
World Wide Web adalah lautan data. Di sini Anda dapat melihat hampir semua informasi yang Anda minati. Namun, "menarik" informasi ini dari Internet sudah lebih sulit. Ada beberapa cara untuk mendapatkan data dan web-scraping adalah salah satunya.
Apa itu pengikisan web? Singkatnya, ini adalah teknologi yang memungkinkan Anda untuk mengambil data dari halaman HTML. Saat menggunakan pengikisan, tidak perlu menyalin-menempelkan informasi yang diperlukan atau mentransfernya dari layar ke notepad. Informasi akan muncul di komputer Anda dalam bentuk yang nyaman bagi Anda.
Mengikis web pada contoh situs Kinopoisk.ru
Merupakan ide yang bagus untuk menetapkan sasaran sendiri agar tidak melakukan pengikisan demi pengikisan. Saya memutuskan bahwa ini akan menjadi perbandingan peringkat film di Kinopoisk.ru dan IMDB.com, serta peringkat rata-rata untuk film berdasarkan genre . Untuk analisis, diambil film yang dirilis dari 2010 hingga 2018, dengan minimum 500 suara.
Untuk memulai, muat perpustakaan yang kami butuhkan:
# library(rvest) library(selectr) library(xml2) library(jsonlite) library(tidyverse)
Selanjutnya, saya mendapatkan jumlah film dalam setahun yang memenuhi syarat pemilihan (lebih dari 500 suara). Ini dilakukan untuk mengetahui jumlah total halaman dengan data dan untuk "menghasilkan" tautan, karena tautan serupa dalam struktur.
# 2018 url <- "https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/1/#results"
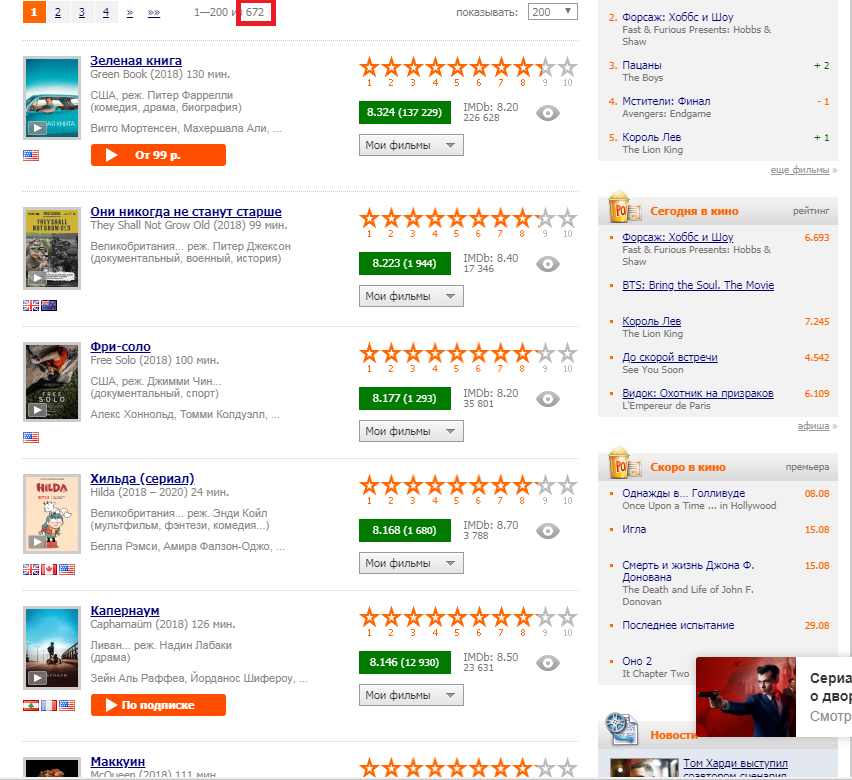
Tugas kita adalah "menarik keluar" nomor 672, disorot dalam gambar dengan kotak merah. Untuk ini kita perlu pengikisan web.
Situs Kinopoisk.ru situs web- rvest menggunakan paket rvest
Pertama kita perlu "membaca" url yang kami terima. Untuk melakukan ini, gunakan fungsi read_html() dari paket read_html() .
