Halo semuanya. Saya akan memberi tahu Anda tentang layanan microser, tetapi dari sudut pandang yang sedikit berbeda dari Vadim Madison di postingan “Apa yang kita ketahui tentang layanan microser” . Secara umum, saya menganggap diri saya seorang pengembang basis data. Apa hubungan microservices dengan itu? Avito menggunakan: Vertica, PostgreSQL, Redis, MongoDB, Tarantool, VoltDB, SQLite ... Secara total, kami memiliki 456+ database untuk 849+ layanan. Dan entah bagaimana Anda harus hidup dengannya.
Dalam posting ini saya akan memberi tahu Anda tentang bagaimana kami mengimplementasikan penemuan data dalam arsitektur microservice. Posting ini adalah transkrip gratis laporan saya dengan Highload ++ 2018 , videonya dapat dilihat di sini .

Setiap orang harus tahu bagaimana arsitektur microservice harus dibangun dalam hal basis. Berikut adalah pola yang biasanya dimulai oleh setiap orang. Ada pangkalan bersama antara layanan. Pada slide, persegi panjang oranye adalah layanan, ada basis bersama di antara mereka.
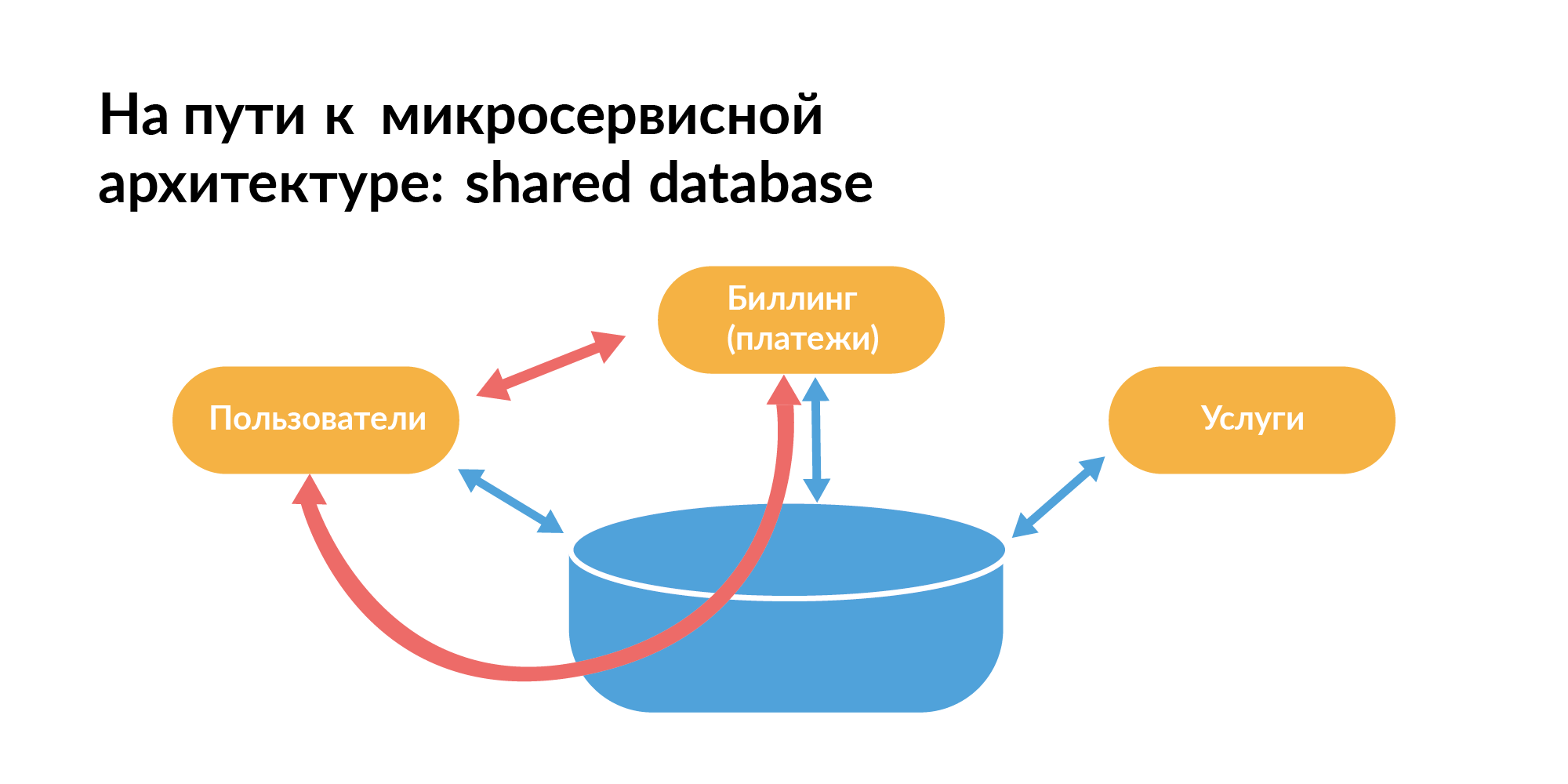
Anda tidak dapat hidup seperti itu, karena Anda tidak dapat menguji layanan secara terpisah ketika, selain komunikasi langsung di antara mereka, ada juga komunikasi melalui database. Satu permintaan layanan dapat memperlambat layanan lainnya. Ini buruk.

Dari sudut pandang bekerja dengan basis data untuk arsitektur layanan mikro, pola DataBase-per-Layanan harus digunakan - setiap layanan memiliki basis datanya sendiri. Jika ada banyak pecahan dalam basis data, maka pangkalan tersebut harus dibagi sehingga mereka bersinkronisasi. Ini adalah teori, tetapi kenyataannya tidak demikian.

Dalam perusahaan nyata, mereka tidak hanya menggunakan layanan mikro, tetapi juga monolit. Ada layanan yang ditulis dengan benar. Dan ada layanan lama yang masih menggunakan pola dasar umum.
Vadim Madison pada presentasinya menunjukkan gambar ini dengan keterhubungan. Hanya dia yang menunjukkannya tanpa satu komponen, dan jaringan di dalamnya seragam. Di jaringan ini di tengah ada titik yang terhubung ke banyak titik (layanan microser). Ini adalah monolit. Ini kecil dalam diagram. Namun faktanya, monolit itu besar. Ketika kita berbicara tentang perusahaan nyata, maka Anda perlu memahami nuansa koeksistensi layanan-mikro, lahir, dan keluar, tetapi arsitektur monolitik masih penting.
Bagaimana cara monolith menulis ulang ke arsitektur layanan mikro di tingkat perencanaan? Tentu saja, ini adalah pemodelan domain. Di mana-mana dikatakan bahwa Anda perlu melakukan pemodelan domain. Tetapi, misalnya, kami di Avito selama beberapa tahun menciptakan layanan microser tanpa pemodelan domain. Lalu saya mengambilnya dan pengembang basis data. Kami menyadari aliran data yang lengkap. Pengetahuan ini membantu merancang model domain.

Penemuan data memiliki interpretasi klasik - ini adalah cara bekerja dengan data yang tersebar di penyimpanan yang berbeda untuk mengarah pada kesimpulan agregat dan membuat kesimpulan yang benar. Ini sebenarnya semua omong kosong pemasaran. Definisi-definisi ini adalah tentang cara mengunduh semua data dari layanan microser ke penyimpanan. Tentang ini saya punya laporan beberapa tahun yang lalu, kami tidak akan memikirkan ini.
Saya akan memberi tahu Anda tentang proses lain yang lebih dekat dengan proses beralih ke layanan-mikro. Saya ingin menunjukkan cara bagaimana Anda dapat memahami kompleksitas sistem yang terus berkembang dalam hal data, dalam hal layanan-layanan mikro. Di mana bisa melihat seluruh gambar ratusan layanan, pangkalan, tim, orang? Sebenarnya, pertanyaan ini adalah ide utama dari laporan tersebut.

Agar tidak mati dalam arsitektur layanan mikro ini, Anda memerlukan kembaran digital. Perusahaan Anda adalah totalitas dari segala sesuatu yang menyediakan infrastruktur teknologi. Anda perlu membuat gambar yang memadai dari semua kesulitan ini, atas dasar yang Anda dapat dengan cepat menyelesaikan masalah. Dan ini bukan repositori analitik.

Tugas apa yang bisa kita atur untuk kembar digital seperti itu? Bagaimanapun, semuanya dimulai dengan penemuan data paling sederhana.
Pertanyaan:
- Layanan apa yang menyimpan data penting?
- Di mana data pribadi tidak disimpan?
- Anda memiliki ratusan pangkalan. Apa data pribadi yang ada? Dan di mana tidak?
- Bagaimana aliran data penting antar layanan?
- Misalnya, layanan tidak memiliki data pribadi, dan kemudian dia mulai mendengarkan bus, dan mereka muncul. Di mana data disalin saat dihapus?
- Siapa yang bisa bekerja dengan data apa?
- Siapa yang dapat mengakses langsung melalui layanan, beberapa melalui database, beberapa melalui bus?
- Siapa yang melalui layanan lain dapat menarik pegangan API (permintaan) dan mengunduh sesuatu?
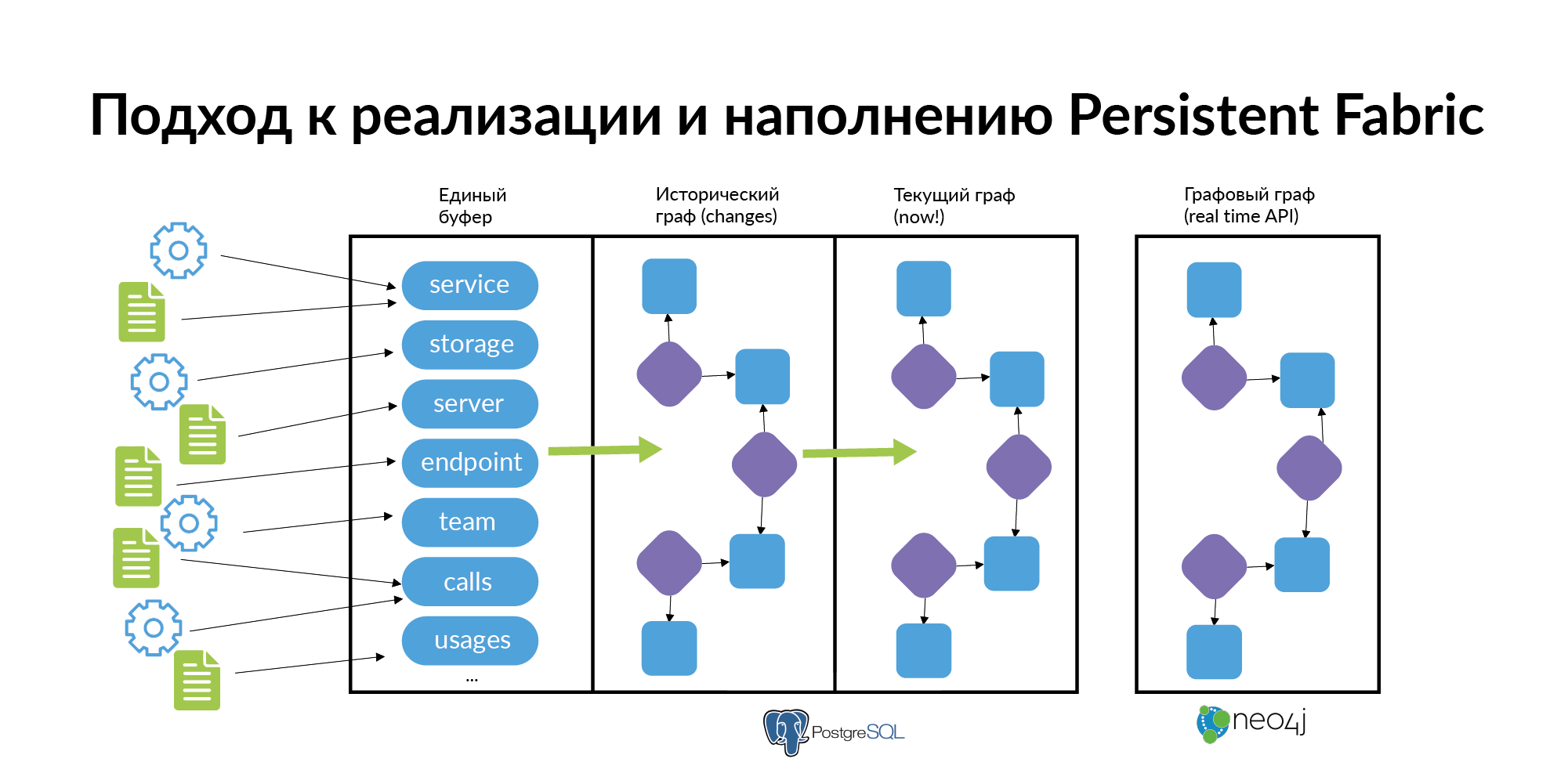
Jawaban atas pertanyaan-pertanyaan ini hampir selalu berupa grafik elemen, grafik hubungan. Grafik ini perlu diisi, diperbarui, dan dipelihara dengan data segar. Kami memutuskan untuk menyebut grafik ini Persistent Fabric (dalam terjemahan - kain ingat). Ini visualisasinya.
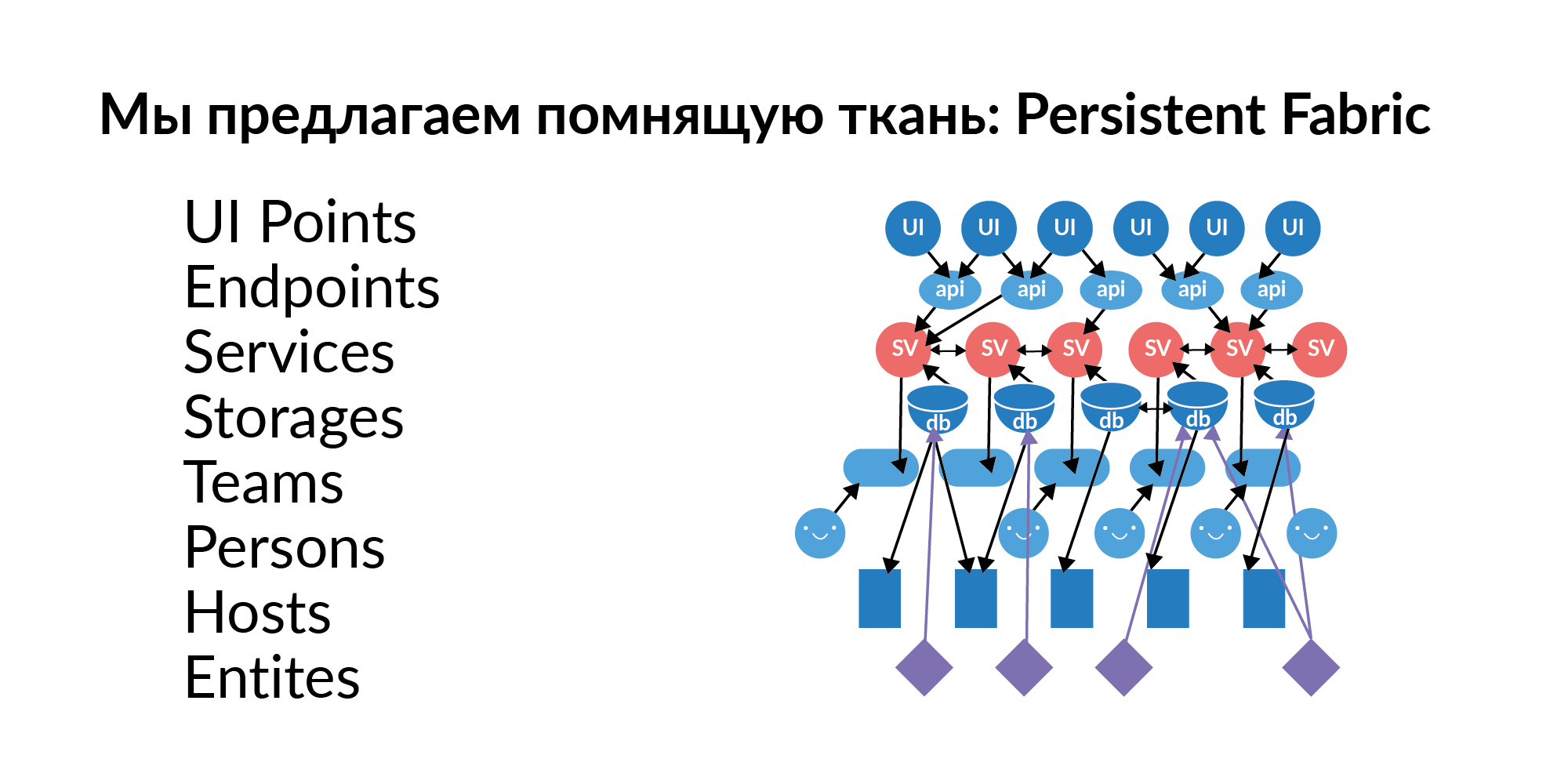
Mari kita lihat apa yang ada di dalam kain mengingat ini.
Titik antarmuka . Ini adalah elemen interaksi pengguna dengan antarmuka grafis. Mungkin ada beberapa titik UI pada satu halaman. Ini, secara relatif, tindakan kunci khusus.
Titik akhir . UI menunjukkan titik akhir brengsek. Dalam tradisi Rusia, ini disebut pena. Menangani layanan. Endpoint menarik layanan.
Layanan Ratusan layanan. Layanan saling terhubung. Kami memahami layanan mana yang dapat menarik layanan. Kami memahami panggilan ke titik UI mana yang dapat memanggil layanan mana dalam rantai.
Basis (dalam arti logis) . Basis sebagai istilah penyimpanan kedengarannya buruk, karena istilah ini merujuk pada sesuatu yang analitis. Sekarang kami menganggap database sebagai penyimpanan. Misalnya, Redis, PostgreSQL, Tarantool. Jika suatu layanan menggunakan basis data, biasanya menggunakan beberapa basis data.
- Untuk penyimpanan data jangka panjang, misalnya, PostgreSQL.
- Redis digunakan sebagai cache.
- Tarantool, yang dapat dengan cepat menghitung sesuatu dalam aliran data.
Tuan rumah Basis data memiliki penyebaran ke host. Satu markas, satu Redis sebenarnya dapat hidup di 16 mesin (master ring) dan 16 slave lainnya. Ini memberikan pemahaman tentang server mana yang Anda butuhkan untuk membatasi akses sehingga beberapa data penting tidak bocor.
Entitas . Entitas disimpan dalam database. Contoh entitas: pengguna, pengumuman, pembayaran. Entitas dapat disimpan dalam beberapa basis data. Dan di sini penting bukan hanya untuk mengetahui bahwa entitas ini ada di sana. Penting untuk mengetahui bahwa entitas ini memiliki satu penyimpanan menjadi Sumber Emas. Sumber Emas adalah basis tempat entitas dibuat dan diedit. Semua basis lainnya adalah cache fungsional. Poin penting. Jika, Tuhan melarang, suatu entitas memiliki dua Sumber Emas, maka koordinasi yang melelahkan dari sumber-sumber yang terpisah diperlukan. Entitas yang ada di database harus diberi akses ke layanan jika kita ingin memperkaya layanan ini dengan fungsionalitas baru.
Tim . Tim yang memiliki layanan. Layanan yang bukan milik tim adalah layanan yang buruk. Sulit baginya untuk menemukan seseorang yang bertanggung jawab.
Sekarang saya akan sangat berkorelasi dengan laporan Vadim Madison, karena ia menyebutkan bahwa layanan tersebut mencerminkan orang yang membuat komitmen terakhir di sana. Ini adalah titik awal yang baik. Tetapi dalam jangka panjang, ini buruk, karena orang yang terakhir berkomitmen di sana dapat berhenti.
Karena itu, Anda perlu mengetahui tim, orang-orang di dalamnya, dan peran mereka. Kami telah mendapatkan grafik sederhana, di mana pada setiap lapisan ada beberapa ratus elemen. Apakah Anda tahu sistem di mana semua ini dapat disimpan?
Poin kuncinya. Agar Persistent Fabric ini hidup, ia tidak boleh hanya diisi satu kali. Layanan dibuat, mereka mati, penyimpanan dialokasikan, mereka bergerak di sekitar server, tim dibuat, rusak, orang-orang beralih ke tim lain. Entitas baru, ditambahkan ke layanan baru, dihapus. Titik akhir dibuat, terdaftar, lintasan pengguna dari sudut pandang GUI juga dibangun kembali. Yang paling penting adalah bahwa Anda tidak perlu menyimpannya di suatu tempat secara teknis. Yang paling penting adalah membuat setiap lapisan Kain Persisten segar dan mutakhir. Itu diperbarui.
Saya mengusulkan untuk berjalan melalui lapisan. Saya akan menggambarkan bagaimana kita melakukannya. Saya akan menunjukkan bagaimana ini dapat dilakukan pada tingkat lapisan individu.

