Suatu hari, Moscow Python Meetup # 66 diadakan - komunitas terus mendiskusikan alat yang relevan yang meningkatkan bahasa dan menyesuaikannya dengan lingkungan yang berbeda. Termasuk di pertemuan itu, laporan saya dibuat. Nama saya Nail, saya sedang melakukan Yandex.Connect.

Cerita yang saya siapkan adalah tentang uWSGI. Ini adalah server aplikasi web multifungsi, dan setiap aplikasi modern disertai dengan metrik. Saya mencoba menunjukkan bagaimana kemampuan uWSGI dapat membantu dalam mengumpulkan metrik.
- Halo semuanya, saya senang menyambut Anda semua di dinding Yandex. Sangat menyenangkan bahwa begitu banyak orang datang untuk melihat laporan saya dan lainnya, bahwa begitu banyak orang tertarik dan tinggal di Python. Tentang apa laporan saya? Ini disebut "uWSGI untuk membantu metrik." Saya akan menceritakan sedikit tentang diri saya. Saya telah terlibat dalam Python selama enam tahun terakhir, saya telah bekerja di tim Yandex.Connect, kami sedang menulis platform bisnis yang menyediakan layanan Yandex yang dikembangkan secara internal untuk pengguna pihak ketiga, yaitu, untuk semua orang. Setiap orang atau organisasi dapat menggunakan produk yang dikembangkan oleh Yandex untuk diri mereka sendiri, untuk tujuan mereka sendiri.
Kami akan berbicara tentang metrik, cara mendapatkan metrik ini, bagaimana kami gunakan di tim kami uWSGI sebagai alat untuk mendapatkan metrik, bagaimana metrik membantu kami. Lalu saya akan menceritakan sedikit cerita optimasi.
Beberapa kata tentang metrik. Seperti yang Anda ketahui, pengembangan aplikasi modern tidak mungkin dilakukan tanpa tes. Sungguh aneh jika seseorang mengembangkan aplikasi mereka tanpa tes. Pada saat yang sama, menurut saya pengoperasian aplikasi modern tidak mungkin tanpa metrik. Aplikasi kita adalah organisme hidup. Seseorang dapat mengambil beberapa metrik, seperti tekanan, detak jantung, - aplikasi juga memiliki indikator yang kami tertarik dan ingin mengamati. Tidak seperti orang yang biasanya mengambil metrik vital ini ketika merasa buruk, dalam hal aplikasi, kita selalu dapat menggunakannya.

Mengapa kami menggunakan metrik? Ngomong-ngomong, siapa yang menggunakan metrik? Saya berharap bahwa setelah laporan saya, akan ada lebih banyak tangan, dan orang-orang akan tertarik dan mulai mengumpulkan metrik, mereka akan memahami bahwa ini perlu dan bermanfaat.
Jadi mengapa kita perlu metrik? Pertama-tama, kita melihat apa yang terjadi dengan sistem, kita menyoroti beberapa indikator normatif untuk sistem kita dan memahami apakah kita melampaui indikator-indikator ini selama proses aplikasi atau tidak. Anda dapat melihat beberapa perilaku abnormal sistem, misalnya, peningkatan jumlah kesalahan, pahami apa yang salah dengan sistem, sebelum pengguna kami dan menerima pesan tentang insiden bukan dari pengguna, tetapi dari sistem pemantauan. Berdasarkan metrik, kami dapat mengatur lansiran dan menerima sms, surat, panggilan, sesuka Anda.

Apa itu aturan? Ini adalah beberapa angka, mungkin penghitung yang tumbuh secara monoton. Misalnya, jumlah permintaan. Beberapa nilai unit yang berubah dalam waktu meningkat atau menurun. Contohnya adalah jumlah tugas dalam antrian. Atau histogram - nilai yang termasuk dalam beberapa interval, yang disebut keranjang. Sebagai aturan, akan lebih mudah untuk membaca data terkait waktu ini dan mencari tahu dalam interval waktu berapa banyak nilai yang sesuai.

Metrik macam apa yang bisa kita ambil? Saya akan fokus pada pengembangan aplikasi web, karena lebih dekat dengan saya. Misalnya, kita dapat memotret jumlah permintaan, titik akhir kita, waktu respons titik akhir kita, kode respons layanan terkait, jika kita pergi ke sana dan kita memiliki arsitektur layanan-mikro. Jika kita menggunakan cache, kita dapat memahami seberapa efektif cache miss atau hit, memahami distribusi waktu respons dari kedua server pihak ketiga, dan, misalnya, database. Tetapi untuk melihat metrik, Anda harus mengumpulkannya.

