Kita semua menyukai dan menggunakan fitur-fitur menarik dari Grup Ketersediaan pada replika sekunder, seperti pemeriksaan integritas, cadangan, dll.
Bahkan, ketidakmampuan untuk menyimpan informasi ini dalam database pada replika masih sakit kepala (dan pikirkan hal-hal seperti CDC untuk ketidaknyamanan yang lebih parah).
Tapi berhentilah mengeluh, inilah ide utamanya: Microsoft terkasih, mari kita gunakan replika kami untuk memperbarui statistik ... well, dan lakukan lebih banyak lagi pada mereka.
Selalu ada * jalan, atau sesuatu seperti itu
* hampir selaluMari kita daftar detail dasar yang diketahui dari solusi yang mungkin pada Enterprise Edition MS SQL Server:
- kami dapat membuat replika dapat dibaca dan membaca data dari mereka (bukan berarti Anda selalu harus melakukan ini, tetapi jika Anda benar-benar tahu apa yang Anda lakukan ...);
- kita bisa menyalin objek kita ke Tempdb (ya, tabel multi-terabyte Anda mungkin tidak cocok untuk operasi semacam itu), atau ke database lain yang bisa ditulis;
- kita dapat menulis hasilnya ke folder bersama yang dapat diakses oleh kedua replika (biarkan itu menjadi file teks dalam file berbagi);
- kita dapat mengekspor statistik sebagai gumpalan dari SQL Server;
- kita dapat mengimpor gumpalan yang diunduh ke dalam statistik.
Ayo lakukan
Saya memiliki tes AG pada sepasang mesin virtual dengan SQL Server 2017 (Anda dapat menggunakan versi apa pun) dan saya akan membuat tabel sederhana di mana saya ingin memperbarui statistik.
Berikut ini adalah skrip untuk membuat tabel dan memasukkan sejuta baris ke dalamnya:
DROP TABLE IF EXISTS dbo.SampleDataTable; CREATE TABLE dbo.SampleDataTable ( C1 BIGINT NOT NULL, C2 BIGINT NOT NULL, CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1) ); INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT t.RN, t.RN FROM ( SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
Sekarang mari kita buat statistik ST_SampleDataTable_C2 untuk kolom c2
CREATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2);
Dan kemudian saya akan memasukkan 1000 baris, yang akan sangat penting dan karena itu saya benar-benar perlu memperbarui statistik.
set nocount on; INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT 10000000 + t.RN, 999999999 FROM ( SELECT TOP (1000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
Sekarang saya memiliki 1000 entri di mana, di kolom C2, nilainya 999999999. Dan ini pasti berarti Masalah Kunci yang Meningkat dan saya benar-benar perlu memperbarui statistik ... pada replika sehingga saya tidak membebani server utama dengan perhitungan dan mencegahnya melayani pelanggan.
Menggunakan perintah DBCC SHOW_STATISTICS tua yang baik, mari kita periksa statistik kami.
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
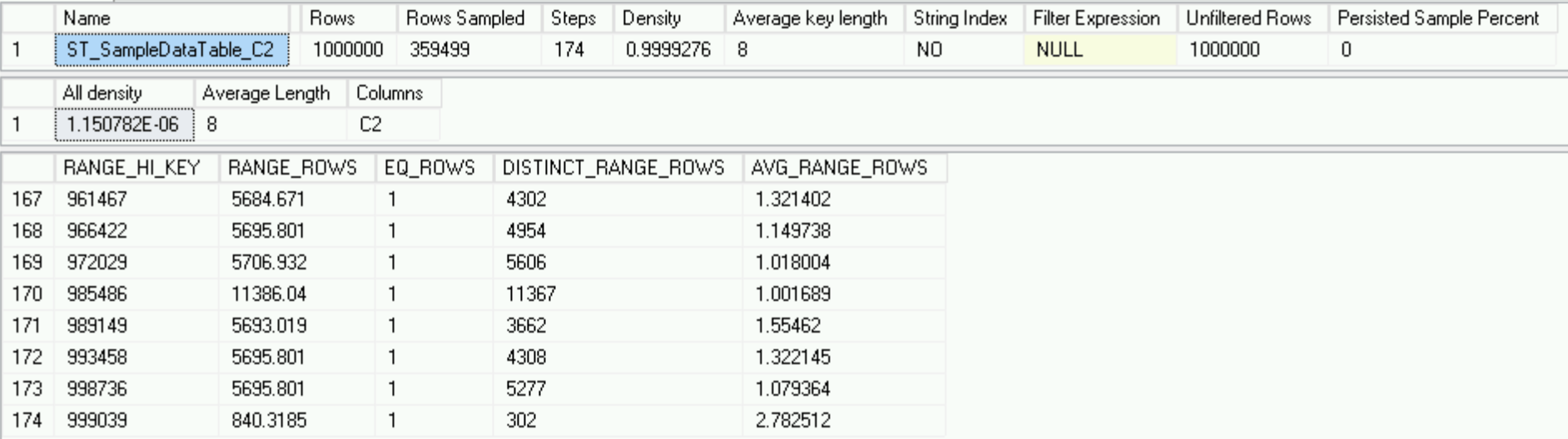
Semuanya sempurna di kerajaan kita dan statistik kita dalam urutan yang sempurna, meskipun hanya memperhitungkan 1 juta baris dan tidak ada ribuan garis yang berbahaya, yang, pada akhirnya, harus menjadi bagian dari statistik ini.
Selain itu, kita dapat melihat aliran statistik menggunakan parameter STATS_STREAM dari perintah DBCC SHOW_STATISTICS:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;

Ini hanya rangkaian karakter yang telah ditulis blog selama bertahun-tahun, tetapi saya masih tidak yakin apakah ini fitur yang sepenuhnya didokumentasikan (meskipun tidak pernah menghentikan orang untuk menggunakannya).
Atas isyarat
Mari kita salin tabel kita pada replika ke tempdb (meskipun AG saya dalam mode sinkron, hal yang sama dapat dilakukan dalam asinkron, hanya data yang mungkin datang dengan sedikit penundaan).
use TempDB; DROP TABLE IF EXISTS dbo.SampleDataTable; CREATE TABLE dbo.SampleDataTable ( C1 BIGINT NOT NULL, C2 BIGINT NOT NULL, CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1) ); INSERT INTO dbo.SampleDataTable SELECT C1, C2 FROM AvGroupDb.dbo.SampleDataTable;
Sekarang kami siap untuk memperbarui statistik dengan pemindaian penuh di tempdb pada replika.
use TempDB; UPDATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2) WITH FULLSCAN;
(
Catatan Penerjemah - Nico lupa membuat statistik, dan menggunakan sintaks yang salah dari operasi STATISTIK UPDATE, alih-alih UPDATE itu harus MENCIPTAKAN, yaitu statistik tidak diperbarui, tetapi dibuat )
Kembali ke DBCC SHOW_STATISTICS dan lihat itu:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
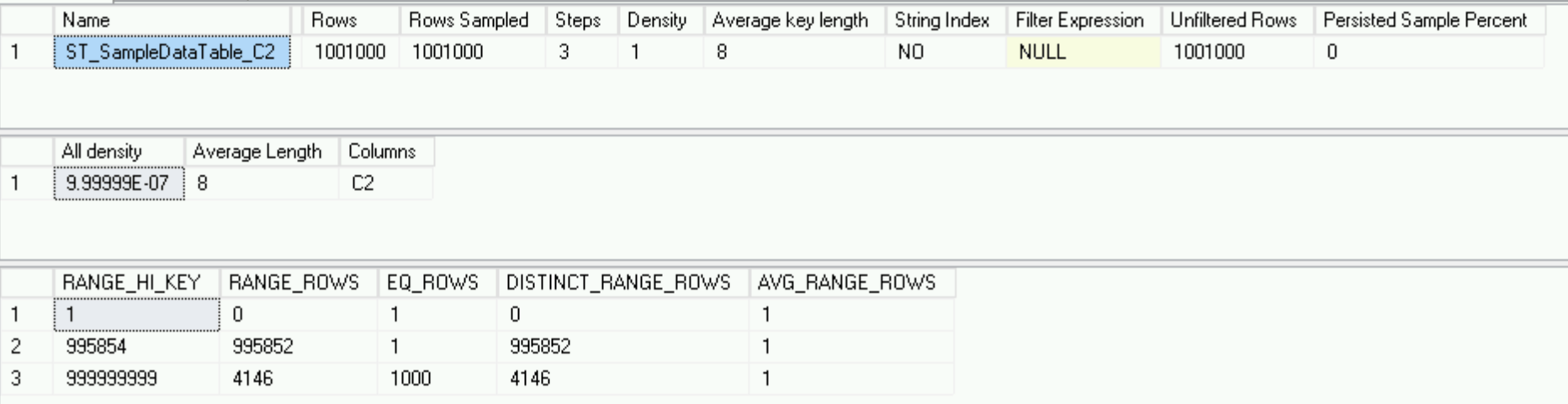
Itu terlihat sangat berbeda dari apa yang ada di server utama - hanya 3 baris versus 178, tetapi itu menggambarkan data dengan sempurna - kami memiliki sejuta baris unik dan 1000 baris dengan nilai kolom C2 yang sama - histogram sebagus mungkin .
