Catatan perev. : Apa yang sekarang disebut SRE (Rekayasa Keandalan Situs - "memastikan keandalan sistem informasi") mencakup berbagai langkah untuk pengoperasian produk perangkat lunak yang bertujuan mencapai tingkat keandalan yang diperlukan. Pemantauan adalah salah satu peristiwa utama, dan "sinyal emas" membentuk metrik utama yang harus diperhitungkan di dalamnya. Karena tidak menemukan materi tentang mereka di Habré, kami memutuskan untuk menerjemahkan catatan pendek dari penulis platform manajemen insiden (VictorOps), yang memberikan gagasan tentang ide umum pendekatan ini.
Rekayasa keandalan situs (
SRE ) yang efektif didasarkan pada pemahaman mendalam tentang infrastruktur dan arsitektur layanan yang mendasarinya. Meningkatkan transparansi keadaan aplikasi dan infrastruktur hanyalah awal dari pekerjaan proaktif dalam penciptaan sistem yang andal. Pada saat yang sama, apa yang disebut "empat sinyal emas" SRE dianggap sebagai titik awal terbaik untuk memantau status sistem. Setelah menetapkan empat metode pemantauan dasar ini, kami dapat melanjutkan untuk meningkatkan transparansi sistem lebih jauh.
Meningkatkan transparansi, ditambah dengan metode kolaborasi yang efektif, memungkinkan tim SRE untuk dengan cepat memonitor sistem dan mengambil langkah-langkah untuk menghilangkan konsekuensi dari insiden, meningkatkan efektivitas keseluruhan metode
pemantauan dan peringatan . Sinyal SRE Emas membantu tim mengidentifikasi potensi kelemahan dalam keandalan, memungkinkan mereka untuk fokus pada pemecahan masalah infrastruktur. Mari kita periksa hubungan antara metode pemantauan dan perintah SRE dan lihat apa efek sinyal emas pada proses.
Monitoring dan SRE
Di Bagian III
kamus DevOps kami
, kami menjelajahi Internet, mencoba menemukan definisi SRE. Menurut
artikel Wikipedia yang terkait,
"Ben Treynor, pendiri Tim Keandalan Situs Google [mengatakan] bahwa SRE adalah" apa yang Anda dapatkan ketika seorang insinyur perangkat lunak melakukan apa yang dulu disebut pemeliharaan " .
" SRE menggabungkan tantangan dan kemampuan rekayasa perangkat lunak dengan tantangan mengoperasikan TI dan membantu Anda menemukan solusi untuk masalah keandalan. Dapat dipahami bahwa tim SRE harus memantau layanan mereka untuk mengidentifikasi bidang-bidang di mana keandalan dapat ditingkatkan.
Inilah tepatnya tugas pemantauan untuk tim SRE. Ini hanya menempati sebagian kecil dalam
penciptaan sistem yang sangat transparan , tetapi ini adalah elemen penting untuk memahami keadaan aplikasi dan infrastruktur. Empat sinyal pemantauan emas dan SRE memberikan tingkat transparansi dasar mengenai keandalan semua yang Anda buat. Setelah mencapai tingkat pengamatan yang nyaman dari sinyal emas, Anda dapat menggunakan informasi tambahan ini untuk analisis yang lebih mendalam menggunakan alat pemantauan.
Sekarang kami telah memutuskan pentingnya memantau sinyal SRE emas, mari beralih ke metrik nyata yang menyusunnya.
Empat sinyal pemantauan emas
Pada awal jalan untuk meningkatkan upaya pemantauan, mungkin sulit untuk memahami dari mana harus memulai. Keempat SRE emas dan sinyal pemantauan pertama kali dikutip dalam
buku Google di SRE , dan saat ini digunakan oleh banyak tim. Sangat bagus untuk memulai dengan mereka, karena mereka membantu menyoroti metrik utama yang harus selalu dilacak.
Jadi, mari kita lihat sinyal emas dan lihat mengapa pemantauan mereka merupakan elemen integral dalam memastikan keandalan sistem apa pun.
