CleverDATA sedang mengembangkan platform untuk bekerja dengan data besar. Secara khusus, pada platform kami dimungkinkan untuk bekerja dengan informasi dari cek belanja online. Tugas kami adalah mempelajari cara memproses data teks cek dan membuat kesimpulan tentang konsumen untuk menciptakan karakteristik yang sesuai pada pertukaran data. Itu wajar untuk mengatasi pembelajaran mesin untuk memecahkan masalah ini. Pada artikel ini kami ingin berbicara tentang masalah yang kami temui dalam klasifikasi teks cek online.
SumberPerusahaan kami mengembangkan solusi untuk monetisasi data. Salah satu produk kami adalah pertukaran data 1DMC, yang memungkinkan Anda untuk memperkaya data dari sumber eksternal (lebih dari 9000 sumber, pemirsa hariannya sekitar 100 juta profil). Tugas-tugas yang 1DMC bantu selesaikan diketahui oleh para pemasar: membangun segmen yang mirip, perusahaan media berbasis luas, kampanye iklan tertarget untuk khalayak yang sangat terspesialisasi, dll. Jika perilaku Anda dekat dengan perilaku audiens target toko, maka Anda cenderung masuk ke segmen yang mirip. Jika informasi tentang kecanduan Anda pada bidang minat apa pun dicatat, maka Anda dapat masuk ke kampanye iklan tertarget yang sangat terspesialisasi. Pada saat yang sama, semua undang-undang tentang data pribadi diterapkan, Anda menerima iklan yang lebih relevan dengan minat Anda, dan perusahaan secara efektif menggunakan anggaran mereka untuk menarik pelanggan.
Informasi tentang profil disimpan di bursa dalam bentuk berbagai atribut yang diartikan manusia:
Ini mungkin informasi bahwa seseorang memiliki peralatan motor, misalnya, helikopter sepeda motor. Atau bahwa seseorang memiliki minat pada makanan dari jenis tertentu, misalnya, dia adalah seorang vegetarian.
Pernyataan masalah dan cara untuk menyelesaikannya
Baru-baru ini, 1DMC menerima data dari salah satu operator data fiskal. Untuk menyajikannya dalam bentuk atribut profil pertukaran, menjadi perlu untuk bekerja dengan memeriksa teks dalam bentuk mentah. Berikut ini adalah teks cek khas untuk salah satu pelanggan:
Dengan demikian, tugasnya adalah mencocokkan cek dengan atribut. Menarik pembelajaran mesin untuk memecahkan masalah yang dijelaskan, pertama-tama, ada keinginan untuk mencoba metode
pengajaran tanpa guru (Pembelajaran
Tanpa Pengawasan). Guru adalah informasi tentang jawaban yang benar, dan karena kita tidak memiliki informasi ini, metode pengajaran tanpa guru bisa cocok dengan kasus yang diselesaikan. Metode pengajaran yang khas tanpa guru adalah pengelompokan, berkat sampel pelatihan ini dibagi menjadi kelompok atau kelompok yang stabil. Dalam kasus kami, setelah mengelompokkan teks sesuai dengan kata-kata, kami harus membandingkan cluster yang dihasilkan dengan atribut. Jumlah atribut unik cukup besar, sehingga diinginkan untuk menghindari markup manual. Pendekatan lain untuk mengajar tanpa guru untuk teks disebut pemodelan topik, yang memungkinkan Anda untuk mengidentifikasi topik utama dalam teks yang tidak ditempatkan. Setelah menggunakan pemodelan tematik, perlu membandingkan topik yang diperoleh dengan atribut, yang juga ingin saya hindari. Selain itu, dimungkinkan untuk menggunakan kedekatan semantik antara teks cek dan deskripsi teks atribut berdasarkan model bahasa apa pun. Namun, percobaan menunjukkan bahwa kualitas model berdasarkan kedekatan semantik tidak cocok untuk tugas kita. Dari sudut pandang bisnis, Anda harus yakin bahwa seseorang menyukai jujitsu dan itulah sebabnya ia membeli barang olahraga. Akan lebih menguntungkan jika tidak menggunakan kesimpulan menengah, kontroversial, dan diragukan. Dengan demikian, sayangnya, metode pembelajaran tanpa pengawasan tidak cocok untuk tugas tersebut.
Jika kita meninggalkan metode pembelajaran yang tidak diawasi, masuk akal untuk beralih ke metode pembelajaran yang diawasi dan, khususnya, ke klasifikasi. Guru adalah informasi tentang kelas yang benar, dan pendekatan tipikal adalah melakukan klasifikasi multi-kelas, tetapi dalam kasus ini tugas menjadi rumit oleh kenyataan bahwa kita mendapatkan terlalu banyak kelas (dengan jumlah atribut unik). Ada fitur lain: atribut dapat bekerja pada teks yang sama dalam beberapa grup, yaitu klasifikasi harus multilabel. Misalnya, informasi bahwa seseorang membeli kasing untuk telepon pintar dapat berisi atribut seperti: orang yang memiliki perangkat seperti Samsung dengan telepon Galaxy, membeli atribut Kasing Kasus Deppa, dan umumnya membeli aksesoris untuk telepon. Artinya, beberapa atribut orang tertentu harus dicatat dalam profil sekaligus.
Untuk menerjemahkan tugas ke dalam kategori "pelatihan dengan guru" Anda perlu mendapat markup. Ketika orang-orang menghadapi masalah seperti itu, mereka mempekerjakan penilai dan, dengan imbalan uang dan waktu, mendapatkan markup yang baik dan membangun model prediksi dari markup. Kemudian sering ternyata markupnya salah, dan penilai perlu terhubung untuk bekerja secara teratur, karena atribut baru dan penyedia data baru muncul. Cara alternatif adalah menggunakan Yandex. Toloki. " Ini memungkinkan Anda mengurangi biaya untuk penilai, tetapi tidak menjamin kualitas.
Selalu ada opsi untuk menemukan pendekatan baru, dan diputuskan untuk pergi dengan cara ini. Jika ada satu set teks untuk satu atribut, maka akan mungkin untuk membangun model klasifikasi biner. Teks untuk setiap atribut dapat diperoleh dari permintaan pencarian, dan untuk pencarian Anda dapat menggunakan deskripsi teks dari atribut, yang ada di taksonomi. Pada tahap ini, kami menemukan fitur berikut: teks output tidak begitu beragam untuk membangun model yang kuat dari mereka, dan untuk mendapatkan berbagai teks masuk akal untuk menggunakan augmentasi teks.
Augmentasi Teks
Untuk augmentasi teks, logis untuk menggunakan model bahasa. Hasil karya model bahasa adalah embeddings - ini adalah pemetaan dari ruang kata ke ruang vektor dengan panjang tetap tertentu, dan vektor yang sesuai dengan kata-kata yang memiliki arti yang sama akan terletak bersebelahan di ruang baru, dan jauh dalam maknanya. Untuk tugas augmentasi teks, properti ini adalah kuncinya, karena dalam hal ini perlu mencari sinonim. Untuk sekumpulan kata acak atas nama atribut taksonomi, kami mengambil sampel subset acak elemen serupa dari ruang representasi teks.
Mari kita lihat augmentasi dengan sebuah contoh. Seseorang memiliki ketertarikan pada genre mistis sinema. Kami mengambil sampel, kami mendapatkan beragam teks yang dapat dikirim ke perayap dan mengumpulkan hasil pencarian. Ini akan menjadi sampel positif untuk pelatihan pengklasifikasi.
Dan kami memilih sampel negatif dengan lebih mudah, kami mencicipi jumlah atribut yang sama yang tidak terkait dengan tema film:
Pelatihan model
Saat menggunakan pendekatan TF-IDF (misalnya, di
sini ) dengan filter berdasarkan frekuensi dan regresi logistik, Anda sudah bisa mendapatkan hasil yang sangat baik: teks yang awalnya sangat berbeda dikirim ke crawler, dan model tersebut berupaya dengan baik. Tentu saja, perlu untuk memverifikasi operasi model pada data nyata, di bawah ini kami menyajikan hasil operasi model sesuai dengan atribut "minat membeli peralatan AEG".
Setiap baris berisi kata-kata AEG, model yang diatasi tanpa positif palsu. Namun, jika kami mengambil kasus yang lebih rumit, misalnya, mobil GAZ, kami akan menghadapi masalah: model ini berfokus pada kata kunci dan tidak menggunakan konteks.
Menangani kesalahan
Kami akan membangun model yang menarik dalam melanjutkan pendidikan - kursus pelatihan kejuruan.
Kursus pelajaran sihir untuk kucing biasa juga merupakan kasus yang sulit, yang dapat menyesatkan seseorang.
Untuk memfilter positif palsu, kami menggunakan embeddings: kami menghitung pusat sampel positif di ruang embedding dan mengukur jarak ke sana untuk setiap baris.
Perbedaan jarak untuk kursus pelajaran sihir dan perolehan abstrak terlihat dengan mata telanjang.
Contoh lain: pemilik merek Audi. Jarak dalam ruang embeddings dalam hal ini juga menyelamatkan dari positif palsu.