# XML HTML webpage <- read_html(url)
Dan kemudian, menggunakan fungsi dari paket rvest pertama-tama kita "mengekstrak" bagian dari dokumen HTML yang kita butuhkan (fungsi html_nodes() ), dan kemudian dari bagian ini kita mengekstrak informasi yang kita butuhkan dalam bentuk yang nyaman bagi kita (fungsi html_text() , html_table() , html_attr() lainnya)
Tetapi bagaimana kita memahami elemen mana yang perlu kita ekstrak? Untuk melakukan ini, kita harus mengarahkan kursor ke informasi yang kita minati, klik LMB dan pilih "view code". Dalam kasus kami, kami mendapatkan gambar berikut:
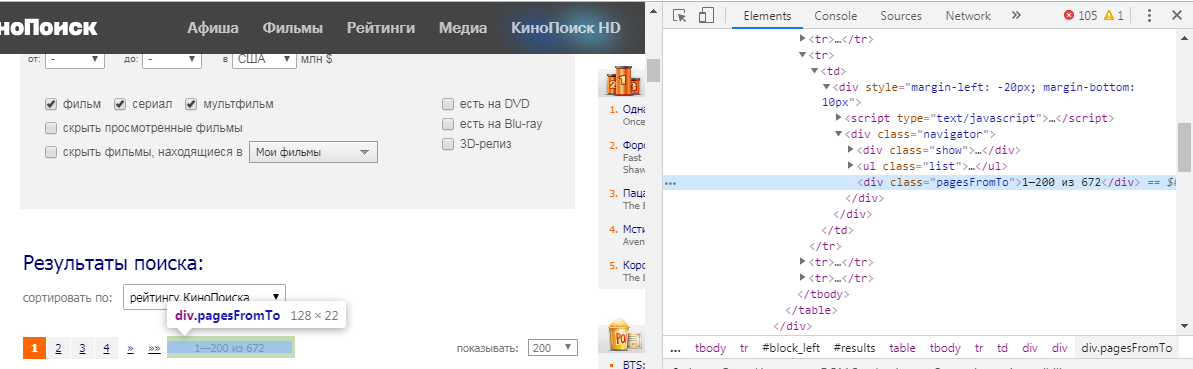
Fungsi html_nodes() memiliki bentuk html_nodes(x, css) . x adalah halaman web yang didefinisikan sebelumnya, tetapi dalam css kita menulis id atau kelas elemen. Dalam kasus kami, itu adalah:
number_html <- html_nodes(webpage, ".pagesFromTo")
Juga, untuk "mendeteksi" elemen yang diinginkan, Anda dapat menggunakan ekstensi selectorGadget , yang menunjukkan apa yang perlu kita masukkan secara eksplisit:
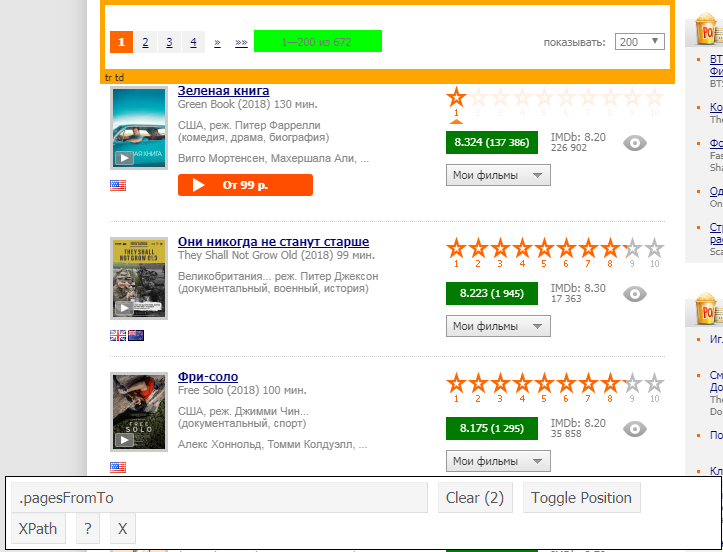
Selanjutnya, dengan fungsi html_text, kami mengekstrak bagian teks dari elemen yang dipilih:
number <- html_text(number_html) [1] "1—50 672" "1—50 672"
Kami mendapatkan nomor yang kami butuhkan dari halaman HTML Kinopoisk, tetapi sekarang kami perlu "membersihkannya". Ini adalah prosedur standar untuk mengikis, karena sangat jarang kita membutuhkan elemen yang kita butuhkan dalam bentuk yang kita butuhkan.
