Dalam
artikel sebelumnya, saya berbicara tentang infrastruktur uji beban besar kami. Rata-rata, kami membuat sekitar 100 server untuk memasok beban dan sekitar 150 server untuk layanan kami. Semua server ini harus dibuat, dihapus, dikonfigurasi, dan dijalankan. Untuk melakukan ini, kami menggunakan alat yang sama seperti pada prod untuk mengurangi jumlah pekerjaan manual:
- Untuk membuat dan menghapus lingkungan pengujian - Skrip Terraform;
- Untuk mengonfigurasi, memperbarui, dan menjalankan - Skrip yang mungkin;
- Untuk penskalaan dinamis tergantung pada beban - skrip Python yang ditulis sendiri.
Berkat skrip Terraform dan Ansible, semua operasi mulai dari membuat instance hingga memulai server dilakukan hanya dengan enam perintah:
# aws ansible-playbook deploy-config.yml # ansible-playbook start-application.yml # ansible-playbook update-test-scenario.yml --ask-vault-pass # Jmeter , infrastructure-aws-cluster/jmeter_clients:~# terraform apply # jmeter ansible-playbook start-jmeter-server-cluster.yml # jmeter ansible-playbook start-stress-test.yml #
Penskalaan server dinamis
Pada jam sibuk produksi, kami memiliki lebih dari 20 ribu pengguna online pada saat yang sama, dan pada jam lain mungkin ada 6 ribu. Tidak masuk akal untuk terus menjaga volume penuh server, jadi kami mengatur penskalaan otomatis untuk server-papan, di mana papan terbuka saat pengguna memasukinya, dan untuk server-API yang memproses permintaan API. Sekarang server dibuat dan dihapus jika perlu.
Mekanisme seperti ini sangat efektif dalam pengujian beban: secara default, kita dapat memiliki jumlah minimum server, dan pada saat pengujian mereka akan secara otomatis naik dalam jumlah yang tepat. Pada awalnya, kita dapat memiliki 4 server papan, dan pada puncaknya - hingga 40. Pada saat yang sama, server baru tidak dibuat segera, tetapi hanya setelah server saat ini dimuat. Misalnya, kriteria untuk membuat instance baru mungkin 50% dari pemanfaatan CPU. Ini memungkinkan Anda untuk tidak memperlambat pertumbuhan pengguna virtual dalam skrip dan tidak membuat server yang tidak perlu.
Bonus dari pendekatan ini adalah bahwa berkat penskalaan dinamis, kami mempelajari berapa kapasitas yang kami butuhkan untuk jumlah pengguna yang berbeda, yang belum kami miliki pada penjualan tersebut.
Koleksi metrik seperti pada prod
Ada banyak pendekatan dan alat untuk memantau tes stres, tetapi kami melakukannya dengan caranya sendiri.
Kami memantau produksi dengan tumpukan standar: Logstash, Elasticsearch, Kibana, Prometheus dan Grafana. Cluster kami untuk pengujian mirip dengan produk, jadi kami memutuskan untuk melakukan pemantauan yang sama dengan prod, dengan metrik yang sama. Ada dua alasan untuk ini:
- Tidak perlu membangun sistem pemantauan dari awal, kami sudah memilikinya lengkap dan segera;
- Kami juga menguji pemantauan penjualan: jika selama pemantauan pengujian kami memahami bahwa kami tidak memiliki cukup data untuk menganalisis masalah, maka mereka tidak akan cukup untuk produksi, ketika masalah seperti itu muncul di sana.