Masalah skalabilitas
Hingga saat ini, pertukaran data beroperasi sekitar 30 ribu atribut, dan yang baru muncul secara teratur. Kebutuhan untuk otomatisasi melatih model-model baru dan menandai dengan atribut-atribut baru cukup jelas. Urutan langkah-langkah untuk membangun model atribut baru adalah sebagai berikut:
- ambil nama atribut dari taksonomi;
- buat daftar permintaan ke mesin pencari menggunakan augmentasi teks;
- pemilihan teks kraulim;
- kami melatih model klasifikasi pada sampel yang diperoleh;
- katakanlah model pembelian data mentah yang terlatih;
- filter hasilnya dengan word2vec ke pusat kelas positif.
Ada sejumlah titik lemah dalam algoritma yang dijelaskan di atas:
- sulit untuk mengendalikan kumpulan teks yang berjongkok;
- sulit untuk mengontrol kualitas sampel pelatihan;
- tidak ada cara untuk menentukan apakah model yang terlatih baik melakukan tugasnya.
Penting untuk dipahami bahwa metrik klasik tidak cocok untuk kontrol kualitas model yang terlatih, karena informasi yang hilang pada kelas benar dalam teks cek. Pembelajaran dan prediksi terjadi pada data yang berbeda, kualitas model dapat diukur pada sampel pelatihan, dan tidak ada markup pada tubuh teks utama, yang berarti Anda tidak dapat menggunakan metode biasa untuk mengevaluasi kualitas.
Penilaian kualitas model
Untuk menilai kualitas model yang dilatih, kami mengambil dua populasi: satu merujuk pada objek di bawah ambang batas respon model, yang kedua mengacu pada objek di mana model dievaluasi di atas ambang batas.
Untuk setiap populasi, kami menghitung jarak word2vec ke pusat sampel pelatihan positif. Kami mendapatkan dua distribusi jarak yang terlihat seperti ini.
Warna merah menunjukkan distribusi jarak untuk objek yang telah melewati ambang, dan biru menunjukkan objek di bawah ambang batas sesuai dengan penilaian model. Distribusi dapat dibagi, dan untuk memperkirakan jarak antara distribusi, pertama-tama logis untuk merujuk pada Kullback-Leibler Divergence (DKL). DCL adalah fungsional asimetris, ketimpangan segitiga tidak puas. Pembatasan ini mempersulit penggunaan DCL sebagai metrik, tetapi dapat digunakan jika mencerminkan ketergantungan yang diperlukan. Dalam kasus kami, DCL mengasumsikan nilai konstan pada semua model terlepas dari nilai ambang, sehingga menjadi perlu untuk mencari metode lain.
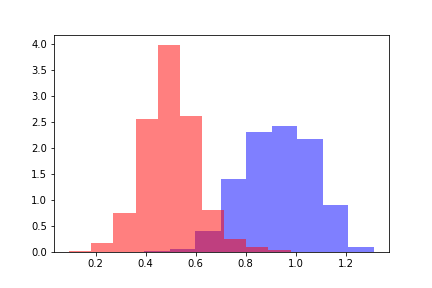
Untuk memperkirakan jarak antara distribusi, kami menghitung selisih antara nilai rata-rata distribusi. Perbedaan yang dihasilkan dapat diukur dalam standar deviasi distribusi awal jarak. Nyatakan nilai yang diperoleh dengan metrik-Z dengan analogi dengan nilai-Z, dan nilai metrik-Z akan menjadi fungsi dari nilai ambang batas dari model prediksi. Untuk setiap ambang batas tetap dari model, fungsi Z-metrik mengembalikan perbedaan antara distribusi dalam sigma dari distribusi jarak awal.
Dari banyak pendekatan yang diuji, Z-metriklah yang memberikan ketergantungan yang diperlukan untuk menentukan kualitas model yang dibangun.
Pertimbangkan perilaku metrik-Z: semakin besar metrik-Z, semakin baik model yang diatasi, karena semakin besar jarak antara distribusi mencirikan klasifikasi kualitatif. Namun, aturan keputusan yang didefinisikan dengan jelas untuk menentukan klasifikasi kualitatif tidak dapat diturunkan. Misalnya, model dengan Z-metrik di sudut kiri bawah gambar mendapat nilai konstan sama dengan 10. Model ini menentukan minat bepergian ke Thailand. Sampel pelatihan sebagian besar diiklankan oleh berbagai spa, dan model dilatih pada teks yang tidak terkait langsung dengan perjalanan ke Thailand. Artinya, model ini bekerja dengan baik, tetapi tidak mencerminkan minat dalam perjalanan ke Thailand.
Z-metic untuk sejumlah model prediksi. Model di bagian kanan gambar bagus, dan lima model di bagian kiri jelek.Selama pencarian dan percobaan, 160 model dengan markup sesuai dengan kriteria "baik / buruk" telah terkumpul. Berdasarkan tanda-tanda z-metrik, sebuah meta-model yang didasarkan pada peningkatan gradien dibangun yang menentukan kualitas model yang dibangun. Dengan demikian, dimungkinkan untuk mengkonfigurasi pemantauan kualitas model yang dibangun dalam mode otomatis.
Ringkasan
Saat ini, urutan tindakan adalah sebagai berikut:
- ambil nama atribut dari taksonomi;
- buat daftar permintaan ke mesin pencari menggunakan augmentasi teks;
- pemilihan teks kraulim;
- kami melatih model klasifikasi pada sampel yang diperoleh;
- katakanlah model pembelian data mentah yang terlatih;
- kami memfilter hasilnya dengan word2vec jarak ke pusat kelas positif;
- kami menghitung Z-metrik dan membuat tanda untuk meta-model;
- kami menggunakan meta-model dan mengevaluasi kualitas model yang dihasilkan;
- jika model memiliki kualitas yang dapat diterima, maka ditambahkan ke set model yang digunakan. Jika tidak, model kembali untuk revisi.
Menurut penilaian meta-model dalam mode otomatis, keputusan dibuat untuk memperkenalkannya ke dalam produksi atau untuk dikembalikan untuk revisi. Penyempurnaan dimungkinkan dengan berbagai cara yang telah diturunkan untuk analis.
- Seringkali model menghalangi kata-kata tertentu yang memiliki beberapa makna. Daftar hitam kata-kata menipu membuat model lebih mudah untuk dikerjakan.
- Pendekatan lain adalah membuat aturan untuk mengecualikan objek dari set pelatihan. Pendekatan ini membantu jika metode pertama tidak berhasil.
- Untuk teks kompleks dan atribut multi-nilai, kamus khusus ditransfer ke model, yang membatasi model, tetapi memungkinkan Anda untuk mengontrol kesalahan.
Tapi bagaimana dengan jaringan saraf?
Pertama-tama, ada keinginan untuk menggunakan jaringan saraf untuk tugas yang dijelaskan. Misalnya, seseorang dapat melatih Transformer pada kumpulan teks yang besar, dan kemudian membuat Transfer Pembelajaran pada set sampel pelatihan kecil dari setiap atribut. Sayangnya, penggunaan jaringan saraf seperti itu harus ditinggalkan karena alasan berikut.
- Jika model untuk satu atribut berhenti berfungsi dengan benar, maka perlu untuk dapat menonaktifkannya tanpa kehilangan atribut yang tersisa.
- Jika model tidak berfungsi dengan baik untuk satu atribut, maka perlu menyetel dan menyetel model secara terpisah, tanpa risiko merusak hasilnya untuk atribut lainnya.
- Ketika atribut baru muncul, Anda perlu mendapatkan model untuk itu sesegera mungkin, tanpa pelatihan jangka panjang semua model (atau satu model besar).
- Memecahkan masalah kontrol kualitas untuk satu atribut lebih cepat dan lebih mudah daripada menyelesaikan masalah kontrol kualitas untuk semua atribut sekaligus. Jika model besar tidak mengatasi salah satu atribut, Anda harus menyesuaikan dan menyesuaikan seluruh model besar, yang membutuhkan lebih banyak waktu dan perhatian spesialis.
Dengan demikian, ansambel model kecil independen untuk menyelesaikan masalah ternyata lebih praktis daripada model besar dan kompleks. Selain itu, model bahasa dan embedding masih digunakan untuk kontrol kualitas dan augmentasi teks, sehingga tidak mungkin untuk sepenuhnya menggunakan jaringan saraf, dan tidak ada tujuan seperti itu. Penggunaan jaringan saraf terbatas pada tugas-tugas di mana mereka diperlukan.
Untuk dilanjutkan
Pekerjaan pada proyek berlanjut: perlu untuk mengatur pemantauan, memperbarui model, bekerja dengan anomali, dll. Salah satu bidang prioritas untuk pengembangan lebih lanjut adalah tugas mengumpulkan dan menganalisis kasus-kasus yang belum diklasifikasikan oleh model apa pun dari ansambel. Namun demikian, sudah sekarang kita melihat hasil pekerjaan kami: sekitar 60% dari cek setelah menerapkan model menerima atribut mereka. Jelas, ada proporsi yang signifikan dari cek yang tidak membawa informasi tentang kepentingan pemilik, sehingga tingkat yang sepenuhnya dimiliki tidak dapat dicapai. Namun demikian, sangat menggembirakan bahwa hasil yang diperoleh sejauh ini sudah melebihi harapan kami dan kami terus bekerja ke arah ini.
Artikel ini ditulis bersama
samy1010 .
Dan pekerjaan tradisional!