Bagaimana kita mengumpulkannya? Ada beberapa opsi. Saya ingin memberi tahu Anda tentang opsi pertama - skema push. Terdiri dari apa itu?
Misalkan kita menerima permintaan dari pengguna. Secara lokal, dengan aplikasi kami, kami memasang beberapa jenis, biasanya agen pendorong. Katakanlah kita memiliki Docker, ada aplikasi di dalamnya, dan agen push masih berdiri paralel. Agen pendorong menerima nilai metrik dari kami secara lokal, entah bagaimana buffer, membuat batch dan mengirimkannya ke sistem penyimpanan metrik.
Apa keuntungan menggunakan skema push? Kami dapat mengirim beberapa metrik langsung ke sistem metrik dari aplikasi, tetapi pada saat yang sama kami mendapatkan semacam interaksi jaringan, latensi, overhead untuk mengumpulkan metrik. Dalam kasus klien push lokal, ini diratakan.
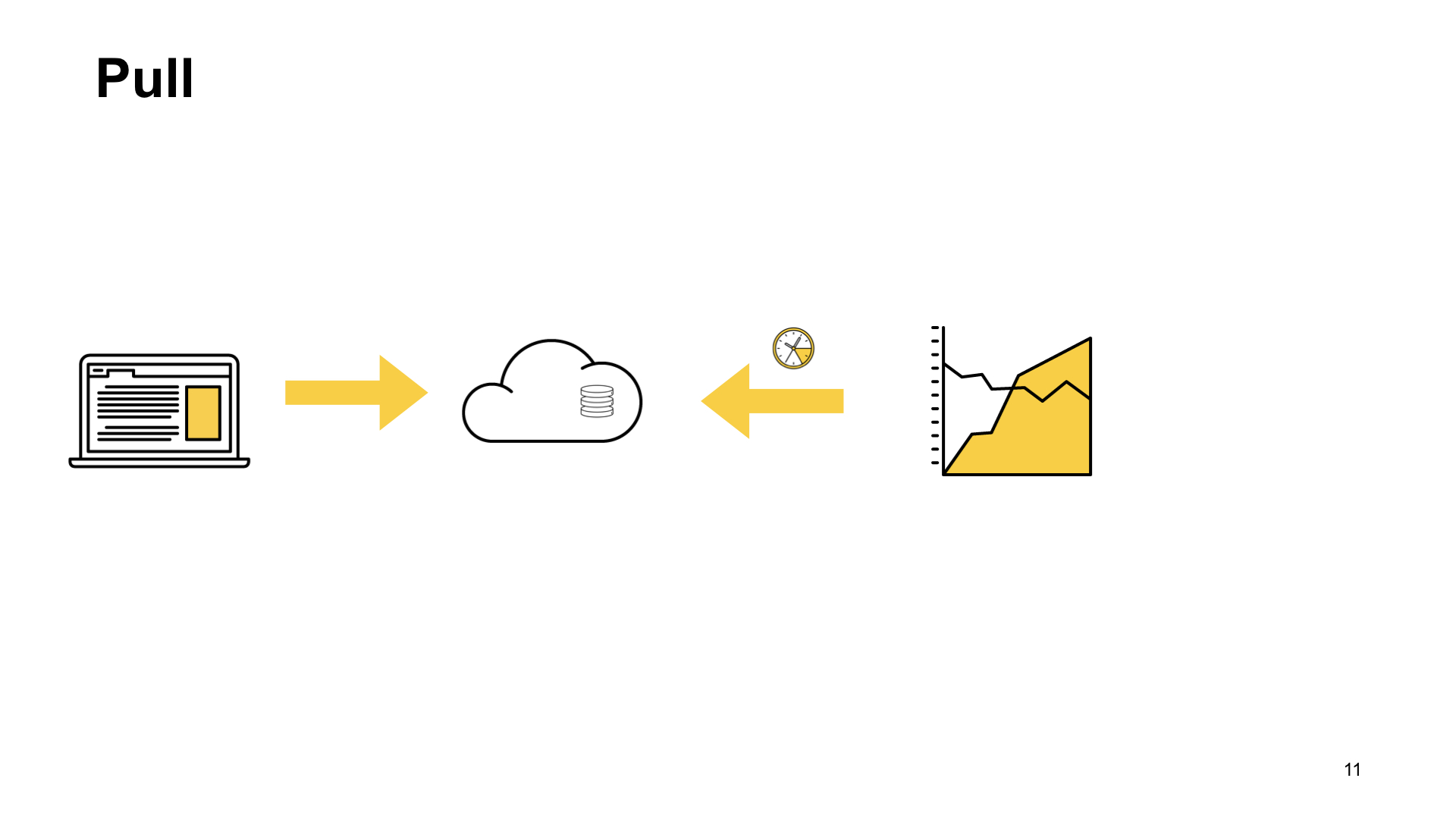
Opsi lain adalah skema tarikan. Dengan skema tarikan, kami memiliki skenario yang sama. Permintaan dari pengguna datang kepada kami, kami entah bagaimana menyimpannya di rumah. Dan kemudian dengan frekuensi tertentu - satu detik, satu menit, sesuai keinginan Anda - sistem pengumpulan metrik sampai pada titik akhir khusus aplikasi kami dan mengambil indikator ini.

Pilihan lain adalah log. Kita semua menulis log dan mengirimnya ke suatu tempat. Tidak ada yang mencegah kami mengambil log ini, entah bagaimana memprosesnya dan mendapatkan metrik berdasarkan log.
Misalnya, kami menulis fakta permintaan pengguna di log, lalu kami mengambil log, hop-hop, dihitung. Contoh khas adalah ELK (Elasticsearch, Logstash, Kibana).

