Ide artikel tersebut lahir secara spontan dari diskusi di komentar pada artikel
"Sesuatu tentang inode" .
Faktanya adalah bahwa spesifikasi internal layanan kami adalah penyimpanan sejumlah besar file kecil. Saat ini, kami memiliki sekitar ratusan terabyte data tersebut. Dan kami menemukan beberapa yang jelas dan tidak terlalu menyapu dan berhasil berjalan pada mereka.
Karena itu, saya berbagi pengalaman kami, mungkin seseorang akan berguna.
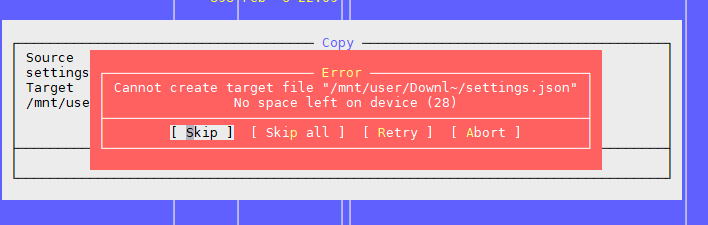
Masalah Satu: “Tidak ada ruang tersisa di perangkat”
Seperti disebutkan dalam artikel di atas, masalahnya adalah bahwa ada blok gratis di sistem file, tetapi inode sudah selesai.
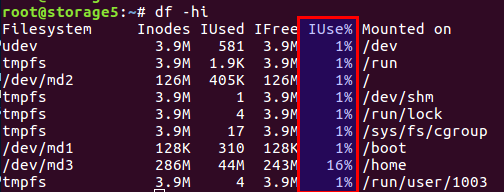
Anda dapat memeriksa jumlah inode bekas dan bebas dengan perintah
df -ih :
Saya tidak akan menceritakan kembali artikel, singkatnya, ada kedua blok untuk data langsung pada disk dan blok untuk meta-informasi, mereka juga inode (indeks node). Jumlah mereka diatur selama inisialisasi sistem file (kita berbicara tentang ext2 dan turunannya) dan tidak berubah lebih lanjut. Saldo blok data dan inode dihitung dari data rata-rata, dalam kasus kami, ketika ada banyak file kecil, keseimbangan harus bergeser ke arah jumlah inode - harus ada lebih banyak.
Linux telah menyediakan opsi dengan saldo berbeda, dan semua konfigurasi yang dihitung sebelumnya ini ada di file
/etc/mke2fs.conf .
Oleh karena itu, selama inisialisasi awal sistem file melalui mke2fs, Anda dapat menentukan profil yang diinginkan.
Berikut beberapa contoh dari file tersebut:
small = { blocksize = 1024 inode_size = 128 inode_ratio = 4096 } big = { inode_ratio = 32768 } largefile = { inode_ratio = 1048576 blocksize = -1 }
Anda dapat memilih use case yang diinginkan dengan opsi -T saat memanggil mke2fs. Anda juga dapat secara manual mengatur parameter yang diperlukan jika tidak ada solusi siap pakai.
Rincian lebih lanjut dijelaskan dalam manual untuk
mke2fs.conf dan
mke2fs .
Fitur yang tidak disebutkan dalam artikel tersebut - Anda dapat mengatur ukuran blok data. Jelas, untuk file besar, masuk akal untuk memiliki ukuran blok yang lebih besar, untuk file kecil - dalam yang lebih kecil.
Namun, ada baiknya mempertimbangkan fitur yang menarik seperti arsitektur prosesor.
Saya pernah berpikir bahwa saya membutuhkan ukuran blok yang lebih besar untuk file foto besar. Itu di rumah, pada nama file rumah WD pada arsitektur ARM. Tanpa ragu-ragu, saya mengatur ukuran blok menjadi 8k atau 16k daripada standar 4k, setelah sebelumnya mengukur penghematan. Dan semuanya indah sampai saat ketika penyimpanan itu sendiri tidak gagal, sementara disk masih hidup. Setelah memasukkan disk ke komputer biasa dengan prosesor Intel biasa, saya mendapat kejutan: ukuran blok tidak didukung. Berlayar Ada data, semuanya baik-baik saja, tetapi tidak mungkin dibaca. Prosesor i386 dan sejenisnya tidak tahu cara bekerja dengan ukuran blok yang tidak cocok dengan ukuran halaman memori, tetapi persis 4k. Secara umum, kasus ini berakhir dengan penggunaan utilitas dari ruang pengguna, semuanya lambat dan sedih, tetapi data disimpan. Siapa yang peduli - google nama utilitas
fuseext2 . Moral: baik memikirkan semua kasus di muka, atau tidak membangun pahlawan super dan menggunakan pengaturan standar untuk ibu rumah tangga.
UPD Menurut komentar pengguna,
berez mengklarifikasi bahwa untuk i386 ukuran blok tidak boleh melebihi 4k, tetapi itu tidak harus persis 4k, yaitu 1k dan 2k valid.
Jadi, bagaimana kami memecahkan masalah.