Informasi tentang tim dapat diambil dari struktur organisasi 1C. Di sini saya ingin menggambarkan bahwa Kain Persisten tidak perlu mengisi seluruh grafik raksasa untuk diisi. Setiap lapisan harus diisi dengan benar.

Informasi tentang orang dapat diambil dari LDAP. Satu orang dapat mengambil peran berbeda dalam tim yang berbeda. Ini sangat normal. Sekarang kami telah membuat sistem People Avito dan dari situ kami mengambil ikatan orang ke tim dan peran mereka. Yang paling penting adalah data sederhana tersebut pergi sehingga setidaknya mereka menyimpan tautan ke ujung tautan, sehingga nama tim sesuai dengan tim dari struktur organisasi 1C.
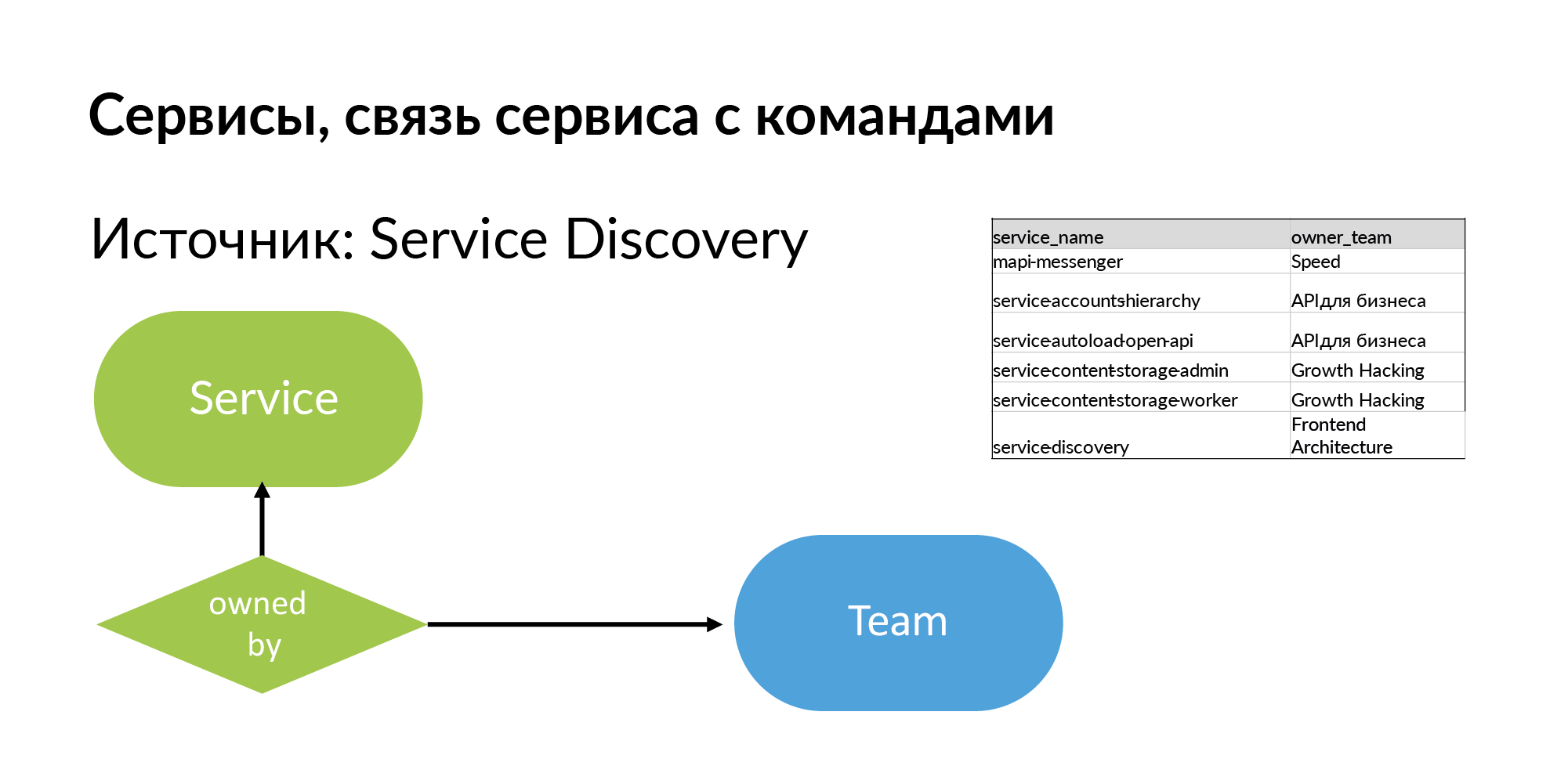
Layanan Untuk layanan, Anda perlu mendapatkan nama dan tim yang memilikinya. Sumbernya adalah Service Discovery. Ini adalah sistem yang disebutkan Vadim Madison dengan nama Atlas. Atlas adalah daftar umum layanan.
Sangat berguna untuk memahami bahwa hampir semua sistem seperti Atlas menyimpan informasi tentang 95% layanan. 5% layanan dalam sistem seperti itu tidak ada, karena layanan lama dibuat tanpa registrasi di Atlas. Dan ketika Anda mulai bekerja dengan skema ini, Anda merasakan apa yang Anda lewatkan.

