Menggunakan data dari sistem manajemen layanan TI (ITSM) sebagai contoh.
Dalam artikel sebelumnya tentang
SAP Process Mining atau cara memahami proses bisnis kami, kami berbicara tentang Proses Mining dan aplikasinya di lingkungan perusahaan. Hari ini kami ingin berbicara lebih banyak tentang model data dan proses persiapannya. Kami akan melihat komponen, bagaimana mereka saling berhubungan, format data apa yang diminta dari pemilik data, dan apa pendekatan untuk menghasilkan tabel acara untuk SAP Process Mining oleh Celonis.
Model Data dalam SAP PROCESS MINING oleh CELONIS
Struktur data dalam penambangan Proses SAP oleh alat Celonis cukup sederhana:
- "Meja acara." Ini adalah bagian yang diperlukan dari model data. Tabel seperti itu hanya bisa satu di setiap model data individu. Grafik proses secara otomatis dihasilkan di atasnya. Lihat gambar 1.
- Direktori adalah tabel lain yang memperluas "tabel acara" dengan informasi analitik tambahan. Berbeda dengan dia dalam referensi informasi tidak berubah seiring waktu. Lebih tepatnya, seharusnya tidak berubah dalam interval waktu yang kami analisis. Misalnya, dapat berupa tabel dengan deskripsi tentang sifat-sifat kontrak, item pengadaan, permintaan untuk sesuatu, karyawan, peraturan, kontraktor, dan objek lain yang entah bagaimana terlibat dalam proses. Dalam hal ini, direktori akan menggambarkan semua jenis properti statis dari objek-objek ini (jumlah, tipe, nama, nama, ukuran, departemen, alamat, dan semua jenis atribut lainnya). Direktori bersifat opsional. Anda dapat menjalankan model data tanpa mereka. Cukup menganalisis proses semacam itu akan kurang menarik.
 Gambar 1. Model data dalam Penambangan Proses: tabel acara dan referensi untuk proses instance
Gambar 1. Model data dalam Penambangan Proses: tabel acara dan referensi untuk proses instanceTabel acara adalah tabel standar (penyimpanan fisik, yang bertentangan dengan tabel logis) di platform dalam memori SAP HANA. Direktori dapat disajikan sebagai tabel standar (penyimpanan fisik), dan tabel perhitungan (Tampilan Perhitungan). Dengan pengecualian yang jarang, mungkin perlu menambahkan beberapa referensi kecil dalam bentuk CSV atau XLSX ke model data yang ada. Fitur ini ada langsung di antarmuka grafis.
Di bawah ini kita akan melihat lebih dekat pada masing-masing dari dua komponen model data ini.
"Tabel acara" (alias "log peristiwa") mengandung setidaknya tiga kolom yang diperlukan:
- Pengidentifikasi proses adalah kunci unik untuk setiap instance proses (misalnya, referensi, insiden, atau nomor tugas). Dalam contoh pada Gambar 2, ini adalah kolom "CASE_ID".
- Aktivitas Ini adalah nama dari langkah dalam proses - semacam acara yang kami minati. Dari kegiatan itulah grafik proses akan disusun (kolom “ACARA”).
- Stempel waktu acara (kolom "TIMESTAMP").
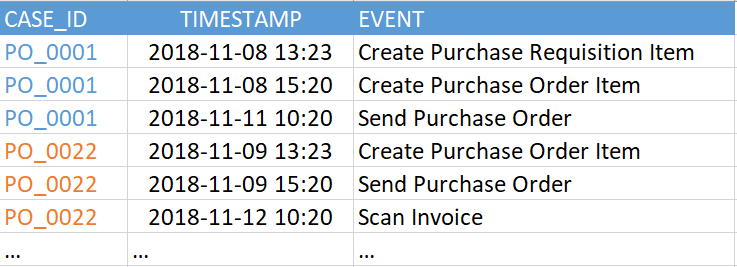 Gambar 2. Contoh tabel acara
Gambar 2. Contoh tabel acaraVersi saat ini dari SAP Process Mining oleh Celonis mendukung hingga 1000 peristiwa unik dalam model data tunggal. Artinya, jumlah nilai unik dalam kolom "ACARA" dalam contoh di atas (dalam tabel acara Anda mungkin disebut berbeda) harus tidak lebih dari 1000. Dan peristiwa itu sendiri (yaitu, baris dalam tabel ini) bisa cukup banyak. Kami telah melihat contoh ratusan juta peristiwa dalam satu model data.
Stempel waktu dapat diwakili baik oleh satu kolom, dan kemudian adalah tugas Anda untuk menentukan apa artinya - awal atau akhir suatu langkah, atau dua kolom, seperti pada Gambar 3, ketika awal dan akhir langkah ditunjukkan secara eksplisit. Perbedaan mendasar antara versi dua kolom adalah bahwa sistem akan dapat secara otomatis mengenali langkah-langkah yang dilakukan secara paralel satu sama lain. Ini terlihat ketika membandingkan waktu mulai dan akhir dari berbagai langkah.
 Gambar 3. Contoh tabel acara dengan dua stempel waktu
Gambar 3. Contoh tabel acara dengan dua stempel waktuSemua kolom lain dalam tabel ini adalah opsional. Grafik proses juga dapat berhasil dipulihkan dengan menggunakan tiga kolom yang diperlukan, tetapi akan sulit untuk menghilangkan perasaan bahwa ada sesuatu yang hilang. Oleh karena itu, sangat disarankan agar Anda tidak membatasi diri hanya pada set speaker minimal.
Kolom tambahan adalah setiap informasi yang menarik bagi Anda, yang berubah selama proses atau dikaitkan dengan peristiwa tertentu. Misalnya, nama karyawan yang membuat acara, kelompok kerja, prioritas aplikasi saat ini. Penekanan pada ketergantungan waktu tidak disengaja di sini. Disarankan agar Anda hanya menyisakan data yang dapat diubah dalam tabel acara. Semua informasi statis lainnya paling baik ditempatkan di direktori yang terpisah. Dengan kata lain, log peristiwa harus dinormalisasi, jika memungkinkan. Hal ini dilakukan bukan untuk mengurangi jumlah data, tetapi untuk memfasilitasi pekerjaan lebih lanjut dengan ekspresi PQL pada tahap membangun laporan analitis.
Biarkan semuanya ada di tempatnyaApa yang terjadi jika Anda menambahkan kolom dengan informasi referensi ke "tabel acara"? Secara umum, tidak ada hal buruk yang akan terjadi, setidaknya pada awalnya. Dan untuk pengujian cepat terhadap ide apa pun, opsi ini cukup cocok. Hanya ada dua konsekuensi negatif: reproduksi salinan data yang tidak perlu dan kesulitan tambahan dalam beberapa rumus analitik. Kesulitan-kesulitan ini bisa dihindari jika semua data tambahan telah diserahkan ke direktori. Secara umum, lebih baik melakukannya segera.
Sedikit tentang perizinanTabel acara dikaitkan dengan lisensi SAP Process Mining oleh Celonis. Satu model data = 1 lisensi = 1 log peristiwa. Dengan reservasi tertentu, kita dapat mengatakan bahwa 1 log peristiwa = 1 proses bisnis. Peringatan akan sebagai berikut: situasi mungkin muncul ketika beberapa proses masuk ke dalam satu log peristiwa, dan sebaliknya - beberapa log peristiwa sengaja dibuat untuk satu proses. Selain itu, istilah "proses bisnis" dapat diartikan dari sudut pandang data yang cukup luas. Oleh karena itu, untuk tujuan lisensi, untuk kriteria yang jelas, jumlah log peristiwa dipilih. Pada kriteria inilah seseorang harus mengandalkan.
DirektoriDirektori bersifat opsional, menambahkannya ke model data adalah opsional. Mereka mengandung informasi tambahan yang mungkin berguna untuk analisis proses. Tetapi, tidak seperti tabel peristiwa, informasi dalam direktori bersifat statis, itu tidak tergantung pada waktu peristiwa itu terjadi.