Mari kita lihat aliran statistik:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;

Anda tidak perlu menjadi jenius untuk melihat bahwa aliran terlihat sangat berbeda - kami melihat karakter 5689A0C6 dalam aliran yang diperbarui, sementara di aslinya, di antara semua nol ini kami melihat EDF10EB4.
Mari kita berkonsentrasi pada mengekspor data ini ke file teks di suatu tempat di luar SQL Server dan melakukannya dengan bantuan perintah BCP yang luar biasa, yang mengharuskan CMDSHELL diaktifkan (catatan: Anda mungkin tidak menginginkan ini di server produksi Anda):
EXEC xp_cmdshell 'BCP "DBCC SHOW_STATISTICS(''AvGroupDb.dbo.SampleDataTable'', ''ST_SampleDataTable_C2'') WITH STATS_STREAM" queryout \\SharedServer\Tempdb\stats.txt -c -T';
Dan inilah seberapa besar file stats.txt akan berada di bola kita:

Hanya beberapa kilobyte! Mudah ditransmisikan, mudah dikelola.
Kembali ke server utama
Di server utama, kita perlu membuat tabel sementara yang akan menyimpan aliran statistik sebelum kita dapat memperbarui statistik dari itu di tabel SampleDataTable utama kita (dalam praktiknya, kita dapat memperluas tabel ini untuk banyak basis data, tabel, statistik).
CREATE TABLE dbo.TempStats( Stats_Stream VARBINARY(MAX), Rows BIGINT, DataPages BIGINT );
Mari mengimpor data dari file teks kami ke tabel sementara kami yang baru dan lihat apa yang kami impor:
BULK INSERT dbo.TempStats FROM '\\SharedServer\Tempdb\stats.txt' SELECT * FROM dbo.TempStats;

Kita dapat melihat data yang sama dengan yang kita hitung pada replika, tetapi data ini sudah ada di server utama kita dan yang tersisa untuk kita lakukan adalah memperbarui statistik kita dari mereka dalam tabel. Operasi ini dapat dilakukan dengan menggunakan operasi STATISTIK PEMBARUAN menggunakan parameter WITH STATS_STREAM = ...
DECLARE @script NVARCHAR(MAX) SELECT @script = 'UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM = ' + CONVERT(nvarchar(max), [Stats_Stream],1) FROM dbo.TempStats PRINT @script; EXECUTE sp_executesql @script;
Skrip ini membaca nilai yang diimpor di atas (ya, saya tahu - saya melakukan contoh ini untuk satu tabel dan tidak repot dengan beberapa statistik, tabel, database, dll.), Menghasilkan pernyataan STATISTIK PEMBARUAN, menampilkannya di layar dan, pada akhirnya, memenuhi itu.
Inilah yang saya dapatkan di output:
UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM =
Menjalankan DBCC SHOW_STATISTICS di server utama memberi saya hasil yang saya harapkan - sama seperti apa yang kami lihat di replika. Lingkaran ditutup.
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2');
Bagian yang sangat mengagumkan dari cerita ini adalah bahwa ukuran objek dengan statistik sangat kecil dan kita dapat mentransfernya ke server utama dengan sangat mudah / instan.
Skenario tidak begitu mendasar.
Jika Anda memiliki beberapa AG di antara replika yang sama, di mana satu replika adalah yang utama dalam satu AG dan yang lainnya adalah yang utama di yang kedua, maka Anda dapat memasukkan data BLOB ke dalam aliran data antara replika dan menambahkan database kecil dengan data yang dikirimkan.
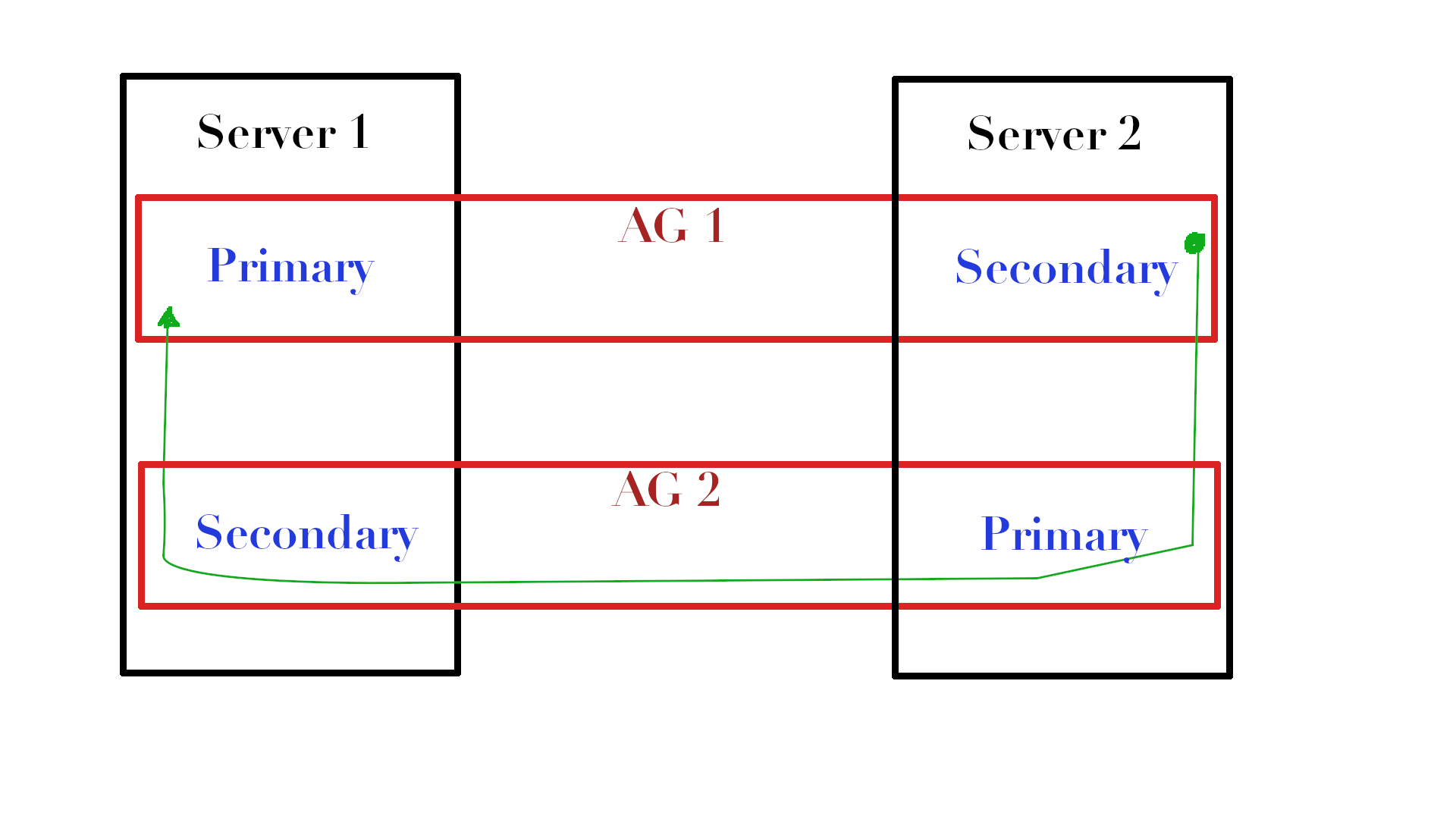
Lihat gambarnya. Jika kami memiliki dua AG (AG1 & AG2) yang terletak di server yang berbeda dan kami memiliki tabel spesifik pada Server1 di AG1 yang ingin kami perbarui statistiknya, maka pada Server2 kami dapat menyalin tabel ini (sebut saja dbo.MyTable ) di tempdb, perbarui, dan menggunakan AG2 kirim objek dengan aliran statistik kembali ke Server1, di mana Anda hanya mengimpor statistik dari aliran ini ke statistik yang kami butuhkan.
Ya, saya tahu, kedengarannya membingungkan, tetapi anggap saja sebagai saluran umpan balik di mana hasilnya dikirim, alih-alih menempatkannya di file bola.
Tempat untuk keraguan
Anda mungkin memiliki beberapa keberatan, misalnya:
- mengapa saya harus melakukan ini pada replika jika saya dapat melakukannya dengan aman di server utama? (well, idenya adalah untuk membongkar server utama)
- tetapi jangan kita, berpotensi, memuat replika (ya, tetapi jika itu menganggur, itu sebabnya kami ingin menggunakan kekuatannya)
- dan kita tidak bisa bertindak di server utama? (tidak, kami baru saja membaca data dari replika dan mengirim kembali beberapa kilobyte, yang pada abad kami gigabyte dan terabyte terdengar seperti "shtoa?") ( Catatan penerjemah - secara umum, hanya dalam kasus replika AG yang dapat dibaca, kami dapat )
- Bagaimana jika di tengah proses server utama mulai memperbarui statistik sendiri? (dalam hal ini, dapat mengganggu proses kedua, atau memulai kembali dengan data yang diperbarui).
Saluran Umpan Balik AG
Ini adalah saluran dengan umpan balik dari replika ke server utama - setelah kami berjanji transaksi di AG sinkron, server utama akan menunggu konfirmasi dari replika - dan saya pikir saluran ini dapat digunakan untuk mengimplementasikan peningkatan ini. Lihatlah foto yang diambil di sebuah pos oleh
Simon Su .
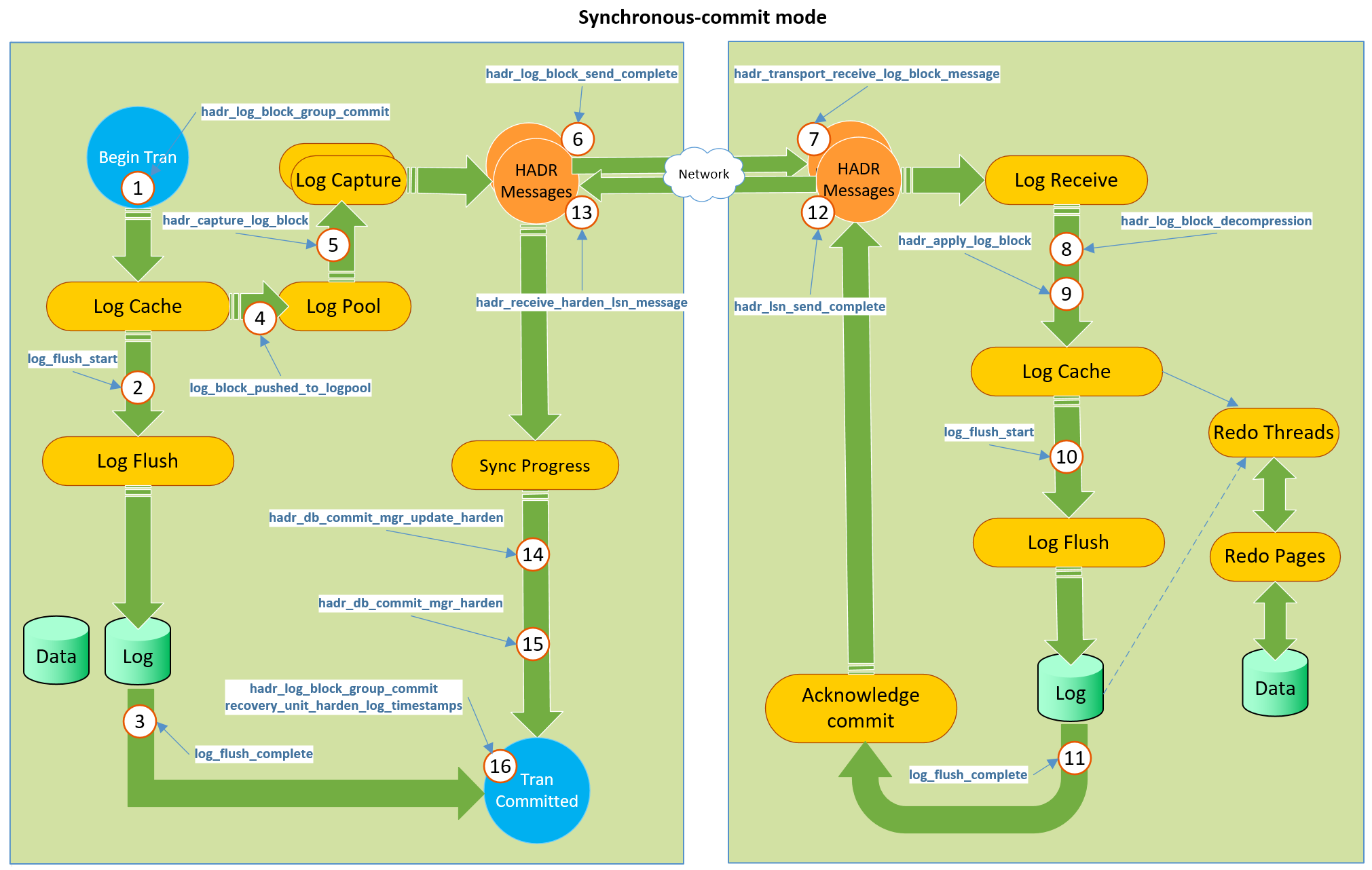
Yang mewakili seluruh mekanisme saluran umpan balik yang ada. Replika, menggunakan langkah 12 dan selanjutnya, mengkonfirmasi ke server utama bahwa informasi telah disimpan. Saluran yang sama dapat digunakan untuk mengirim objek aliran statistik setelah menghitung ulang pada replika. Tentu saja, kita tidak perlu menggunakan tempdb untuk tujuan ini, tetapi membuat objek dalam-memori di dalam database yang seharusnya tidak disimpan secara permanen (lihat tabel Hanya-OLema Skema OLTP Dalam Memori Anda, atau pikirkan tabel NOLOGGING di Oracle), dan harus dihapus pada akhir operasi - itu akan sangat keren.
Pikiran umum
Seharusnya tidak tergantung pada apakah replika sinkron atau tidak - sebagian besar statistik waktu tidak diperbarui setiap beberapa detik dan ini membawa kita ke bagian kedua dari ide - untuk membuat panggilan untuk memperbarui statistik di server utama dengan parameter seperti parameter
UPDATE STATISTICS dbo.MyAwesomeTable(HugeImportantStatOnC17) WITH FULLSCAN, SECONDARY
di mana parameter SECONDARY menunjukkan di mana operasi akan dilakukan.
Dan seperti halnya dengan cadangan, kita harus dapat menentukan replika yang disukai untuk melakukan STATISTIK PEMBARUAN (atau operasi lainnya di masa mendatang) dalam pengaturan.
Saya yakin bahwa fitur ini akan mendorong banyak pengguna Edisi Perusahaan untuk bermigrasi ke versi baru SQL Server, yang akan memungkinkan mendistribusikan operasi berat antar replika.
Adapun situasi saat ini, saya pasti melihat bagaimana Anda dapat mengotomatisasi solusi ini menggunakan Powershell.
Microsoft, giliran Anda! ;)
Pilih fitur yang diusulkan di
sini .
Catatan Penerjemah: Setiap saran dan komentar tentang terjemahan dan gaya disambut, seperti biasa.
Saya biasanya menyebut replika primer dalam terjemahan “server utama”, dan replika sekunder - hanya replika. Mungkin ini tidak sepenuhnya benar, tetapi telingaku sakit kurang dari replika "primer" dan "sekunder" di msdn.