Kami mendapat 2 elemen identik karena fakta bahwa jumlah film ditunjukkan di bagian atas dan bawah halaman dan pemilih css mereka persis sama. Karenanya, sebagai permulaan, kami menghapus elemen berlebih:
number <- number[1] [1] "1—50 672"
Selanjutnya, kita perlu menyingkirkan bagian dari vektor yang naik ke angka 672. Anda dapat melakukan ini dengan cara yang berbeda, tetapi dasar dari semua metode adalah menulis ekspresi reguler. Dalam hal ini, saya “mengganti” bagian “1-50 dari” dengan kekosongan (Anda dapat menggunakan str_remove alih-alih str_replace ), kemudian menghapus spasi tambahan (fungsi str_trim ) dan akhirnya menerjemahkan vektor dari karakter ke tipe numerik. Pada output, saya mendapatkan nomor 672. Tepatnya begitu banyak film tahun 2018 memiliki lebih dari 500 suara pengguna di Kinopoisk.
number <- str_replace(number, ".{2,}", "") number <- as.numeric(str_trim(number)) [1] 672
Apa yang akan kita lakukan selanjutnya? Jika Anda melihat halaman-halaman di Kinopoisk Anda akan melihat bahwa alamat halaman pencarian memiliki struktur yang sama dan hanya berbeda dalam jumlah. Oleh karena itu, agar tidak memasukkan alamat halaman secara manual setiap kali, kami akan menghitung jumlah halaman dan “menghasilkan” jumlah alamat yang diperlukan. Ini dilakukan seperti ini:
# page_number <- ceiling(number/50) # page <- sapply(seq(1:page_number), function(n){ list_page <- paste0("https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/", n, "/#results") })
Outputnya adalah 14 alamat. Fungsi ceiling dalam contoh ini membulatkan angka ke bilangan bulat BESAR.
Dan kemudian kita menggunakan fungsi lapply ke input yang diberi alamat alamat halaman, dan fungsi "mengekstrak" informasi dari halaman Kinopoisk tentang nama, peringkat, jumlah suara dan genre utama (maksimal 3) dari film. Kode fungsi dapat ditemukan di repositori di Github .
Hasilnya, kami mendapatkan tabel dengan 8111 film.
Perlu dicatat tentang penggunaan fungsi Sys.sleep. Dengan menggunakannya, Anda dapat mengatur waktu tunda antar ekspresi. Mengapa ini dibutuhkan? Jika Anda ingin menerima informasi dalam satu tahun, maka tidak perlu. Tetapi jika Anda tertarik pada sejumlah besar film / tahun, maka setelah sejumlah permintaan, Kinopoisk akan menganggap Anda robot dan Anda akan menerima daftar kosong untuk permintaan Anda. Untuk menghindari ini, Anda harus memasukkan waktu tunda.
Demikian pula, "memo" situs IMDB.com.
Analisis Data
Kami memiliki dua tabel, di satu informasi tentang film dengan IMDB, di yang lain dari Kinopoisk. Sekarang kita perlu menggabungkannya. Kami akan bersatu sesuai dengan kolom NAMA dan TAHUN. Untuk mengurangi jumlah perbedaan dalam nama, bahkan pada tahap pengikisan, saya menghapus semua tanda baca dan mengubah huruf menjadi huruf kecil. Akibatnya, setelah semua koneksi dan penghapusan, kami mendapatkan 3450 film yang memiliki informasi yang kami butuhkan dari kedua situs.
Saya tertarik pada perbedaan dalam peringkat film di dua situs, jadi kami akan membuat variabel DELTA, yang merupakan perbedaan antara perkiraan IMDB dan Kinopoisk. Jika DELTA positif, maka skor IMDB lebih tinggi, jika negatif, lebih rendah.
Pertama, buat histogram untuk indikator DELTA:
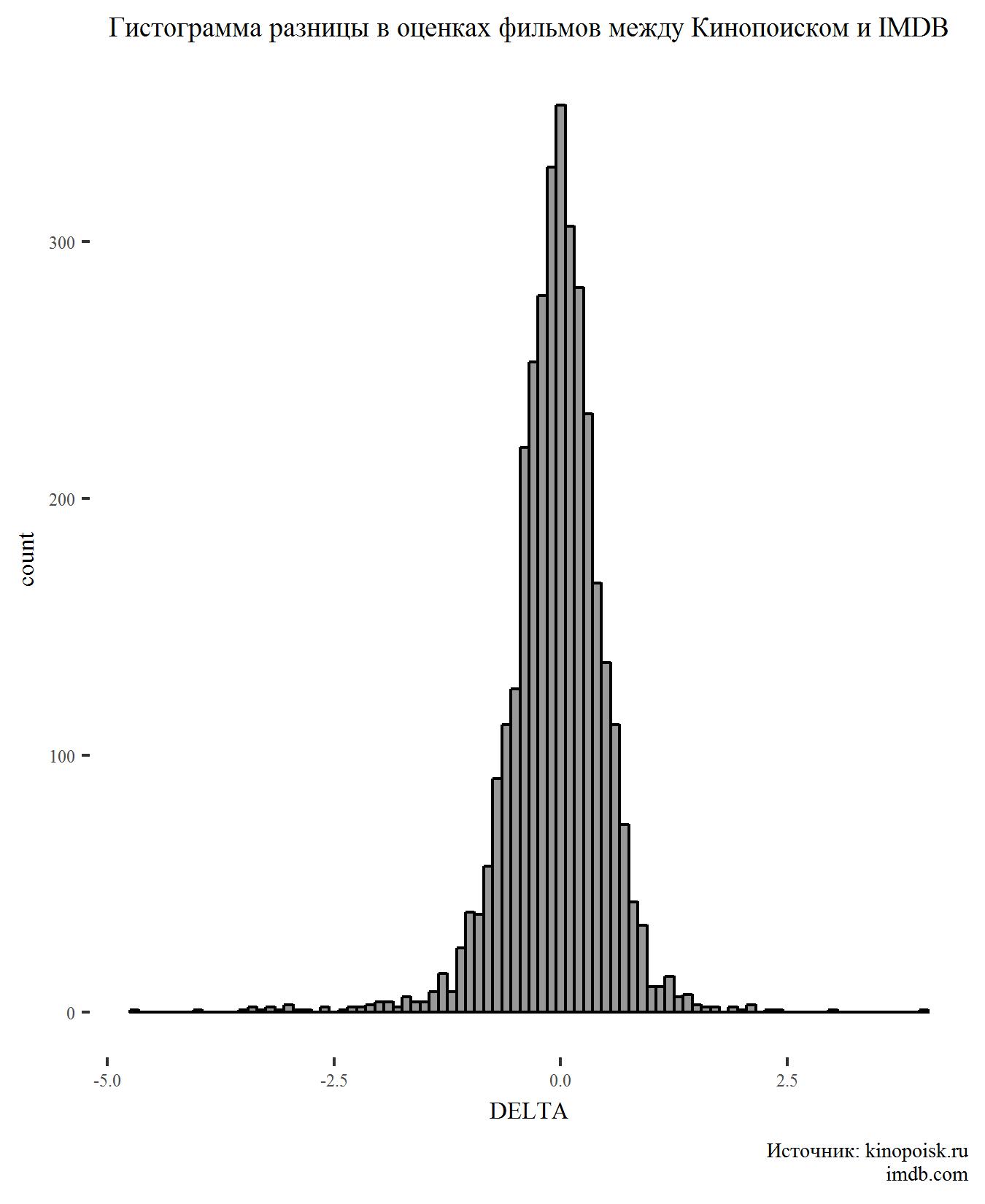
Tidak ada yang mengejutkan pada grafik. Perbedaan peringkat memiliki distribusi normal dan puncak di wilayah nol, yang menunjukkan bahwa pengguna kedua situs biasanya setuju pada peringkat film.