Satu kasus khusus harus disebutkan di sini. Ketika sampai pada data pengguna yang melakukan langkah-langkah dalam proses bisnis, muncul pertanyaan: apakah ini rujukan informasi? Di satu sisi, ya - ini adalah data statis. Akan menyenangkan untuk meninggalkan dalam tabel acara hanya “USER_ID” tertentu, yang menurutnya nama, posisi, dan departemen pengguna, keanggotaan dalam kelompok kerja, dll. Akan dikaitkan dengan aktivitas. Tetapi di sisi lain, mari kita bayangkan bahwa kita menganalisis proses bisnis pada rentang waktu 2-3 tahun. Selama waktu ini, pengguna dapat mengubah beberapa pos dan beralih antar departemen atau kelompok kerja. Ternyata ini adalah informasi yang sudah berubah dari waktu ke waktu. Dan dalam hal ini, harus dibiarkan di tabel acara, yang pada gilirannya akan mengarah pada fakta bahwa selain "USER_ID" di log acara akan muncul kolom seperti "kelompok kerja", "posisi", "departemen" dan bahkan "nama lengkap" (nama belakang) itu juga bisa berubah selama ini). Secara umum, pertanyaan apakah akan menormalkan informasi pengguna atau tidak tetap pada kebijaksanaan pelanggan.
Direktori dapat ditambahkan ke model data yang ada kapan saja.
Untuk melakukan ini cukup sederhana:
- Tabel dibuat di SAP HANA.
- Tabel ditambahkan ke model data umum menggunakan tombol "Impor Data".
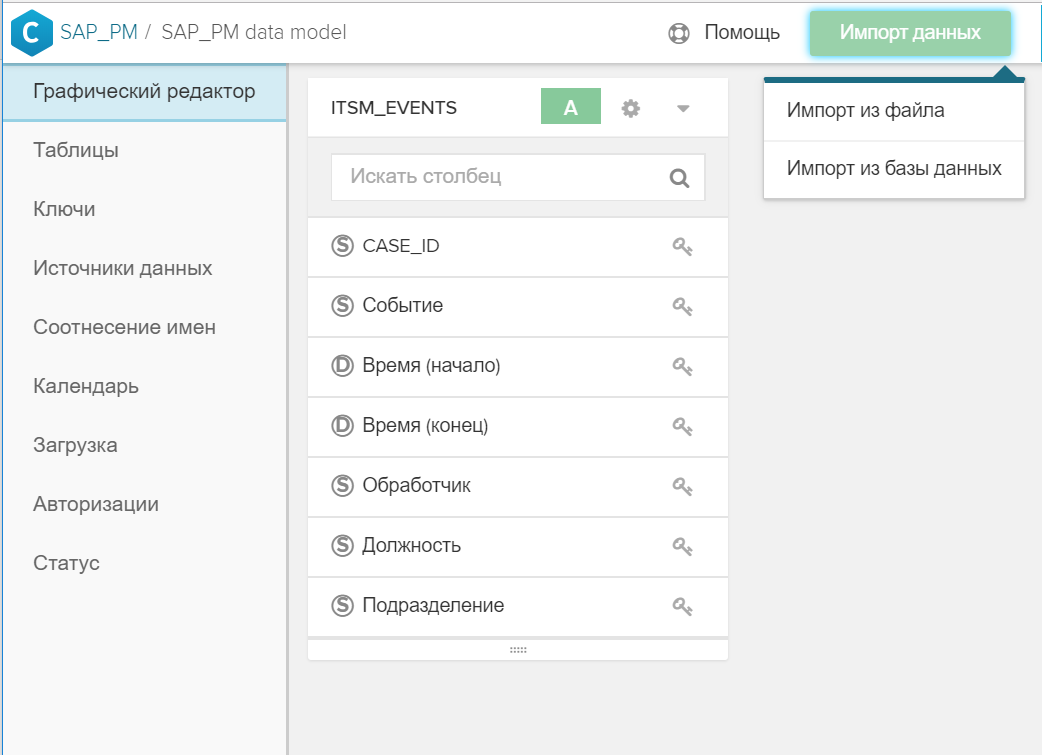
Gambar 4. Impor tabel atau file ke dalam model data yang ada - Kunci (atau kunci) ditunjukkan dalam antarmuka grafis, di mana direktori baru dikaitkan dengan tabel acara dan / atau dengan direktori lain. Untuk melakukan ini, cukup klik pada ikon
 dalam satu tabel dan kemudian pada yang sesuai di meja lain.
dalam satu tabel dan kemudian pada yang sesuai di meja lain.
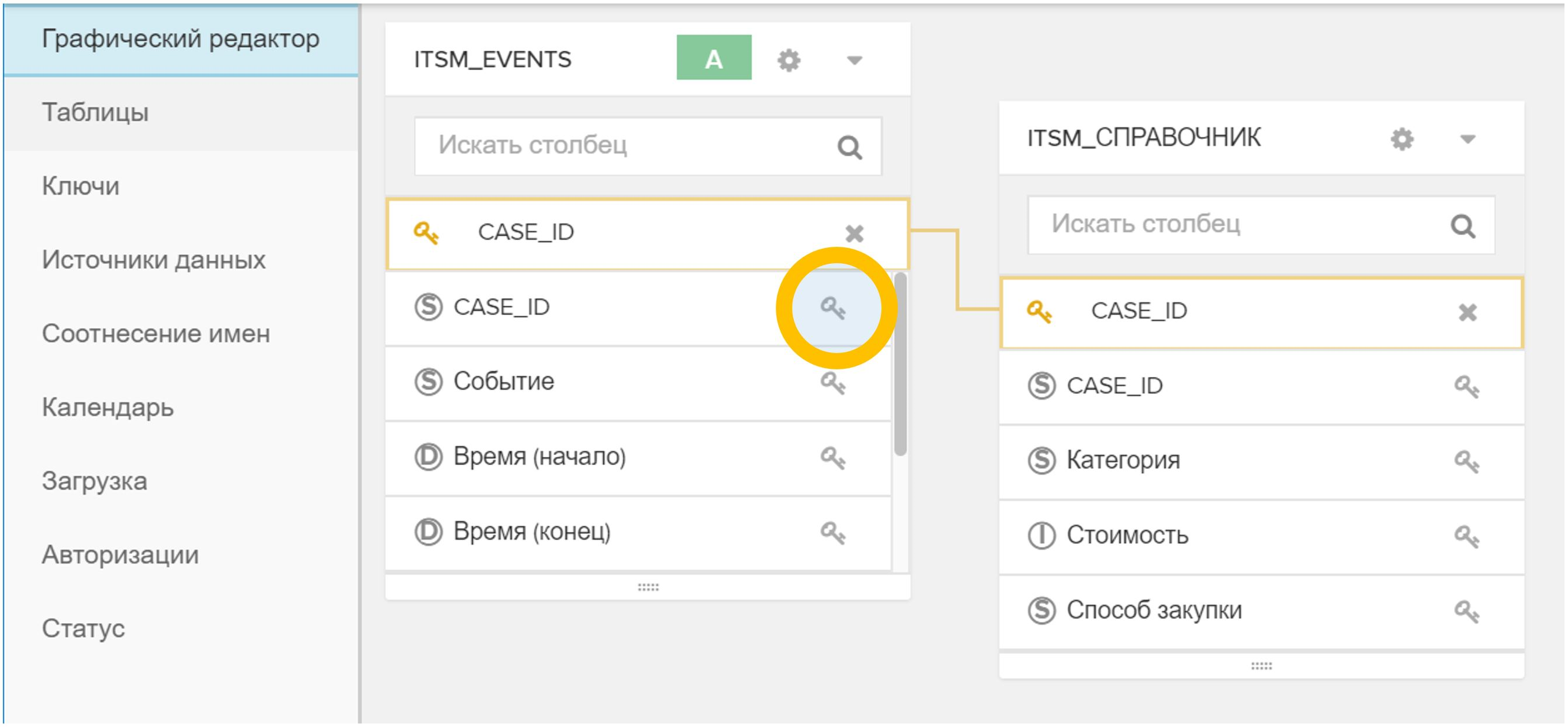
Gambar 5. Menghubungkan tabel dalam model data dengan bidang arbitrer (dalam hal ini, CASE_ID) - Di menu "Status", klik tombol "Reload from source". Proses ini biasanya memakan waktu beberapa detik.