Bagaimana cara kerjanya dengan kita? Yandex memiliki infrastruktur sendiri, sistem pengumpulan metrik sendiri. Dia mengharapkan respons standar untuk pegangan yang menerapkan skema tarikan. Plus kami memiliki cloud internal tempat kami meluncurkan aplikasi kami. Dan semua ini terintegrasi ke dalam satu sistem. Mengunggah ke cloud, kami cukup menunjukkan: "Buka pena ini dan dapatkan metriknya."

Berikut adalah contoh respons untuk skema penarikan yang diharapkan oleh sistem pengumpulan metrik kami.
Bagi kami sendiri dalam tim, kami memutuskan untuk memilih cara yang lebih cocok bagi kami, untuk menyoroti beberapa kriteria yang dengannya kami akan memilih opsi terbaik untuk kami. Efisiensi adalah seberapa cepat kita bisa mendapatkan dalam sistem metrik tampilan fakta tindakan apa pun. Ketergantungan - apakah kita perlu menginstal alat tambahan atau entah bagaimana mengkonfigurasi infrastruktur untuk mendapatkan metrik. Dan fleksibilitas - cara metode ini cocok untuk berbagai jenis aplikasi.
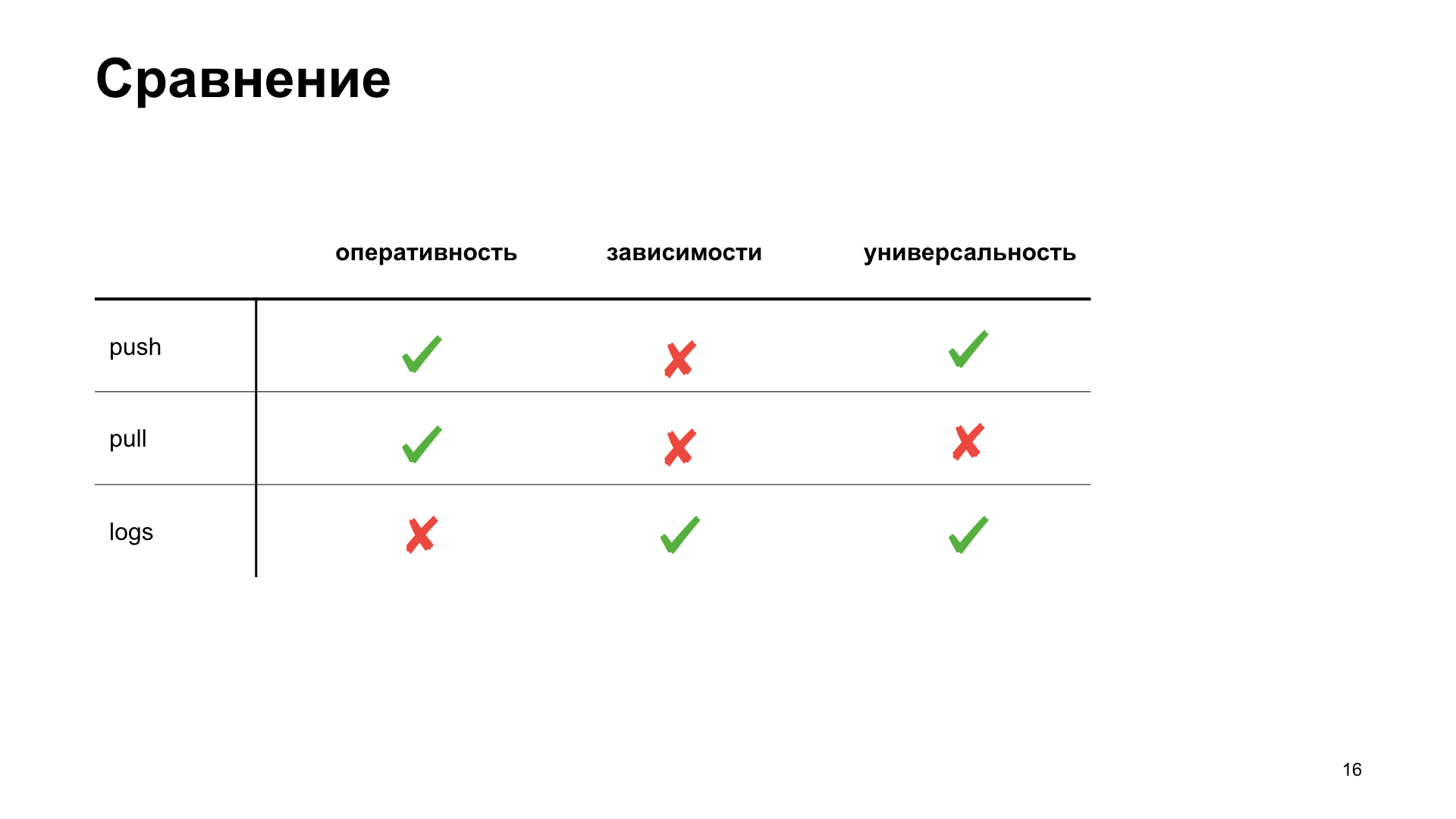
Itulah yang akhirnya kami dapatkan. Meskipun, sesuai dengan kriteria efisiensi dan fleksibilitas, skema push akan menang. Tetapi kami sedang mengembangkan aplikasi web, dan cloud kami sudah memiliki infrastruktur siap pakai untuk bekerja dengan tugas ini, jadi kami memutuskan untuk memilih skema penarik untuk diri kami sendiri. Kami akan membicarakannya.
Untuk memberikan sesuatu pada skema penarik, kita perlu melakukan pra-agregat di suatu tempat, menyimpannya. Sistem pemantauan kami beroperasi ke pegangan setiap lima detik. Di mana kita bisa menabung? Secara lokal di memori Anda atau di penyimpanan pihak ketiga.

