Kami berpikir untuk membangun infrastruktur uji beban besar setahun yang lalu, ketika kami mencapai tanda 12K pengguna online yang bekerja di
layanan kami pada saat yang sama. Selama 3 bulan kami membuat versi pertama tes, yang menunjukkan batas layanan.
Ironi takdir adalah bahwa pada saat yang sama dengan uji diluncurkan, kami mencapai batas pada prod, sebagai akibatnya layanan turun 2 jam. Ini juga mendorong kami untuk mulai bergerak dari melakukan pengujian dari kasus ke kasus ke menciptakan infrastruktur penahan beban yang efektif. Dengan infrastruktur, maksud saya semua alat untuk bekerja dengan beban: alat untuk meluncurkan dan memulai, sebuah cluster untuk memuat beban, sebuah cluster, produk serupa, layanan untuk mengumpulkan metrik dan untuk menyiapkan laporan, kode untuk mengelola semua ini dan layanan untuk penskalaan.
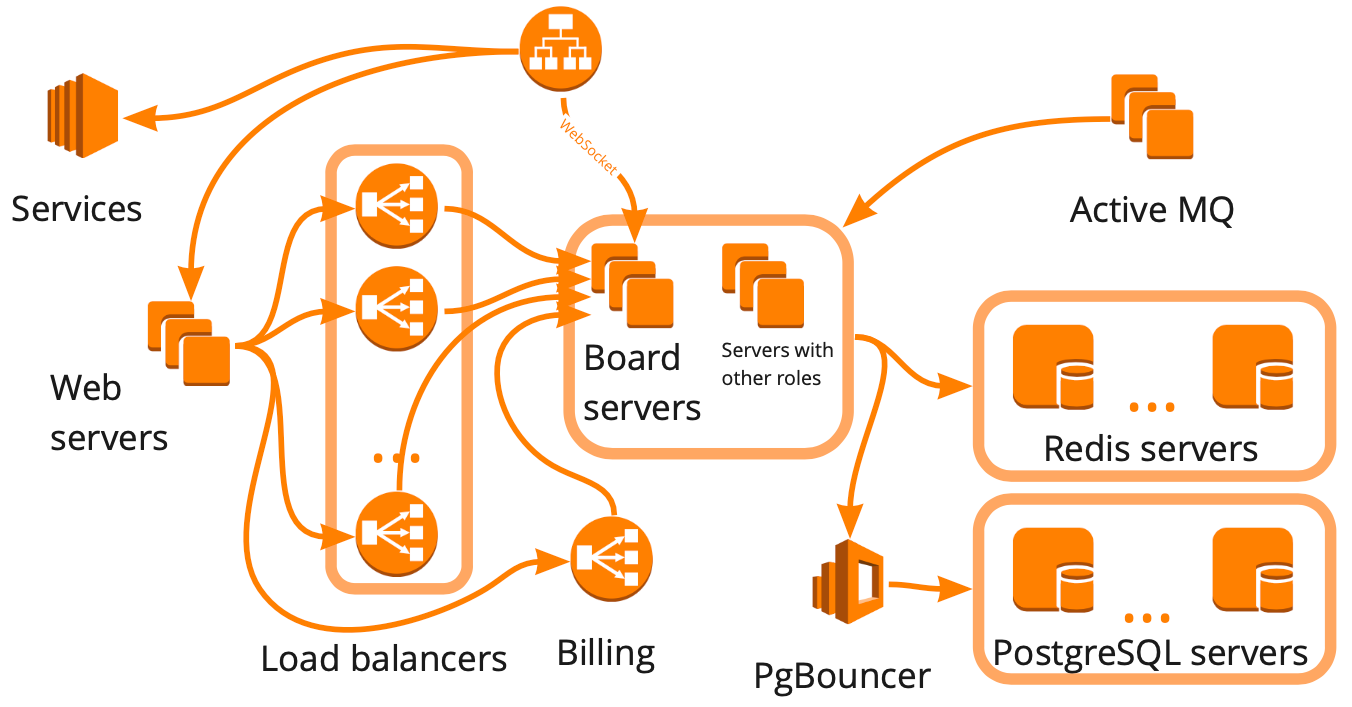
Beginilah sederhananya skema miro.com terlihat: ada banyak server berbeda yang entah bagaimana berinteraksi satu sama lain, dan masing-masing melakukan tugas tertentu. Tampaknya untuk membangun infrastruktur uji beban, cukup bagi kami untuk menggambar skema seperti itu, memperhitungkan semua hubungan dan mulai membahas setiap blok secara berurutan dengan skrip. Pendekatan ini baik, tetapi akan membutuhkan waktu berbulan-bulan, yang tidak cocok untuk kami karena pertumbuhan yang cepat - selama enam bulan terakhir kami telah tumbuh dari 12K menjadi 20K pengguna online yang bekerja di layanan pada saat yang sama. Selain itu, kami tidak tahu bagaimana infrastruktur layanan kami akan merespons peningkatan beban: blok mana yang akan menjadi hambatan, dan mana yang dapat kami skala secara linear.
Akibatnya, kami memutuskan untuk menguji layanan menggunakan pengguna virtual, mensimulasikan pekerjaan realistis mereka, yaitu, membangun klon produksi dan melakukan tes besar, yang:
- memuat cluster yang identik dengan produksi dalam struktur, tetapi di depannya berkuasa;
- memberi kami semua data untuk membuat keputusan;
- akan menunjukkan bahwa seluruh infrastruktur mampu menahan beban yang tepat;
- akan menjadi dasar untuk tes stres yang mungkin kita butuhkan di masa depan.
Satu-satunya minus dari tes semacam itu adalah harga biayanya, karena untuk itu kita memerlukan lingkungan yang akan lebih besar dari lingkungan produksi.
Dalam artikel ini saya akan memberi tahu Anda tentang membuat skenario realistis, plugin - WS, Stress-client, Taurus, - cluster load, klaster penjualan, dan tunjukkan contoh penggunaan tes.
Artikel selanjutnya adalah tentang bagaimana kami mengelola ratusan server untuk uji beban.
Buat skenario realistis
Untuk membuat skenario yang realistis, kita perlu:
- menganalisis pekerjaan pengguna di prod, dan untuk ini, tentukan metrik yang penting bagi kami, mulailah mengumpulkannya secara teratur dan menganalisis lompatan;
- membuat blok khusus yang nyaman yang dengannya kita dapat dengan efisien memuat bagian yang diperlukan dari logika bisnis;
- Verifikasi realisme skrip dengan metrik server.
Sekarang, lebih banyak tentang setiap item.
Analisis pekerjaan pengguna pada prodDalam layanan kami, pengguna dapat membuat papan dan mengerjakannya dengan konten yang berbeda: foto, teks, mocapas, stiker, diagram, dll. Metrik pertama yang perlu kami kumpulkan adalah jumlah papan dan distribusi konten di dalamnya.
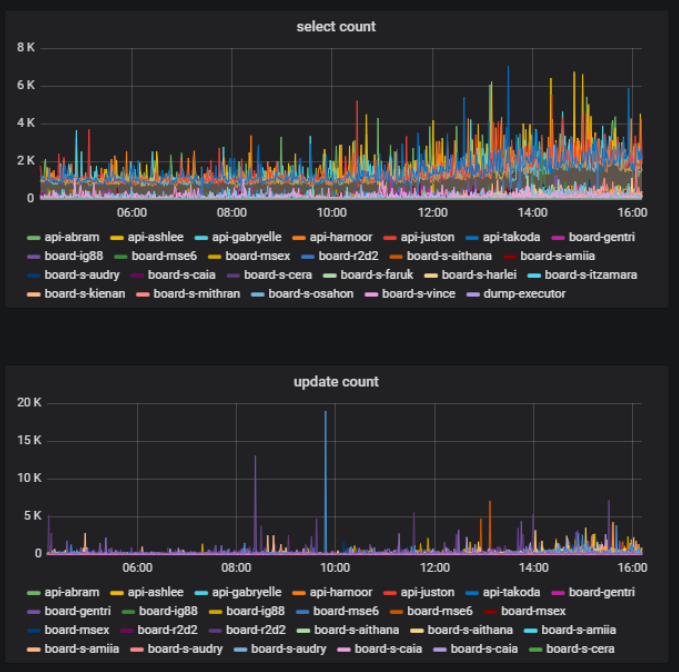
Pada papan yang sama pada saat bersamaan, beberapa pengguna dapat secara aktif melakukan sesuatu - membuat, menghapus, mengedit - dan beberapa hanya melihat materi yang dibuat. Ini juga merupakan metrik penting - rasio jumlah pengguna yang mengubah konten di papan tulis dengan jumlah total pengguna di satu papan. Ini bisa kita peroleh berdasarkan statistik saat bekerja dengan database.
Di backend kami, kami menggunakan pendekatan komponen. Komponen yang kita sebut model. Kami memecah kode kami menjadi model sehingga untuk setiap bagian dari logika bisnis, model tertentu bertanggung jawab. Kita dapat menghitung jumlah panggilan basis data yang terjadi melalui masing-masing model dan memahami bagian mana dari logika yang paling memuat basis data.
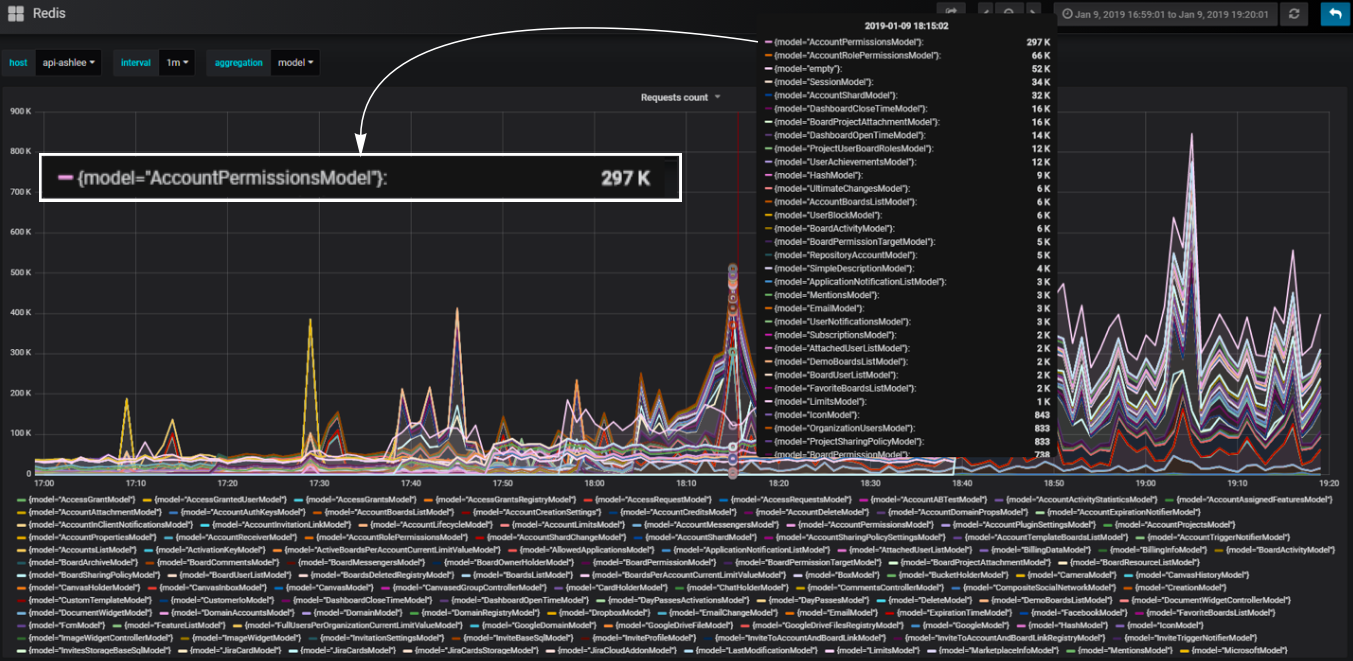 Blok khusus yang nyaman
Blok khusus yang nyamanMisalnya, kita perlu menambahkan blok ke skrip yang memuat layanan kami secara identik dengan bagaimana hal itu terjadi ketika Anda membuka halaman dasbor dengan daftar papan pengguna. Selama pemuatan halaman ini, http-permintaan dengan sejumlah besar data dikirim: jumlah papan, akun yang dapat diakses pengguna, semua pengguna akun, dan sebagainya.

Bagaimana cara memuat dasbor secara efektif? Ketika menganalisis perilaku produksi, kami melihat lonjakan beban dalam database selama pembukaan dasbor akun besar. Kami dapat membuat ulang akun yang identik dan mengubah intensitas penggunaan datanya dalam skrip, secara efektif memuat dasbor dengan sejumlah kecil klik. Kami juga dapat membuat beban yang tidak merata untuk realisme yang lebih besar.
Pada saat yang sama, penting bagi kami bahwa jumlah pengguna virtual dan beban yang dibuat oleh mereka adalah sama mungkin dengan pengguna dan beban pada produksi. Untuk melakukan ini, kami juga membuat ulang dalam pengujian beban latar belakang pada rata-rata dasbor. Dengan demikian, sebagian besar pengguna virtual bekerja pada dasbor rata-rata kecil, dan hanya beberapa pengguna yang menciptakan beban yang merusak, seperti yang terjadi dalam produksi.
Awalnya, kami tidak ingin membahas setiap peran server dan setiap hubungan dengan skrip terpisah. Ini dapat dilihat pada contoh dengan dashboard - kami hanya mengulangi selama pengujian apa yang terjadi ketika dashboard dibuka pada prod ketika pengguna membukanya, dan kami tidak membahas apa pengaruhnya dengan skrip sintetis. Ini memungkinkan Anda untuk secara otomatis memberi nuansa pengujian yang bahkan tidak kami antisipasi. Dengan demikian, kami mendekati pembuatan uji infrastruktur dari sisi logika bisnis.
Kami menggunakan logika ini untuk memuat semua blok layanan secara efektif. Pada saat yang sama, setiap blok individu dari sudut pandang logika penggunaan fungsional mungkin tidak realistis; penting bahwa ini memberikan beban metrik yang realistis di server. Dan kemudian kita bisa membuat skrip dari blok-blok ini yang meniru karya nyata pengguna.

Data adalah bagian dari skrip.
Perlu diingat bahwa data juga merupakan bagian dari skrip, dan logika kode itu sendiri sangat bergantung pada data. Ketika membangun database besar untuk pengujian - dan itu jelas harus besar untuk tes infrastruktur besar - kita perlu belajar cara membuat data yang tidak akan memberikan gulungan selama pelaksanaan skrip. Jika Anda mengumpulkan data sampah, skrip mungkin berubah menjadi tidak realistis, dan basis data besar akan sulit untuk diperbaiki. Karenanya, kami mulai menggunakan API Istirahat untuk membuat data dengan cara yang sama seperti yang dilakukan pengguna kami.
Misalnya, untuk membuat papan dengan data yang tersedia, kami mengeksekusi permintaan API untuk memuat papan dari cadangan. Hasilnya, kami mendapatkan data nyata yang jujur - papan berbeda dengan ukuran berbeda. Pada saat yang sama, database sedang diisi cukup cepat karena fakta bahwa kami menarik permintaan dalam skrip multithreadedly. Dalam kecepatan, ini sebanding dengan generasi data sampah.
Hasil untuk bagian ini
- Gunakan skenario realistis jika Anda ingin memeriksa semuanya sekaligus;
- Menganalisis perilaku pengguna nyata untuk merancang struktur skrip;
- Segera buat blok nyaman untuk kustomisasi;
- Konfigurasikan dengan metrik server nyata, bukan dengan analitik penggunaan;
- Ingat bahwa data adalah bagian dari skrip.
Muat cluster
Skema alat untuk menerapkan beban:
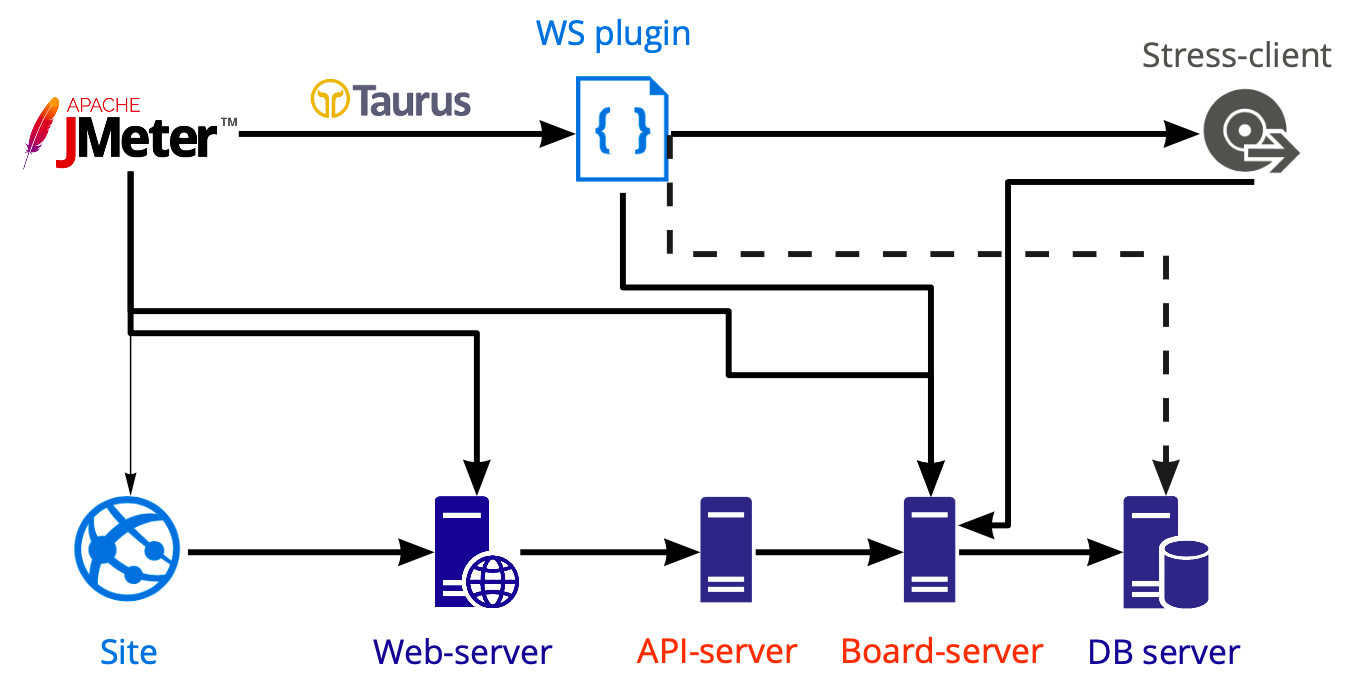
Di Jmeter, kami membuat skrip yang kami luncurkan menggunakan Taurus dan memuat berbagai server dengan itu: web, api, server papan. Kami melakukan tes basis data secara terpisah menggunakan Postgresql, bukan Jmeter, sehingga diagram menunjukkan garis putus-putus.
Pekerjaan khusus di dalam soket web
Bekerja di papan terjadi di dalam koneksi-WS, dan di papan itulah pekerjaan multi-pengguna dimungkinkan. Sekarang di kotak Jmeter di dalam manajer plug-in ada beberapa plug-in untuk bekerja dengan soket web. Logikanya sama di mana-mana - plugin cukup membuka koneksi soket web, tetapi semua tindakan yang terjadi di dalam, dalam hal apa pun, Anda perlu menulis sendiri. Mengapa Karena kami tidak dapat bekerja dengan cara yang sama dengan permintaan http, yaitu, kami tidak dapat menulis skrip, menarik nilai dinamis dengan extractors dan melewati mereka lebih jauh.
Pekerjaan di dalam soket web biasanya sangat khusus: Anda memanggil metode tertentu dengan kustom data tertentu dan, karenanya, Anda sendiri perlu memahami apakah permintaan itu dieksekusi dengan benar dan berapa lama waktu yang diperlukan untuk mengeksekusi. Pendengar di dalam plugin ini juga ditulis secara independen, kami tidak menemukan solusi siap pakai yang bagus.
Klien stres
Kami ingin sesederhana mungkin mengulangi apa yang dilakukan pengguna nyata. Tapi kami tidak tahu bagaimana cara merekam dan memutar ulang apa yang terjadi di browser di dalam WS. Jika kita menulis semuanya di dalam WS dari awal, maka kita akan mendapatkan klien baru, dan bukan yang digunakan pengguna nyata. Saya tidak ingin menulis klien baru jika kami sudah punya klien.
Oleh karena itu, kami memutuskan untuk menempatkan klien kami di dalam Jmeter. Dan dihadapkan pada sejumlah kesulitan. Sebagai contoh, mengeksekusi js di dalam Jmeter adalah cerita yang terpisah, seperti Ini adalah versi yang sangat
spesifik dari fitur yang didukung. Dan jika Anda ingin menggunakan kode klien Anda yang sudah ada, kemungkinan besar Anda tidak akan berhasil, karena konstruksi baru-ketinggalan jaman tidak dapat diluncurkan di sini, mereka harus ditulis ulang.
Kesulitan kedua adalah bahwa kami tidak ingin mendukung seluruh kode klien untuk pengujian beban. Oleh karena itu, kami menghapus semua yang tidak perlu dari klien dan hanya meninggalkan interaksi klien-server. Ini memungkinkan kami untuk menggunakan metode client-server dan melakukan segala yang dapat dilakukan klien kami. Nilai tambahnya adalah interaksi klien-server sangat jarang berubah, yang berarti bahwa dukungan kode di dalam skrip jarang diperlukan. Misalnya, selama enam bulan terakhir saya tidak pernah membuat perubahan pada kode, karena itu berfungsi dengan baik.
Kesulitan ketiga - penampilan skrip besar secara signifikan menyulitkan skrip. Pertama, itu bisa menjadi hambatan dalam tes. Kedua, kami kemungkinan besar tidak akan dapat memulai sejumlah besar utas dari satu mesin. Sekarang kita hanya dapat meluncurkan 730 utas.
Contoh Amazon Instance kami Jmeter server AWS: m5.large ($0.06 per Hour) vCPU: 2 Mem (GiB): 8 Dedicated EBS Bandwidth (Mbps): Up to 3,500 Network Performance (Gbps): Up to 10 → ~730
Di mana mendapatkan ratusan server dan cara menyimpan
Selanjutnya, muncul pertanyaan: 730 utas dari satu mesin, tetapi kami menginginkan 50 ribu. Di mana untuk meningkatkan banyak server? Kami menciptakan solusi cloud, jadi membeli server untuk menguji solusi cloud sepertinya aneh. Plus, selalu ada kelambatan tertentu dalam proses pembelian besi baru. Oleh karena itu, kita perlu menaikkannya juga di cloud, jadi kami akhirnya memilih antara penyedia cloud dan alat cloud load.
Kami tidak menggunakan alat cloud load seperti Blazemeter dan RedLine13, karena mereka memiliki batasan penggunaan yang tidak sesuai dengan kami. Kami memiliki lokasi pengujian yang berbeda, jadi kami ingin menemukan solusi universal yang memungkinkan 90% pengembangan digunakan, termasuk dalam pengujian lokal.
Akibatnya, kami memilih di antara penyedia cloud.
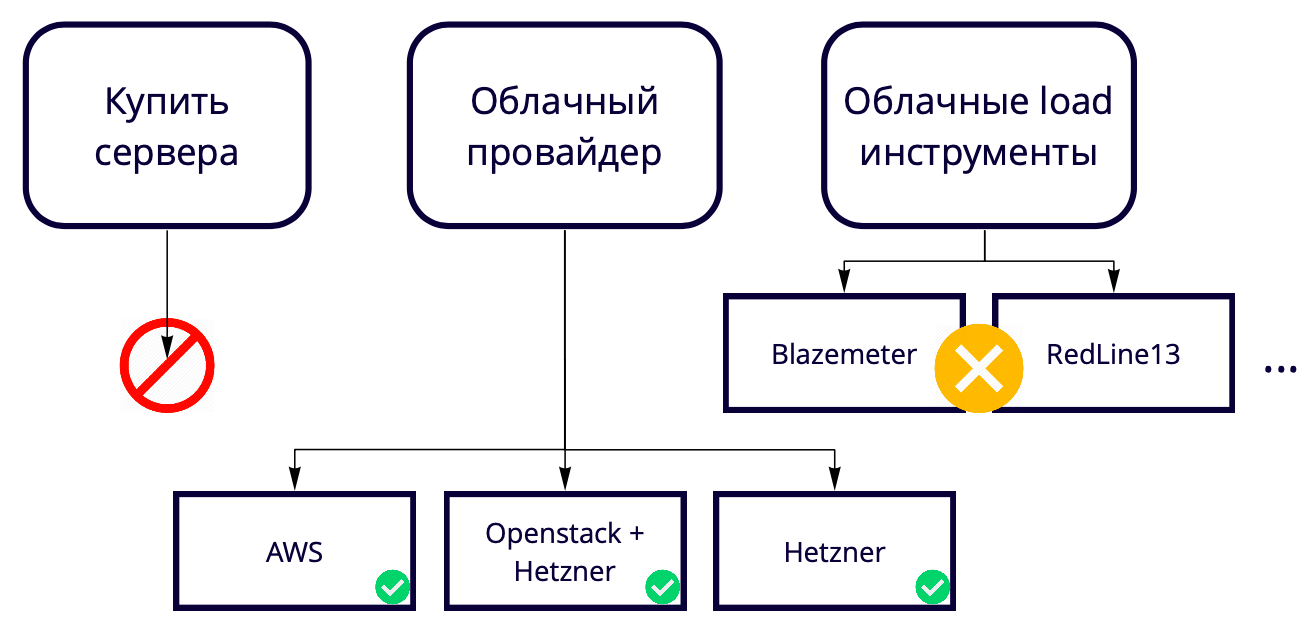
Produksi kami menggunakan AWS, jadi kami menguji sebagian besar di sana, dan kami ingin bangku pengujian sedapat mungkin sama dengan produksi. Amazon memiliki banyak fitur berbayar, beberapa di antaranya kami gunakan dalam produk, misalnya penyeimbang. Jika fitur ini tidak diperlukan di AWS, maka Anda dapat menggunakannya 17 kali lebih murah di Hetzner. Atau Anda dapat menyimpan server di Hetzner, menggunakan Openstack dan menulis balancers sendiri, karena menggunakan Openstack Anda dapat mengulangi seluruh infrastruktur. Kami telah berhasil.
Menguji 50 ribu pengguna dengan 69 instans di AWS berharga sekitar $ 3 ribu per bulan. Bagaimana cara menyimpan? Sebagai contoh, AWS memiliki instance sementara - instance spot. Kesejukan mereka adalah bahwa kami tidak menyimpannya terus-menerus, kami hanya membesarkannya selama pengujian dan biayanya lebih murah. Nuansanya adalah orang lain dapat membelinya dengan harga yang lebih tinggi tepat pada saat pengujian kami. Untungnya, ini belum pernah terjadi sebelumnya, tetapi kami sudah menghemat setidaknya 60% dari biaya dengan biaya mereka.
Muat cluster
Kami menggunakan kotak cluster Jmeter. Ini berfungsi dengan baik, tidak perlu dimodifikasi dengan cara apa pun. Ini memiliki beberapa opsi peluncuran. Kami menggunakan yang paling sederhana ketika satu wizard memulai N instance, dan mungkin ada ratusan wizard.
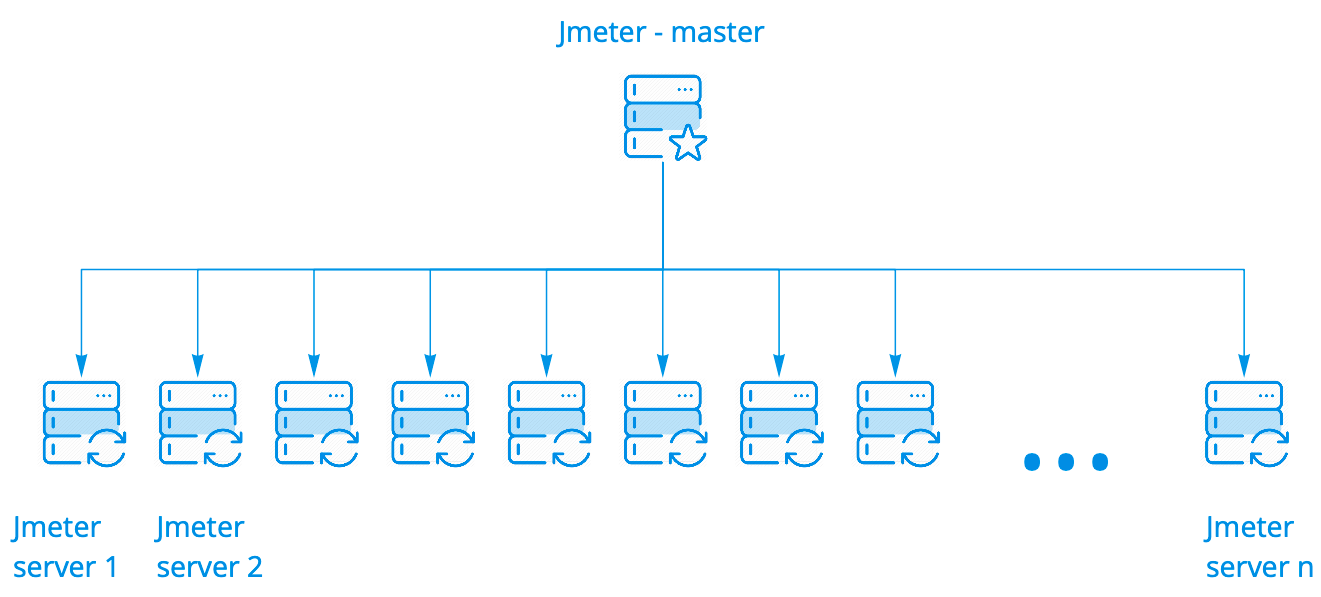
Wisaya menjalankan skrip pada server Jmeter, sambil tetap berkomunikasi dengan mereka, mengumpulkan statistik umum dari semua instance secara real time dan menampilkannya di konsol. Semua ini terlihat persis sama dengan menjalankan skrip di satu server, meskipun kami melihat hasil peluncuran di seratus server.
Untuk analisis terperinci dari hasil eksekusi skrip pada semua contoh, kami menggunakan Kibana. Parsim log menggunakan Filebeat.

Pendengar Prometheus untuk Apache JMeter
Jmeter memiliki
plugin untuk bekerja dengan Prometheus , yang di luar kotak memberikan semua statistik tentang penggunaan JVM dan utas di dalam tes. Ini memungkinkan Anda untuk melihat seberapa sering pengguna masuk, keluar, dan sebagainya. Plugin dapat disesuaikan untuk mengirim data pada skrip ke Prometheus dan melihatnya secara real time di Grafana.
Taurus
Kami ingin menyelesaikan sejumlah masalah saat ini dengan Taurus, tetapi belum menanganinya:
- Konfigurasi bukan klon skrip. Jika Anda menguji pada Jmeter, maka Anda mungkin menghadapi kebutuhan untuk menjalankan skrip dengan set parameter sumber yang berbeda, di mana Anda harus membuat klonnya. Dalam Taurus dimungkinkan untuk memiliki satu skenario, dan dengan bantuan konfigurasi untuk mengontrol parameter peluncuran;
- Konfigurasi untuk mengelola server Jmeter ketika bekerja dengan sebuah cluster;
- Penganalisa hasil online yang memungkinkan Anda untuk mengumpulkan hasil secara terpisah dari utas Jmeter dan tidak membebani skrip itu sendiri;
- Integrasi yang mudah dengan CI;
- Kemampuan untuk menguji sistem terdistribusi.
Hasil dari bagian ini
- Jika kita menggunakan kode di dalam Jmeter, maka lebih baik untuk segera memikirkan kinerjanya, karena kalau tidak kita bisa menguji Jmeter, bukan produk kita;
- Cluster Jmeter adalah hal yang luar biasa: mudah dikonfigurasikan, pemantauan mudah dilakukan;
- Sekelompok besar dapat disimpan dalam instance spot, itu akan jauh lebih murah;
- Hati-hati dengan pendengar di dalam Jmeter sehingga skrip tidak memperlambat kerja pada sejumlah besar server.
Contoh menggunakan tes infrastruktur
Seluruh cerita di atas sebagian besar tentang membuat skenario realistis untuk tes batas layanan. Contoh di bawah ini menunjukkan bagaimana Anda dapat menggunakan kembali infrastruktur uji beban untuk menyelesaikan masalah lokal. Saya akan berbicara secara rinci tentang dua tes, tetapi secara umum kami melakukan sekitar 10 jenis tes beban secara berkala.
Pengujian basis data
Apa yang bisa kita muat dalam database? Kueri berat tidak mungkin, karena kami dapat mengujinya dalam mode single-threaded, jika kami hanya melihat rencana kueri.
Situasi yang menarik adalah ketika kita menjalankan tes dan melihat beban pada disk. Grafik menunjukkan bagaimana iowait naik.
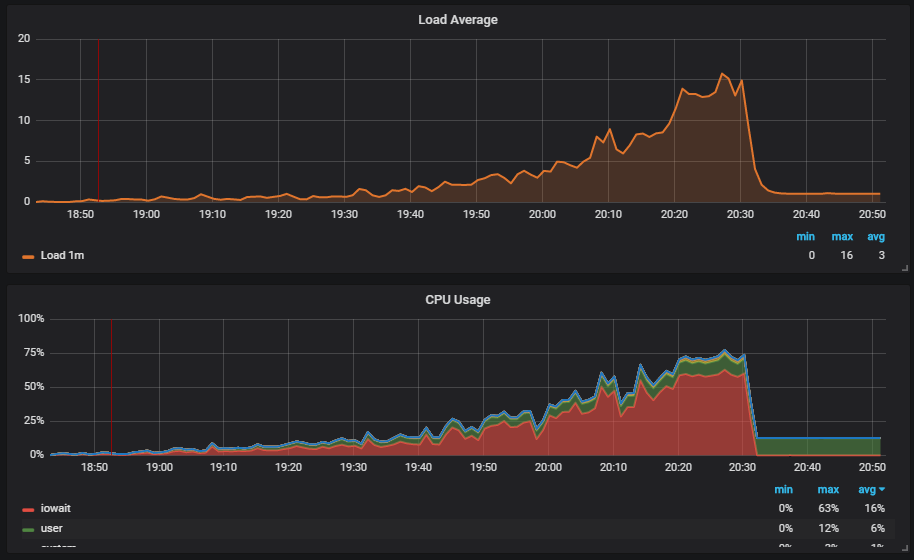
Lebih lanjut kita melihat bahwa ini mempengaruhi pengguna.
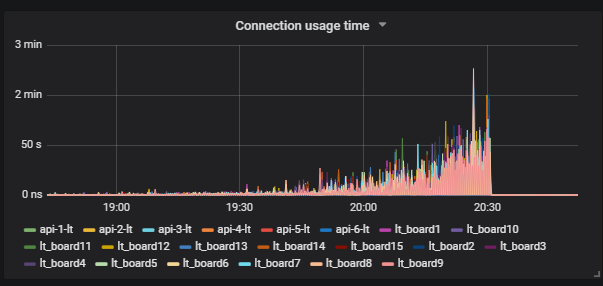
Kami memahami alasannya: Vakum tidak berfungsi dan tidak menghapus data sampah dari database. Jika Anda belum bekerja dengan Postgresql, maka Vakum sama seperti pengumpul Sampah di Jawa.

Lebih jauh kita melihat bahwa
Checkpoint mulai berjalan sesuai jadwal. Bagi kami, ini adalah sinyal bahwa konfigurasi Postgresql tidak sesuai dengan intensitas kerja dengan database.
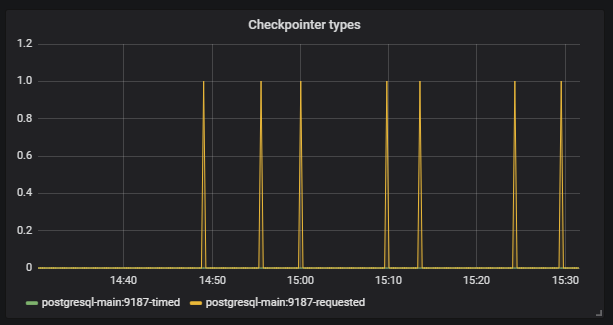
Tugas kita adalah mengkonfigurasi database dengan benar sehingga situasi seperti itu tidak terulang kembali. Postgresql yang sama memiliki banyak pengaturan. Untuk fine tuning, Anda perlu bekerja dalam iterasi pendek: mengoreksi konfigurasi, diluncurkan, diperiksa, dikoreksi konfigurasi, diluncurkan, diperiksa. Tentu saja, untuk ini Anda harus menerapkan beban yang baik ke pangkalan, tetapi untuk ini Anda hanya perlu tes infrastruktur besar.
Keunikannya adalah agar tes dapat berakselerasi secara normal dan tidak jatuh di tempat yang tidak diperlukan, overclocking harus panjang. Kami membutuhkan waktu sekitar tiga jam untuk menguji, dan ini tidak lagi terlihat seperti iterasi pendek.
Kami mencari solusi. Kami menemukan salah satu alat Postgresql -
Pg_replay . Dia dapat membuat multi-threaded persis apa yang ditulis dalam log dan persis seperti yang terjadi pada saat rekaman mereka. Bagaimana kita dapat menggunakannya secara efektif? Kami menutup basis dump, lalu mencatat semua yang terjadi pada basis data setelah menyimpan ke log, dan kemudian kami memiliki kesempatan untuk menggunakan dump dan memainkan semua yang terjadi dengan basis multithreaded.
Di mana menulis log? Solusi populer untuk merekam log adalah dengan mengumpulkannya pada prod, karena ini memberikan skrip yang dapat direproduksi paling realistis. Tetapi ada sejumlah masalah:
- Untuk pengujian Anda perlu menggunakan data penjualan, yang tidak selalu memungkinkan;
- Prosesnya menggunakan operasi syslog yang mahal;
- Disk sedang memuat.
Pendekatan kami untuk tes besar membantu kami di sini. Kami melakukan dump pada lingkungan pengujian, menjalankan tes besar dan mencatat log dari semua yang terjadi pada saat skrip realistis dijalankan. Selanjutnya, kami menggunakan alat
marucy kami sendiri untuk menguji database:
- Sebuah instance dibuat di AWS;
- Tumpukan yang kami butuhkan dikerahkan;
- Pg_replay diluncurkan dan memainkan log yang diperlukan;
- Kami menggunakan pemantauan kami untuk menganalisis hasil Prometheus + Grafana. Ada contoh dasbor di repositori.
Saat memulai marucy, kami dapat mengirimkan sejumlah kecil parameter yang dapat diubah, misalnya, intensitas skrip.
Akibatnya, kami menggunakan skrip realistis kami untuk membuat tes, dan kemudian memainkan tes tanpa menggunakan cluster besar. Penting untuk mempertimbangkan bahwa untuk menguji setiap basis data sql, skrip harus tidak rata, jika tidak database itu akan berperilaku berbeda dari prod.
Pemantauan degradasi
Untuk pengujian degradasi, kami menggunakan skenario realistis kami. Idenya adalah bahwa kita perlu memastikan bahwa layanan tidak bekerja lebih lambat setelah rilis berikutnya. Jika pengembang kami mengubah kode yang mengarah ke peningkatan waktu eksekusi permintaan, kami dapat membandingkan nilai-nilai baru dengan yang referensi dan memberi sinyal jika build memiliki kesalahan. Untuk nilai referensi, kami mengambil nilai saat ini yang sesuai dengan kami.
Mengontrol waktu eksekusi permintaan berguna, tetapi kami melangkah lebih jauh. Kami ingin melihat bahwa waktu respons selama pekerjaan pengguna nyata setelah rilis tidak menjadi lebih lama. Kami berpikir bahwa pada saat stress test, kami mungkin dapat masuk dan memeriksa sesuatu, tetapi ini hanya akan belasan kasus. Lebih efisien untuk menjalankan tes fungsional yang ada dan melihat seribu kasus dalam waktu bersamaan.

Bagaimana cara kerjanya untuk kita? Ada master yang, setelah perakitan, dikerahkan ke bangku tes. Kemudian, tes fungsional secara otomatis berjalan paralel dengan tes beban. Kemudian kami mendapatkan laporan di Allure tentang bagaimana tes fungsional berjalan di bawah beban.
Dalam laporan ini, misalnya, kita melihat bahwa uji perbandingan telah jatuh dengan nilai referensi.
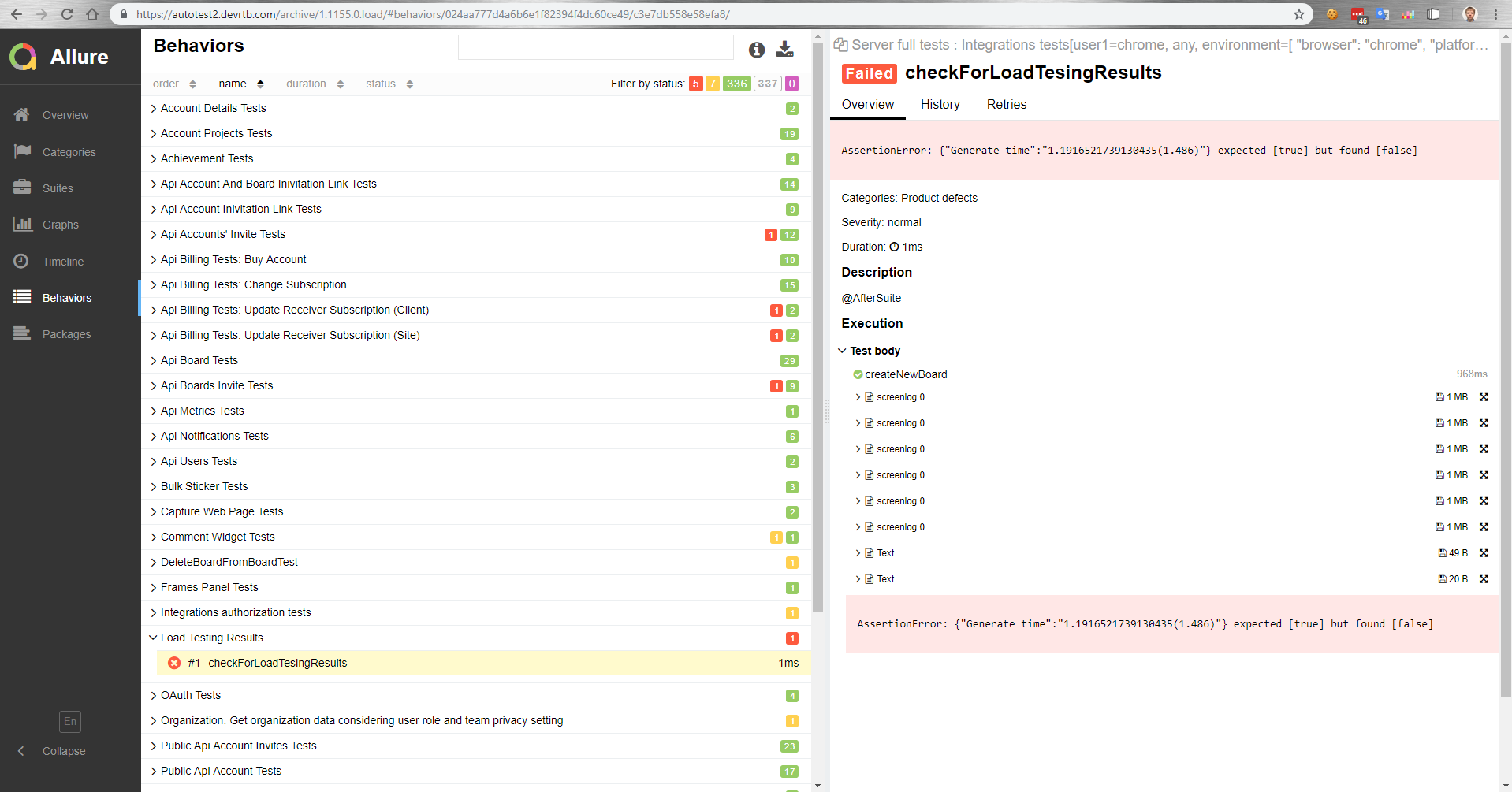
Juga dalam tes fungsional, kita dapat mengukur waktu pelaksanaan operasi di browser. Atau, tes fungsional sama sekali tidak berhasil karena peningkatan waktu pelaksanaan operasi di bawah beban, karena batas waktu pada klien akan bekerja.
Hasil untuk bagian ini
- Tes realistis memungkinkan Anda menguji basis data dengan murah dan mengkonfigurasinya dengan mudah;
- Pengujian fungsional di bawah beban dimungkinkan.
Artikel selanjutnya adalah tentang bagaimana kami mengelola ratusan server untuk uji beban.