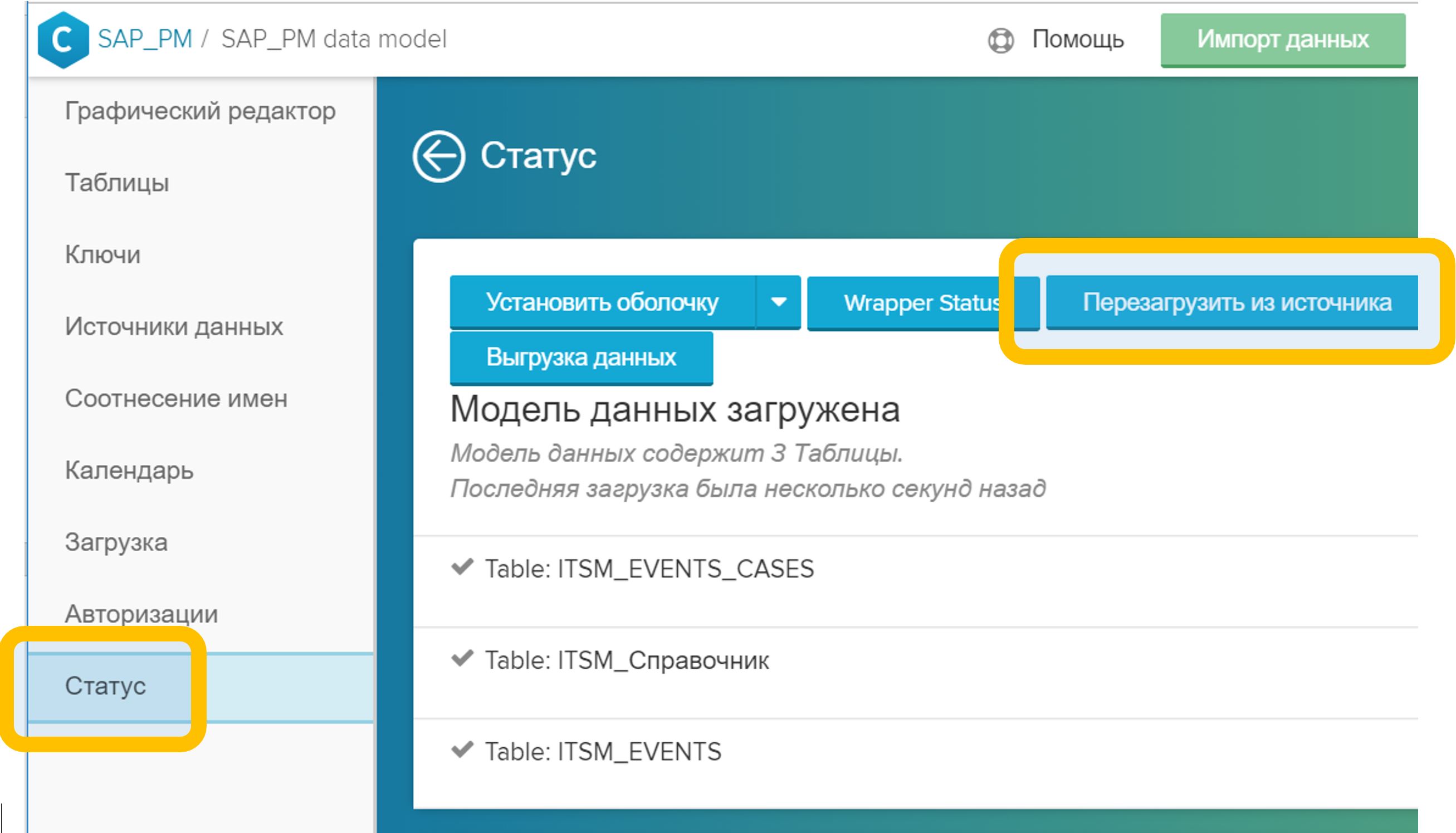 Gambar 6. Reload model data dari sumber
Gambar 6. Reload model data dari sumber
Setelah menyelesaikan langkah-langkah ini, Anda dapat langsung menggunakan analitik baru, baik dalam laporan baru maupun yang sudah ada. Pengayaan model data tidak membahayakan pekerjaan analis saat ini dengan cara apa pun: semua laporan yang dibuat terus bekerja, Anda tidak perlu mengulanginya atau mengubahnya.
Untuk direktori yang relatif kecil, ada satu kemungkinan lagi: tentu saja bukan versi yang sepenuhnya industri, tetapi juga bisa berguna. Ini tentang memuat file CSV, XLSX, DBF melalui antarmuka grafis langsung ke model data. Prosedurnya tetap sama persis seperti yang dijelaskan di atas, hanya alih-alih tabel database, file yang disiapkan sebelumnya digunakan, yang dimuat dengan tombol Impor Data.
CA Tabel: Referensi Proses InstansPembicaraan sebelumnya tentang buku referensi dimulai dengan fakta bahwa itu adalah opsional. Mereka dapat dihilangkan sama sekali dari model data dan terbatas pada tabel peristiwa. Ini hampir benar.
Satu referensi wajib memang ada. Ini harus berupa tabel yang ditandai dengan status "CA Table". CA adalah rangkaian acara. Dan, Anda dapat menebaknya, kunci dalam direktori ini adalah “CASE_ID” - pengidentifikasi unik dari instance proses. Referensi semacam itu menggambarkan sifat statis dari setiap proses proses. Contoh dari ITSM: penulis banding, layanan bisnis, tanggal penutupan, atau karyawan yang berhasil menyelesaikan insiden, tanda karakter massal, dll.
 Gambar 7. Contoh Tabel CA
Gambar 7. Contoh Tabel CANamun saya tidak banyak menipu Anda. Jika karena alasan tertentu Anda memutuskan untuk tidak menambahkan direktori yang diperlukan ke model data, sistem akan menghasilkannya sendiri. Hasil kerjanya dapat dilihat di tab Status: jika tabel acara Anda dipanggil, katakanlah, “ITSM_EVENTS”, maka tabel “ITSM_EVENTS_CASES” akan dihasilkan bersamaan dengan itu, seperti pada Gambar 8.
Gambar 8. Tabel rantai peristiwa (CA) yang dihasilkan secara otomatisTabel CA yang dihasilkan secara otomatis akan menjadi deskripsi yang sangat sederhana dari proses instance: kunci, jumlah acara, durasi proses (seolah-olah Anda mengelompokkan tabel acara dengan pengidentifikasi proses, menghitung jumlah baris dan perbedaan antara waktu langkah pertama dan terakhir). Oleh karena itu, masuk akal untuk membuat versi CA tabel Anda sendiri yang lebih menarik. Itu dapat ditambahkan ke model data kapan saja. Dalam hal ini, segera setelah Anda menambahkan Tabel CA Anda ke model, direktori yang dihasilkan oleh sistem (dalam kasus kami adalah "ITSM_EVENTS_CASES") akan secara otomatis dihapus dari model data.
Mengapa "CA Table" menarik? Dialah yang ditampilkan dalam antarmuka grafis sebagai detail proses. Jika analis, ketika bekerja dengan model data, menemukan sesuatu yang menarik dalam proses dan ingin turun ke contoh spesifik individu, maka ia akan menggunakan laporan "Lihat CA", yaitu, merinci. Setelah membuka laporan seperti itu, Anda akan menemukan di dalamnya direktori proses (dikombinasikan dengan tabel acara, tentu saja). Oleh karena itu, tambahkan ke "CA Table" segala sesuatu yang dapat digunakan analis untuk memahami sifat-sifat proses dan kondisi prosesnya.