Berkumpul, tetapi tidak cukup. Uji-t dari dua sampel independen memungkinkan kita untuk mengatakan bahwa peringkat pada Kinopoisk lebih tinggi dan perbedaan ini signifikan secara statistik (p-value <0,05).
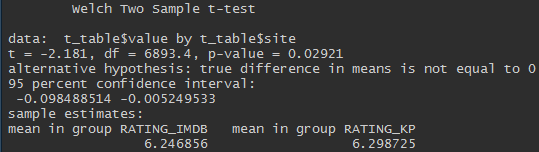
Meskipun perbedaannya signifikan, itu sangat kecil.
Selanjutnya, mari kita lihat bagaimana perbedaan dalam peringkat tergantung pada jumlah suara.
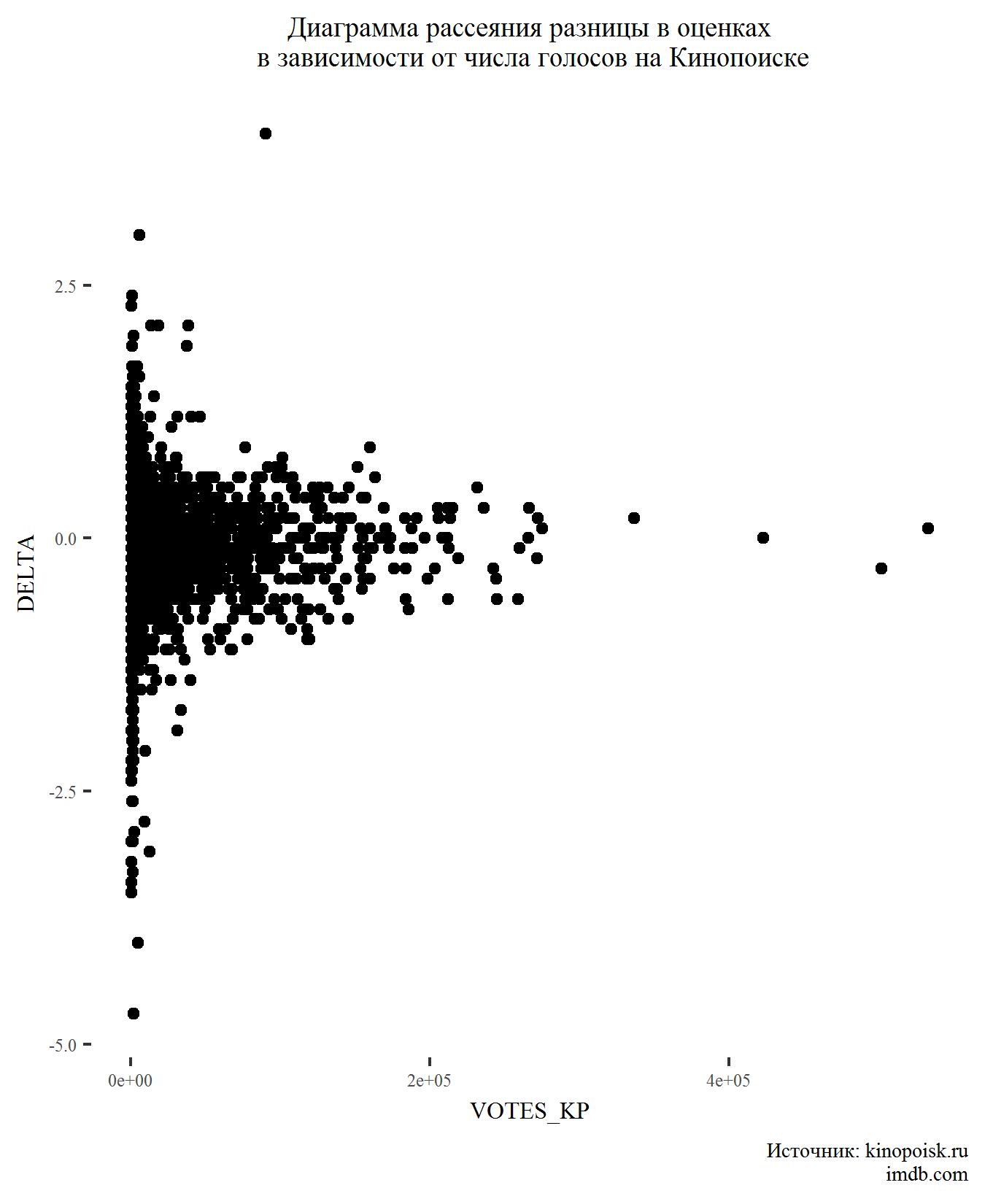
Tidak ada yang tak terduga di sini. Film dengan jumlah suara yang besar biasanya memiliki perbedaan peringkat yang sangat kecil.