Penyimpanan adalah repositori generik. Itu bisa PostgreSQL, MongoDB, Memcache, Vertica. Kami memiliki beberapa sumber untuk Penemuan Penyimpanan. Database NoSQL menggunakan setengah dari Atlas mereka sendiri. Untuk informasi tentang database PostgreSQL, parsing yaml digunakan. Tetapi mereka ingin membuat Storage Discovery mereka lebih benar.
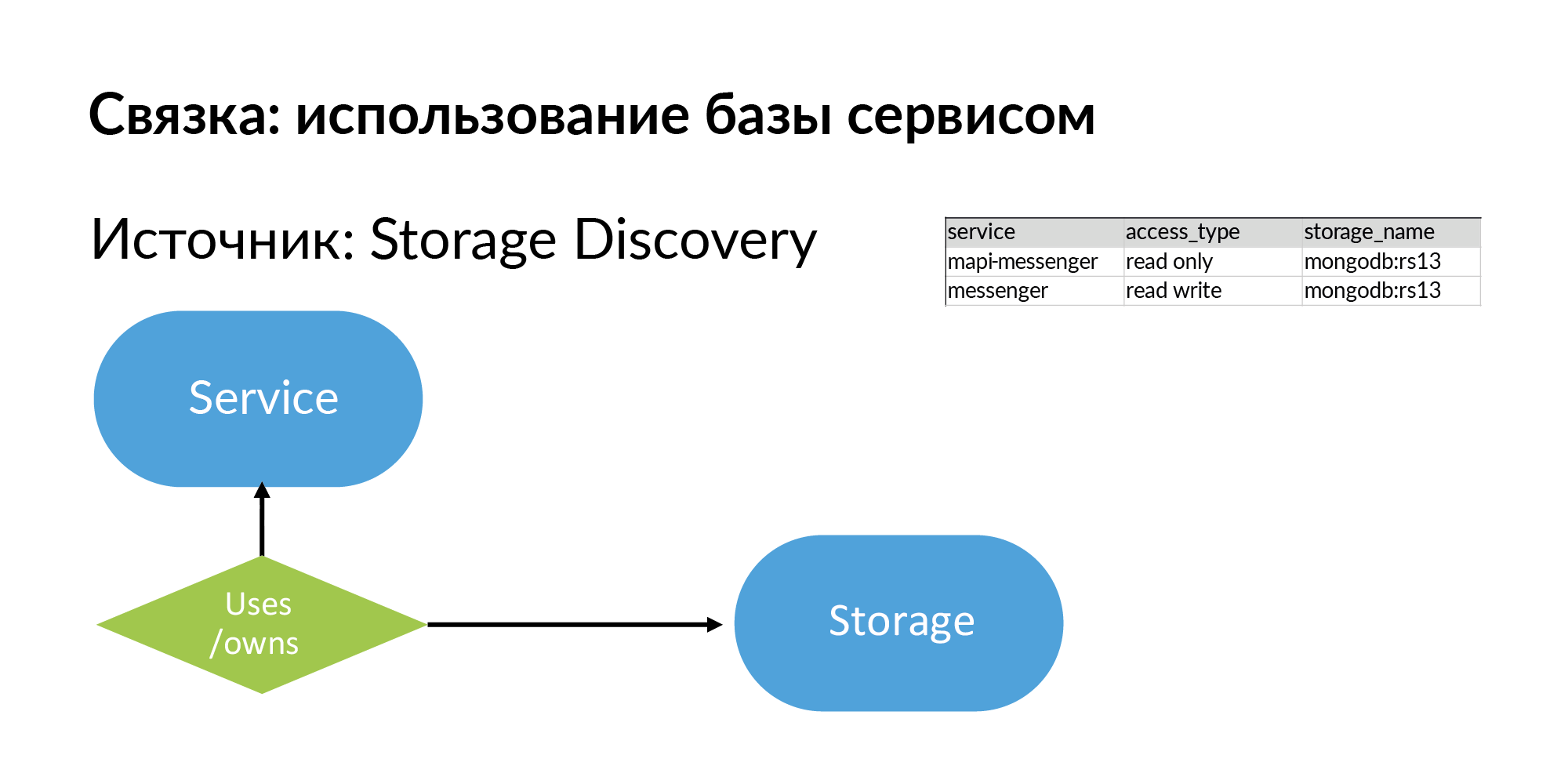
Jadi, penyimpanan dan informasi tentang apa yang menggunakan layanan, baik, atau memiliki (ini adalah jenis yang berbeda) penyimpanan. Lihat, semua yang saya jelaskan, pada prinsipnya, cukup sederhana, dapat diisi bahkan di Google Sheets.
Apa yang bisa dilakukan dengan ini? Mari kita bayangkan bahwa ini adalah grafik. Bagaimana cara kerjanya dengan grafik? Tambahkan ke basis grafik. Misalnya, dalam Neo4j. Ini sudah merupakan contoh dari kueri nyata dan contoh hasil dari kueri ini.
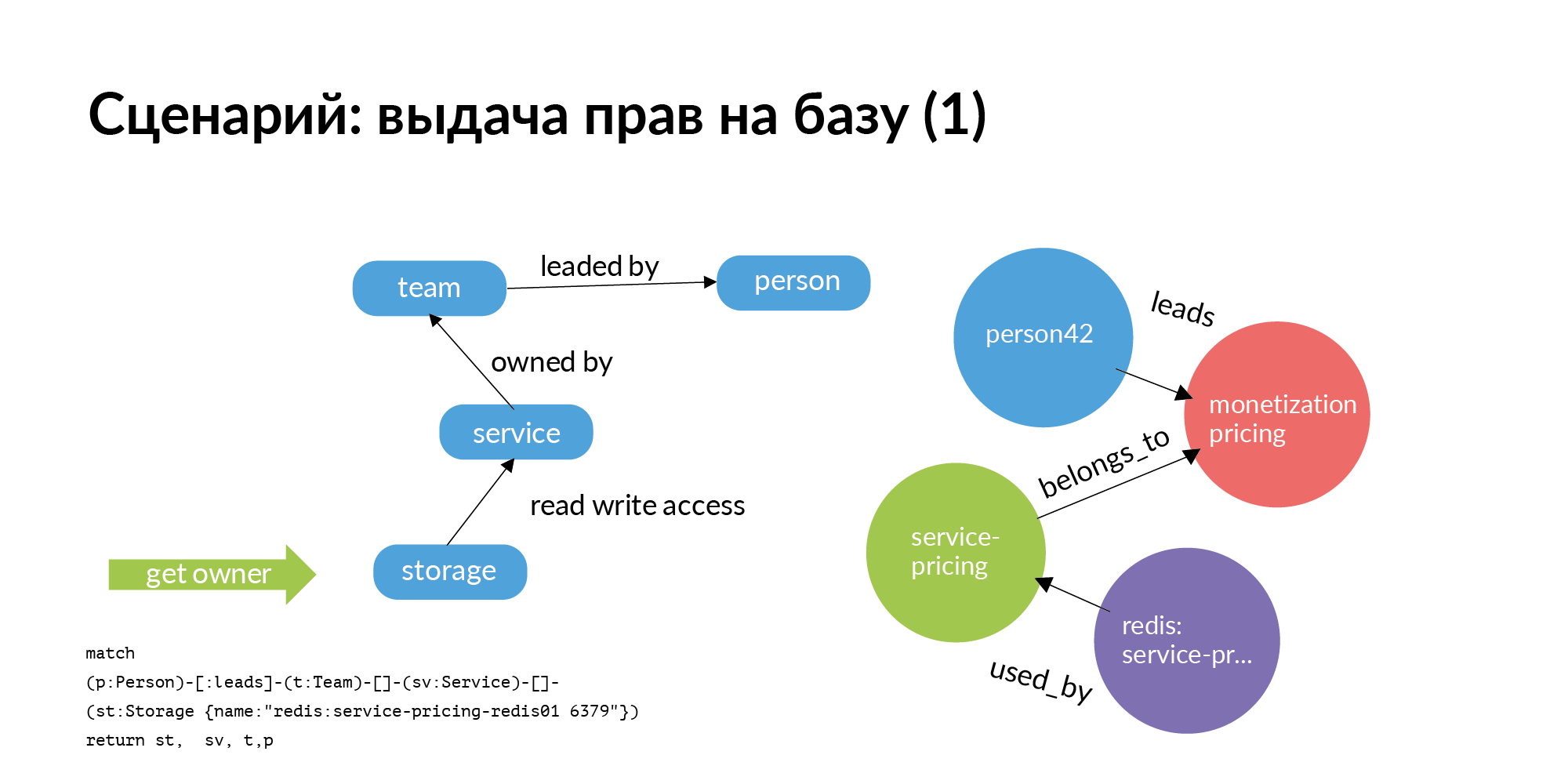
Skenario pertama. Kami perlu mengeluarkan hak untuk pangkalan. Pangkalan harus benar-benar dalam pelayanan. Ini harus mencakup hanya layanan ini dan hanya anggota tim yang memiliki layanan. Tapi kita hidup di dunia nyata. Cukup sering, tim lain merasa perlu untuk pergi ke pangkalan layanan lain. Pertanyaan: siapa yang bertanya tentang pemberian hak? Masalah yang sangat besar adalah ratusan pangkalan untuk memahami siapa yang bertanggung jawab. Terlepas dari kenyataan bahwa siapa yang membuatnya, berhenti dulu, atau dipindahkan ke posisi lain, atau tidak ingat sama sekali siapa yang bekerja dengannya.
Dan di sini adalah permintaan grafik paling sederhana (Neo4j). Anda membutuhkan akses ke penyimpanan. Anda beralih dari penyimpanan ke layanan yang memilikinya. Pergi ke tim yang memiliki layanan. Selanjutnya untuk layanan ini, Anda akan mengetahui siapa yang dimiliki tim TechLead ini. Di Avito, tim produk memiliki manajer teknis dan manajer produk yang tidak dapat membantu dengan pangkalan. Hanya setengah dari permintaan yang benar-benar ditampilkan pada slide. Akses ke penyimpanan bukan operasi atom. Untuk mengakses penyimpanan, Anda perlu mengakses server tempat penyimpanannya. Ini adalah tugas terpisah yang agak menarik.
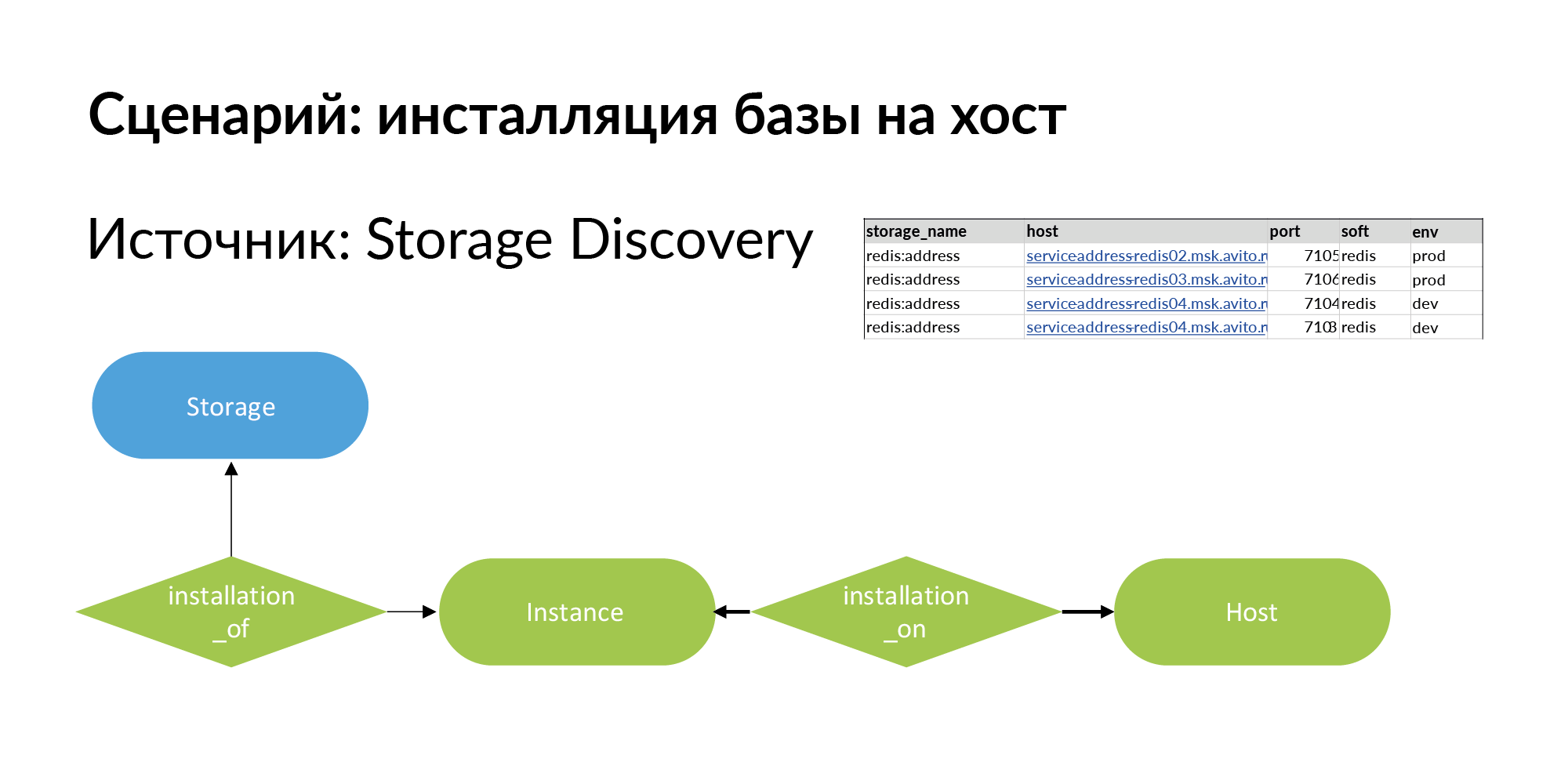
Untuk mengatasinya, kami menambahkan entitas baru. Ini adalah instalasi. Inilah masalah terminologisnya. Ada penyimpanan, misalnya pangkalan Redis (redis: address). Ada host - bisa berupa mesin fisik, wadah lxc, kubernetes. Menginstal penyimpanan di host yang kita sebut Instance.
Itu dapat memiliki empat instalasi pada tiga host, seperti yang ditunjukkan pada contoh di atas. Penyimpanan untuk produksi sebaiknya dipasang pada mesin fisik yang terpisah untuk meningkatkan kinerja. Untuk lingkungan dev, yang harus Anda lakukan adalah menginstal pada satu host dan menetapkan port yang berbeda untuk Redis.

Permintaan pertama untuk penerbitan hak ke pangkalan pergi ke kepala. Kepala menegaskan bahwa hak dapat diberikan.
Berikutnya adalah bagian kedua dari permintaan. Permintaan kedua dari penyimpanan pergi ke instance dan host. Permintaan ini mempertimbangkan semua instalasi untuk lingkungan yang sesuai. Pada slide adalah contoh untuk lingkungan produksi. Berdasarkan hal ini, hak untuk terhubung ke host tertentu dan port spesifik sudah dikeluarkan. Ini adalah contoh permintaan hibah untuk karyawan non-tim.

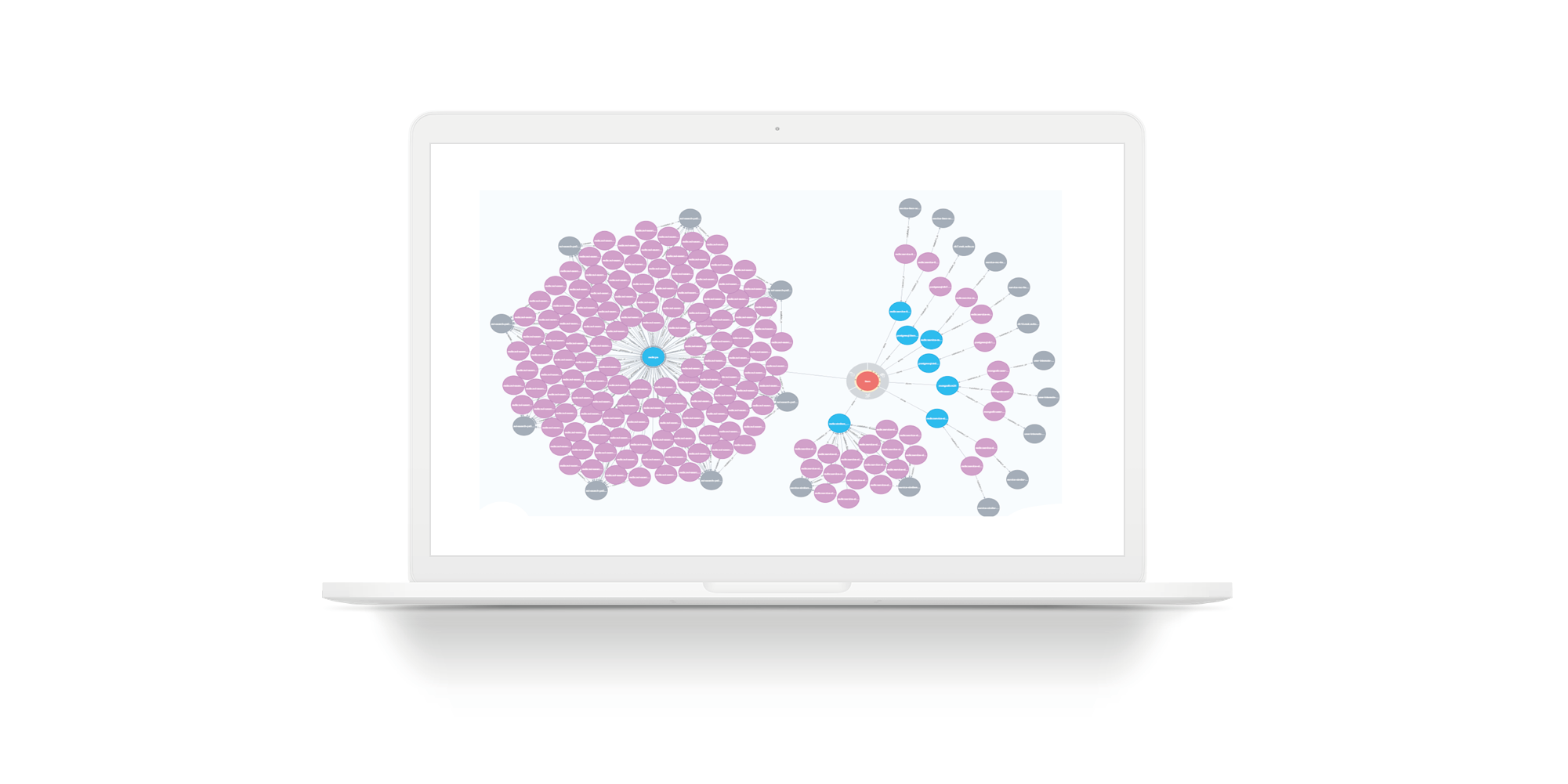
Pertimbangkan sebuah contoh ketika sebuah tim perlu mengambil karyawan baru. Ia perlu diberikan akses (untuk pemula - hanya baca) ke semua layanan, ke semua penyimpanan perintah ini. Pada slide, tim yang sebenarnya dengan pilihan yang tidak lengkap. Lingkaran hijau adalah pemimpin tim. Lingkaran merah muda adalah tim. Kuning adalah layanan. Sejumlah layanan kuning memiliki penyimpanan biru. Yang abu-abu adalah tuan rumah. Violet adalah instalasi penyimpanan di host. Ini adalah contoh untuk unit kecil. Tetapi ada banyak unit yang layanannya bukan 7, tetapi 27. Untuk unit seperti itu, gambarnya akan besar. Jika Anda menggunakan Persistent Fabric, Anda dapat membuat permintaan di dalamnya dan mendapatkan jawaban dalam daftar.