Jika kita menyimpan secara lokal, maka sebagai aturan, ini cocok untuk kasus dengan satu proses. Dan kami, di uWSGI kami, menjalankan beberapa proses secara paralel. Atau kita dapat menggunakan beberapa jenis penyimpanan bersama. Apa yang terlintas dalam pikiran kita dengan kata "penyimpanan bersama"? Ini adalah semacam database Redis, Memcached, relasional atau non-relasional, atau bahkan file.

Tentang uWSGI. Biarkan saya mengingatkan Anda tentang mereka yang jarang menggunakannya: uWSGI adalah server aplikasi web yang memungkinkan Anda menjalankan aplikasi Python di bawah Anda. Ini mengimplementasikan antarmuka, protokol uWSGI. Protokol ini dijelaskan dalam PEP 333, yang tertarik, Anda dapat membaca.

Ini juga akan membantu kita untuk memilih solusi Yandex.Tank terbaik. Ini adalah alat pengujian beban, memungkinkan Anda untuk menggunakan aplikasi kami dengan berbagai profil beban dan membuat grafik yang indah. Atau berfungsi di konsol, sesuka Anda.

Eksperimennya. Kami akan membuat aplikasi sintetis untuk pengujian sintetis kami, kami akan menggantinya dengan tangki. Aplikasi uWSGI akan memiliki konflik sederhana dengan 10 pekerja.

Ini adalah aplikasi Flask kami. Payload yang dilakukan oleh aplikasi kita, kita akan meniru loop kosong.

Kami memecat, dan Yandex.Tank memberi kami salah satu dari grafik ini. Apa yang dia perlihatkan? Persentase waktu respons. Garis miring adalah RPS yang tumbuh, dan histogram adalah apa persentil server web kami muat di bawah beban seperti itu.
Kami akan mengambil opsi ini sebagai referensi dan melihat bagaimana berbagai opsi untuk menyimpan metrik memengaruhi kinerja.

Opsi paling sederhana adalah menggunakan PostgreSQL. Karena kami bekerja dengan PostgreSQL, kami memilikinya. Mari kita gunakan apa yang sudah siap.
Katakanlah kita memiliki label di PostgreSQL di mana kita cukup menambah penghitungnya.

Sudah pada sejumlah kecil RPS kami melihat penurunan kinerja yang kuat. Bisa dikatakan besar sekali.

Opsi selanjutnya adalah Redis. Tapi di sini kita melakukan lebih pintar: kita menginstalnya secara lokal dan pergi bukan melalui jaringan, tetapi melalui soket Unix. Tingkatkan juga counter.
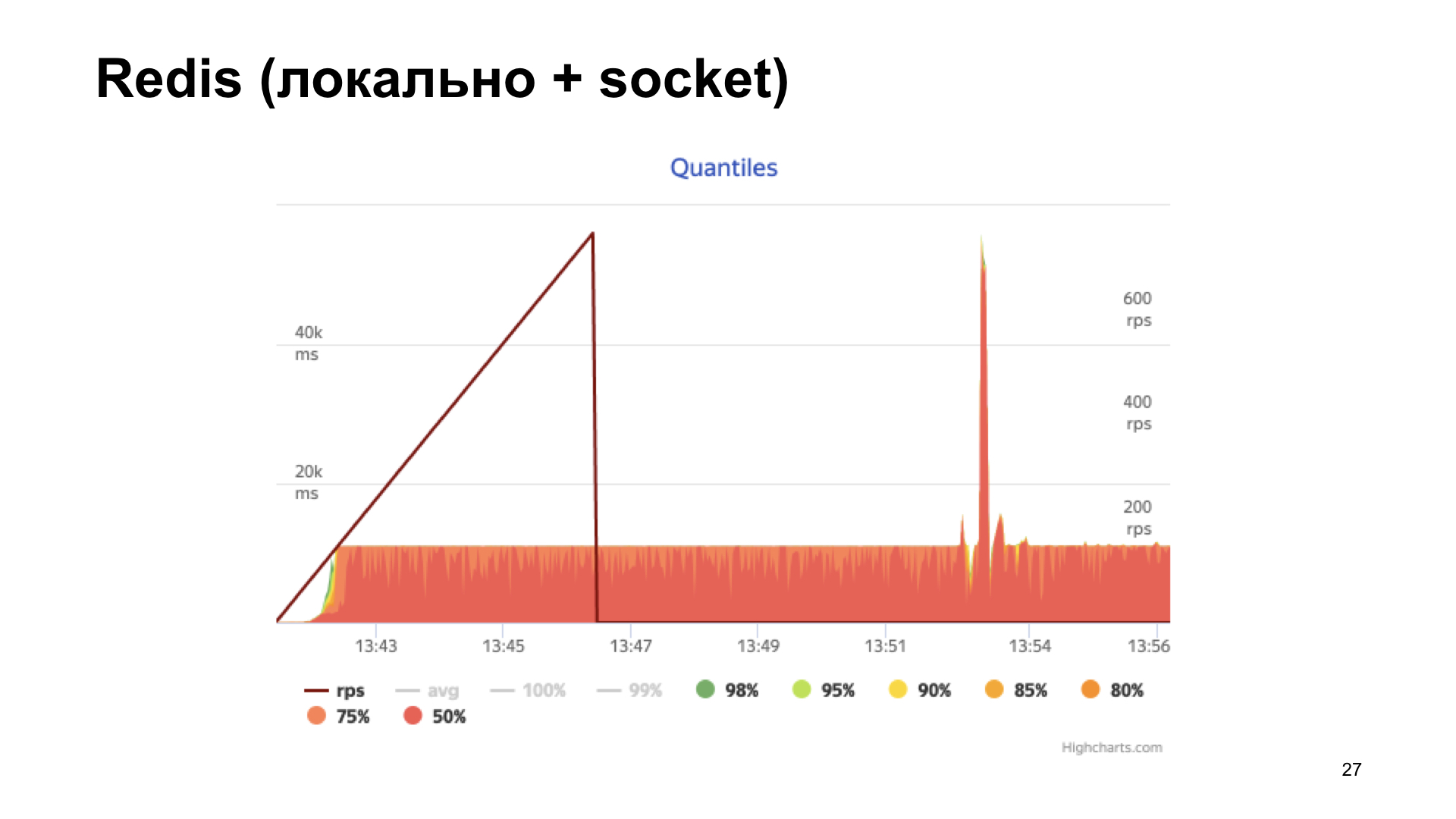
Kami mendapatkan histogram waktu respons di output. Kita melihat bahwa segala sesuatunya lebih baik di sini, tetapi pada titik tertentu kita mengalami rak, dan kemudian produktivitas tidak lagi tumbuh. Opsi ini tampaknya lebih optimal, tetapi kami ingin melakukan yang lebih baik lagi.

Di sini uWSGI, gabungan nyata, datang untuk membantu kami. Ada banyak modul berbeda. Bagal untuk menjalankan subproses, kerangka kerja cache, cron, subsistem metrik, dan sistem peringatan. “Sistem metrik subsistem” - terdengar menjanjikan.

Dia tahu cara menambahkan semacam metrik, menambah penghitung, mengurangi penghitung, mengalikan, membagi - apa pun yang diinginkan hati Anda.
Satu-satunya subsistem metrik tidak dapat memberikan dengan tepat metrik yang ada di dalamnya.
Mengapa ini penting bagi kami? Seperti yang Anda lihat sebelumnya, kami memiliki pegangan untuk memberikan statistik dalam format tertentu, dan beberapa pekerja berjalan. Kami tidak tahu pekerja mana yang akan menerima permintaan, tetapi untuk mengembalikan semua metrik, kami perlu membuat semacam daftar nama dan entah bagaimana mengacaknya di antara proses. Ini masalah besar, saya ingin menghindari ini. Apa lagi yang kita miliki?

Tentu saja, subsistem cache. Dan di sini kita melihat: dia dapat melakukan hal yang hampir sama, dan juga dapat memberikan nama-nama kunci yang disimpan dalam cache. Ini yang kamu butuhkan.

Subsistem cache adalah cache yang dibangun ke dalam uWSGI. Modul cepat dan aman, yang merupakan penyimpanan nilai kunci biasa.

Tetapi karena ini adalah cache, ada masalah kedua yang terkenal: bagaimana memberi nama variabel dan cara membatalkan cache? Dalam kasus kami, mari kita lihat apa pengaturan cache default. Ini memiliki batasan pada panjang kunci. Dalam kasus kami, ini adalah nama metrik. Standarnya adalah 2048 byte. Dan Anda dapat menambah konfigurasi jika perlu. Jumlah elemen yang disimpan secara default adalah 65.536. Tampaknya nilai ini harus cukup untuk semua orang. Tidak mungkin ada orang yang akan mengumpulkan sejumlah metrik dari aplikasi mereka.
Dan ttl secara default adalah 0. Artinya, nilai dari cache yang disimpan tidak cacat waktu. Jadi, kita bisa mendapatkannya dari cache dan mengirimkannya ke sistem metrik.