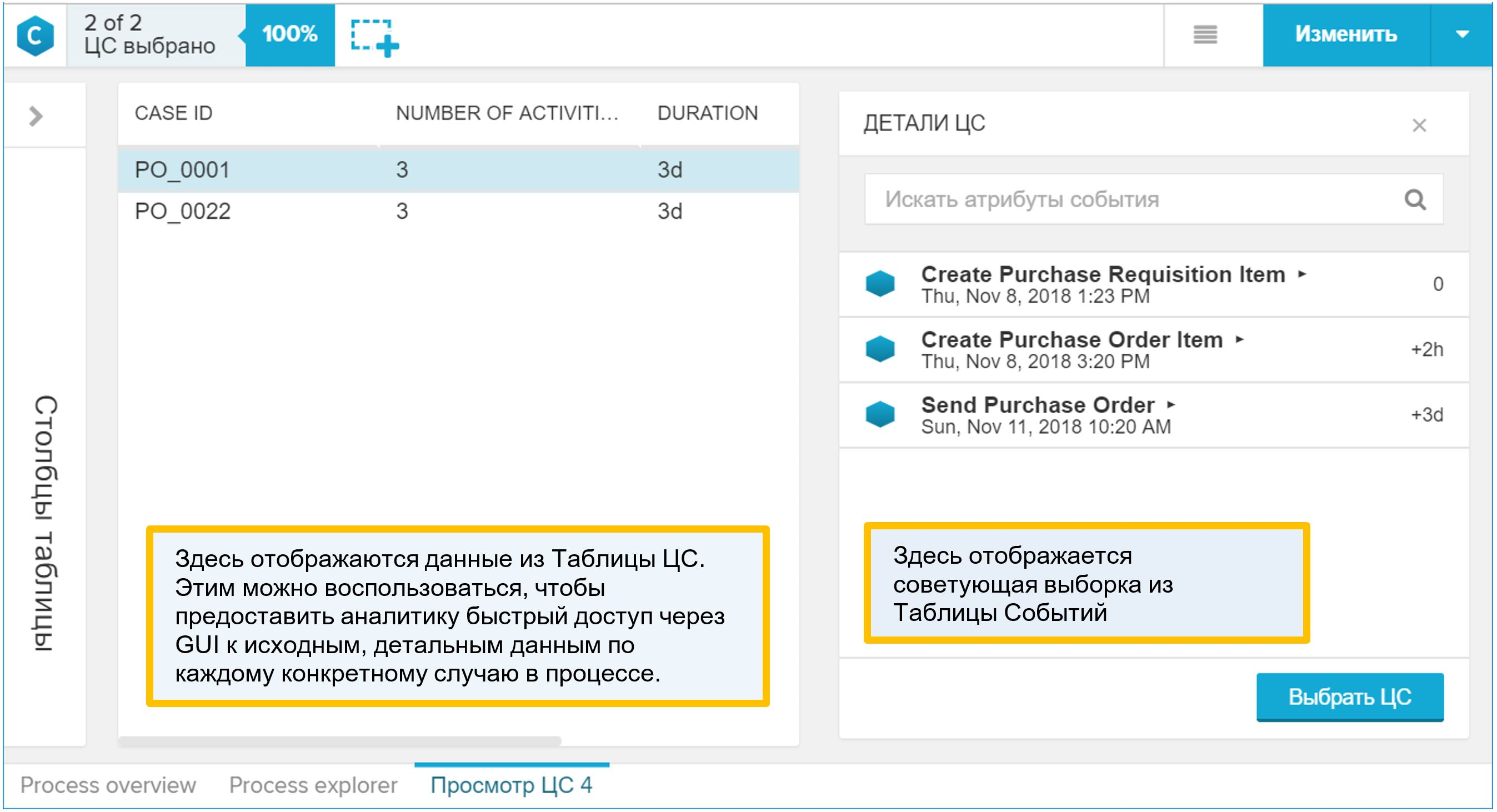 Gambar 9. Laporan contoh sintetis "Lihat CA"
Gambar 9. Laporan contoh sintetis "Lihat CA"Cara menambahkan referensi proses Anda ke model data:
- Tabel dibuat di SAP HANA.
- Tabel ditambahkan ke model data umum menggunakan tombol "Impor Data".
- Di antarmuka grafis, di properti tabel, Anda perlu mengatur peran "Tabel dengan CA".
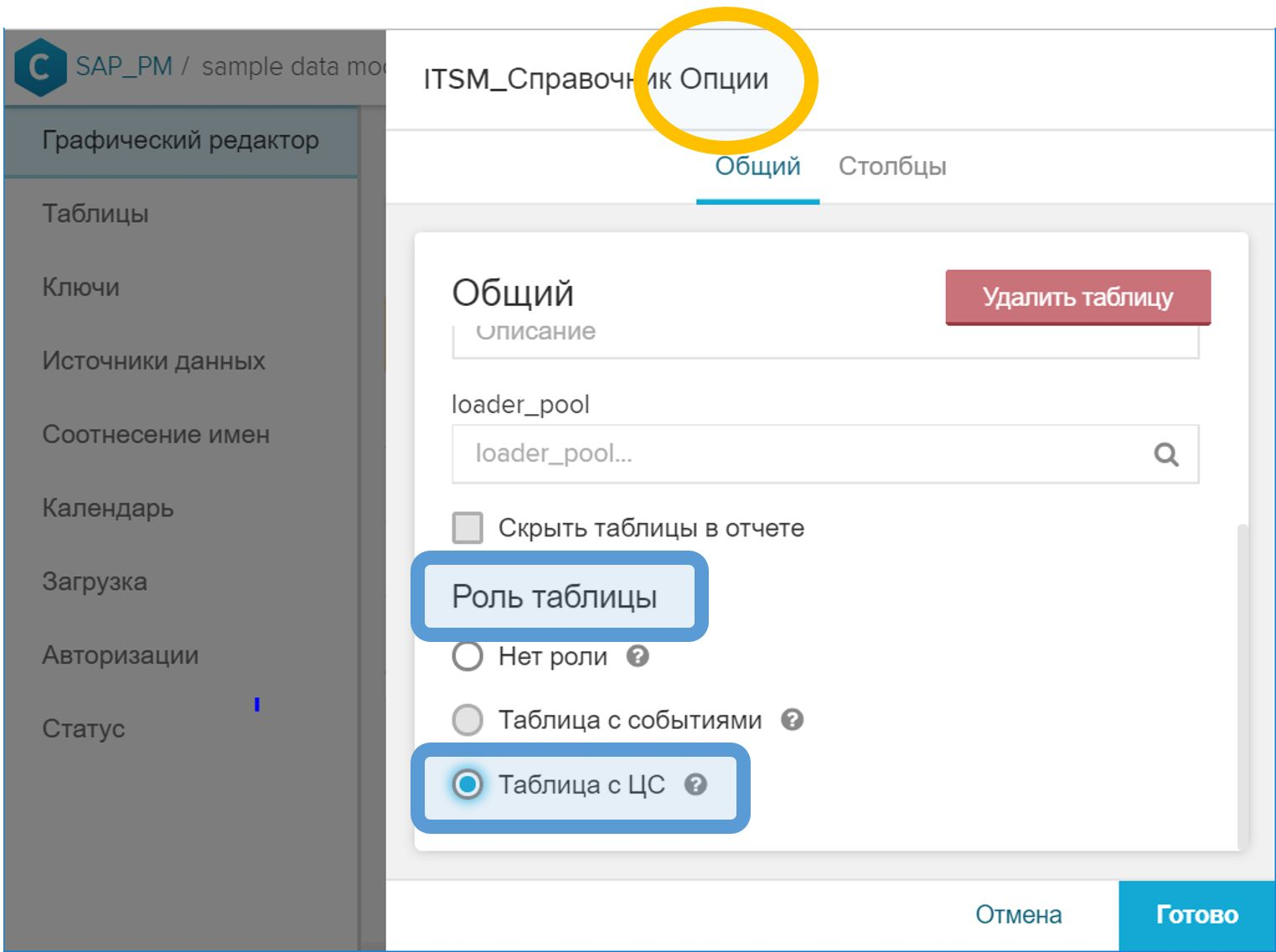
Gambar 10. Peran "Table with CA" untuk menunjukkan direktori instance proses - Di GUI, kaitkan tabel CA dengan tabel acara dengan ID proses. Langkah ini dilakukan dengan cara yang sama seperti dalam kasus direktori biasa - dengan tombol simbol kunci ( ) di seberang bidang yang sesuai.
- Di menu "Status", klik tombol "Reload from source".
Catatan penting: kolom "CASE_ID" (dalam setiap kasus, itu bisa disebut sebaliknya) dalam tabel CA, yang berisi pengidentifikasi proses dan digunakan untuk mengaitkan dengan tabel acara, seharusnya hanya berisi nilai unik. Ini cukup logis. Dan jika karena alasan tertentu tidak demikian, maka ketika memuat model data pada langkah (5), kesalahan yang sesuai akan dihasilkan (tentang ketidakmungkinan melakukan operasi "BERGABUNG" pada tabel acara dan tabel CA).
Membuat model data dari riwayat perubahan
Dalam praktiknya, kami menemukan sumber data yang sangat berbeda untuk Penambangan Proses. Komposisi mereka ditentukan oleh proses bisnis yang dipilih dan standar yang diadopsi oleh pelanggan.
Salah satu kasus yang paling umum adalah data dari sistem manajemen layanan TI (ITSM, IT Service Management), jadi kami memutuskan untuk menguraikan contoh ini terlebih dahulu. Faktanya, tidak ada ikatan ketat dengan ITSM dalam pendekatan ini. Itu dapat diterapkan dalam proses bisnis lain, di mana sumber data adalah riwayat perubahan atau log audit.
Apa yang harus ditanyakan dari IT?Jika Anda bukan karyawan TI atau spesialis yang melayani basis ITSM, maka bersiaplah untuk fakta bahwa Anda akan diminta untuk merumuskan jawaban yang tepat untuk pertanyaan "apa yang Anda bongkar?" atau "apa yang kamu inginkan dari kami?"
Dan ini tidak selalu diketahui - apa sebenarnya yang dibutuhkan. Analisis proses bisnis adalah studi, pencarian pola dan perburuan "wawasan". Jika kita tahu sebelumnya "wawasan" macam apa yang kita cari, maka ini bukan "wawasan" lagi. Bahkan, saya ingin mendapatkan "segalanya": atribut, hubungan, perubahan. Tetapi, seperti yang diperlihatkan oleh praktik, tidak pernah mungkin untuk mendapatkan jawaban akurat yang bagus untuk pertanyaan yang terlalu umum.
Ada dua kemungkinan jawaban untuk pertanyaan "apa yang Anda bongkar".
Pilihannya salah: minta dasar untuk membongkar semua perubahan dalam status aplikasi ditambah seperangkat atribut yang jelas (katakanlah, prioritas, artis, kelompok kerja, dll.). Pertama, Anda mendapatkan seperangkat analis terbatas: Anda sudah tahu apa yang akan Anda ukur dalam proses (di sinilah set atribut berasal), jadi Proses Penambangan akan berubah menjadi alat untuk menghitung proses KPI (sangat mudah, saya harus mengatakan, sebuah alat; tetapi tetap saya ingin lebih lanjut).
Kedua, masing-masing departemen TI secara berbeda menginterpretasikan permintaan untuk menambahkan atribut permintaan tambahan ke unggahan. Misalnya, ambil prioritas: itu dapat berubah saat bekerja pada panggilan. Banding didaftarkan dengan satu prioritas, kemudian spesialis dari kelompok kerja mengubahnya, dan ditutup dengan status yang berbeda. Dan sekarang pertanyaannya adalah: dalam bongkar muat yang Anda minta, momen apa yang sesuai dengan prioritas? Awalnya, tampaknya nilai prioritas harus sesuai dengan kolom "Tanggal dan waktu acara". Namun dalam kenyataannya sering kali ternyata hanya status permintaan yang sesuai dengan tanggal dan waktu yang ditentukan, dan semua kolom lainnya adalah nilai-nilai pada saat pembongkaran atau pada saat penutupan permintaan. Dan Anda tidak akan tahu tentang ini sekaligus.
Menurut saya ada opsi yang lebih baik. Anda dapat meminta data dalam bentuk tabel berikut:
- Jumlah banding, insiden, tugas (SD *, IM *, RT *, ...) adalah pengidentifikasi objek dalam sistem ITSM (NVARCHAR)
- Stempel waktu (TIMESTAMP)
- Nama Atribut (NVARCHAR)
- Nilai Lama (NVARCHAR)
- Nilai Baru (NVARCHAR)
- Siapa yang telah berubah (NVARCHAR)
Sebenarnya, ini tidak lebih dari sejarah perubahan atribut apa pun. Dalam antarmuka sistem ITSM Anda dapat melihat tabel seperti itu pada tab dengan nama "Sejarah" atau "Jurnal".
Keuntungan dari pendekatan ini jelas:
- Format unggah sederhana dan jelas. Dia akrab dengan para profesional TI dalam antarmuka grafis dari sistem itu sendiri. Seharusnya tidak menimbulkan pertanyaan dari basis.
- Kami mendapatkan daftar semua atribut yang mungkin dengan semua nilai yang mungkin. Ya, akan ada banyak dari mereka, kemungkinan besar beberapa ratus. Tetapi menyaring hal-hal yang tidak perlu dan tidak menarik sangat sederhana, tetapi setiap kali meminta pembongkaran tambahan tidak selalu mudah dan selalu lama (terutama ketika Anda tidak tahu atribut apa yang ada dalam sistem sama sekali).
- Ini adalah model data yang dapat diandalkan. Sulit untuk merusaknya, kecuali Anda sengaja membuat informasi palsu.
- Kami tahu persis apa yang dimiliki setiap atribut pada setiap saat. Ini penting karena kami menguji diri kami dan memastikan modelnya benar. Dan selama analisis, kita dapat menambahkan langkah-langkah menengah ke model ("memperbesar") dan menentukan nilai atribut yang benar di semua titik waktu tambahan.
Kerugian dari opsi kedua juga jelas. Dan mereka, menurut saya, dapat diselesaikan (sebagai lawan dari masalah data yang tidak lengkap):
- Skrip SQL untuk persiapan data menjadi agak lebih rumit - dibandingkan dengan opsi ketika tim berbasis IT melakukan persiapan data parsial untuk Anda (lihat versi pertama dari kueri di atas), tanpa curiga. Ya, dia (skrip) lebih rumit, tetapi dia sendirian. Saya pikir itu akan menjadi ide yang buruk untuk berbagi persiapan data antara tim ITSM dan tim Proses Penambangan. Idealnya, seluruh transformasi harus ditransfer ke tim Proses Penambangan sehingga mereka memahami apa yang sebenarnya terjadi dengan data, dan untuk meminimalkan gangguan dengan data di sisi sumber. Format pertukaran data yang sederhana membantu mencapai tujuan ini.
- Volume bongkar besar. Pesanannya mungkin ini: 10-30 GB / tahun untuk perusahaan besar. Tetapi memuat volume seperti itu ke dalam HANA sama sekali bukan masalah dan bahkan tidak dianggap sebagai tugas. Selain itu, kita berbicara tentang "mengunggah" hanya selama proyek percontohan, sementara integrasi ETL / ELT antara sumber data dan HANA (misalnya, HANA Smart Data Integration) akan digunakan dalam operasi industri, dan item ini akan berhenti menjadi masalah.
Saya tidak ingin mengatakan bahwa ini adalah satu-satunya cara yang benar untuk mendapatkan data dari sistem ITSM untuk tugas-tugas Proses Penambangan. Tetapi pada saat ini, saya cenderung percaya bahwa ini adalah format yang paling nyaman untuk tugas ini. Mungkin ada banyak pendekatan yang lebih menarik, dan saya akan sangat senang mendiskusikan ide-ide alternatif jika Anda membaginya dengan saya.
Pembuatan Tabel Acara
Jadi, di pintu keluar, kami memiliki riwayat perubahan atribut permintaan, insiden, panggilan, tugas, dan objek ITSM lainnya. Dari tabel seperti itu, dimungkinkan untuk menghasilkan kedua komponen utama dari model data Proses Penambangan: tabel peristiwa dan tabel CA.
Untuk menghasilkan acara berdasarkan riwayat perubahan, lakukan hal berikut:
- Dari riwayat perubahan, kumpulkan semua nilai unik dari kolom "nama atribut" (syarat).
- Tentukan perubahan atribut mana yang ingin Anda lihat pada grafik proses. Apa itu "acara" bagi kita?
- Membuat Tampilan Perhitungan yang sesuai atau menulis skrip SQL yang memfilter baris yang dipilih dari riwayat perubahan dan menghasilkan tabel acara.
Misalkan tabel perubahan adalah sebagai berikut:
CREATE COLUMN TABLE "SAP_PM"."ITSM_HISTORY" ( "CASE_ID" NVARCHAR(256), "ATTRIBUTE" NVARCHAR(256), "VALUE_OLD" NVARCHAR(1024), "VALUE_NEW" NVARCHAR(1024), "TS" TIMESTAMP, "USER" NVARCHAR(256) );
Pertama, lihat daftar semua atribut yang ada. Ini dapat dilakukan di menu "Open Data Preview" atau dengan query SQL sederhana seperti ini:
SELECT DISTINCT "ATTRIBUTE" FROM "SAP_PM"."ITSM_HISTORY";
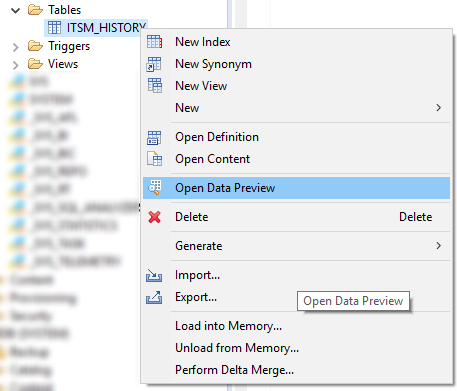 Gambar 11. Menu konteks dengan perintah Open Data Preview di SAP HANA Studio
Gambar 11. Menu konteks dengan perintah Open Data Preview di SAP HANA StudioKemudian kita menentukan komposisi atribut, yang perubahannya bagi kita merupakan peristiwa dalam proses. Berikut adalah daftar kandidat yang jelas untuk daftar tersebut:
- Status
- Diajak bekerja
- Kategori telah diubah
- Batas waktu dilanggar
- Waktu reaksi dilanggar
- Permintaan telah dikembalikan untuk revisi.
- Galat baris pertama
- Kelompok kerja
- Prioritas
Peristiwa utama di sini, tentu saja, adalah transisi antara status tugas banding / insiden \ aplikasi \. Nilai atribut "Status" (VALUE_NEW) itu sendiri akan menjadi nama langkah proses bagi kami. Karenanya, membuat tabel acara sebagai perkiraan pertama mungkin terlihat seperti ini:
CREATE COLUMN TABLE "SAP_PM"."ITSM_EVENTS" ( "CASE_ID" NVARCHAR(256) ,"EVENT" NVARCHAR(1024) ,"TS" TIMESTAMP ,"USER" NVARCHAR(256) ,"VALUE_OLD" NVARCHAR(1024) ,"VALUE_NEW" NVARCHAR(1024) ); INSERT INTO "SAP_PM"."ITSM_EVENTS" SELECT "CASE_ID" ,"VALUE_NEW" AS "EVENT" ,"TS" ,"USER" ,"VALUE_OLD" ,"VALUE_NEW" FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' ;
Mengubah atribut-atribut lainnya adalah langkah-langkah tambahan kami yang membuat meneliti proses ini menjadi lebih menarik. Komposisi mereka ditentukan oleh permintaan analis bisnis dan dapat berubah ketika praktik Proses Penambangan di perusahaan berkembang.
INSERT INTO "SAP_PM"."ITSM_EVENTS" SELECT "CASE_ID" ,"ATTRIBUTE" AS "EVENT" ,"TS" ,"USER" ,"VALUE_OLD" ,"VALUE_NEW" FROM "SAP_PM"."ITSM_HISTORY" WHERE "VALUE_OLD" IS NOT NULL AND "ATTRIBUTE" IN ( ' ' ,' ' ,' ' ,' ' ,' ' ,' 1- ' ,' ' ,'') );
Memperluas daftar atribut di WHERE "ATTRIBUTE" IN (.....) Filter Anda meningkatkan variasi langkah-langkah yang ditampilkan pada grafik proses. Perlu dicatat bahwa berbagai langkah tidak selalu merupakan berkah. Terkadang, perincian yang terlalu terperinci hanya membuat sulit untuk memahami prosesnya. Saya pikir bahwa setelah iterasi pertama Anda akan menentukan langkah-langkah mana yang diperlukan dan mana yang harus dikeluarkan dari model data (dan kebebasan untuk membuat keputusan seperti itu dan cepat beradaptasi dengan mereka adalah argumen lain yang mendukung transfer pekerjaan transformasi data ke sisi tim Proses Penambangan) .
Filter "VALUE_OLD" BUKAN NULL, kemungkinan besar Anda akan menggantinya dengan sesuatu yang lebih cocok untuk kondisi Anda dan untuk atribut yang dipilih. Saya akan mencoba menjelaskan arti dari filter ini. Dalam beberapa implementasi populer sistem ITSM, pada saat pendaftaran (pembukaan) banding, informasi tentang inisialisasi semua atribut objek dimasukkan ke dalam jurnal. Artinya, semua bidang ditandai dengan beberapa nilai default. Saat ini, VALUE_NEW akan berisi nilai inisialisasi yang sama, dan VALUE_OLD tidak akan berisi apa pun - lagipula, tidak ada riwayat hingga saat ini. Kami benar-benar tidak perlu catatan ini dalam proses. Mereka harus dihapus dengan filter yang sesuai dengan kondisi spesifik Anda. Filter semacam itu mungkin:
- "VALUE_OLD" BUKAN NULL
- "VALUE_NEW" = 'ya'
- Anda dapat fokus pada cap waktu (hanya ambil peristiwa yang terjadi setelah pendaftaran objek).
- Anda dapat fokus pada bidang "USER" jika akun sistem diinisialisasi.
- Segala kondisi lain yang Anda alami.
CA Table Generation
Riwayat perubahan yang sama yang melayani kami sebagai sumber acara juga akan berguna untuk membuat direktori instance proses (CA Tables). Algoritma serupa:
1. Tetapkan daftar atribut yang:
a. Jangan mengubah selama pengerjaan aplikasi, misalnya, penulis banding dan departemennya, penilaian pengguna atas hasil pekerjaan, bendera pelanggaran batas waktu.
b. Mereka dapat berubah, tetapi kami hanya tertarik pada nilai pada titik-titik tertentu: pada saat pendaftaran, penutupan, saat merekrut, mentransfer dari baris ke-2 ke baris ke-1, dll.
c. Mereka dapat berubah, tetapi kami hanya tertarik pada nilai gabungan (maksimum, minimum, kuantitas, dll.)
2. Buat tabel diagonal dengan set kolom yang diinginkan. Setiap atribut yang menarik bagi kami akan menghasilkan kumpulan barisnya sendiri (sesuai dengan jumlah instance proses), di mana hanya satu kolom yang akan memiliki nilai, dan semua sisanya akan kosong (NULL).
3. Kami menciutkan tabel diagonal ke direktori akhir menggunakan pengelompokan oleh pengidentifikasi proses.
Contoh atribut yang masuk akal untuk dimasukkan ke dalam tabel CA (dalam praktiknya, daftar ini bisa lebih lama):
- Layanan
- Sistem IT
- Penulis
- Organisasi Penulis
- Peringkat pengguna untuk kualitas solusi
- Jumlah pengembalian untuk bekerja
- Kapan dibawa kerja
- Dibuat oleh
- Siapa yang tutup
- Dipecahkan oleh Baris 1
- Klasifikasi / perutean tidak valid
- Batas waktu
- Pelanggaran batas waktu
Satu dan atribut yang sama dapat berupa sumber suatu peristiwa dalam suatu proses atau properti dari suatu proses contoh. Misalnya, atribut "Prioritas". Di satu sisi, kami tertarik pada signifikansinya pada saat pendaftaran banding, dan di sisi lain, semua fakta perubahan dalam atribut ini dapat diserahkan ke grafik proses sebagai langkah independen.
Contoh lain adalah Tenggat. Ini adalah properti referensi yang jelas dari proses, tetapi Anda dapat membuat langkah virtual dalam grafik proses dari proses tersebut: operasi seperti "Tenggat Waktu" tidak ada dalam proses, tetapi jika kami menambahkan entri yang sesuai ke Tabel Acara, kami akan membuatnya secara artifisial dan dapat memvisualisasikan lokasi relatif terhadap waktu pelaksanaan langkah-langkah lain langsung pada grafik proses. Ini nyaman untuk analisis cepat.
Secara umum, ketika kita membuat properti proses berdasarkan riwayat perubahan atribut, sumber informasi yang berguna bagi kita bisa menjadi:
- Nilai atribut itu sendiri (contoh: "Nilai pengguna")
- Pengguna yang mengubahnya
- Ubah waktu
- Waktu ketika atribut mengambil nilai tertentu (contoh: atribut "Tenggat waktu dilanggar" tidak tertarik pada nilai atribut itu sendiri, tetapi pada saat itu berubah menjadi setara dengan bendera yang dinaikkan - misalnya, 'ya' atau 1)
- Fakta bahwa atribut hadir dalam sejarah (contoh: "Kejadian massal" dengan nilai 'ya')
Daftar ini, tentu saja, dapat dilanjutkan dengan ide-ide lain untuk menggunakan atribut dan semua yang terhubung dengannya.
Sekarang kita telah memutuskan daftar properti yang diminati, mari kita lihat salah satu skenario yang mungkin untuk menghasilkan tabel CA. Pertama, buat tabel itu sendiri dengan set kolom yang kita tentukan di atas untuk diri kita sendiri:
CREATE COLUMN TABLE "SAP_PM"."ITSM_CASES" ( "CASE_ID" NVARCHAR(256) NOT NULL ,"CATEGORY" NVARCHAR(256) DEFAULT NULL ,"AUTHOR" NVARCHAR(256) DEFAULT NULL ,"RESOLVER" NVARCHAR(256) DEFAULT NULL ,"RAITING" INTEGER DEFAULT NULL ,"OPEN_TIME" TIMESTAMP DEFAULT NULL ,"START_TIME" TIMESTAMP DEFAULT NULL ,"DEADLINE" TIMESTAMP DEFAULT NULL );
Kita juga akan membutuhkan tabel sementara “ITSM_CASES_STAGING”, yang akan memungkinkan kita untuk memilah daftar atribut yang rata untuk kolom properti yang diperlukan dalam direktori instance proses:
CREATE COLUMN TABLE "SAP_PM"."ITSM_CASES_STAGING" LIKE "SAP_PM"."ITSM_CASES" WITH NO DATA;
Ini akan menjadi tabel diagonal - di setiap baris hanya dua bidang yang memiliki nilai: "CASE_ID", mis. pengidentifikasi proses, dan satu bidang tunggal dengan properti proses. Kolom yang tersisa di baris akan kosong (NULL). Pada tahap akhir, kita dengan mudah memecah diagonal menjadi baris dengan agregasi sederhana dan dengan demikian mendapatkan tabel CA yang kita butuhkan.
Contoh untuk kategori perawatan:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "CATEGORY") SELECT "CASE_ID", LAST_VALUE("VALUE_NEW" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' GROUP BY "CASE_ID" ;
Misalkan penulis adalah pengguna non-sistem pertama dalam sejarah banding yang mendaftar banding (dalam kasus khusus Anda, kriteria mungkin lebih akurat):
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "AUTHOR") SELECT "CASE_ID", FIRST_VALUE("USER" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "USER" != 'SYSTEM' GROUP BY "CASE_ID" ;
Jika kami menganggap bahwa prosesor, yang meletakkan status terakhir "Solusi yang diusulkan" (dan solusi dapat ditawarkan berulang kali, tetapi hanya yang terakhir diperbaiki), berhasil menyelesaikan masalah, maka properti dari proses instance ini dapat dirumuskan sebagai berikut:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "RESOLVER") SELECT "CASE_ID", LAST_VALUE("USER" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' AND "VALUE_NEW" = ' ' GROUP BY "CASE_ID" ;
Peringkat pengguna (kepuasannya dengan keputusan):
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "RAITING") SELECT "CASE_ID", TO_INTEGER(LAST_VALUE("VALUE_NEW" ORDER BY "TS")) FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND "VALUE_NEW" IS NOT NULL GROUP BY "CASE_ID" ;
Waktu pendaftaran (pembuatan) hanyalah catatan paling awal dalam sejarah sirkulasi:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "OPEN_TIME") SELECT "CASE_ID", MIN("TS") FROM "SAP_PM"."ITSM_HISTORY" GROUP BY "CASE_ID" ;
Waktu reaksi adalah karakteristik penting dari kualitas layanan. Untuk menghitungnya, Anda perlu tahu kapan bendera “Dibawa ke kantor” pertama kali dinaikkan:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "START_TIME") SELECT "CASE_ID", MIN("TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND 'VALUE_NEW' = '' GROUP BY "CASE_ID" ;
Tenggat waktu digunakan untuk menghitung KPI untuk tanggapan tepat waktu terhadap banding atau penyelesaian insiden. Dalam prosesnya, batas waktu mungkin berulang kali berubah. Untuk menghitung KPI, kita perlu mengetahui versi terbaru dari atribut ini. Jika kita ingin secara eksplisit melacak bagaimana tenggat waktu telah berubah, yaitu untuk menampilkan kasus-kasus seperti itu pada grafik proses, kita juga harus menggunakan atribut ini untuk menghasilkan entri dalam tabel acara. Ini adalah contoh atribut, yang secara bersamaan berfungsi sebagai properti dari proses dan sumber acara.
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "DEADLINE") SELECT "CASE_ID", MAX(TO_DATE("VALUE_NEW")) FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND 'VALUE_NEW' IS NOT NULL GROUP BY "CASE_ID" ;
Semua contoh di atas adalah dari jenis yang sama. Dengan analogi dengan mereka, tabel CA dapat diperluas dengan atribut apa pun yang menarik minat Anda. Selain itu, ini bisa dilakukan setelah dimulainya proyek, sistem ini memungkinkan Anda untuk memperluas model data selama operasinya.
Ketika tabel diagonal sementara kami diisi dengan properti instance proses, yang tersisa hanyalah melakukan agregasi dan mendapatkan tabel CA final:
INSERT INTO "SAP_PM"."ITSM_CASES" SELECT "CASE_ID" ,MAX("CATEGORY") ,MAX("AUTHOR") ,MAX("RESOLVER") ,MAX("RAITING") ,MAX("OPEN_TIME") ,MAX("START_TIME") ,MAX("DEADLINE") FROM "SAP_PM"."ITSM_CASES_STAGING" GROUP BY "CASE_ID" ;
Setelah itu, kita tidak lagi membutuhkan data dalam tabel sementara. Tabel itu sendiri dapat dibiarkan terus mengulangi proses di atas secara teratur untuk memperbarui model data dalam Proses Penambangan:
DELETE FROM "SAP_PM"."ITSM_CASES_STAGING";
Kiat untuk menyiapkan dan membersihkan file CSV untuk proyek percontohan
Anda mungkin akan mulai berkenalan dengan Penambangan Proses disiplin dengan proyek percontohan. Dalam hal ini, akses langsung ke sumber data tidak dapat diperoleh, baik karyawan TI dan petugas keamanan informasi akan menolak ini. Ini berarti bahwa sebagai bagian dari proyek percontohan, kita harus bekerja dengan mengekspor data dari sistem perusahaan ke file CSV dan kemudian mengimpornya ke SAP HANA untuk membangun model data.
Dalam instalasi industri, tidak akan ada ekspor ke CSV. Sebagai gantinya, alat integrasi SAP HANA akan digunakan, khususnya: Integrasi Data Cerdas (SDI), Akses Data Cerdas (SDA) atau Server Replikasi Transformasi Lansekap SAP (SLT). Tetapi untuk pengujian dan pengenalan dengan teknologi, mengekspor ke file teks CSV adalah metode yang lebih sederhana secara organisasi. Karenanya, akan bermanfaat untuk berbagi dengan Anda beberapa kiat untuk menyiapkan data dalam CSV agar impor cepat dan berhasil ke dalam basis data.