Mari terus mengisi bahan pintar kami dan berbicara tentang entitas bisnis. Entitas di Avito adalah pengumuman, pengguna, pembayaran, dan sebagainya. Dari publikasi saya ( HP Vertica, merancang gudang data , data besar , Vertica + Anchor Modeling = mulai menumbuhkan jamur Anda ) tentang gudang data, Anda tahu bahwa ada ratusan entitas ini di Avito. Faktanya, semuanya tidak harus dicatat. Dari mana saya bisa mendapatkan daftar entitas? Dari repositori analitik. Anda dapat mengunggah informasi tentang dari mana mereka mendapatkan entitas ini. Pada tahap pertama, ini sudah cukup.
Selanjutnya kami mengembangkan pengetahuan ini: untuk setiap entitas kami membuat daftar repositori di mana ia berada. Kami juga menunjukkan bahwa penyimpanan menyimpan entitas sebagai cache atau penyimpanan menyimpan entitas sebagai Sumber Emas, yaitu, itu adalah sumber utamanya.

Saat Anda mengisi kolom ini, Anda memiliki kesempatan untuk mengajukan permintaan. Anda memiliki beberapa entitas, dan Anda perlu memahami: di layanan apa entitas itu hidup, di mana ia mencerminkan, di mana penyimpanan, di mana host itu diinstal? Misalnya, saat memproses data pribadi, Anda perlu memusnahkan file log. Untuk melakukan ini, sangat penting untuk memahami mesin fisik mana file log dapat tetap.
Slide menggambarkan permintaan sederhana untuk entitas imajiner. Jumlah penyimpanan dikurangi sehingga grafik pas ke slide. Lingkaran merah adalah entitas. Lingkaran biru adalah pangkalan tempat entitas ini berada. Sisanya seperti pada slide sebelumnya: lingkaran abu-abu adalah host, lingkaran ungu adalah instalasi penyimpanan pada host.
Dengan demikian, jika Anda ingin melalui PCI DSS, Anda perlu membatasi akses ke entitas tertentu. Untuk melakukan ini, Anda perlu membatasi akses ke lingkaran abu-abu. Jika Anda membutuhkan akses waktu nyata, kami menutup akses ke lingkaran ungu. Ini informasi statis.
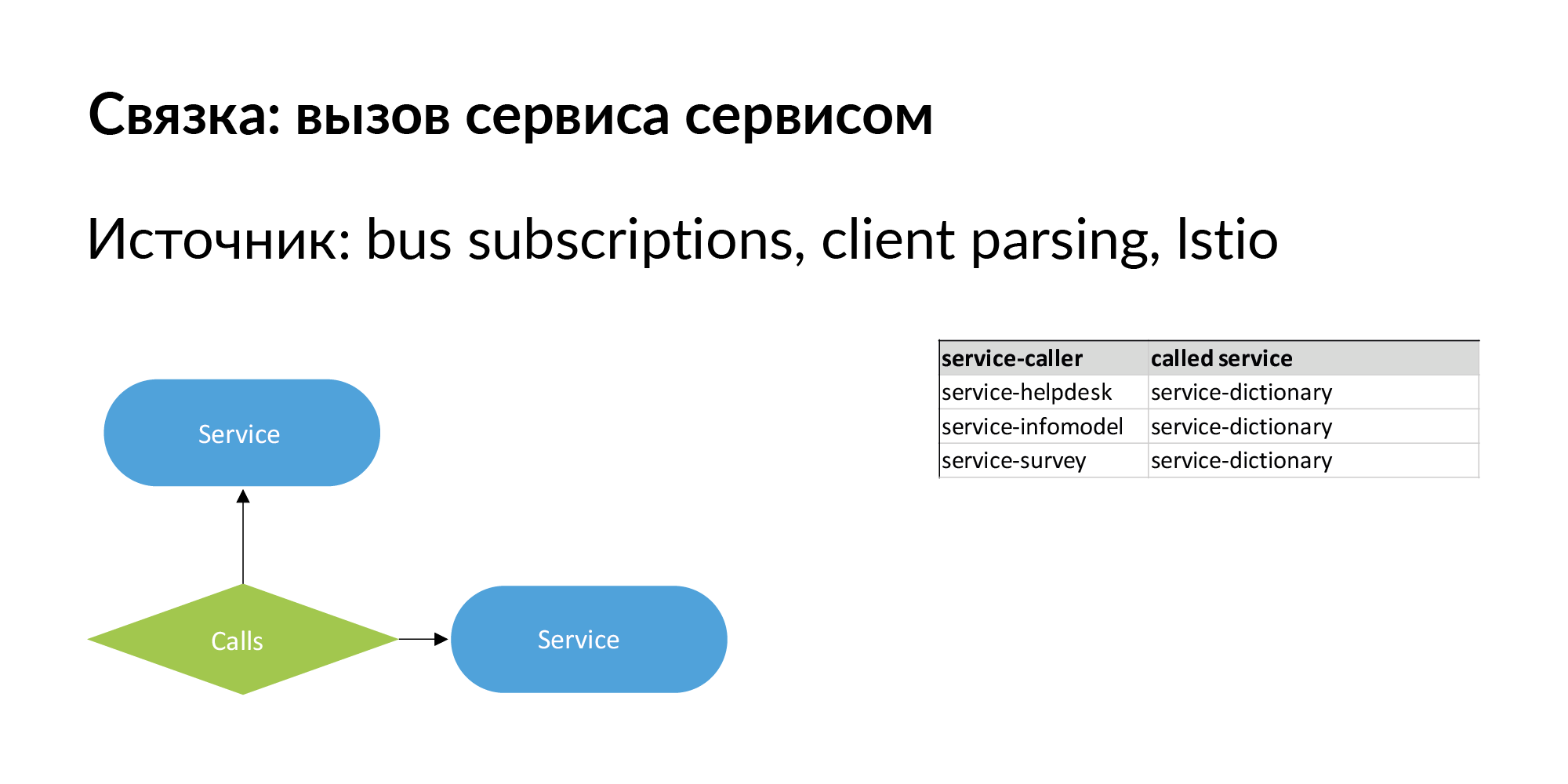
Ketika kita berbicara tentang arsitektur microservice, yang paling penting adalah bahwa itu berubah. Penting untuk tidak hanya memiliki hubungan hirarkis antara entitas, tetapi juga hubungan saudara. Banyak layanan adalah contoh dari koneksi tingkat tunggal, yang telah kami pompakan dengan baik dan gunakan. Satu bundel dari bentuk "layanan panggilan layanan". Ada informasi tentang panggilan langsung - layanan memanggil API dari layanan lain.
Seharusnya juga ada informasi tentang koneksi formulir: layanan No. 1 mengirimkan acara ke bus (antrian), dan layanan No. 2 berlangganan ke acara ini. Ini seperti koneksi lambat asinkron yang melewati bus. Hubungan ini juga penting dalam hal pergerakan data. Dengan menggunakan tautan seperti itu, Anda dapat memeriksa operasi layanan jika versi layanan yang mereka berlangganan telah berubah.
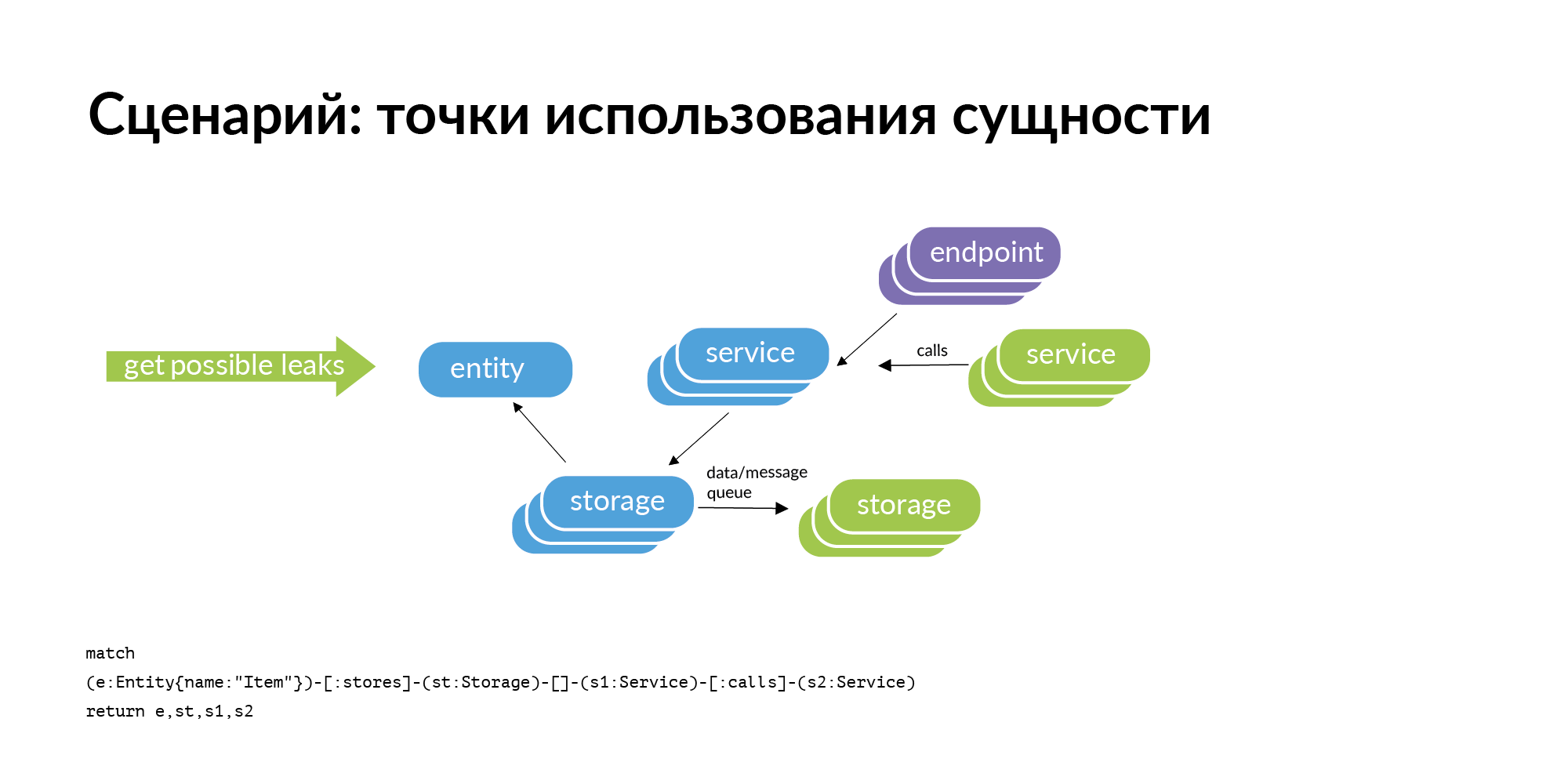
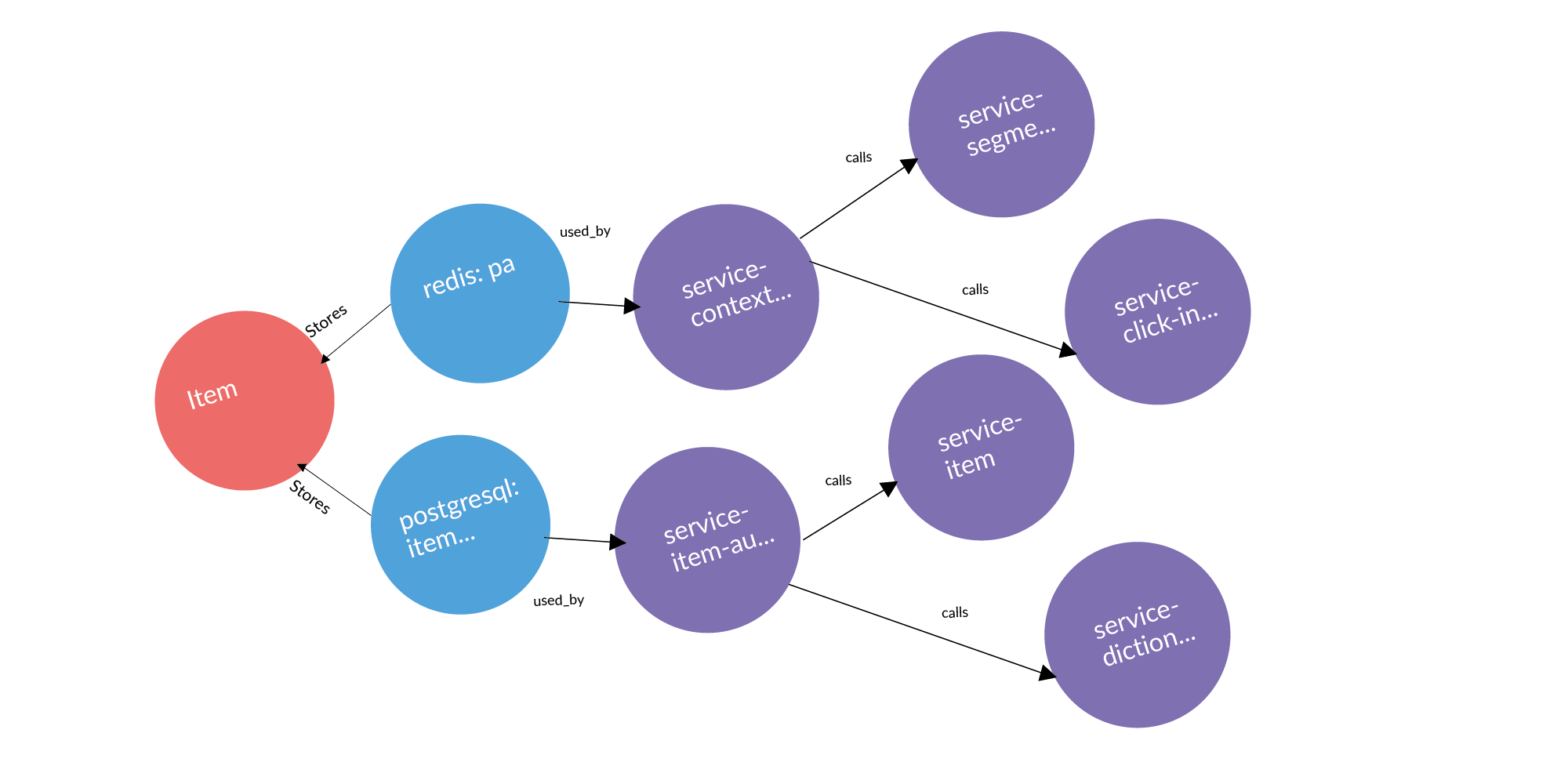
Ada entitas dan kita tahu bahwa itu disimpan dalam penyimpanan tertentu. Jika kita mempertimbangkan masalah menemukan titik menggunakan entitas, maka kueri jelas yang muncul bersama kita adalah pemeriksaan perimeter. Penyimpanan milik beberapa layanan. Di mana entitas ini bisa bocor (disalin) dari perimeter? Itu dapat bocor melalui panggilan layanan. Layanan ini menghubungi, menerima, dan mempertahankan pengguna. Itu bisa bocor melalui ban. Ban dapat menghubungkan Anda satu sama lain menggunakan RabbitMQ, Londiste. Pada slide Londiste, kami belum memuatnya. Namun panggilan sudah dimuat.
Berikut ini adalah contoh dari permintaan nyata: sebuah iklan, dua basis data tempat ia disimpan, dua layanan yang memiliki basis data ini. Setelah tiga kolom adalah layanan yang bekerja dengan layanan yang memiliki entitas ini. Ini adalah titik kebocoran potensial yang perlu ditambahkan.

Titik akhir. Vadim menyebutkan bahwa Anda dapat menggunakan dokumentasi untuk membangun registri layanan titik akhir. Anda juga dapat memperoleh informasi ini dari pemantauan. Jika Endpoint penting, maka pengembang sendiri akan menambahkannya ke pemantauan. Jika Endpoint tidak dimonitor, maka kami tidak membutuhkannya.
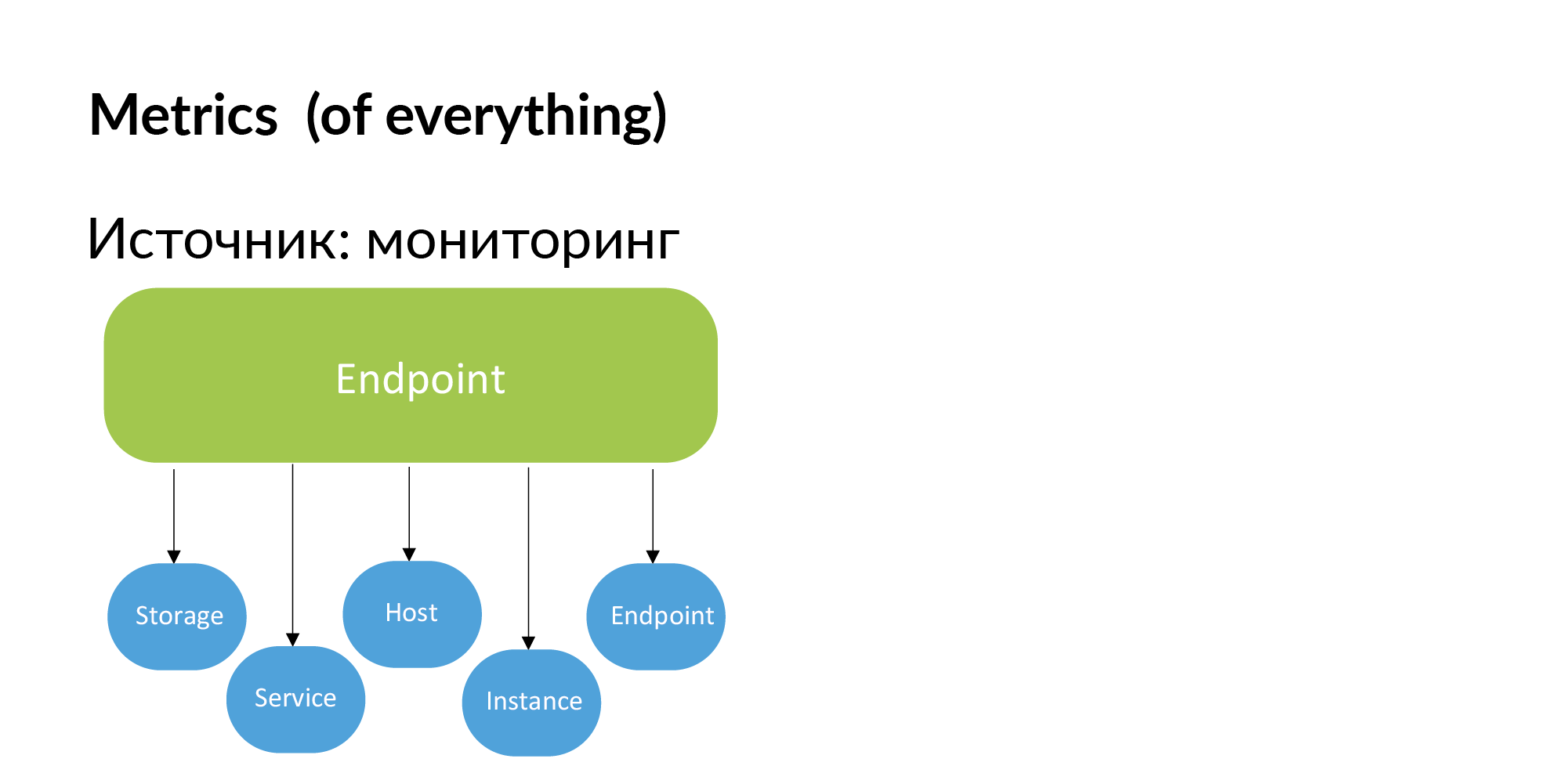
Dengan demikian, metrik dapat diperoleh dari pemantauan. Mengikat metrik ke penyimpanan, ke layanan, ke host, ke instance (basis data) dan titik akhir.

Ketika Anda menemukan kegagalan, misalnya, titik akhir mengeluarkan kode HTTP 500, maka untuk melacak akar masalah, Anda perlu membuat permintaan untuk titik akhir ini. Dari endpoint, pergi ke layanan, pergi ke layanan yang panggilan layanan ini, dari layanan pergi ke penyimpanan, dari penyimpanan pergi ke instance dan host.
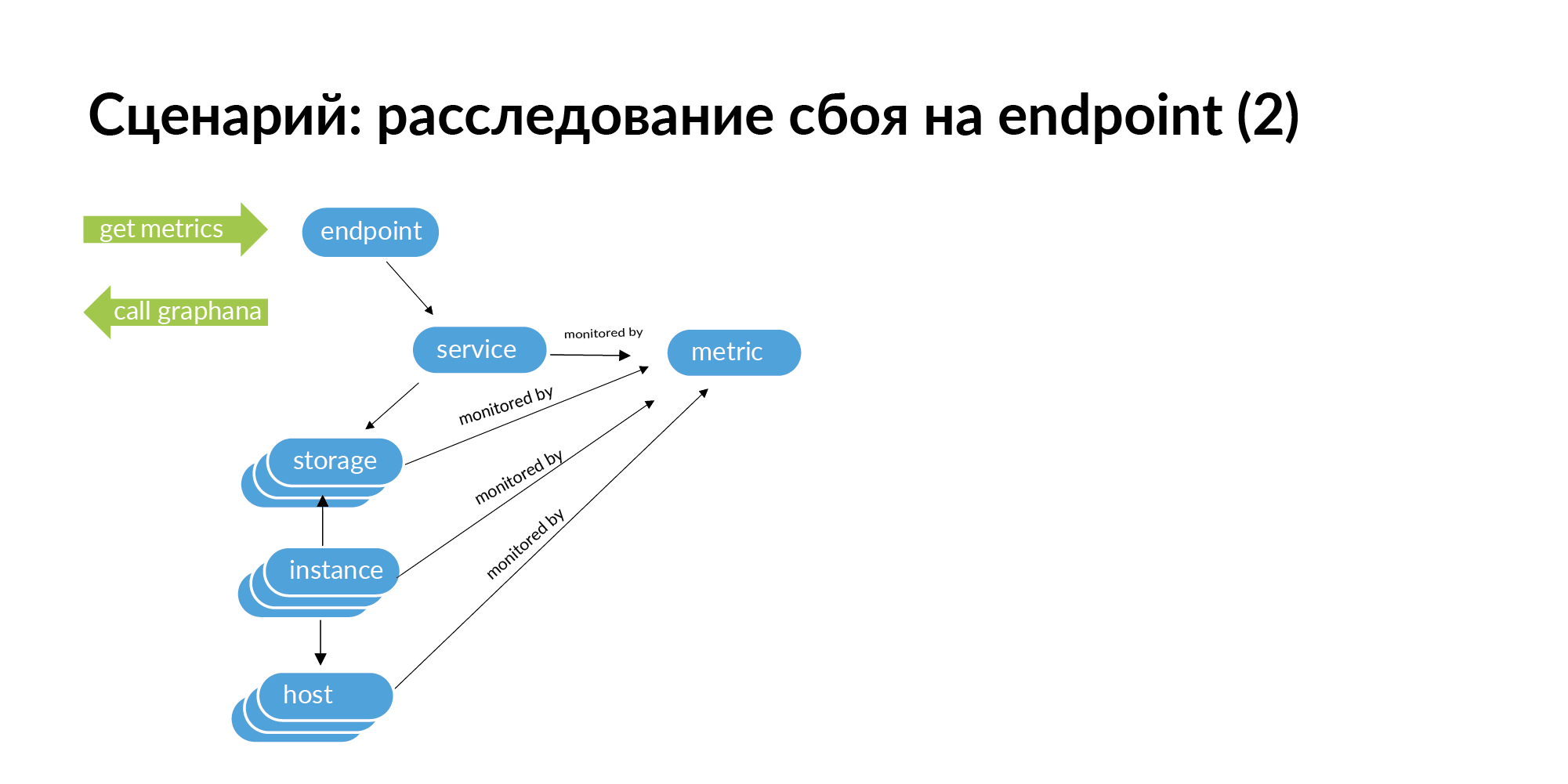
Selanjutnya, jika Anda turun grafik ini, atas dasar itu Anda bisa mendapatkan daftar pengidentifikasi untuk pemantauan. Anda dapat mencari titik akhir ini seluruh rantai ke bawah, yang dapat menyebabkan kegagalan. Dalam arsitektur microservice, kegagalan di titik akhir dapat disebabkan oleh kegagalan jaringan pada beberapa server tempat satu basis data digunakan. Hal ini dapat dilihat dalam pemantauan, tetapi dengan struktur layanan yang besar, sangat sulit untuk memeriksa semua layanan dalam pemantauan.

Pengujian. Untuk menguji secara memadai layanan mikro, Anda perlu memeriksa layanan dengan layanan lain yang perlu berfungsi. Anda perlu meningkatkan dalam lingkungan pengujian layanan yang dipanggil. Dan untuk layanan yang dipanggil, naikkan semua pangkalan. Dalam ingatan kita, kita mendapatkan subgraf yang terhubung. Di kolom ini, tidak semua koneksi diperlukan, beberapa dapat diabaikan. Subgraf ini dapat diisolasi beban diuji sebagai sistem tertutup sepenuhnya.
Akan lebih baik sekarang untuk menunjukkan grafik entitas Avito, di mana subgraph terisolasi dari layanan mikro yang dapat ditingkatkan secara independen dapat diuji dan diluncurkan dalam produksi. Faktanya, ternyata panggilan subgraph dari hampir semua layanan microser masuk dan keluar dari monolith. — , , .
, . , . . .
— , . .
- . . . . storage. — . endpoint. , , .. .
- . «» . , , , connection, connection , . , . ( , Anchor Modeling ). . « ». . Neo4j, .
- , . . , UI points frontend , backend , storage DBA, DevOps , .
in-progress
.
(Londiste, PGQ, RabbitMQ).
. UI points . . (Persistent Fabric), UI points, Endpoint, . , , , , .