Sekali lagi, opsinya adalah aplikasi yang menggunakan kotak uWSGI.
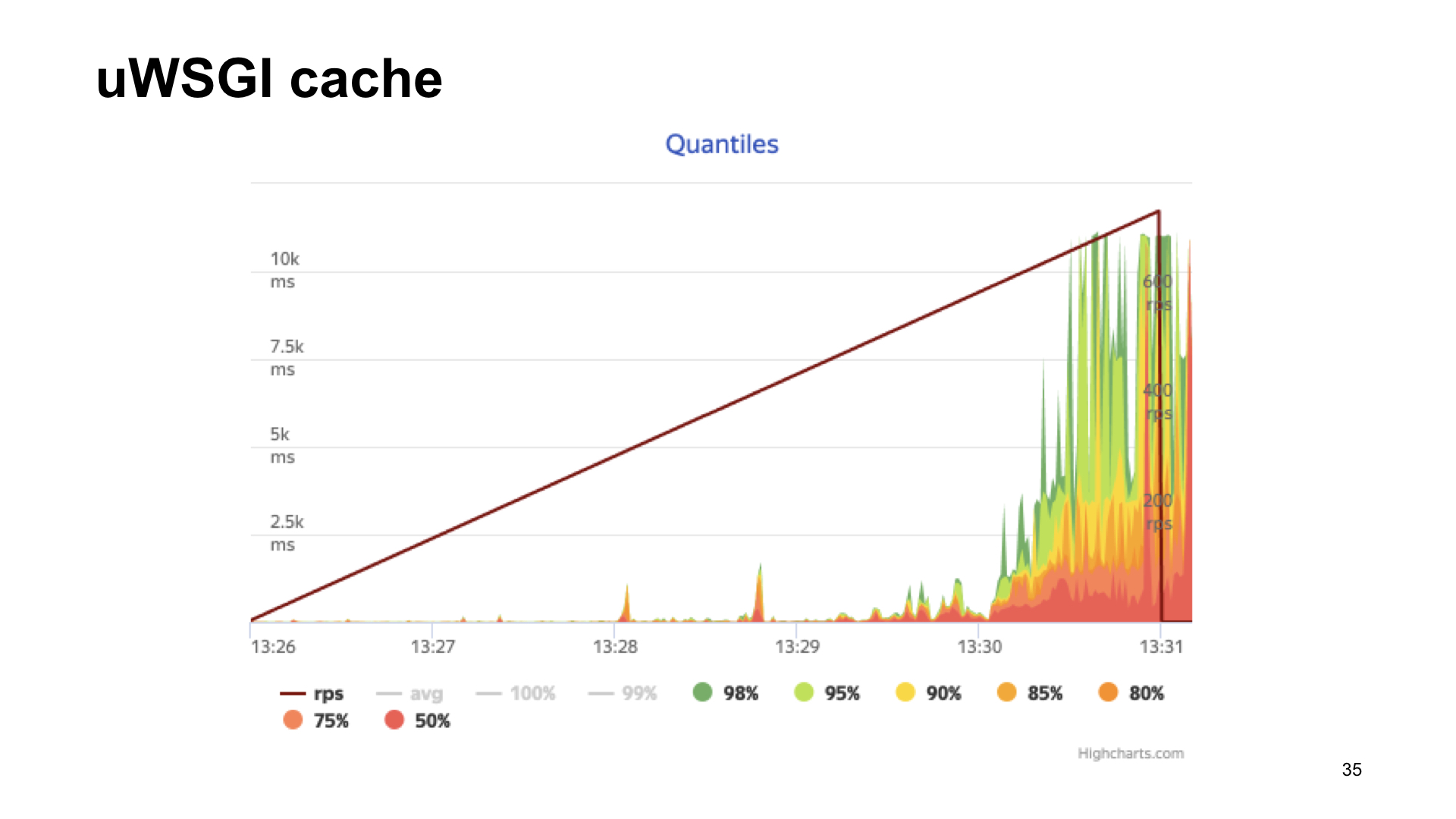
Berikut adalah hasil penembakan aplikasi ini.

Hasilnya tanpa metrik, jika dengan uWSGI, dengan peregangan terlihat hampir sama.
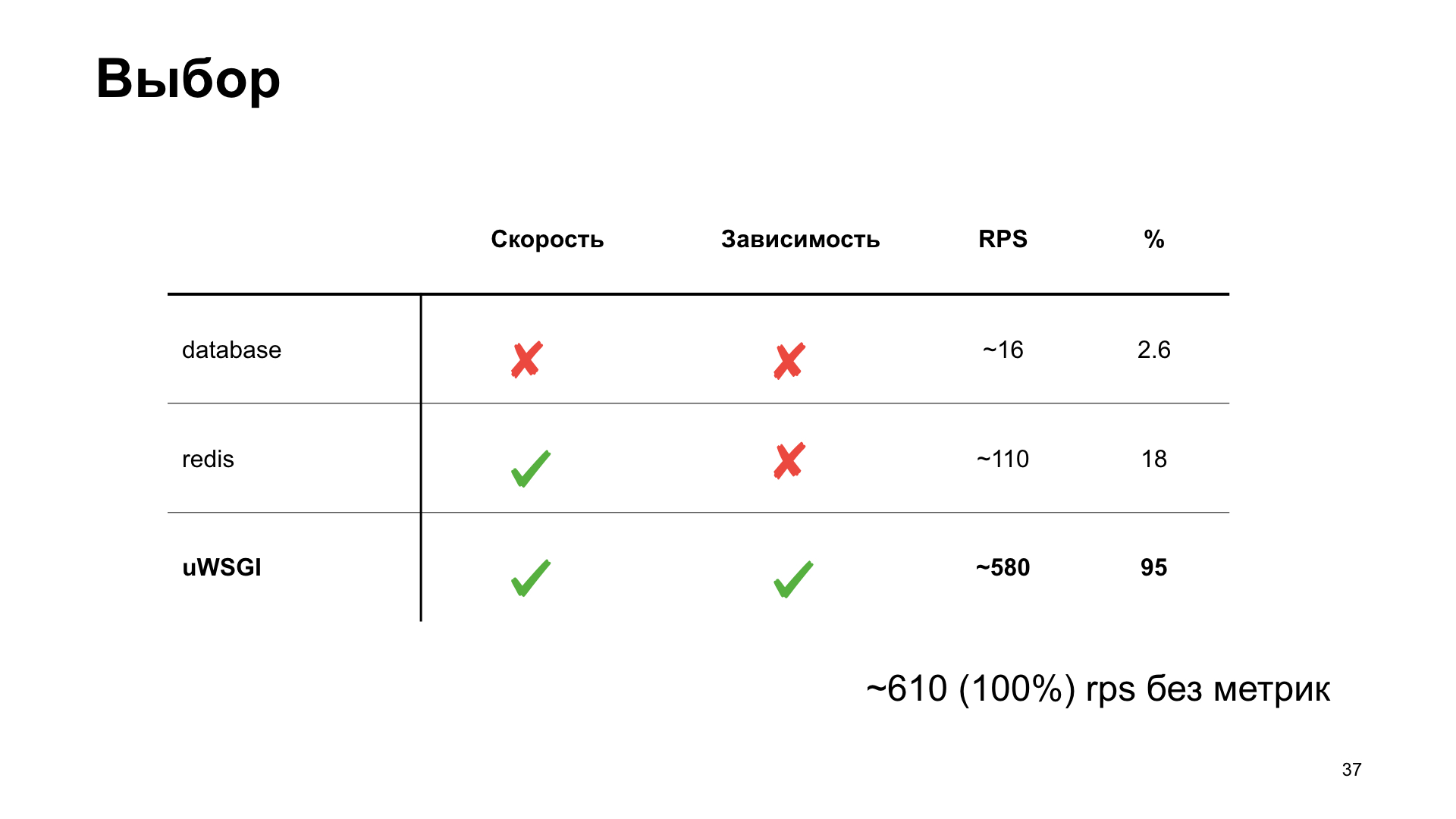
Seperti yang Anda lihat, dalam kasus uWSGI, kami hanya kehilangan 5% kinerja relatif terhadap versi "vanilla" tanpa metrik. Opsi lain memiliki drawdown yang cukup signifikan, dan karena itu, sebagai hasil voting penonton, uWSGI menang.

Bagaimana kami menerapkan ini? Kami menulis perpustakaan kecil, pembungkus di sekitar uWSGI. Misalnya, kami memasang turunan perpustakaan kami dan di sini kami menambahkan metrik "Waktu permintaan basis data" sebagai contoh.

Kami juga tertarik melacak cara kerja cache. Kami cukup mendefinisikan kembali metode memca klien, menghemat waktu untuk menerima data, waktu untuk mengunduh dan jumlah cache hit dan cache miss.