Pertama, kami mengalami masalah ketika disk multi-terabyte penuh dengan data, dan kami tidak dapat mengulang konfigurasi sistem file.
Kedua, keputusan itu mendesak.
Sebagai hasilnya, kami sampai pada kesimpulan bahwa kami perlu mengubah keseimbangan dengan mengurangi jumlah file.
Untuk mengurangi jumlah file, diputuskan untuk meletakkan file dalam satu arsip umum. Mempertimbangkan spesifikasi kami, kami menempatkan semua file dalam satu arsip untuk periode waktu tertentu, dan mengarsipkan tugas cron setiap hari di malam hari.
Arsip zip terpilih. Dalam komentar pada artikel sebelumnya, tar diusulkan, tetapi ada satu komplikasi dengan itu: tar tidak memiliki daftar isi, dan file-file tersebut di-threaded di dalamnya (karena suatu alasan, "tar" adalah singkatan dari "Arsip Arsip", sebuah warisan dari drive tape), yaitu. . jika Anda perlu membaca file di akhir arsip, Anda harus membaca seluruh arsip, karena tidak ada offset untuk setiap file relatif terhadap awal arsip. Dan karena itu operasi yang panjang. Dalam zip, semuanya jauh lebih baik: ia memiliki daftar isi dan offset file yang sama di dalam arsip, dan waktu akses ke setiap file tidak tergantung pada lokasinya. Nah, dalam kasus kami, dimungkinkan untuk mengatur opsi kompresi ke "0", karena semua file sudah dikompres dalam gzip sebelumnya.
Klien mengambil file melalui nginx, dan menurut API lama, hanya nama file yang ditentukan, misalnya seperti ini:
http://www.server.com/hydra/20170416/0453/3bd24ae7-1df4-4d76-9d28-5b7fcb7fd8e5
Untuk membongkar file dengan cepat, kami menemukan dan menghubungkan modul modul nginx-unzip (
https://github.com/youzee/nginx-unzip-module ) dan menyiapkan dua upstream.
Hasilnya adalah konfigurasi ini:

Dua host di pengaturan tampak seperti ini:
server { listen *:8081; location / { root /home/filestorage; } }
server { listen *:8082; location ~ ^/hydra/(\d+)/(\d+)/(.*)$ { root /home/filestorage; file_in_unzip_archivefile "/home/filestorage/hydra/$1/$2.zip"; file_in_unzip_extract "$2/$3"; file_in_unzip; } }
Dan konfigurasi hulu pada hulu nginx:
upstream storage { server server.com:8081; server server.com:8082; }
Cara kerjanya:
- Klien pergi ke nginx depan
- Front nginx mencoba memberikan file dari hulu pertama, mis. langsung dari sistem file
- Jika tidak ada file, ia mencoba memberikannya dari hulu kedua, yang mencoba menemukan file di dalam arsip
Masalah kedua: sekali lagi, "Tidak ada ruang tersisa di perangkat"
Ini adalah masalah kedua yang kami temui ketika ada banyak file di direktori.
Kami mencoba membuat file, sistem bersumpah bahwa tidak ada ruang. Ubah nama file dan coba buat lagi.
Ternyata.
Itu terlihat seperti ini:

Memeriksa inode tidak memberi apa-apa - ada banyak dari mereka gratis.
Memeriksa tempat itu sama.
Kami pikir mungkin ada terlalu banyak file dalam direktori, tetapi ada batasnya, tetapi sekali lagi tidak: Jumlah maksimum file per direktori: ~ 1,3 × 10 ^ 20
Ya, dan Anda dapat membuat file jika Anda mengubah nama.
Kesimpulannya adalah masalah dalam nama file.
Pencarian lebih lanjut menunjukkan bahwa masalahnya ada dalam algoritma hashing ketika membangun indeks direktori, dengan sejumlah besar file ada tabrakan dengan semua konsekuensi berikutnya. Detail lebih lanjut dapat ditemukan di sini:
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Hash_Tree_DirectoriesAnda dapat menonaktifkan opsi ini, tetapi ... mencari file dengan nama bisa menjadi panjang tak terduga saat menyortir semua file.
tune2fs -O "^dir_index" /dev/sdb3
Secara umum, bagaimana solusinya mungkin bekerja.
Moral: banyak file dalam direktori biasanya buruk. Ini tidak perlu.
Biasanya dalam kasus seperti itu mereka membuat subdirektori, dengan huruf pertama dari nama file atau dengan beberapa parameter lain, misalnya, berdasarkan tanggal, dalam kebanyakan kasus ini menyimpan.
Tetapi jumlah total file kecil masih buruk, bahkan jika mereka dibagi menjadi direktori - lalu lihat masalah pertama.
Masalah ketiga: cara melihat daftar file, jika ada banyak
Dalam situasi kami, ketika kami memiliki banyak file, dengan satu atau lain cara kami dihadapkan dengan masalah cara melihat isi direktori.
Solusi standar adalah
ls .
Oke, mari kita lihat apa yang terjadi pada 4772098 file:
$ time ls /home/app/express.repository/offercache/ >/dev/null real 0m30.203s user 0m28.327s sys 0m1.876s
30 detik ... itu akan terlalu banyak. Dan sebagian besar waktu yang dibutuhkan untuk memproses file di ruang pengguna, dan tidak sama sekali ke kernel.