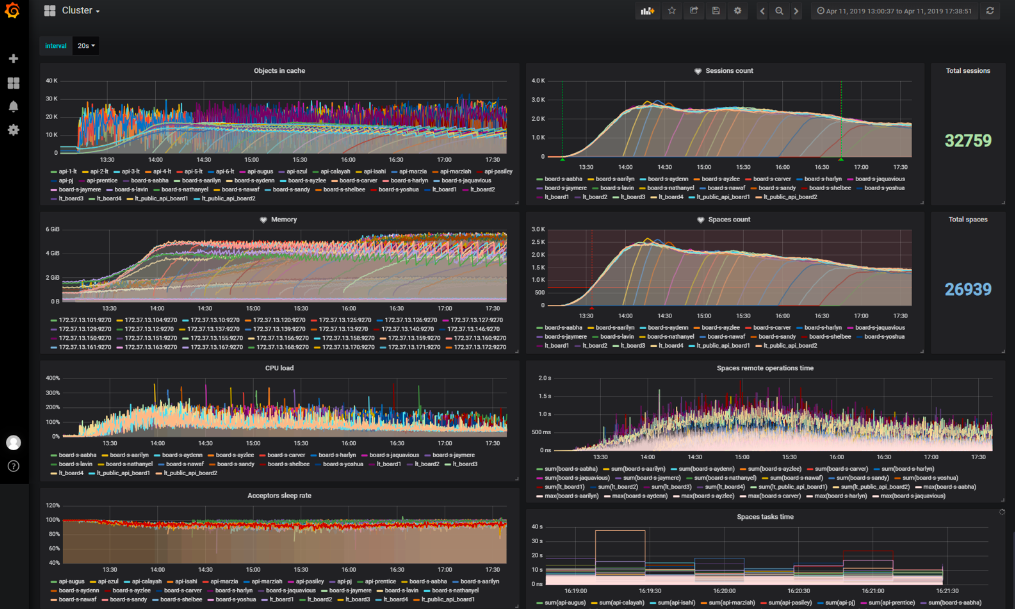
Apa yang kami tunjukkan dalam laporan
- Karakteristik teknis dudukan;
- Script itu sendiri, dijelaskan dalam kata-kata, bukan kode;
- Hasil yang dapat dimengerti oleh semua anggota tim, baik pengembang maupun manajer;
- Grafik keadaan umum dudukan;
- Grafik yang menunjukkan bottleneck atau yang dipengaruhi oleh optimasi diperiksa dalam tes.
Penting bahwa semua hasil disimpan di satu tempat. Jadi akan lebih mudah untuk membandingkan mereka satu sama lain dari peluncuran ke peluncuran.
Kami membuat laporan dalam produk kami
(contoh papan tulis dengan laporan) :
Membuat laporan membutuhkan banyak waktu. Karena itu, kami berencana untuk membuat pengumpulan informasi umum otomatis menggunakan
API publik kami .
Infrastruktur sebagai kode
Kami bertanggung jawab atas kualitas produk, bukan QA Engineers, tetapi seluruh tim. Tes stres adalah salah satu alat jaminan kualitas. Keren, jika tim mengerti bahwa penting untuk memeriksa di bawah memuat perubahan yang telah dibuat. Untuk mulai memikirkannya, dia harus bertanggung jawab atas produksi. Di sini kami dibantu oleh prinsip-prinsip budaya DevOps, yang kami mulai terapkan dalam pekerjaan kami.
Tetapi mulai berpikir untuk melakukan tes stres hanyalah langkah pertama. Tim tidak akan dapat memikirkan tes tanpa memahami perangkat produksi. Kami menghadapi masalah seperti itu ketika kami mulai mengatur proses melakukan tes beban dalam tim. Pada saat itu, tim tidak memiliki cara untuk mengetahui alat produksi, sehingga sulit bagi mereka untuk bekerja pada desain tes. Ada beberapa alasan: kurangnya dokumentasi terbaru atau satu orang yang akan menyimpan seluruh gambar di kepala; beberapa pertumbuhan tim pengembangan.
Untuk membantu tim memahami pekerjaan penjualan, pendekatan Infrastruktur dapat digunakan sebagai kode, yang mulai kami gunakan dalam tim pengembangan.
Masalah apa yang sudah kami mulai pecahkan dengan menggunakan pendekatan ini:
- Semuanya harus ditulis dan dapat dinaikkan kapan saja. Ini secara signifikan mengurangi waktu pemulihan untuk penjualan jika terjadi kecelakaan pusat data dan memungkinkan Anda untuk menjaga jumlah lingkungan pengujian yang relevan dengan tepat;
- Penghematan yang wajar: kami menerapkan lingkungan di Openstack ketika itu dapat menggantikan platform mahal seperti AWS;
- Tim sendiri membuat tes stres karena mereka mengerti perangkat itu laku;
- Kode menggantikan dokumentasi, sehingga tidak perlu memperbaharuinya tanpa henti, selalu lengkap dan terkini;
- Anda tidak perlu ahli terpisah di bidang sempit untuk menyelesaikan masalah biasa. Insinyur mana pun dapat mengetahui kode tersebut;
- Dengan struktur penjualan yang jelas, jauh lebih mudah untuk menjadwalkan tes beban penelitian seperti pengujian kekacauan monyet atau tes kebocoran memori yang panjang.
Saya ingin memperluas pendekatan ini tidak hanya untuk penciptaan infrastruktur, tetapi juga dengan dukungan berbagai alat. Sebagai contoh, tes database, yang saya
bicarakan di artikel sebelumnya , kami benar-benar berubah menjadi kode. Karena itu, alih-alih situs yang disiapkan sebelumnya, kami memiliki serangkaian skrip, yang dengannya dalam 7 menit kami mendapatkan lingkungan yang dikonfigurasi dalam akun AWS yang benar-benar kosong dan dapat memulai pengujian. Untuk alasan yang sama, kami sekarang mempertimbangkan
Gatling dengan hati-hati, yang pembuatnya posisikan sebagai alat untuk "Memuat uji sebagai kode".
Pendekatan infrastruktur sebagai kode memerlukan pendekatan yang sama untuk mengujinya dan skrip yang ditulis tim untuk meningkatkan infrastruktur fitur baru. Semua ini harus ditanggung oleh tes. Ada juga berbagai kerangka kerja pengujian, seperti
Molekul . Ada alat untuk pengujian kekacauan monyet, untuk AWS ada alat berbayar, untuk Docker ada
Pumba , dll. Mereka memungkinkan Anda untuk menyelesaikan berbagai jenis tugas:
- Cara memeriksa apakah salah satu contoh di AWS lumpuh untuk memeriksa apakah beban pada server yang tersisa diseimbangkan kembali dan jika layanan akan selamat dari pengalihan permintaan yang sedemikian tajam;
- Bagaimana mensimulasikan operasi lambat jaringan, kerusakan dan masalah teknis lainnya, setelah itu logika infrastruktur layanan tidak boleh rusak.
Solusi masalah seperti itu dalam rencana langsung kami.
Kesimpulan
- Tidak sepadan dengan waktu untuk mengatur secara manual infrastruktur pengujian, lebih baik mengotomatiskan tindakan ini untuk mengelola semua lingkungan dengan lebih andal, termasuk prod;
- Penskalaan dinamis secara signifikan mengurangi biaya mempertahankan penjualan dan lingkungan pengujian yang besar, dan juga mengurangi faktor manusia saat penskalaan;
- Anda tidak dapat menggunakan sistem pemantauan terpisah untuk pengujian, tetapi ambil dari pasar;
- Adalah penting bahwa laporan stress test dikumpulkan secara otomatis di satu tempat dan memiliki pandangan yang seragam. Ini akan memungkinkan mereka untuk dengan mudah membandingkan dan menganalisis perubahan;
- Tes stres akan menjadi proses di perusahaan ketika tim merasa bertanggung jawab atas penjualan;
- Tes beban - tes infrastruktur. Jika tes beban berhasil, ada kemungkinan itu tidak dikompilasi dengan benar. Validasi kebenaran tes membutuhkan pemahaman yang mendalam tentang penjualan. Tim harus memiliki kesempatan untuk memahami perangkat penjualan secara mandiri. Kami memecahkan masalah ini dengan menggunakan Infrastruktur sebagai pendekatan Kode;
- Skrip persiapan infrastruktur juga memerlukan pengujian seperti kode lainnya.