Apakah menurut Anda sulit untuk menulis chatbot Anda sendiri dengan Python yang dapat mendukung percakapan? Ternyata sangat mudah jika Anda menemukan kumpulan data yang baik. Selain itu, ini dapat dilakukan bahkan tanpa jaringan saraf, meskipun beberapa sihir matematika masih diperlukan.
Kita akan melakukan langkah-langkah kecil: pertama, ingat bagaimana memuat data ke Python, kemudian belajar menghitung kata, secara bertahap menghubungkan aljabar linier dan teoritikus, dan pada akhirnya kita membuat bot untuk Telegram dari algoritma obrolan yang dihasilkan.
Tutorial ini cocok untuk mereka yang sudah sedikit menyentuh Python, tetapi tidak terlalu terbiasa dengan pembelajaran mesin. Saya sengaja tidak menggunakan pustaka nlp-sh untuk menunjukkan bahwa sesuatu yang bekerja dapat dirakit di sklearn kosong.
Cari jawaban dalam dataset dialog
Setahun yang lalu, saya diminta untuk menunjukkan kepada orang-orang yang sebelumnya tidak pernah terlibat dalam analisis data beberapa aplikasi pembelajaran mesin inspirasional yang dapat Anda bangun sendiri. Saya mencoba membawa bot-talker dengan mereka, dan kami benar-benar melakukannya dalam satu malam. Kami menyukai proses dan hasilnya, dan menulisnya di
blog saya . Dan sekarang saya pikir Habru akan menarik.
Jadi di sini kita mulai. Tugas kami adalah membuat algoritma yang akan memberikan jawaban yang sesuai untuk frasa apa pun. Misalnya, pada "apa kabar?" jawab "luar biasa, dan kamu?". Cara termudah untuk mencapai ini adalah dengan menemukan basis data pertanyaan dan jawaban yang sudah jadi. Misalnya, ambil subtitle dari sejumlah besar film.
Namun, saya akan bertindak lebih selingkuh, dan mengambil data dari
kompetisi Yandex. Algoritma 2018 - ini adalah dialog yang sama dari film-film di mana karyawan Toloka menandai sekuel yang baik dan tidak buruk. Yandex mengumpulkan data ini untuk melatih Alice (artikel tentang nyali
1 ,
2 ,
3 ). Sebenarnya, saya terinspirasi oleh Alice ketika saya datang dengan bot ini.
Tabel dari Yandex menunjukkan tiga frasa terakhir dan jawabannya (balas), tetapi kami hanya akan menggunakan yang terbaru (context_0).
Dengan memiliki basis data dialog, Anda dapat mencarinya di setiap replika pengguna, dan memberikan jawaban yang siap (jika ada banyak replika seperti itu, pilih secara acak). Dengan "apa kabar?" ternyata hebat, seperti dibuktikan oleh screenshot terlampir. Ini, jika ada, adalah
notebook jupyter dengan Python 3. Jika Anda ingin mengulanginya sendiri, cara termudah adalah menginstal
Anaconda - ini termasuk Python dan banyak paket berguna untuk itu. Atau Anda tidak dapat menginstal apa pun, tetapi jalankan notebook
di Google cloud .

Masalah dengan pencarian kata demi kata adalah memiliki cakupan yang rendah. Untuk frasa "apa kabar?" dalam database 40 ribu jawaban tidak ada kecocokan persis, meskipun memiliki arti yang sama. Oleh karena itu, di bagian selanjutnya, kami akan melengkapi kode kami menggunakan matematika yang berbeda untuk menerapkan perkiraan pencarian. Dan sebelum itu, Anda dapat membaca tentang
panda library dan mencari tahu apa yang masing-masing dari 6 baris kode di atas.
Vektorisasi Teks
Sekarang kita berbicara tentang bagaimana mengubah teks menjadi vektor numerik untuk melakukan pencarian perkiraan pada mereka.
Kami telah bertemu dengan panda library di Python - ini memungkinkan Anda untuk memuat tabel, mencari di dalamnya, dll. Sekarang mari kita sentuh
perpustakaan scikit-learning (sklearn), yang memungkinkan manipulasi data yang lebih rumit - apa yang disebut pembelajaran mesin. Ini berarti bahwa algoritma apa pun harus terlebih dahulu menunjukkan data (fit) sehingga mempelajari sesuatu yang penting tentang mereka. Akibatnya, algoritma "belajar" untuk melakukan sesuatu yang berguna dengan data ini - mentransformasikannya (mengubah), atau bahkan memprediksi nilai yang tidak diketahui (prediksi).
Dalam hal ini, kami ingin mengubah teks ("pertanyaan") menjadi vektor numerik. Ini diperlukan agar dimungkinkan untuk menemukan teks yang "dekat" satu sama lain, menggunakan konsep jarak matematis. Jarak antara dua titik dapat dihitung dengan teorema Pythagoras - sebagai akar dari jumlah kuadrat dari perbedaan koordinat mereka. Dalam matematika, ini disebut metrik Euclidean. Jika kita dapat mengubah teks menjadi objek yang memiliki koordinat, maka kita dapat menghitung metrik Euclidean dan, misalnya, menemukan dalam database pertanyaan yang paling mirip "apa yang Anda pikirkan?".
Cara termudah untuk menentukan koordinat teks adalah dengan memberi nomor semua kata dalam bahasa, dan mengatakan bahwa koordinat ke-10 dari teks sama dengan jumlah kemunculan kata ke-1 di dalamnya. Misalnya, untuk teks "Aku tidak bisa menahan tangis" koordinat dari kata "tidak" adalah 2, koordinat kata "Aku", "bisa" dan "menangis" adalah 1, dan koordinat semua kata lain (puluhan ribu di antaranya) adalah 0. Representasi ini kehilangan informasi tentang susunan kata, tetapi masih berfungsi dengan baik.
Masalahnya adalah bahwa untuk kata-kata yang sering ditemukan (misalnya, partikel "dan" dan "a"), koordinatnya akan sangat besar, meskipun mereka membawa sedikit informasi. Untuk mengurangi masalah ini, koordinat setiap kata dapat dibagi dengan logaritma dari jumlah teks di mana kata tersebut muncul - ini disebut tf-idf dan juga berfungsi dengan baik.

Hanya ada satu masalah: dalam database kami 60 ribu "pertanyaan" tekstual, yang berisi 14 ribu kata berbeda. Jika Anda mengubah semua pertanyaan menjadi vektor, Anda mendapatkan matriks 60k * 14k. Tidak terlalu keren untuk bekerja dengan ini, jadi kami akan berbicara tentang mengurangi dimensi nanti.
Pengurangan dimensi
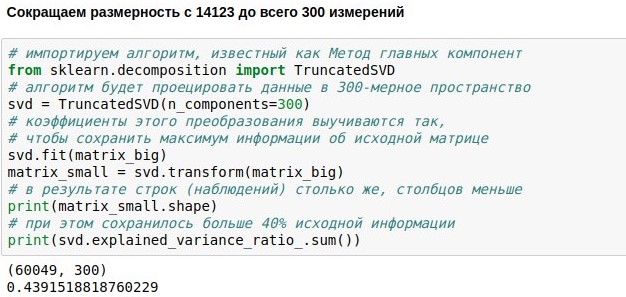
Kami telah menetapkan tugas untuk membuat obrolan chatbot, data unduhan dan vektor untuk pelatihannya. Sekarang kami memiliki matriks numerik yang mewakili replika pengguna. Ini terdiri dari 60 ribu baris (ada begitu banyak replika dalam database dialog) dan 14 ribu kolom (ada begitu banyak kata yang berbeda di dalamnya). Tugas kita sekarang adalah membuatnya lebih kecil. Misalnya, untuk menyajikan setiap teks bukan sebagai dimensi 14123, tetapi hanya vektor 300 dimensi.
Ini dapat dicapai dengan mengalikan matriks ukuran 60049x14123 kami dengan matriks proyeksi pilihan ukuran 14123x300, sebagai hasilnya kami mendapatkan hasil 60049x300. Algoritma PCA (
metode komponen utama ) memilih matriks proyeksi sehingga matriks asli kemudian dapat direkonstruksi dengan kesalahan standar terkecil. Dalam kasus kami, dimungkinkan untuk mempertahankan sekitar 44% dari matriks asli, meskipun dimensi berkurang hampir 50 kali lipat.
Apa yang memungkinkan kompresi efektif seperti itu? Ingat bahwa matriks asli berisi penghitung untuk menyebutkan kata-kata individual dalam teks. Tetapi kata-kata, sebagai suatu peraturan, digunakan tidak secara independen satu sama lain, tetapi dalam konteks. Misalnya, semakin sering kata “pemblokiran” muncul dalam teks berita, semakin sering, kemungkinan besar kata “telegram” juga ditemukan dalam teks ini. Tetapi korelasi dari kata "blocking", misalnya, dengan kata "caftan" adalah negatif - mereka ditemukan dalam konteks yang berbeda.
Jadi, ternyata metode komponen utama tidak hanya mengingat 14 ribu kata, tetapi 300 konteks khas yang dengannya kata-kata ini kemudian dapat dicoba untuk dipulihkan. Kolom dari matriks proyeksi yang bersesuaian dengan kata-kata sinonim biasanya sama satu sama lain karena kata-kata ini sering ditemukan dalam konteks yang sama. Ini berarti bahwa adalah mungkin untuk mengurangi pengukuran yang berlebihan tanpa kehilangan keinformatifan.
Dalam banyak aplikasi modern, matriks proyeksi kata dihitung oleh jaringan saraf (mis.
Word2vec ). Tetapi pada kenyataannya, aljabar linier sederhana sudah cukup untuk hasil praktis yang bermanfaat. Metode komponen utama secara komputasi direduksi menjadi SVD, dan untuk menghitung vektor eigen dan nilai eigen dari matriks. Namun, ini dapat diprogram tanpa mengetahui detailnya.
Cari tetangga terdekat
Di bagian sebelumnya, kami mengunggah kotak dialog ke python, membuat vektornya, dan mengurangi dimensi, dan sekarang kami ingin akhirnya belajar bagaimana mencari tetangga terdekat kami di ruang 300-dimensi kami dan akhirnya menjawab pertanyaan dengan penuh arti.
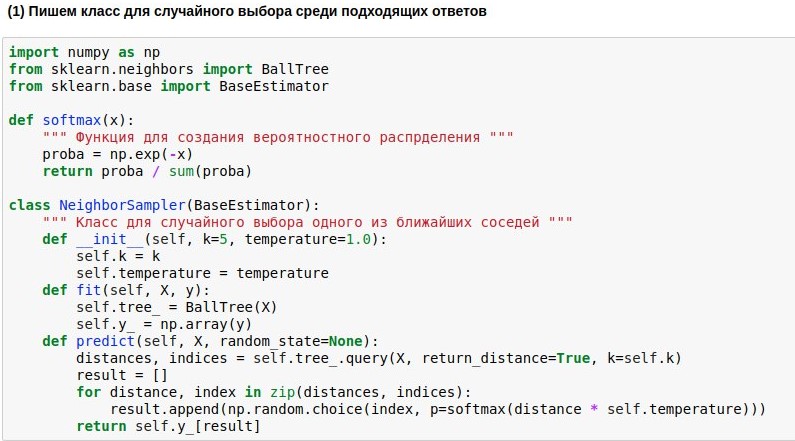
Karena kami belajar bagaimana memetakan pertanyaan ke ruang Euclidean dengan dimensi yang tidak terlalu tinggi, pencarian tetangga di dalamnya dapat dilakukan dengan cukup cepat. Kami akan menggunakan algoritma pencarian tetangga
BallTree yang sudah jadi. Tapi kami akan menulis model pembungkus kami, yang akan memilih salah satu tetangga terdekat, dan semakin dekat tetangga, semakin tinggi kemungkinan pilihannya. Karena selalu menganggap salah satu tetangga terdekat itu membosankan, tetapi tidak terikat dengan kemiripan sama sekali itu berbahaya.
Oleh karena itu, kami ingin mengubah jarak yang ditemukan dari kueri ke teks referensi menjadi probabilitas memilih teks-teks ini. Untuk melakukan ini, Anda dapat menggunakan fungsi softmax, yang sering masih berdiri di pintu keluar dari jaringan saraf. Dia mengubah argumennya menjadi satu set angka non-negatif, yang jumlahnya adalah 1 - hanya yang kita butuhkan. Selanjutnya, kita dapat menggunakan "probabilitas" yang diperoleh untuk pilihan jawaban acak.
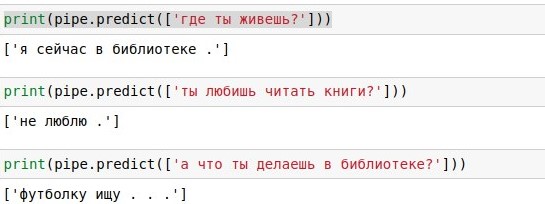
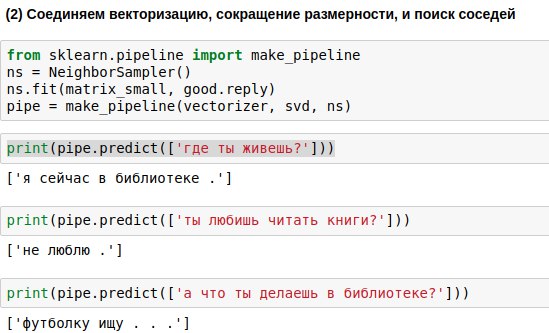
Frase yang akan dimasukkan pengguna harus melewati ketiga algoritma - vektorizer, metode komponen utama, dan algoritma pemilihan respons. Untuk menulis lebih sedikit kode, Anda dapat menautkannya ke rantai tunggal (pipa), menerapkan algoritma secara berurutan.
Hasilnya, kami mendapatkan algoritme yang, pada pertanyaan pengguna, dapat menemukan pertanyaan yang mirip dengannya dan memberikan jawaban untuknya. Dan kadang-kadang jawaban ini bahkan terdengar hampir bermakna.
Menerbitkan bot di Telegram
Kami telah menemukan cara membuat ruang obrolan chatbot yang akan memberikan sekitar jawaban yang relevan dengan permintaan pengguna. Sekarang saya menunjukkan kepada Anda cara melepaskan chatbot di Telegram.
Cara termudah untuk menggunakan ini adalah pembungkus API Telegram siap pakai untuk python - misalnya,
pytelegrambotapi . Jadi, petunjuk langkah demi langkah:
- Daftarkan bot masa depan Anda dengan @botfather dan dapatkan token akses, yang harus Anda masukkan ke dalam kode Anda.
- Jalankan perintah instalasi sekali - pip instal pytelegrambotapi pada baris perintah (atau via! Langsung di notepad).
- Jalankan kode seperti pada tangkapan layar. Sel akan masuk ke mode eksekusi (*), dan saat berada dalam mode ini, Anda dapat berkomunikasi dengan bot Anda sebanyak yang Anda inginkan. Untuk menghentikan bot, tekan Ctrl + C. Kebenaran yang menyedihkan, tetapi penting: jika Anda berada di Rusia, maka kemungkinan besar, sebelum memulai sel ini, Anda harus mengaktifkan VPN agar tidak mendapatkan kesalahan saat menghubungkan ke telegram. Alternatif yang lebih sederhana untuk VPN adalah menulis semua kode bukan pada komputer lokal Anda, tetapi di google colab ( seperti ini ).
- Jika Anda ingin bot bekerja secara permanen, Anda harus meletakkan kodenya di beberapa layanan cloud - misalnya, AWS, Heroku, now.sh atau Yandex.Cloud. Anda dapat mempelajari tentang cara menjalankannya dalam perincian terkecil di situs layanan ini atau dalam artikel di Habré di sana. Misalnya, lobak dengan contoh kecil bot berjalan di heroku dan meletakkan log di mongodb.
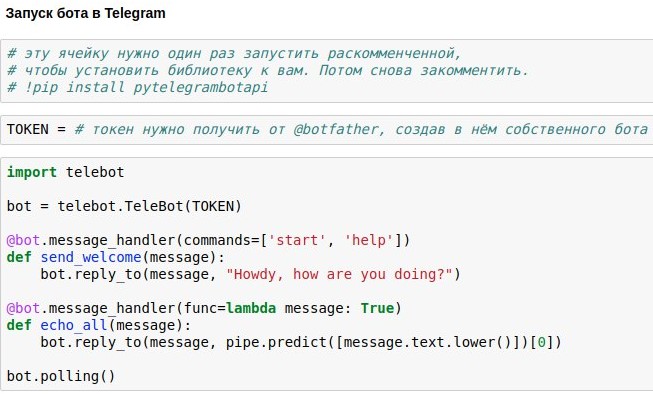
Saya sengaja tidak mengunggah kode lengkap untuk artikel - Anda akan mendapatkan lebih banyak kesenangan dan pengalaman yang berguna ketika Anda mencetaknya sendiri dan mendapatkan bot yang berfungsi sebagai hasil dari upaya Anda sendiri. Ya, atau jika Anda terlalu malas untuk melakukan ini, Anda dapat mengobrol dengan bot
versi saya .