Persyaratan format yang disarankan untuk file itu sendiri ketika mengekspor:
- Format File: CSV
- Pengkodean: UTF8
- Separator Bidang: karakter apa saja yang cocok untuk Anda. Misalnya, “|” atau "^" atau "~". Logika pilihannya sederhana - kita harus mencoba menghindari situasi ketika "split" terkandung dalam data itu sendiri.
- Hal ini diperlukan untuk menghapus pemisah dari nilai kolom. Ya, Anda mungkin mengatakan bahwa untuk ini, sebenarnya, ada tanda kutip. Tetapi, seperti yang ditunjukkan oleh pengalaman, dengan tanda kutip, banyak masalah muncul. Secara umum, mari kita hapus (atau ganti) karakter pemisah dari nilai bidang. Proyek percontohan Anda tidak akan banyak menderita karena ketidaktepatan tersebut, tetapi waktu untuk persiapan data sangat terasa.
- Tanda kutip: hapus semua tanda kutip dari nilai bidang. Tanda kutip sering ditemukan dalam nama perusahaan - katakanlah, Kalinka LLC. Tetapi ada opsi seperti itu: MPZ Kalinka LLC. Dan sekarang ini adalah kesulitan besar. Tanda kutip dalam nilai bidang harus disertai dengan simbol "\", atau dihapus, diganti dengan yang lain. Ini paling dapat diandalkan untuk menghapusnya. Nilai bidang tidak akan banyak menderita dari ini.
- Transfer kereta: hapus semua karakter CHAR (10) dan CHAR (13) dari nilai bidang. Kalau tidak, impor dari CSV tidak akan mungkin.
Jika kita memperhitungkan poin akun (4) + (5) + (6), maka masuk akal untuk menggunakan konstruksi berikut dalam seleksi:
REPLACE(REPLACE(REPLACE(REPLACE("COLUMN", '|', ';'), '"', ''), CHAR(13), ' '), CHAR(10), ' ') as "COLUMN"
Selanjutnya, ketika file CSV siap, mereka perlu disalin ke server HANA dalam folder yang dinyatakan aman untuk mengimpor file (misalnya, / usr / getah / HDB / impor). Mengimpor data ke HANA dari file CSV lokal adalah prosedur yang cukup cepat, asalkan file tersebut "bersih":
- setiap baris tabel di masa depan berada dalam satu dan hanya satu baris file;
- jumlah kolom di semua baris adalah sama;
- tanda kutip dipasangkan atau hilang sama sekali;
- tanda kutip dalam nilai-nilai bidang baik menyertai "melarikan diri" -simbol "\", atau tidak ada sama sekali;
- Pengkodean UTF-8 (dan bukan UTF8-BOM, seperti yang terjadi ketika mengekspor ke sistem Windows).
Untuk memeriksa file CSV sebelum mengimpornya dan menemukan area masalah jika ada (dan dengan probabilitas 99%), Anda dapat menggunakan perintah berikut:
1. Periksa karakter BOM di awal file:
file data.csv
Jika hasil dari perintahnya seperti ini: “Teks UTF-8 Unicode (with BOM)”, ini berarti bahwa penyandiannya adalah UTF8-BOM dan Anda harus menghapus karakter BOM dari file. Anda dapat menghapusnya sebagai berikut:
sed -i's 1s / ^ \ xEF \ xBB \ xBF // ' data.csv
2. Jumlah kolom harus sama untuk setiap baris file:
cat data.csv
| awk -F »;" '{print NF}' | sort | uniqatau seperti ini:
untuk saya dalam $ (ls * .csv); lakukan echo $ i; kucing $ i | awk -F ';' '{print NF}' | sortir | uniq -c; gema; dilakukan;Ubah ';' dalam parameter F ke apa pemisah bidang dalam kasus Anda.
Sebagai hasil dari perintah ini, Anda mendapatkan distribusi baris dengan jumlah kolom di setiap baris. Idealnya, Anda harus mendapatkan sesuatu seperti ini:
EKKO.csv
79536 200
Di sini file berisi 79536 baris, dan semuanya berisi 200 kolom. Tidak ada baris dengan jumlah kolom yang berbeda. Seharusnya begitu.
Dan ini adalah contoh hasil yang salah:
LFA1.csv
73636 180
7 181
Di sini kita melihat bahwa sebagian besar baris mengandung 180 kolom (dan, mungkin, ini adalah jumlah kolom yang benar), tetapi ada baris dengan kolom ke-181. Artinya, salah satu bidang berisi tanda pemisah nilainya. Kami beruntung dan hanya ada 7 potong garis seperti itu - mereka dapat dengan mudah dilihat secara manual dan entah bagaimana diperbaiki. Anda dapat melihat garis di mana jumlah kolom tidak sama dengan 180, seperti ini:
cat data.csv
| awk -F ";" '{if (NF! = 180) {print $ 0}}'Catatan tentang menggunakan perintah di atas. Perintah-perintah ini tidak akan memperhatikan tanda kutip. Jika tanda pembatas terdapat di bidang terlampir dalam tanda kutip (yang berarti bahwa semuanya baik-baik saja di sini dari sudut pandang impor ke dalam basis data), maka memeriksa dengan metode ini akan mengungkapkan masalah palsu (kolom tambahan) - ini juga harus diperhitungkan ketika menganalisis hasil.
3. Jika tanda kutip tidak berpasangan dan tidak dapat menyelesaikan masalah ini, maka Anda dapat menghapus semua tanda kutip dari file:
sed -i 's / "// g' data.csv
Bahaya dari pendekatan ini adalah bahwa jika nilai bidang berisi karakter pemisah, maka jumlah kolom di baris akan berubah. Oleh karena itu, karakter pemisah harus dihapus dari nilai bidang pada tahap ekspor (hapus atau ganti dengan karakter lain).
4. Bidang kosong
Menghadapi situasi di mana impor data yang berhasil dicegah oleh nilai-nilai bidang kosong dalam formulir ini:
; ""
Dimana “;” Apakah tanda pemisah bidang dalam hal ini. Yaitu, bidangnya adalah dua tanda kutip ganda (string kosong kosong). Jika Anda tiba-tiba tidak dapat mengimpor data, dan Anda mencurigai bahwa masalahnya mungkin adalah bidang kosong, maka coba ganti "" dengan NULL
sed -i 's /; "" /; NULL / g' data.csv
(gantikan ";" untuk opsi pemisah Anda)
5. Berguna untuk mencari format angka "kotor" dalam data:
; "0" (angka berisi spasi)
; "100.10-" (tanda "-" setelah nomor tersebut)
Bugatti 3/4 "300 crane - dimensi inci ditunjukkan oleh tanda kutip ganda - dan ini secara otomatis mengarah pada masalah tanda kutip tidak berpasangan saat mengekspor.
Sayangnya, ini bukan daftar lengkap masalah yang mungkin terjadi dengan format data yang tidak nyaman untuk diimpor ke dalam basis data. Akan sangat bagus untuk mengetahui pilihan Anda dari latihan: kesalahan aneh apa yang Anda temui? Bagaimana Anda mendeteksi dan menghilangkannya. Bagikan komentar Anda.
Kesimpulan
Secara umum, model data untuk Proses Penambangan sangat sederhana: tabel acara plus, opsional, buku referensi tambahan. Tapi seperti yang biasanya terjadi, itu mulai tampak sederhana hanya ketika setidaknya satu siklus tugas telah selesai - maka seluruh proses terlihat secara keseluruhan, dan rencana kerja jelas. Saya harap artikel ini membantu Anda memahami persiapan data untuk proyek Proses Penambangan pertama Anda. Secara umum, proses persiapan terlihat seperti ini:
- Meminta riwayat perubahan dari pemilik data
- Memeriksa dan membersihkan unggahan (persiapan file CSV)
- Impor ke SAP HANA
- Bangunan meja acara
- Membangun tabel CA (referensi proses)
Dan, pada kenyataannya, ini adalah di mana persiapan model data dimulai dan bagian yang paling menarik dimulai - Proses Penambangan. Jika Anda memiliki pertanyaan selama implementasi proyek Proses Penambangan, jangan ragu untuk menulis di komentar, saya akan dengan senang hati membantu. Semoga beruntung
Fedor Pavlov, pakar platform SAP CIS