1. Latensi
Berapa lama untuk memproses permintaan? Tetapkan titik referensi untuk keterlambatan khas permintaan yang berhasil, dan bandingkan dengan penundaan untuk permintaan yang tidak berhasil. Keterlambatan pelacakan yang disebabkan oleh kesalahan memungkinkan Anda untuk menyelesaikan masalah yang terkait dengan kecepatan deteksi dan respons insiden.
2. Lalu Lintas
Sinyal ini tidak memerlukan penjelasan khusus. Apa pengaruh jumlah pengguna atau jumlah transaksi yang melewati layanan terhadap sistem? Tergantung pada fungsionalitas layanan, pengukuran lalu lintas dapat berbeda secara signifikan dari perusahaan ke perusahaan. Dengan melacak interaksi dengan pengguna nyata dan lalu lintas, Anda dapat lebih memahami bagaimana pengguna akhir merasakan layanan dan mendapatkan ide tentang bagaimana sistem berperilaku di bawah tekanan.
3. Kesalahan
Tentu saja, setiap tim harus melacak kesalahan. Terlepas dari apakah kesalahan dipicu secara manual atau otonom (seperti permintaan HTTP gagal), perintah SRE harus melacaknya. Banyak tim SRE menggunakan
perangkat lunak manajemen insiden khusus
untuk mengingatkan mereka akan kesalahan kritis, menemukan penyebabnya, dan mengambil tindakan korektif.
4. Kejenuhan
Setiap tim harus memantau beban sistem mereka. Penting untuk menetapkan metrik untuk saturasi, yang berarti bahwa layanan telah mencapai kemampuan maksimalnya. Sebagian besar layanan mulai kehilangan kinerja bahkan sebelum beban mencapai 100%, jadi memahami fungsi sistem Anda sendiri adalah penting untuk menentukan pedoman saturasi yang masuk akal.
Dengan mengatur aturan pemantauan dan peringatan untuk empat sinyal emas, Anda akan membahas sebagian besar insiden utama dalam sistem. Namun, untuk mulai membuat sistem pemantauan proaktif dan SRE, Anda harus menggali lebih dalam lagi.
Catatan perev. : Sebagai contoh menggambarkan dasbor dengan grafik "sinyal emas", kami menyajikan hasil konfigurasi pemantauan yang sesuai untuk Kubernetes dari artikel ini dari Sysdig :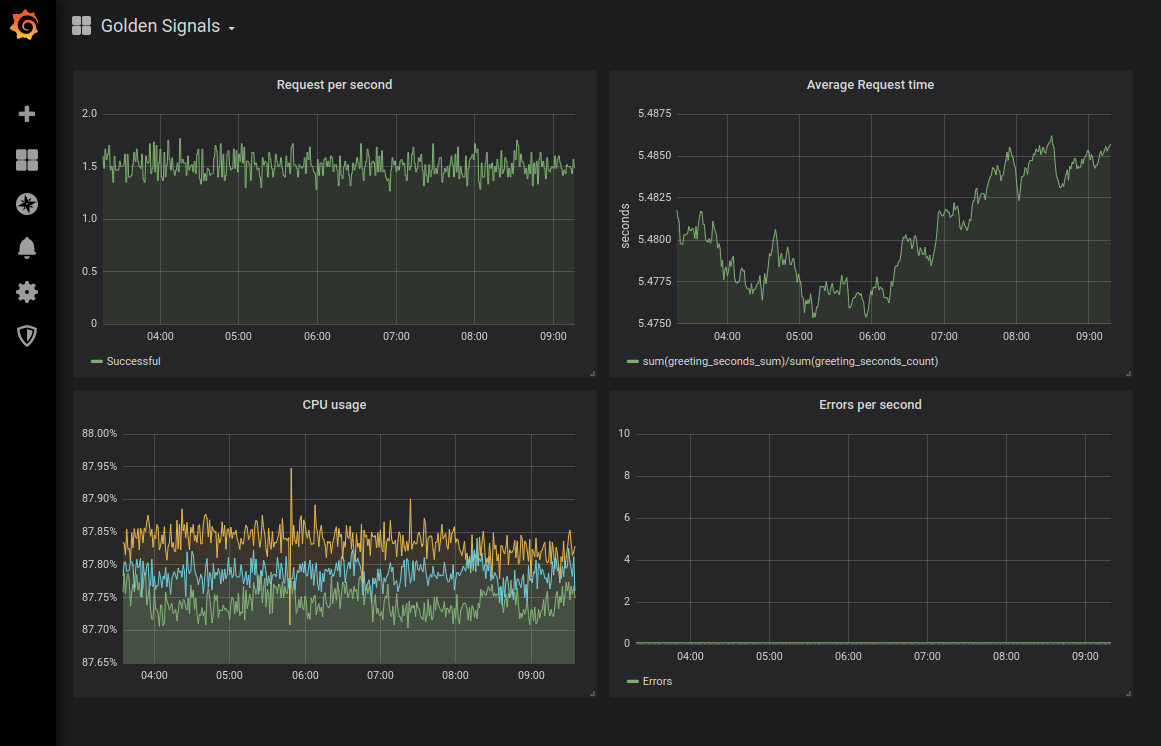 Catatan perev. : Dan di sini adalah representasi yang lebih visual dari sinyal emas dari Denise Yu , yang dapat digunakan sebagai memo yang nyaman:
Catatan perev. : Dan di sini adalah representasi yang lebih visual dari sinyal emas dari Denise Yu , yang dapat digunakan sebagai memo yang nyaman:
SRE proaktif melampaui sinyal emas
Memantau sinyal emas adalah awal yang baik untuk menganalisis insiden dalam layanan, tetapi itu tidak cukup. Tim SRE yang berpengalaman secara proaktif mengeksplorasi sistem mereka dengan berbagai metode tambahan. Melakukan tes terorganisir pada tahap persiapan dan dalam produksi, tim SRE secara aktif mempelajari sistem mereka dan menggunakan informasi yang diterima untuk meningkatkan keandalan layanan.
Rekayasa kekacauan
Rekayasa kekacauan adalah disiplin yang digunakan tim untuk menguji sistem mereka untuk secara proaktif mendeteksi kelemahan dan kerentanan. Secara manual memperkenalkan kekacauan ke dalam layanan, Anda dapat melihat bagaimana sistem merespons berbagai keadaan.
Catatan perev. : Baca lebih lanjut tentang pendekatan ini dalam artikel "Rekayasa Kekacauan: seni penghancuran yang disengaja" ( bagian 1 dan bagian 2 ).Hari Game
Sementara chaos engineering berfokus pada memahami sistem,
hari-hari bermain membantu staf untuk memahami. Mereka digunakan untuk menguji ketahanan tim ketika harus merespons insiden dan menghilangkan konsekuensinya. Hasil hari-hari bermain game dapat digunakan untuk mengembangkan proses yang lebih efisien atau untuk menentukan kebutuhan akan alat baru yang meningkatkan efisiensi staf.
Pemantauan sintetis
Pemantauan sintetis memungkinkan tim untuk membuat pengguna buatan dan mensimulasikan perilaku mereka menggunakan layanan. Anda dapat mengatur pola perilaku tertentu dan mengamati bagaimana sistem berperilaku di bawah beban yang diberikan. Pemantauan sintetis adalah metode yang sangat baik untuk pengujian terperinci dan menentukan keandalan layanan khusus di seluruh sistem.
...
Setiap tim yang ingin memantau status sistem secara visual diperlukan untuk memantau sinyal SRE emas. Tetapi gagasan tentang keadaan dan keandalan keseluruhan sistem sama sekali tidak sama dengan bekerja untuk meningkatkan keandalannya. Dalam ekosistem modern dari sistem yang sangat terdistribusi dan penyebaran cepat, tim SRE menghadapi tugas yang menakutkan. Sinyal emas pemantauan dan SRE dapat menjadi titik awal dari mana
peningkatan lebih lanjut
dalam SRE akan dimulai.
PS dari penerjemah
Baca juga di blog kami: