Penguraian teks selalu dimulai dengan analisis leksikal atau tokenizing. Ada cara mudah untuk menyelesaikan masalah ini untuk hampir semua bahasa menggunakan ekspresi reguler. Penggunaan lain dari regexp tua yang baik.
Saya sering menghadapi tugas mengurai teks. Untuk tugas-tugas sederhana, seperti menganalisis nilai yang dimasukkan pengguna, fungsi ekspresi reguler dasar sudah cukup. Untuk tugas yang rumit dan berat seperti menulis kompiler atau analisis kode statis, Anda dapat menggunakan alat khusus (AntLR, JavaCC, Yacc). Tetapi saya sering menemukan tugas-tugas tingkat menengah, ketika tidak ada cukup ekspresi reguler, tapi saya tidak ingin menarik alat-alat berat ke dalam proyek. Selain itu, alat ini biasanya berfungsi pada tahap waktu kompilasi dan pada saat run-time tidak memungkinkan perubahan parameter analisis (misalnya, membentuk daftar kata kunci dari file atau tabel database).
Sebagai contoh, saya akan memberikan tugas yang muncul selama proses mempercepat query SQL . Kami menganalisis log kueri SQL kami dan ingin menemukan kueri "buruk" menurut aturan tertentu. Misalnya, kueri tempat bidang yang sama diperiksa untuk serangkaian nilai menggunakan OR
name = 'John' OR name = 'Michael' OR name = 'Bob'
Kami ingin mengganti permintaan tersebut dengan
name IN ('John', 'Michael', 'Bob')
Ekspresi reguler tidak bisa lagi mengatasinya, tetapi saya juga tidak ingin membuat parser SQL lengkap menggunakan AntLR. Dimungkinkan untuk membagi teks permintaan menjadi token dan menggunakan kode sederhana untuk membuat penguraian tanpa alat khusus.
Masalah ini dapat dipecahkan dengan menggunakan fungsionalitas dasar dari ekspresi reguler. Mari kita coba untuk membagi query SQL menjadi token. Kami akan melihat versi SQL yang disederhanakan agar tidak membebani teks dengan detail. Untuk membuat lexer SQL lengkap, Anda harus menulis ekspresi reguler yang sedikit lebih kompleks.
Berikut adalah serangkaian ekspresi untuk token bahasa SQL dasar:
1. keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b 2. id : [A-Za-z][A-Za-z0-9]* 3. real_number : [0-9]+\.[0-9]* 4. number : [0-9]+ 5. string : '[^']*' 6. space : \s+ 7. comment : \-\-[^\n\r]* 8. operation : [+\-\*/.=\(\)]
Saya ingin memperhatikan ekspresi reguler untuk kata kunci
keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b
Ini memiliki dua fitur.
- Operator \ b digunakan di awal dan di akhir, misalnya, agar tidak memotong atau awalan dari organisasi kata, yang merupakan kata kunci dan yang beberapa mesin regex akan terpisah menjadi token terpisah tanpa menggunakan operator \ b.
- semua kata dikelompokkan oleh tanda kurung non-menangkap (? :) yang tidak menangkap pertandingan. Ini akan digunakan di masa depan agar tidak melanggar pengindeksan ekspresi reguler parsial dalam ekspresi umum.
Sekarang Anda dapat menggabungkan semua ekspresi ini menjadi satu kesatuan, menggunakan pengelompokan dan operator |
(\b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b)|([A-Za-z][A-Za-z0-9]*)|([0-9]+\.[0-9]*)|([0-9]+)|('[^']*')|(\s+)|(\-\-[^\n\r]*)|([+\-\*/.=\(\)])
Sekarang Anda dapat mencoba menerapkan ekspresi ini ke ekspresi SQL, misalnya untuk itu
SELECT count(id)
Berikut ini hasilnya pada Regex Tester. Dengan mengklik tautan, Anda dapat bermain-main dengan ekspresi dan hasil analisis. Dapat dilihat bahwa, misalnya, SELECT berkorespondensi langsung dengan 1 grup, yang sesuai dengan jenis kata kunci .
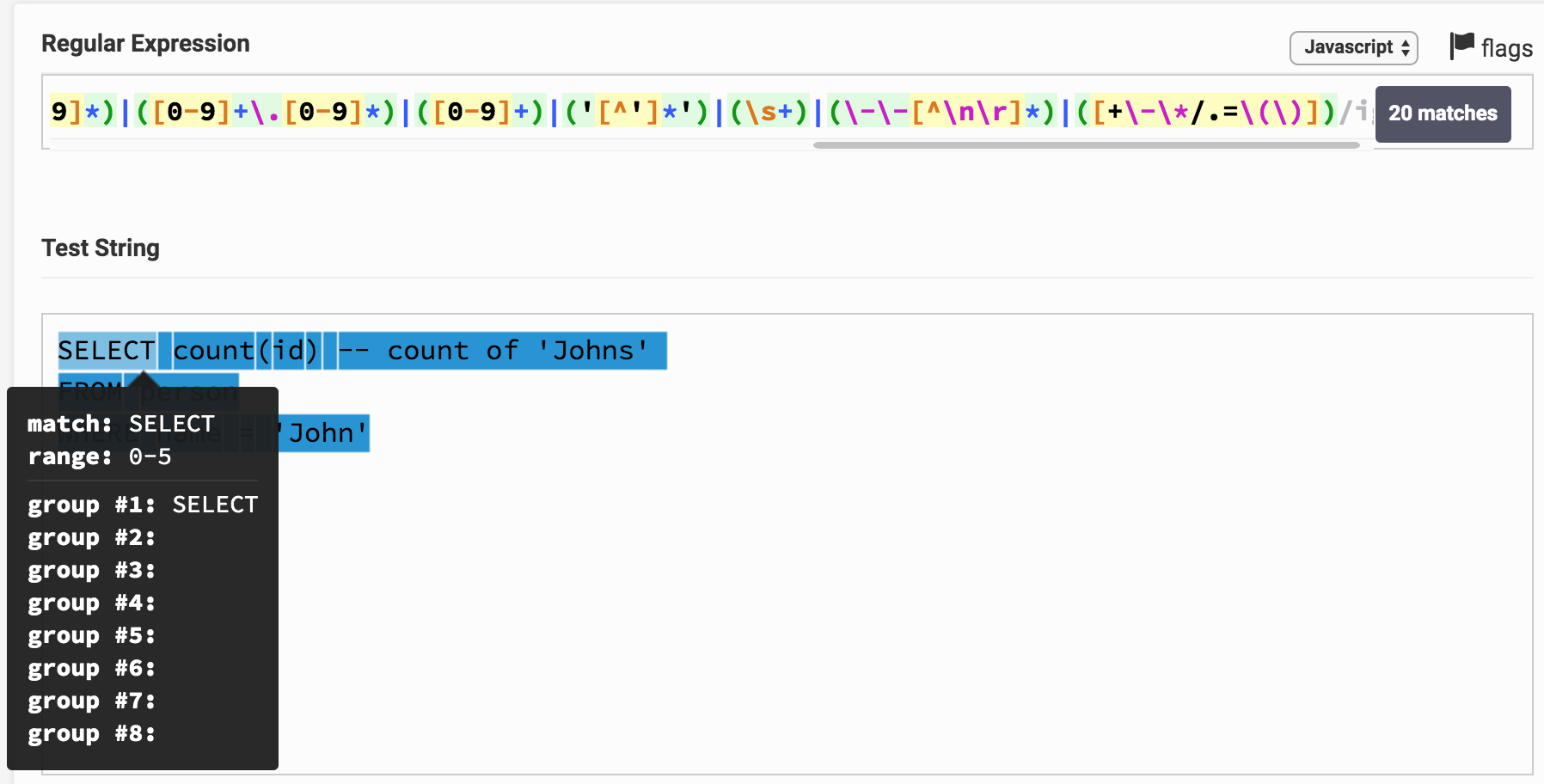
Anda mungkin memperhatikan bahwa seluruh teks permintaan ternyata dibagi menjadi substring dan masing-masing sesuai dengan grup tertentu. Dengan nomor grup, Anda dapat menghubungkannya dengan jenis token (token).
Membuat algoritma yang diberikan menjadi program dalam bahasa pemrograman apa pun yang mendukung ekspresi reguler tidaklah sulit. Ini adalah kelas kecil yang mengimplementasikan ini di Jawa.
RegexTokenizer.java (+ beberapa kelas lagi) package org.example; import java.util.ArrayList; import java.util.Enumeration; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; import java.util.stream.Collectors; public class RegexTokenizer implements Enumeration<Token> {
Di kelas ini, algoritma diimplementasikan menggunakan kelompok bernama, yang tidak ada di semua mesin. Fitur ini memungkinkan Anda untuk mengakses grup bukan dengan indeks, tetapi dengan nama, yang sedikit lebih nyaman daripada mengakses dengan indeks.
Pada I7 2.3GHz saya, kelas ini menunjukkan kecepatan analisis 5-20 MB per detik (tergantung pada kompleksitas ekspresi). Algoritme dapat diparalelkan dengan menganalisis beberapa file sekaligus, meningkatkan kecepatan kerja secara keseluruhan.
Saya menemukan beberapa algoritme yang serupa di jaringan, tetapi saya menemukan opsi yang tidak membentuk ekspresi reguler yang sama, tetapi secara konsisten menerapkan ekspresi reguler untuk setiap jenis token ke awal baris, kemudian membuang token yang ditemukan dari awal baris dan sekali lagi mencoba menerapkan semua regexps. Ini bekerja sekitar 10-20 kali lebih lambat, membutuhkan lebih banyak memori dan algoritma lebih rumit. Saya mencapai kecepatan kerja yang lebih besar hanya dengan menggunakan implementasi ekspresi reguler saya berdasarkan DFA ( deterministic finite state machine). Dalam mesin regex, NKA biasanya digunakan - mesin keadaan terbatas nondeterministic ). DFA 2-3 kali lebih cepat, tetapi ekspresi reguler untuk itu lebih sulit untuk ditulis karena terbatasnya operator.
Dalam contoh saya untuk SQL, saya menyederhanakan ekspresi reguler sedikit dan tokenizer yang dihasilkan tidak dapat dianggap sebagai analisa leksikal penuh dari query SQL, tetapi tujuan artikel ini adalah untuk menunjukkan prinsip, dan tidak membuat tokenizer SQL nyata. Saya menggunakan pendekatan ini dalam praktik saya dan membuat analisis leksikal penuh untuk SQL, Java, C, XML, HTML, JSON, Pascal, dan bahkan COBOL (saya harus mengotak-atiknya).
Berikut adalah beberapa aturan sederhana untuk menulis ekspresi reguler untuk analisis leksikal.
- Jika token yang sama dapat ditetapkan untuk jenis yang berbeda (misalnya, kata kunci apa pun dapat dikenali sebagai pengidentifikasi), maka jenis yang lebih sempit harus ditentukan di awal. Kemudian ekspresi reguler untuk itu akan diterapkan terlebih dahulu dan itu akan menentukan jenis token. Misalnya, dalam contoh saya, kata kunci didefinisikan sebelum id dan token pilih akan dikenali sebagai kata kunci , bukan id
- Tentukan token yang lebih panjang terlebih dahulu, lalu yang lebih pendek. Misalnya, Anda pertama-tama perlu mendefinisikan <= , > = dan kemudian memisahkan > , < , = Dalam hal ini, teks <= akan dikenali dengan benar sebagai token tunggal dari operator yang kurang dari atau sama, dan bukan dua token yang terpisah < dan =
- Belajarlah untuk menggunakan lookahead dan lookbehind . Sebagai contoh, karakter * dalam SQL memiliki arti operator perkalian dan indikasi semua bidang dalam tabel. Menggunakan tampilan sederhana di belakang , Anda dapat memisahkan dua kasus ini, misalnya, di sini regexp (? <=. \ S | select \ s ) * menemukan karakter * hanya dalam nilai "semua bidang tabel".
- Terkadang berguna untuk mendefinisikan ekspresi reguler untuk kesalahan yang terjadi dalam teks. Misalnya, jika Anda melakukan penyorotan sintaks, Anda dapat mendefinisikan jenis token string yang belum selesai sebagai
'[^\n\r]* . Dalam proses pengeditan teks, pengguna mungkin tidak punya waktu untuk menutup tanda kutip dalam string, tetapi tokenizer Anda akan dapat mengenali situasi ini dengan benar dan menyorotnya dengan benar.
Dengan menggunakan aturan ini dan menerapkan algoritma ini, Anda dapat dengan cepat membagi teks menjadi token untuk hampir semua bahasa.