Tapi ada solusinya:
$ time find /home/app/express.repository/offercache/ >/dev/null real 0m3.714s user 0m1.998s sys 0m1.717s
3 detik 10 kali lebih cepat.
Hore!
UPDSolusi yang lebih cepat dari pengguna
berez adalah menonaktifkan penyortiran
ls time ls -U /home/app/express.repository/offercache/ >/dev/null real 0m2.985s user 0m1.377s sys 0m1.608s
Masalah keempat: LA besar saat bekerja dengan file
Secara berkala, sebuah situasi muncul ketika Anda perlu menyalin banyak file dari satu mesin ke komputer lain. Pada saat yang sama, LA sering tumbuh tidak realistis, karena semuanya tergantung pada kinerja disk itu sendiri.
Hal paling masuk akal yang Anda inginkan adalah menggunakan SSD. Sangat keren. Satu-satunya pertanyaan adalah biaya SSD multi-terabyte.
Tetapi jika disk biasa, Anda perlu menyalin file, dan ini juga merupakan sistem produksi, di mana kelebihan menyebabkan seruan tidak puas dari pelanggan? Setidaknya ada dua alat yang berguna:
nice dan
ionice .
nice - mengurangi prioritas proses, masing-masing, sheduler mendistribusikan lebih banyak irisan waktu ke proses lain yang lebih prioritas.
Dalam praktik kami, membantu menetapkan nice to maximum (19 adalah prioritas minimum, -20 (minus 20) adalah maksimum).
ionice - dengan demikian menyesuaikan prioritas input / output (penjadwalan I / O)
Jika Anda menggunakan RAID dan perlu menyinkronkan secara tiba-tiba (setelah reboot gagal atau perlu mengembalikan array RAID setelah mengganti disk), maka dalam beberapa situasi masuk akal untuk mengurangi kecepatan sinkronisasi sehingga proses lain dapat bekerja lebih atau kurang cukup. Untuk melakukan ini, perintah berikut akan membantu:
echo 1000 > /proc/sys/dev/raid/speed_limit_max
Masalah kelima: Cara menyinkronkan file secara real-time
Kami memiliki semua file dalam jumlah besar yang sama yang harus didukung ke server kedua untuk menghindari ... File terus-menerus ditulis, oleh karena itu, agar memiliki kerugian minimum, Anda harus menyalinnya secepat mungkin.
Solusi Standar: Rsync over SSH.
Ini adalah pilihan yang baik, kecuali jika Anda perlu melakukannya setiap beberapa detik sekali. Dan ada banyak file. Bahkan jika Anda tidak menyalinnya, Anda masih perlu memahami apa yang telah berubah, dan membandingkan beberapa juta file adalah waktu dan pemuatan di disk.
Yaitu kita harus segera tahu apa yang akan disalin, tanpa memulai perbandingan setiap saat.
Keselamatan -
lsyncd .
Lsyncd -
Daemon Sinkronisasi Langsung (Cermin) . Ini juga bekerja melalui rsync, tetapi juga memonitor sistem file untuk perubahan menggunakan inotify dan fsevents dan mulai menyalin hanya untuk file-file yang telah muncul atau diubah.
Masalah keenam: bagaimana memahami siapa yang memuat disk
Semua orang mungkin mengetahui hal ini, namun demikian
iotop kelengkapan: untuk memantau subsistem disk terdapat perintah
iotop - seperti
top , tetapi menunjukkan proses yang menggunakan disk paling aktif.

Omong-omong, atasan lama yang baik juga menjelaskan bahwa ada masalah dengan disk atau tidak. Ada dua parameter yang paling cocok untuk ini:
Load Average dan
IOwait .
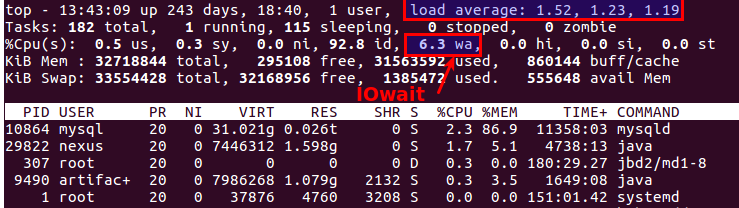
Yang pertama menunjukkan berapa banyak proses dalam antrian layanan, biasanya lebih dari 2 - ada sesuatu yang salah. Dengan penyalinan aktif ke server cadangan, kami mengizinkan hingga 6-8, setelah itu situasinya dianggap tidak normal.
Yang kedua adalah seberapa banyak prosesor sibuk dengan operasi disk. IOwait> 10% memprihatinkan, meskipun pada server dengan profil beban tertentu stabil 40-50%, dan ini benar-benar normal.
Saya akan mengakhiri di sini, meskipun mungkin ada banyak hal yang tidak harus kita hadapi, saya akan senang menunggu komentar dan deskripsi kasus nyata yang menarik.