Selamat datang, Habr!
Pada suatu waktu, kami adalah orang pertama yang
memperkenalkan tema
Kafka ke pasar Rusia dan terus
memantau perkembangannya. Secara khusus, topik interaksi antara Kafka dan
Kubernetes tampak menarik bagi kami. Sebuah ulasan (dan agak hati-hati)
artikel tentang hal ini diterbitkan di blog perusahaan Confluent Oktober lalu, ditulis oleh Gwen Shapira. Hari ini kami ingin menarik perhatian Anda ke artikel April yang lebih baru oleh Johann Gyger, yang, meskipun bukan tanpa tanda tanya dalam judul, mempertimbangkan topik dengan cara yang lebih substantif, menyertai teks dengan tautan yang menarik. Mohon maafkan kami terjemahan gratis "chaos monkey" jika Anda bisa!
Pendahuluan
Kubernetes dirancang untuk menangani beban stateless. Biasanya, beban kerja tersebut disajikan dalam bentuk arsitektur layanan mikro, bebannya ringan, cocok untuk penskalaan horizontal, mematuhi prinsip-prinsip aplikasi 12-faktor, dan memungkinkan bekerja dengan pemutus sirkuit dan monyet kekacauan.
Kafka, yang terletak di sisi lain, pada dasarnya bertindak sebagai basis data terdistribusi. Jadi, ketika bekerja, Anda harus berurusan dengan kondisi tersebut, dan itu jauh lebih berat daripada layanan mikro. Kubernetes mendukung banyak stateful, tetapi seperti yang ditunjukkan Kelsey Hightower dalam dua tweetnya, mereka harus ditangani dengan hati-hati:
Tampaknya bagi sebagian orang bahwa jika Anda menggulung Kubernet ke beban stateful, itu berubah menjadi basis data yang dikelola sepenuhnya yang dapat bersaing dengan RDS. Ini tidak benar. Mungkin jika Anda hanya bekerja keras, mengacaukan komponen tambahan dan menarik tim insinyur-SRE, Anda dapat menginstal RDS di atas Kubernetes.
Saya selalu merekomendasikan bahwa setiap orang sangat berhati-hati saat meluncurkan muatan yang menjaga keadaan di Kubernetes. Sebagian besar dari mereka yang tertarik pada "bisakah saya menjalankan banyak stateful di Kubernetes" tidak memiliki pengalaman yang cukup bekerja dengan Kubernetes, dan seringkali dengan beban yang mereka tanyakan.
Jadi, haruskah saya menjalankan Kafka di Kubernetes? Counter-question: akankah Kafka bekerja lebih baik tanpa Kubernetes? Itulah mengapa saya ingin menekankan dalam artikel ini bagaimana Kafka dan Kubernet saling melengkapi, dan apa jebakan yang dapat terjadi ketika digabungkan.
Lead time
Mari kita bicara tentang hal dasar - lingkungan runtime itu sendiri
ProsesnyaBroker Kafka nyaman saat bekerja dengan CPU. TLS mungkin menimbulkan beberapa overhead. Pada saat yang sama, klien Kafka dapat memuat CPU lebih banyak jika mereka menggunakan enkripsi, tetapi ini tidak mempengaruhi broker.
MemoriBroker Kafka melahap ingatannya. Ukuran tumpukan JVM biasanya modis untuk membatasi 4-5 GB, tetapi Anda juga akan membutuhkan banyak memori sistem, karena Kafka menggunakan cache halaman dengan sangat aktif. Di Kubernetes, tentukan batas wadah untuk sumber daya dan permintaan dengan tepat.
Gudang dataPenyimpanan data dalam wadah bersifat sementara - data hilang saat dimulai ulang. Anda dapat menggunakan volume
emptyDir untuk data Kafka, dan efeknya akan serupa: data broker Anda akan hilang setelah selesai. Pesan Anda masih dapat disimpan di broker lain sebagai replika. Karena itu, setelah restart, broker yang gagal harus terlebih dahulu mereplikasi semua data, dan proses ini mungkin membutuhkan banyak waktu.
