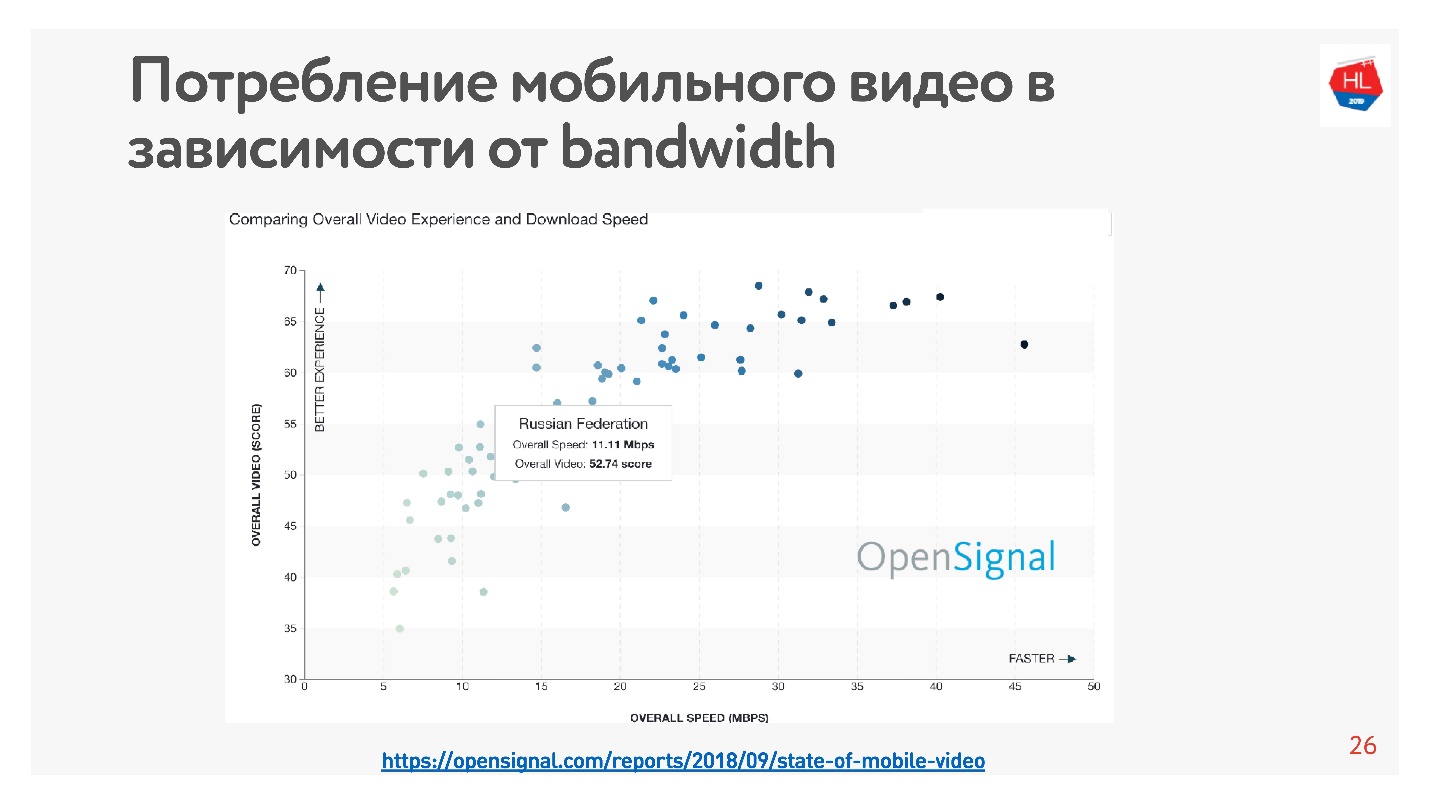
Menurut statistik ini, Rusia memiliki Internet yang cukup cepat, tetapi menurut data internal kami, kecepatan rata-rata sedikit lebih rendah.
Dalam mendukung fakta bahwa kecepatan internet secara keseluruhan tidak mencukupi, dikatakan bahwa semua pencipta aplikasi besar, jejaring sosial, layanan video dan sebagainya mengoptimalkan layanan mereka untuk bekerja di jaringan yang buruk. Setelah 10 Kb data yang diterima, Anda dapat melihat informasi minimum dalam rekaman, dan pada kecepatan 500 Kb Anda dapat menonton video.
Cara mempercepat pemuatan
Dalam proses pengembangan platform Video, kami menyadari bahwa TCP tidak terlalu efektif dalam jaringan nirkabel. Bagaimana Anda sampai pada kesimpulan ini?
Kami memutuskan untuk mempercepat unduhan dan melakukan trik berikutnya.
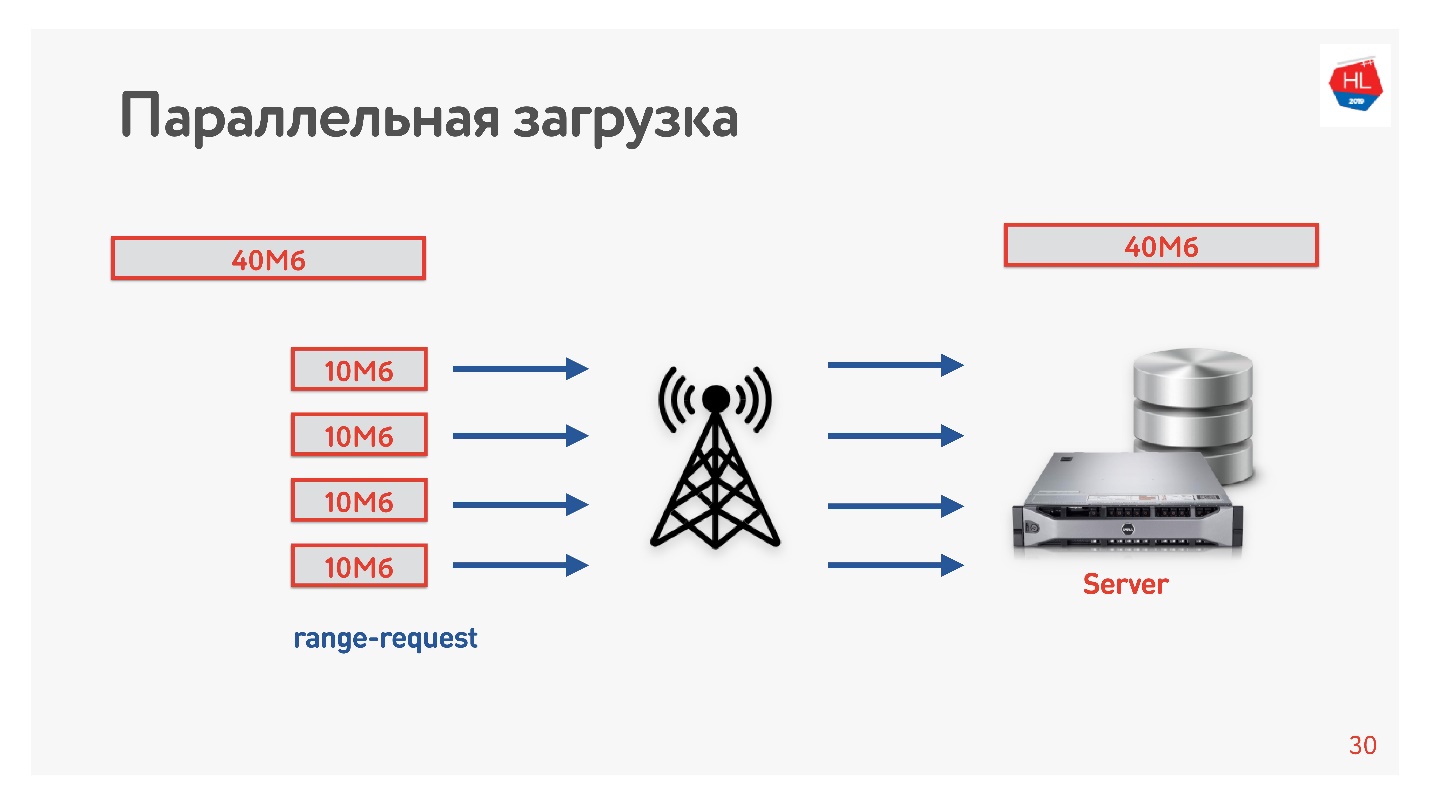
Kami mengunduh video dari klien ke server dalam beberapa aliran, yaitu, 40 MB dibagi menjadi 4 bagian dari 10 MB dan dimuat secara paralel. Kami memulainya di Android dan memuatnya secara paralel lebih cepat daripada dalam satu koneksi (
demo dalam laporan). Yang paling menarik adalah ketika kami meluncurkan unduhan paralel ke dalam produksi, kami melihat bahwa di beberapa daerah kecepatan unduhan meningkat 3 kali lipat!
Empat koneksi TCP sebenarnya dapat mengunggah data ke server 3 kali lebih cepat.
Jadi kami meningkatkan kecepatan pengunduhan video dan menyimpulkan bahwa pengunduhan perlu diparalelkan.
TCP di jaringan yang tidak stabil
Efek luar biasa dengan paralelisme dapat disentuh. Cukup dengan mengambil pengukur kecepatan untuk menerima / mengirim data (misalnya, Tes Kecepatan) dan pembentuk lalu lintas (misalnya, kondisioner tautan jaringan, jika Anda memiliki Mac) Kami membatasi jaringan untuk parameter 1 Mbps untuk diunggah dan diunduh dan mulai meningkatkan kehilangan paket.

Tabel menunjukkan RTT dan kerugian. Dapat dilihat bahwa dalam kasus kehilangan 0%, jaringan digunakan 100%.
Dengan iterasi berikutnya, kami meningkatkan packet loss sebesar 5%, dan kami melihat bahwa jaringan hanya digunakan oleh 74%. Tampaknya baik-baik saja - dengan kehilangan paket 5%, 26% dari jaringan hilang. Tetapi jika Anda juga meningkatkan ping, maka
kurang dari setengah saluran akan tetap.
Jika saluran dengan RTT tinggi dan kehilangan paket besar, maka satu koneksi TCP tidak sepenuhnya memanfaatkan jaringan.
Trik lebih lanjut menunjukkan bahwa jika Anda mulai menggunakan koneksi TCP paralel (Anda bisa menjalankan beberapa Tes Kecepatan secara bersamaan), Anda dapat melihat pertumbuhan sebaliknya dari pemanfaatan saluran.
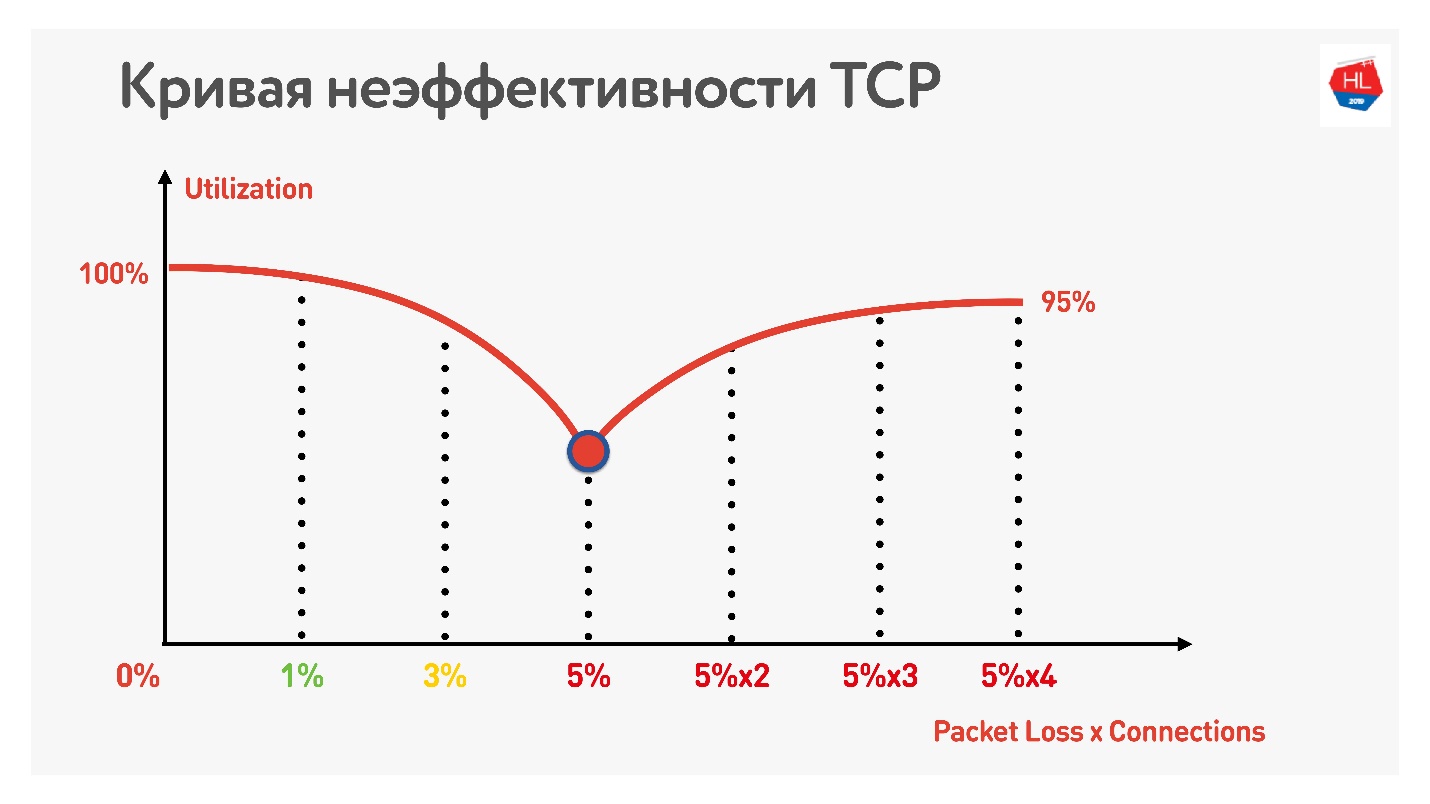
Dengan peningkatan jumlah koneksi TCP paralel, pemanfaatan jaringan menjadi hampir sama dengan throughput, dikurangi persentase kerugian.
Jadi, ternyata:
- Jaringan seluler nirkabel telah menang dan tidak stabil.
- TCP tidak sepenuhnya memanfaatkan saluran di jaringan yang tidak stabil.
- Konsumsi konten tergantung pada kecepatan Internet: semakin tinggi kecepatan Internet, semakin banyak pengguna menonton, dan kami sangat mencintai pengguna kami dan ingin mereka menonton lebih banyak.
Jelas, Anda perlu pindah ke suatu tempat dan mempertimbangkan alternatif untuk TCP.
TCP vs bukan TCP
Bagaimana membandingkan yang hangat? Ada dua opsi.
Opsi pertama - pada level IP ada TCP dan UDP, kita dapat membeli beberapa protokol lain dari atas. Jelas, jika Anda memulai protokol Anda sendiri secara paralel dengan TCP dan UDP, maka Firewall, Brandmauer, router dan seluruh dunia yang terlibat dalam pengiriman paket tidak akan mengetahuinya. Akibatnya, Anda harus menunggu selama bertahun-tahun ketika semua peralatan diperbarui dan mulai bekerja dengan protokol baru.
Opsi kedua adalah membuat protokol pengiriman data Anda sendiri yang andal di atas UDP yang tidak bisa diandalkan. Tentunya, Anda bisa menunggu lama sampai Linux, Android dan iOS menambahkan protokol baru ke kernel Anda, jadi Anda perlu memotong protokol menjadi User Space.
Solusi ini tampaknya menarik, kita akan menyebutnya protokol UDP buatan sendiri. Untuk mulai mengembangkannya, Anda tidak perlu sesuatu yang istimewa: cukup buka soket UDP dan kirim datanya.
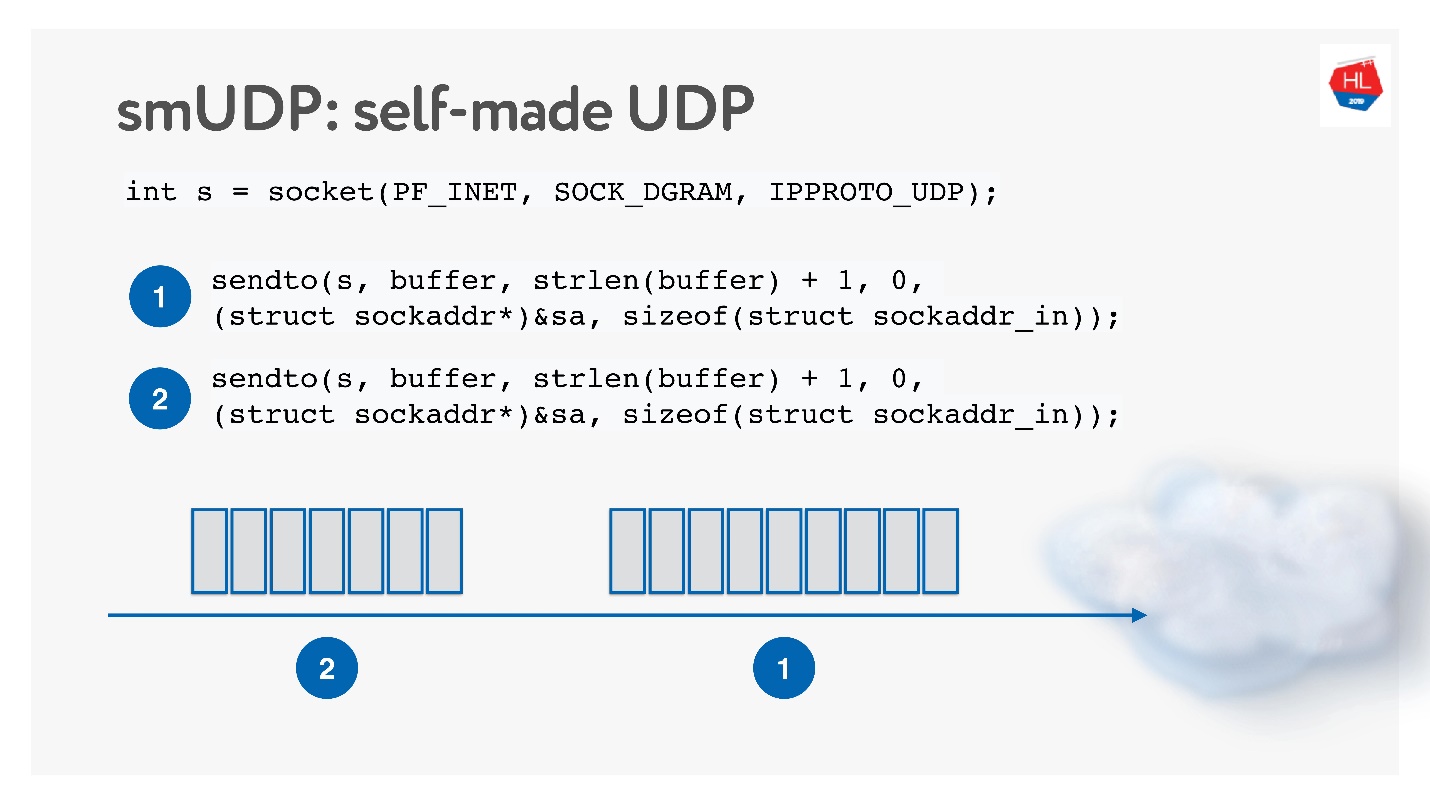
Kami akan mengembangkannya, sambil mempelajari cara kerja jaringan.
TCP vs UDP buatan sendiri
Nah, dan apa yang harus dibandingkan?
Jaringan berbeda:
- Dengan kemacetan, ketika ada banyak paket dan beberapa dari mereka jatuh karena kemacetan saluran atau peralatan.
- Kecepatan tinggi dengan pulang pergi besar (misalnya, ketika server relatif jauh).
- Aneh - ketika sepertinya tidak ada yang terjadi pada jaringan, tetapi paket-paket masih menghilang hanya karena titik akses Wi-Fi ada di belakang dinding.
Anda selalu dapat menyentuh sendiri profil jaringan: pilih satu atau beberapa profil lain di ponsel Anda dan jalankan Tes Kecepatan.

Selain profil jaringan, Anda juga perlu menentukan profil konsumsi lalu lintas. Inilah yang kami gunakan:
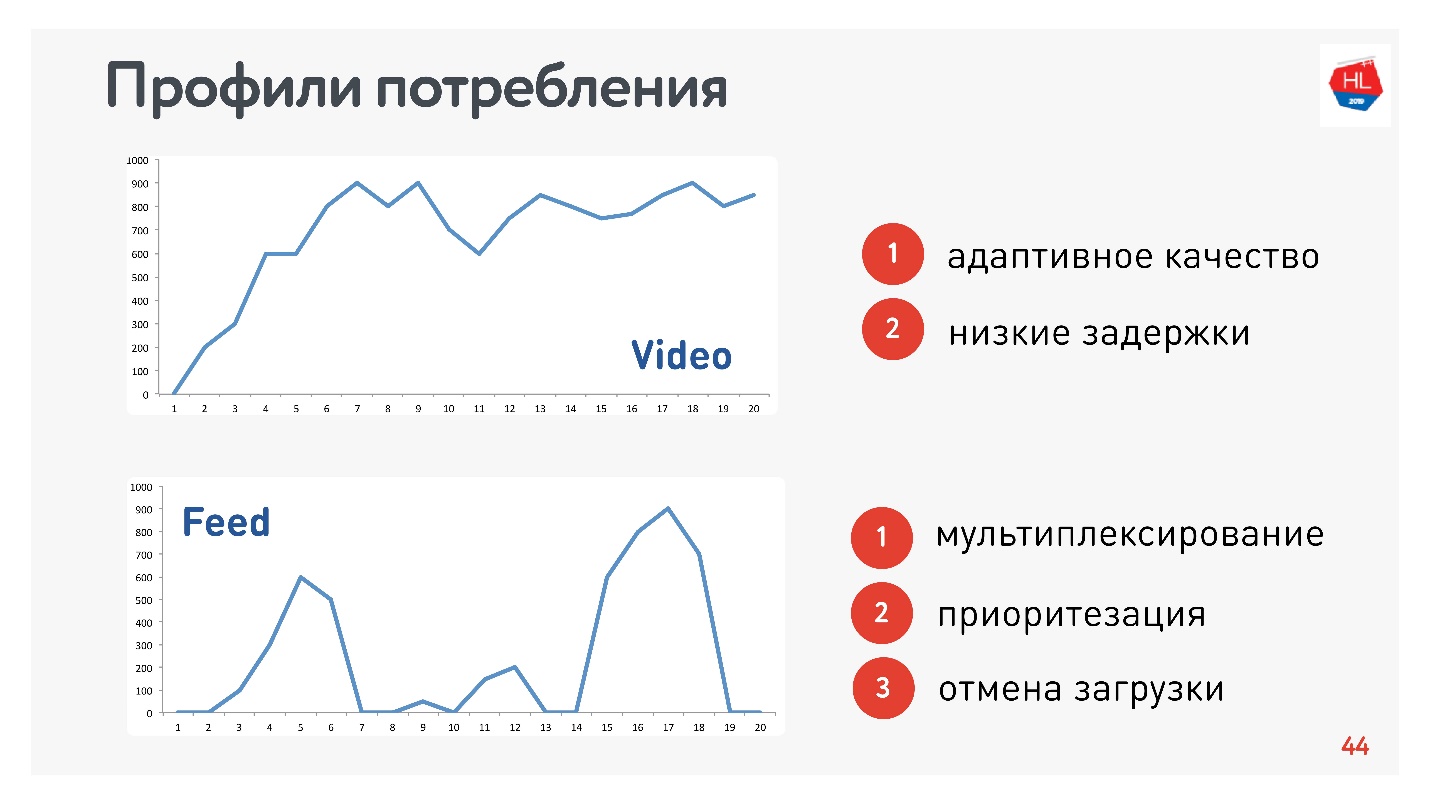
Karena saya bertanggung jawab atas Video dan Stream, profilnya sesuai:
- Video Profil, saat Anda menghubungkan dan mengalirkan konten ini atau itu. Kecepatan koneksi meningkat, seperti pada grafik atas. Persyaratan untuk protokol ini: latensi rendah dan adaptasi bitrate.
- Opsi tampilan tape: pemuatan data impuls, permintaan latar belakang, waktu henti. Persyaratan untuk protokol ini: data yang diterima multipleks dan diprioritaskan, prioritas konten pengguna lebih tinggi dari proses latar belakang, ada pembatalan pengunduhan.
Tentu saja, Anda perlu membandingkan protokol pada HTTP paling populer.
HTTP 1.1 dan HTTP 2.0
Tumpukan standar 2000-an tampak seperti HTTP 1.1 di atas SSL. Tumpukan modern adalah HTTP 2.0, TLS 1.3, dan semuanya ada di atas TCP.
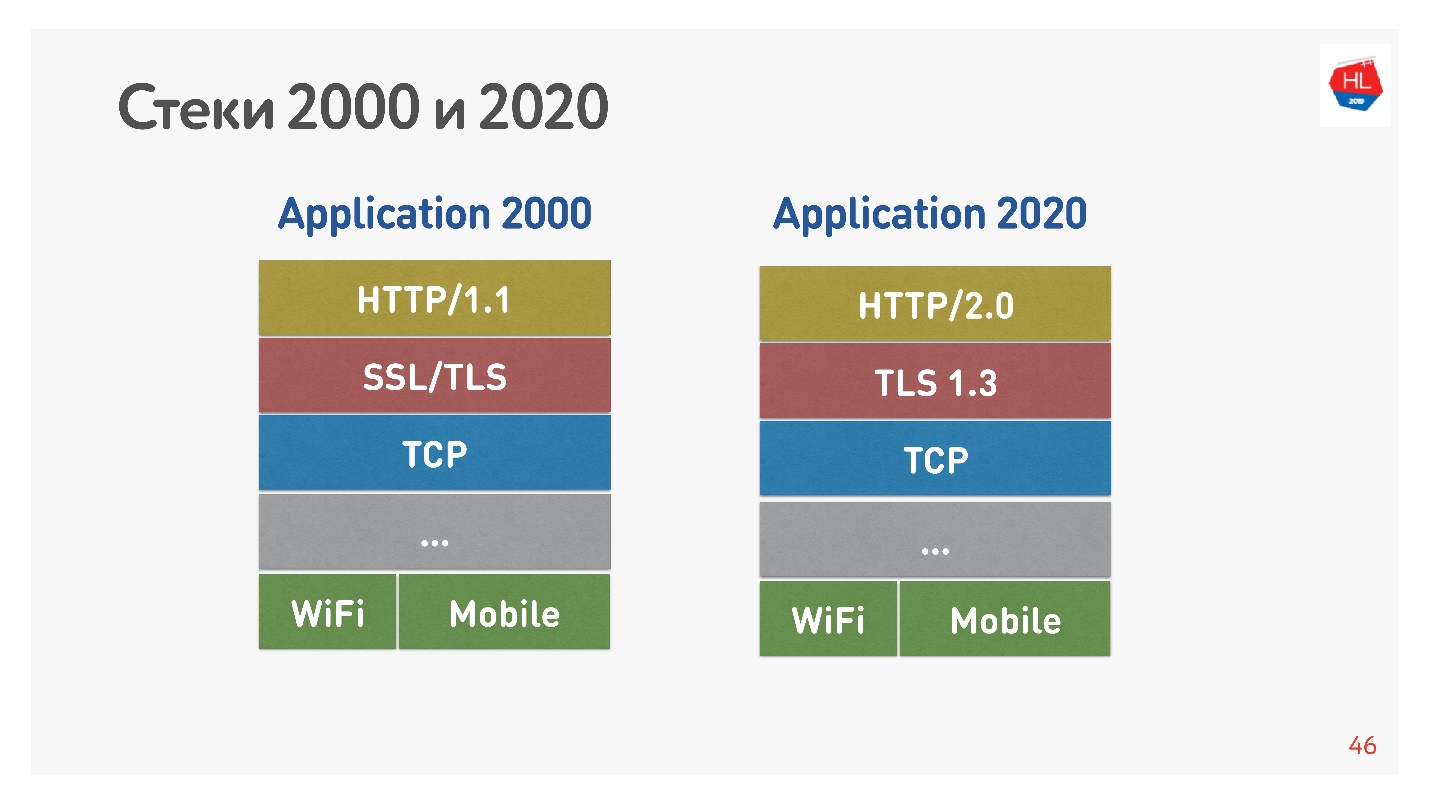
Perbedaan utama adalah bahwa HTTP 1.1 menggunakan kumpulan koneksi terbatas di browser ke satu domain, sehingga mereka membuat domain terpisah untuk gambar, untuk data, dan sebagainya. HTTP 2.0 menawarkan satu koneksi multipleks tempat semua data ini dikirimkan.
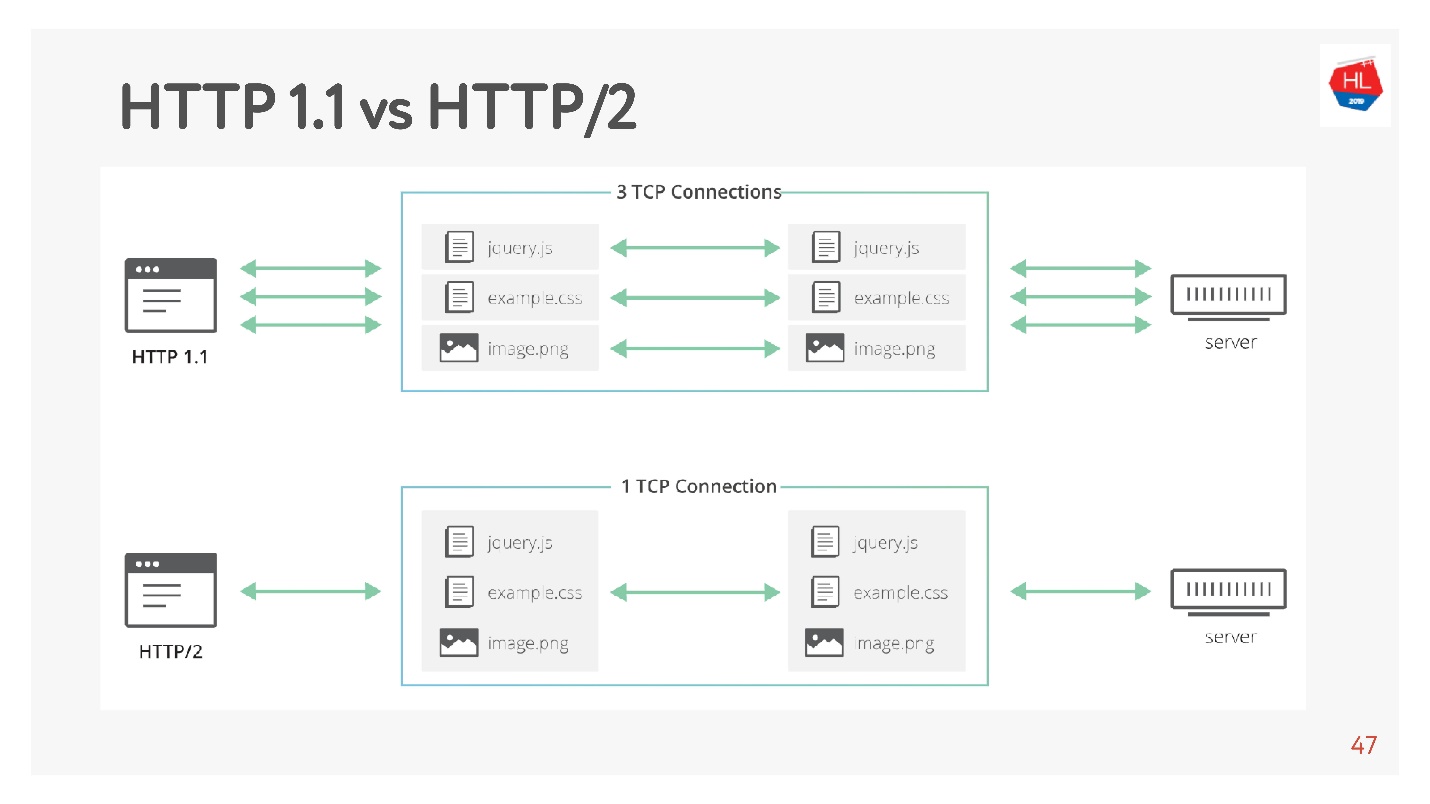
HTTP 1.1 berfungsi seperti ini: membuat permintaan, mendapatkan data, membuat permintaan, mendapatkan data.
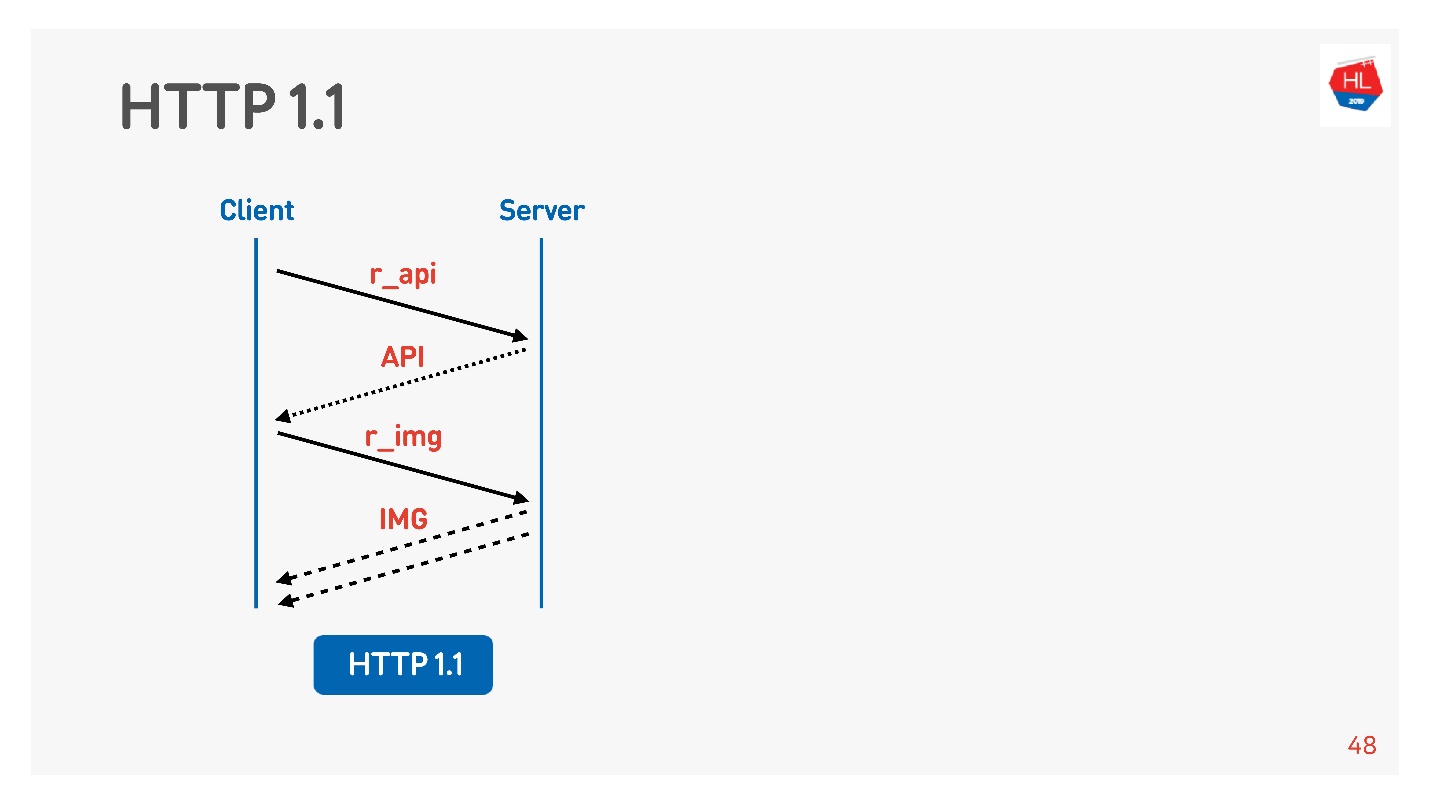
Biasanya browser atau aplikasi seluler adalah bullet, yaitu koneksi untuk menerima gambar, data dengan API, dan Anda secara bersamaan menjalankan permintaan untuk gambar, untuk API, untuk video, dan sebagainya.
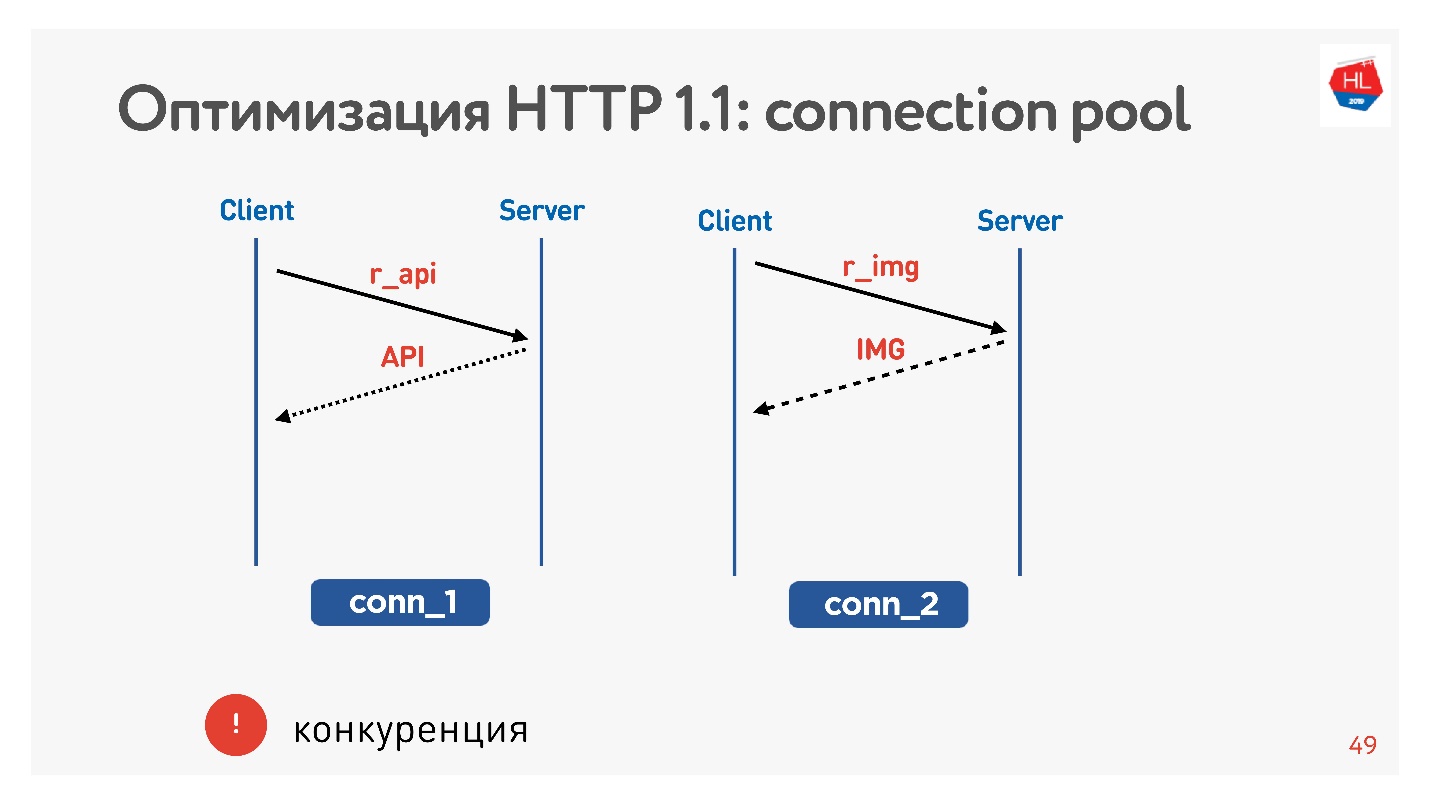
Masalah utamanya adalah kompetisi. Anda tidak memiliki kendali atas permintaan yang diajukan. Anda memahami bahwa pengguna tidak lagi membutuhkan gambar yang dibaliknya, tetapi tidak dapat melakukan apa pun.
Dengan HTTP 1.1, Anda masih mendapatkan apa yang Anda minta, sulit untuk membatalkan unduhan.
Satu-satunya soket stopkontak adalah untuk menutup koneksi. Maka kita akan melihat mengapa ini buruk.
Perbedaan dalam HTTP 2.0
HTTP 2.0 memecahkan masalah ini:
- biner, kompresi tajuk;
- multiplexing data;
- prioritisasi;
- membatalkan pengunduhan;
- dorongan server
Mari kita pertimbangkan poin yang lebih penting bagi kita.
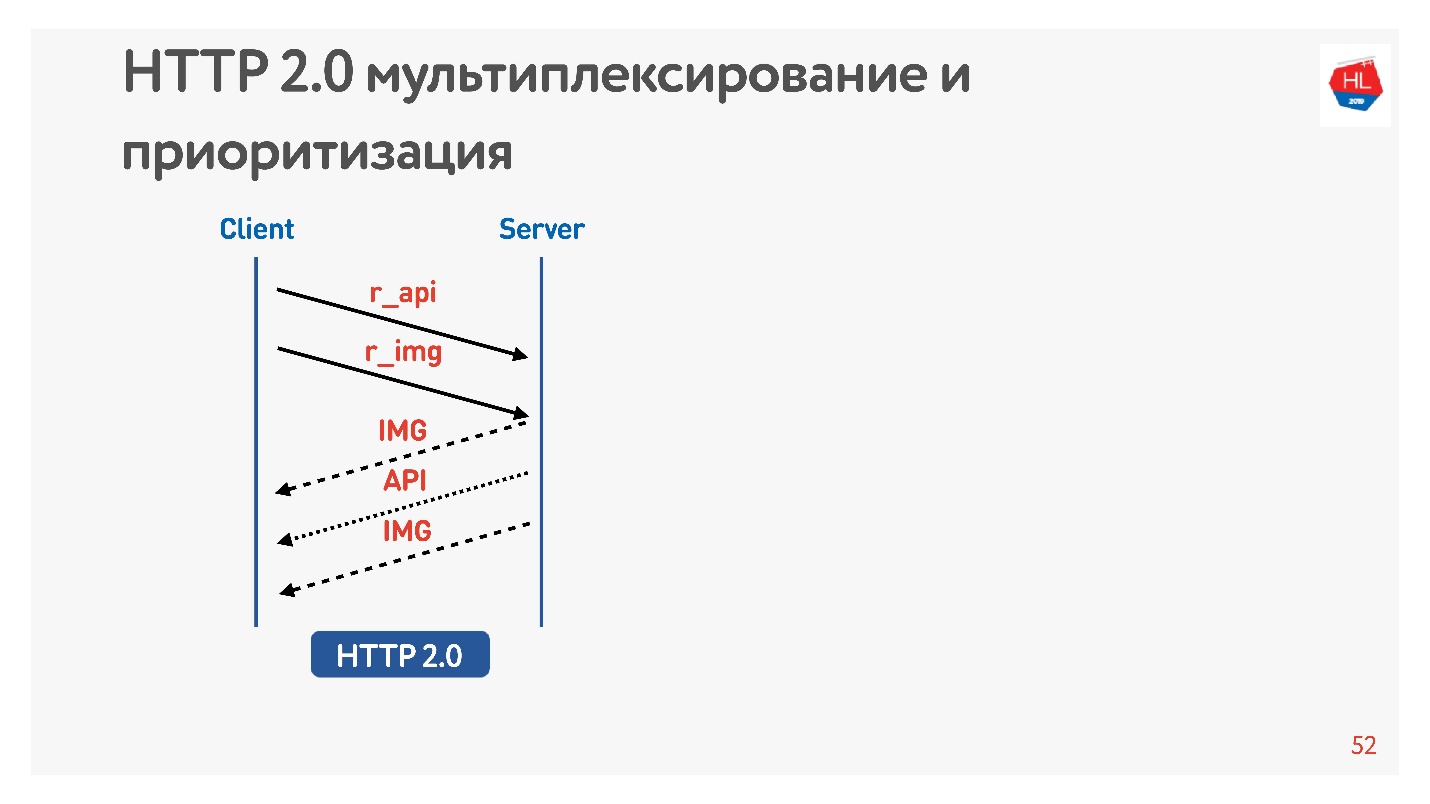
Minta gambar dan API. Gambar segera diberikan, API disiapkan setelah beberapa saat. API diberikan - gambar diberikan sampai akhir. Semua ini terjadi secara transparan.
Konten prioritas tinggi diunduh lebih awal.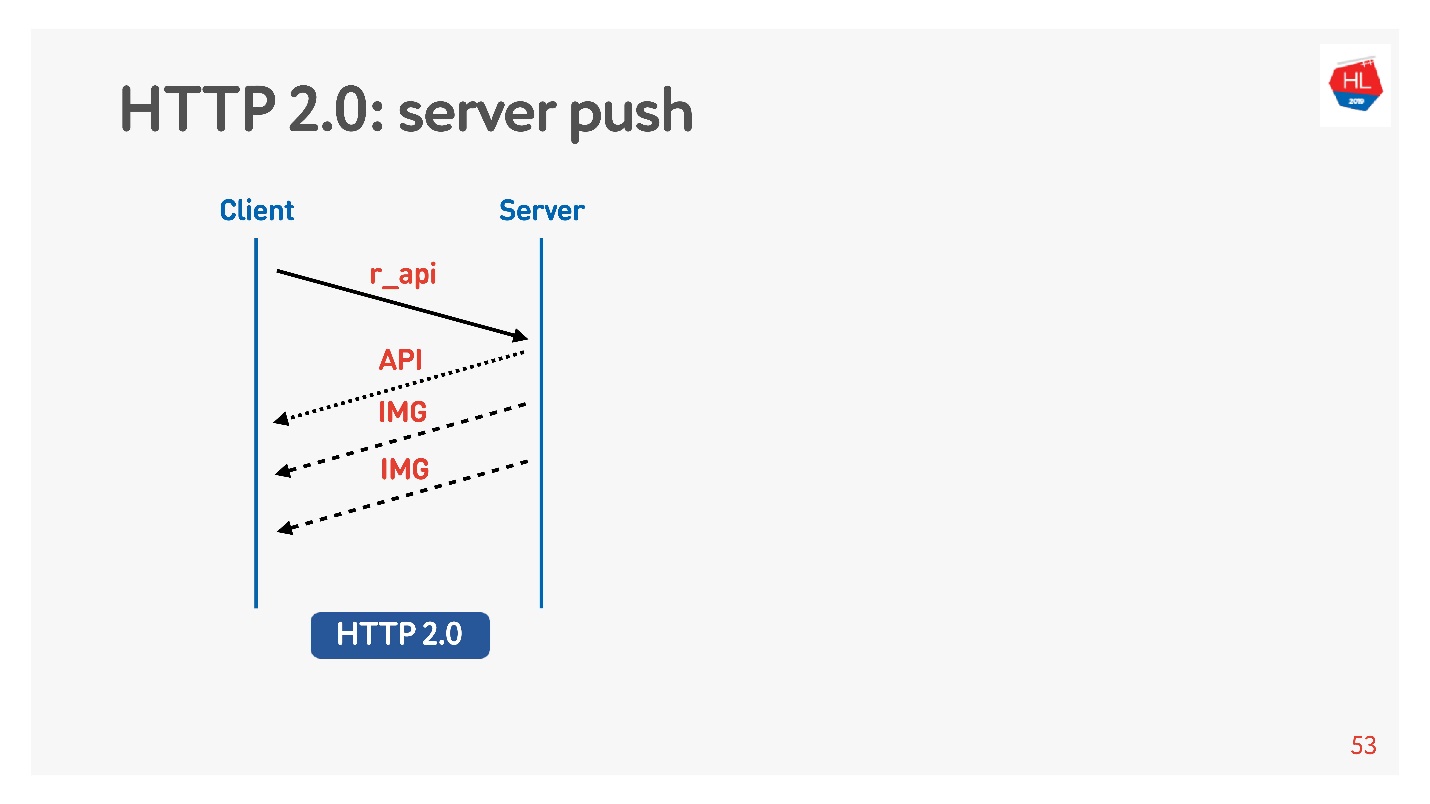 Server push
Server push adalah hal seperti itu ketika Anda meminta sesuatu yang spesifik seperti API, tetapi bahkan dalam memuat gambar klien di-cache yang pasti akan diperlukan untuk melihat, misalnya, rekaman.
Ada juga perintah
Reset stream yang dijalankan oleh browser sendiri jika Anda berpindah antar halaman, dll. Untuk klien seluler, dengan bantuannya, Anda dapat menolak menerima data tanpa kehilangan koneksi.
Dengan demikian, kami akan membandingkan TCP pada yang berbeda:
- Profil jaringan: Wi-Fi, 3G, LTE.
- Profil konsumsi: streaming (video), multiplexing dan prioritisasi dengan membatalkan unduhan (HTTP / 2) untuk menerima konten rekaman.
Model lossless
Mari kita mulai perbandingan dengan jaringan sederhana yang hanya memiliki dua parameter: waktu pulang-pergi dan bandwidth.
RTT adalah ping, waktu penyelesaian paket, penerimaan pengakuan, atau waktu gema respons.
Untuk mengukur
bandwidth -
bandwidth jaringan - kami mengirim paket paket dan menghitung jumlah paket yang dikirimkan pada interval waktu tertentu.
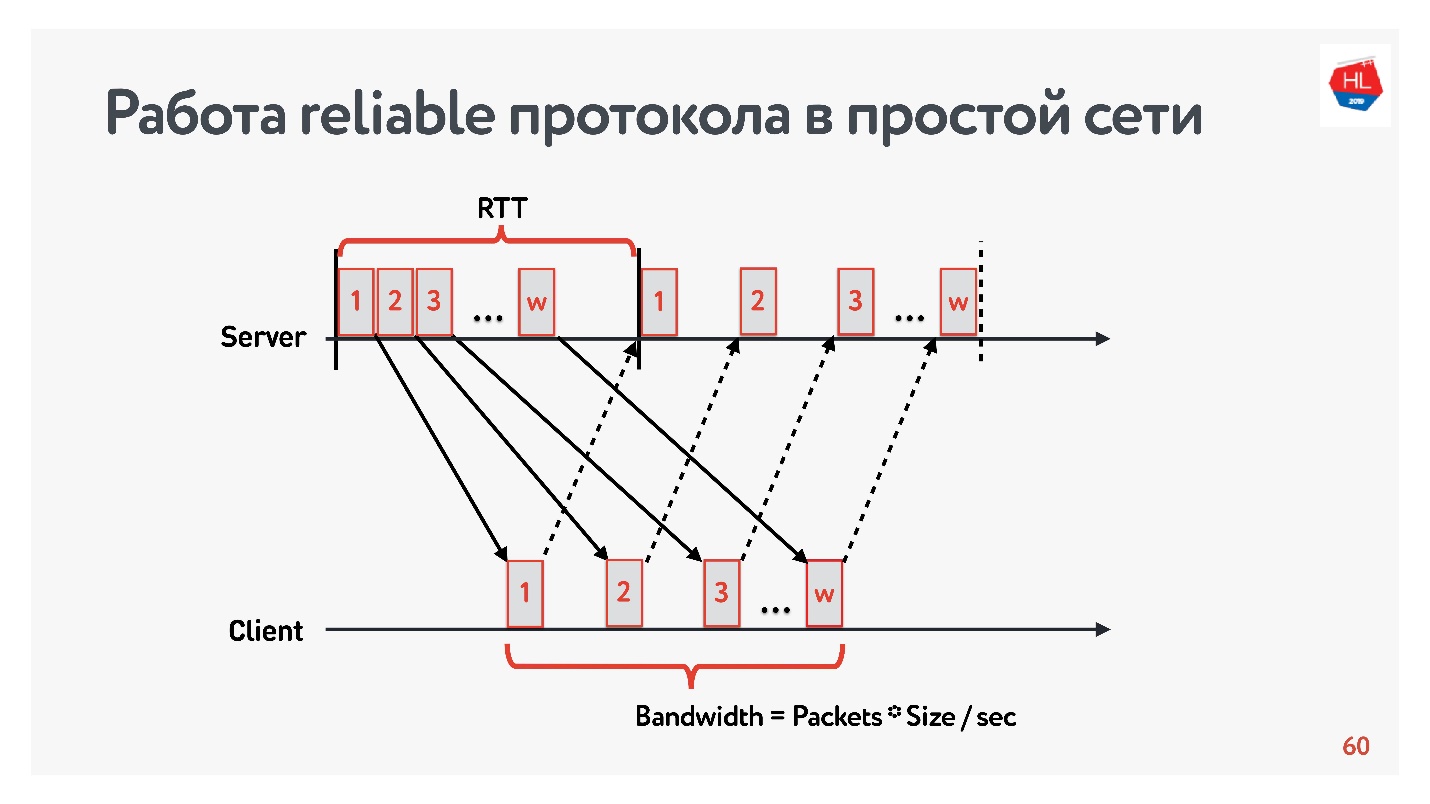
Karena kami bekerja dengan protokol yang andal, tentu saja, ada pengakuan - kami mengirim paket dan menerima konfirmasi tanda terima.
Masalah internet lambat
Pada awal pengembangan layanan video kami pada 2013, teman saya pergi ke California dan memutuskan untuk menonton seri baru seri favoritnya di Odnoklassniki. Dia memiliki RTT 250 ms, Wi-Fi sempurna 400 Mbps di kampus Google, dia ingin melihat seri baru dalam FullHD.
Apakah Anda pikir dia bisa menonton video? Jawabannya tergantung pada konfigurasi buffer send / recv di server kami.
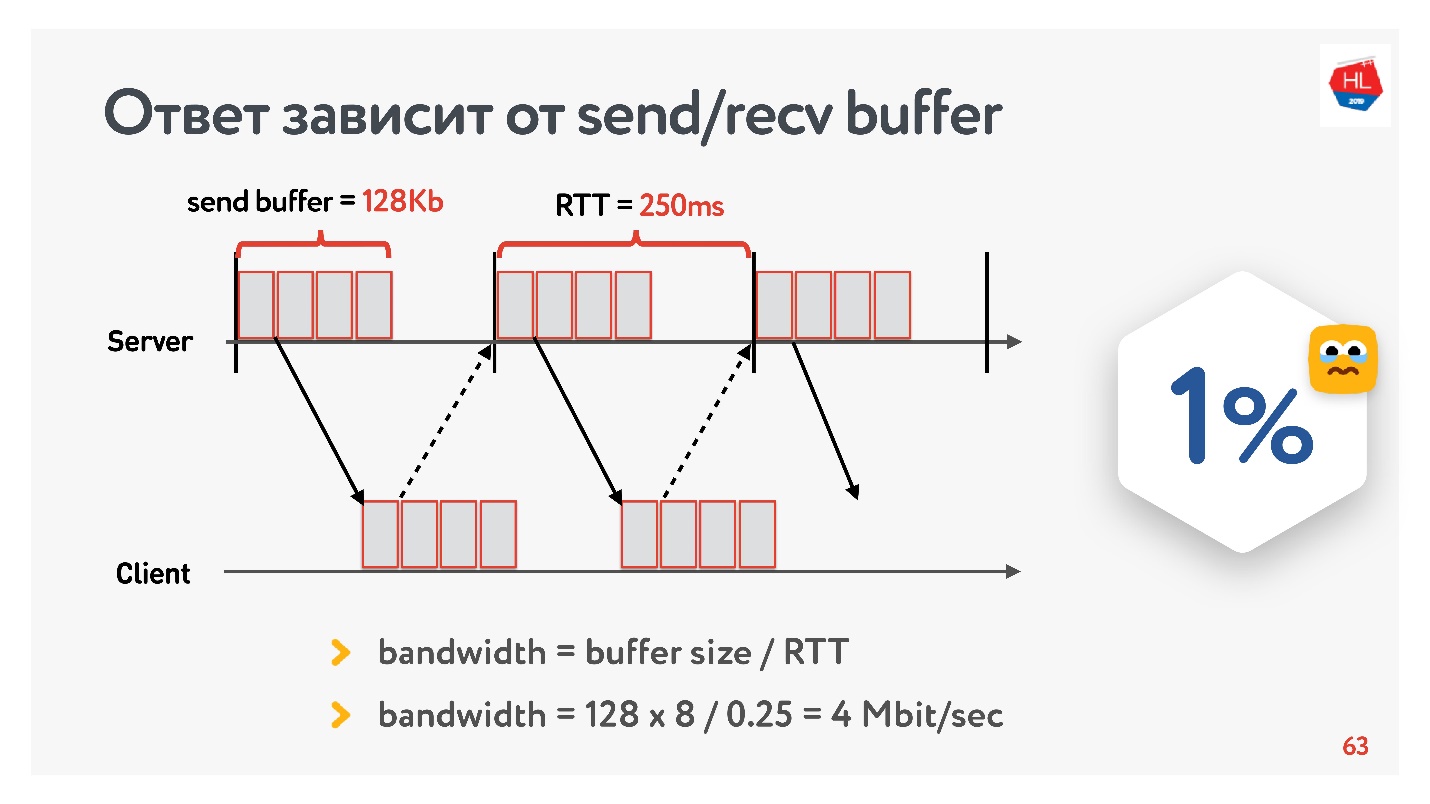
Karena kami memiliki protokol dengan pengakuan, semua data yang tidak menerima konfirmasi pengiriman disimpan dalam buffer. Jika buffer pengiriman dibatasi hingga 128 Kb, maka 128 Kb ini kurang dari untuk RTT, kami tidak dapat mengirim. Jadi, dari jaringan kami 400 Mbit / s, 4 Mbit / s tetap. Ini tidak cukup untuk menonton video online dalam FullHD.
Lalu saya menarik ukuran buffer dan melihat bagaimana kecepatan output dari satu segmen video benar-benar berubah tergantung pada perubahan ukuran buffer. Segera buat reservasi agar recv buffer disetel secara otomatis, mis. apa yang dikirim server, klien selalu dapat menerima.

Resep TCP yang jelas: jika Anda mengirim data berkecepatan tinggi dalam jarak jauh, Anda perlu meningkatkan buffer pengiriman.
Segalanya tampak baik-baik saja. Anda dapat pergi ke layanan fast.com, yang mengukur kecepatan Internet Anda ke server Netflix. Dari kantor saya mendapat kecepatan 210 Mbps. Dan kemudian melalui pembentuk jaring saya mengatur kondisi tugas dan pergi ke situs ini lagi. Magic - Saya mendapat 4 Mbps dengan tepat.
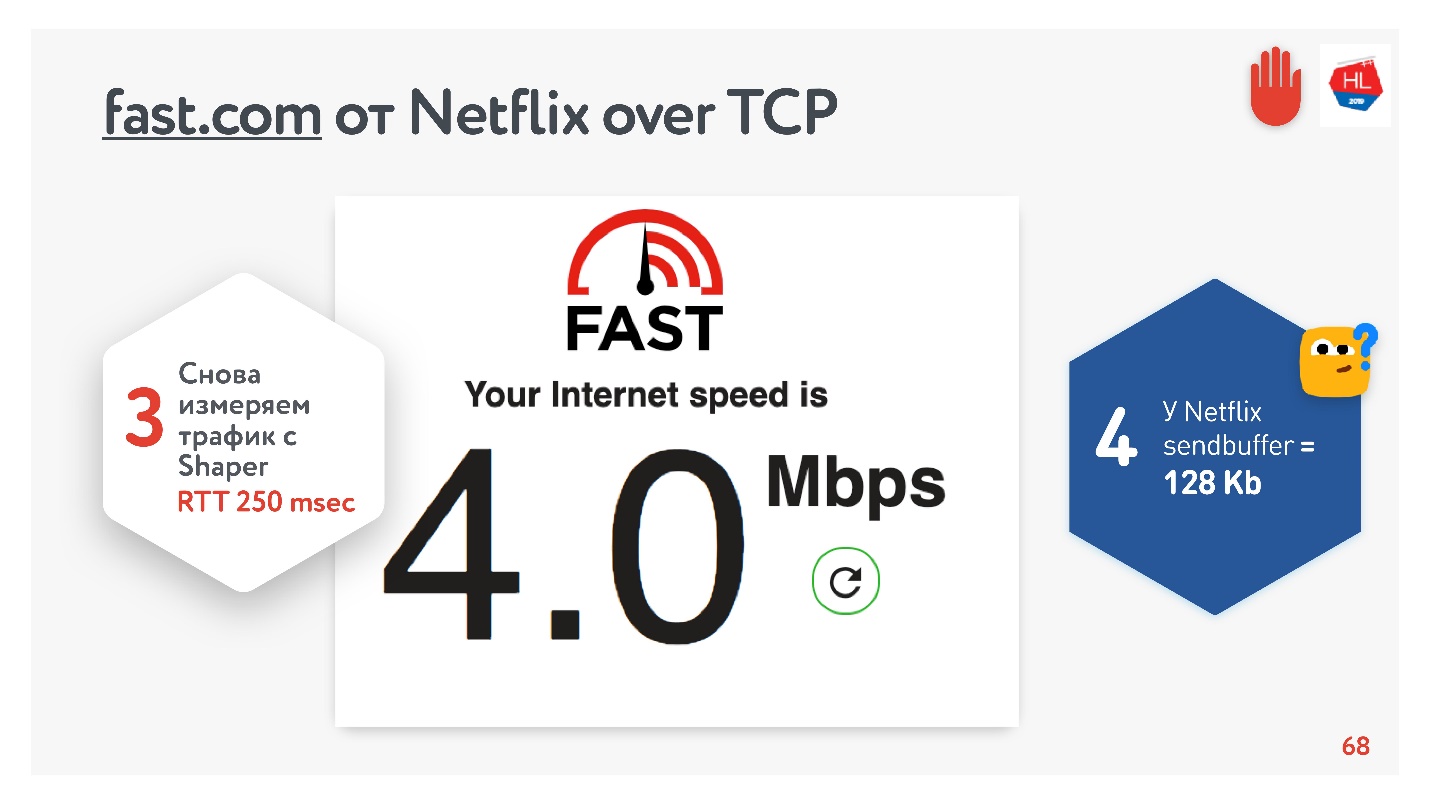
Tidak peduli bagaimana saya memutarnya, Netflix tidak berhasil mendapatkan buffer yang lebih besar dari 128 KB.
Ukuran penyangga
Untuk mengetahui ukuran buffer optimal, Anda perlu memahami paket On-the-fly.
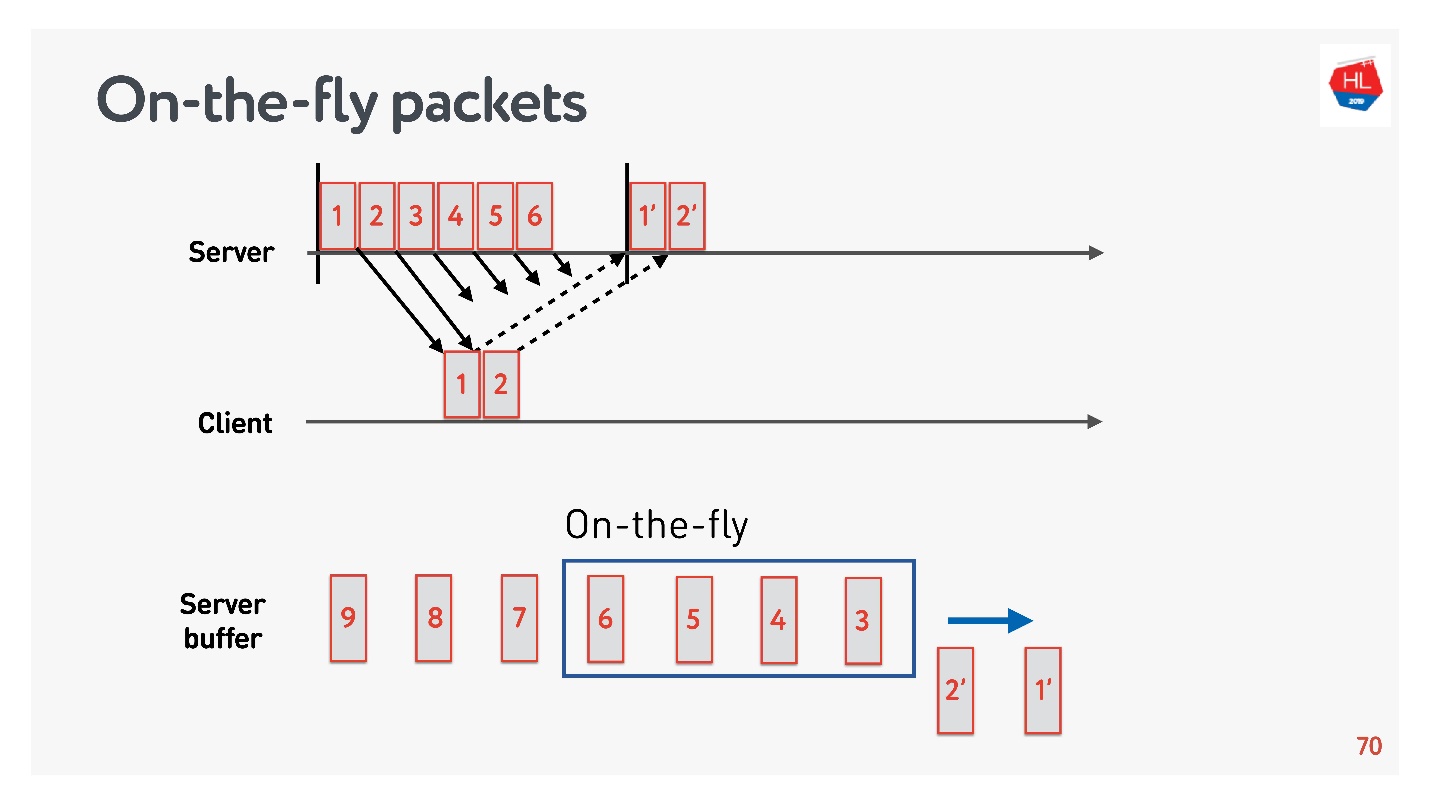
Ada status jaringan:
- paket 1 dan 2 telah dikirim, konfirmasi telah diterima untuk mereka;
- paket 3, 4, 5, 6 dikirim, tetapi hasil pengiriman tidak diketahui (paket on-the-fly);
- paket lain sedang dalam antrian.
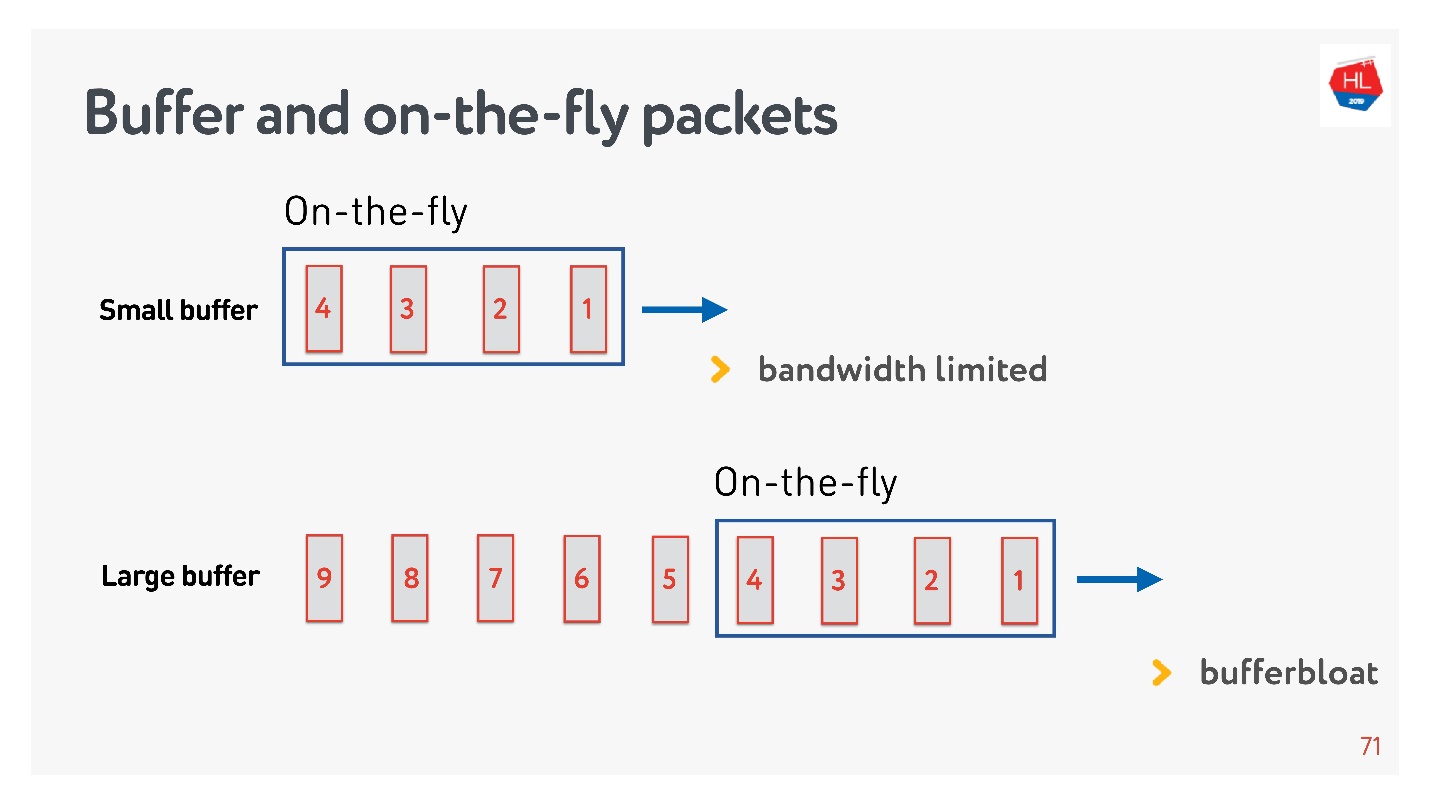
Jika jumlah paket dalam On-the-fly sama dengan ukuran buffer, maka itu tidak cukup besar. Dalam hal ini, jaringan kelaparan, tidak dimanfaatkan sepenuhnya.
Situasi sebaliknya dimungkinkan - buffer terlalu besar. Dalam hal ini, buffer membengkak. Kenapa ini buruk?

Jika kita berbicara tentang multiplexing data dan mengirim beberapa permintaan secara bersamaan, misalnya gambar dalam koneksi dan API yang sama, maka ketika seluruh gambar megabita besar masuk ke buffer, dan kami mencoba memasukkan API prioritas tinggi juga, buffer membengkak. Anda harus menunggu sangat lama ketika gambar hilang.
Solusi sederhana adalah menyesuaikan ukuran buffer secara otomatis. Sekarang tersedia di banyak klien dan bekerja seperti ini.
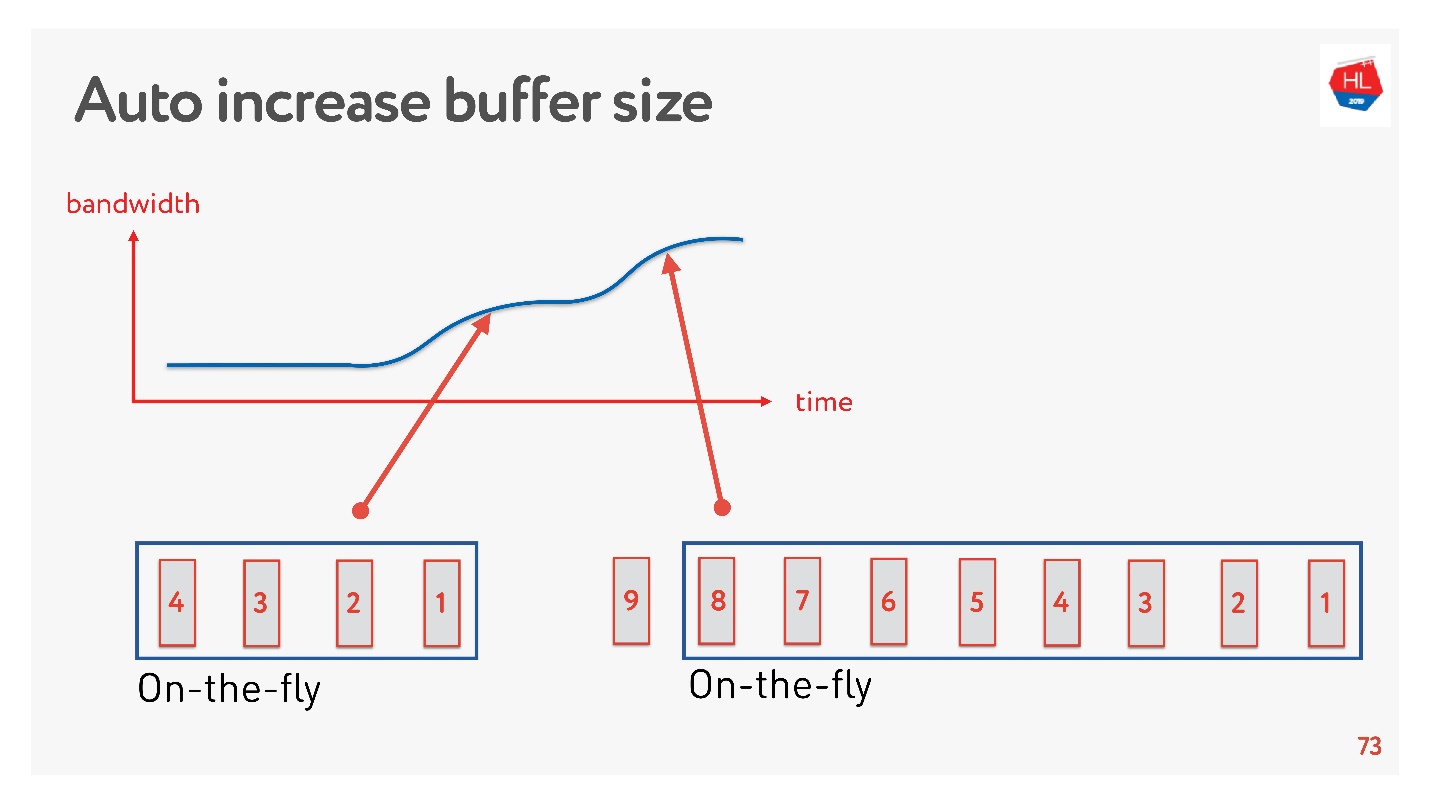
Jika banyak paket dapat dikirim sekarang, buffer meningkat, transfer data semakin cepat, ukuran buffer bertambah, semuanya tampak hebat.
Tapi ada masalah. Jika buffer telah meningkat, itu tidak dapat dikurangi dengan mudah. Ini adalah tugas yang lebih sulit. Jika kecepatan melorot, maka terjadi pembengkakan buffer yang sama. Buffer cukup besar dan penuh, kita harus menunggu sampai semua data dikirim ke klien.
Jika kita menulis protokol UDP kita sendiri, maka semuanya sangat sederhana - kita memiliki akses ke buffer.
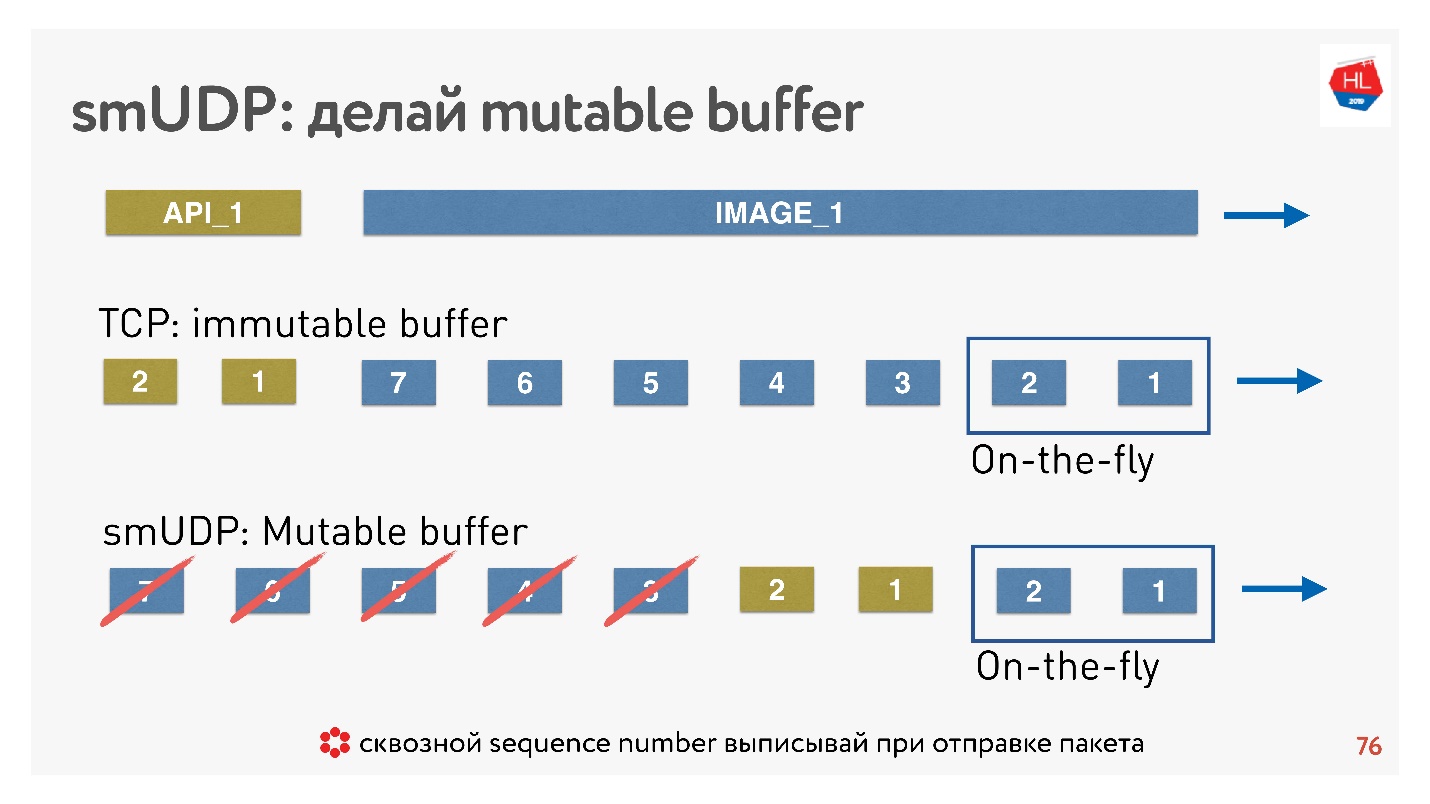
Jika TCP dalam situasi seperti itu hanya menambah data sampai akhir, dan Anda tidak dapat melakukan apa pun, maka dalam protokol buatan sendiri Anda dapat memasukkan data, misalnya, meneruskan, segera setelah paket On-the-fly.
Dan jika pembatalan datang, dan klien mengatakan bahwa gambar ini tidak lagi diperlukan, ia membutuhkan data API, ia menggulir konten lebih lanjut, Anda dapat membuang semua ini dari buffer dan mengirim yang diperlukan.
Bagaimana ini dilakukan? Diketahui bahwa untuk mengembalikan paket, mengatur pengiriman, menerima ucapan terima kasih, Anda memerlukan beberapa sequence_id dari paket. Sequence_id kami ditulis hanya untuk paket on-the-fly, yaitu, kami mengeluarkannya hanya ketika kami mengirim paket. Segala sesuatu yang lain dalam buffer dapat dipindahkan seperti yang kita inginkan hingga paket hilang.
Kesimpulan: buffer TCP harus dikonfigurasi dengan benar, menangkap keseimbangan agar tidak berbatasan dengan jaringan dan tidak mengembang buffer. Untuk protokol UDP Anda sendiri, semuanya sederhana - ini dapat dikontrol.
Model jaringan lossy
Kami pindah ke tingkat yang lebih tinggi, jaringan menjadi sedikit lebih rumit, paket loss muncul di dalamnya. Untuk jaringan seluler, ini adalah situasi yang umum. Beberapa paket yang dikirim tidak mencapai klien. Algoritme pemulihan transmisi ulang standar berfungsi seperti ini:
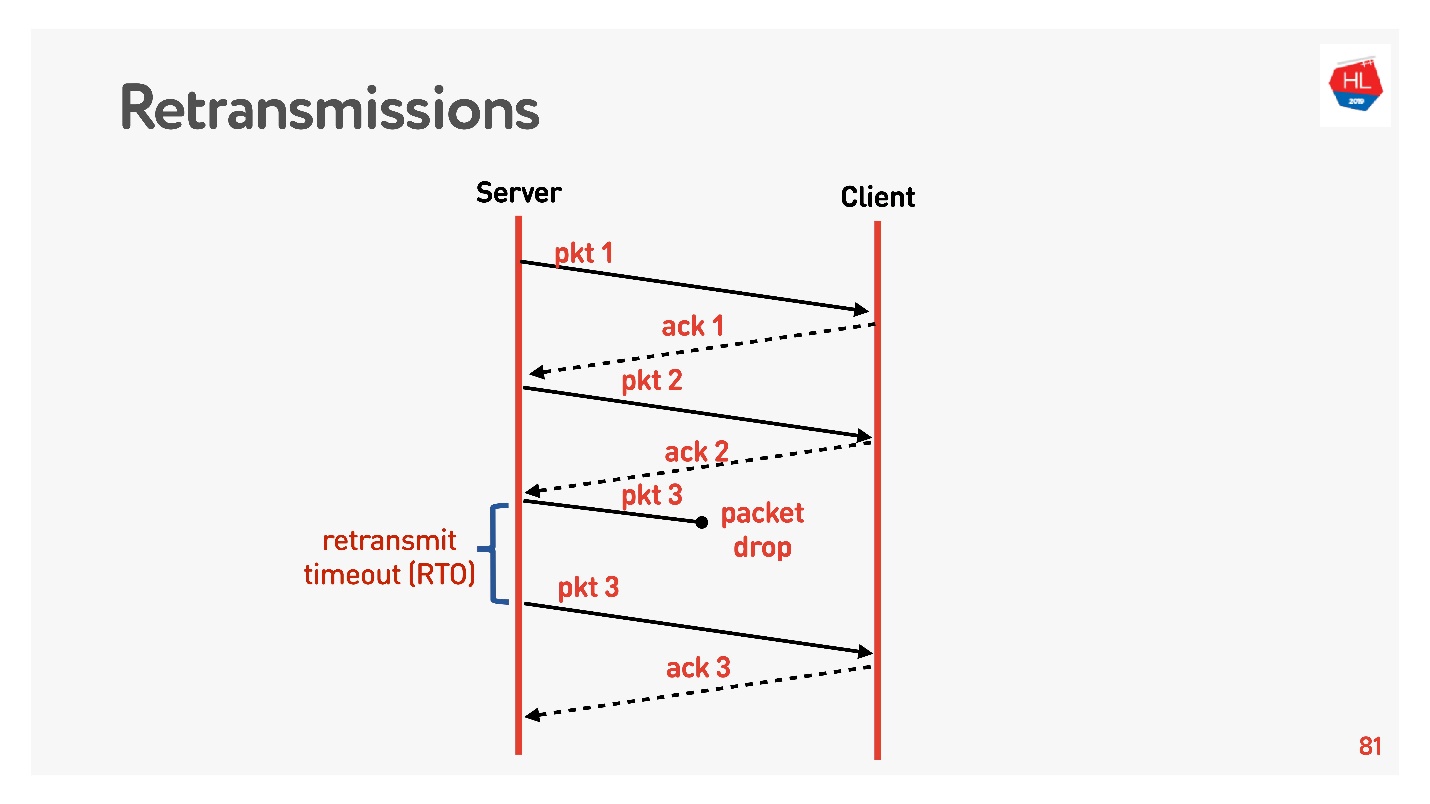
Mengirim paket, untuk setiap paket menerima pengakuan. Retransmit timeout (RTO) RTT , .
TCP, 5% , 50%.
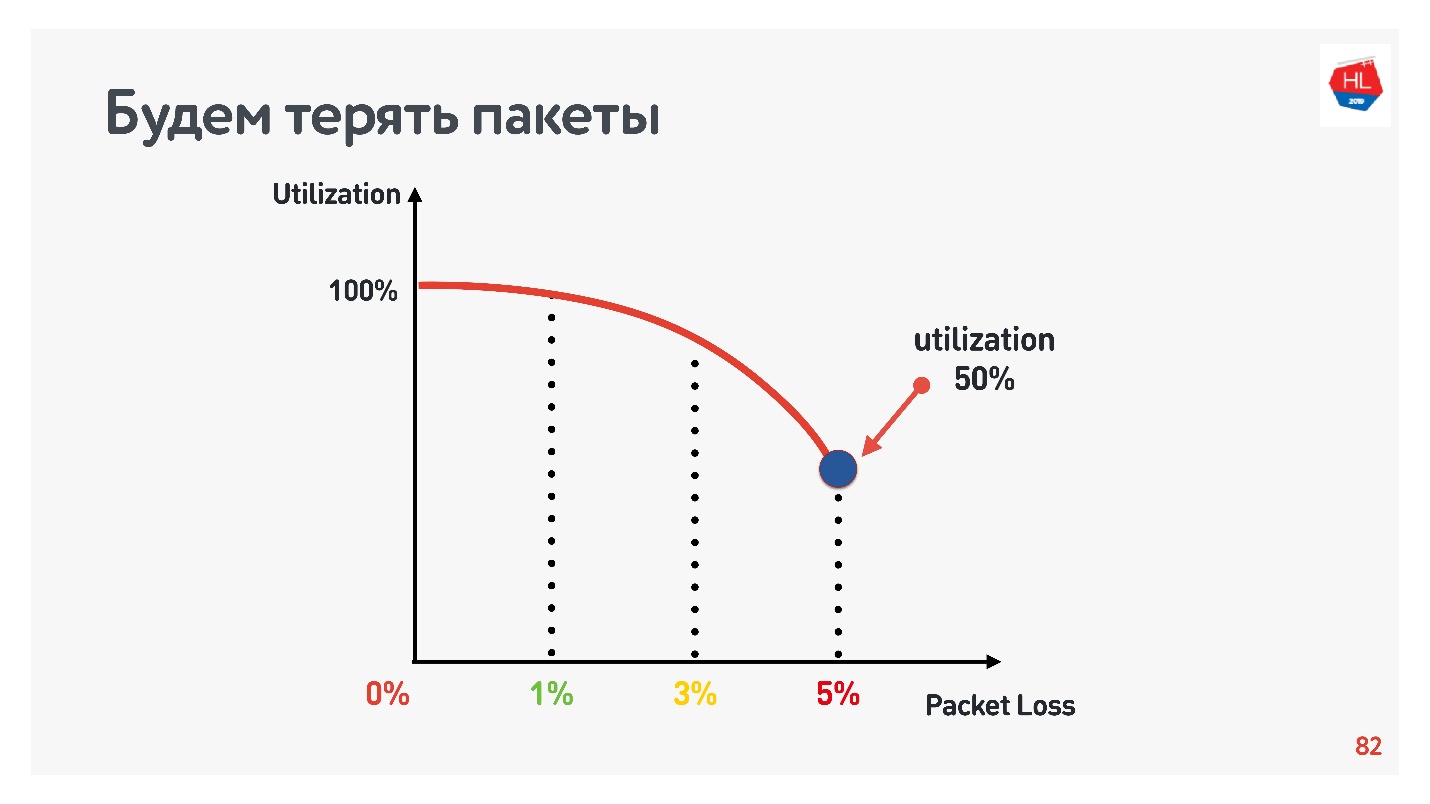
retransmit, , . , , Congestion control.
Congestion control
flow control, .
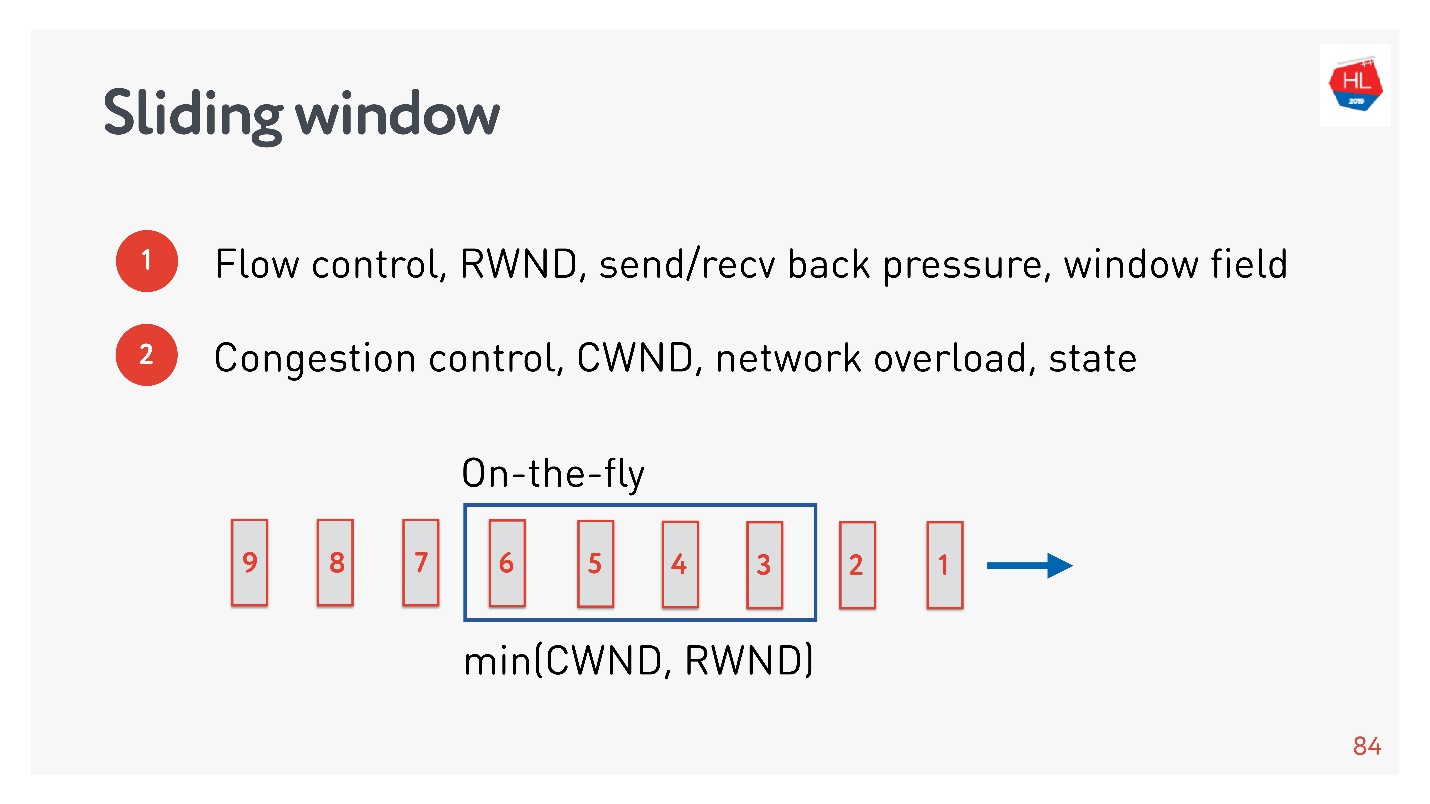
- Flow control — . , , . flow control recv window, . flow control — back pressure , - .
- congestion control . , — .
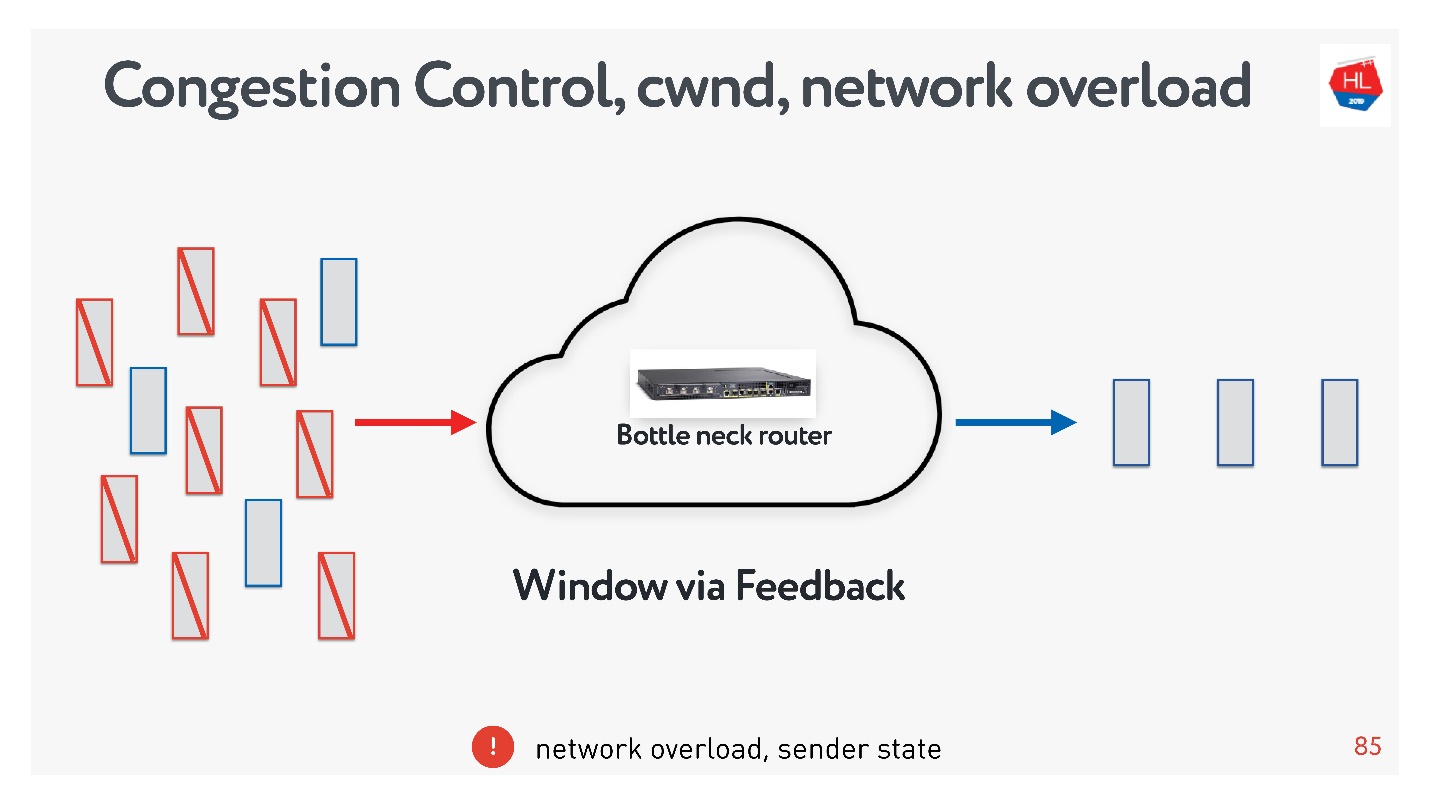
, : , , , . , congestion control.
TCP window.
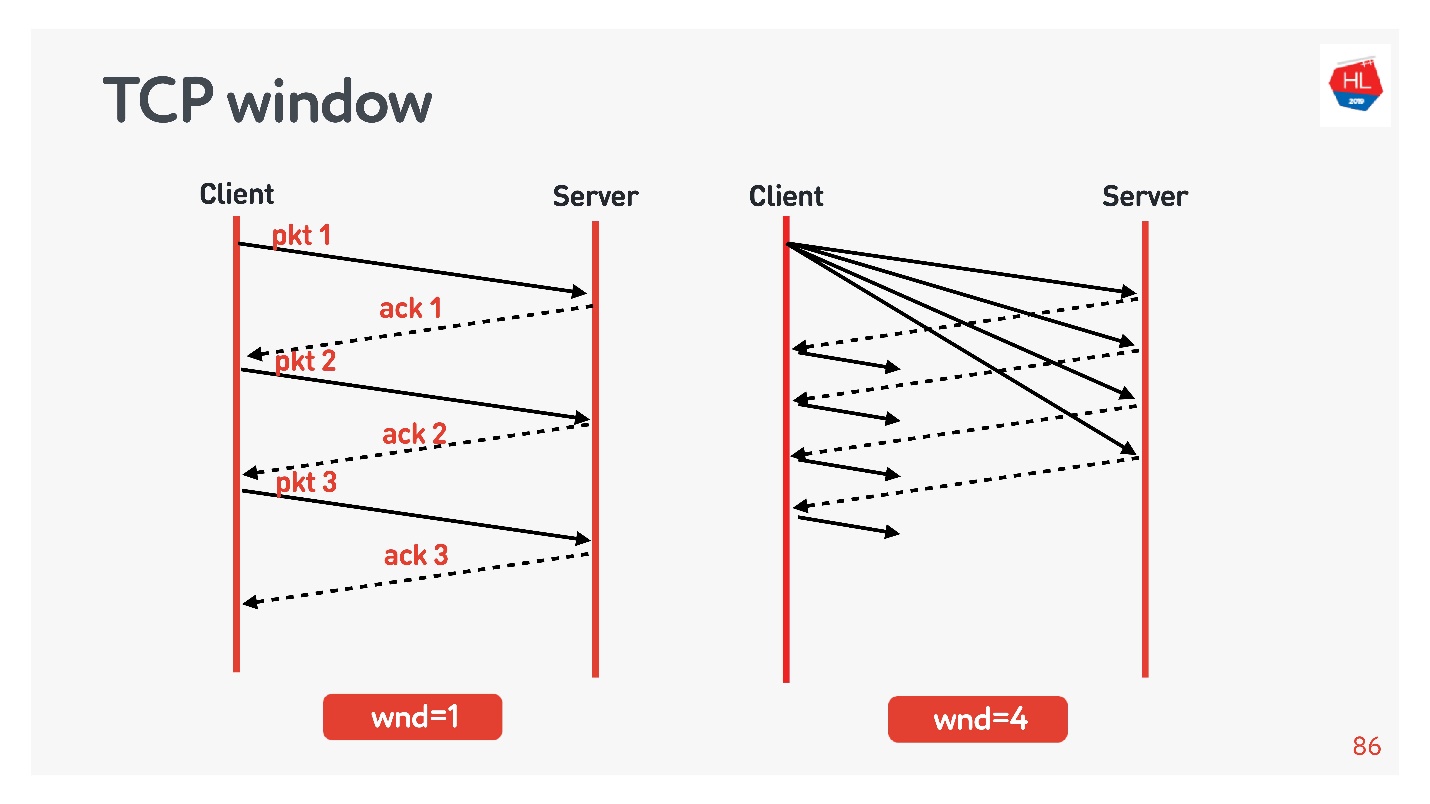
flow control congestion control, .
:
- TCP window = 1, : acknowledgement, ..
- TCP window = 4, , acknowledgement .
, . initial window TCP = 10.
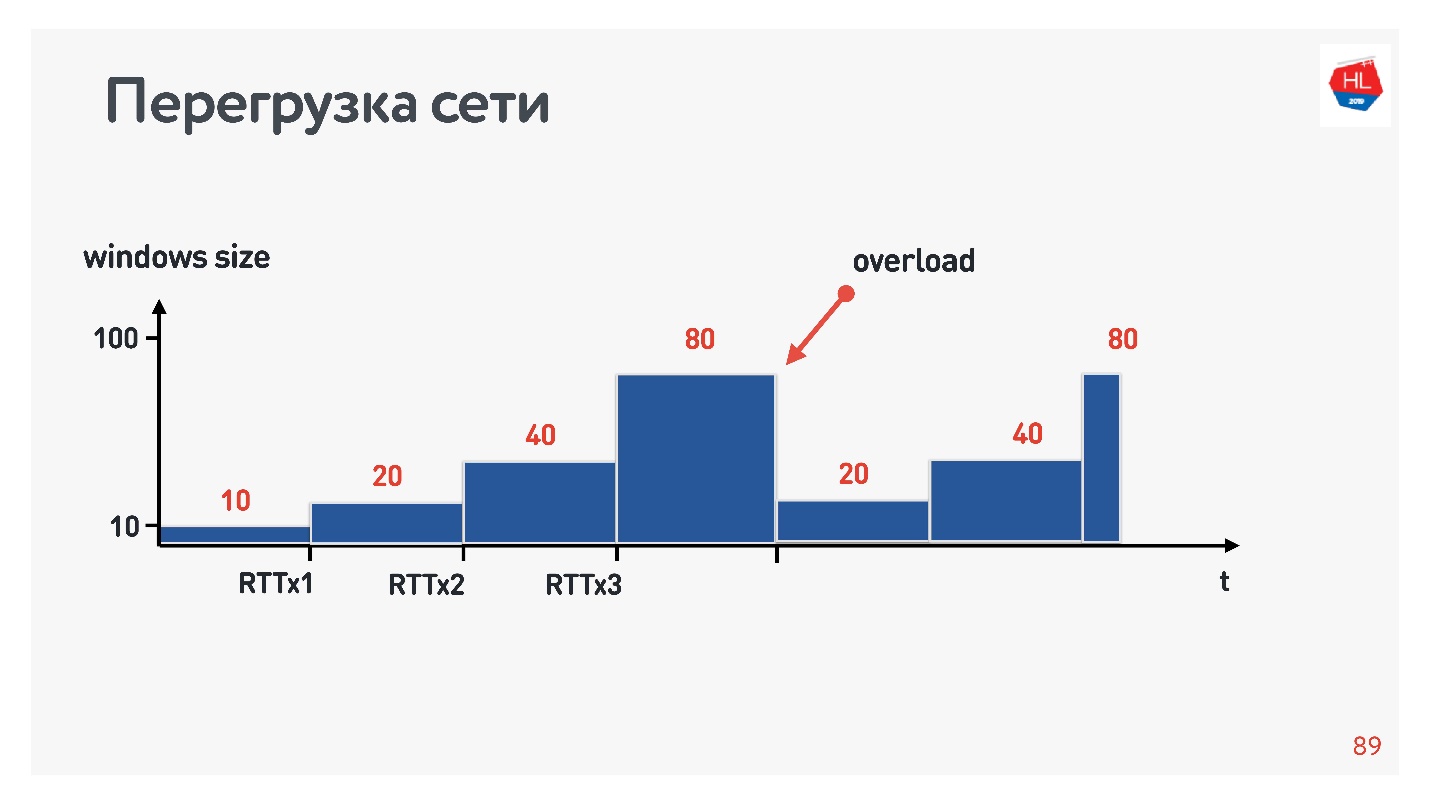
, , .
?
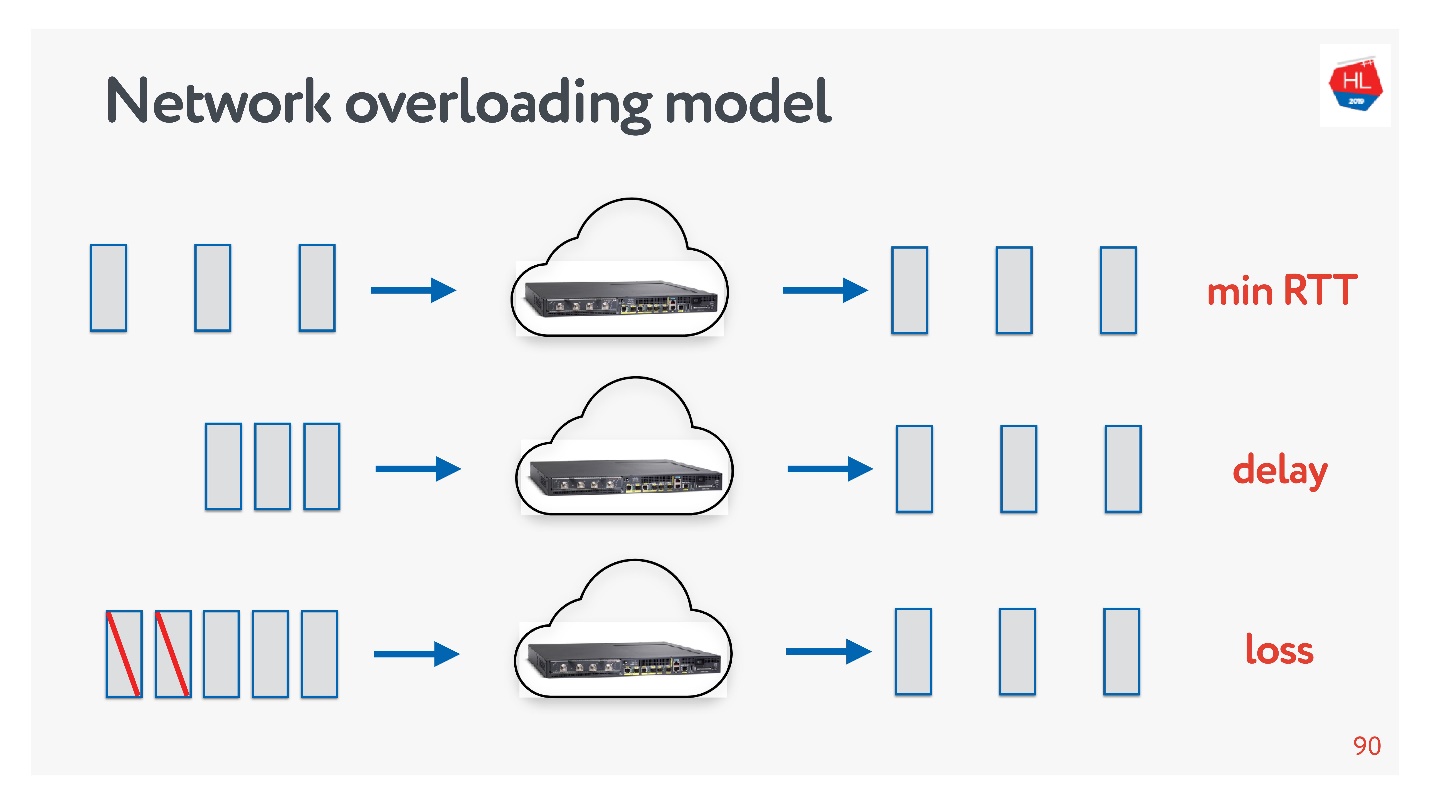
- , . , .
- : , acknowledgements .
- - , acknowledgements ( ).
.
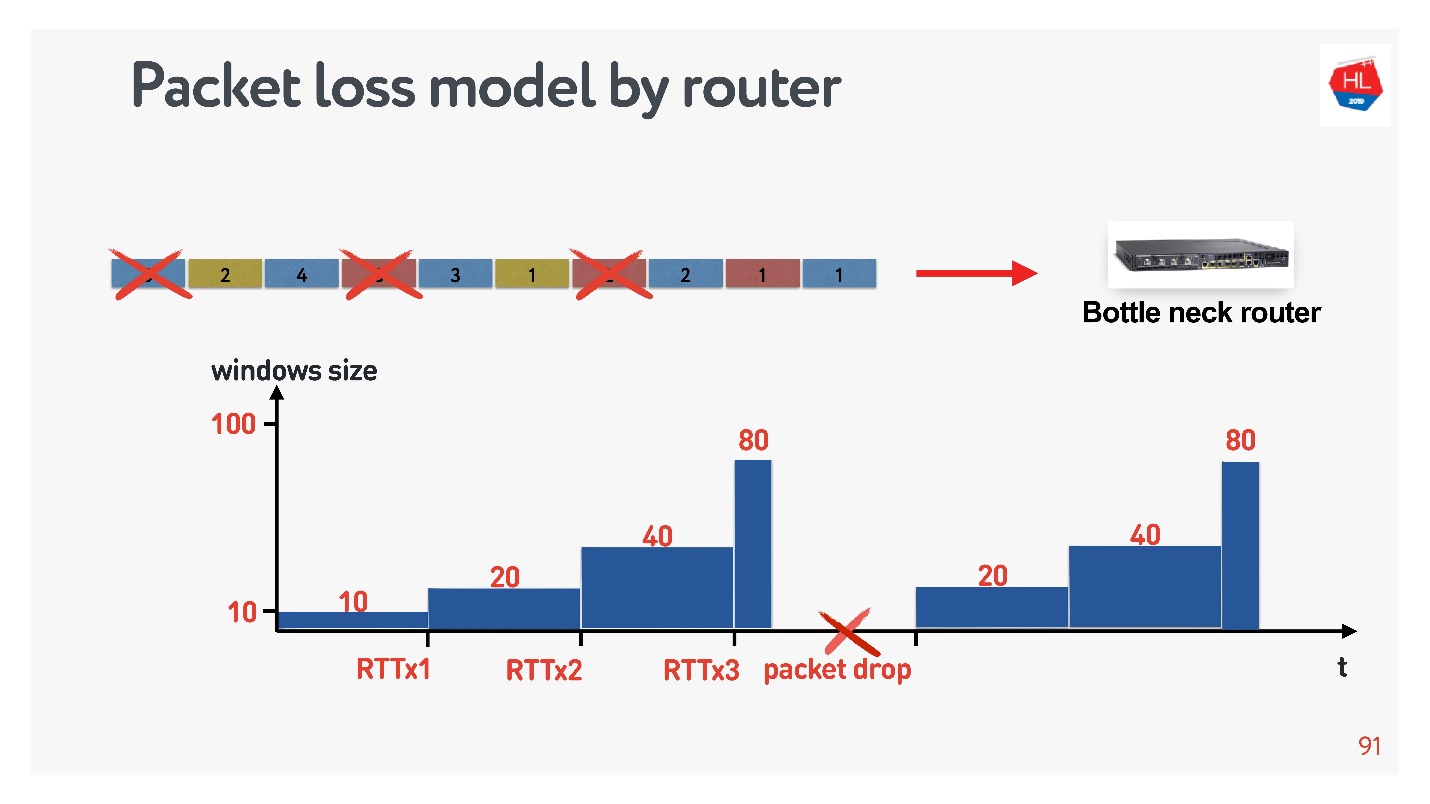
, , . : , .. , . congestion control, TCP window, , .
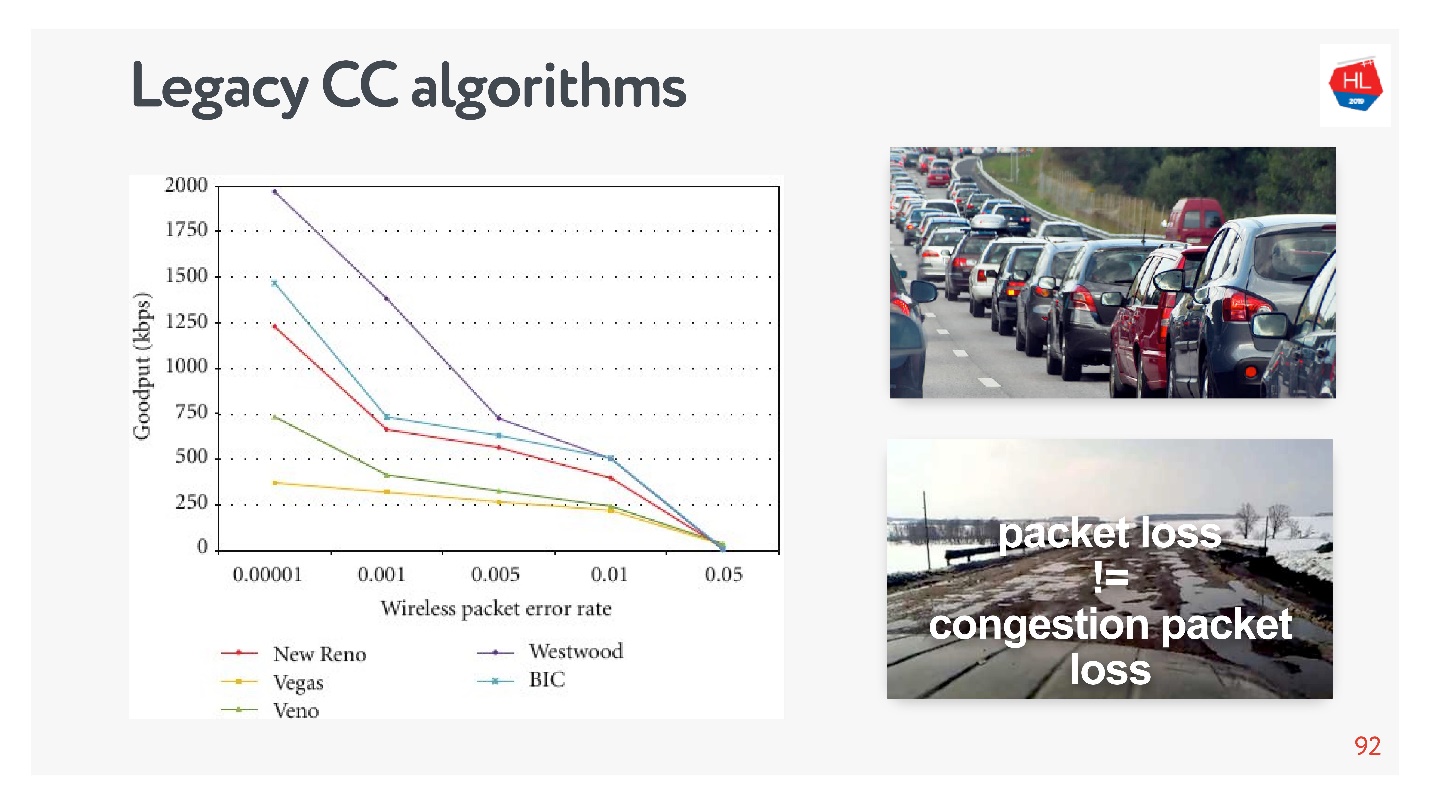
congestion control, , — . packet loss — , . , , — , .
, TCP , , congestion control loss-. congestion control loss delay, , .
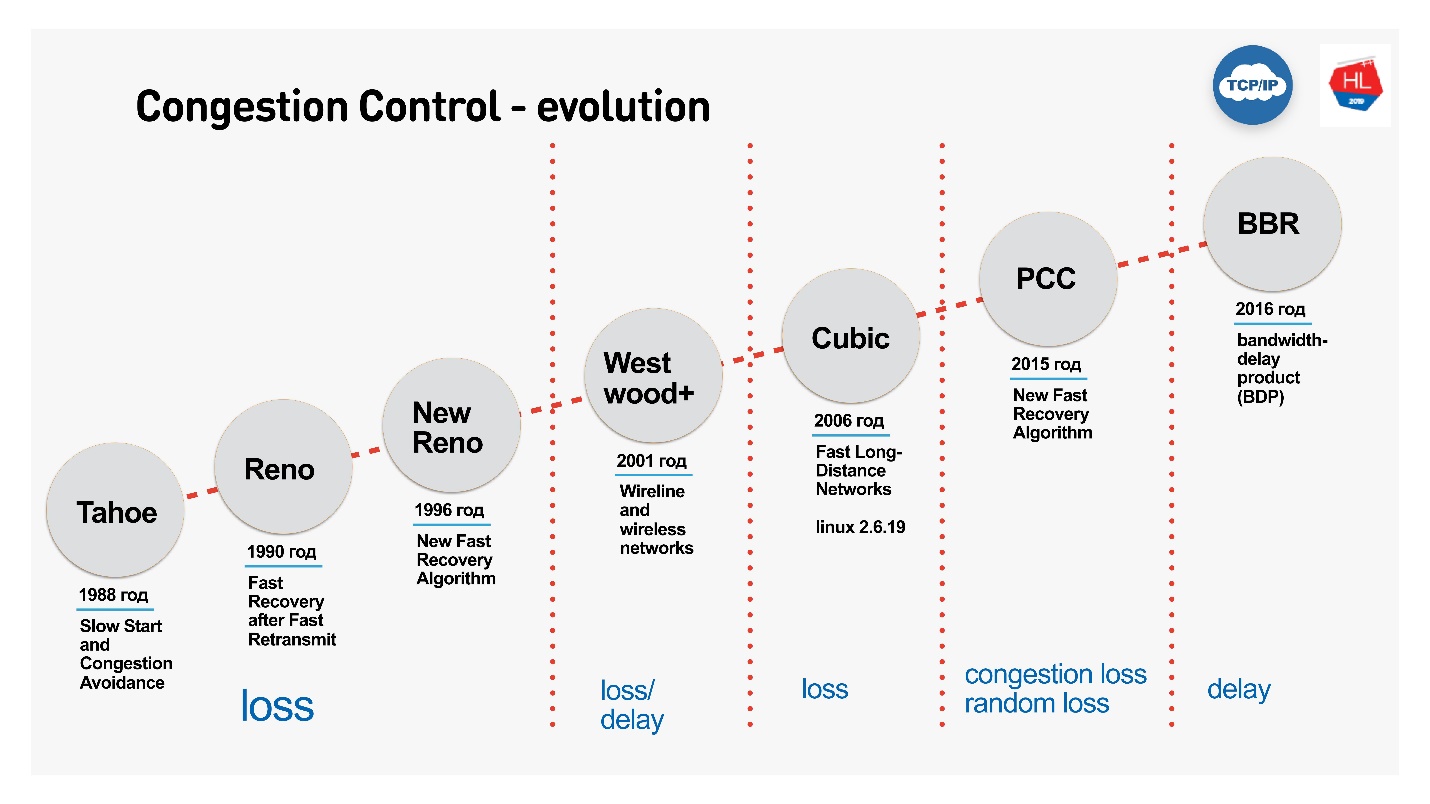
:
- Cubic — Congestion Control Linux 2.6. : — .
- BBR — Congestion Control, Google 2016 . .
BBR Congestion Control
Cubic BBR feedback.
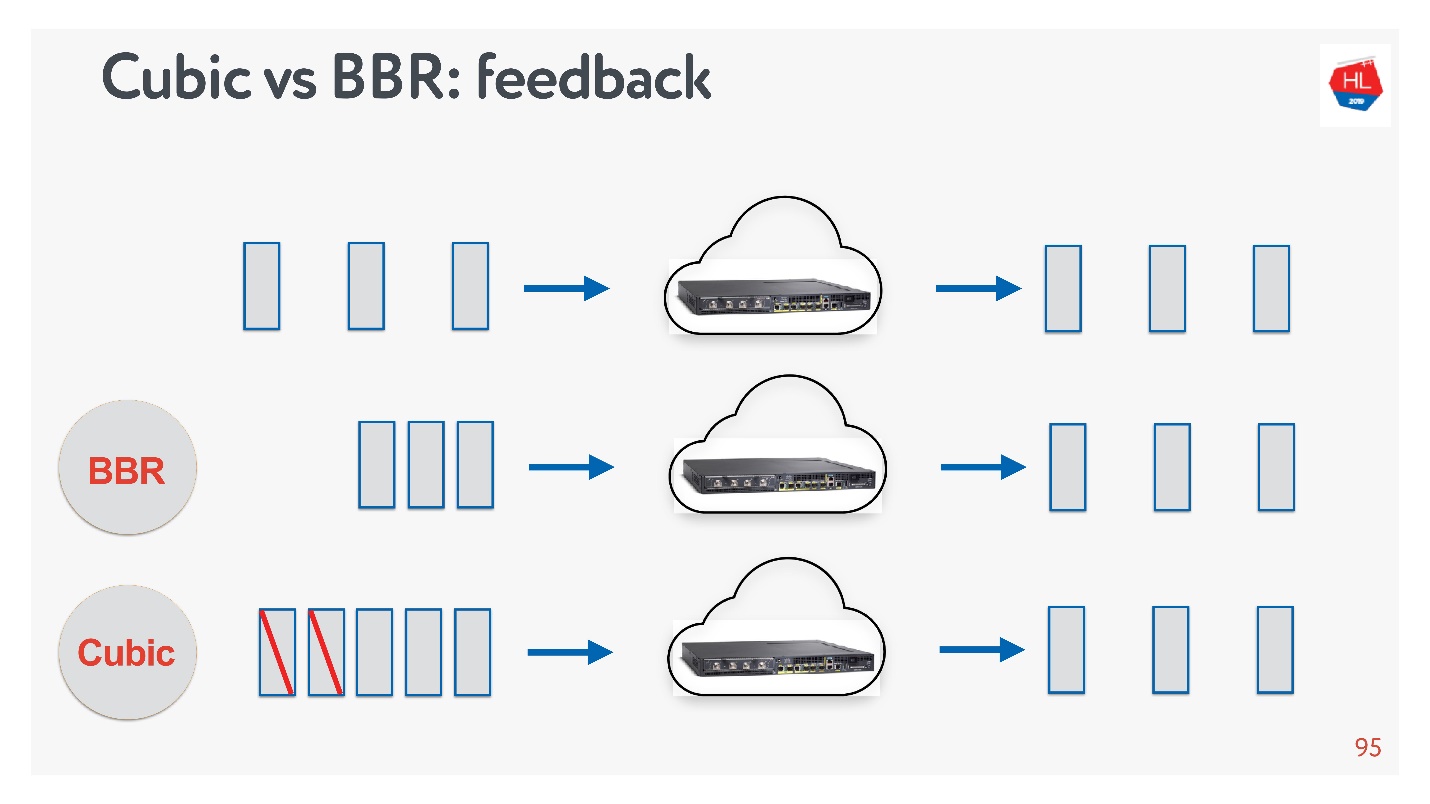
, — acknowledgement . :
Di bawah ini adalah grafik dari penundaan terhadap waktu koneksi, yang menunjukkan apa yang terjadi pada Kontrol Kemacetan yang berbeda.
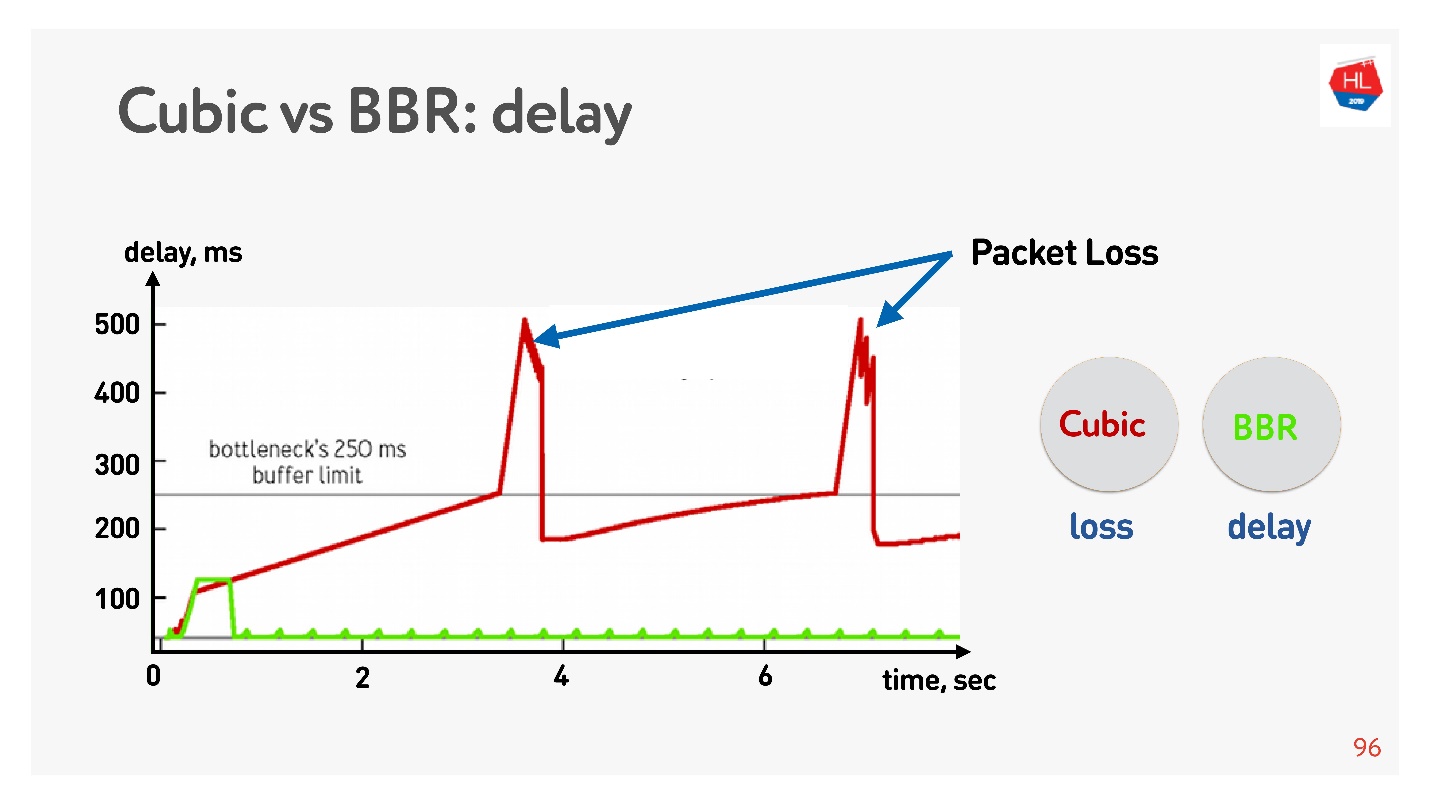
BBR pertama kali merasakan waktu pulang-pergi, mengirimkan lebih banyak paket, kemudian menyadari bahwa buffer tersumbat, dan memasuki mode operasi dengan penundaan minimal.
Cubic bekerja secara agresif - itu meluap ke seluruh buffer, dan ketika buffer meluap dan kehilangan paket terjadi, cubic mengurangi jendela.
Tampaknya dengan bantuan BBR akan mungkin untuk menyelesaikan semua masalah, tetapi ada
jitter di jaringan - paket kadang-kadang tertunda, kadang-kadang dikelompokkan dalam bundel. Anda mengirim mereka dengan frekuensi tertentu, dan mereka datang berkelompok. Lebih buruk lagi, ketika Anda menerima ucapan terima kasih kembali ke paket-paket ini, dan mereka juga entah bagaimana "jitter".
Karena saya berjanji bahwa semuanya dapat disentuh dengan tangan, maka kami melakukan ping, misalnya, situs
HighLoad ++ , melihat ping dan mempertimbangkan jitter di antara paket-paket.
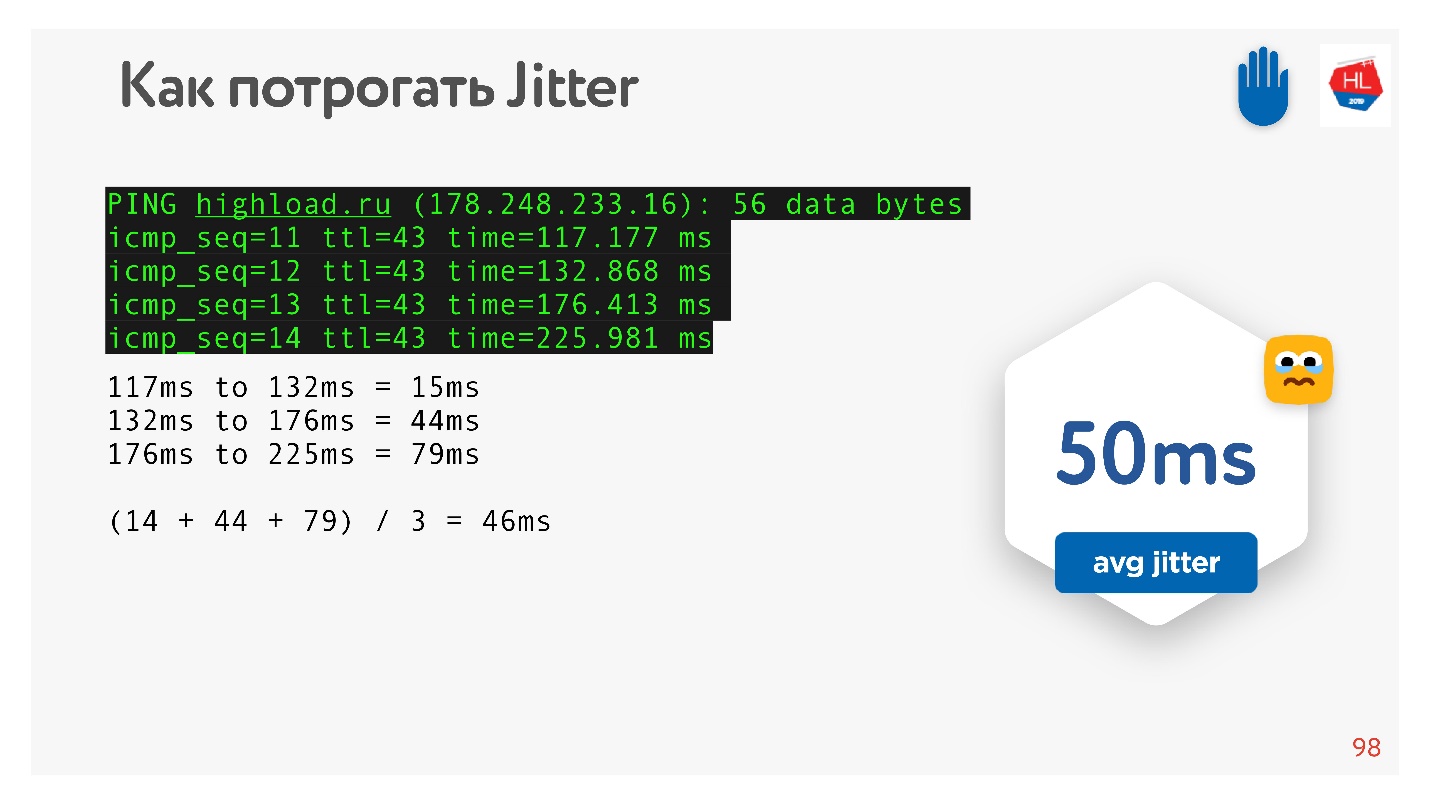
Dapat dilihat bahwa paket datang tidak rata, rata-rata jitter adalah sekitar 50 ms. Secara alami, BBR mungkin salah.
BBR bagus karena membedakan antara: kehilangan kongesti nyata, kehilangan paket karena buffer overflow perangkat, dan kehilangan acak karena buruknya jaringan nirkabel. Tapi itu tidak berfungsi dengan baik jika jitter tinggi. Bagaimana saya bisa membantunya?
Cara membuat kontrol kemacetan lebih baik
Bahkan, TCP tidak memiliki informasi yang cukup dalam pengakuan, hanya memiliki paket apa yang dilihatnya. Ada juga pengakuan selektif, yang mengatakan paket mana yang dikonfirmasi, yang belum tiba. Tetapi informasi ini tidak cukup.
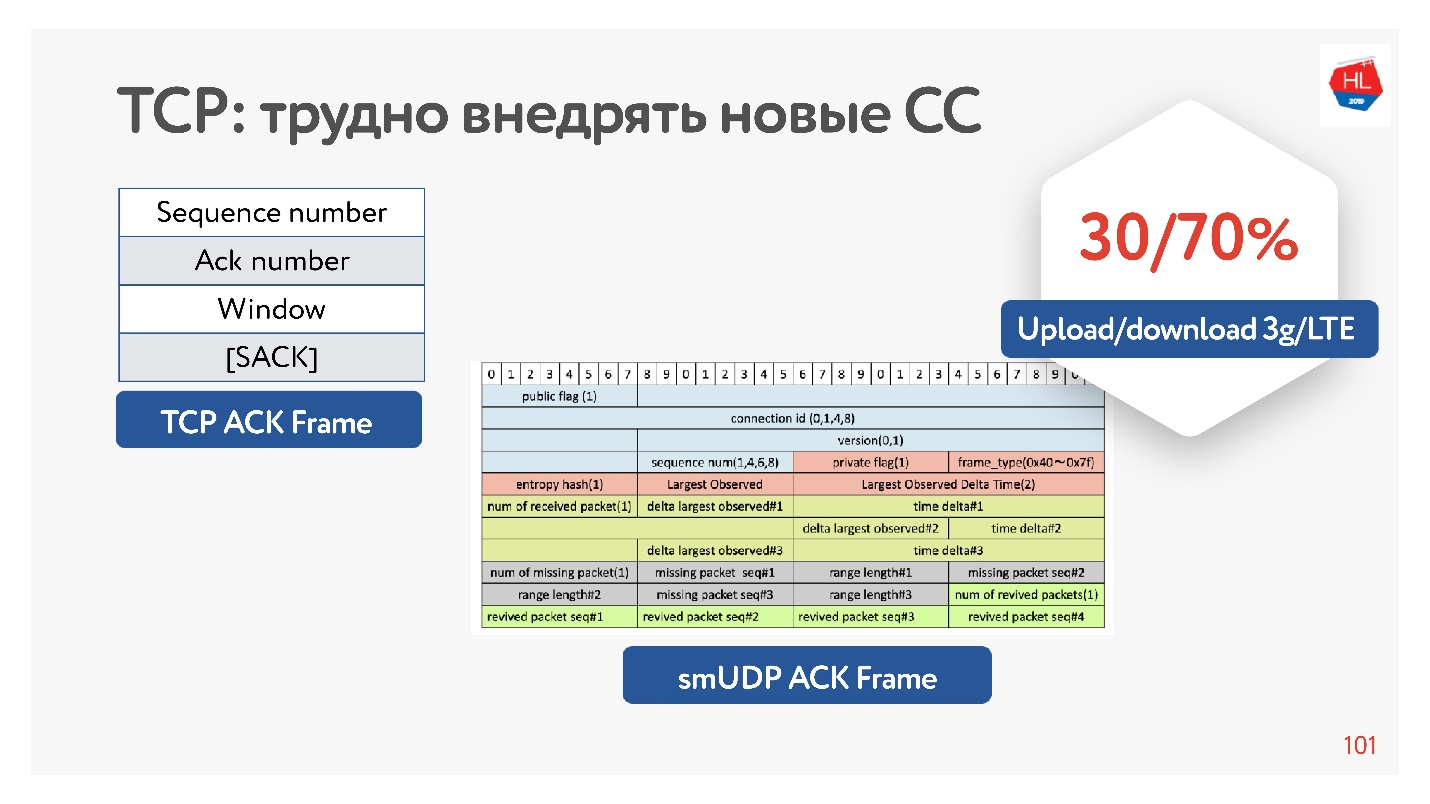
Jika Anda memiliki kesempatan untuk meningkatkan pengakuan, Anda masih dapat menghemat waktu - tidak hanya mengirim paket-paket ini, tetapi juga tiba di klien. Itu, pada kenyataannya, di server untuk mengumpulkan klien jitter.
Mengapa efektif meningkatkan pengakuan? Karena jaringan seluler asimetris. Misalnya, biasanya dengan 3G atau LTE, 70% dari bandwidth dialokasikan untuk mengunduh data dan 30% untuk mengunggah. Pemancar beralih: unggah - unduh, unggah - unduh, dan Anda tidak memengaruhinya dengan cara apa pun. Jika Anda tidak membongkar apa pun, maka itu hanya menganggur. Karena itu, jika Anda memiliki ide menarik, tingkatkan pengakuan, jangan malu-malu - ini bukan masalah.
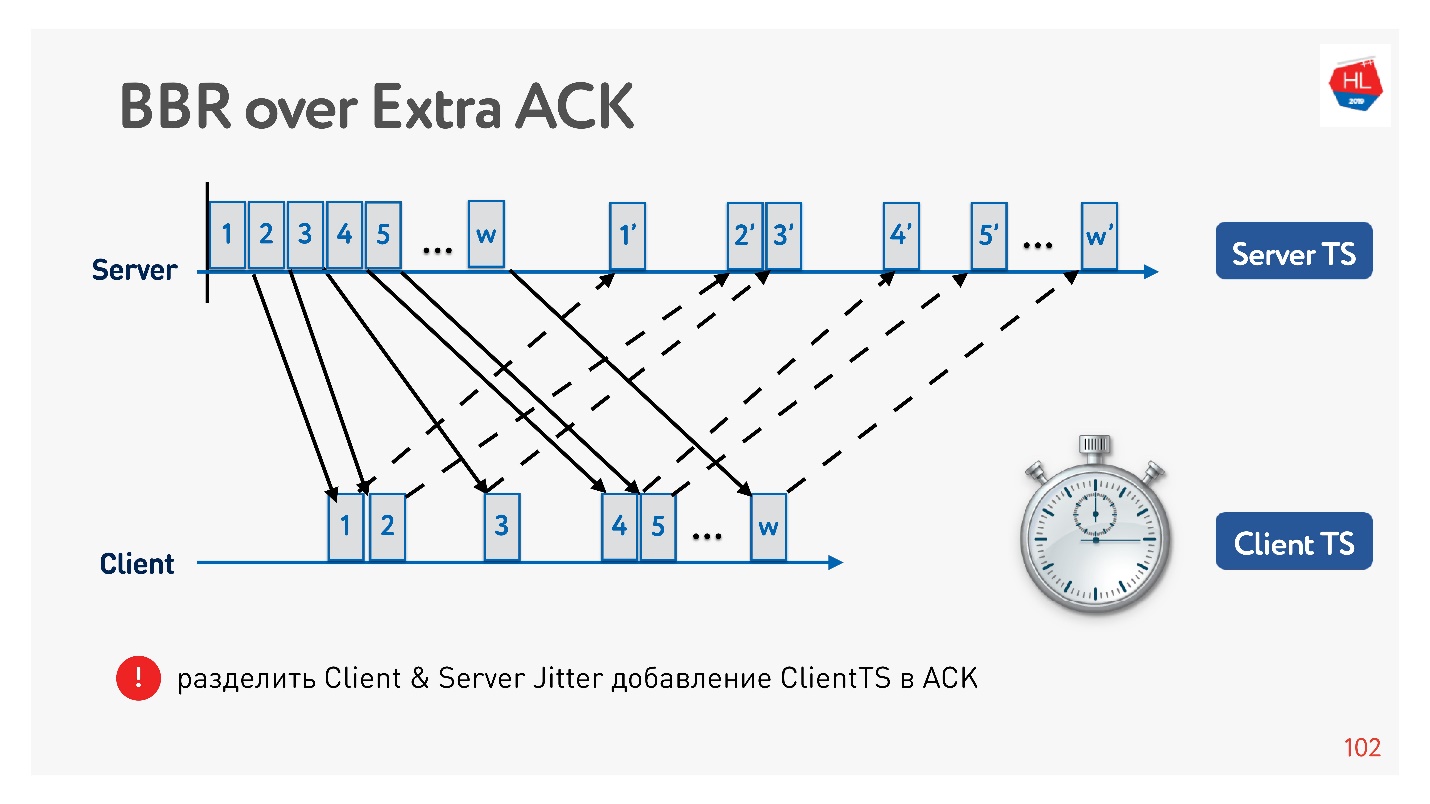
Contoh bagaimana Anda dapat menggunakan pengakuan untuk membagi jitter ke dalam pengiriman dan jitter untuk menerima, dan melacaknya secara terpisah. Kemudian kita menjadi lebih fleksibel, dan kita mengerti kapan kehilangan kemacetan terjadi, dan ketika kehilangan acak terjadi. Misalnya, Anda dapat memahami berapa banyak jitter di setiap arah, dan lebih tepatnya mengkonfigurasi jendela.

Kontrol kemacetan mana yang harus dipilih
Teman sekelas adalah jaringan besar dengan banyak lalu lintas berbeda: video, API, gambar. Dan ada statistik yang mengontrol kemacetan yang lebih baik untuk dipilih.
BBR selalu efektif untuk video karena mengurangi penundaan. Dalam kasus lain, Cubic biasanya digunakan - itu bagus untuk foto. Tetapi ada opsi lain.

Ada puluhan opsi kontrol kemacetan yang berbeda. Untuk memilih yang terbaik, Anda dapat mengumpulkan statistik pada klien dan mencoba satu atau lain kontrol kemacetan untuk berbagai jenis profil pemuatan.
Misalnya, ini adalah efek memulai BBR pada video.
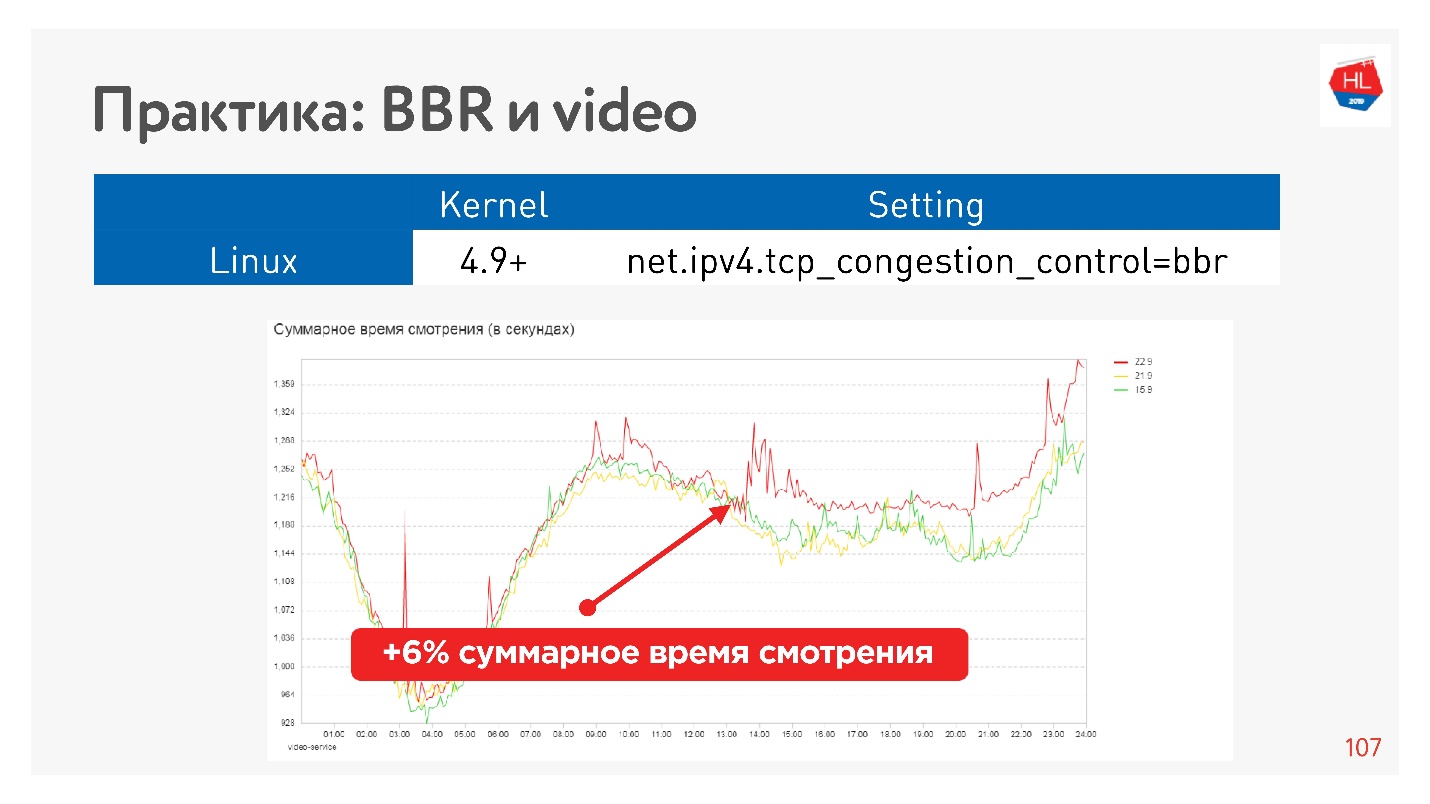
Kami berhasil meningkatkan kedalaman tampilan secara serius. Google mengatakan mereka memiliki sekitar 10% lebih sedikit buffering pada pemain saat menggunakan BBR.
Hebat, tapi bagaimana dengan pelanggan kami?

Klien agak lambat, mereka semua memiliki Cubic, dan Anda tidak dapat mempengaruhinya. Tapi tidak apa-apa, kadang-kadang Anda bisa memparalelkan data, dan itu akan baik.
Kesimpulan tentang kontrol kemacetan:- BBR selalu bagus untuk video.
- Dalam kasus lain, jika kami menggunakan protokol UDP kami sendiri, Anda dapat mengambil kendali kemacetan dengan Anda.
- Dari sudut pandang TCP, Anda hanya dapat menggunakan kontrol kemacetan, yang ada di kernel. Jika Anda ingin menerapkan kontrol kemacetan Anda ke dalam kernel, Anda harus mematuhi spesifikasi TCP. Tidak mungkin untuk mengembang pengakuan, untuk membuat perubahan, karena mereka tidak ada di klien.
Jika Anda membuat protokol UDP, Anda memiliki lebih banyak kebebasan dalam hal kontrol kemacetan.
Multiplexing dan Prioritas
Ini adalah tren baru, semua orang melakukannya sekarang. Ada masalah apa? Jika kita menggunakan TCP, pasti semua orang (atau hampir semua orang) tahu situasi pemblokiran head-of-line.
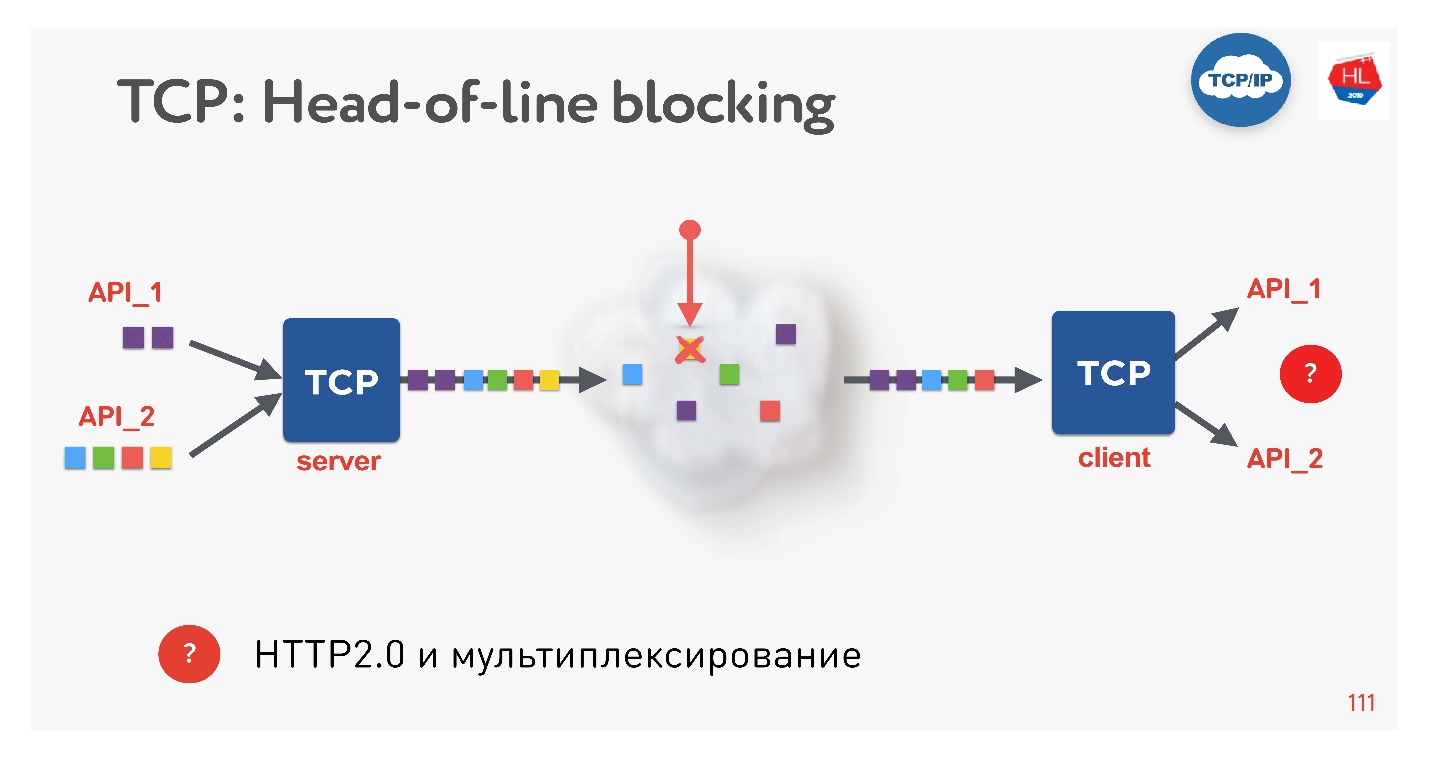
Ada beberapa permintaan yang multiplexing melalui koneksi TCP tunggal. Kami mengirim mereka ke jaringan, tetapi beberapa paket hilang. Sambungan TCP akan mentransmisikan ulang paket ini, akan mengirimkan kembali dalam waktu dekat dengan RTT atau lebih. Saat ini, kami tidak akan bisa mendapatkan apa pun, meskipun buffer TCP berisi data dari permintaan lain yang sepenuhnya siap untuk diambil.
Ternyata multiplexing melalui TCP, jika Anda menggunakan HTTP 2.0, tidak selalu efektif pada jaringan yang buruk.
Masalah selanjutnya adalah pembengkakan buffer.

Ketika gambar dikirim ke klien, buffer meningkat. Kami mengirimnya untuk waktu yang lama, dan kemudian permintaan API muncul, dan itu tidak dapat diprioritaskan. Dalam kasus seperti itu, penentuan prioritas TCP tidak berfungsi.
Jadi, jika packet loss terjadi, ada pemblokiran head-of-Line, dan ketika klien memiliki bitrate variabel (dan ini sering terjadi pada klien seluler), efek bufferbloat muncul. Akibatnya, tidak multiplexing, atau prioritisasi, atau server push, atau segala sesuatu yang lain, karena kami memiliki buffer atau klien mengharapkan sesuatu.
Jika kita melakukan multiplexing sendiri, maka kita bisa meletakkan berbagai data di sana.
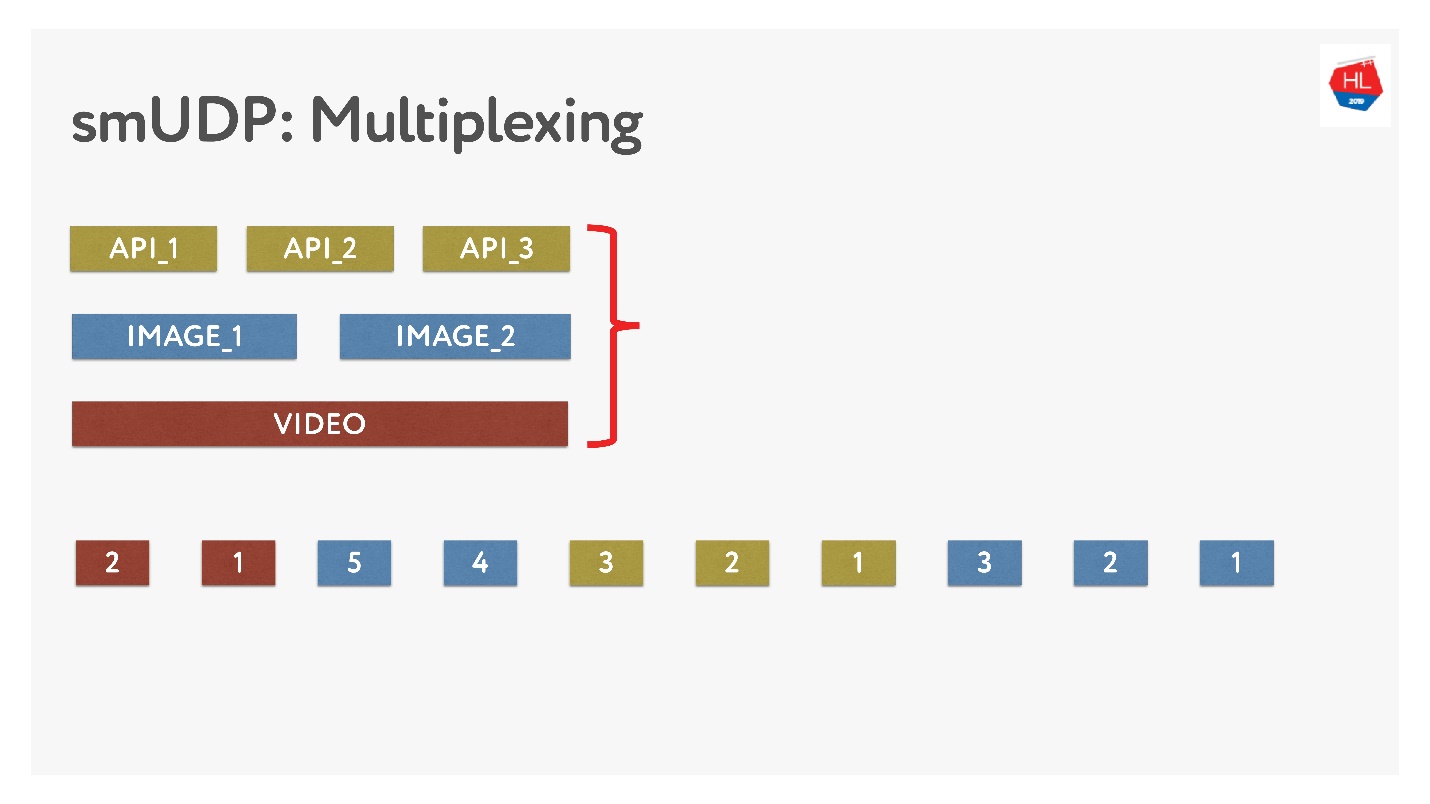
Ini tidak sulit, cukup tambahkan paket dengan nomor ke buffer. On-the-fly - jangan menyentuh apa yang sudah dikirim, tetapi apa yang belum terkirim dapat diatur ulang. Ini terlihat seperti ini.
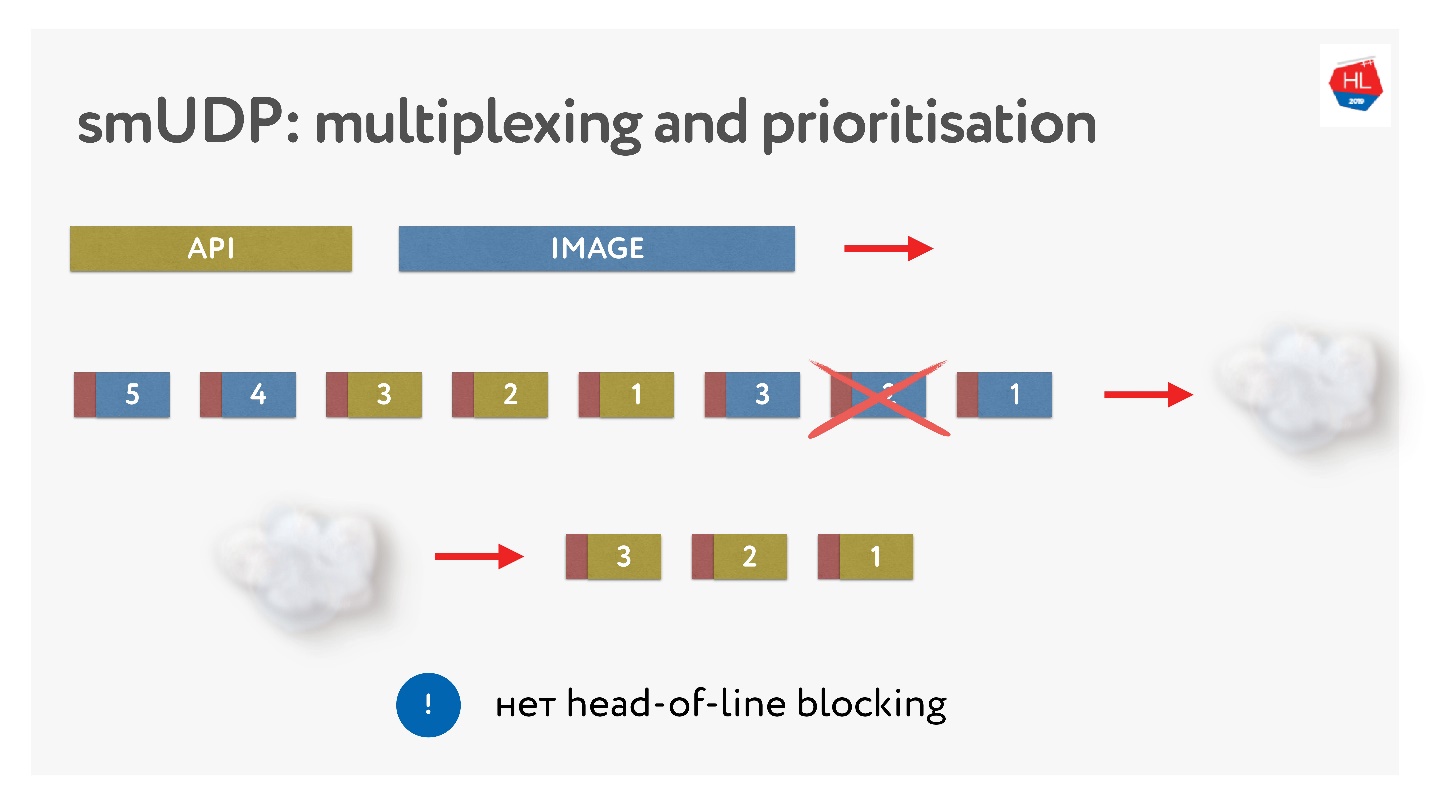
Mereka mengirim gambar, memecahnya menjadi paket, datang permintaan API prioritas: mereka memasukkannya, mengirim gambar. Bahkan jika suatu paket hilang, kita bisa mendapatkan permintaan API yang sudah jadi dari buffer, itu adalah prioritas tinggi dan akan dengan cepat menjangkau klien. Dalam TCP, menurut definisi, streaming transfer data tidak dimungkinkan.
Buat koneksi
Jika kita profil aplikasi kita, kita akan melihat bahwa sebagian besar waktu jaringan menganggur pada awal aplikasi, karena koneksi pertama kali dibuat sebelum API, maka kita mendapatkan data, kemudian koneksi dibuat sebelum gambar, data ini diunduh, dll. Ini selalu terjadi - jaringan digunakan oleh puncak.

Untuk mengatasinya, mari kita lihat bagaimana koneksi dibuat.
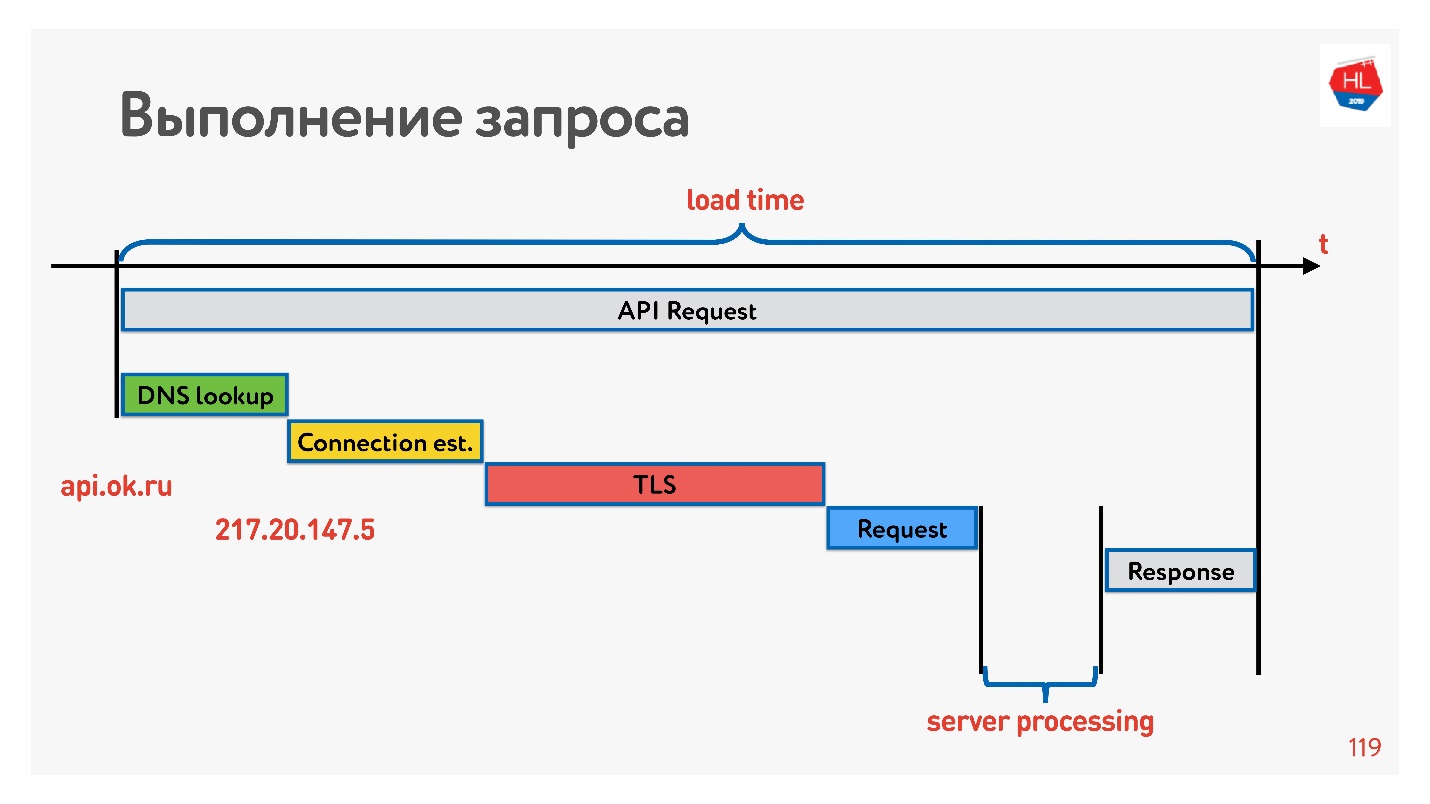
Yang pertama adalah menyelesaikan DNS - kami tidak dapat melakukan apa pun dengan ini. Selanjutnya, buat koneksi TCP, buat koneksi aman, lalu jalankan permintaan dan terima respons. Yang paling menarik adalah bagian dari pekerjaan yang server lakukan ketika menanggapi permintaan biasanya membutuhkan waktu lebih sedikit daripada membangun koneksi.
Sekarang sangat modis untuk mengukur angka latensi untuk memori, untuk disk, untuk hal lain. Anda dapat mengukurnya untuk jaringan 3G, 4G dan melihat berapa lama yang dibutuhkan untuk membuat koneksi TCP dengan TLS.
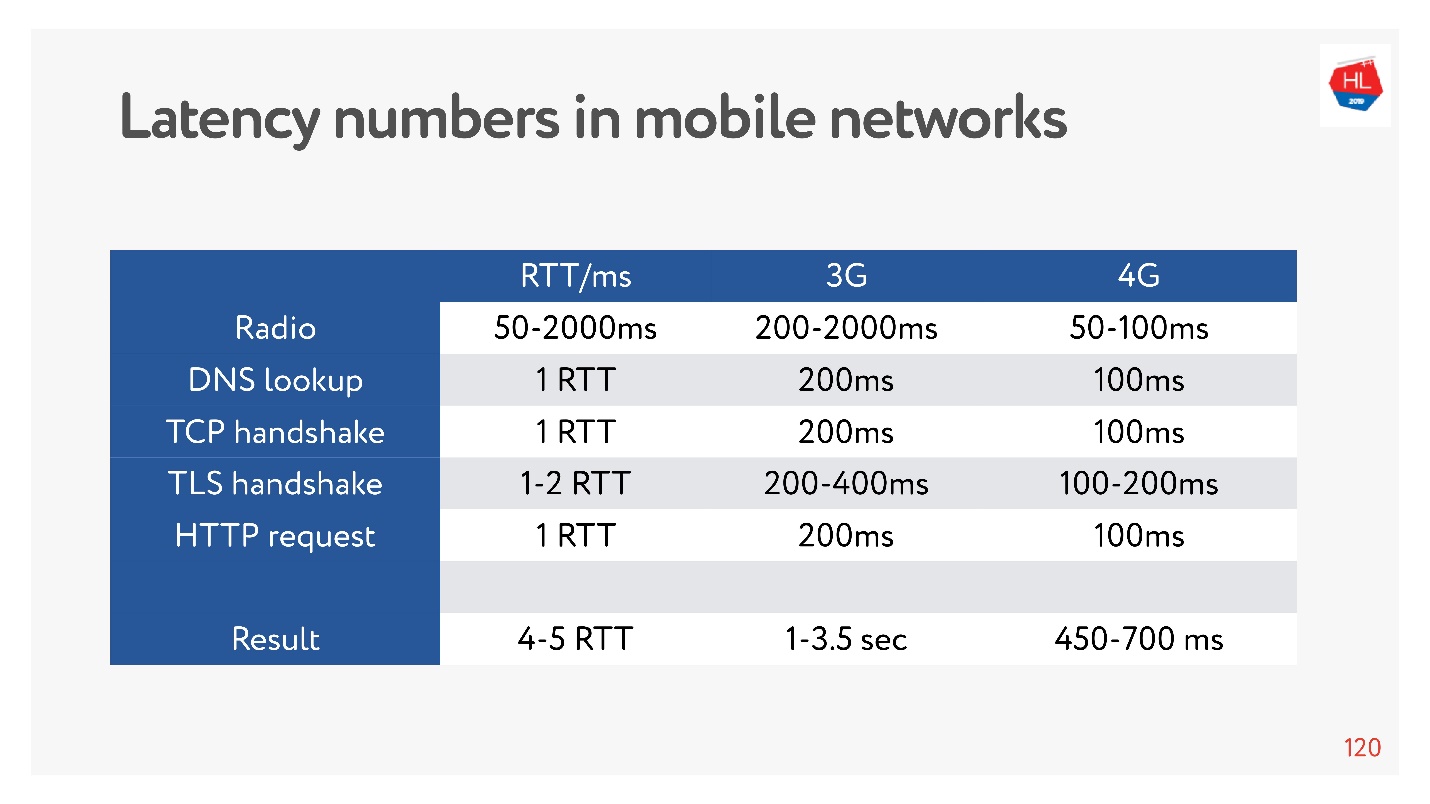
Dan itu bisa beberapa detik! Bahkan pada 4G hingga 700 ms juga signifikan. Tapi TCP tidak bisa hidup dengan mudah selama ini.
Koneksi didasarkan pada algoritma
handshake TCP 3-way dasar. Lakukan syn, syn + ack, lalu perbaiki permintaan nanti (di sebelah kiri dalam diagram).
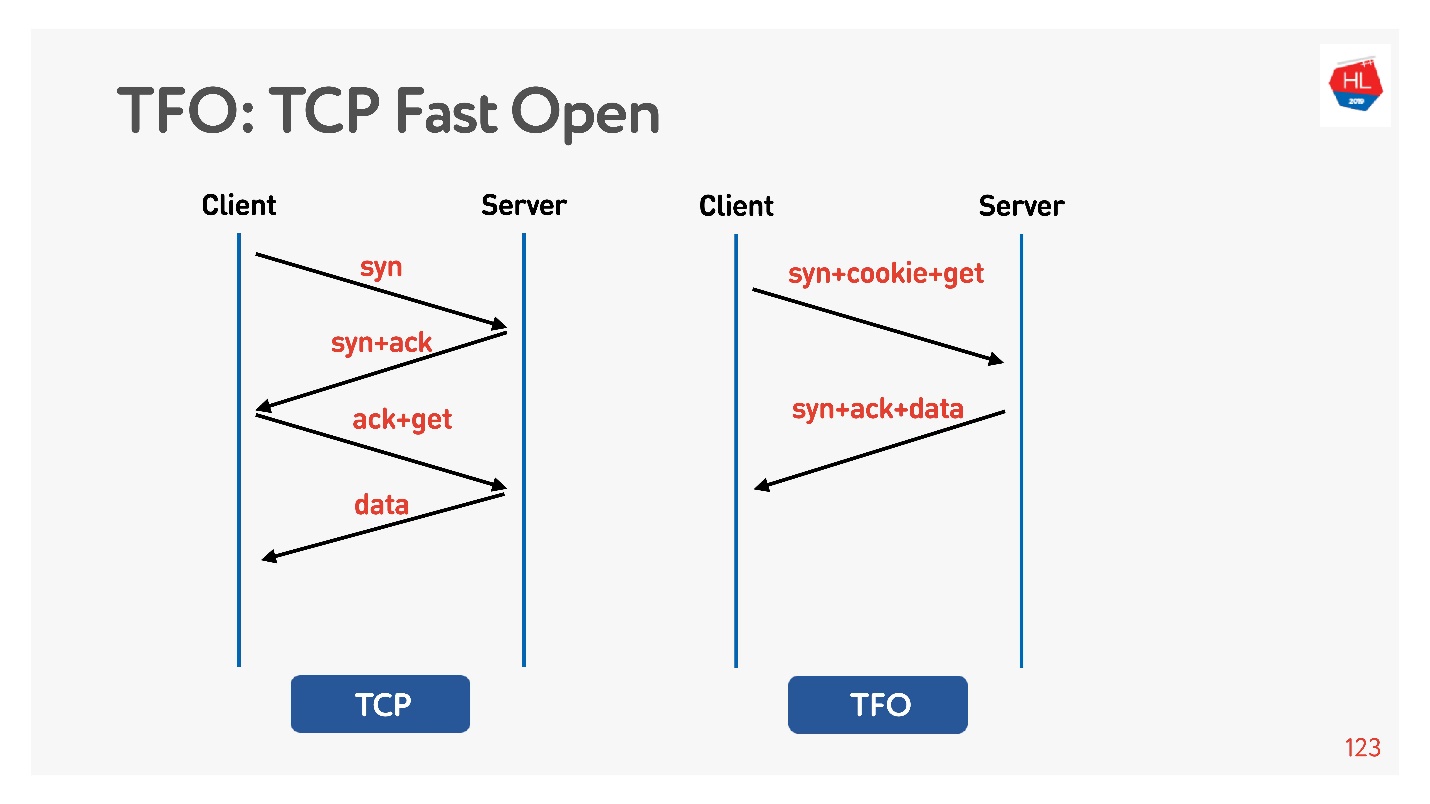
Ada
TCP Fast Open (kanan). Jika Anda sudah berjabat tangan dengan server ini, ada cookie, Anda dapat segera mengirim permintaan Anda untuk zero-RTT. Untuk menggunakan ini, Anda perlu membuat socket, membuat sendto () data pertama, katakan bahwa Anda ingin FASTOPEN.

Nginx dapat melakukan semua ini - cukup nyalakan, semuanya akan bekerja (atau nyalakan di kernel).
TLS
Mari kita periksa apakah TLS itu buruk.
Saya mengatur pembentuk bersih lagi untuk 200 ms, ping google.com dan melihat bahwa RTT = 220 adalah pembentuk RTT + RTT saya. Lalu saya membuat permintaan melalui HTTP dan HTTPS. Saya menemukan bahwa melalui HTTP dimungkinkan untuk mendapatkan respons selama RTT, yaitu, TFO berfungsi untuk Google dari komputer saya. Untuk HTTPS, ini butuh waktu lebih lama.

Ini adalah overhead TLS yang umum yang membutuhkan pengiriman pesan untuk membuat koneksi yang aman.
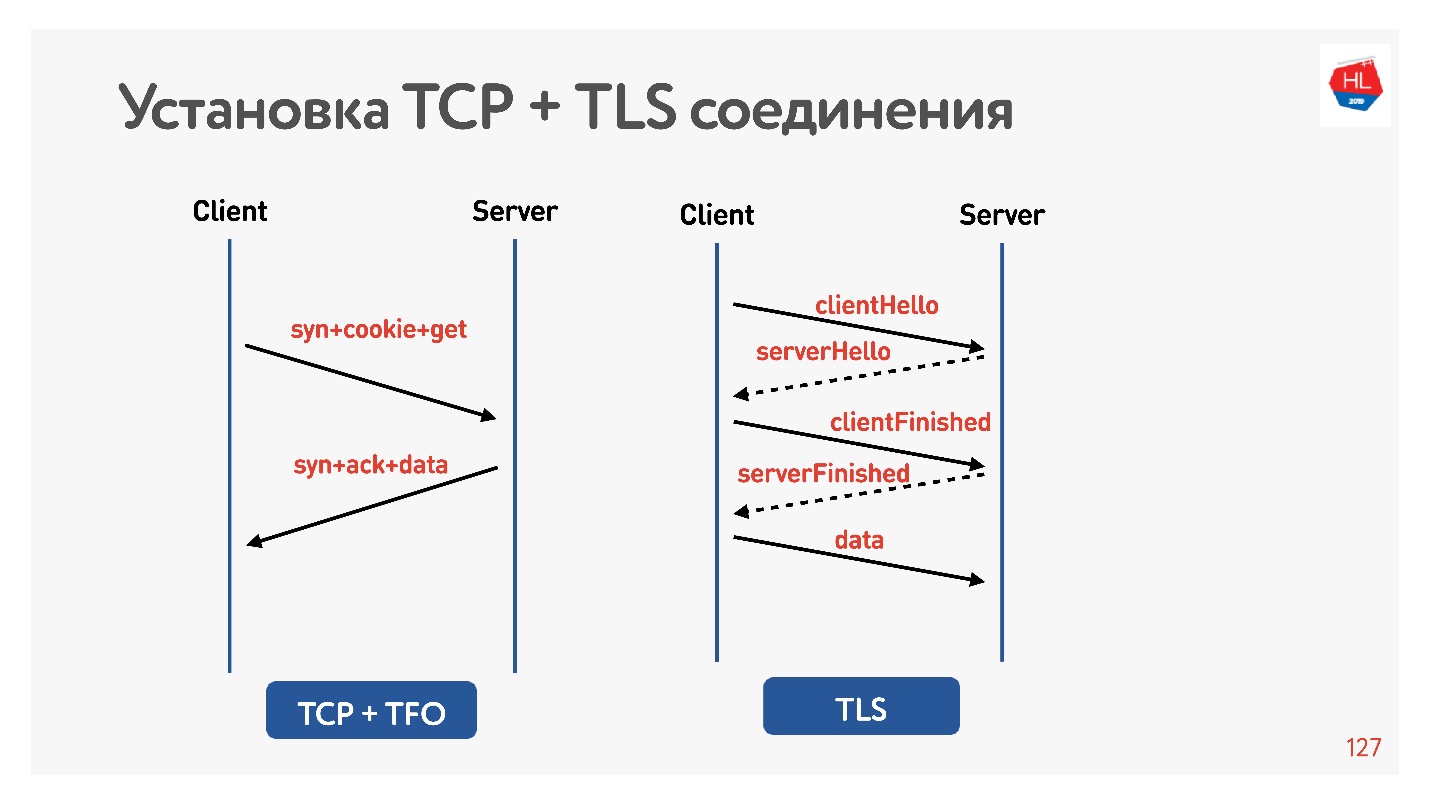
Untuk melakukan ini, mereka berpikir untuk kita, menambahkan TLS 1.3. Juga mudah dimasukkan ke dalam nginx.
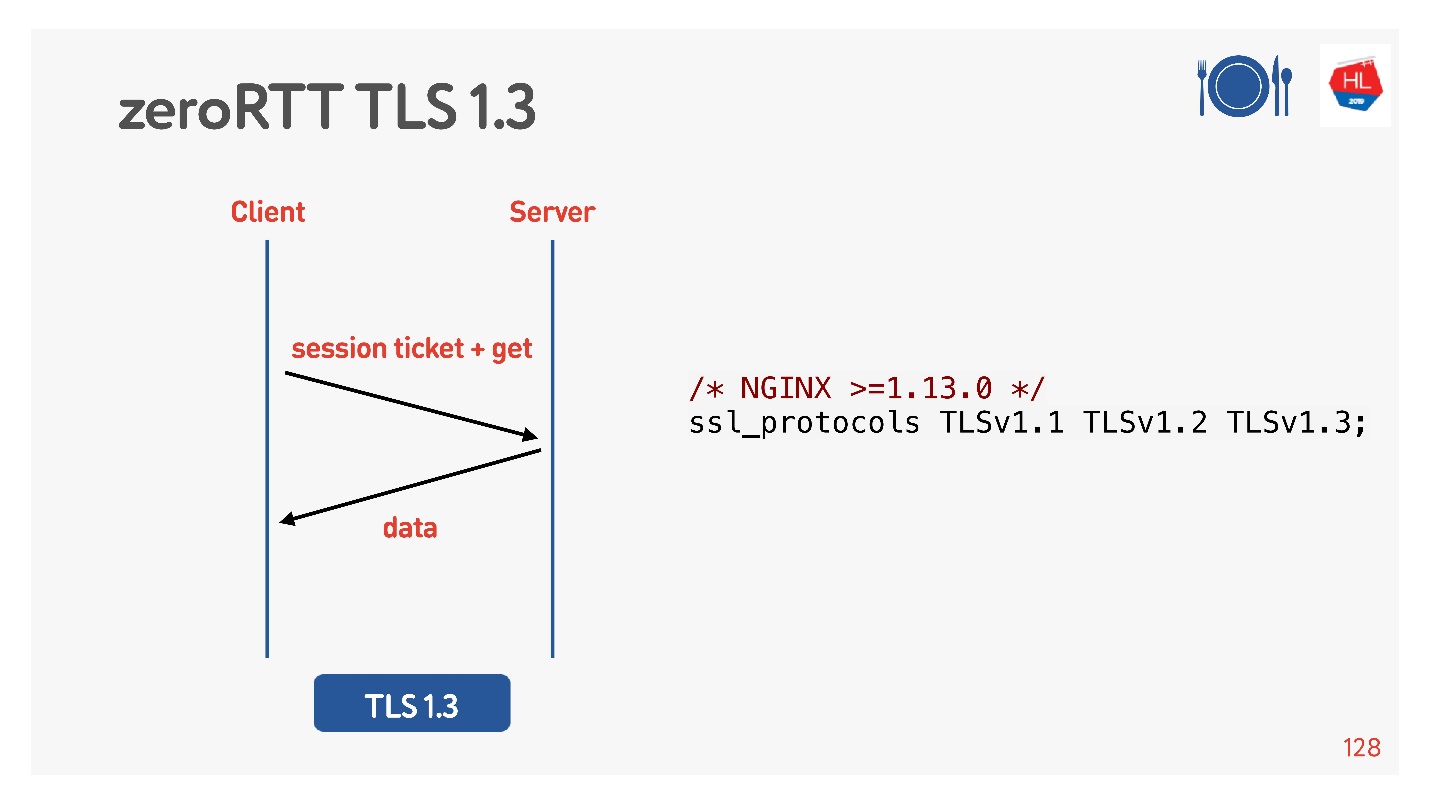
Segalanya tampak bekerja. Tapi mari kita lihat apa yang ada di klien seluler kami yang memanfaatkan semua ini.
Ada apa dengan pelanggan
TCP Fast Open adalah hal yang keren. Menurut statistik.
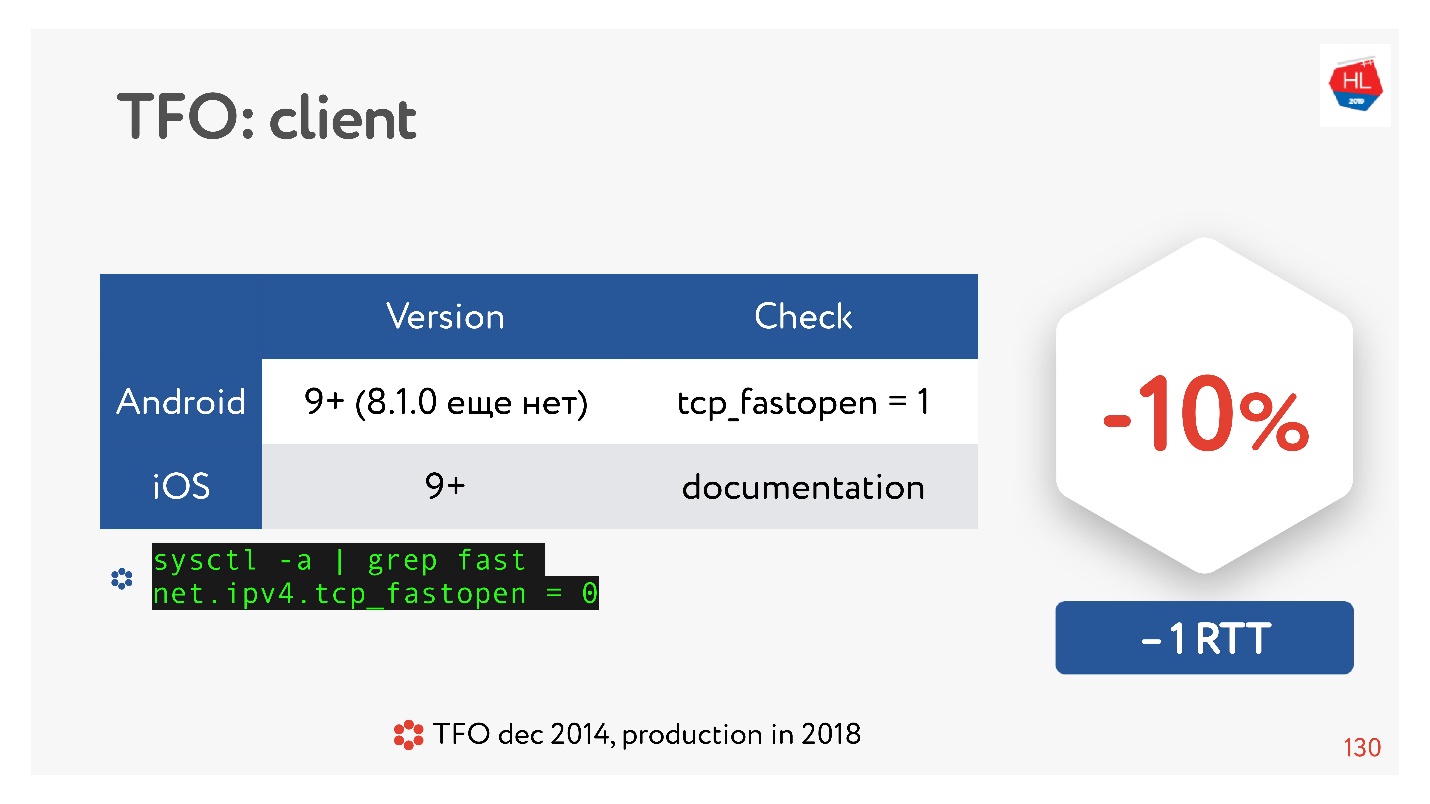
Ada banyak artikel yang mengatakan bahwa membangun koneksi dijamin lulus 10% lebih cepat. Tetapi pada Android 8.1.0 (saya menonton berbagai perangkat) tidak ada yang memiliki TFO. Di Android 9, saya melihat TFO pada emulator, tetapi tidak pada perangkat nyata. IOS sedikit lebih baik. Di sini Anda bisa melihatnya:
sysctl -a | grep fast net.ipv4.tcp_fastopen = 0
Mengapa ini terjadi? TCP Fast Open diusulkan kembali pada tahun 2014, sekarang sudah standar, didukung di Linux dan semuanya hebat. Tetapi ada masalah sehingga jabat tangan TFO mulai berantakan di beberapa jaringan. Ini karena beberapa penyedia (atau beberapa perangkat) digunakan untuk memeriksa TCP, melakukan optimasi mereka, dan tidak berharap bahwa akan ada jabat tangan TFO. Oleh karena itu, implementasinya membutuhkan banyak waktu, dan sampai sekarang, klien seluler tidak memasukkannya secara default, setidaknya Android.
Dengan TLS 1.3, yang menjanjikan kita pengaturan koneksi zero-RTT bahkan lebih baik. Saya tidak menemukan perangkat Android yang akan berfungsi. Oleh karena itu, Facebook membuat perpustakaan
Fizz . Beberapa bulan yang lalu, itu menjadi tersedia di open source, Anda dapat menyeretnya dengan Anda dan menggunakan TLS 1.3. Ternyata bahkan keamanan harus diseret, tidak ada yang muncul dalam inti dari ini.
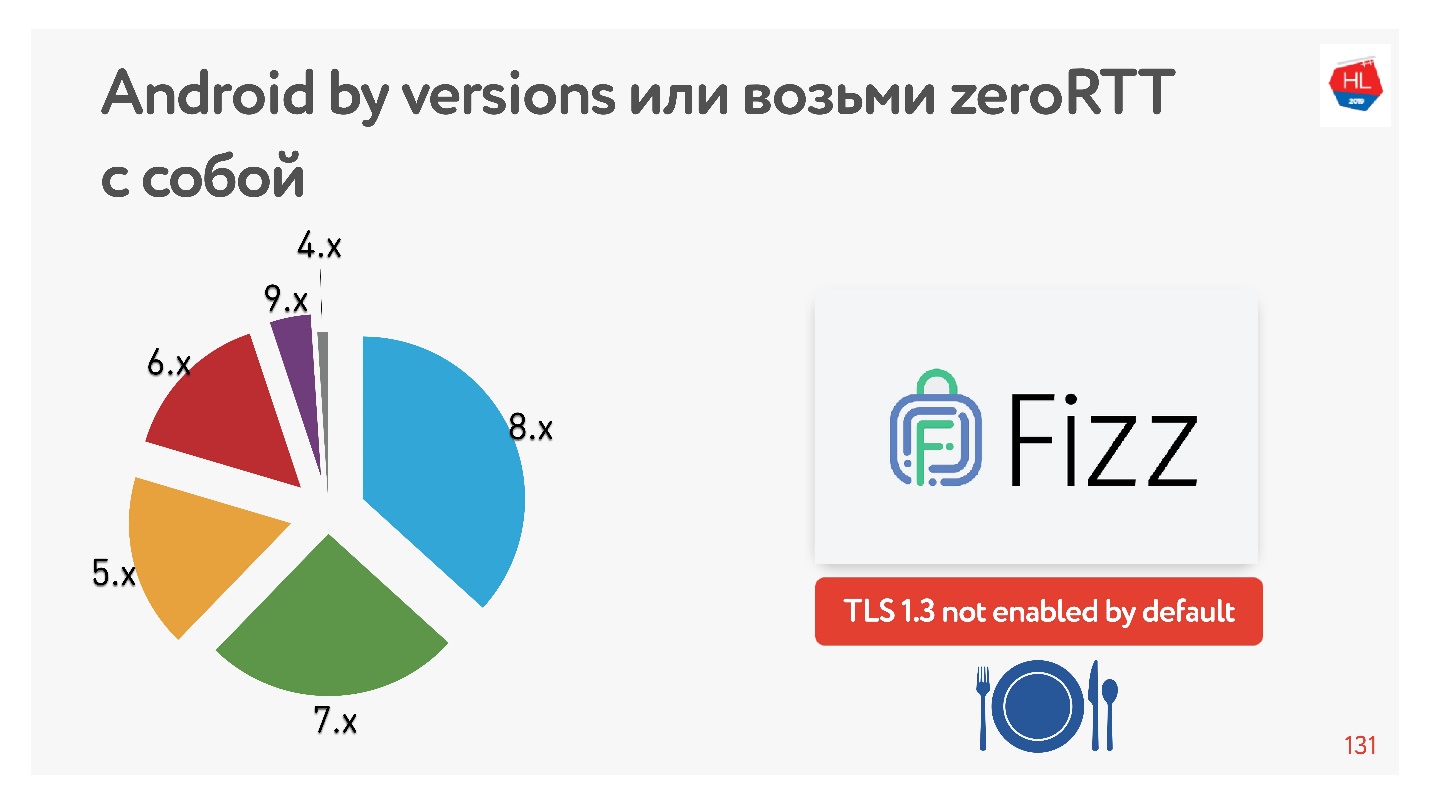
Diagram menunjukkan penggunaan berbagai versi Android oleh klien seluler kami. V 9.x cukup sedikit - di mana TFO dapat muncul, dan TLS1.3 tidak ditemukan di tempat lain.
Kesimpulan tentang membangun koneksi:- TFO tidak tersedia untuk 95% perangkat.
- TLS1.3 perlu dibawa sendiri.
- Jika Anda perlu mengulang ini di UDP, maka transfer semua ini ke UDP dan ulangi.
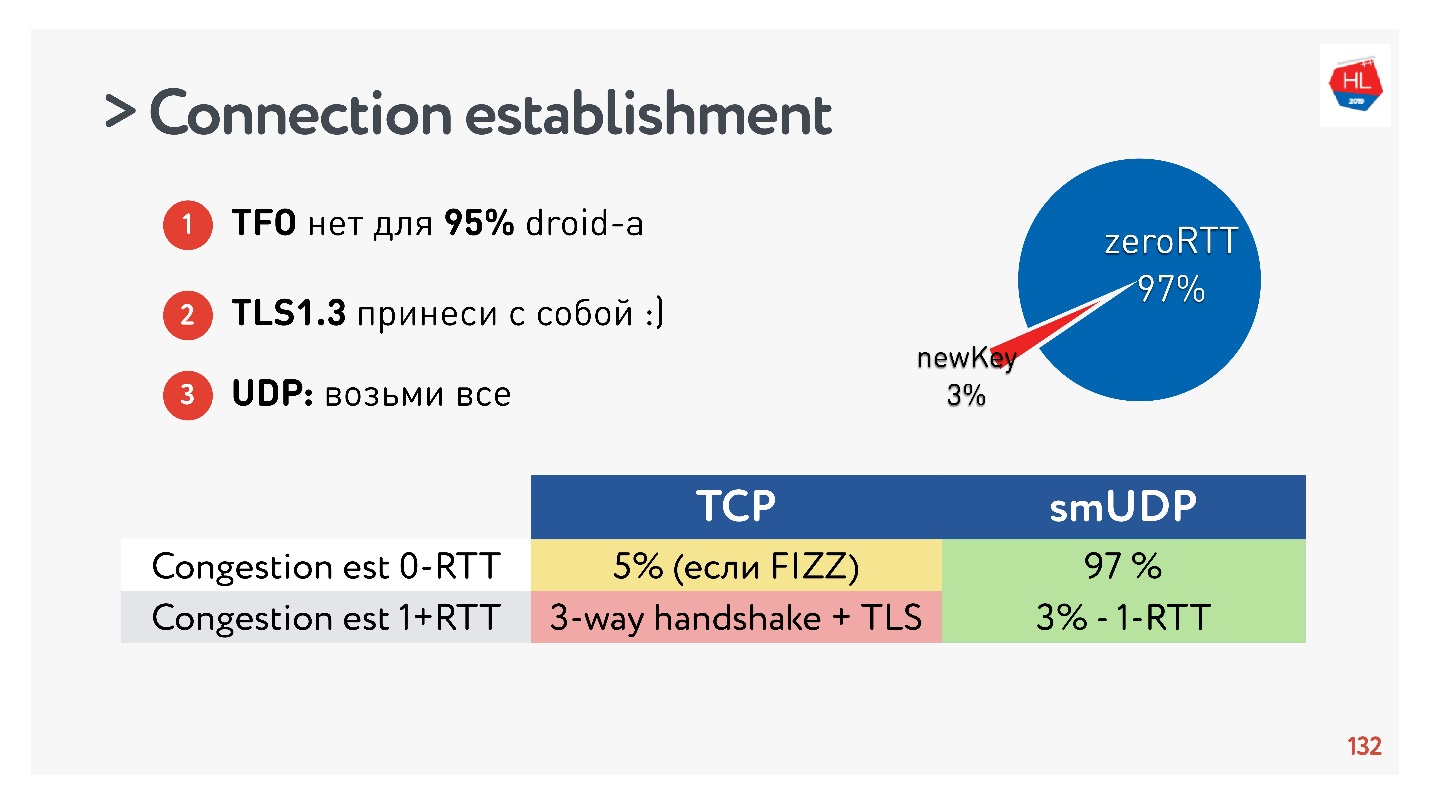
Ternyata 97% dari koneksi yang dibuat menggunakan kunci yang ada, yaitu, 97% dibuat untuk nol RTT, dan hanya 3% yang baru. Kunci disimpan pada perangkat untuk beberapa waktu.
TCP tidak dapat menyombongkannya. Dalam maksimal 5% kasus, jika Anda melakukan semuanya dengan benar, Anda akan bisa mendapatkan nol-RTT nyata yang dibicarakan semua orang sekarang.
Perubahan alamat IP
Seringkali, ketika Anda meninggalkan rumah, ponsel Anda beralih dari Wi-Fi ke 4G.
TCP berfungsi seperti ini: alamat IP telah berubah - koneksi gagal.
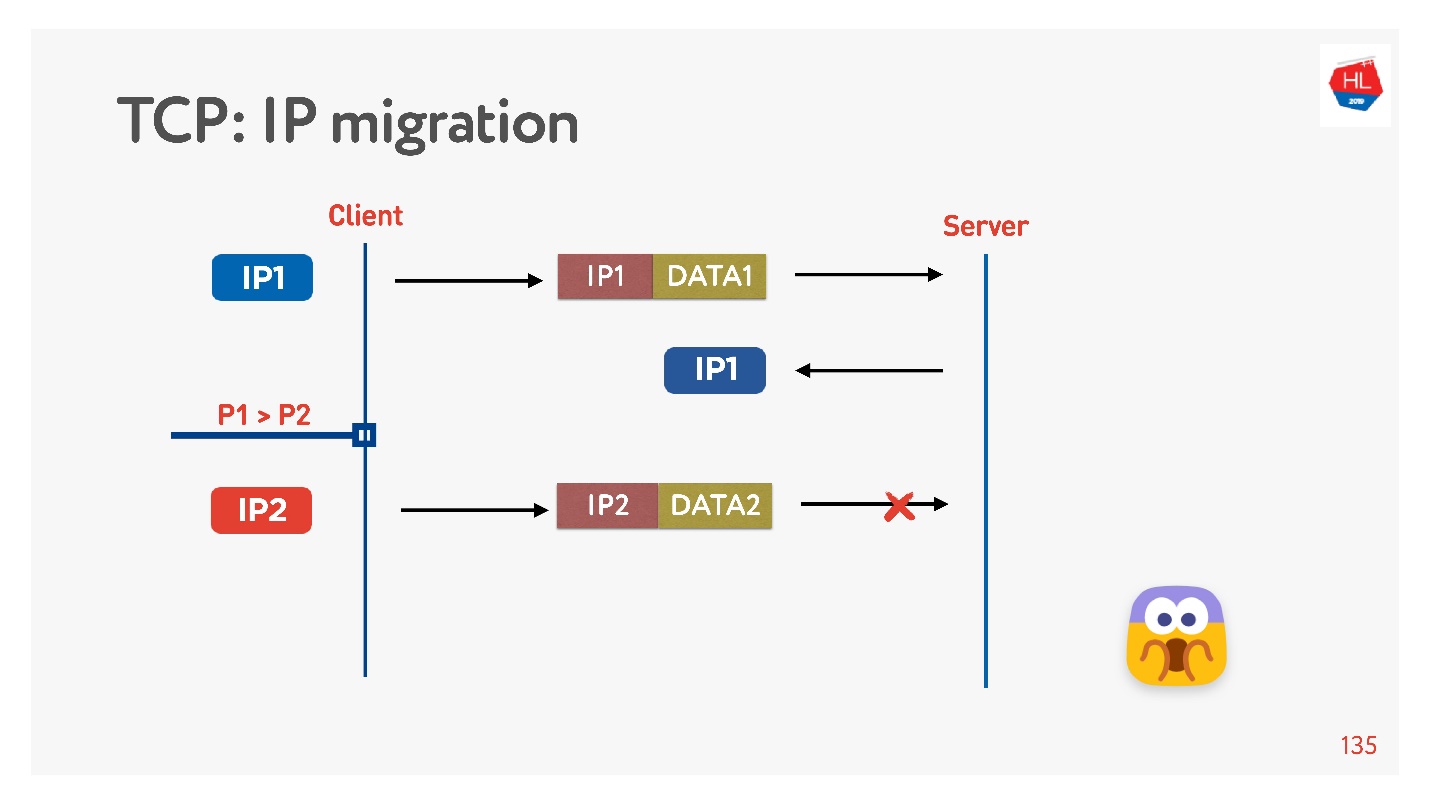
Jika Anda menulis protokol UDP Anda, ini sangat sederhana, dengan menerapkan ID koneksi (CUID) di setiap paket, Anda dapat mengidentifikasinya, bahkan jika itu berasal dari alamat IP yang berbeda.

Jelas bahwa Anda perlu memastikan bahwa ia memiliki kunci yang benar, semuanya didekripsi, dll. Tetapi pada prinsipnya, Anda dapat mulai menanggapi alamat ini, tidak akan ada masalah dengan ini.
Dalam TCP, Migrasi IP adalah hal yang mustahil.
Jika Anda membuat UDP Anda, dan Anda datang ke server yang sama, Anda perlu melakukan sedikit keajaiban, memasukkan CID di setiap paket, dan Anda akan dapat menggunakan koneksi yang telah dibuat saat mengubah alamat IP.
Koneksi ulang
Semua orang mengatakan Anda perlu menggunakan kembali koneksi karena koneksi adalah hal yang sangat mahal.

Tetapi ada jebakan dalam menggunakan kembali senyawa.
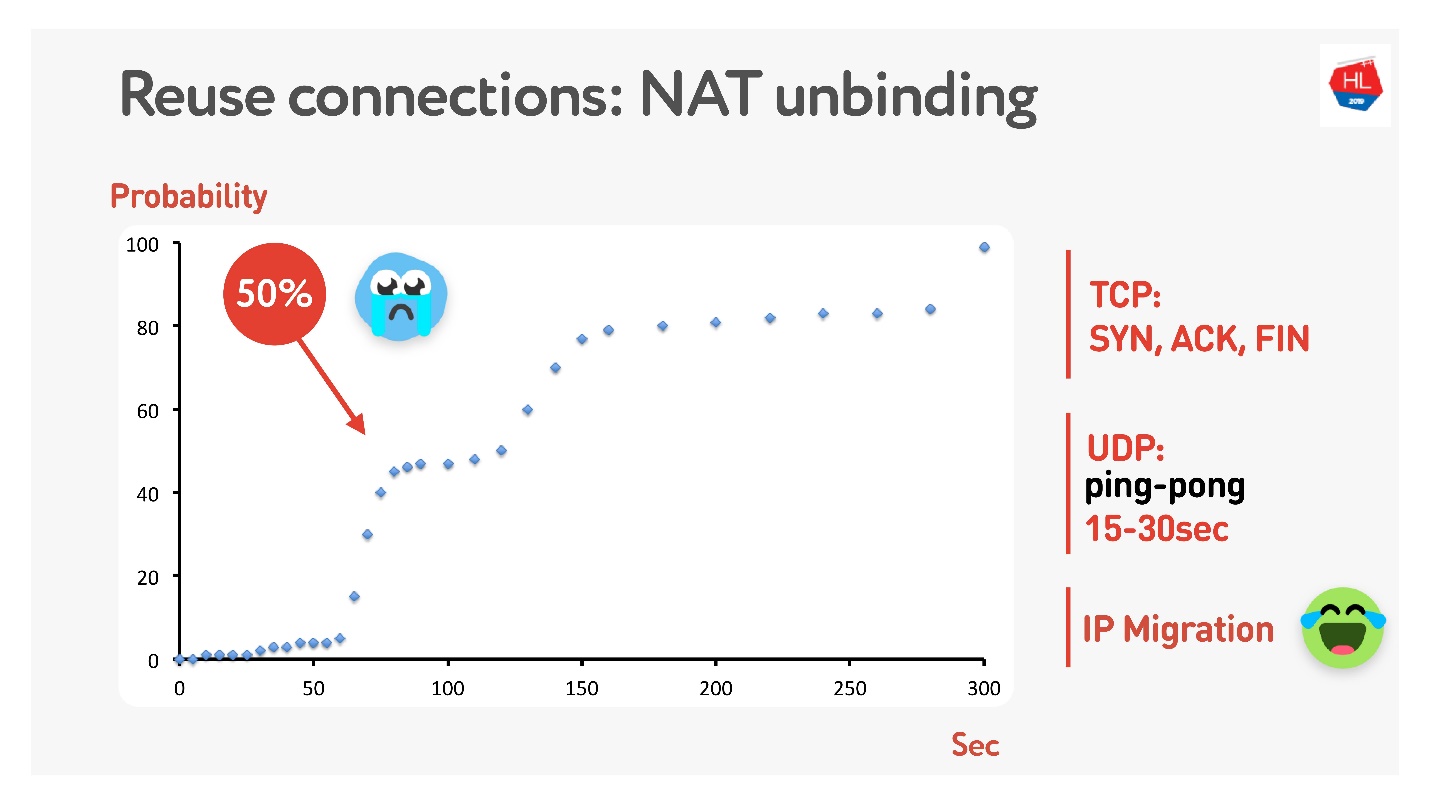
Kemungkinan besar, banyak orang ingat (jika tidak, lihat di
sini ) bahwa tidak semua orang memiliki alamat publik, tetapi ada NAT, yang biasanya menyimpan pemetaan untuk beberapa waktu di router rumah. Untuk TCP, jelas berapa banyak yang harus disimpan, tetapi untuk UDP tidak jelas. NAT beroperasi pada batas waktu, jika Anda mengukur batas waktu ini dengan hati-hati, kami mendapatkan bahwa dalam sekitar 15-30 detik lebih dari 50% koneksi akan mulai gagal.
Tidak apa-apa - kami akan membuat paket ping-pong selama 15 detik. Untuk kasus ketika koneksi masih terputus, ada Migrasi IP, yang murah memungkinkan Anda untuk mengubah port pada router.
Paket mondar-mandir
Ini adalah hal yang sangat penting jika Anda melakukan protokol UDP Anda.

Jika sangat sederhana, semakin lama Anda terus mengirim paket ke jaringan, semakin besar kemungkinan hilangnya paket. Jika Anda memfilter paket, maka packet loss akan lebih rendah.
Ada banyak teori berbeda tentang bagaimana ini bekerja, tetapi saya suka yang ini.
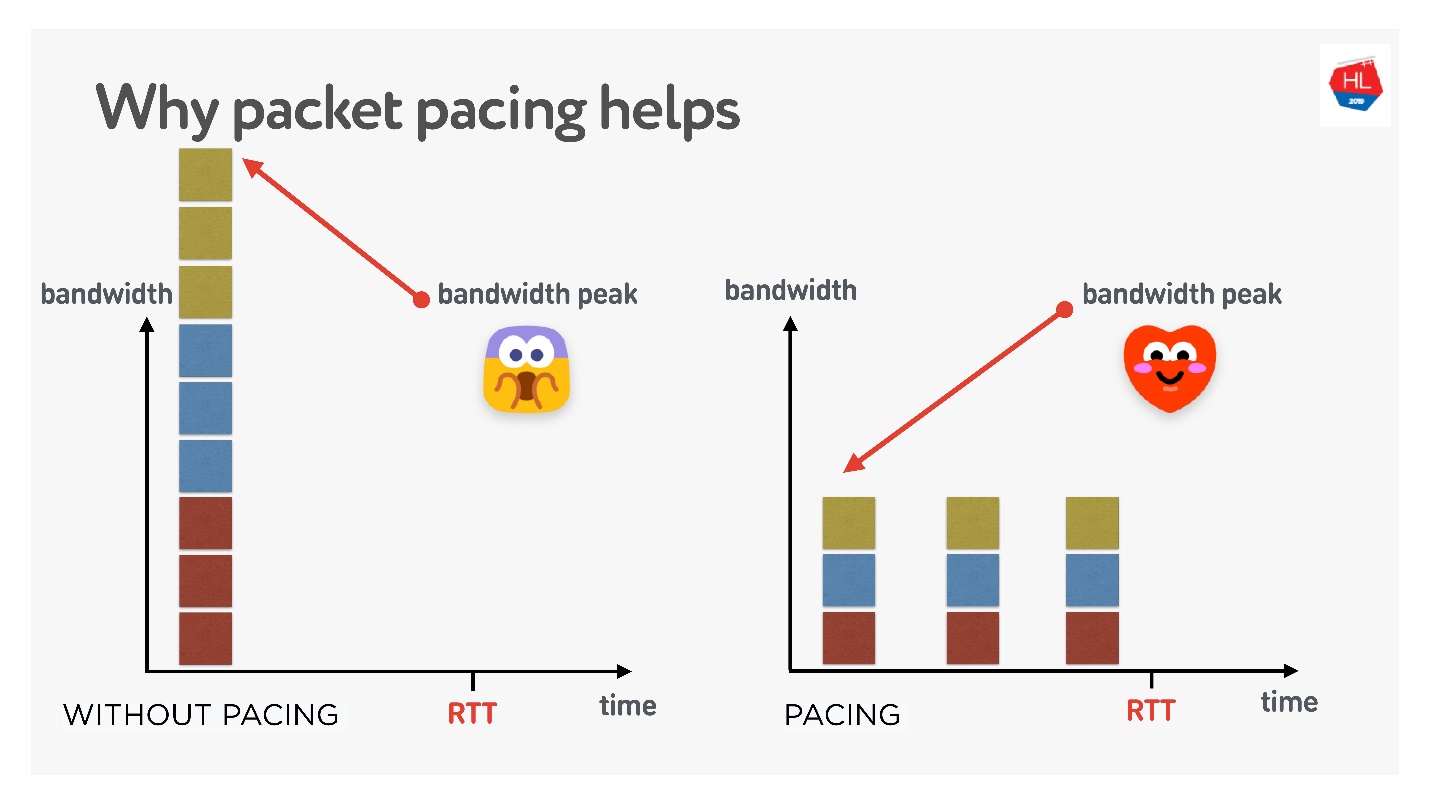
Ada 3 koneksi yang dibuat sekaligus. Anda memiliki jendela awal yang disebut - 10 paket yang dibuat pada saat yang sama. Tentu saja, bandwidth mungkin tidak cukup pada saat ini. Tetapi jika Anda hati-hati mendistribusikannya, pisahkan, maka semuanya akan baik-baik saja, seperti pada gambar yang tepat.
Dengan demikian, jika Anda menetapkan tingkat seragam untuk mengirim paket, menipiskannya, maka probabilitas bahwa akan ada buffer overflow satu kali menjadi lebih rendah. Ini tidak terbukti, tetapi secara teori ternyata seperti ini.

Saat Anda perlu memotong paket (lakukan mondar-mandir):
- Saat Anda membuat jendela.
- Ketika Anda memperbesar jendela, misalnya, disarankan untuk menambahkan paket sebanyak yang dapat dikirim untuk RTT / 2. Ini tidak akan menurunkan waktu pengiriman, tetapi mengurangi kehilangan paket.
- Dalam kasus kehilangan kemacetan, untuk mengurangi jendela Anda perlu mengolesi paket lebih banyak lagi. 4/5 RTT adalah sosok yang dipilih secara empiris.
MTU
Saat menulis protokol UDP Anda, pastikan untuk mengingat tentang MTU. MTU adalah ukuran data yang dapat Anda teruskan.
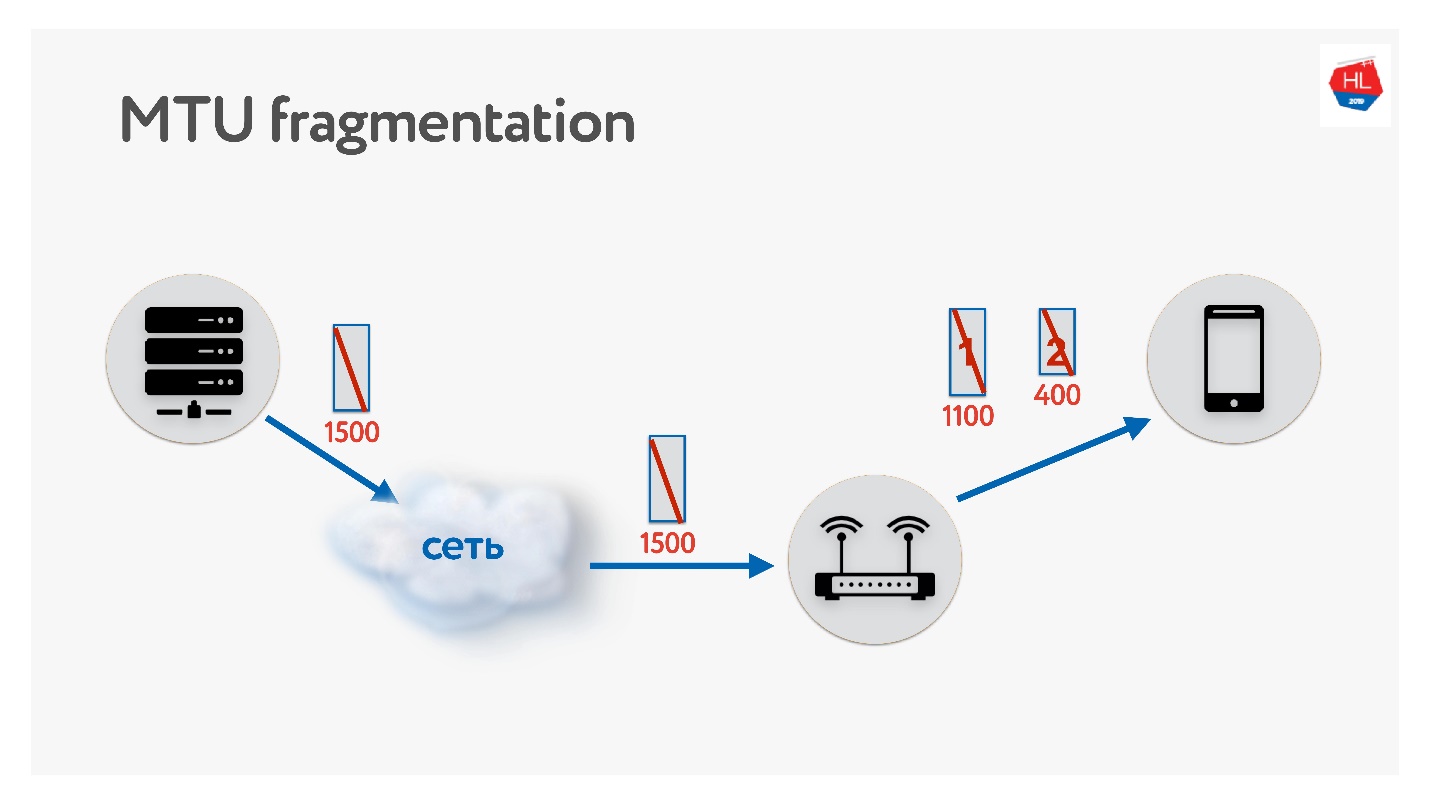
Kami mengirim paket dari server ke klien, misalnya, dengan ukuran 1500. Jika ada router di jalur yang tidak mendukung ukuran MTU ini, itu akan memecahnya. Satu-satunya masalah fragmentasi adalah bahwa jika satu paket hilang, keduanya akan hilang, dan semua ini harus ditransmisikan ulang. Oleh karena itu, TCP memiliki algoritma untuk menentukan MTU - PMTU.

Setiap router melihat MTU antarmuka-nya, mengirimkannya ke satu klien, yang lain mengirimkannya ke kliennya, semua orang tahu berapa banyak MTU yang mereka miliki di klien. Kemudian fragmentasi dilarang oleh bendera dan paket ukuran MTU dikirim. Jika saat ini seseorang di dalam jaringan menyadari bahwa ia memiliki lebih sedikit MTU, maka melalui ICMP ia akan berkata: "Maaf, paket itu hilang karena fragmentasi diperlukan" dan menunjukkan ukuran MTU. Kami akan mengubah ukuran ini dan melanjutkan pengiriman. Dalam kasus terburuk, overhead kecil kami adalah RTT / 2. Ini dalam TCP.
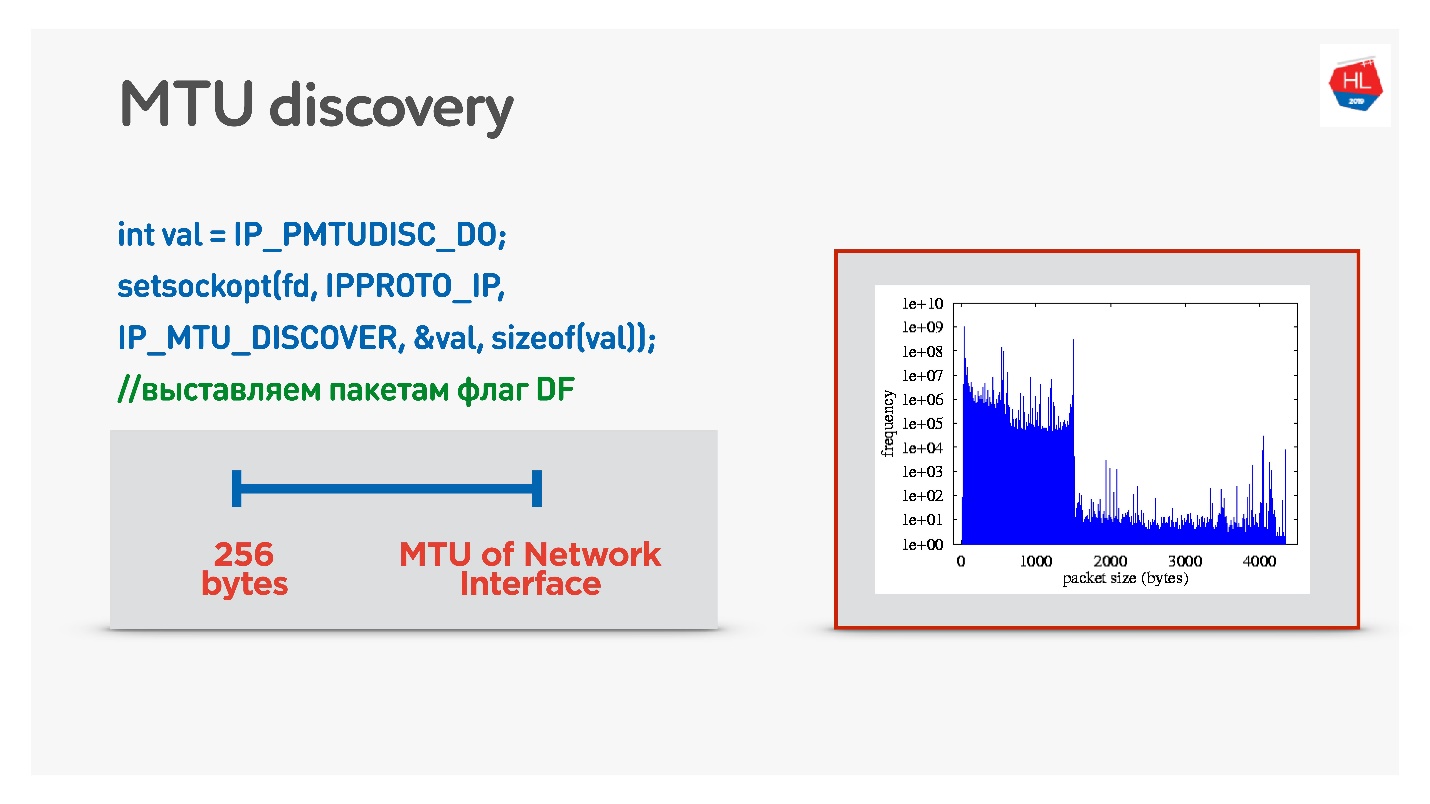
Jika di UDP Anda tidak ingin repot dengan ICMP, maka Anda dapat melakukan hal berikut: izinkan fragmentasi saat mengirim data normal. Yaitu, untuk mengirim paket terfragmentasi - biarkan mereka bekerja. Dan secara paralel untuk memulai proses yang melarang fragmentasi, pencarian biner akan memilih MTU optimal, yang kemudian akan kita buka. Ini tidak sepenuhnya efektif, karena pada awalnya MTU akan terasa hangat.
Opsi yang lebih rumit adalah melihat distribusi MTU di antara klien seluler.

Dari semua klien, kami mengirim paket dengan berbagai ukuran dengan larangan fragmentasi. Artinya, jika paket tidak mencapai, itu akan turun, dan MTU terkecil harus mencapai 100%. Tetapi ada paket kecil yang hilang, jadi ada dua slide pada grafik:
- 1350 byte - alih-alih 98%, kami mendapatkan pengiriman 95% segera.
- 1500 byte - MTU, setelah itu sudah 80% klien tidak akan menerima paket seperti itu.
Bahkan, kita dapat mengatakan ini: kita mengabaikan 1-2% dari pelanggan kita, membiarkan mereka hidup dengan paket yang terfragmentasi. Tetapi kita akan segera mulai dari apa yang kita butuhkan - ini dari 1350.
Koreksi kesalahan (SACK, NACK, FEC)
Jika Anda membuat protokol, Anda perlu memperbaiki kesalahan. Jika paket tidak ada (ini normal untuk jaringan nirkabel), itu perlu dipulihkan.
Dalam kasus paling sederhana (lebih detail di
sini ), ada relay melalui Retransmit Time Out (RTO). Jika paket tidak ada, tunggu waktu pengiriman ulang dan kirim lagi.
Algoritma selanjutnya adalah
Fast retransmit . Ini semua adalah algoritma TCP, tetapi mereka dapat dengan mudah dipindahkan ke UDP.
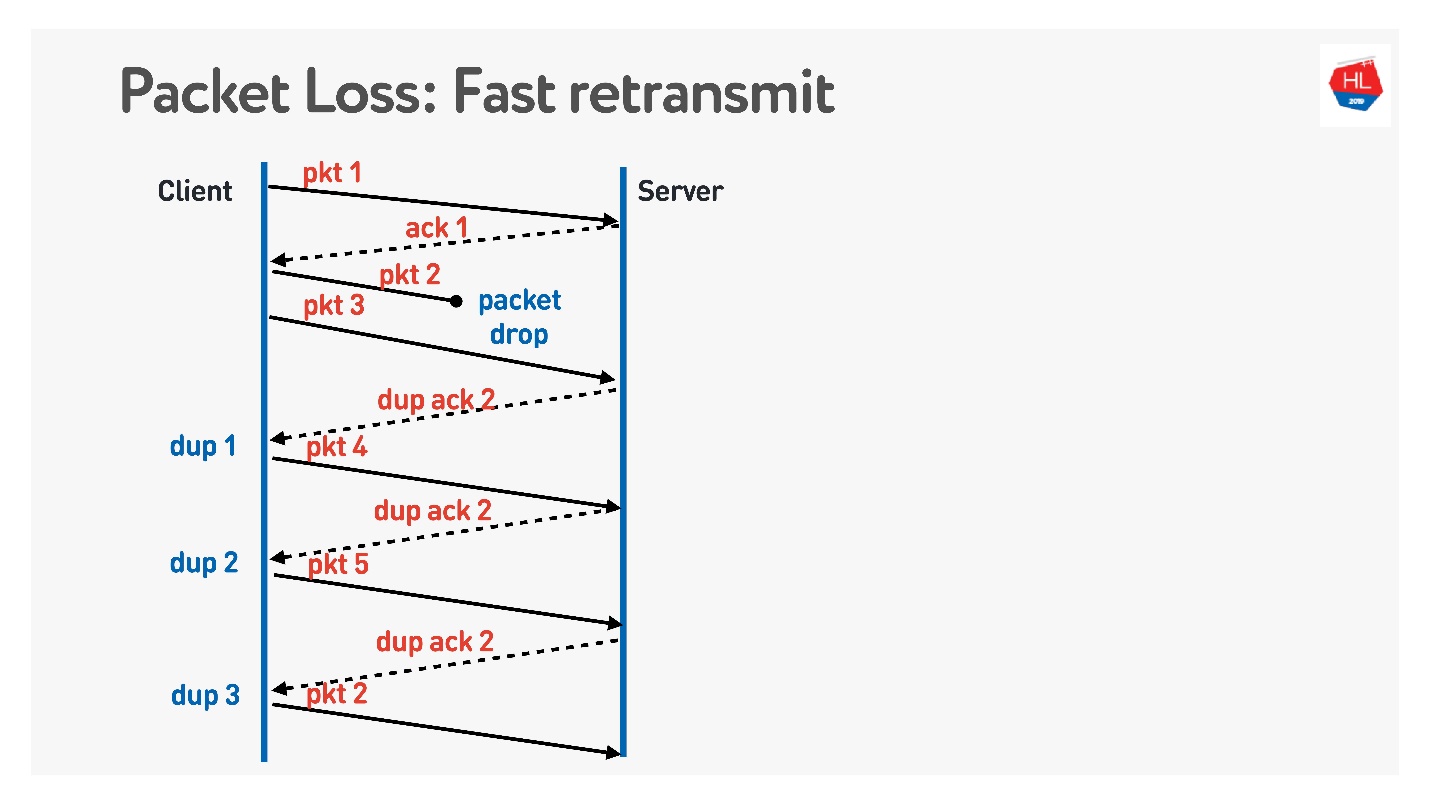
Ketika paket hilang, kami terus mengirim - ada pengiriman paket lain. Pada saat ini, server mengatakan bahwa ia menerima paket berikutnya, tetapi tidak ada yang sebelumnya. Untuk melakukan ini, ia membuat pernyataan yang rumit, yang sama dengan nomor paket +1, dan menetapkan flag ack duplikat. Dia mengirim dup ack demikian, dan pada yang ketiga kita biasanya mengerti bahwa paket telah hilang dan mengirimkannya kembali.
Apa lagi yang ingin Anda lakukan berkelas, apa yang tidak ada dalam TCP dan apa yang mereka usulkan untuk dilakukan di UDP adalah
Forward Error Correction .

Tampaknya jika kita tahu bahwa paket mungkin hilang, kita dapat mengambil satu set paket, menambahkan paket XOR ke dalamnya dan memperbaiki masalah tanpa transmisi ulang tambahan segera pada klien saat menerima data. Tetapi ada masalah jika beberapa paket hilang. Tampaknya itu bisa diselesaikan melalui perlindungan paritas, Reed-Solomon, dll.
Kami mencobanya dengan cara ini, ternyata ternyata paket-paket itu menghilang dalam bundel.
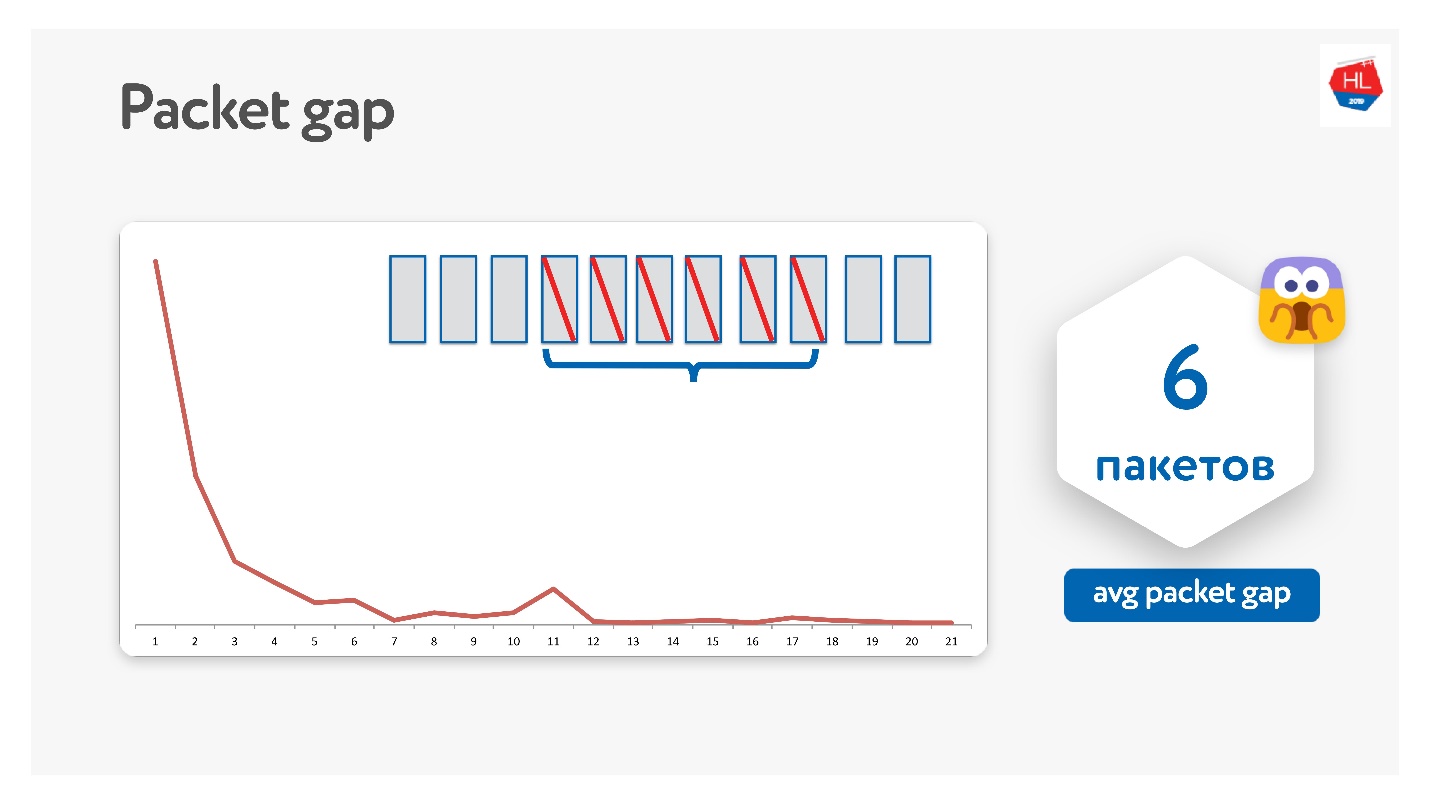
Kesenjangan paket rata-rata menjadi 6. Ini adalah celah paket yang sangat tidak nyaman - Anda memerlukan banyak kode koreksi kesalahan. Pada saat yang sama, ada semacam puncak di 11 - saya tidak tahu mengapa, tetapi paket-paket kadang-kadang menghilang dalam paket 11. Karena celah paket ini, ini tidak berfungsi.
Google juga mencoba ini, semua orang memimpikan FEC, tetapi sejauh ini belum ada yang berhasil.
Ada opsi lain ketika FEC dapat membantu.

Selain mentransmisikan kembali melalui Retransmit Time Out, Fast Retransmit, ada juga
probe kehilangan ekor . Ini adalah hal seperti itu ketika Anda mengirim data, dan ekornya hilang. Artinya, Anda mengirim bagian dari data, mengirim paket kelima - sudah tiba. Kemudian paket-paket mulai menghilang, misalnya, karena jaringan gagal. Paket hilang, menghilang, dan Anda menerima pemberitahuan hanya untuk paket kelima.
Untuk memahami apakah data ini telah mencapai, setelah beberapa saat Anda mulai melakukan TLP (probe kehilangan ekor), tanyakan apakah akhirnya diterima. Faktanya adalah bahwa transfer data telah berakhir, dan Anda tidak mengirim apa pun, maka Fast Retransmit tidak akan berfungsi. Untuk mengatasinya, lakukan TLP.
Anda dapat menambahkan FEC ke TLP. Anda dapat melihat semua paket yang tidak datang, menghitung paritasnya dan mengirim TLP dengan beberapa paket paritas.
Ini semua keren, sepertinya berhasil. Tapi ada masalah seperti itu.
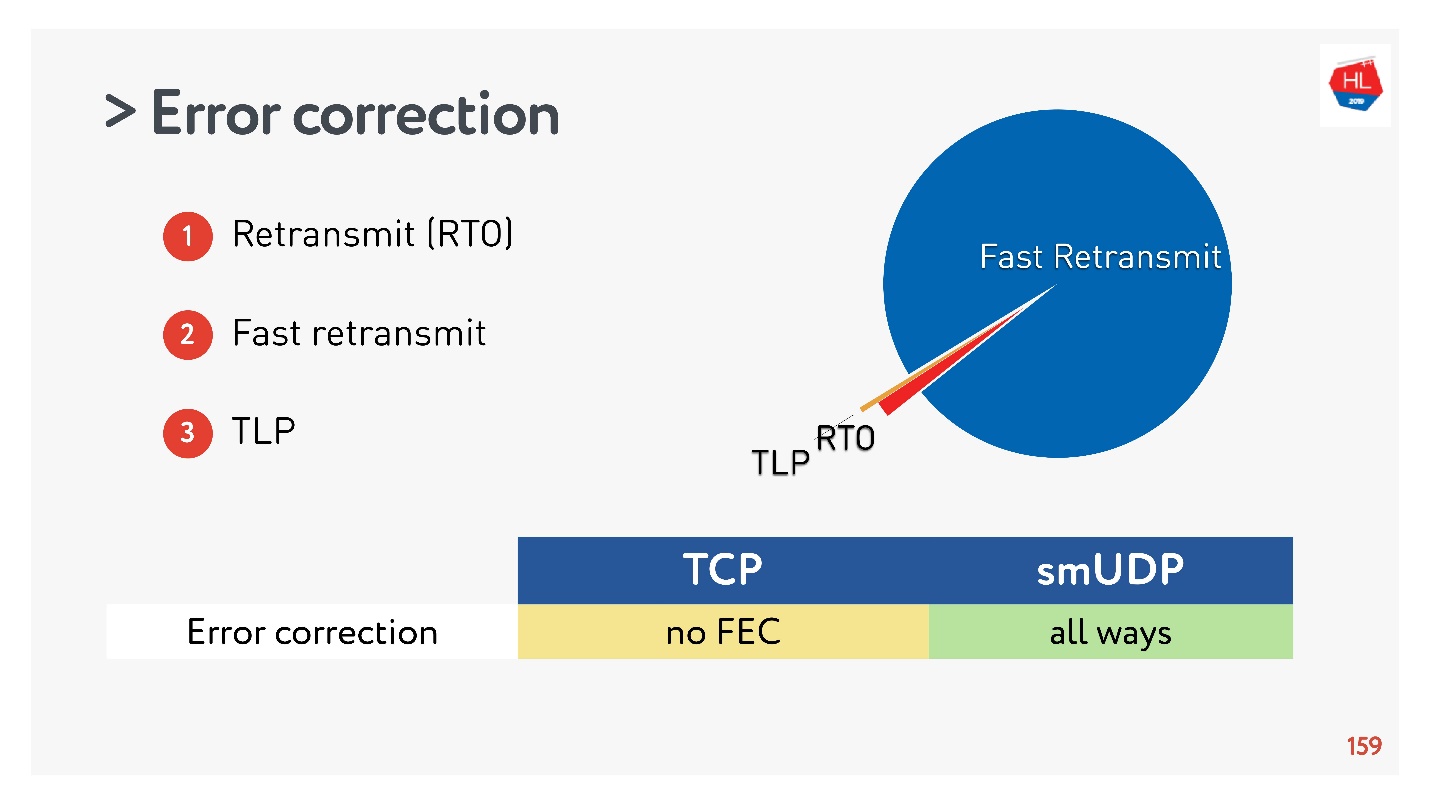
Kami mengumpulkan statistik, dan ternyata 98% kesalahan diperbaiki melalui Fast Retransmit. Sisanya diperbaiki melalui Retransmit Time Out, dan kurang dari 1% melalui TLP. Jika Anda memperbaiki sesuatu yang lain FEC, itu akan kurang dari 0,5%.
TCP tidak mendukung FEC. Dalam UDP tidak sulit untuk melakukan ini, tetapi dalam kasus umum, algoritma pemulihan TCP standar sudah cukup.
Performa
Adalah mungkin untuk tidak merusak kinerja dengan membandingkan TCP dengan UDP.
TCP adalah protokol yang sangat lama dengan banyak optimasi yang berbeda, misalnya, LSO (big segment offload) dan zerocopy. Sekarang untuk UDP semuanya tidak tersedia. Oleh karena itu, kinerja UDP hanya 20% relatif terhadap TCP dari server yang sama. Tetapi sudah ada solusi siap pakai (
UDP GSO ,
zerocopy ) yang memungkinkan Linux mendukung hal ini.
Masalah utama yang mendukung pengoptimalan untuk zerocopy dan LSO adalah bahwa pacing hilang.

Waktu ke pasar atau apa yang membunuh TCP
Baru-baru ini, ketika jaringan nirkabel seluler menjadi populer, banyak standar TCP yang berbeda muncul: TLP, TFO, kontrol Congestion baru, RACK, BBR dan banyak lagi.

Tetapi masalah utama adalah banyak dari mereka tidak diimplementasikan, karena TCP dikatakan keras. Dalam banyak kasus, operator melihat paket TCP dan berharap dapat melihat apa yang mereka harapkan. Karena itu, sangat sulit untuk berubah.
Selain itu, klien seluler diperbarui untuk waktu yang lama, dan kami tidak dapat mengirimkan pembaruan ini. Jika Anda melihat pembaruan terbaru apa saja yang tersedia di klien, dan apa yang ada di server, Anda dapat mengatakan bahwa hampir tidak ada apa-apa di klien.
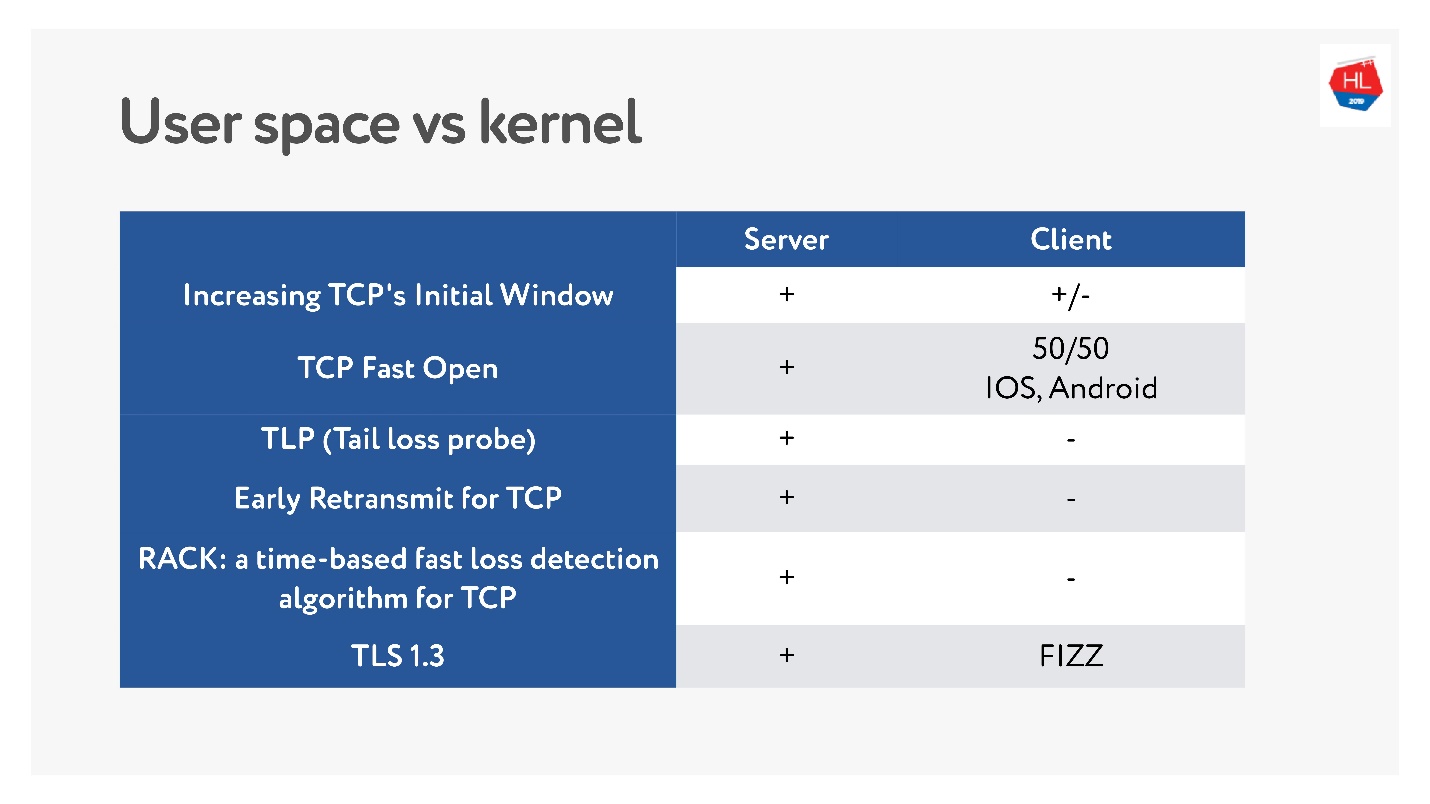
Oleh karena itu, keputusan untuk menulis protokol di ruang pengguna, setidaknya selama Anda mengakumulasikan semua fitur ini, sepertinya tidak terlalu buruk.

Dengan TCP, fitur telah bergulir selama bertahun-tahun. Untuk protokol UDP Anda, Anda dapat memutakhirkan versi secara harfiah dalam satu pembaruan klien dan server. Tetapi Anda perlu menambahkan versi negosiasi.
TCP vs UDP buatan sendiri. Pertarungan terakhir
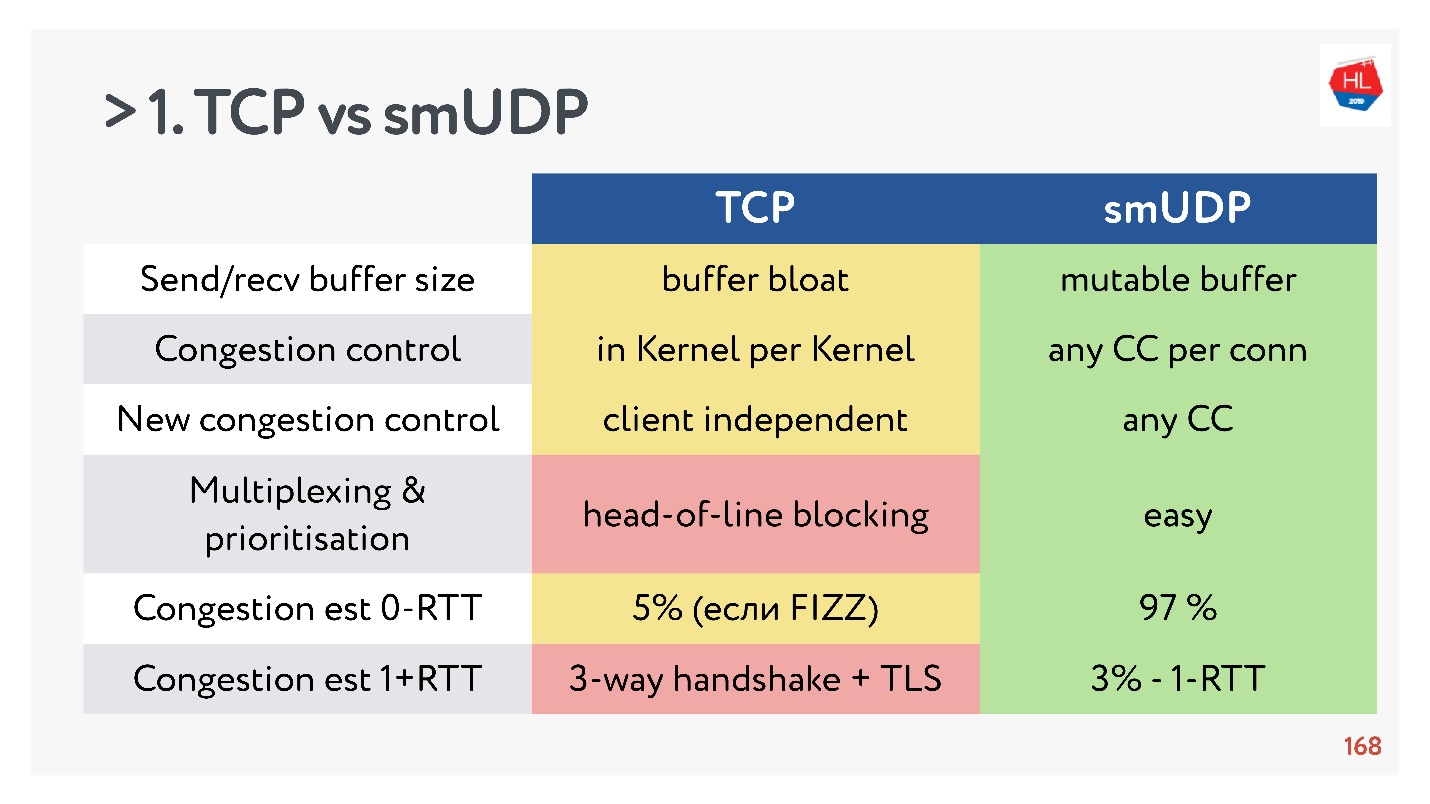
- Send / recv buffer: buffer yang dapat diubah dapat dilakukan untuk protokol Anda, akan ada masalah dengan buffer bloat dengan TCP.
- Kontrol kemacetan bisa Anda gunakan yang sudah ada. Di UDP mereka ada.
- Kontrol Congestion yang baru sulit untuk ditambahkan ke TCP, karena Anda perlu memodifikasi pengakuan, Anda tidak bisa melakukan ini pada klien.
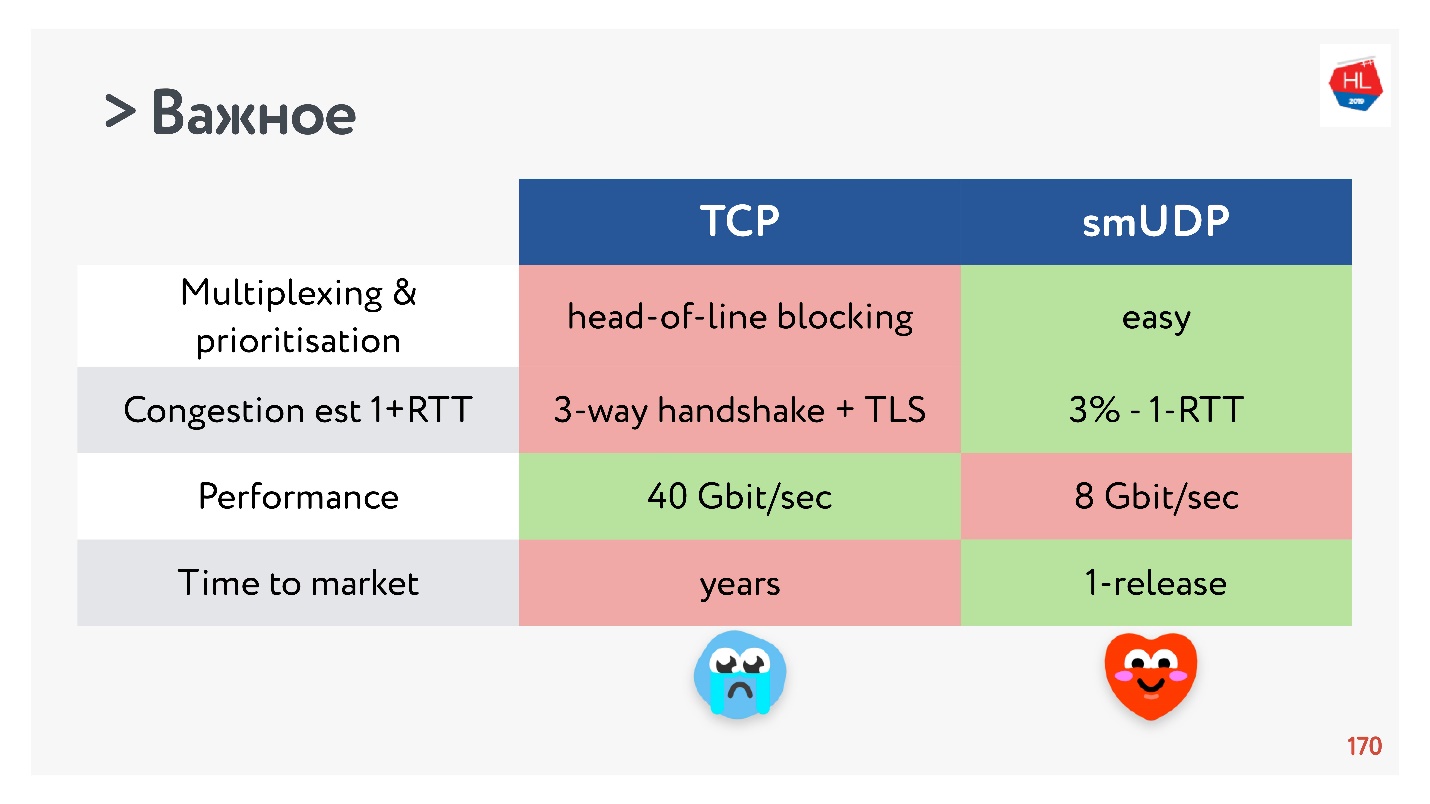
- Multiplexing adalah masalah kritis. Pemblokiran head-of-line terjadi, ketika Anda kehilangan suatu paket, Anda tidak bisa multiplex ke TCP. Oleh karena itu, HTTP2.0 over TCP seharusnya tidak memberikan peningkatan yang serius.
- Kasus ketika Anda bisa mendapatkan pengaturan koneksi untuk 0-RTT di TCP sangat jarang, dari urutan 5%, dan urutan 97% untuk UDP buatan sendiri.

- Migrasi IP bukanlah fitur yang begitu penting, tetapi dalam kasus langganan yang rumit dan status penyimpanan di server, itu pasti diperlukan, tetapi tidak diimplementasikan dalam TCP.
- Nat unbinding tidak mendukung UDP. Dalam hal ini, UDP sering perlu melakukan paket ping-pong.
- Paket pacing di UDP sederhana, sementara tidak ada optimasi, di TCP opsi ini tidak berfungsi.
- MTU dan koreksi kesalahan keduanya sebanding.
- Kecepatan TCP, tentu saja, lebih cepat daripada UDP sekarang, jika Anda mendistribusikan banyak lalu lintas. Tetapi beberapa optimasi membutuhkan waktu yang sangat lama untuk dicapai.
Jika Anda mengumpulkan semua yang paling penting, maka UDP, lebih mungkin, memiliki lebih banyak pro daripada kontra.
 Pilih UDP!
Pilih UDP!Menguji UDP buatan sendiri pada pengguna
Kami telah mengumpulkan bangku tes.
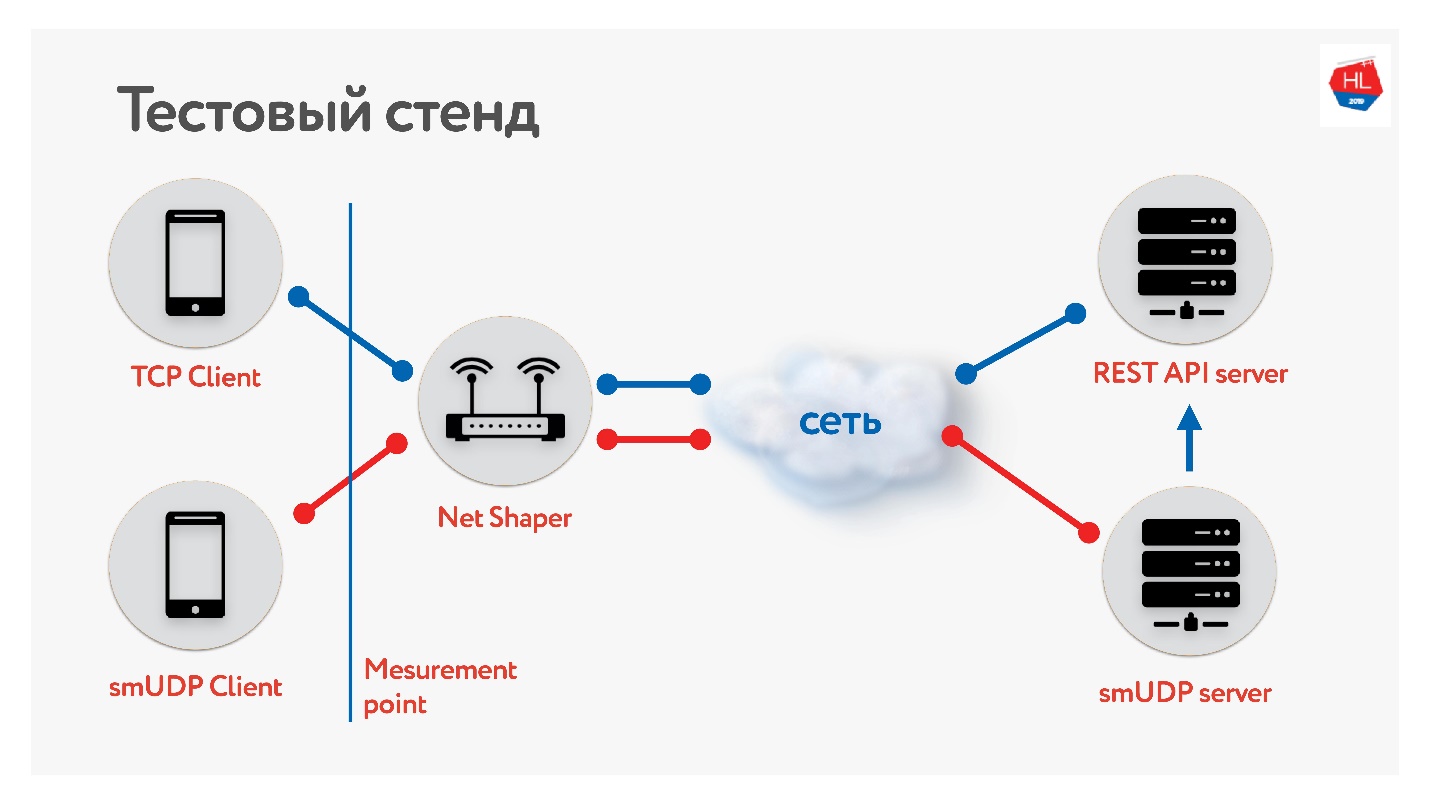
Ada klien di TCP dan UDP. Kami menormalkan lalu lintas melalui pembentuk bersih, dikirim ke Internet dan ke server. Satu layanan REST API, yang kedua dengan UDP. Dan UDP pergi ke REST API yang sama di dalam pusat data yang sama untuk memeriksa data. Kami mengumpulkan berbagai profil klien seluler kami dan
meluncurkan tes .

Mengukur rata-rata di atas portal, kami melihat bahwa kami dapat mengurangi waktu memanggil API sebesar 10%, gambar sebesar 7%. Aktivitas pengguna hanya tumbuh 1%, tapi kami tidak menyerah, kami pikir itu akan lebih baik.

Dalam hal beban, kami sekarang memiliki sekitar 10 juta pengguna di UDP buatan kami sendiri, lalu lintas hingga 80 Gb / s, 6 juta paket per detik dan 20 server semuanya melayani ini.
Daftar periksa UDP
Jika Anda akan menulis protokol Anda, Anda perlu daftar periksa:
- Mondar-mandir
- Penemuan MTU.
- Diperlukan perbaikan bug .
- Kontrol aliran dan kontrol kemacetan.
- Secara opsional Anda dapat mendukung Migrasi IP, TLP mudah.
Ingatlah bahwa salurannya asimetris, dan saat Anda menerima data dari server, unggahan Anda mungkin menganggur, coba gunakan.
QUIC
Tidak jujur mengatakan bahwa Google tidak melakukannya.

Ada protokol QUIC yang diterapkan Google di bawah HTTP 2.0, yang mendukung banyak hal yang sama.
Mengapa QUIC tidak begitu cepat
Ketika QUIC keluar, ada banyak kebencian tentang fakta bahwa Google mengatakan bahwa semuanya bekerja lebih cepat, dan "Saya mengukurnya di rumah menggunakan komputer - kerjanya lebih lambat."
 Artikel
Artikel ini
memiliki banyak gambar dan pengukuran.
Nah, ternyata kita melakukan semua ini dengan sia-sia, apakah orang mengukur untuk kita? Ada pengukuran rumah nyata, bahkan dengan contoh kode.

Bahkan, tidak akan ada peningkatan sampai Anda memaralelkan permintaan, bekerja di jaringan nyata, dan sampai paket hilang dibagi menjadi kehilangan kemacetan dan kehilangan acak. Kita membutuhkan persaingan nyata dari jaringan nyata.
Tetapi ada yang positif, kata mereka, QUIC tidak lebih baik atau lebih buruk. Dengan demikian, dalam jaringan yang sempurna, QUIC berfungsi dengan baik.
Masa depan
Google baru-baru ini menamai HTTP 2.0 di atas QUIC HTTP 3, jangan bingung, karena HTTP 2.0 bisa di atas TCP dan di atas QUIC. Sekarang HTTP 3.
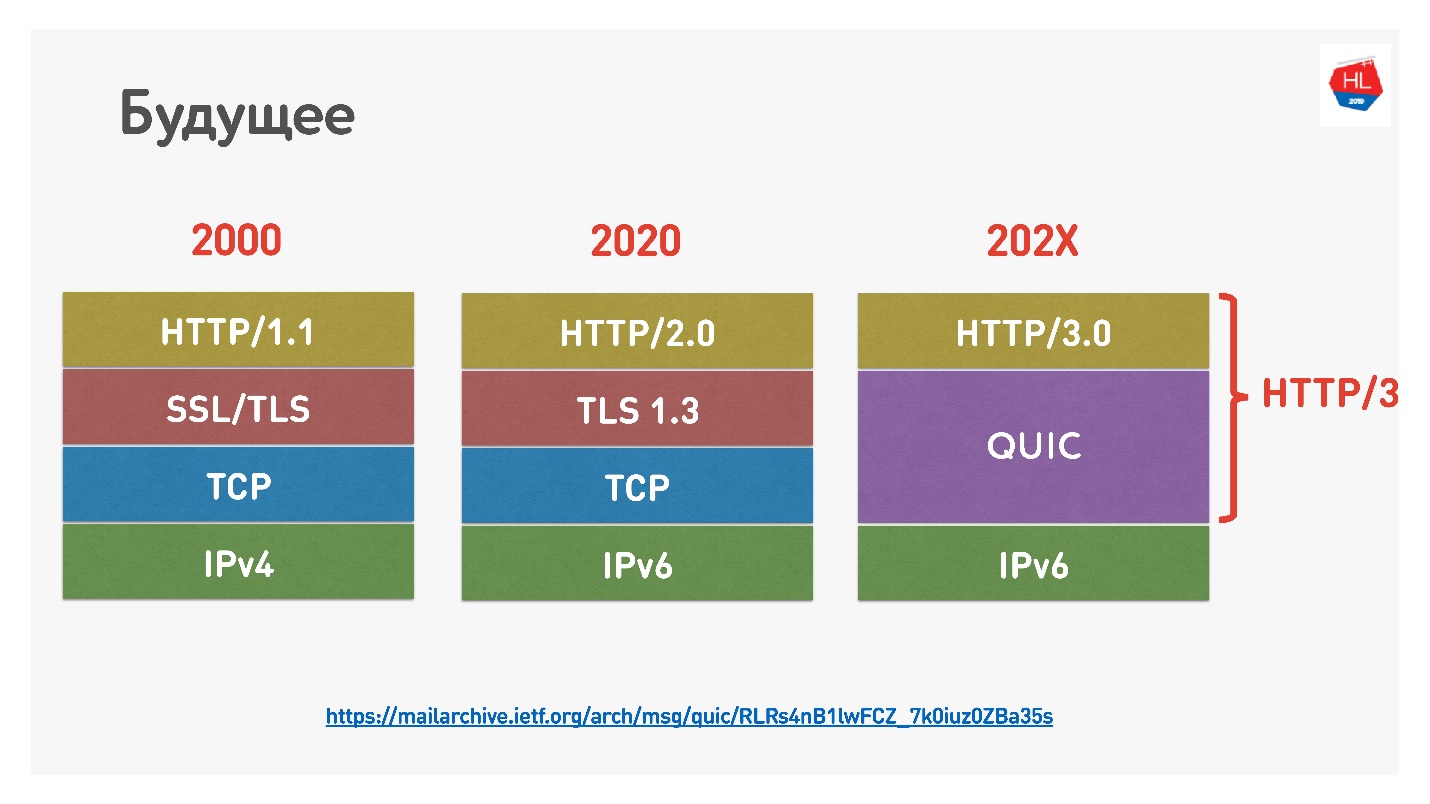
Ada juga
Google QUIC - ini QUIC, yang diterapkan di Chrome, dan iQUIC - QUIC standar. QUIC terstandarisasi tidak diterapkan di mana pun, server iQUIC standar tidak berjabat tangan dengan Google QUIC. Sekarang mereka berjanji untuk menyelesaikan masalah ini, dan segera akan tersedia.
QUIC ada di mana-mana
Jika Anda masih tidak percaya bahwa TCP sudah mati, maka saya akan memberi tahu Anda bahwa ketika Anda menggunakan Chrome, Android, dan segera iOS, dan pergi ke google, youtube dan sebagainya, maka Anda menggunakan QUIC dan UDP (
prooflink ).
QUIC sekarang adalah:
- 1,9% dari semua situs web;
- 12% dari semua lalu lintas;
- 30% dari lalu lintas video di jaringan seluler.
Bagaimana cara memeriksa bahwa Anda menggunakan QUIC jika Anda tidak percaya? Buka di Chrome Wireshark. Saya mencari iQUIC, saya belum menemukannya di mana pun, tetapi GQUIC terjadi.
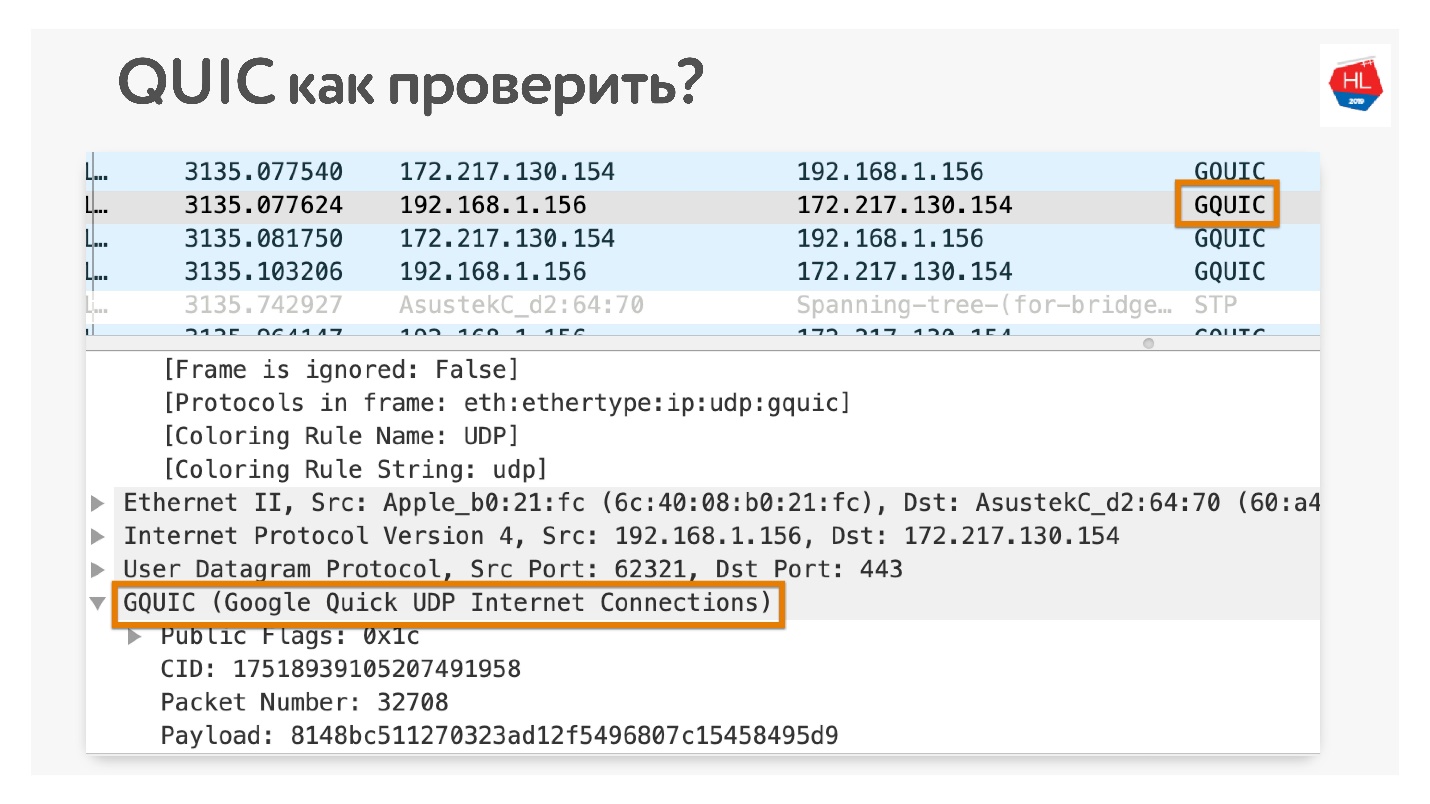
Anda juga dapat online di browser Anda dan juga melihat apa yang ada di GQUIC.

Beberapa lagi masa depan
Multipath menunggu kita segera.
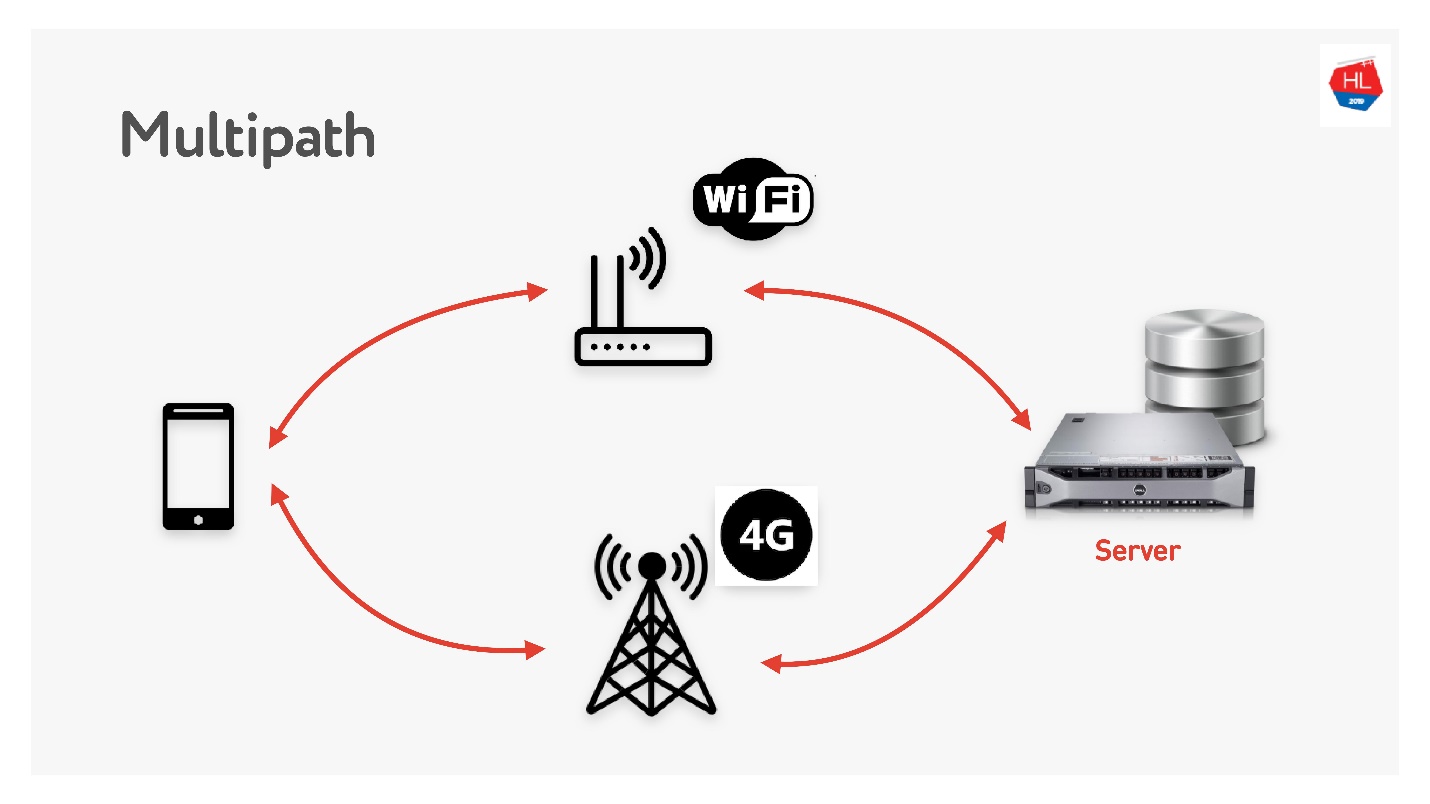
Saat Anda memiliki klien seluler yang memiliki Wi-Fi dan 3G, Anda dapat menggunakan kedua saluran. Multipath TCP sekarang dalam pengembangan dan akan segera tersedia di kernel Linux. Jelas, itu tidak akan menjangkau pelanggan segera, saya pikir itu bisa dilakukan pada UDP lebih cepat.
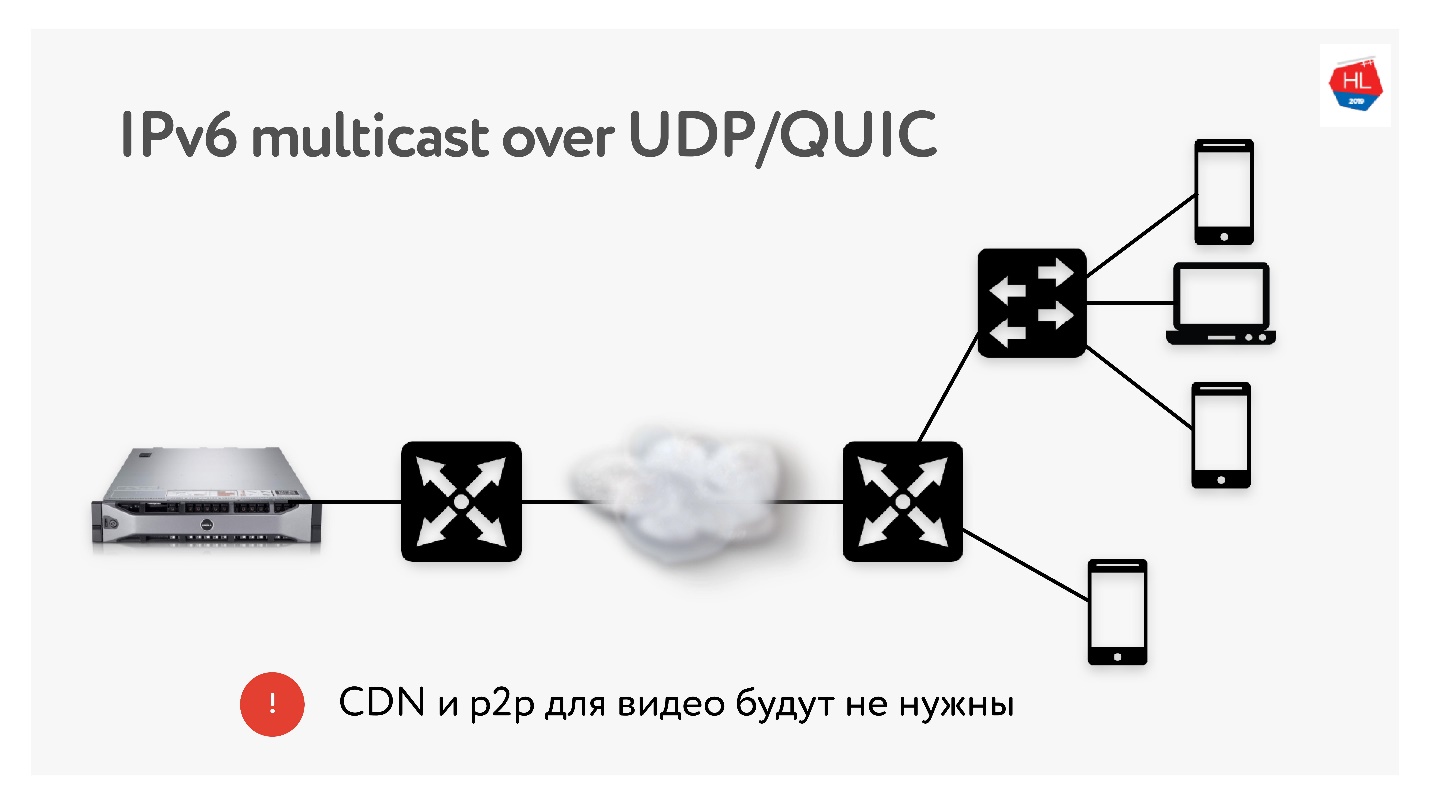
Karena kami melakukan banyak terjemahan masing-masing 3 TB, kami sangat sering menggunakan teknologi seperti distribusi CDN dan p2p, ketika konten yang sama perlu dikirim ke banyak pengguna di seluruh dunia.
Di IPv6 ada multicast dengan UDP, yang akan memungkinkan pengiriman paket ke beberapa pengguna yang berlangganan sekaligus. Oleh karena itu, saya berpikir bahwa teknologi CDN dan p2p tidak akan dibutuhkan dalam waktu dekat jika kami mengirimkan semua konten menggunakan multicast ke IPv6.
Kesimpulan
Saya harap Anda mengerti:
- Bagaimana jaringan benar-benar bekerja, dan TCP dapat diulangi melalui UDP dan dilakukan dengan lebih baik.
- TCP itu tidak terlalu buruk jika Anda mengkonfigurasinya dengan benar, tetapi itu benar-benar menyerah dan hampir tidak lagi berkembang.
- Jangan percaya pembenci UDP yang mengatakan mereka tidak akan bekerja di ruang pengguna. Semua masalah ini bisa diselesaikan. Cobalah - ini adalah masa depan yang dekat.
- Jika Anda tidak percaya, maka Anda dapat dan harus menyentuh jaringan dengan tangan Anda. Saya menunjukkan bagaimana hampir semuanya dapat diperiksa.
Anda membaca semuanya dan mencari tahu apa selanjutnya?
- Konfigurasikan protokol (TCP, UDP - tidak masalah) untuk situasi (profil jaringan + memuat profil).
- Gunakan resep TCP yang saya katakan: TFO, kirim / terima penyangga, TLS1.3, CC ...
- Buat protokol UDP Anda jika Anda memiliki sumber daya.
- Jika Anda telah melakukan UDP, periksa daftar periksa UDP bahwa Anda telah melakukan semua yang Anda butuhkan. Lupa omong kosong seperti mondar-mandir, itu tidak akan berhasil.
Jika Anda tidak memiliki sumber daya, siapkan infrastruktur Anda untuk QUIC. Cepat atau lambat dia akan mendatangimu.
Kami menentukan masa depan. Kami memutuskan protokol apa yang akan digunakan. Jika Anda ingin menggunakan QUIC - gunakan, jika Anda ingin UDP atau tetap menggunakan TCP - putuskan sendiri di masa depan.
Tautan yang bermanfaat
Hingga 7 September, Anda masih dapat mengirimkan aplikasi untuk Moscow HighLoad ++ dan membagikan bagaimana Anda mempersiapkan layanan Anda untuk beban tinggi. Tetapi program ini secara bertahap telah diisi, dari laporan Odnoklassniki telah diterima pada arsitektur baru grafik teman, tentang mengoptimalkan layanan hadiah untuk beban tinggi dan tentang apa yang harus dilakukan jika Anda telah mengoptimalkan semuanya dan data tidak mencapai pengguna dengan cukup cepat.