Sekarang mari kita beralih ke mengevaluasi film berdasarkan genre. Perlu segera dicatat bahwa satu film dapat memiliki hingga tiga genre, tetapi hanya satu peringkat, sehingga satu film dapat masuk "ke dalam ujian" dan komedi, dan melodrama.
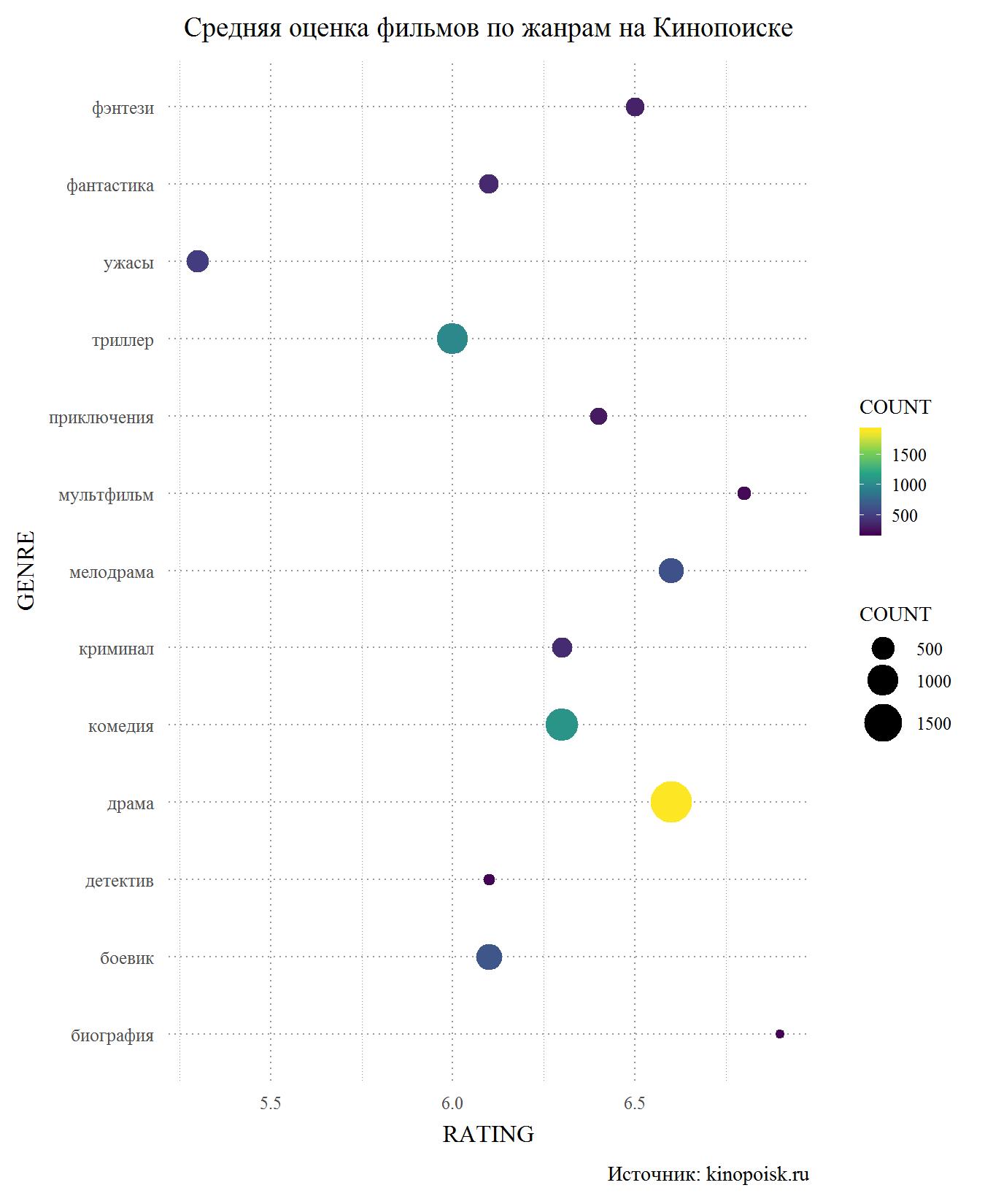
Mari kita mulai dengan Kinopoisk. Di antara genre dengan setidaknya 150 penampilan di basis data, horor adalah orang luar yang jelas. Juga pengguna tingkat rendah thriller, detektif aksi dan, yang mengejutkan bagi saya, fiksi ilmiah. Di sisi lain, film-film melodramatik di Kinopoisk hadir dengan ledakan, memiliki peringkat rata-rata di atas 6,5 dan yang kedua setelah kartun dan biopik, yang jauh lebih kecil dalam basis data
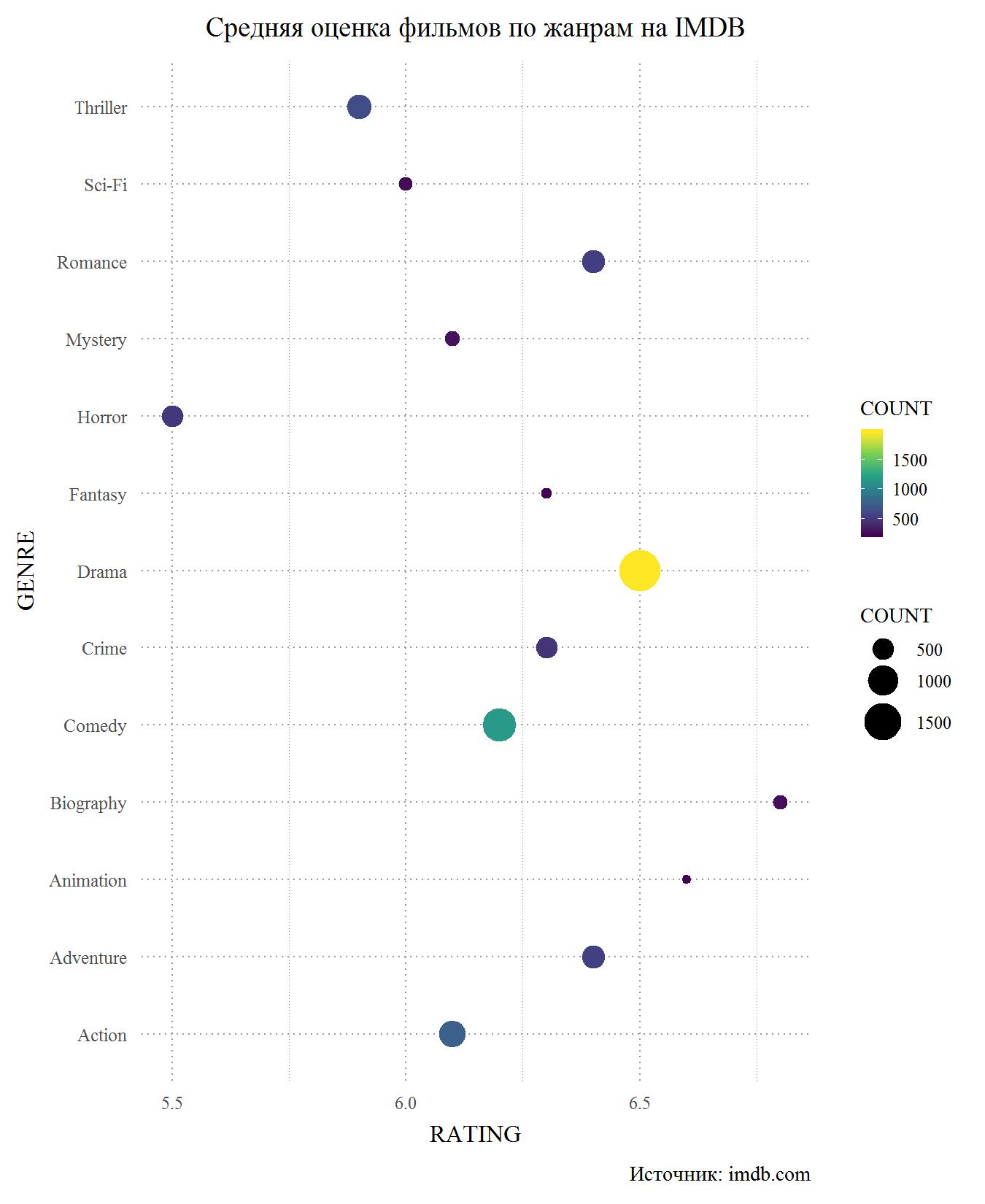
Sekarang perhatikan grafik yang sama, tetapi untuk IMDB. Pada prinsipnya, dia kembali menegaskan bahwa perbedaan peringkat antara situs tidak signifikan. Ini tidak mengherankan, karena banyak pengguna memiliki akun di kedua situs dan tidak mungkin memberikan peringkat yang berbeda di situs yang berbeda. Sekali lagi, pecundang utama adalah kengerian, dan kita dapat mengatakan bahwa mereka adalah genre film yang berperingkat paling rendah. Sulit bagi saya untuk menilai mengapa ini terjadi, karena satu-satunya film horor yang saya tonton dalam hidup saya adalah Gremlins. Mungkin itu adalah kengerian yang merupakan genre anggaran terendah, di mana permainan aktor lemah yang lemah dan skenario yang terus terang buruk berasal. Thrillers dengan fiksi ilmiah dan IMDB adalah di antara yang tertinggal, tetapi para militan melakukan lebih baik. Di antara para pemimpinnya adalah lagi film biografi dan kartun. Drama ini menempati posisi ketiga, tetapi skor untuk melodrama jatuh di bawah 6,5, ke tingkat film petualangan. Juga di IMDB di bawah komedi.
Kesimpulan dan sedikit tentang "faktor eksternal"
Meskipun ada perbedaan dalam perkiraan (pada Kinopoisk mereka sedikit lebih tinggi), tetapi hanya sedikit. Menurut berbagai genre, perbedaan besar juga tak terlihat. Blockbuster yang memiliki puluhan atau bahkan ratusan ribu suara, jika mereka memiliki perbedaan, maka dalam 0,5 poin.
Film dengan jumlah suara kecil (terutama di Kinopoisk), hingga 10 ribu, biasanya memiliki perbedaan besar dalam peringkat. Namun, perbedaan terbesar dalam peringkat yang mendukung IMDB adalah film dengan 30.000 suara di situs asing dan lebih dari 90.000 di Kinopoisk. Ini adalah penciptaan Alexei Pimanov "Crimea". Apakah filmnya begitu disukai oleh pemirsa asing? Hampir tidak. Kemungkinan besar, para pembuat film menggunakan "kebijakan pemasaran" yang sama sehubungan dengan IMDB seperti di Kinopoisk. Hanya saja jika Kinopoisk "membersihkan" perkiraan seperti itu, maka mereka tetap menggunakan IMDB. Saya pikir itu sebabnya ada "Krimea" adalah "kinchik kecil yang baik".
Saya akan berterima kasih atas komentar, saran, keluhan
Tautan repositori Github
Profil Lingkaran Saya