Bagaimana kita melakukan ini di dalam perpustakaan? Untuk mengirimkan nilai, kami mendapatkan nama-nama kunci yang disimpan dalam cache, menjalankannya dan memberikannya dalam format yang diinginkan ke titik akhir.
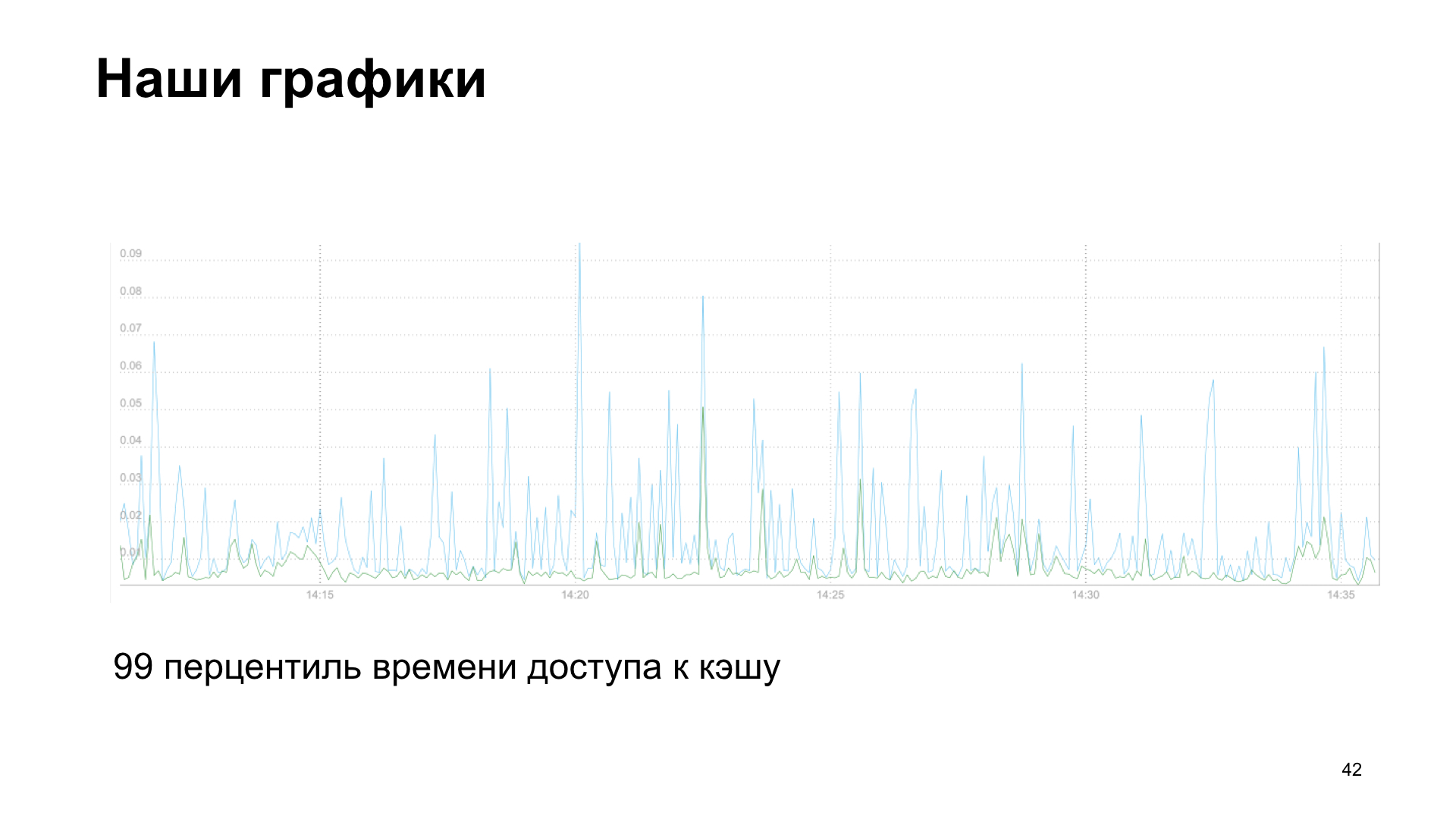
Sebagai hasilnya, kami mendapatkan grafik, dalam hal ini adalah persentil ke-99 dari waktu akses cache, membaca dan menulis.

Atau, sebagai opsi, jumlah permintaan layanan pihak ketiga ke API kami.

Kami memiliki kisah kegagalan dan kesuksesan. Kami mulai menambahkan lebih banyak metrik dan melihat penurunan kinerja. Metrik itu sendiri membantu kami. Jika Anda mengumpulkan metrik, maka Anda dapat melihat ada sesuatu yang salah. Oleh karena itu, saya juga menyarankan Anda untuk melihat secara metrik metrik yang telah Anda kumpulkan selama seminggu, sebulan, enam bulan. Dan lihat tren apa yang ditampilkan aplikasi Anda di indikator mana. Kami menyadari bahwa kami mulai bersandar pada perhitungan metrik.

Pembuatan profil membantu kami. Di sini Anda melihat flamegraph, secara visual menunjukkan kepada kita berapa banyak panggilan dari berbagai fungsi yang diambil selama proses, yang panggilan memberikan kontribusi terbesar dalam waktu. Kami menyadari bahwa kami tidak melakukannya dengan baik di versi pertama menggunakan acar. Di dalam perpustakaan kami, dia menghabiskan banyak waktu mengasinkan.

Kami menolak pengawetan, ditransfer ke cashe inc, mengukur segalanya, itu menjadi lebih cepat.

Dalam implementasi baru, kami menghabiskan sebagian besar waktu kami bekerja dengan cache, bukan acar.

Kenapa aku memberitahumu ini? Saya mendorong Anda untuk mulai mengumpulkan metrik, menonton metrik, dan fokus pada metrik. Saat memilih opsi pengumpulan metrik yang mungkin, bandingkan opsi, lihat mana yang terbaik untuk Anda. Dan, tentu saja, membuat profil itu bagus. Jika Anda melihat ada sesuatu yang salah, ada yang melambat - profil.
Terima kasih semuanya! Seperti yang saya janjikan, referensi: