Sistem informasi modern cukup kompleks. Terakhir namun tidak kalah pentingnya, kompleksitasnya adalah karena kompleksitas data yang diproses di dalamnya. Kompleksitas data sering terletak pada variasi model data yang digunakan. Jadi, misalnya, ketika data menjadi "besar", salah satu karakteristik yang tidak nyaman dianggap tidak hanya volumenya ("volume"), tetapi juga variasinya ("variasi").
Jika Anda masih tidak menemukan cacat dalam alasan tersebut, maka baca terus.

Ketekunan polyglot
Hal tersebut mengarah pada fakta bahwa kadang-kadang bahkan dalam kerangka satu sistem perlu menggunakan beberapa DBMS yang berbeda untuk menyimpan data dan memecahkan berbagai masalah dalam memprosesnya, masing-masing mendukung model data sendiri. Dengan tangan ringan M. Fowler, penulis sejumlah buku terkenal dan salah satu penulis bersama Agile Manifesto, situasi ini disebut penyimpanan multivarian (“persistensi poliglot”).
Fowler juga memiliki contoh pengorganisasian penyimpanan data berikut dalam aplikasi yang berfungsi penuh dan sarat muatan dalam bidang perdagangan elektronik.

Contoh ini, tentu saja, agak dilebih-lebihkan, tetapi beberapa pertimbangan untuk memilih satu atau beberapa DBMS untuk tujuan yang sesuai dapat ditemukan, misalnya, di sini .
Jelas menjadi menteri di kebun binatang semacam itu tidak mudah.
- Jumlah kode yang melakukan penyimpanan data tumbuh sebanding dengan jumlah DBMS yang digunakan; jumlah kode yang menyinkronkan data baik jika tidak sebanding dengan kuadrat dari angka itu.
- Kelipatan dari jumlah DBMS yang digunakan meningkatkan biaya untuk memberikan karakteristik perusahaan (skalabilitas, toleransi kesalahan, ketersediaan tinggi) untuk masing-masing DBMS yang digunakan.
- Tidak mungkin untuk memberikan karakteristik perusahaan dari subsistem penyimpanan secara keseluruhan - terutama transaksional.
Dari sudut pandang direktur kebun binatang, semuanya terlihat seperti ini:
- Peningkatan ganda dalam biaya lisensi dan dukungan teknis dari produsen DBMS.
- Staf menggembung dan waktu memimpin lebih lama.
- Kerugian atau hukuman finansial langsung karena data tidak konsisten.
Ada peningkatan yang signifikan dalam total biaya kepemilikan sistem (TCO). Apakah ada jalan keluar dari situasi "penyimpanan multivarian"?
Multimodel
Istilah "penyimpanan multivarian" mulai digunakan pada tahun 2011. Kesadaran akan masalah pendekatan dan pencarian solusi membutuhkan waktu beberapa tahun, dan pada 2015, jawabannya dirumuskan oleh para analis Gartner:
Tampaknya kali ini analis Gartner tidak salah dengan ramalan tersebut. Jika Anda membuka halaman dengan peringkat DBMS utama pada DB-Engine, Anda dapat melihat bahwa sebagian besar pemimpinnya memposisikan diri mereka secara tepat sebagai DBMS multimodel. Hal yang sama dapat dilihat pada halaman dengan peringkat pribadi apa pun.
Tabel di bawah ini menunjukkan DBMS - pemimpin di masing-masing peringkat pribadi, menyatakan multi-model mereka. Untuk setiap DBMS, model yang didukung awal (setelah satu-satunya) diindikasikan dan, bersama dengan itu, model yang didukung sekarang. DBMS juga mempresentasikan posisi mereka sebagai "awalnya multimodel" dan tidak memiliki model warisan asli, menurut pencipta.
Catatan tabelTanda bintang pada pernyataan tanda tabel yang membutuhkan pemesanan:
- PostgreSQL tidak mendukung model data grafik, tetapi didukung oleh produk yang didasarkan padanya , seperti, misalnya, AgensGraph.
- Seperti yang diterapkan pada MongoDB, lebih tepat untuk berbicara lebih banyak tentang keberadaan operator grafik dalam bahasa query (
$lookup , $graphLookup ) daripada tentang dukungan untuk model grafik, meskipun, tentu saja, pengenalan mereka memerlukan beberapa optimasi pada tingkat penyimpanan fisik ke arah dukungan model grafik. - Untuk Redis, ini merujuk pada ekstensi RedisGraph .
Selanjutnya, untuk masing-masing kelas kami akan menunjukkan bagaimana dukungan dari beberapa model dalam DBMS dari kelas ini diimplementasikan. Kami akan mempertimbangkan model relasional, dokumen dan grafik yang paling penting dan menunjukkan dengan contoh-contoh DBMS spesifik bagaimana "yang hilang" diimplementasikan.
Multimodel DBMS Berdasarkan Model Relasional
DBMSs terkemuka saat ini bersifat relasional, perkiraan Gartner tidak dapat dianggap benar jika RDBMSs tidak menunjukkan pergerakan ke arah multi-model. Dan mereka menunjukkan. Sekarang, gagasan bahwa DBMS multimodel seperti pisau Swiss, yang tidak dapat dilakukan dengan baik, dapat segera dikirim ke Larry Ellison.
Penulis, bagaimanapun, menyukai implementasi multimodeling di Microsoft SQL Server, pada contoh yang dukungan RDBMS untuk model dokumen dan grafik akan dijelaskan.
Model Dokumen di MS SQL Server
Tentang bagaimana MS SQL Server mendukung model dokumen, sudah ada dua artikel bagus tentang Habré, saya akan membatasi diri untuk menceritakan kembali dan komentar singkat:
Cara untuk mendukung model dokumen dalam MS SQL Server cukup khas untuk DBMS relasional: Dokumen JSON diusulkan untuk disimpan dalam bidang teks biasa. Dukungan model dokumen adalah menyediakan operator khusus untuk mengurai JSON ini:
Argumen kedua untuk kedua operator adalah ekspresi dalam sintaks seperti JSONPath.
Dapat dikatakan secara abstrak bahwa dokumen yang disimpan dengan cara ini bukan "entitas kelas satu" dalam DBMS relasional, tidak seperti tupel. Secara khusus, MS SQL Server saat ini tidak memiliki indeks pada bidang dokumen JSON, yang membuatnya sulit untuk bergabung dengan tabel dengan nilai-nilai bidang ini dan bahkan memilih dokumen berdasarkan nilai-nilai ini. Namun, dimungkinkan untuk membuat kolom yang dapat dihitung dan indeksnya di bidang ini.
Selain itu, MS SQL Server menyediakan kemampuan untuk dengan mudah membangun dokumen JSON dari isi tabel menggunakan pernyataan FOR JSON PATH , fitur yang, dalam arti, adalah kebalikan dari penyimpanan biasa sebelumnya. Jelas bahwa tidak peduli seberapa cepat RDBMS, pendekatan ini bertentangan dengan ideologi dokumen DBMS, yang sebenarnya menyimpan jawaban siap pakai untuk pertanyaan populer, dan hanya dapat menyelesaikan masalah kemudahan pengembangan, tetapi tidak kecepatan.
Akhirnya, MS SQL Server memungkinkan Anda untuk memecahkan masalah, kebalikan dari desain dokumen: Anda dapat menguraikan JSON menjadi tabel menggunakan OPENJSON . Jika dokumen tidak sepenuhnya rata, Anda harus menggunakan CROSS APPLY .
Model grafik dalam MS SQL Server
Dukungan untuk model grafik ( LPG ) yang diterapkan di Microsoft SQL Server juga cukup dapat diprediksi : diusulkan untuk menggunakan tabel khusus untuk menyimpan node dan untuk menyimpan tepi grafik. Tabel tersebut dibuat menggunakan ekspresi CREATE TABLE AS NODE dan CREATE TABLE AS EDGE .
Tabel dari tipe pertama mirip dengan tabel biasa untuk menyimpan catatan dengan satu-satunya perbedaan eksternal bahwa tabel berisi bidang sistem $node_id - pengidentifikasi simpul grafik yang unik dalam database.
Demikian pula, tabel dari tipe kedua memiliki bidang sistem $from_id dan $to_id , catatan dalam tabel tersebut dengan jelas mendefinisikan hubungan antar node. Tabel terpisah digunakan untuk menyimpan hubungan masing-masing jenis.
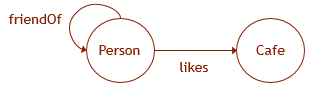 Kami menggambarkan apa yang dikatakan dengan contoh. Biarkan data grafik memiliki skema seperti yang ditunjukkan pada gambar. Kemudian, untuk membuat struktur yang sesuai dalam database, Anda perlu menjalankan query DDL berikut:
Kami menggambarkan apa yang dikatakan dengan contoh. Biarkan data grafik memiliki skema seperti yang ditunjukkan pada gambar. Kemudian, untuk membuat struktur yang sesuai dalam database, Anda perlu menjalankan query DDL berikut:
CREATE TABLE Person ( ID INTEGER NOT NULL, name VARCHAR(100) ) AS NODE; CREATE TABLE Cafe ( ID INTEGER NOT NULL, name VARCHAR(100), ) AS NODE; CREATE TABLE likes ( rating INTEGER ) AS EDGE; CREATE TABLE friendOf AS EDGE;
Spesifisitas utama dari tabel tersebut adalah bahwa dalam query mereka dimungkinkan untuk menggunakan pola grafik dengan sintaks seperti Cypher (namun, " * ", dll., Belum didukung). Juga, berdasarkan pengukuran kinerja, dapat diasumsikan bahwa metode menyimpan data dalam tabel ini berbeda dari mekanisme untuk menyimpan data dalam tabel biasa dan dioptimalkan untuk melakukan kueri grafik tersebut.
SELECT Cafe.name FROM Person, likes, Cafe WHERE MATCH (Person-(friendOf)-(likes)->Cafe) AND Person.name = 'John';
Selain itu, cukup sulit untuk tidak menggunakan pola grafik ini ketika bekerja dengan tabel seperti itu, karena dalam pertanyaan SQL biasa untuk memecahkan masalah yang sama, upaya tambahan akan diperlukan untuk mendapatkan pengidentifikasi simpul "grafik" sistem ( $node_id , $from_id , $to_id ; untuk ini untuk alasan yang sama, permintaan penyisipan data tidak diberikan di sini terlalu rumit).
Meringkas deskripsi implementasi dokumen dan model grafik di MS SQL Server, saya akan mencatat bahwa implementasi seperti satu model di atas yang lain tampaknya tidak berhasil terutama dari sudut pandang desain bahasa. Diperlukan untuk memperluas satu bahasa dengan yang lain, bahasa tidak sepenuhnya "orthogonal", aturan kompatibilitas bisa sangat aneh.
Multimodel DBMS Berdasarkan Model Dokumen
Pada bagian ini, saya ingin menggambarkan implementasi multimodel dalam dokumen DBMS menggunakan contoh bukan yang paling populer di antaranya MongoDB (seperti yang dikatakan, itu hanya berisi operator grafik kondisional $lookup dan $graphLookup yang tidak berfungsi pada koleksi $graphLookup ), tetapi pada contoh itu lebih matang dan “ Perusahaan »DBMS MarkLogic .
Jadi, biarkan koleksi berisi kumpulan dokumen XML dari formulir berikut (MarkLogic juga memungkinkan menyimpan dokumen JSON):
<Person INN="631803299804"> <name>John</name> <surname>Smith</surname> </Person>
Model Relasional di MarkLogic
Representasi relasional dari kumpulan dokumen dapat dibuat menggunakan templat tampilan (konten elemen value dalam contoh di bawah ini dapat XPath sewenang-wenang):
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <rows> <row> <view-name>Person</view-name> <columns> <column> <name>SSN</name> <value>@SSN</value> <type>string</type> </column> <column> <name>name</name> <value>name</value> </column> <column> <name>surname</name> <value>surname</value> </column> </columns> </row> <rows> </template>
Kueri SQL dapat dialamatkan ke tampilan yang dibuat (misalnya, melalui ODBC):
SELECT name, surname FROM Person WHERE name="John"
Sayangnya, tampilan relasional yang dibuat menggunakan templat tampilan hanya-baca. Saat memproses permintaan untuk itu, MarkLogic akan mencoba menggunakan indeks dokumen . Dulu ada pandangan relasional terbatas dalam MarkLogic yang seluruhnya berbasis indeks dan dapat ditulis, tetapi sekarang mereka dianggap usang.
Model Grafik dalam MarkLogic
Dengan dukungan model grafik ( RDF ), semuanya hampir sama. Sekali lagi, menggunakan templat tampilan, Anda dapat membuat representasi RDF dari kumpulan dokumen dari contoh di atas:
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <vars> <var> <name>PREFIX</name> <val>"http://example.org/example#"</val> </var> </vars> <triples> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || surname )</value></predicate> <object><value>xs:string( surname )</value></object> </triple> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || name )</value></predicate> <object><value>xs:string( name )</value></object> </triple> </triples> </template>
Grafik RDF yang dihasilkan dapat diatasi dengan kueri SPARQL:
PREFIX : <http://example.org/example
Berbeda dengan relasional, model grafik MarkLogic mendukung dalam dua cara lain:
- DBMS dapat berupa repositori terpisah dari data RDF yang lengkap (kembar tiga di dalamnya akan disebut dikelola, berbeda dengan ekstrak yang diekstrak di atas).
- RDF dalam serialisasi khusus dapat dengan mudah dimasukkan ke dalam dokumen XML atau JSON (dan kembar tiga akan disebut tidak terkelola ). Ini mungkin alternatif untuk mekanisme
idref , dll.
API Optik memberikan ide bagus tentang bagaimana "benar-benar" semuanya bekerja di MarkLogic, dalam hal ini adalah level rendah, meskipun tujuannya agak sebaliknya - untuk mencoba abstrak dari model data yang digunakan, untuk memastikan kerja yang konsisten dengan data dalam model yang berbeda, transaksionalitas dan pr
Multimodel DBMS “tanpa model utama”
DBMS juga tersedia di pasar, memposisikan diri mereka sebagai multi-model pada awalnya, tidak memiliki model dasar yang diwariskan. Ini termasuk ArangoDB , OrientDB (sejak 2018, perusahaan pengembangan milik SAP) dan CosmosDB (layanan yang termasuk dalam platform cloud Microsoft Azure).
Bahkan, ada model "dasar" di ArangoDB dan OrientDB. Dalam kedua kasus, ini adalah model data eksklusif, yang merupakan generalisasi dokumen. Generalisasi terutama untuk memfasilitasi kemampuan untuk menghasilkan grafik dan permintaan relasional.
Model-model ini adalah satu-satunya yang tersedia untuk digunakan dalam DBMS yang ditunjukkan, bahasa permintaan mereka dirancang untuk bekerja dengan mereka. Tentu saja, model dan DBMS seperti itu cukup menjanjikan, tetapi kurangnya kompatibilitas dengan model dan bahasa standar membuatnya tidak mungkin untuk menggunakan DBMS ini dalam sistem lama - menggantinya dengan DBMS yang sudah mereka gunakan.
Tentang ArangoDB dan OrientDB di Habré sudah ada artikel yang bagus: BERGABUNG dalam basis data NoSQL .
Arangodb
ArangoDB mengklaim dukungan untuk model data grafik.
Node grafik di ArangoDB adalah dokumen biasa, dan edge adalah dokumen dari jenis khusus yang dimiliki, bersama dengan bidang sistem yang biasa ( _id , _rev , _rev ), bidang sistem _to dan _to . Dokumen dalam dokumen DBMS secara tradisional digabungkan ke dalam koleksi. Koleksi dokumen yang mewakili tepi disebut koleksi tepi di ArangoDB. Omong-omong, dokumen koleksi tepi juga merupakan dokumen, jadi tepi di ArangoDB juga dapat bertindak sebagai simpul.
Sumber dataMisalkan kita memiliki koleksi persons - persons yang dokumennya terlihat seperti ini:
[ { "_id" : "people/alice" , "_key" : "alice" , "name" : "" }, { "_id" : "people/bob" , "_key" : "bob" , "name" : "" } ]
Biarkan juga memiliki koleksi cafes :
[ { "_id" : "cafes/jd" , "_key" : "jd" , "name" : " " }, { "_id" : "cafes/jj" , "_key" : "jj" , "name" : "-" } ]
Maka koleksi likes mungkin terlihat seperti ini:
[ { "_id" : "likes/1" , "_key" : "1" , "_from" : "persons/alice" , "_to" : "cafes/jd", "since" : 2010 }, { "_id" : "likes/2" , "_key" : "2" , "_from" : "persons/alice" , "_to" : "cafes/jj", "since" : 2011 } , { "_id" : "likes/3" , "_key" : "3" , "_from" : "persons/bob" , "_to" : "cafes/jd", "since" : 2012 } ]
Kueri dan HasilKueri gaya grafik di AQL yang digunakan di ArangoDB yang mengembalikan informasi formulir yang dapat dibaca manusia tentang siapa yang suka kafe mana yang terlihat seperti ini:
FOR p IN persons FOR c IN OUTBOUND p likes RETURN { person : p.name , likes : c.name }
Dalam gaya relasional, ketika kita lebih cenderung "menghitung" hubungan, daripada menyimpannya, kueri ini dapat ditulis ulang seperti ini (ngomong-ngomong, Anda bisa melakukannya tanpa koleksi likes ):
FOR p IN persons FOR l IN likes FILTER p._key == l._from FOR c IN cafes FILTER l._to == c._key RETURN { person : p.name , likes : c.name }
Hasilnya dalam kedua kasus akan sama:
[ { "person" : "" , likes : "-" } , { "person" : "" , likes : " " } , { "person" : "" , likes : " " } ]
Lebih banyak pertanyaan dan hasilJika tampaknya format hasil di atas lebih khas untuk DBMS relasional daripada untuk dokumen, Anda dapat mencoba kueri ini (atau Anda dapat menggunakan COLLECT ):
FOR p IN persons RETURN { person : p.name, likes : ( FOR c IN OUTBOUND p likes RETURN c.name ) }
Hasilnya adalah sebagai berikut:
[ { "person" : "" , likes : ["-" , " "] } , { "person" : "" , likes : [" "] } ]
Oriententb
Implementasi model grafik di atas model dokumen di OrientDB didasarkan pada kemampuan bidang dokumen untuk memiliki, di samping nilai skalar standar yang kurang lebih, nilai jenis seperti LINK , LINKLIST , LINKSET , LINKMAP dan LINKBAG . Nilai dari tipe ini adalah tautan atau kumpulan tautan ke pengidentifikasi dokumen sistem .
Pengidentifikasi dokumen yang ditugaskan oleh sistem memiliki "makna fisik", menunjukkan posisi catatan dalam database, dan terlihat seperti ini: @rid : #3:16 . Dengan demikian, nilai-nilai properti referensi adalah pointer yang benar-benar lebih mungkin (seperti dalam model grafik), daripada kondisi pemilihan (seperti dalam model relasional).
Seperti di ArangoDB, di OrientDB tepi diwakili oleh dokumen terpisah (meskipun jika tepi tidak memiliki properti sendiri, itu dapat dibuat ringan dan dokumen terpisah tidak akan sesuai dengan itu).
Sumber dataDalam format yang dekat dengan format dump basis data OrientDB, data dari contoh sebelumnya untuk ArangoDB akan terlihat seperti ini:
[ { "@type": "document", "@rid": "#11:0", "@class": "Person", "name": "", "out_likes": [ "#30:1", "#30:2" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#12:0", "@class": "Person", "name": "", "out_likes": [ "#30:3" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#21:0", "@class": "Cafe", "name": "-", "in_likes": [ "#30:2", "#30:3" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#22:0", "@class": "Cafe", "name": " ", "in_likes": [ "#30:1" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#30:1", "@class": "likes", "in": "#22:0", "out": "#11:0", "since": 1262286000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:2", "@class": "likes", "in": "#21:0", "out": "#11:0", "since": 1293822000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:3", "@class": "likes", "in": "#21:0", "out": "#12:0", "since": 1325354400000, "@fieldTypes": "in=LINK,out=LINK,since=date" } ]
Seperti yang dapat kita lihat, simpul juga menyimpan informasi tentang tepi yang masuk dan keluar. Saat menggunakan API Dokumen, Anda harus mengikuti integritas referensial sendiri, dan API Grafik menangani ini. Tapi mari kita lihat seperti apa panggilan ke OrientDB di "bersih", tidak terintegrasi ke dalam bahasa pemrograman, bahasa query.
Kueri dan HasilKueri yang serupa dengan kueri dari contoh untuk ArangoDB di OrientDB terlihat seperti ini:
SELECT name AS person_name, OUT('likes').name AS cafe_name FROM Person UNWIND cafe_name
Hasilnya akan diperoleh sebagai berikut:
[ { "person_name": "", "cafe_name": " " }, { "person_name": "", "cafe_name": "-" }, { "person_name": "", "cafe_name": "-" } ]
Jika format hasil lagi tampaknya terlalu "relasional", Anda harus menghapus baris dengan UNWIND() :
[ { "person_name": "", "cafe_name": [ " ", "-" ] }, { "person_name": "", "cafe_name": [ "-" ' } ]
Bahasa query OrientDB dapat digambarkan sebagai SQL dengan sisipan mirip GREMLIN. Versi 2.2 memperkenalkan formulir permintaan seperti Cypher, MATCH :
MATCH {CLASS: Person, AS: person}-likes->{CLASS: Cafe, AS: cafe} RETURN person.name AS person_name, LIST(cafe.name) AS cafe_name GROUP BY person_name
Format hasil akan sama seperti pada permintaan sebelumnya. Pikirkan tentang apa yang perlu dihapus untuk membuatnya lebih "relasional", seperti dalam kueri pertama.
Azure CosmosDB
Pada tingkat lebih rendah, apa yang dikatakan di atas tentang ArangoDB dan OrientDB mengacu pada Azure CosmosDB. CosmosDB menyediakan API akses data berikut: SQL, MongoDB, GREMLIN, dan Cassandra.
SQL API dan MongoDB API digunakan untuk mengakses data dalam model dokumen. API GREMLIN dan API Cassandra - untuk mengakses data masing-masing dalam grafik dan kolom. Data dalam semua model disimpan dalam format model internal CosmosDB: ARS ("atom-record-sequence"), yang juga dekat dengan dokumen.

Tetapi model data yang dipilih oleh pengguna dan API yang digunakan diperbaiki pada saat membuat akun di layanan. Tidak mungkin mengakses data yang dimuat dalam satu model dalam format model lain, yang akan diilustrasikan oleh sesuatu seperti ini:

Dengan demikian, multimodel di Azure CosmosDB saat ini hanya merupakan kesempatan untuk menggunakan beberapa basis data yang mendukung berbagai model dari pabrikan yang sama, yang tidak menyelesaikan semua masalah penyimpanan multivarian.
Multimodel DBMS berdasarkan pada model grafik?
Patut dicatat bahwa di pasaran tidak ada DBMS multimodel yang didasarkan pada model grafik (kecuali untuk dukungan multimodel untuk dua model grafik secara bersamaan: RDF dan LPG; lihat ini dalam publikasi sebelumnya ). Kesulitan terbesar adalah implementasi di atas model grafik dokumen, daripada yang relasional.
Pertanyaan tentang bagaimana menerapkan model relasional di atas model grafik dianggap bahkan pada saat pembentukan yang terakhir. Seperti yang dikatakan David McGovern , misalnya:
Tidak ada yang inheren dalam pendekatan grafik yang mencegah pembuatan layer (misalnya, dengan pengindeksan yang sesuai) pada database grafik yang memungkinkan tampilan relasional dengan (1) pemulihan tupel dari pasangan nilai kunci biasa dan (2) pengelompokan tupel oleh jenis hubungan.
Saat menerapkan model dokumen di atas grafik, Anda perlu mengingat, misalnya, berikut ini:
- Elemen-elemen dari array JSON dianggap dipesan, berasal dari bagian atas tepi grafik - tidak;
- Data dalam model dokumen biasanya didenormalisasi, Anda masih tidak ingin menyimpan beberapa salinan dari dokumen terlampir yang sama, dan sub dokumen biasanya tidak memiliki pengidentifikasi;
- Di sisi lain, ideologi dokumen DBMS adalah bahwa dokumen adalah "unit" siap pakai yang tidak perlu dibangun kembali setiap saat. Diperlukan untuk memberikan dalam model grafik kemampuan untuk dengan cepat mendapatkan subgraph yang sesuai dengan dokumen yang sudah jadi.
Beberapa iklanPenulis artikel ini terkait dengan pengembangan NitrosBase DBMS, model internal yang grafis, dan model eksternal - relasional dan dokumen - adalah perwakilannya. Semua model sama: hampir semua data tersedia di salah satu dari mereka menggunakan bahasa query alami untuk itu. Selain itu, dalam representasi apa pun, data dapat berubah. Perubahan akan tercermin dalam model internal dan, karenanya, dalam representasi lain.
Seperti apa model yang cocok di NitrosBase - Saya akan jelaskan, saya harap, di salah satu artikel berikut.
Kesimpulan
Saya berharap bahwa kontur umum dari apa yang disebut multimodeling menjadi lebih atau kurang jelas bagi pembaca. DBMS yang cukup berbeda disebut multimodel, dan "dukungan untuk beberapa model" mungkin terlihat berbeda. Untuk memahami apa yang disebut "multi-model" dalam setiap kasus, ada baiknya untuk menjawab pertanyaan-pertanyaan berikut:
- Apakah ini tentang mendukung model tradisional, atau tentang model hybrid tunggal?
- Apakah model "sama" atau salah satu dari mereka tunduk pada yang lain?
- Apakah model "acuh tak acuh" satu sama lain? Apakah data yang direkam dalam satu model dapat dibaca di model lain atau bahkan ditimpa?
Saya pikir sudah mungkin untuk memberikan jawaban positif terhadap pertanyaan tentang relevansi DBMS multimodel, tetapi pertanyaan yang menarik adalah varietas mana yang akan lebih diminati dalam waktu dekat. Tampaknya DBMS multimodel yang mendukung model tradisional, terutama yang bersifat relasional, akan lebih diminati; , , , — .