Halo semuanya. Kami membagikan terjemahan dari bagian akhir artikel, disiapkan khusus untuk siswa kursus
Data Engineer . Bagian pertama dapat ditemukan di
sini .
Apache Beam dan DataFlow untuk jaringan pipa real-time
Pengaturan Google Cloud
Catatan: Saya menggunakan Google Cloud Shell untuk memulai pipeline dan menerbitkan data log pengguna, karena saya punya masalah menjalankan pipeline di Python 3. Google Cloud Shell menggunakan Python 2, yang lebih kompatibel dengan Apache Beam.
Untuk memulai conveyor, kita perlu mempelajari sedikit pengaturannya. Bagi Anda yang belum pernah menggunakan GCP sebelumnya, Anda harus menyelesaikan 6 langkah berikut di
halaman ini.
Setelah itu, kami perlu mengunggah skrip kami ke Google Cloud Storage dan menyalinnya ke Google Cloud Shel kami. Mengunggah ke penyimpanan cloud cukup sepele (deskripsi dapat ditemukan di
sini ). Untuk menyalin file kami, kami dapat membuka Google Cloud Shel dari toolbar dengan mengklik ikon pertama di sebelah kiri pada Gambar 2 di bawah ini.
 Gambar 2
Gambar 2Perintah yang kita butuhkan untuk menyalin file dan menginstal perpustakaan yang diperlukan tercantum di bawah ini.
Membuat database dan tabel kami
Setelah kita menyelesaikan semua langkah konfigurasi, hal selanjutnya yang perlu kita lakukan adalah membuat dataset dan tabel di BigQuery. Ada beberapa cara untuk melakukan ini, tetapi yang paling mudah adalah menggunakan konsol Google Cloud dengan terlebih dahulu membuat dataset. Anda bisa mengikuti langkah-langkah di
tautan berikut untuk membuat tabel dengan skema. Tabel kami akan memiliki
7 kolom yang sesuai dengan komponen setiap log pengguna. Untuk kenyamanan, kami akan mendefinisikan semua kolom sebagai string (tipe string), dengan pengecualian variabel timelocal, dan beri nama sesuai dengan variabel yang kami buat sebelumnya. Tata letak tabel kita akan terlihat seperti Gambar 3.
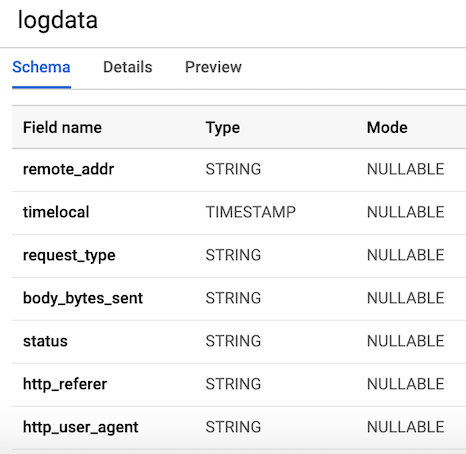 Gambar 3. Tata letak tabel
Gambar 3. Tata letak tabelPublikasikan data log pengguna
Pub / Sub adalah komponen penting dari pipa kami karena memungkinkan beberapa aplikasi independen untuk saling berinteraksi. Secara khusus, ini berfungsi sebagai perantara yang memungkinkan kami untuk mengirim dan menerima pesan antar aplikasi. Hal pertama yang perlu kita lakukan adalah membuat topik. Cukup buka Pub / Sub di konsol dan tekan CREATE TOPIC.
Kode di bawah ini memanggil skrip kami untuk menghasilkan data log yang ditentukan di atas, dan kemudian menghubungkan dan mengirim log ke Pub / Sub. Satu-satunya hal yang perlu kita lakukan adalah membuat objek
PublisherClient , tentukan path ke topik menggunakan metode
topic_path dan panggil fungsi
publish dengan
topic_path dan data. Harap perhatikan bahwa kami mengimpor
generate_log_line dari skrip
stream_logs kami, jadi pastikan bahwa file-file ini berada di folder yang sama, jika tidak Anda akan mendapatkan kesalahan impor. Kemudian kita dapat menjalankan ini melalui konsol google kita menggunakan:
python publish.py
from stream_logs import generate_log_line import logging from google.cloud import pubsub_v1 import random import time PROJECT_ID="user-logs-237110" TOPIC = "userlogs" publisher = pubsub_v1.PublisherClient() topic_path = publisher.topic_path(PROJECT_ID, TOPIC) def publish(publisher, topic, message): data = message.encode('utf-8') return publisher.publish(topic_path, data = data) def callback(message_future):
Segera setelah file dimulai, kita dapat mengamati output data log ke konsol, seperti yang ditunjukkan pada gambar di bawah ini. Script ini akan berfungsi sampai kita menggunakan
CTRL + C untuk menyelesaikannya.
 Gambar 4. Output dari
Gambar 4. Output dari publish_logs.py
Menulis kode untuk saluran pipa kami
Sekarang kami telah menyiapkan segalanya, kami dapat melanjutkan ke bagian yang paling menarik - menulis kode pipa kami menggunakan Beam dan Python. Untuk membuat pipa Beam, kita perlu membuat objek pipa (p). Setelah kami membuat objek pipa, kami dapat menerapkan beberapa fungsi satu demi satu menggunakan operator
pipe (|) . Secara umum, alur kerjanya terlihat seperti gambar di bawah ini.
[Final Output PCollection] = ([Initial Input PCollection] | [First Transform] | [Second Transform] | [Third Transform])
Dalam kode kami, kami akan membuat dua fungsi yang ditentukan pengguna. Fungsi
regex_clean , yang memindai data dan mengambil baris terkait berdasarkan daftar POLA menggunakan fungsi pencarian ulang. Fungsi mengembalikan string yang dipisahkan koma. Jika Anda bukan ahli ekspresi reguler, saya sarankan Anda membaca
tutorial ini dan berlatih di notepad untuk memeriksa kode. Setelah itu, kita mendefinisikan fungsi ParDo kustom yang disebut
Split , yang merupakan variasi dari transformasi Beam untuk pemrosesan paralel. Dengan Python, ini dilakukan dengan cara khusus - kita harus membuat kelas yang mewarisi dari kelas DoFn Beam. Fungsi Split mengambil string yang diurai dari fungsi sebelumnya dan mengembalikan daftar kamus dengan kunci yang sesuai dengan nama kolom di tabel BigQuery kami. Ada sesuatu yang perlu diperhatikan tentang fungsi ini: Saya harus mengimpor
datetime di dalam fungsi untuk membuatnya berfungsi. Saya menerima kesalahan impor di awal file, yang aneh. Daftar ini kemudian diteruskan ke fungsi
WriteToBigQuery , yang hanya menambahkan data kami ke tabel. Kode untuk Pekerjaan Batch DataFlow dan Streaming Pekerjaan DataFlow ditampilkan di bawah ini. Satu-satunya perbedaan antara batch dan stream code adalah bahwa dalam pemrosesan batch kami membaca CSV dari
src_path menggunakan fungsi
ReadFromText dari Beam.
Pekerjaan Batch DataFlow (pemrosesan paket)
import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import bigquery import re import logging import sys PROJECT='user-logs-237110' schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' src_path = "user_log_fileC.txt" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'status': element[3], 'body_bytes_sent': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(): p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.textio.ReadFromText(src_path) | "clean address" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) p.run() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
Pekerjaan Streaming DataFlow
from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import pubsub_v1 from google.cloud import bigquery import apache_beam as beam import logging import argparse import sys import re PROJECT="user-logs-237110" schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' TOPIC = "projects/user-logs-237110/topics/userlogs" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'body_bytes_sent': element[3], 'status': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(argv=None): parser = argparse.ArgumentParser() parser.add_argument("--input_topic") parser.add_argument("--output") known_args = parser.parse_known_args(argv) p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.ReadFromPubSub(topic=TOPIC).with_output_types(bytes) | "Decode" >> beam.Map(lambda x: x.decode('utf-8')) | "Clean Data" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) result = p.run() result.wait_until_finish() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
Konveyor mulai
Kita dapat memulai jalur pipa dengan beberapa cara berbeda. Jika kami mau, kami bisa menjalankannya secara lokal dari terminal, dari jarak jauh masuk ke GCP.
python -m main_pipeline_stream.py \ --input_topic "projects/user-logs-237110/topics/userlogs" \ --streaming
Namun, kami akan meluncurkannya menggunakan DataFlow. Kita dapat melakukan ini menggunakan perintah di bawah ini dengan mengatur parameter yang diperlukan berikut ini.
project - ID proyek GCP Anda.runner adalah runner pipa yang akan menganalisis program Anda dan membangun pipa Anda. Untuk berjalan di cloud, Anda harus menentukan DataflowRunner.staging_location - Jalur ke penyimpanan cloud Cloud Dataflow untuk mengindeks paket kode yang diperlukan oleh penangan proses.temp_location - path ke Cloud Dataflow penyimpanan cloud untuk meng-host file pekerjaan sementara yang dibuat selama operasi pipa.streaming
python main_pipeline_stream.py \ --runner DataFlow \ --project $PROJECT \ --temp_location $BUCKET/tmp \ --staging_location $BUCKET/staging --streaming
Ketika perintah ini sedang berjalan, kita bisa pergi ke tab DataFlow di konsol google dan melihat pipeline kita. Dengan mengklik pada pipeline, kita akan melihat sesuatu yang mirip dengan Gambar 4. Untuk keperluan debugging, akan sangat berguna untuk pergi ke log dan kemudian ke Stackdriver untuk melihat log detail. Ini membantu saya menyelesaikan masalah dengan saluran pipa di sejumlah kasus.
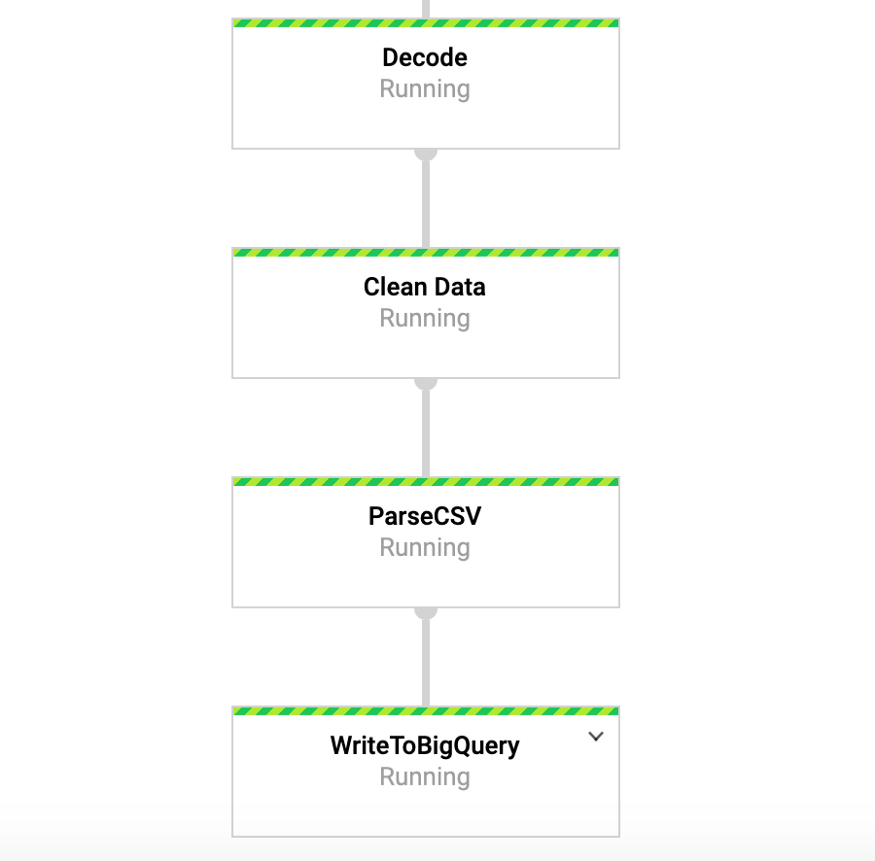 Gambar 4: Konveyor Balok
Gambar 4: Konveyor BalokAkses data kami di BigQuery
Jadi, kita seharusnya sudah memulai jalur pipa dengan data yang masuk ke tabel kita. Untuk menguji ini, kita bisa pergi ke BigQuery dan melihat datanya. Setelah menggunakan perintah di bawah ini, Anda akan melihat beberapa baris pertama dari kumpulan data. Sekarang kami memiliki data yang disimpan di BigQuery, kami dapat melakukan analisis lebih lanjut, serta berbagi data dengan rekan kerja dan mulai menjawab pertanyaan bisnis.
SELECT * FROM `user-logs-237110.userlogs.logdata` LIMIT 10;
 Gambar 5: BigQuery
Gambar 5: BigQueryKesimpulan
Kami berharap posting ini akan berfungsi sebagai contoh yang berguna untuk membuat pipa data streaming, serta menemukan cara untuk membuat data lebih mudah diakses. Menyimpan data dalam format ini memberi kita banyak keuntungan. Sekarang kita dapat mulai menjawab pertanyaan-pertanyaan penting, misalnya, berapa banyak orang yang menggunakan produk kita? Apakah basis pengguna bertambah seiring waktu? Aspek apa dari produk yang paling berinteraksi dengan orang? Dan adakah kesalahan yang seharusnya tidak terjadi? Ini adalah masalah yang akan menarik bagi organisasi. Berdasarkan gagasan yang muncul dari jawaban atas pertanyaan-pertanyaan ini, kami akan dapat meningkatkan produk dan meningkatkan minat pengguna.
Balok sangat berguna untuk jenis latihan ini, dan juga memiliki sejumlah kasus penggunaan menarik lainnya. Misalnya, Anda dapat menganalisis data tentang kutu tukar secara real time dan melakukan transaksi berdasarkan analisis, mungkin Anda memiliki data sensor yang berasal dari kendaraan, dan Anda ingin menghitung perhitungan tingkat lalu lintas. Anda juga dapat, misalnya, menjadi perusahaan game yang mengumpulkan data pengguna dan menggunakannya untuk membuat dasbor untuk melacak metrik kunci. Oke, tuan-tuan, topik ini sudah untuk posting lain, terima kasih sudah membaca, dan bagi mereka yang ingin melihat kode lengkap, di bawah ini adalah tautan ke GitHub saya.
https://github.com/DFoly/User_log_pipeline
Itu saja.
Baca bagian pertama .