Inilah sebabnya mengapa penyimpanan data jangka panjang harus digunakan. Biarkan penyimpanan non-lokal jangka panjang dengan sistem file XFS atau, lebih tepatnya, ext4. Jangan gunakan NFS. Saya memperingatkan. Versi NFS v3 atau v4 tidak akan berfungsi. Singkatnya, broker Kafka akan berakhir jika tidak dapat menghapus direktori data karena masalah "pengubahan nama bodoh" yang relevan di NFS. Jika saya masih belum meyakinkan Anda,
baca artikel ini dengan sangat hati-hati. Gudang data harus non-lokal sehingga Kubernetes dapat lebih fleksibel memilih node baru setelah restart atau relokasi.
JaringanSeperti kebanyakan sistem terdistribusi, kinerja Kafka sangat tergantung pada latensi jaringan yang minimal dan bandwidth yang maksimum. Jangan mencoba menempatkan semua broker pada simpul yang sama, karena ini akan mengurangi ketersediaan. Jika simpul Kubernetes gagal, seluruh kluster Kafka juga gagal. Juga, jangan bubarkan kluster Kafka di seluruh pusat data. Hal yang sama berlaku untuk kluster Kubernetes. Kompromi yang baik dalam hal ini adalah memilih zona akses yang berbeda.
Konfigurasi
Manifesto umumSitus web Kubernetes memiliki
panduan yang sangat baik tentang cara mengkonfigurasi ZooKeeper menggunakan manifes. Karena ZooKeeper adalah bagian dari Kafka, dari sinilah nyaman untuk mulai berkenalan dengan konsep Kubernet apa yang berlaku di sini. Setelah Anda mengetahuinya, Anda dapat menggunakan konsep yang sama dengan cluster Kafka.
- Sub : sub adalah unit terkecil yang bisa digunakan di Kubernetes. Pod berisi beban kerja Anda, dan pod itu sendiri terkait dengan proses di cluster Anda. Sebuah perapian berisi satu atau lebih wadah. Setiap server ZooKeeper di ensemble dan masing-masing broker di cluster Kafka akan bekerja dalam pendekatan terpisah.
- StatefulSet : StatefulSet adalah objek Kubernetes yang bekerja dengan banyak beban kerja stateful, yang memerlukan koordinasi. StatefulSet memberikan jaminan terkait pemesanan perapian dan keunikannya.
- Layanan tanpa kepala : Layanan memungkinkan Anda melepaskan pod dari klien menggunakan nama logis. Kubernetes dalam hal ini bertanggung jawab untuk menyeimbangkan beban. Namun, ketika mempertahankan beban kerja stateful, seperti dalam kasus ZooKeeper dan Kafka, klien perlu bertukar informasi dengan contoh spesifik. Di sinilah layanan tanpa kepala sangat berguna: dalam hal ini, klien masih akan memiliki nama logis, tetapi Anda tidak harus langsung masuk ke bawah.
- Volume untuk penyimpanan jangka panjang : volume ini diperlukan untuk konfigurasi penyimpanan jangka panjang non-lokal blok, yang disebutkan di atas.
Yolean menyediakan serangkaian manifes komprehensif yang memudahkan untuk memulai dengan Kafka di Kubernetes.
Grafik helmHelm adalah manajer paket untuk Kubernetes, yang dapat dibandingkan dengan manajer paket untuk OS, seperti yum, apt, Homebrew atau Chocolatey. Menggunakannya adalah mudah untuk menginstal paket perangkat lunak yang telah ditentukan yang dijelaskan dalam diagram Helm. Diagram Helm yang dipilih dengan baik memfasilitasi tugas yang sulit: cara mengkonfigurasi dengan benar semua parameter untuk menggunakan Kafka di Kubernetes. Ada beberapa diagram Kafka: yang resmi
dalam keadaan inkubator , ada satu dari
Confluent , satu lagi dari
Bitnami .
OperatorKarena Helm memiliki kelemahan tertentu, alat lain semakin populer: operator Kubernetes. Operator tidak hanya mengemas perangkat lunak untuk Kubernetes, tetapi juga memungkinkan Anda untuk menggunakan perangkat lunak tersebut dan juga mengelolanya.
Daftar
operator hebat menyebutkan dua operator untuk Kafka. Salah satunya adalah
Strimzi . Dengan bantuan Strimzi, mudah untuk meningkatkan cluster Kafka dalam hitungan menit. Hampir tidak ada konfigurasi yang diperlukan, selain itu, operator itu sendiri menyediakan beberapa fitur yang bagus, misalnya, enkripsi TLS dari tipe "point-to-point" di dalam cluster. Confluent juga menyediakan
operatornya sendiri .
PerformaSangat penting untuk menguji kinerja dengan memasok instance Kafka yang diinstal dengan titik kontrol. Tes-tes ini akan membantu Anda mengidentifikasi potensi kemacetan sebelum masalah dimulai. Untungnya, Kafka sudah menyediakan dua alat pengujian kinerja:
kafka-producer-perf-test.sh dan
kafka-consumer-perf-test.sh . Gunakan secara aktif. Untuk referensi, Anda dapat merujuk ke hasil yang dijelaskan dalam
posting ini oleh Jay Kreps, atau gunakan ulasan Stéphane Maarek Amazon MSK ini.
Operasi
PemantauanTransparansi dalam sistem sangat penting - jika tidak, Anda tidak akan mengerti apa yang terjadi di dalamnya. Saat ini ada toolkit solid yang menyediakan pemantauan berdasarkan metrik dalam gaya cloud asli. Dua alat yang populer untuk tujuan ini adalah Prometheus dan Grafana. Prometheus dapat mengumpulkan metrik dari semua proses Java (Kafka, Zookeeper, Kafka Connect) menggunakan eksportir JMX - dengan cara paling sederhana. Jika Anda menambahkan metrik cAdvisor, Anda dapat lebih memahami bagaimana sumber daya digunakan di Kubernetes.
Strimzi memiliki contoh dasbor Grafana yang sangat nyaman untuk Kafka. Ini memvisualisasikan metrik kunci, misalnya, tentang sektor yang tidak direplikasi atau yang sedang offline. Semuanya sangat jelas di sana. Metrik ini dilengkapi dengan informasi tentang pemanfaatan dan kinerja sumber daya, serta indikator stabilitas. Dengan demikian, Anda mendapatkan pemantauan dasar cluster Kafka tanpa alasan!
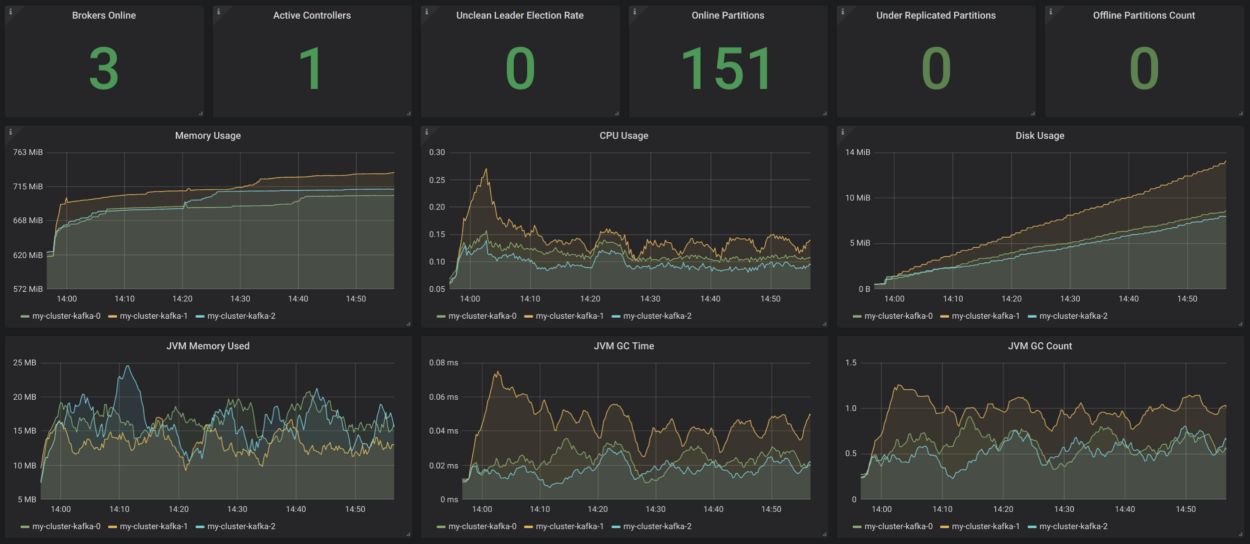
Sumber:
strimzi.io/docs/master/#kafka_dashboardAkan lebih baik untuk melengkapi semua ini dengan pemantauan pelanggan (metrik untuk konsumen dan produsen), serta pemantauan lag (untuk ini ada
Burrow ) dan pemantauan ujung-ke-ujung - untuk ini, gunakan
Monitor Kafka .
PenebanganPenebangan adalah tugas penting lainnya. Pastikan bahwa semua kontainer di instalasi Kafka Anda dicatat di
stdout dan
stderr , dan pastikan bahwa kluster Kubernetes Anda mengumpulkan semua log dalam infrastruktur
logging pusat, seperti
Elasticsearch .
Pemeriksaan KesehatanKubernetes menggunakan probe liveness dan readiness untuk memeriksa apakah pod Anda berfungsi dengan baik. Jika tes langsung gagal, Kubernetes akan menghentikan wadah ini, dan kemudian secara otomatis memulai ulang jika kebijakan mulai ulang diatur sesuai. Jika pemeriksaan ketersediaan gagal, maka Kubernetes mengisolasi ini di bawah dari layanan permintaan. Jadi, dalam kasus seperti itu, intervensi manual tidak lagi diperlukan sama sekali, dan ini merupakan nilai tambah yang besar.
Meluncurkan pembaruanStatefulSet mendukung pembaruan otomatis: ketika memilih strategi RollingUpdate, masing-masing di bawah Kafka akan diperbarui secara bergantian. Dengan cara ini, downtime dapat dikurangi menjadi nol.
ScalingMelakukan scaling a Kafka cluster bukanlah tugas yang mudah. Namun, di Kubernetes sangat mudah untuk menskala pod ke sejumlah replika, yang berarti Anda dapat secara deklaratif mengidentifikasi sebanyak mungkin pialang Kafka yang Anda inginkan. Yang paling sulit dalam hal ini adalah penugasan kembali sektor setelah penskalaan atau sebelum penskalaan. Sekali lagi, Kubernetes akan membantu Anda dengan tugas ini.
AdministrasiTugas-tugas yang berkaitan dengan mengelola cluster Kafka Anda, khususnya, membuat topik dan menugaskan kembali sektor, dapat dilakukan dengan menggunakan skrip shell yang ada, membuka antarmuka baris perintah di pod Anda. Namun, solusi ini tidak terlalu cantik. Strimzi mendukung mengelola topik menggunakan operator lain. Ada sesuatu untuk dimodifikasi di sini.
Cadangkan & KembalikanSekarang ketersediaan Kafka akan tergantung pada ketersediaan Kubernetes. Jika kluster Kubernet Anda jatuh, maka dalam kasus terburuk, kluster Kafka juga jatuh. Di bawah hukum Murphy, ini akan terjadi dan Anda akan kehilangan data. Untuk mengurangi risiko semacam ini, miliki konsep cadangan yang baik. Anda dapat menggunakan MirrorMaker, opsi lain adalah menggunakan S3 untuk ini, seperti yang dijelaskan dalam
posting ini dari Zalando.
Kesimpulan
Ketika bekerja dengan kelompok Kafka kecil atau menengah, sangat disarankan untuk menggunakan Kubernet, karena memberikan fleksibilitas tambahan dan menyederhanakan pekerjaan dengan operator. Jika Anda memiliki persyaratan non-fungsional yang sangat serius terkait latensi dan / atau throughput, maka mungkin lebih baik untuk mempertimbangkan beberapa opsi penempatan lainnya.